- 机器学习概述
- 机器学习算法基础
XGBoost小试牛刀XGBoost原理与理论证明- 模型选择与优化
- XGBoost应用
机器学习概述
何谓机器学习
机器学习应用开发步骤
定义问题
数据采集
数据清洗
通过数据采集得到的原始数据可能并不规范,需对数据进行清洗才能满足使用需求。例如,去掉数据集中的重复数据、噪声数据,修正错误数据等,最后将数据转换为需要的格式,以方便后续处理。
特征选择与处理
特征选择是在原始特征中选出对模型有用的特征,去除数据集中与模型预测无太大关系的特征。通过分析数据,可以人工选择贡献较大的特征,也可以采用类似PCA等算法进行选择。此外,还要对特征进行相应处理,如对数值型特征进行标准化,对类别型特征进行one-hot编码等。
训练模型
特征数据准备完成后,即可根据具体任务选择合适的模型并进行训练。对于监督学习,一般会将数据集分为训练集和测试集,通过训练集训练模型参数,然后通过测试集测试模型精度。而无监督学习则不需对算法进行训练,而只需通过算法发现数据的内在结构,发现其中的隐藏模式即可。
模型评估与调优
模型使用
集成学习发展与XGBoost提出
集成学习是目前机器学习领域最热门的研究方向之一,近年来许多机器学习竞赛的冠军均使用了集成学习,而XGBoost是集成学习中集大成者。
集成学习
集成学习的基本思想是把多个学习器通过一定方法进行组合,以达到最终效果的提升。虽然每个学习器对全局数据的预测精度不高,但在某一方面的预测精度可能比较高,俗话说“三个臭皮匠顶个诸葛亮”,将多个学习器进行组合,通过优势互补即可达到强学习器的效果。集成学习最早来自于Valiant提出的PAC(Probably ApproximatelyCorrect)学习模型,该模型首次定义了弱学习和强学习的概念:识别准确率仅比随机猜测高一些的学习算法为弱学习算法;识别准确率很高并能在多项式时间内完成的学习算法称为强学习算法。该模型提出给定任意的弱学习算法,能否将其提升为强学习算法的问题。1990年,Schapire对其进行了肯定的证明。这样一来,我们只需要先找到一个弱学习算法,再将其提升为强学习算法,而不用一开始就找强学习算法,因为强学习算法比弱学习算法更难找到。目前集成学习中最具代表性的方法是:Boosting、Bagging和Stacking。
Boosting
简单来讲,Boosting会训练一系列的弱学习器,并将所有学习器的预测结果组合起来作为最终预测结果,在学习过程中,后期的学习器更关注先前学习器学习中的错误。1995年,Freund等人提出了AdaBoost,成为了Boosting代表性的算法。AdaBoost继承了Boosting的思想,并为每个弱学习器赋予不同的权值,将所有弱学习器的权重和作为预测的结果,达到强学习器的效果。Gradient Boosting是Boosting思想的另外一种实现方法,由Friedman于1999年提出。与AdaBoost类似,Gradient Boosting也是将弱学习器通过一定方法的融合,提升为强学习器。与AdaBoost不同的是,它将损失函数梯度下降的方向作为优化的目标,新的学习器建立在之前学习器损失函数梯度下降的方向,代表算法有GBDT、XGBoost等。一般认为,Boosting可以有效提高模型的准确性,但各个学习器之间只能串行生成,时间开销较大。
Bagging
Bagging(Bootstrap Aggregating)对数据集进行有放回采样,得到多个数据集的随机采样子集,用这些随机子集分别对多个学习器进行训练(对于分类任务,采用简单投票法;对于回归任务采用简单平均法),从而得到最终预测结果。随机森林是Bagging最具代表性的应用,将Bagging的思想应用于决策树,并进行了一定的扩展。一般情况下,Bagging模型的精度要比Boosting低,但其各学习器可并行进行训练,节省大量时间开销。
Stacking
Stacking的思想是通过训练集训练好所有的基模型,然后用基模型的预测结果生成一个新的数据,作为组合器模型的输入,用以训练组合器模型,最终得到预测结果。组合器模型通常采用逻辑回归。
XGBoost
虽然这些年神经网络(尤其是深度神经网络)变得越来越流行,但XGBoost仍旧在训练样本有限、训练时间短、调参知识缺乏的场景下具有独特的优势。相比深度神经网络,XGBoost能够更好地处理表格数据,并具有更强的可解释性,另外具有易于调参、输入数据不变性等优势。
XGBoost是Gradient Boosting的实现,相比其他实现方法,XGBoost做了很多优化,在模型训练速度和精度上都有明显提升,其优良特性如下。
- 将正则项加入目标函数中,控制模型的复杂度,防止过拟合。
- 对目标函数进行二阶泰勒展开,同时用到了一阶导数和二阶导数。
- 实现了可并行的近似直方图算法。
- 实现了缩减和列采样(借鉴了GBDT和随机森林)。
- 实现了快速直方图算法,引入了基于loss-guide的树构建方法(借鉴了LightGBM)。
- 实现了求解带权值的分位数近似算法(weighted quantile sketch)。
- 可根据样本自动学习缺失值的分裂方向,进行缺失值处理。
- 数据预先排序,并以块(block)的形式保存,有利于并行计算。
- 采用缓存感知访问、外存块计算等方式提高数据访问和计算效率。
- 基于Rabit实现分布式计算,并集成于主流大数据平台中。
- 除
CART作为基分类器外,XGBoost还支持线性分类器及LambdaMART排序模型等算法。 - 实现了DART,引入Dropout技术。
机器学习算法基础
决策树
决策树是XGBoost模型的基本构成单元,因此通过本节的学习可以为深入理解XGBoost打下坚实的基础。1966年Hunt提出的CLS算法是最早的决策树算法。Quinlan在1986年提出的ID3、1993年提出的C4.5以及Breiman在1984年提出的CART,是迄今为止最具影响力的决策树算法。
决策树是一种树形结构,可用于解决分类问题和回归问题。每个叶子节点代表预测结果,从根节点到叶子节点的路径则代表判定规则。
假如有一批人的特征数据,特征包括头发长度、体重、身高。现在需要通过这些特征判定这些人的性别,此时便可以采用决策树。图3-9是根据数据设计的决策树,图中叶子节点的值表示节点上样本为男性的概率。
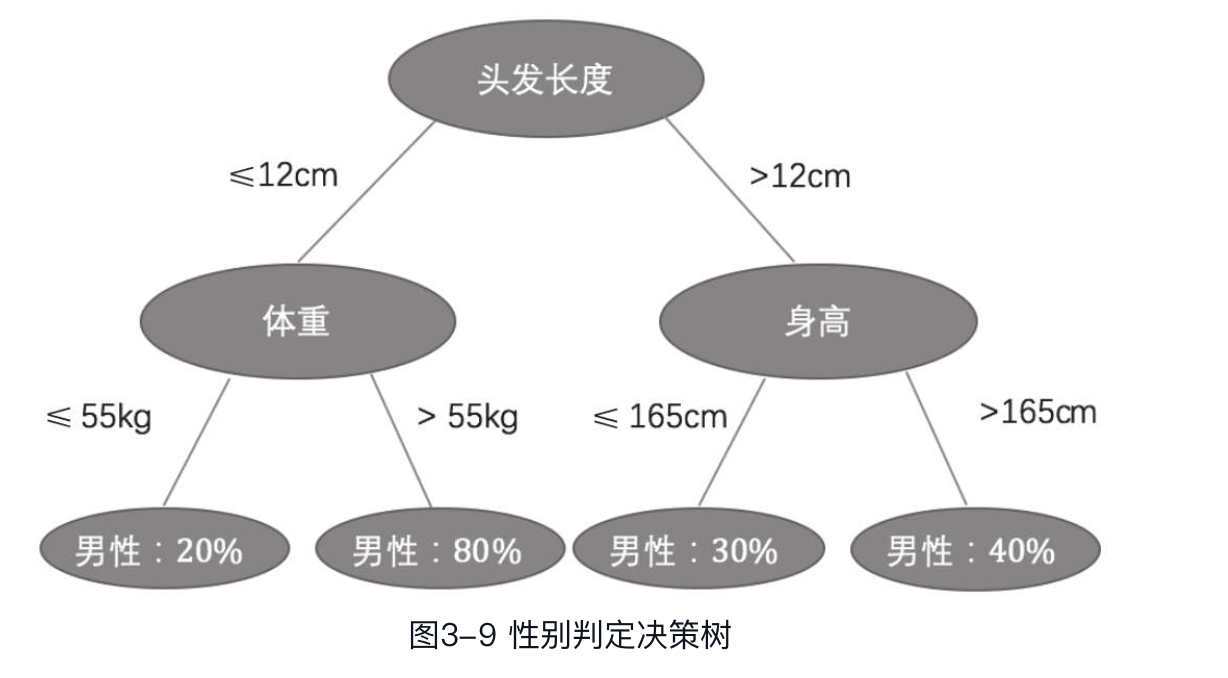
图3-9中,如果一个人的头发长度小于12cm并且体重大于55kg,那这个人有80%的概率是一名男性,有20%的概率是一名女性。可以看到,决策树具有天然的可解释性,可以非常直观地展示整个决策过程。此外,我们也可以很容易地将其转化为规则,直接通过代码实现。
构造决策树
决策树的训练目标,其实就是得到一种分类规则,使数据集中的所有样本都能被划分到正确的类别。这样的决策树可能有多个,也可能没有,所以我们的目标是找到一棵能将大部分样本正确分类并且具有较好泛化能力的树。决策树学习的损失函数一般是正则化的极大似然函数。从所有的决策树中选出最优的决策树是NP完全问题,一般采用启发式算法近似求解,因此生成决策树过程中的每一步都会采用当前最优的决策。
首先,为根节点选择一个最优特征对数据集进行划分,然后分别对其子节点进行最优划分,即每一步求局部最优解,直至该子集的所有样本都被正确地分类,则生成分类对应的叶子节点。如果子集中还存在没有被正确分类的样本,则继续划分,直至生成一棵完整的决策树。
以上述判定性别的问题为例,决策树生成过程如图3-10所示。
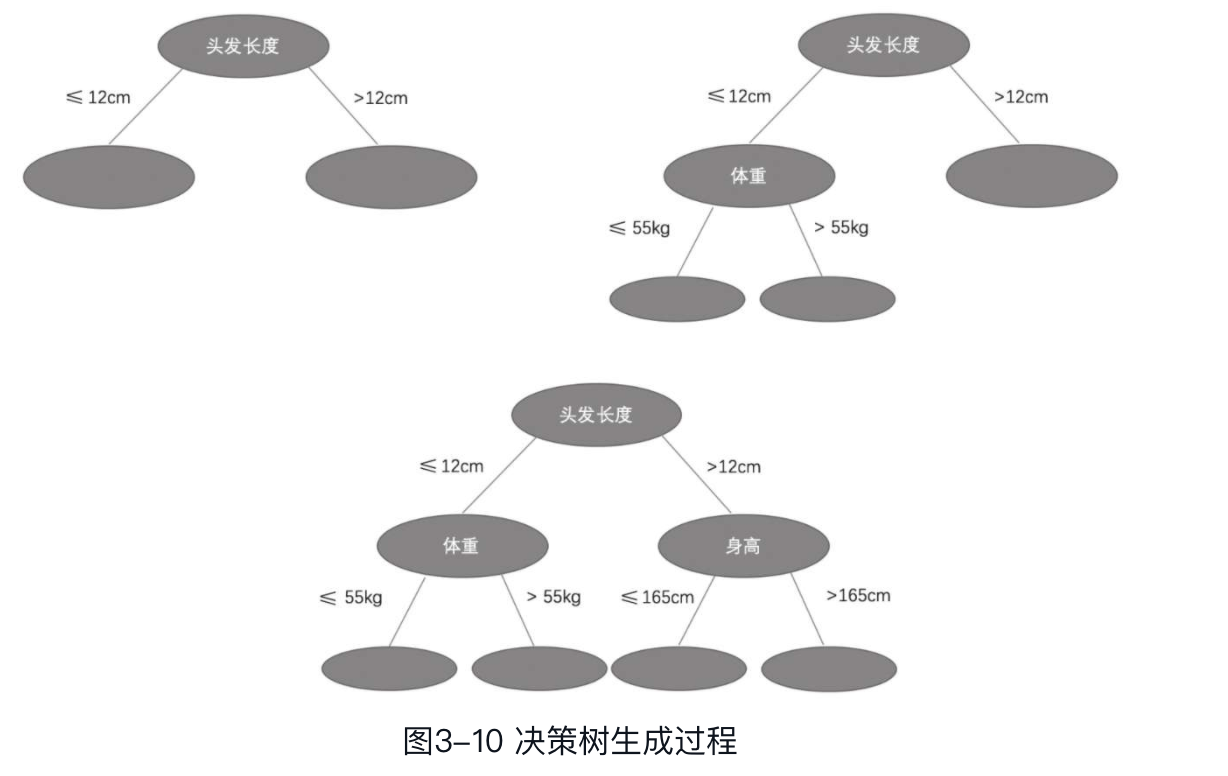
这样生成的决策树虽然可以对现有样本进行很好的分类,但是泛化能力不一定好,因此可能需要进行剪枝。另外,如果特征很多,则需要进行特征选择。
特征选择
特征选择是指选择出那些有分类能力的特征,作为决策树划分的特征。好的特征选择能够提升模型性能,帮助使用者理解数据样本的特点和结构,有利于进一步优化模型或算法。采用特征选择主要有如下益处:
- 简化模型,缩短模型训练时间;
- 避免维度灾难;
- 减少过拟合,提高模型泛化能力。
那怎么衡量特征是否有分类能力呢?通常在特征选择中会使用信息增益、信息增益比等。不同的决策树算法选择不同的方法作特征选择,常用的决策树算法有ID3、C4.5、CART等。
ID3
ID3算法由Ross Quinlan于1986年提出。该算法根据最大信息增益的原则对数据集进行划分。从根节点开始,遍历所有未被使用的特征,计算特征的信息增益,选取信息增益最大的特征作为节点分裂的特征,然后为该特征的每一个可能取值分别生成子节点,再对子节点递归调用上述方法,直到所有特征的信息增益均小于某阈值或没有特征可以选择。最终,对于每个叶子节点,将其中样本数量最多的类作为该节点的类标签。
信息增益
信息是一个比较抽象的东西,如何度量其包含的信息量大小呢?1948年香农提出了信息熵的概念,解决了信息的度量问题。信息熵,简称熵(entropy),是信息的期望值,表示随机变量不确定性的度量,记作:
其中,为事件发生的概率。熵只依赖于随机变量的分布,而不依赖其取值,熵越大,表示随机变量的不确定性越大。
假设样本集合为,表示集合中样本的数量,样本集合共有个分类,每个分类的概率为,其中表示属于第类的样本数量,则该样本集合的熵为:
在介绍信息增益之前,还需要介绍另外一个概念——条件熵(conditional entropy)。设有随机变量,条件熵表示在已知随机变量的条件下随机变量的不确定性,条件熵定义为在给定条件下,的条件概率分布的熵对的数学期望:
Entropie
其中,
在决策树学习的过程中,信息增益是特征选择的一个重要指标。由前面信息熵的介绍可知,熵可以表示样本集合的不确定性(熵越大,样本的不确定性就越大),因此当通过某一特征对样本集合进行划分时,可通过划分前后熵的差值来衡量该特征对样本集合划分的好坏,差值越大表示不确定性降低越多,则信息增益越大。假设划分前样本集合的熵为,按特征划分后样本集合的熵为,则信息增益为:
信息增益表示用特征对样本集合进行划分时不确定性的减少程度。换句话说,按照特征对样本进行分类,分类后数据的确定性是否比之前更高。通过计算信息增益,我们可以选择合适的特征作为决策树节点分裂的依据。下面通过例子进一步说明。
表3-1是根据天气情况判断是否进行户外活动的数据表。该数据表包含户外天气、温度、湿度和是否有风几个特征,类别标签为是否户外活动。各特征的具体信息如下。
- 户外天气:晴朗,阴天,下雨;
- 温度:凉爽,适中,热;
- 湿度:高,适中;
- 是否有风:是,否;
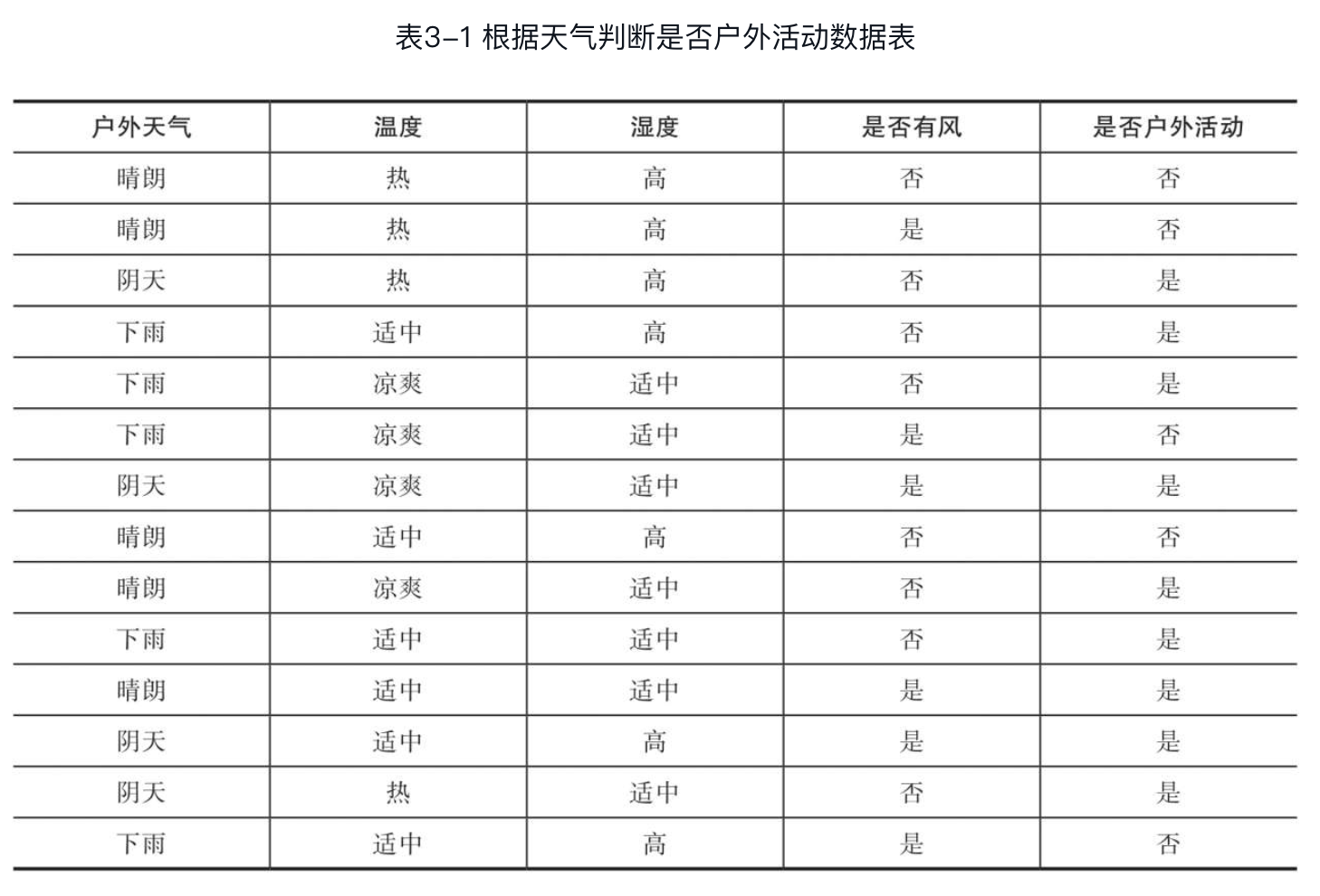
下面计算每个特征的信息增益。为便于说明,用表示该数据集,用、、、分别表示户外天气、温度、湿度、是否有风这4个特征。
首先计算数据集的熵:
Entropie
然后计算特征对数据集的条件熵,将数据集分为3部分:晴天、雨天、阴天,分别对应数据子集,。
最后计算信息增益:
gain Entropie Entropie
同理可以计算、、的信息增益:
gain
gain
gain
显然,特征的信息增益最大,可以将其作为节点分裂的特征。
ID3算法过程
- 从根节点开始分裂。
- 节点分裂前,遍历所有未被使用的特征,计算特征的信息增益。
- 选取信息增益最大的特征作为节点分裂的特征,并对该特征每个可能的取值生成一个子节点。
- 对子节点循环执行步骤2、3,直至所有特征信息增益均小于某阈值或没有特征可以选择。
当一个特征可能的取值较多时,根据该特征更容易得到纯度更好的样本子集,信息增益会更大,因此ID3算法会偏向选择取值较多的特征,但不适用于极端情况下连续取值的特征选择。
C4.5
C4.5是ID3算法的扩展,其构建决策树的算法过程也与ID3算法相似,唯一的区别在于C4.5不再采用信息增益,而是采用信息增益比进行特征选择,解决了ID3算法不能处理连续取值特征的问题。
信息增益比,是在信息增益的基础上乘以一个调节参数,特征的取值个数越多,该参数越小,反之则越大。信息增益比定义如下:
调节参数为的倒数,表示数据集以特征作为随机变量的熵,其中为特征的取值个数。定义如下:
=-\sum_{i=1}^{n} \frac{\left|D_{i}\right|}{|D|} \log \frac{\left|D_{i}\right|}{|D|}$
CART
CART和ID3、C4.5算法类似,也是由特征选择、决策树构建和剪枝几部分组成。CART采用的是二分递归分裂的思想,因此生成的决策树均为二叉树。CART包含两种类型的决策树:分类树和回归树。分类树的预测值是离散的,通常会将叶子节点中多数样本的类别作为该节点的预测类别。回归树的预测值是连续的,通常会将叶子节点中多数样本的平均值作为该节点的预测值。分类树采用基尼系数进行特征选择,而回归树采用均方误差。CART是XGBoost树模型的重要组成部分,详细介绍参见第5章相关内容。
决策树剪枝
剪枝是决策树算法中必不可少的一部分。因为在决策树学习的过程中,为了尽可能正确地分类训练样本,算法会过多地进行节点分裂,导致生成的决策树非常详细且复杂。这样的模型对样本噪声非常敏感,容易产生过拟合,对新样本的预测能力也较差,因此需要通过决策树剪枝来提高模型的泛化能力。
决策树的剪枝策略分为预剪枝(pre-pruning)和后剪枝(post-pruning)两类。预剪枝是在决策树分裂过程中,在每个节点分裂前预先进行评估,若该节点分裂后并不能使决策树模型泛化能力有所提升,则该节点不分裂。后剪枝则是先构造一棵完全决策树,然后自底向上对非叶子节点进行评估,若将该非叶子节点剪枝有助于决策树模型泛化能力的提升,则将该节点子树剪去,使其变为叶子节点。
决策树解决肿瘤分类问题
本节介绍如何应用决策树解决实际问题,以预测良性/恶性乳腺肿瘤的二分类问题为例。scikit-learn实现了决策树算法,它采用的是一种优化的CART版本,既可以解决分类问题,也可以解决回归问题。分类问题使用DecisionTreeClassifier类,回归问题使用DecisionTreeRegressor类。两个类的参数相似,只有部分有所区别,以下是对主要参数的说明。
criterion:特征选择采用的标准。DecisionTreeClassifier分类树默认采用gini(基尼系数)进行特征选择,也可以使用entropy(信息增益)。DecisionTreeRegressor默认采用MSE(均方误差),也可以使用MAE(平均绝对误差)。splitter:节点划分的策略。支持best和random两种方式,默认为best,即选取所有特征中最优的切分点作为节点的分裂点,random则随机选取部分切分点,从中选取局部最优的切分点作为节点的分裂点。max_depth:树的最大深度,默认为None,表示没有最大深度限制。节点停止分裂的条件是:样本均属于相同类别或所有叶子节点包含的样本数量小于min_samples_split。若将该参数设置为None以外的其他值,则决策树生成过程中达到该阈值深度时,节点停止分裂。min_samples_split:节点划分的最小样本数,默认为2。若节点包含的样本数小于该值,则该节点不再分裂。若该字段设置为浮点数,则表示最小样本百分比,划分的最小样本数为ceil(min_samples_split*n_samples)。min_samples_leaf:叶子节点包含的最小样本数,默认为1。此字段和min_samples_split类似,取值可以是整型,也可以是浮点型。整型表示一个叶子节点包含的最小样本数,浮点型则表示百分比。叶子节点包含的最小样本数为ceil(min_samples_leaf*n_samples)。max_features:划分节点时备选的最大特征数,默认为None,表示选用所有特征。若该字段为整数,表示选用的最大特征数;若为浮点数,则表示选用特征的最大百分比。最大特征数为int(max_features*n_features)。max_leaf_nodes:最大叶子节点数,默认为None,表示不作限制。通过配置该字段,可以限制决策树的最大叶子节点数,防止模型过拟合。class_weight:类别权重,默认为None,表示每个类别的权重均为1。该字段主要用于分类问题,防止训练集中某些类别的样本过多,导致决策树训练更偏向于这些类别。通过该字段可以指定每个类别的权重,也可以设置为“balanced”,使算法自动计算类别的权重,样本量少的类别权重会高一些。
以上是scikit-learn决策树中的常用参数,另外还有random_state、min_impurity_decrease、min_impurity_split等参数,其说明和使用方法可参阅相关资料。
加载任务数据集:
from sklearn import datasets
cancer=datasets.load_breast_cancer()
X=cancer.data
y=cancer.target
划分训练集和测试集,比例为4:1。
from sklearn.model_selection import train_test_split
X_train,X_test,Y_trian,Y_test=train_test_split(X,y,test_size=1/5.,random_state=8)
因为是分类任务,所以调用scikit-learn中的DecisionTreeClassifier接口进行模型训练。通过训练好的模型对测试集进行预测,并评估预测效果,具体代码如下:
from sklearn import tree
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
#决策树
clf=tree.DecisionTreeClassifier(max_depth=4)
#训练模型
clf.fit(X_train,y_trian)
#预测
y_pred=clf.predict(X_test)
#评估预测效果
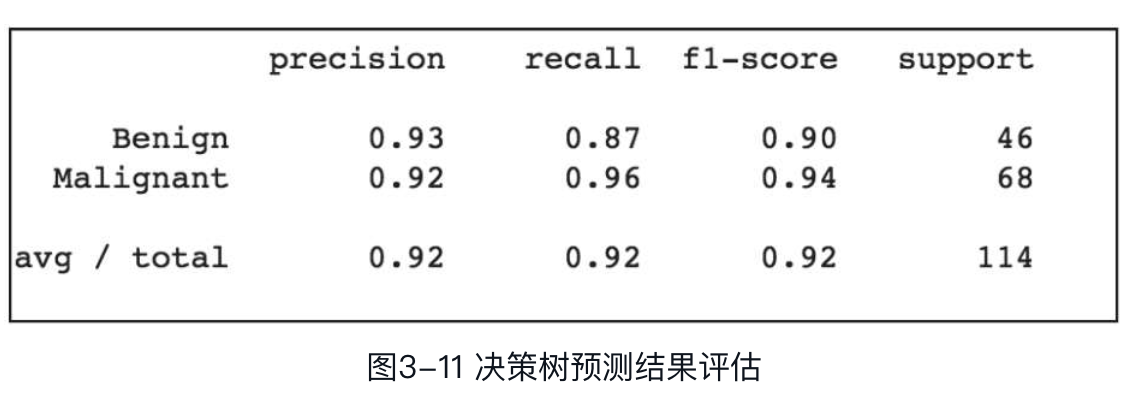
print(classification_report(y_test,y_pred,target_names=['Benign','Malignant']))
评估结果输出如图3-11所示。
决策树可视化结果如图3-12所示。
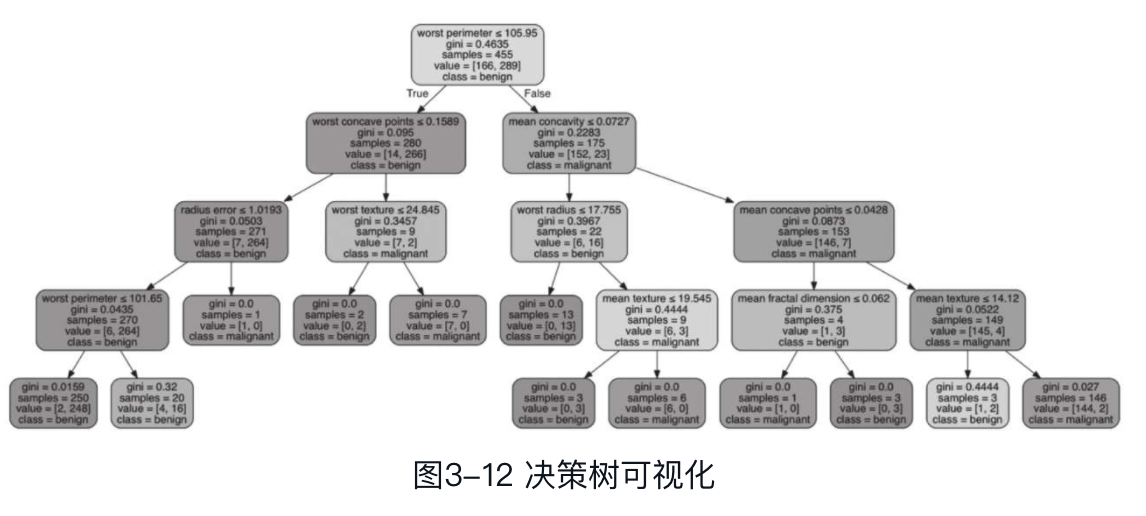
该决策树训练时指定了max_depth为4,读者可以根据实际情况自行调节该参数。图3-12直观地展示了各个节点的基尼系数、包含样本数、预测值、划分类别以及非叶子节点的分裂条件等信息。以其中一个非叶子节点为例,如图3-13所示。

该节点的分裂条件为worst perimeter特征是否小于等于101.65,计算的基尼系数为0.0435,共包含270个样本,两个类别预测值分别为6和264,因为第2个类别预测值更高,所以该节点类别被判定属于benign。
XGBoost小试牛刀
XGBoost实现原理
XGBoost由多棵决策树(CART)组成,每棵决策树预测真实值与之前所有决策树预测值之和的残差(残差=真实值-预测值),将所有决策树的预测值累加起来即为最终结果。如图4-1所示,现有A、B、C、D这4个用户,通过决策树预测其是否使用支付宝(预测值越大,表明使用支付宝的可能性越大)
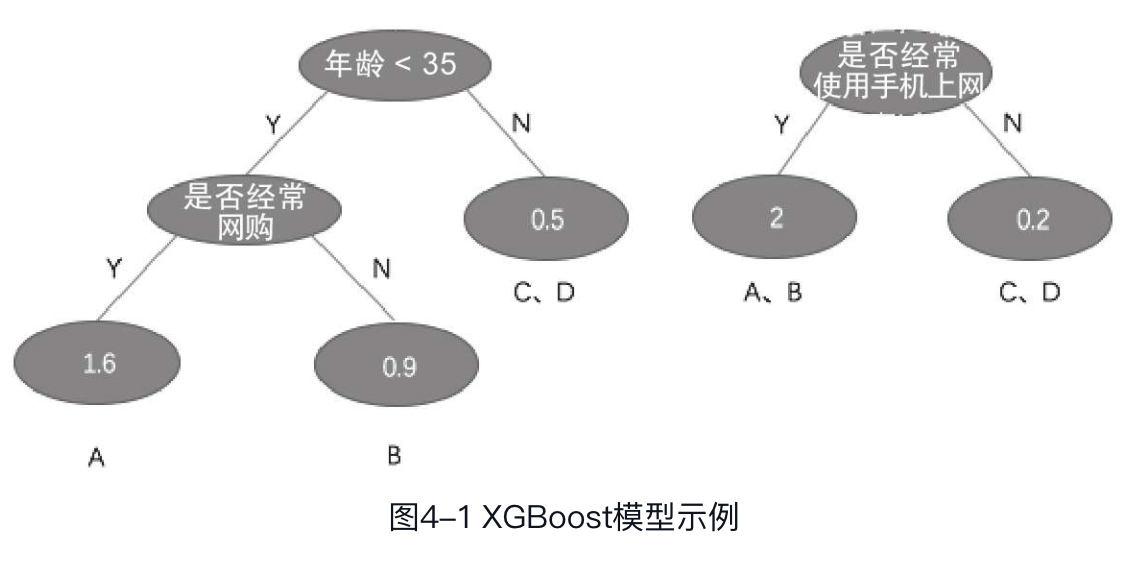
在图4-1中,非叶子节点为决策树采用的特征,分别为:年龄是否小于35岁、是否经常网上购物、是否经常使用手机上网。每个样本最终都会被分到一个叶子节点上,叶子节点的值表示被分到该节点的样本的预测值。根据残差的定义,样本所在的所有叶子节点的预测值之和为最终预测值,则A、B、C、D 4个用户使用支付宝的预测值计算如下:
预测结果为,A、B用户比C、D用户更倾向于使用支付宝。
二分类问题
XGBoost树模型由多棵回归树组成,并将多棵决策树的预测值累计相加作为最终结果。回归树产生的是连续的回归值,如何用它解决二分类问题呢?通过前面的学习知道,逻辑回归是在线性回归的基础上通过sigmoid函数将预测值映射到0~1的区间来代表二分类结果的概率。和逻辑回归一样,XGBoost也是采用sigmoid函数来解决二分类问题,即先通过回归树对样本进行预测,得到每棵树的预测结果,然后将其进行累加求和,最后通过sigmoid函数将其映射到0~1的区间代表二分类结果的概率。另外,对于二分类问题,XGBoost的目标函数采用的是类似逻辑回归的logloss,而非最小二乘。
XGBoost中关于二分类的常用参数有如下几个。
- Objective
该参数用来指定目标函数,XGBoost可以根据该参数判断进行何种学习任务,binary:logistic和binary:logitraw都表示学习任务类型为二binary:logistic输出为概率,binary:logitraw输出为逻辑转换前的输出分数。 - eval_metric
该参数用来指定模型的评估函数,和二分类相关的评估函数有:error、logloss和auc。error也称错误率,即预测错误的样本数占总样本数的比例,准确来说是预测错误样本的权重和占总样本权重和的比例,也可通过error@k的形式手工指定二分类的阈值。logloss通过惩罚分类来量化模型的准确性,最大限度减少log loss,等同于最大化模型的准确率。另外,AUC也是二分类中最常用的评估指标之一.
蘑菇数据集是一个非常著名的二分类数据集。该数据集一共包含23个特征,包括大小、表面、颜色等,每一种蘑菇都会被定义为可食用的或者有毒的,需要通过样本数据分析这些特征与蘑菇毒性的关系。以下是各个特征的详细说明。
- 帽形(cap-shape):钟形=b,圆锥形=c,凸形=x,平面=f,把手形=k,凹陷=S
- 帽面(cap-surface):纤维状=f,凹槽状=g,鳞片状=y,光滑=s。
- 帽颜色(cap-color):棕色=n,浅黄色=b,肉桂色=c,灰色=g,绿色=r,粉红色=p,紫色=u,红色=e,白色=w,黄色=y。
- 创伤(bruises):创伤=t,no=f。
- 气味(odor):杏仁=a,茴香=l,石灰=c,腥味=y,臭味=f,霉味=m,无=n,刺鼻=p,辣=s。
- 菌褶附属物(gill-attachment:):附着=a,下降=d,自由=f,缺口=n。
- 菌褶间距(gill-spacing):紧密=c,拥挤=w,远隔=d。
- 菌褶大小(gill-size):宽=b,窄=n。
- 菌褶颜色(gill-color):黑色=k,棕色=n,浅黄色=b,巧克力色=h,灰色=g,绿色=r,橙色=o,粉红色=p,紫色=u,红色=e,白色=w,黄色=y。
- 茎形(stalk-shape):扩大=e,锥形=t。
- 茎根(stalk-root):球根=b,棒状=c,杯状=u,均等的=e,根状菌索=z,扎根=r,缺省=?。
- 环上茎面(stalk-surface-above-ring):纤维状=f,鳞片状=y,丝状=k,光滑=s。
- 环下茎面(stalk-surface-below-ring):纤维状=f,鳞片状=y,丝状=k,光滑=s。
- 环上茎颜色(stalk-color-above-ring):棕色=n,浅黄色=b,黄棕色=c,灰色=g,橙色=o,粉红色=p,红色=e,白色=w,黄色=y。
- 环下茎颜色(stalk-color-below-ring):棕色=n,浅黄色=b,黄棕色=c,灰色=g,橙色=o,粉红色=p,红色=e,白色=w,黄色=y。
- 菌幕类型(veil-type):部分=p,普遍=u。
- 菌幕颜色(veil-color):棕色=n,橙色=o,白色=w,黄色=y。
- 环数量(ring-number):没有=n,一个=o,两个=t。
- 环类型(ring-type):蛛网状=c,消散状=e,喇叭形=f,大规模的=l,无=n,悬垂的=p,覆盖=s,环带=z。
- 孢子显现颜色(spore-print-color):黑色=k,棕色=n,蓝色=b,巧克力色=h,绿色=r,橙色=o,紫色=u,白色=w,黄色=y。
- 种群(population):丰富=a,聚集=c,众多=n,分散=s,个别=v,单独=y。
- 栖息地(habitat):草地=g,树叶=l,草甸=m,路上=p,城市=u,荒地=w,树林=d。23)class:label字段,有可食用(edible)和有毒性(poisonous)两个取值。
该数据集总共有8124个样本,其中类别为可食用的样本有4208个,类别为有毒性的样本有3916个。
首先需要对特征进行预处理。因为原始文件agaricus-lepiota.data中的数据并不能直接作为XGBoost的输入进行加载,原始数据格式如下:
XGBoost不能直接处理上述数据,需要进行预处理。这里将其中的字符数据转为数值型,并以LibSVM的格式输出。LibSVM是机器学习中经常采用的一种数据格式,如下:
label为训练数据集的目标值;index为特征索引,是一个以1为起始的整数;value是该特征的取值,如果某一特征的值缺省,则该特征可以空着不填,因此对于一个样本来讲,输出后的数据文件index可能并不连续,上述样本处理后的格式如下:
1 3:1 10:1 11:1 21:1 30:1 34:1 36:140: 141:1 53:1 58:1 65:1 69:1 77:1 86:1 88:1 92:1 95:1 102:1 105:1 117:1 124:1
0 3:1 10:1 20:1 21:1 23:1 34:1 36:1 39:1 41:1 53:1 56:1 65:1 69:1 77:1 86:1 88:1 92:1 95:1 102:1 106:1 116:1 120:1
第一个样本中最开始的“1”便是该样本的label,在二分类问题中,一般1代表正样本,0代表负样本。之后的每个特征为一项,冒号前为该特征的索引,如3、10等,冒号后为该特征取值,如3、10两个特征的取值都是1。另外,观察处理后的数据可以发现,特征索引已经远远超过了22,如第一行样本中特征索引最大已经达到了124。
观察该数据集可以发现,其中大部分特征是离散型特征,连续型特征较少。在机器学习算法中,特征之间距离的计算是十分重要的,因此,直接把离散变量的取值转化为数值,并不能很好地代表特征间的距离,如菌幕颜色特征,其总共有棕色、橙色、白色、黄色4种颜色,假如将其映射为1、2、3、4,则棕色和橙色之间的距离是2-1=1,而棕色和白色之间的距离是3-1=2。这显然是不符合实际情况的,因为任意两个颜色之间的距离应该是相等的。因此,需要对特征进行独热编码(one-hot encoding)。简单来讲,独热编码就是离散特征有多少取值,就用多少维来表示该特征。仍然以菌幕颜色特征为例,经过独热编码后,其将会转为4个特征,分别是菌幕颜色是否为棕色、菌幕颜色是否为橙色、菌幕颜色是否为白色和菌幕颜色是否为黄色,并且这4个特征取值只有0和1。经过独热编码之后,每两个颜色之间的距离都是一样的,比之前的处理更合理。离散特征经过独热编码之后,数据集的总特征数会变多,这就是上述示例中出现较大特征索引的原因。
先加载训练集和测试集:
import XGBoost as xgb
xgb_train=xgb.DMatrix('./agaricus.txt.train')
xgb_test=xgb.DMatrix('./agaricus.txt.test')
params={
"objective":"binary:logistic",
"booster":"gbtree",
"eta":1.0,
"gamma":1.0,
"min_child_weight":1,
"max_depth":3
}
num_round=2
watchlist=[(xgb_train,'train'),(xgb_test,'test')]
model=xgb.train(params,xgb_train,num_round,watchlist)
params中的objective和booster参数已经介绍过了,分别用于指定任务的学习目标和booster类型。objective设为binary:logistic,表示任务为二分类问题,最终输出为sigmoid变换后的概率。booster为gbtree表示采用XGBoost中的树模型。参数eta表示学习率,类似于梯度下降中法的α,每次迭代完更新权重的步长。参数gamma表示节点分裂时损失函数减小的最小值,此处为1.0,表示损失函数至少下降1.0该节点才会进行分裂。参数min_child_weight表示叶子节点最小样本权重和,若节点分裂导致叶子节点的样本权重和小于该值,则节点不进行分裂。参数max_depth表示决策树分裂的最大深度。另外,该示例中指定了num_round为2,即模型会进行两轮booster训练,最终会生成两棵决策树。通过定义参数watchlist,模型在训练过程中会实时输出训练集和验证集的评估指标。模型训练过程的输出结果如图4-2所示。

模型训练完成之后,可通过save_model方法将模型保存成模型文件,以供后续预测使用,如下:
model.save_model("/0002. Model")
预测时,先加载保存的模型文件,然后再对数据集进行预测,如下:
bst=xgb.Booster()
bst.load_model("./0002.model")
pred=bst.predict(xgb_test)
下面来看一下文本格式的XGBoost树模型文件,如图4-5所示。

在图4-5中,一个booster代表一棵决策树,该模型一共有两棵决策树。在每棵决策树中,每一行代表一个节点,位于行首的数字代表该节点的索引,数字0表示该节点为根节点。若该行节点是非叶子节点,则索引后面是该节点的分裂条件,如图4-5中第2行:
0:[odor=pungent] yes=2, no=1
该节点的索引为0,表示该节点是根节点,其分裂条件是odor=pungent,满足该条件的样本会被划分到节点2,不满足的则被划分到节点1。若该行节点是叶子节点,则索引后面是该叶子节点最终得到的权重。如图4-5中的第5行:
7:1eaf=1.90175
leaf表示该节点为叶子节点,最终得到的权重为1.90175。
多分类问题
与处理二分类问题类似,XGBoost在处理多分类问题时也是在树模型的基础上进行转换,不过不再是sigmoid函数,而是softmax函数。相信读者对softmax变换并不陌生,第3章已有所介绍,它可以将多分类的预测值映射到0到1之间,代表样本属于该类别的概率。
XGBoost中解决多分类问题的主要参数如下。
num_class:说明在该分类任务的类别数量。objective:该参数中的multi:softmax和multi:softprob均是指定学习任务为多分类。multi:softmax通过softmax函数解决多分类问题。multi:softprob和multi:softmax一样,主要区别在于其输出的是一个ndata*nclass向量,表示样本属于每个分类的预测概率。eval_metric:与多分类相关的评估函数有merror和mlogloss。merror也称多分类错误率,通过判断样本所有分类预测值中预测值最大的分类和样本label是否一致来确定预测是否正确,其计算方式和error相似。mlogloss也是多分类问题中常用的评估指标。有关merror和mlogloss会在第7章中详细介绍。
下面以识别小麦种子的类别作为示例,介绍如何通过XGBoost解决多分类问题。已知小麦种子数据集包含7个特征,分别为面积、周长、紧凑度、籽粒长度、籽粒宽度、不对称系数、籽粒腹沟长度,且均为连续型特征,以及小麦类别字段,共有3个类别,分别用1、2、3表示。
加载该数据并进行特征处理,代码如下:
import pandas as pd
import XGBoost as xgb
import numpy as np
#使label取值在num_class-1范围内
data=pd.read_csv('./seeds_datasets.txt',header=None,sep='\s+',converters={7:lambda x:int(x)-1})
#将最后一列字段名设置为label
data.rename(columns={7:'label'},inplace=True)
为便于后续处理,将最后一个类别字段作为label字段,因为label的取值需在0到num_class-1范围内,因此需对类别字段进行处理(数据集中的3个类别取值分别为1~3),这里直接减1即可。完成数据加载后,下面来看一下数据集的数据结构,输出前10行数据,代码如下:
data.head(10)
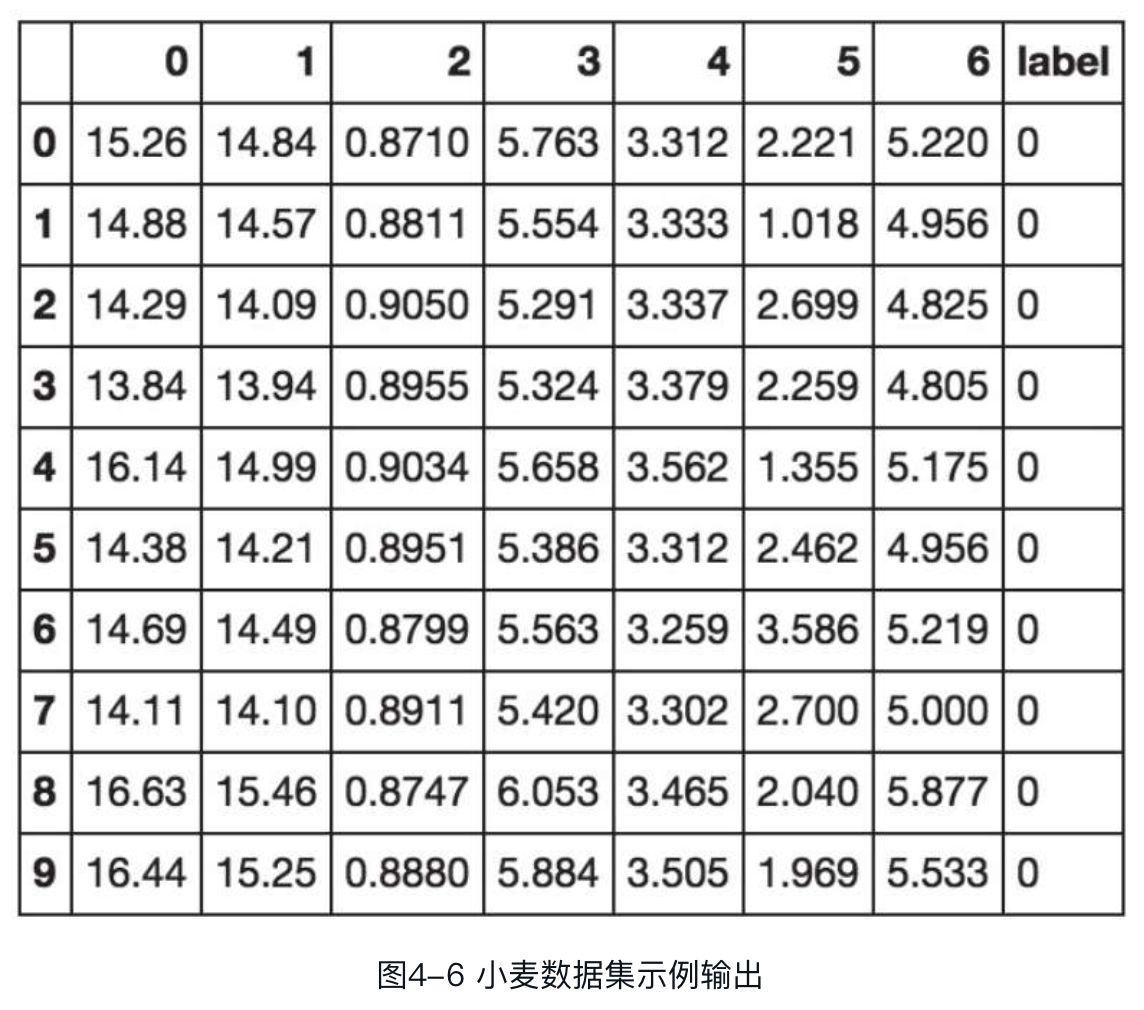
可以看到,数据集共包含8列,其中前7列为特征列,最后1列为label列,和数据集描述相符。除label列外,剩余特征没有指定列名,所以pandas自动以数字索引作为列名。
下面对数据集进行划分(训练集和测试集的划分比例为4:1),并指定label字段生成XGBoost中的DMatrix数据结构,代码如下:
#生成一个随机数并选择小于 0.8 的数据
mask=np.random.randn(len(data))<0.8
train=data[mask]
test=data[~mask]
#生成DMatrix
xgb_train=xgb.DMatrix(train.loc[:,:6],label=train.label)
xgb_test=xgb.DMatrix(test[:,:6],label=test.label)
置参数objective为multi:softmax,表示采用softmax进行多分类,学习率参数eta和最大树深度max_depth在之前的示例中已有所介绍,不再赘述。参数num_class指定类别数量为3。相关代码如下:
#通过softmax进行分类
params={
'objective':'multi:softmax',
'eta':0.1,
'max_depth':5,
'num_class':3
}
watchlist=[(xgb_train,'train'),(xgb_test,'test')]
num_round=50
bst=xgb.train(params,xgb_train,num_round,watchlist)
总共训练50轮,训练过程的部分输出结果如图4-7所示。

在未指定评估函数的情况下,XGBoost默认采用merror作为多分类问题的评估指标。下面通过训练好的模型对测试集进行预测,并计算错误率,代码如下:
#模型预测
pred=bst.predict(xgb_test)
error_rate=np.sum(pred!=test.label)/test.shape[0]
通过模型得到预测值pred,然后对比预测值和实际的label值,计算错误率,输出如下:测试集错误率(softmax):0.0408163265306
为了方便对比学习,下面采用multi:softprob方法重新训练模型,代码如下:
#重新训练模型,输出概率值
params['objective']='multi:softprob'
bst=xgb.train(params,xgb_train,num_rounds,watchlist)
模型训练过程输出结果如图4-8所示。对比两种函数变换方法的训练输出结果可以看出,不论采用multi:softmax还是multi:softprob作为objective训练模型,并不会影响到模型精度。

下面对测试集进行预测并计算错误率,代码如下:
pred_prob=bst.predict(xgb_test)
pred_label=np.argmax(pred_prob,axis=1)
error_rate=np.sum(pred_prob!=test.label)/test.shape[0]
此时模型预测输出的pred_prob是样本属于各类别的概率向量,如下:
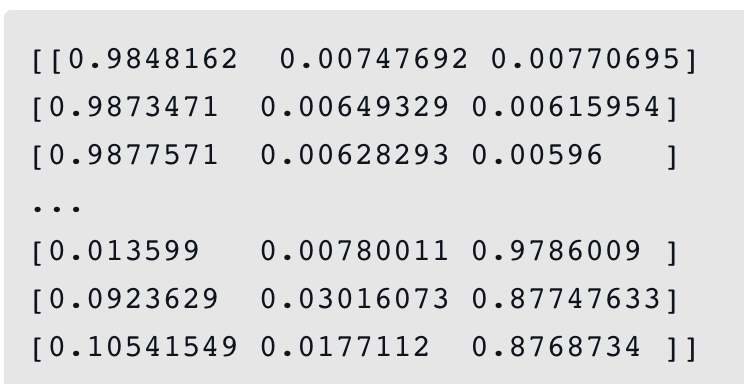
下一步是比较预测值与实际的label值来判断是否预测正确。和multi:softmax不同,此时需要借助numpy中的argmax函数将概率向量转化为样本预测值。argmax函数可以获取每个样本的概率向量中最大值的索引,即为样本的预测类别,最终返回所有样本所属类别索引的向量,如下:

之后的处理则和采用multi:softmax时一样,统计预测错误的样本数,最终计算出分类错误率。采用multi:softprob得到的错误率和multi:softmax也是一样的:测试集错误率(softprob):0.0408163265306
回归问题
用XGBoost解决回归问题是很顺理成章的事情,因为XGBoost本身采用的就是回归树,将每棵回归树对样本的预测值相加即为最终预测值。XGBoost支持多种回归模型,包括线性回归、泊松回归、伽马(gamma)回归等,不同的回归模型有不同的目标函数。以下是回归问题中用到的主要参数。
objective
reg:linear:线性回归,并非指线性模型(线性模型由booster参数指定),用于数据符合正态分布的回归问题,目标函数为最小二乘。reg:logistic:逻辑回归,目标函数为logloss。count:poisson:计数数据的泊松回归。reg:gamma:对数连接函数下的伽马回归。reg:tweedie:对数连接函数下的tweedie回归。
eval_metric
回归问题的评估指标主要有RMSE、MAE,另外还有一些如poisson-nloglik、gamma-nloglik、gamma-deviance、tweedie-nloglik等用于特定回归的评估指标。其中RMSE(Root Mean Square Error,均方根误差),是回归模型中最常采用的评估指标之一,是预测值与真实值偏差的平方和与样本数比值的平方根。指标MAE(Mean Absolute Error,平均绝对误差),是回归模型中常用的评估指标,衡量的是预测值和真实值之间绝对差异的平均值。指标RMSE和MAE会在第7章详细介绍。
下面通过评估混凝土坍度的示例,介绍如何通过XGBoost解决一般的回归问题。混凝土坍度测试数据集是一个通过混凝土的各种指标特征评估其抗压强度的数据集,共包含1030个样本、9个特征,特征的具体信息如下。
- 水泥:数据类型为浮点型,单位为立方米每千克。
- 高炉渣:数据类型为浮点型,单位为立方米每千克。
- 煤灰:数据类型为浮点型,单位为立方米每千克。
- 水:数据类型为浮点型,单位为立方米每千克。
- 高效减水剂:数据类型为浮点型,单位为立方米每千克。
- 粗骨料:数据类型为浮点型,单位为立方米每千克。
- 细骨料:数据类型为浮点型,单位为立方米每千克。
- 年龄:数据类型为整型,单位为天。
- 混凝土抗压强度定量:数据类型为浮点型,单位为MPa。
其中混凝土抗压强度定量为目标特征。可以看到,所有特征均为数值型特征且不存在缺省值,此类特征不用进行处理。
对数据进行加载和特征处理,这里采用pandas中的read_excel读取该数据集,处理代码如下:

通过head函数输出前10行数据,查看数据集的数据结构:
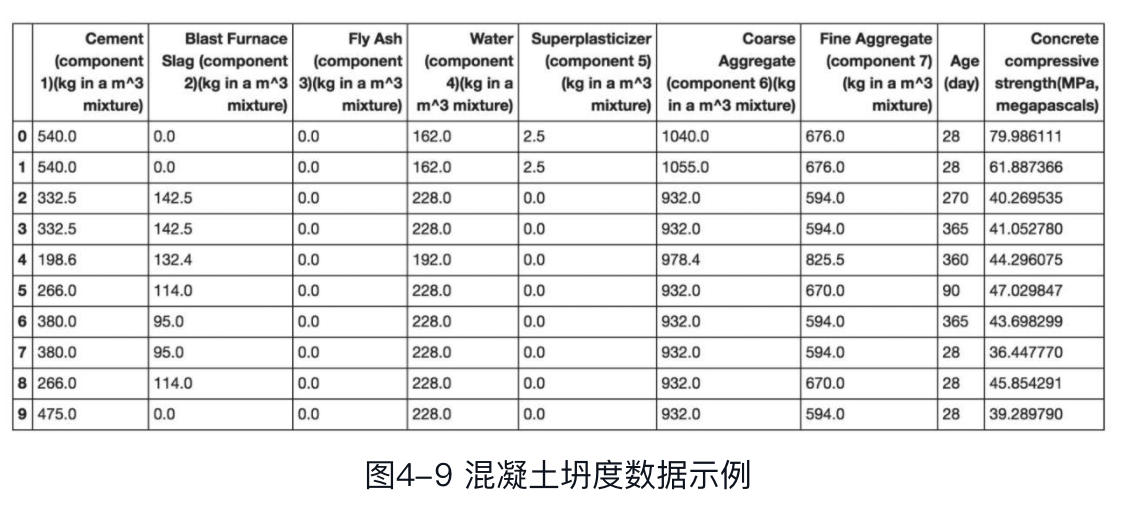
为便于后续处理,将混凝土抗压强度一列改名为label,代码如下:

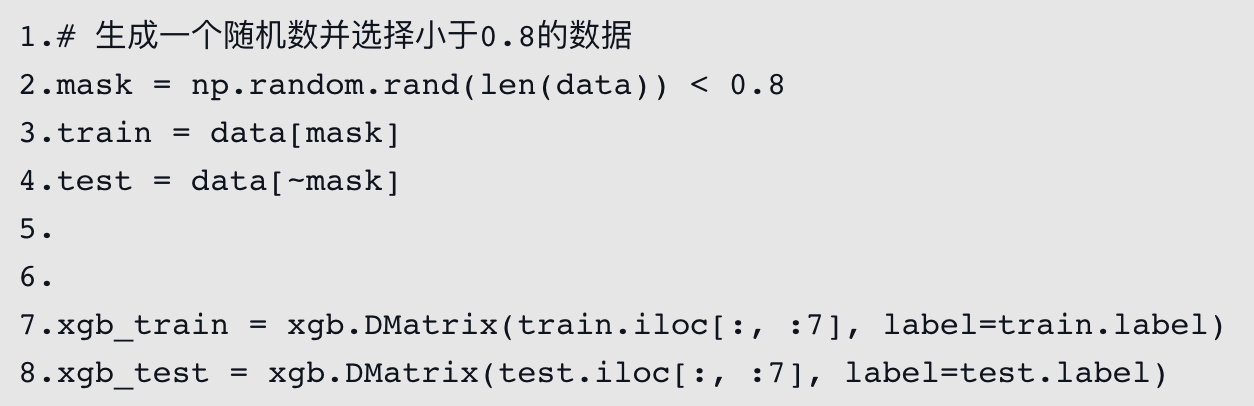
数据集划分。按4:1的比例将数据集划分为训练集和测试集,并指定label字段生成XGBoost中的DMatrix数据结构,代码如下:
得到训练集和测试集后,即可加载数据并进行模型训练。本示例的模型训练代码和二分类示例十分相似,唯一不同的是参数objective设置为回归参数reg:linear,代码如下:

训练过程的部分输出结果如图4-10所示。

reg:linear默认采用的评估指标是RMSE,用户也可以通过设置eval_metric参数采用其他评估指标。预测时首先加载训练好的模型,然后对测试集进行预测,如下:

输出预测结果如下:

可以看到,回归模型的预测结果不再是离散的分类值,或0~1的概率值,而是连续的数值型数据。
排序问题
XGBoost也可应用于机器学习中的排序问题。XGBoost的排序学习采用一种将Lambda-Rank和MART(MultipleAdditive Regression Trees)结合的排序算法,即LambdaMART算法。其中MART模型的输出为一组回归树输出的线性组合,而LambdaRank则提供了一种梯度定义方法,针对不同问题可定义不同的梯度。LambdaMART算法将会在第5章详细介绍。XGBoost中排序问题的相关参数如下。
objective:该参数用来指定目标函数,rank:pairwise、rank:ndcg和rank:map均表示排序任务。rank:pairwise通过最小化pairwise损失完成排序任务,rank:ndcg是以最大化NDCG为目标实现list-wise排序,而rank:map则以最大化MAP为目标实现list-wise排序。eval_metric:该参数用来设置模型的评估指标,排序问题的评估指标有map、ndcg、auc.
排序学习算法
大数据时代的今天,从海量数据中快速找到需要的信息变得越来越困难,搜索引擎早已成为人们日常生活中必不可少的工具。搜索引擎中最为重要的一项技术便是排序(rank),利用机器学习优化搜索引擎的排序结果,很自然地成为业界的研究热点。
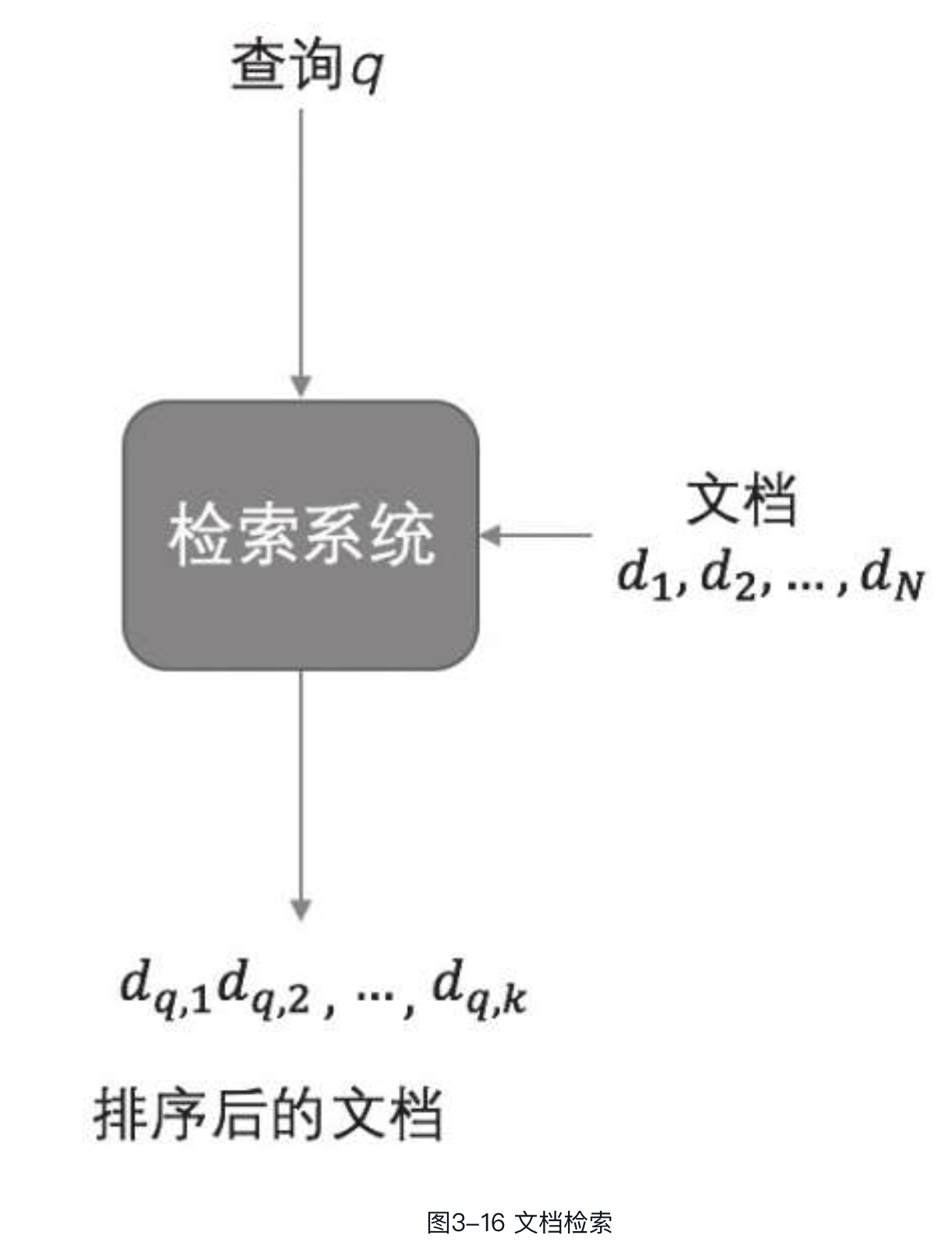
先来看一个经典的排序场景——文档检索。给定一个查询,将返回相关的文档,然后通过排序模型f(q,d)根据查询和文档之间的相关度对文档进行排序,再返回给用户,如图3-16所示,其中q代表查询(query),d代表一个文档。
通过机器学习解决排序问题,主要任务就是构建一个排序模型f(q,d),对查询下的文档进行排序,这个过程即为排序学习(learning to rank)。图3-17所示为排序学习的基本框架:
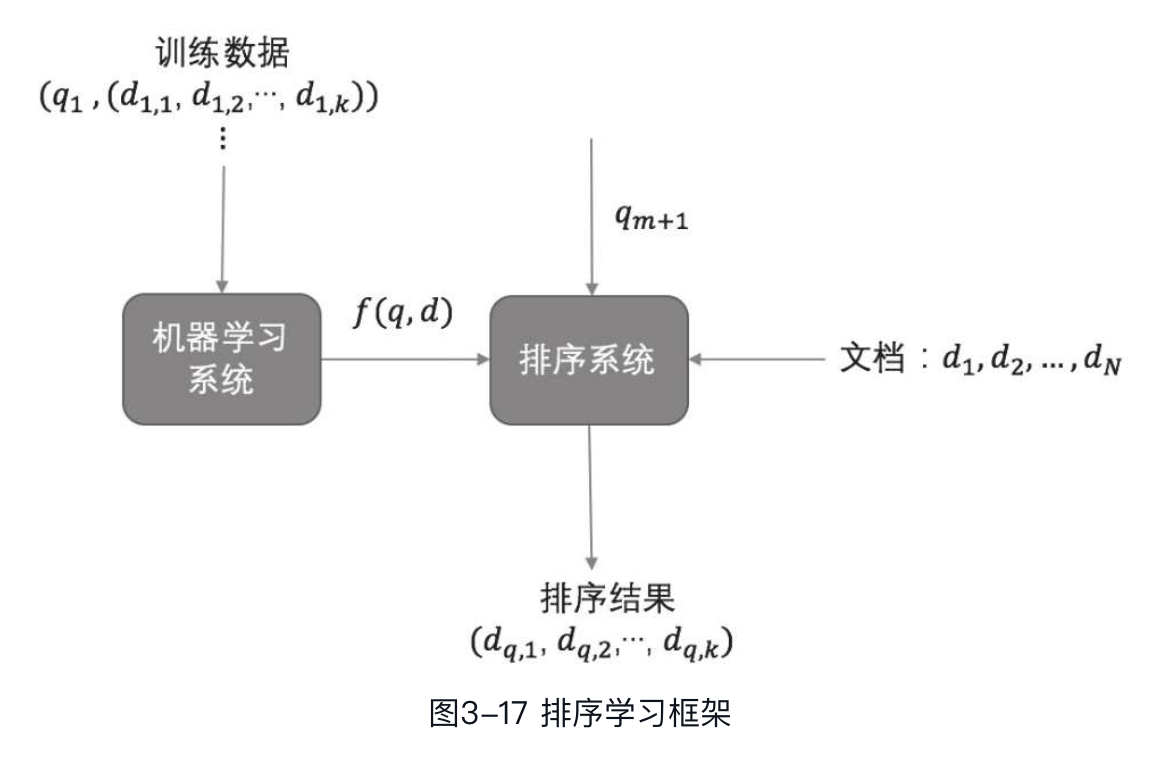
在学习系统中,先通过训练集对模型进行训练。训练集包括文档和查询相关的特征,每个查询与多个文档相关联,文档与查询之间的相关度用label表示,label得分越高表明相关度越大。每个查询-文档对的相关特征(如余弦相似度等)构成样本的特征向量,i,对应的相关度得分作为该样本的label,用,对应的相关度得分作为该样本的label,用表示,这样就构成了一个具体的训练实例,i,yi)。所有的训练实例构成训练集,输入到学习系统中训练模型,得到排序模型。所有的训练实例构成训练集,输入到学习系统中训练模型,得到排序模型f(q,d)。对于给定的查询-文档对的特征向量,使用排序模型预测其相关度得分。
从目前的研究方法来看,排序学习算法主要分为以下3种:Pointwise方法、Pairwise方法和Listwise方法。
Pointwise方法
Pointwise方法是把排序问题转化为机器学习中常规的分类、回归问题,从而可以直接应用现有的分类、回归方法解决排序问题。Pointwise的处理对象是单一文档。将单一查询文档对转化为特征向量,相关度作为Label,构成训练样本,然后采用分类或回归方法进行训练。得到训练模型后,再通过模型对新的查询和文档进行预测,得到相关度得分,最终将该得分作为文档排序的依据。下面通过例子来说明Pointwise方法。表3-2提供了4个训练样本,每个样本有2个特征:文档的余弦相似度以及页面的PageRank值。Label分为3个等级,即不相关、相关和非常相关。Pointwise方法通过多分类算法训练该数据集,然后通过训练后得到的模型对新的查询和文档进行预测。
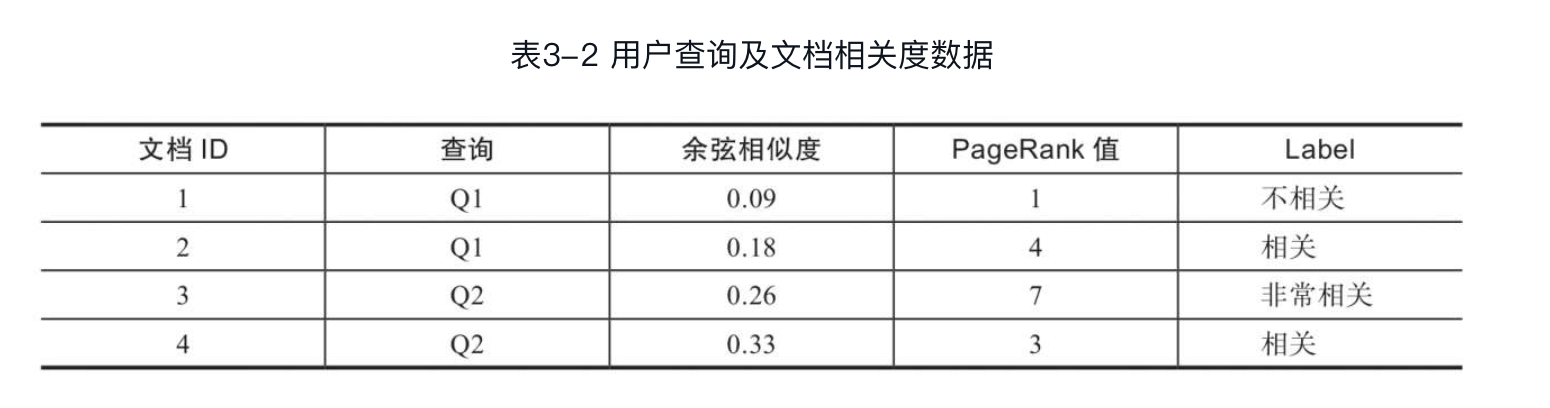
Pointwise方法存在一定的局限性,它仅仅考虑单个文档的绝对相关度,没有考虑给定查询下的文档集合的排序关系。此外,排在前面的文档相比于排在后面的文档对排序的影响更为重要,因为在很多情况下人们只关注top k的文档,而Pointwise方法并没有考虑这方面的影响。
Pairwise方法
如前所述,Pointwise方法只考虑单个文档与查询的绝对相关度,没有考虑给定查询下的文档集合的排序关系。Pairwise则将重点转向了文档之间的排序关系,它将排序问题转化为文档对排序关系的分类和回归问题。Pairwise方法有许多实现,如Ranking SVM、RankNet、Lambda Rank以及LambdaMART等。
对于给定查询下的文档集合,其中任何两个相关度不同的文档都可以组成一个训练实例。若比更相关,则该实例的label为1,否则为-1,这样就得到一个二分类的训练集。使用该训练集进行训练,得到模型后,可以预测所有文档对的排序关系,进而实现对所有文档进行排序。
Pairwise方法虽然考虑了文档之间的相对排序关系,但仍然没有考虑文档出现在结果列表中的位置。排在前面的文档更为重要,如果前面的文档出现错误,远比排在后面的文档出现错误影响更大。另外,对于不同的查询,相关文档数量有时差别会很大,转化为文档对后,有的查询可能有几百个文档对,而有的只有几个。这会使模型评估变得非常困难,如查询1对应100个文档对,查询2对应10个文档对。如果模型对查询1可以正确预测80个文档对,对查询2可正确预测3个,则总的文档对的预测准确率为[(80+3)/(100+10)]×100%≈75%,而对于两个查询的准确率分别为80%和30%,平均准确率为55%,与总文档对的预测准确率差别很大,即模型更偏向于相关文档集更大的查询。
Listwise方法
Pointwise方法和Pairwise方法分别以一个文档和文档对作为训练实例,Listwise方法则采用更直接的方式,即以整个文档列表作为一个训练实例。Listwise方法包括ListNet、AdaRank等。
Listwise根据训练集样本训练得到一个最优模型f,对新查询通过模型对每个文档进行打分,然后将得分由高到低排序,得到最终排序结果,其中的关键问题是如何优化训练得到最优模型。其中一种方法是针对排序指标进行,如MAP、NDCG作为最优评分函数,但因为很多类似NDCG这样的评分函数具有非连续性,因此比较难优化。另外一种方法是优化损失函数,如以正确排序与预测排序的分值向量间余弦相似度作为损失函数等。
排序评价指标
精确率、召回率和F-Score
AUC
AUC(Area Under the Curve,曲线下面积)是二分类问题中较常用的评估指标之一,此处的曲线即ROC(Receiver Operating Characteristic)曲线。ROC曲线描述的是模型的TPR(True Positive Rate)和FPR(False Postive Rate)之间的变化关系,其中TPR为模型分类正确的正样本个数占总正样本个数的比例,FPR为模型分类错误的负样本个数占总负样本个数的比例。
ROC曲线的横轴为FPR,纵轴为TPR。对于二分类问题,可以为每个样本预测一个正样本概率,通过与设定阈值的比较,决定其属于正样本还是负样本。例如,假设设定阈值为0.7,概率大于0.7的为正样本,小于0.7的为负样本,即可求得一组(FPR,TPR)的值作为坐标点,然后逐渐减小阈值,则更多的样本会划分为正样本,但也会导致一些负样本被错误划分为正样本,即FPR和TPR会同时增大,最大为坐标(1,1)。相反,阈值逐渐增大时,FPR和TPR会同时减小,最小为(0,0)。由此,便可得到ROC曲线。
ROC曲线有4个比较特殊的点:
- (0,0)——FPR和TPR均为0,表示模型将样本全部预测为负样本;
- (0,1)——FPR为0,TPR为1,表示模型将样本全部预测正确;
- (1,0)——FPR为1,TPR为0,表示模型将样本全部预测错误;
- (1,1)——FPR和TPR均为1,表示模型将样本全部预测为正样本。
当FPR和TPR相等时(即斜对角线),表示预测的正样本一半是对的,一半是错的,即可代表随机分类的结果。由此可知,若ROC曲线在斜对角线以下,表示模型分类的效果比随机分类还要差,反之,则表明模型分类效果优于随机分类。虽然ROC曲线可以在一定程度上反映分类的效果,但需要比较多个模型的分类效果时,ROC曲线则不够直观。因此,AUC便应运而生。AUC即ROC曲线下的面积,它是一种定量的指标,取值范围为[0,1],AUC越大,表明模型分类效果越好。当AUC<0.5时,表明模型分类效果差于随机分类;当0.5<AUC<1时,表明模型分类效果优于随机分类;当AUC=1时,表明模型完全分类正确。AUC在XGBoost中的参数为auc,可用于二分类问题和排序问题。
MAP
MAP(Mean Average Precision)是信息检索中的一个评价指标。MAP假定相关度有两个级别——相关与不相关。在学习MAP之前,我们先来了解一下AP(Average Precision),其计算方法如下:
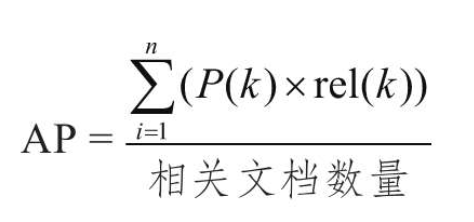
其中,k为文档在排序列表中的位置,P(k)为前k个结果的准确率,即

rel(k)表示位置k的文档是否相关,相关为1,不相关为0。
MAP为一组查询的AP的平均值,公式如下:
其中,q为查询,AP(q)为查询的平均准确率,Q为查询个数。
NDCG
前面介绍了准确率、MAP等信息检索评价指标,下面介绍另外一种评价指标——NDCG(Normalized DiscountedCumulative Gain)。在MAP中,相关度只有相关、不相关两个级别。NDCG则可以定义多级相关度,相关度级别更高的文档排序更靠前。在了解NDCG之前,先介绍一下DCG(Discounted Cumulative Gain),即折扣累计增益。DCG认为应对出现在排序列表中靠后的文档进行惩罚,因此文档相关度与其所在位置的对数成反比。只考虑前P个文档,DCG定义为:
其中,i是位置i上的文档相关度得分,为折算因子。DCG还有另外一种定义,也经常被使用:
该定义更强调检索相关度高的文档,被广泛应用于网络搜索公司和Kaggle等机器学习竞赛中。
因为不同的搜索结果列表长度很可能有所不同,因此不能用DCG对不同搜索结果进行对比,需要对DCG值进行归一化,即需要用到下面要介绍的NDCG。首先计算位置p最大可能的DCG,即理想情况下的DCG(IDCG):
则NDCG为:
NDCG会对文档排名较高的给予高分。对于理想情况下的排名,每个位置的NDCG值总为1;对于非理想的排名,NDCG值小于1。
下面通过例子来介绍NDCG的计算过程,假设查询q的结果列表包含5个文档,分别为(下标表示当前排序位置),相关度级别取值为1、2、3,分别代表不相关、相关、非常相关,的相关度分别为3、1、3、2、2。对每个文档计算和,如表3-3所示。
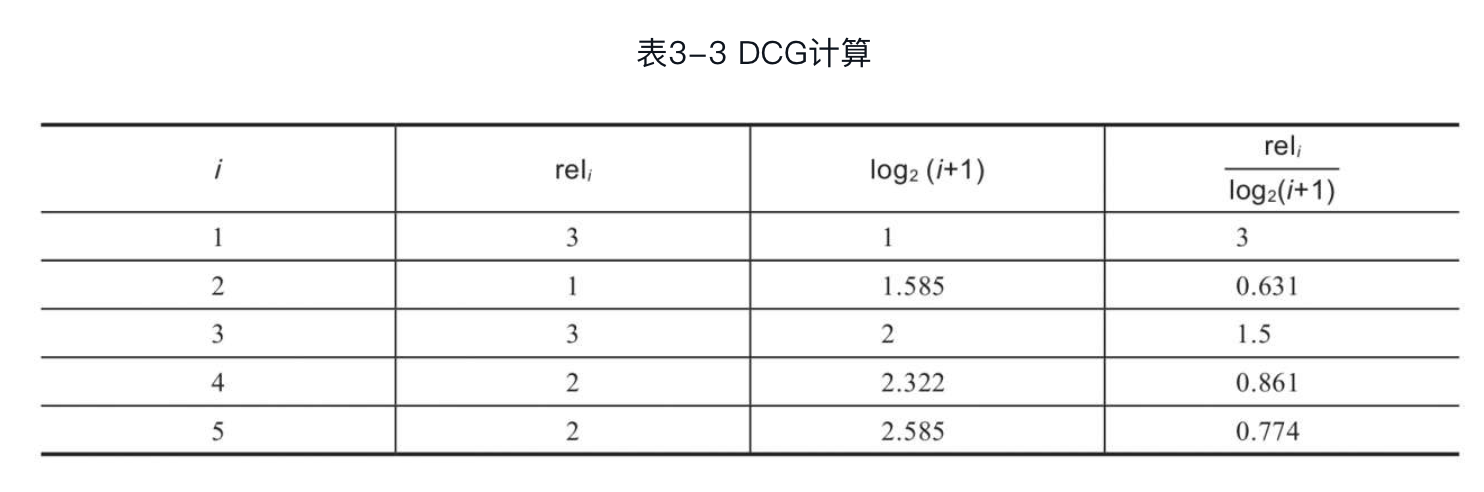
由此可计算为:
由表3-3可知,交换排名第一位和第二位的文档会导致DCG减小,因为不相关的文档排到了更高的位置,而非常相关文档却排到了更低的位置,因此不相关文档对应较大的折算因子,而相关文档对应较小的折算因子,导致DCG减小。假设除了查询结果列表的5个文档之外,还有两个文档$D_{6}, D_{7}$6、D7未进入结果列表,其相关度分别为3和1。对这7个文档按相关度进行排序,有:
3,3,3,2,2,1,1
计算到位置5的理想DCG(IDCG)为:
可求得为:
其他常用功能
本节以诊断乳腺肿瘤的二分类问题为例,介绍XGBoost中其他的常用功能,以下是数据加载和模型训练的代码:

将DMatrix保存为二进制文件
XGBoost可以将DMatrix数据结构保存为可直接加载的二进制文件。该操作的好处是将完成特征处理并且已转换为DMatrix格式的数据进行保存,下次加载时避免重复操作从而节省加载时间。将测试集保存为二进制文件,然后重新加载,最后的预测结果与之前是一致的。相关代码如下:

基于历史预测值继续训练
XGBoost支持在历史模型预测值的基础上继续训练,使模型快速达到较高的准确度,节省计算时间。此处的预测值为未进行转化(如sigmoid、softmax等)的原始值。

显然,设置历史预测值作为初始值训练模型时,模型很快达到了较高的准确度。

自定义目标函数和评估函数
实际应用中的需求是多种多样的,XGBoost内置的目标函数和评估函数并不能满足所有的应用需求,此时就需要自定义目标函数和评估函数。当然,并不是所有的函数都可以作为XGBoost的目标函数,由于XGBoost的特性,自定义目标函数时需返回其一阶、二阶梯度,因此目标函数需满足二次可微(后续会详细介绍)。需要注意的是,通过自定义目标函数得到的预测值是模型预测的原始值,不会进行任何转换(如sigmoid转换、softmax转换)。原因不难理解,自定义objective之后,模型并不知道该任务是什么类型的任务,因此也就不会再做转换。
自定义目标函数后,XGBoost内置的评估函数不一定适用。比如用户自定义了一个logloss的目标函数,得到的预测值是没有经过sigmoid转换的,而内置的评估函数默认是经过转换的,因此评估时就会出错。下面示例便实现了一个自定义的logloss目标函数和自定义的评估函数,代码如下:

该示例实现了一个二分类对数似然函数的自定义目标函数和一个错误率的评估函数。下面介绍自定义目标函数的实现。前述可知,二分类对数似然函数形式如下:
对其求一阶导为:
二阶导为:
其中为样本label,为当前模型的预测值(未进行变换),根据上述公式,logregobj函数实现了二分类对数似然函数一阶梯度和二阶梯度的计算,并作为函数返回值返回,从而实现自定义目标函数。自定义评估函数实现简单,此处不再详述。
因为模型产出的预测值preds为原始值,所以在自定义目标函数内部对preds进行了转换,转换之后再计算一阶、二阶梯度。另外,在自定义评估函数中的preds也为转换前的原始值,因此以0(而非0.5)作为分类阈值,即预测值大于0认为是正样本,小于0为是负样本。
实现了自定义函数后,即可通过该函数进行模型训练和评估,相关参数为obj和feval(不同语言版本的名称略有不同)。这两个参数均为函数引用,默认值为None,其中参数obj为目标函数,可调用系统内置的目标函数,也可调用用户自定义目标函数。参数feval为评估函数,可调用内置评估函数,也可调用用户自定义评估函数,通过指定的评估函数对模型预测结果进行评估。XGBoost通过上述两个参数即可实现基于用户自定义函数的模型训练与评估。
在某些应用场景下,若评估函数存在一阶导数和二阶导数,也可将评估函数作为目标函数进行训练。
交叉验证
交叉验证主要用于验证模型性能,评估机器学习算法的预测误差,分析其泛化能力。它的基本思想是将数据集划分为训练集和验证集,用训练集拟合模型,用验证集进行验证,从而评估预测误差(详见第8章交叉验证)。通过XGBoost进行交叉验证的代码如下:

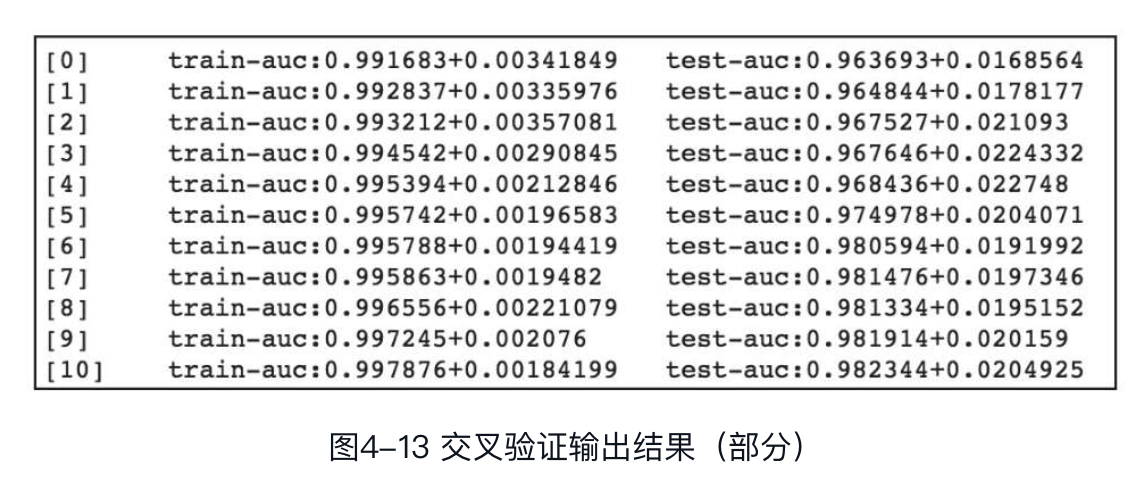
XGBoost通过cv函数进行交叉验证,参数nfold表示交叉验证中数据集被随机(参数seed为随机数种子)折叠为若干份,如nfold=5表示将数据集随机分为5份,选择第i份作为验证集,其余4份作为训练集。数据集中的每份都会依次作为验证集,这样最终会训练5个模型,得到5个结果。参数metrics是交叉验证使用的评估指标。参数callbacks可以定义多个callback函数,这些callback函数会在每一轮迭代的最后被调用,用户也可使用XGBoost中预定义的callback函数,如xgb.callback.reset_learning_rate(custom_rates)等。示例中采用了XGBoost内置的callback函数print_evaluation来输出评估指标的标准差。最终结果的输出格式为:指标名称:均值+标准差
执行上述代码,交叉验证部分输出结果如图所示。
如果不需要输出标准差,只输出metrics中定义的指标,则将show_stdv置为False即可。另外,可以借助XGBoost内置的early_stop函数,使模型在一定迭代次数内准确率没有提升时停止训练,本示例以test-auc作为准确率的评估指标。

输出结果如图所示。
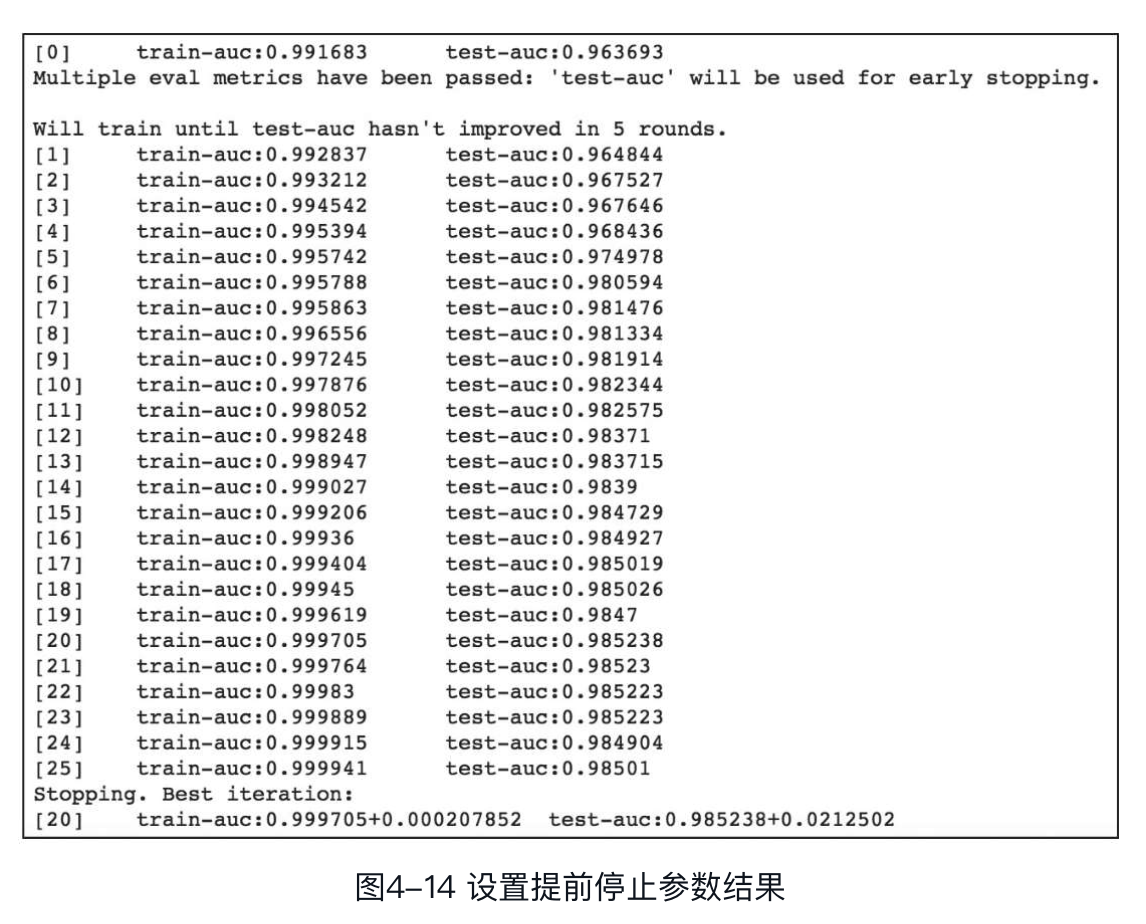
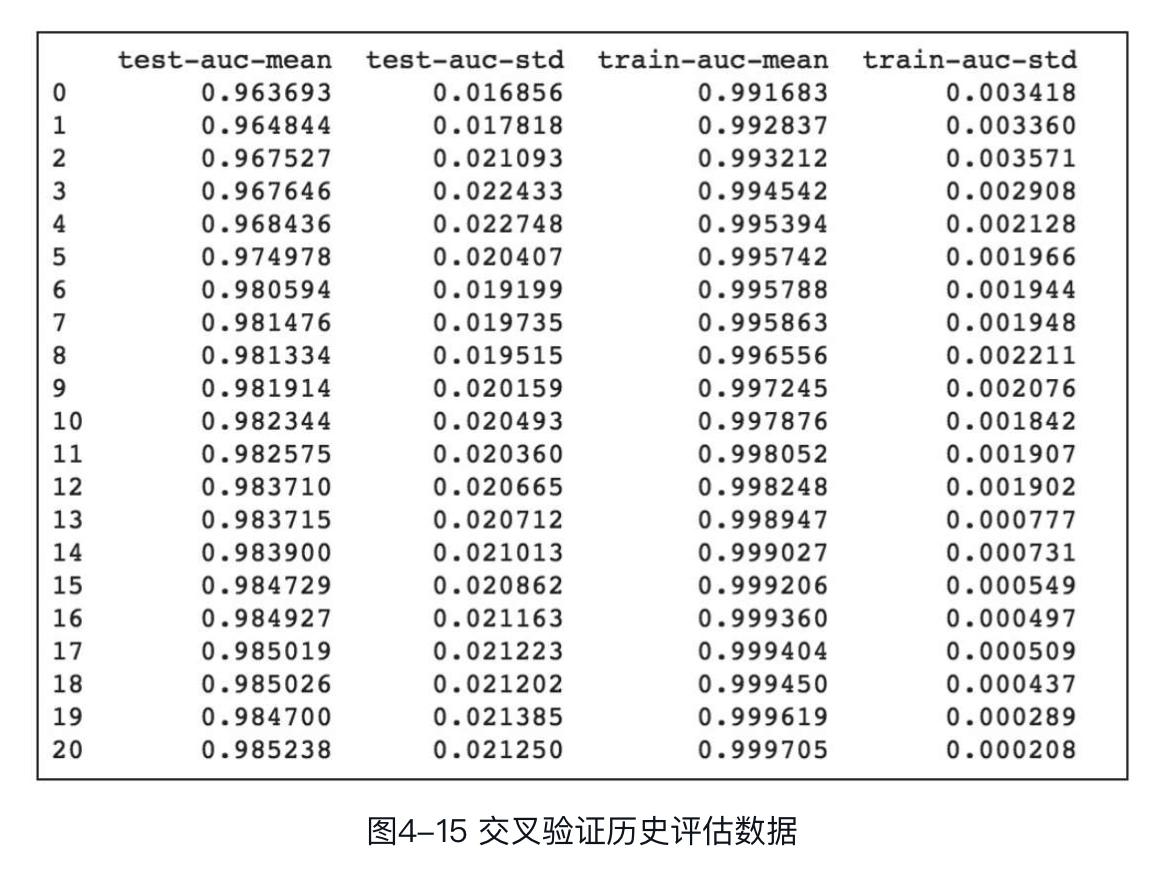
可以看到,模型训练进行到第20轮时,test-auc达到了0.985238,后续经过5轮迭代,test-auc并未提升,因此模型认为第20轮的模型为最优模型,停止后续训练过程。另外,cv函数会返回历史评估数据,将上例中的res变量打印至终端,输出结果如图所示。
交叉验证还支持自定义预处理函数,用于对数据集和参数进行预处理,再将处理后的数据进行随机划分。下面示例定义了一个预处理函数,该函数的功能是设置参数scale_pos_weight,解决正负样本悬殊的问题。代码如下:

前文介绍过,用户可以自定义目标函数来满足不同的应用需求,在交叉验证中,用户依然可以自定义目标函数,如下:

保存评估结果
由前述可知,XGBoost会打印训练过程中的评估结果,用户可以实时观测模型的训练效果。为便于后续使用,我们也可以将评估结果保存下来,如下:

用户只需定义一个dict类型的变量evals_result,并将其作为参数传入训练函数,即可将评估结果保存。通过访问evals_result来获取评估结果。代码如下:

访问保留的评估结果如图所示。

通过前n棵树进行预测
默认情况下,XGBoost会使用模型中所有决策树进行预测。在某些应用场景下,可以通过指定参数ntree_limit实现只使用前n棵树(非整个模型)进行预测,如下:

输出结果如图所示。
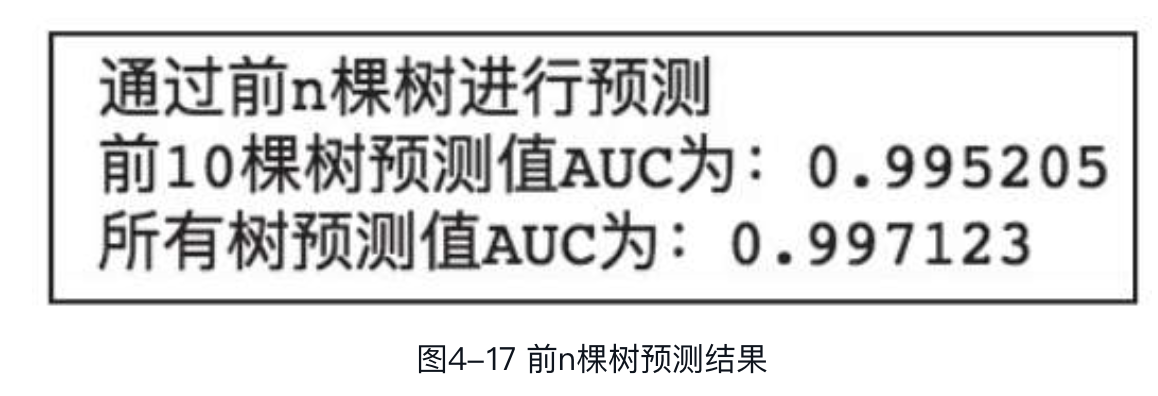
由迭代轮数可知,模型由50棵决策树组成。示例中先使用前10棵决策树进行预测,再用整个模型预测。可以看到,两次预测结果的AUC是不同的,只用前10棵树预测的结果要略差一些。
预测叶子节点索引
在XGBoost的树模型中,每个叶子节点在其所在的决策树中都有一个唯一索引。在预测阶段,样本在每棵决策树中都会被划分到唯一的叶子节点,所有叶子节点的索引组成一个向量,在某种程度上,该向量可以代表样本在模型中被划分的情况。XGBoost支持用户获得这样的叶子节点索引向量,只需将参数pred_leaf置为True即可,如下:

输出结果如图所示。
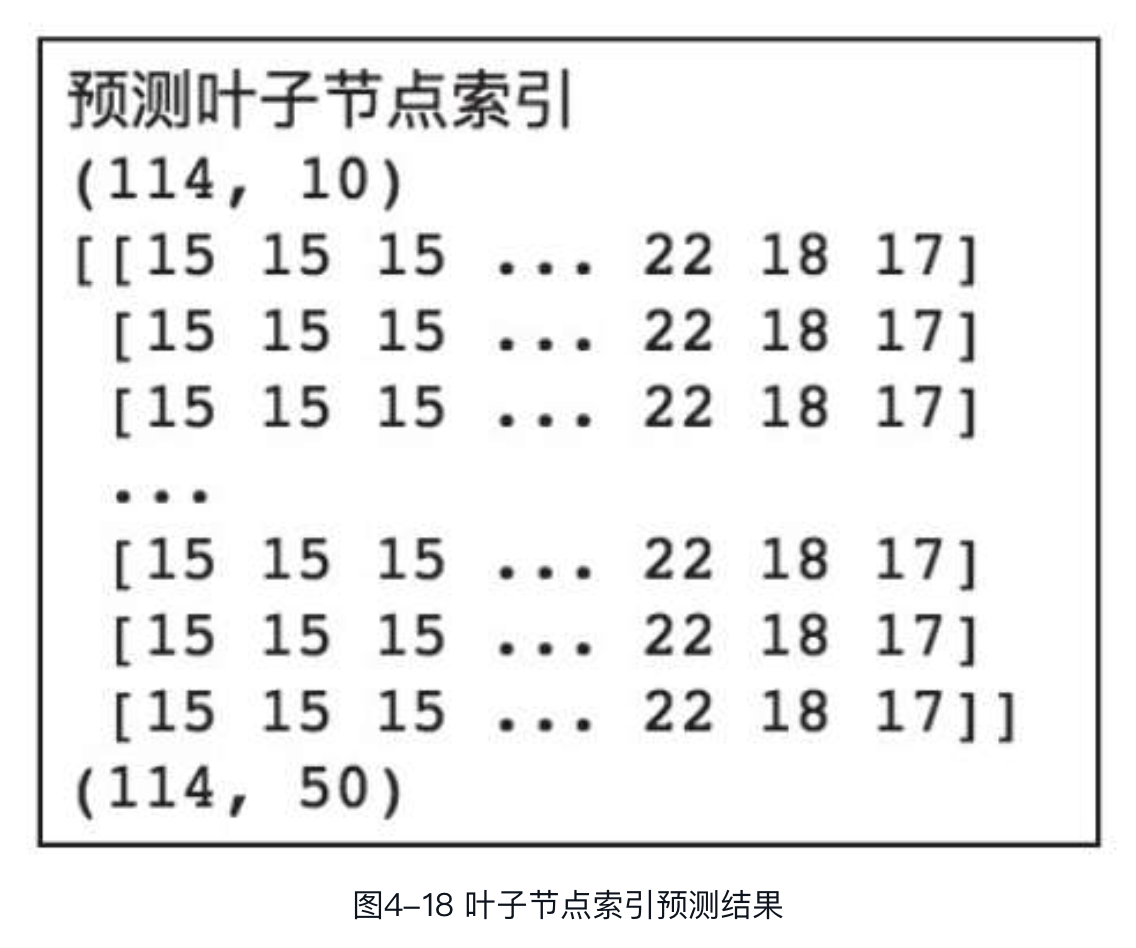
可以看到,两种方式得到的索引矩阵行数均为114,和数据集中的样本数量是一致的。通过前10棵树预测,得到的索引矩阵leafindex列数为10,通过整个模型预测后的列数为50,和决策树数量是一致的。索引矩阵中的元素便是该样本在对应决策树中归属叶子节点的索引。
scikit-learn版本
XGBoost有一个scikit-learn接口版本,该版本与scikit-learn实现了很好的融合,能够使用scikit-learn中的Gridsearch等实现XGBoost的超参数调优。还可以结合pipeline,实现机器学习过程的流式化封装和管理。以下代码展示了如何通过XGBoost的scikit-learn接口版本解决分类、回归等问题:

由上述示例可知,scikit-learn接口版本通过XGBClassifier解决分类问题,通过XGB-Regressor解决回归问题,并与scikit-learn保持一致,通过fit方法完成模型拟合。
通过前面的学习,相信读者已经可以构建一个初始的XGBoost模型。但在解决实际应用的问题时,初始模型是远远不够的,需要对其进行参数调优。XGBoost中有很多参数,单纯靠人工进行参数调优,工作量十分巨大,因此需要借助skicit-learn的GridSearchCV,示例代码如下所示:

示例中定义了每个参数的取值范围,将其传入GridSearchCV函数。GridSearchCV会遍历所有的参数组合,并输出其中最优的组合,输出结果如图所示。

如果模型训练时fit函数中设置了评估数据集参数eval_set,则可通过evals_result函数获取所有评估数据集的评估结果;若设置了参数eval_metric,则评估结果中会包含所有eval_metric中的评估指标,获取评估结果代码如下:

提前停止训练
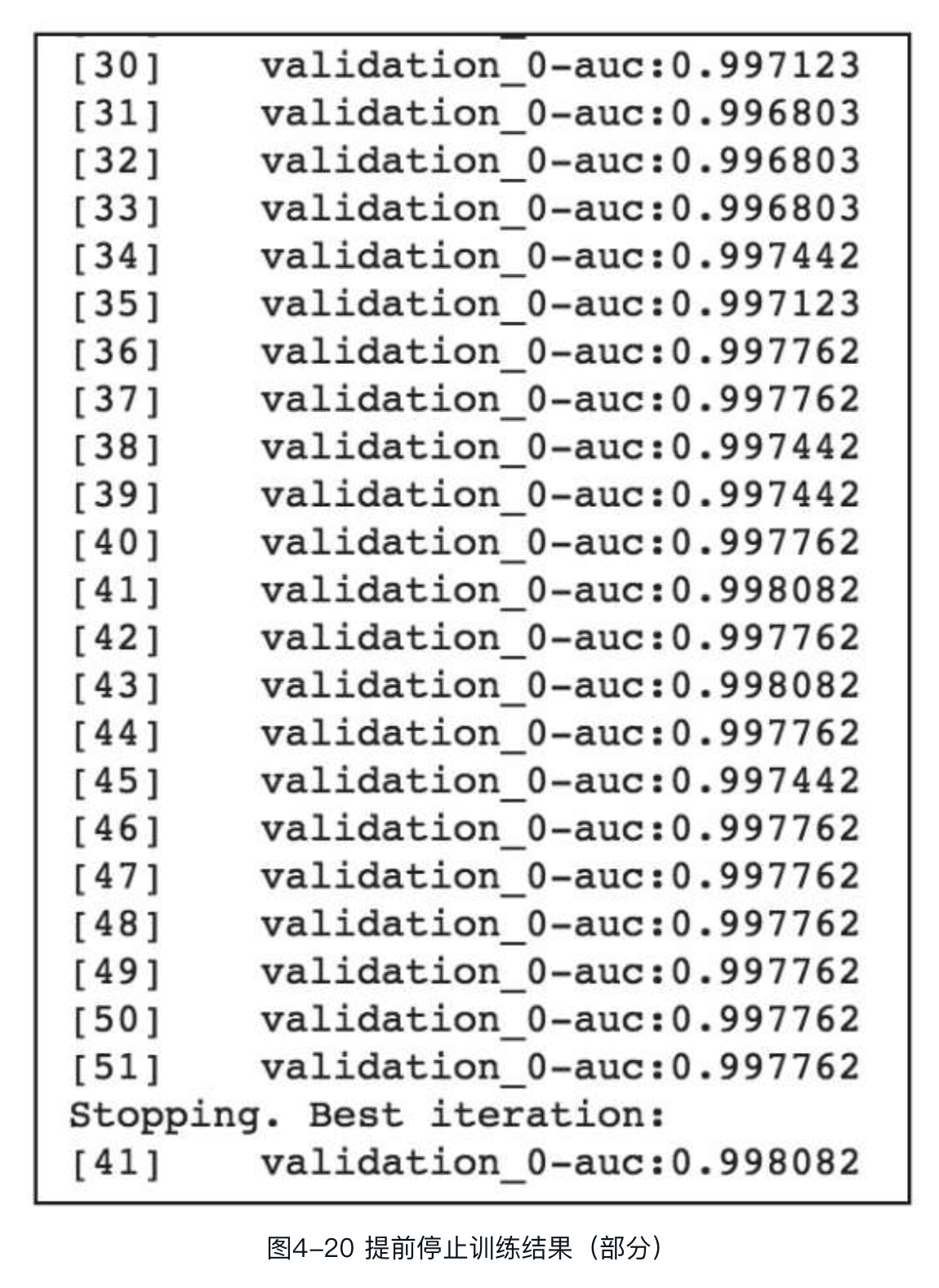
在XGBoost中,通过设置参数early_stopping_rounds,可以实现在一定迭代次数内评估指标没有提升就停止训练。提前停止训练,需在参数evals中至少设置一个评估指标,当存在多个评估指标时,默认选择最后一个。提前停止训练后,模型会包含3个额外字段:bst.best_score,bst.best_iteration和bst.best_ntree_limit。其中,best_score为模型训练中评估指标的最优值,best_iteration为最优迭代轮数,best_ntree_limit为最优的前n棵树。调用代码如下:

sklearn版本也支持提前停止训练,调用代码如下:

部分输出结果如图所示。由图可知,在第41轮之后AUC不再提高,因此51轮过后模型提前停止训练,模型最优的迭代轮数为第41轮。
特征重要性
通常来讲,特征的重要性表明每个特征在模型中的重要性或价值,某个特征在决策树中做出的关键决策越多,其特征重要性评分越高。XGBoost有3个衡量特征重要性的指标:weight、gain和cover。后续XGBoost又增加了total_gain和total_cover两种方式。表示总收益和总覆盖率。默认方式为weight,表示在模型中一个特征被选作分裂特征的次数。gain表示特征在模型中被使用的平均收益,收益通过损失函数的变化度量。cover表示特征在模型中被使用的平均覆盖率,通过节点的二阶梯度和来度量。
XGBoost提供了两个获取特征重要性评分的方法:get_fscore和get_score。get_fscore函数采用了默认的weight指标计算特征重要性评分,而get_score可通过参数选择weight、gain或者cover。首先介绍get_fscore函数,仍以二分类为例进行说明,代码如下:

模型训练完毕后,通过get_fscore获取模型特征重要性评分,然后按重要程度对特征排序,部分输出结果如图所示。
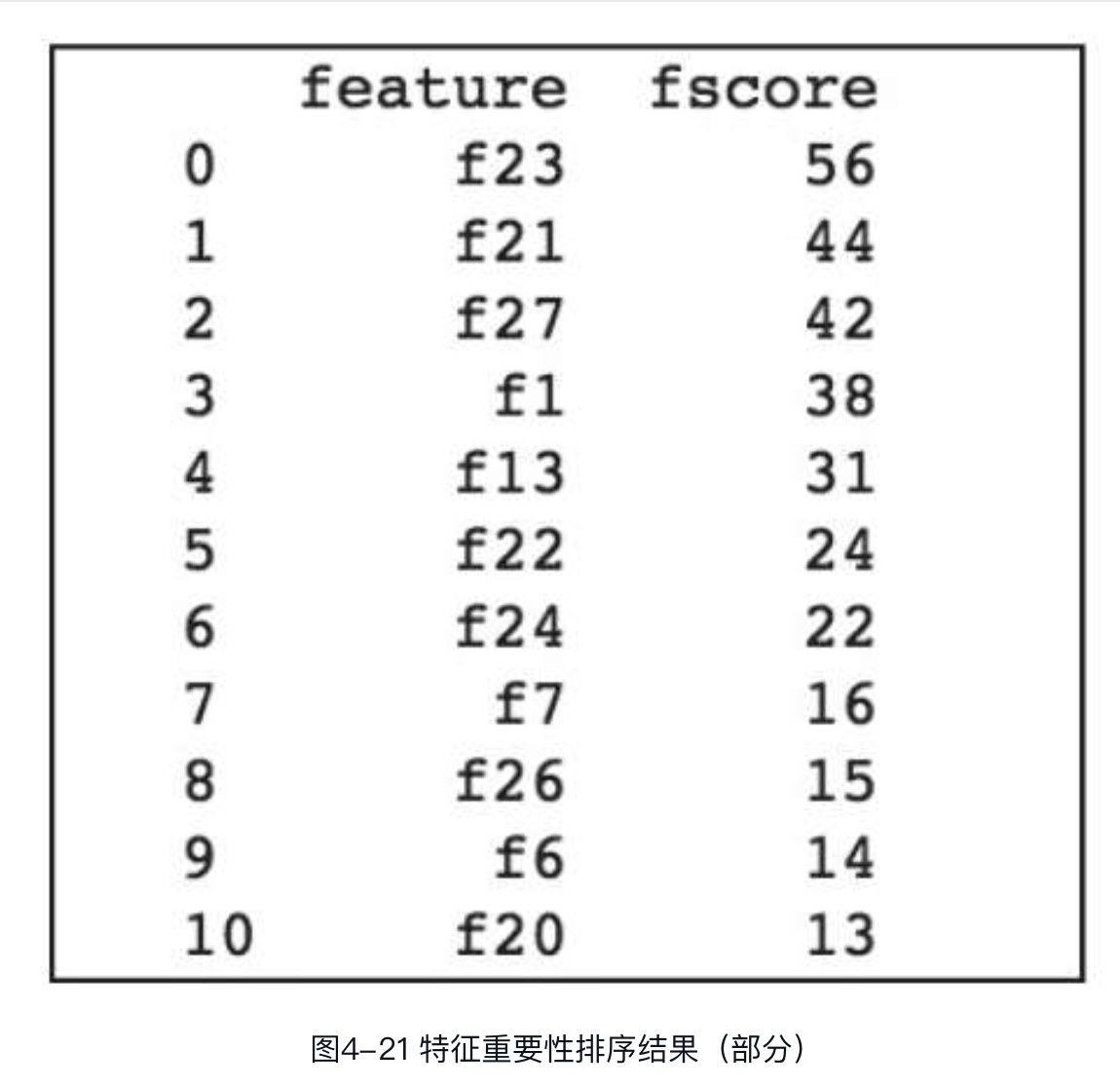
在图中,feature为特征名称,此处因未指定特征映射文件,因此名称以编号展示,读者可尝试传入特征映射文件,观察特征名称的输出变化。fscore为特征重要性评分,此处为该特征在模型中作为分裂特征的次数。计算每个特征在所有特征中的权重占比,可以得到如图所示结果。
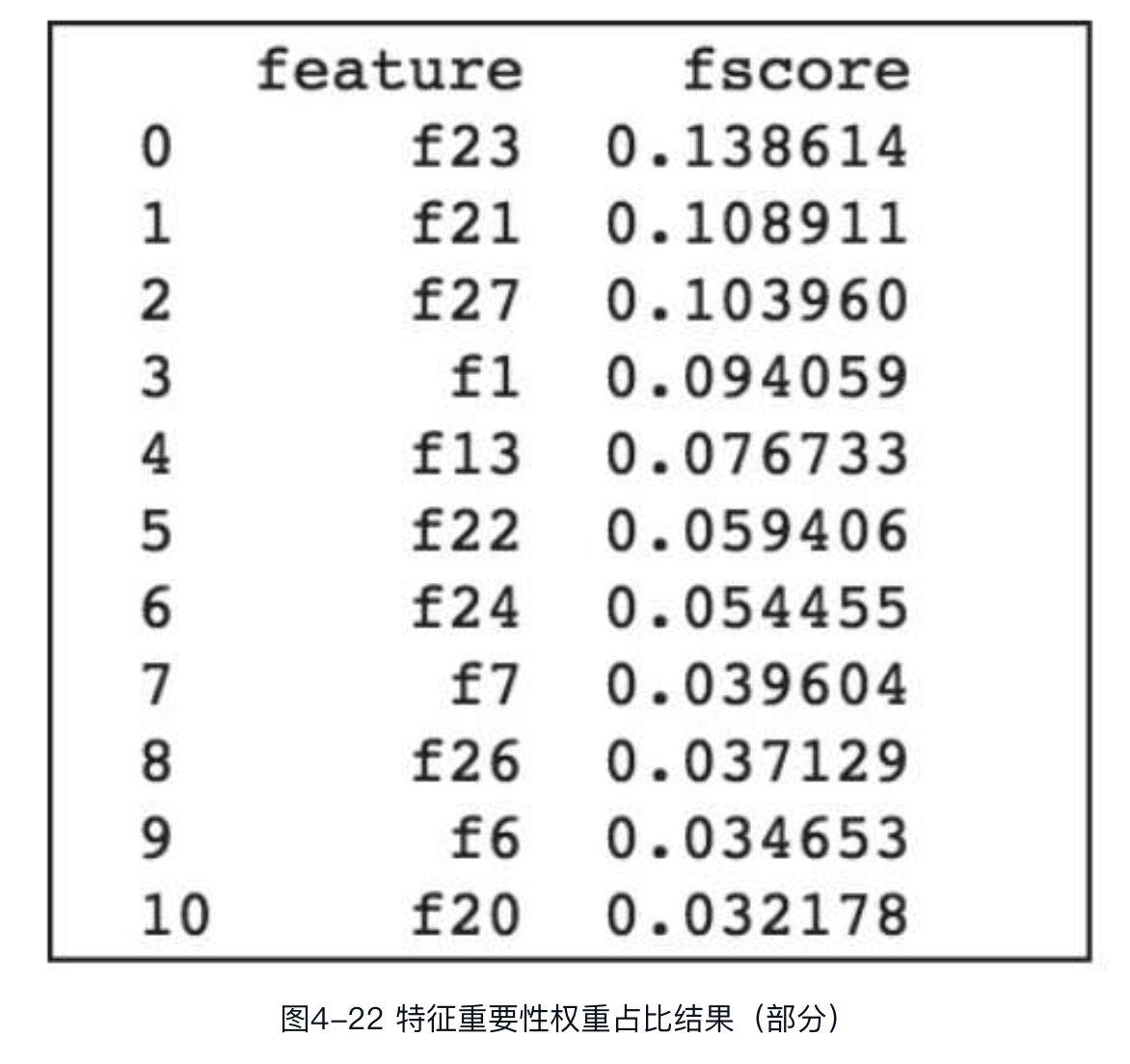
如果想以gain和cover作为评估特征重要性的指标,可通过get_score函数获取,代码如下:

输出结果如图所示。
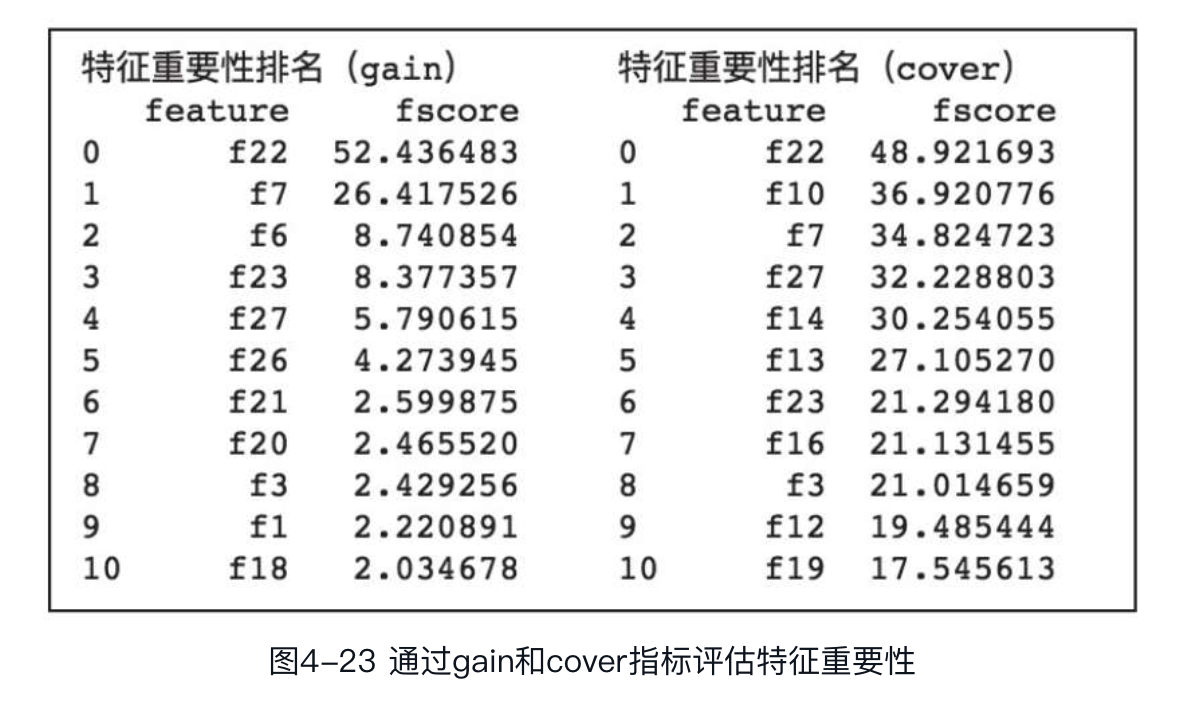
可以看到,以不同的指标计算特征重要性,得到的排序结果是不同的,可以帮助用户从不同角度分析哪些特征更有价值。
基于特征重要性的特征选择
在了解了特征重要性之后,可以结合scikit-learn的SelectFromModel类进行特征选择。SelectFromModel类相关信息如下:

参数说明如下。
estimator:构建transformer的基础estimator。estimator既可以是已拟合的(如果prefit设置为True),也可以是未拟合的,拟合过的estimator需要包含feature_importances_或coef_属性。threshold:特征提取的阈值。当特征重要性取值大于等于该阈值时,特征被选取,否则被丢弃。该参数可以是数值类型,也可以是字符串形式,如果设为"median",则表示该阈值取值为特征重要性的中位数;设为"mean",表示取值为特征重要性的平均值。另外,还可以加扩展因子,如"1.25*mean"。当参数为None时,如果estimator有L1正则参数,则默认使用阈值1e-5;如果没有L1正则参数,则默认使用"mean"。prefit:是否为预装模型,直接传给构造函数,如果设置为True,则必须直接调用transform,并且SelectFromModel不能和cross_val_score、GridSearchCV、克隆estimator的类似工具一起使用。如果设置为False,则先通过fit训练模型,再调用transform进行特征选择。norm_order:范数的阶,当estimator的coef_属性为二维时,用于过滤低于阈值的系数向量。
下面来看一个通过SelectFromModel对XGBoost模型进行特征选择的示例:

在上述代码中,首先通过XGBoost的sklearn版本中的XGBClassifier拟合训练集数据,计算模型对测试集预测结果的AUC,用于和特征选择后的模型预测效果对比。然后获取模型的特征重要性评分,sklearn版本通过feature_importances_来获取,相当于get_fscore()。因为要将每个特征重要性评分作为阈值进行特征选择,相同评分无须重复进行,因此要对特征重要性评分进行去重、排序的处理。遍历处理后的重要性评分,使其依次作为阈值进行特征选择,并输出每个阈值对应的特征选择数量,以及模型对测试集的预测结果评估,输出结果如图所示。
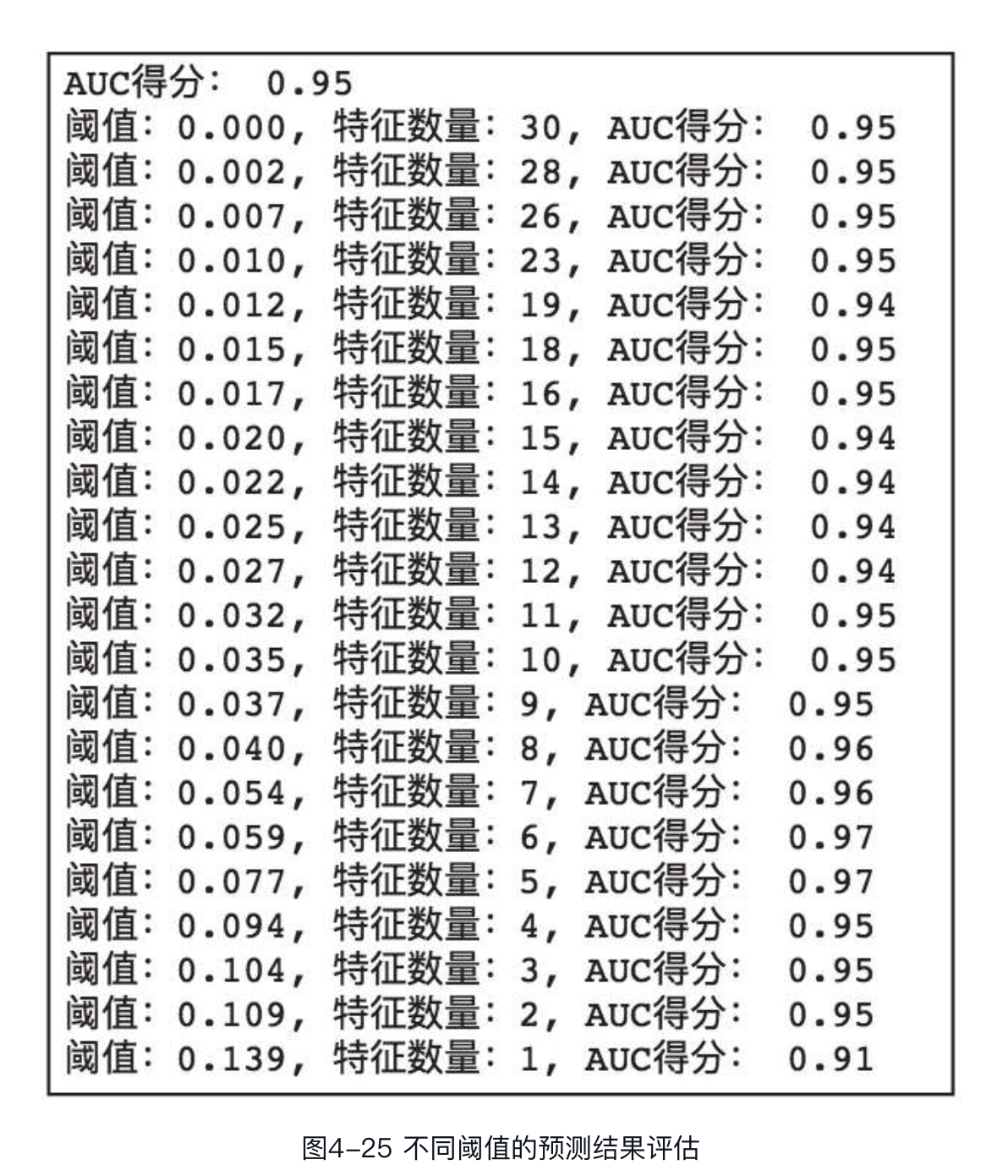
可以看到,当特征数量为5和6时,测试集AUC均为0.97。因此,在保证AUC的前提下,可将特征数量由126个缩减为5个。我们可以通过SelectFromModel类中的get_support方法获取被选择的特征,该方法包含一个参数indices,默认取值为False,表示方法的返回值为选择特征的掩码,如下:

输出结果是一个和原始数据集特征数量相同的数组,True表示该特征被选择,False表示该特征被丢弃。当参数indices设为True时,方法返回值为选择特征的索引,如下:

当indices被置为True后,输出不再是与原始数据集特征数量相同的掩码数组,而是一个只包含被选特征索引的整型数组。
个性化归因
在实际应用场景中,除了需要评估特征对模型的重要性之外,有时还需要评估特征对于单个样本的贡献值,即特征对于样本预测值的影响有多大。例如,银行对用户借贷是否逾期进行预测,除了希望得到预测结果外,分析师可能更想知道模型是如何判定一个样本会有逾期风险的。在0.81及以上版本的XGBoost中,提供了两种单样本的模型归因方法:SHAP和Saabas,这两种方法的实现原理会在第5章中介绍。本节主要聚焦于如何应用该归因方法。
和特征重要性类似,首先需要训练一个模型。模型训练好之后,即可通过归因方法计算预测样本的特征贡献度。以SHAP方法为例,其调用方法非常简单,只需在执行predict函数时将参数pred_contribs设置为True即可,代码如下:

此时predict函数的返回值不再是数据集的预测值,而是每个样本的各个特征对该样本的贡献值。返回矩阵的行数为数据集的样本数量,列数则比特征总数量多一列。其中前m(特征数量)列为各个特征对该样本的贡献值,最后一列为偏置项(Bias)。偏置项可以理解为在没有任何特征的情况下每个预测样本的基础分,一般为所有样本真实值的均值。下面将pred_contribs中的一个样本打印出来:

因为该数据集包含30个特征,因此一个样本的输出向量有31列,最后一列即为偏置项。由图可以清楚地看到每个特征对该样本的贡献值,正值表明该特征对样本的影响是正向的,负值表示是负向的。所有的特征贡献值(包括偏置项)加起来即为预测样本未转换(如sigmoid转换)前的预测值。此外,XGBoost还支持SHAP方法对任意两两交叉特征贡献值的评估,只需将参数pred_interactions置为True即可,如下:

此时的返回结果中,每个样本由一个二维矩阵解释,矩阵的行数和列数均为31,矩阵中的值Matrix[i][j]表示第i个特征和第j个特征交叉对该样本的贡献值。矩阵中所有值的和即为样本未转换前的预测值。
除了SHAP方法外,XGBoost还支持另外一种单样本归因方法Sabbas。相比SHAP方法,Sabbas实现简单、容易理解,但其弊端也是不可忽视的,即容易产生不一致的问题,具体可参见第5章。这里主要介绍它的调用方法,如下:

可以看到,只需在SHAP调用方法的基础上将参数approx_contribs设置为True即可。Sabbas方法返回的数据格式与SHAP是一样的,即输出每个特征的贡献值和偏置项。
XGBoost原理与理论证明
本章将深入介绍XGBoost中树模型和线性模型的实现原理,并进行详细的公式推导,从理论上证明模型的有效性。XGBoost树模型通过CART实现集成学习,通过Gradient Boosting进行模型训练,相关内容分别在5.1节和5.2节介绍。随后两节阐述Gradient Tree Boosting以及切分点查找算法的实现原理。XGBoost通过算法优化,可以显著提高模型的训练速度,解决数据不能完全加载进内存引起的性能瓶颈问题。随后介绍了排序学习、DART、可解释性等在XGBoost中的实现,扩展了其适用的应用场景。本章的最后阐述了XGBoost系统优化的相关算法,不但可以解决缓存命中率低的问题,还将大大提高数据加载速度,节省训练时间。
CART
XGBoost由多棵CART(Classification And Regression Tree)组成,每一棵决策树学习的是目标值与之前所有树预测值之和的残差,多棵决策树共同决策,最后将所有树的结果累加起来作为最终的预测结果。在训练阶段,每棵新增加的树是在已训练完成的树的基础上进行训练的。
CART算法的决策树类型:分类树和回归树。分类树的预测值是离散的,通常会将叶子节点中多数样本的类别作为该节点的预测类别。回归树的预测值是连续的,通常会将叶子节点中多数样本的平均值作为该节点的预测值。
CART算法采用的是二分递归分裂的思想:首先按一定的度量方法选出最优特征及切分点,然后通过该特征及切分点将样本集划分为两个子样本集,即由该节点生成两个子节点,依次递归该过程直到满足结束条件。因此,CART算法生成的决策树均为二叉树。通常CART算法在生成决策树后,采用剪枝算法对生成的决策树进行剪枝,防止对噪声数据或者一些孤立点的过度学习导致过拟合。
CART生成
在特征选择方法上,ID3算法采用信息增益来度量划分数据集前后不确定性减少的程度,从而进行最优特征选择,C4.5算法采用的是信息增益比。CART算法则采用了一种新的策略:分类树采用基尼指数最小化进行特征选择,回归树则采用平方误差最小化。
分类树的生成
CART生成树的过程是自上而下进行的,从根节点开始,通过特征选择进行分裂。CART采用基尼指数作为特征选择的度量方式生成分类树,通过基尼指数最小化进行最优特征选择,决定最优切分点。
基尼指数的定义如下:
式中,为样本集;表示类别个数;表示类别为的样本占所有样本的比值。由此可知,样本分布越集中,则基尼指数越小。当所有样本都是一个类别时,基尼指数为0;样本分布越均匀,则基尼指数越大。对于二分类问题可进行如下推导:
基尼指数越大,表明经过特征分裂后的样本不确定性越大,反之,不确定性越小。针对所有可能的特征及所有可能的切分点,分别计算分裂后的基尼指数,选择基尼指数最小的特征及切分点作为最优特征和最优切分点。通过最优特征和最优切分点对节点进行分裂,生成子节点,即将原样本集划分成了两个子样本集,然后对子节点递归调用上述步骤,直到满足停止条件。一般来说,停止条件是基尼指数小于某阈值或者节点样本数小于一定阈值。当然,如果某节点的样本已全部属于一种类别,分裂也会停止。由此,我们可以得出分类树生成的步骤。
- 从根节点开始分裂。
- 节点分裂之前,计算所有可能的特征及它们所有可能的切分点分裂后的基尼指数。
- 选出基尼指数最小的特征及其切分点作为最优特征和最优切分点。通过最优特征和最优切分点对节点进行分裂,生成两个子节点。
- 对新生成的子节点递归步骤2、3,直至满足停止条件。
- 生成分类树。
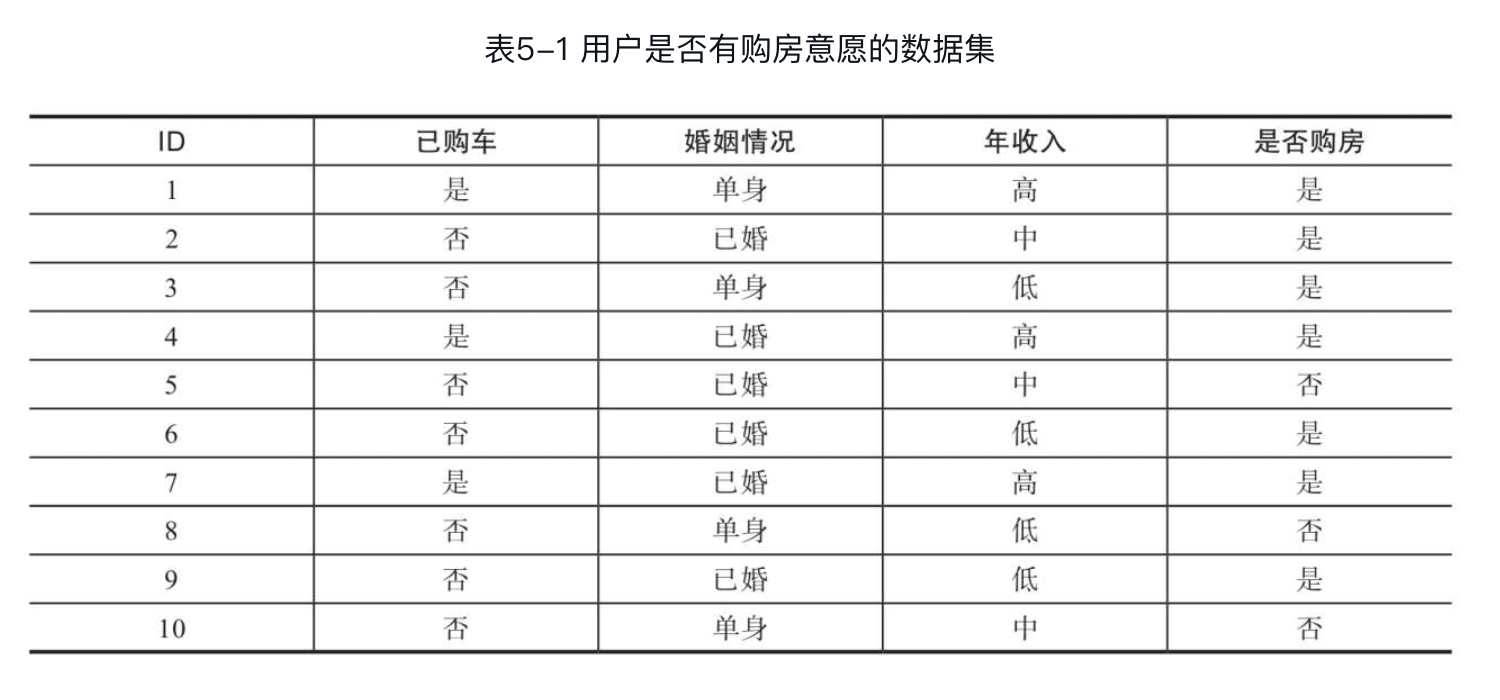
下面通过一个例子来理解分类树生成的过程。表5-1是预测用户是否有购房意愿的数据集,数据包含3个特征:第一个特征为已购车,取值是或否;第二个特征是婚姻状况,取值单身或已婚;第三个特征为年收入,取值分别为高、中、低;最后一列为类别,即用户是否购买房产,类别可能值有两个,即是或否。
回归树的生成
回归树是预测值为连续值的决策树,一般将叶子节点所有样本的平均值作为该节点的预测值。CART算法生成回归树的方法与生成分类树的不同,不再通过基尼指数进行特征选择,而是采用平方误差最小化。平方误差的定义如下:
回归树在进行特征选择时,对于所有特征及切分点,分别计算分裂后子节点的平方误差之和,选择平方误差之和最小的作为最优特征和最优切分点。
回归树的生成步骤如下。
- 从根节点开始分裂。
- 节点分裂之前,计算所有可能的特征及它们所有可能的切分点分裂后的平方误差。
- 如果所有的平方误差均相同或减小值小于某一阈值,或者节点包含的样本数小于某一阈值,则分裂停止;否则,选择使平方误差最小的特征和切分点作为最优特征和最优切分点进行分裂,生成两个子节点。
- 对于每一个生成的新节点,递归执行步骤2、步骤3,直至满足停止条件。
XGBoost中采用的决策树(即回归树),因而决策树的生成过程与上述过程类似,只不过在细节上稍有变化,在后续的章节中我们将陆续介绍。
剪枝算法
通过上面的介绍,相信读者已经了解了决策树的生成过程,CART的生成树算法根据基尼指数或平方误差进行分裂,最终生成决策树。在这种情况下,生成的决策树往往较为复杂,虽然对训练样本的预测具有很高的准确率,但也可能因为过多地拟合噪声,导致泛化能力比较差,出现过拟合问题。剪枝算法用于修剪分裂前后预测误差变化不大的子树,降低树的复杂度,提高泛化能力,防止过拟合。
剪枝算法分为预剪枝算法和后剪枝算法。CART算法采用后剪枝算法,即生成决策树后再对其剪枝。剪枝过程如下。
- 对于生成的决策树,从底部开始由下往上依次进行剪枝,直到根节点。对于每一种剪枝情况都会生成一棵子树,由此可得到一个子树集合。
- 在测试集上使用交叉验证的方法依次对每棵子树进行验证,选取最优子树。
在生成子树集合的过程中,首先会定义一个剪枝损失函数,该函数由预测误差和树的复杂度共同决定。对于一棵完整的树,其子树数目是有限的,我们可以找到这些有限的子树,而剪枝后的最优决策树也必定在这些有限子树中。在交叉验证中可采用独立于训练集的数据集作为验证集,比较各子树对于验证集的评估指标(分类树的评估指标为基尼指数,回归树的评估指标为平方误差),最后选出最优决策树。XGBoost在实现时并未完全按照上述剪枝过程,而是采用了简单、高效的剪枝方法,即判断当前节点的收益是否小于定义的最小收益,若比最小收益小,则进行剪枝。
本节介绍了CART算法中的分类树的生成和回归树的生成。分类树的生成以基尼指数作为特征选择的度量方式,对所有特征及其切分点进行计算,选取基尼指数最小的特征及其切分点作为最优特征和最优切分点,生成分类树。回归树的生成与分类树的生成实现原理类似,区别只是其特征选择的度量方式采用的是平方误差而不是基尼系数。本节还介绍了CART的剪枝算法,首先生成子树集合,再通过交叉验证的方法从子树集合中选取最优子树。因为XGBoost树模型就是由CART树组成的,因此CART算法是XGBoost实现原理中不可或缺的部分。理解了CART算法,也就理解了XGBoost模型构建的过程。
Boosting算法思想与实现
由前述内容可知,XGBoost是由多棵决策树(即CART回归树)构成的,那么多棵决策树是如何协作的呢?此时便用到了Boosting技术。Boosting的基本思想是将多个弱学习器通过一定的方法整合为一个强学习器。在分类问题中,虽然每个弱分类器对全局的预测准确率不高,但可能对数据某一方面的预测准确率非常高,将很多局部预测准确率非常高的弱分类器进行组合,即可达到全局预测准确率高的强分类器的效果。
AdaBoost
AdaBoost算法很好地继承了Boosting的思想,即为每个弱学习器赋予不同的权值,将所有弱学习器的权重和作为预测的结果,达到强学习器的效果。对于分类问题,AdaBoost首先为每个训练样本赋予一个初始权值,每轮对一个弱分类器进行训练,其次将预测结果与样本的类别对比,提高预测错误的样本的权值,降低预测正确的样本的权值;然后计算该分类器的分类误差率,通过分类误差率计算该分类器的权值,分类误差率越小,权值越大,反之越小;进行下一轮训练得到下一个分类器,如此直至满足停止条件。假设共得到了个分类器,对应的权值为,则最终分类结果由这个分类器通过加权投票决定。权值越大的分类器发挥的作用越大,反之越小。AdaBoost算法是一种精确度很高的算法,它可以用各种类型的学习器作为自己的子学习器,将其由弱学习器提升为强学习器。
Gradient Boosting
Gradient Boosting是Boosting思想的另外一种实现,由Friedman于1999年提出。Gradient Boosting与AdaBoost类似,也是将弱学习器通过一定方法的融合,提升为强学习器。与AdaBoost不同的是,它将损失函数梯度下降方向作为优化目标。因为损失函数用于衡量模型对数据的拟合程度,损失函数越小,说明模型对数据拟合得越好,在梯度下降的方向不断优化,使损失函数持续下降,从而提高了模型的拟合程度。
Gradient Boosting既可以应用于分类问题,也可以应用于回归问题。下面以回归问题为例介绍Gradient Boosting的训练过程。
假设模型为,损失函数为,每一轮模型训练的目标是使预测值与真实值的平方误差最小。假设第轮的模型函数为,在进行第轮训练时,Gradient Boosting并不改变,而是在的基础上增加一个新模型,使得模型预测准确率得以提高,即。为梯度下降的步长,子模型可以是线性回归、决策树等模型。
首先,通过常数初始化模型,,即通过训练一个常数使得所有样本的损失函数之和最小。随后,在第轮训练中,每个模型学习之前模型损失函数的梯度方向。具体方法为:先对损失函数求偏导:
偏导表示损失函数的梯度方向,再取负表示负梯度方向,通过负梯度方向逐步优化模型。在第1轮训练中,模型以为目标值进行学习,即学习真实值与预测值之间的“残差”,再通过损失函数最小化找到最优,由此得到。以此类推,第轮的模型以作为目标值进行学习,得到,直到满足停止条件,最终得到模型。
每次子模型学习的都是前面所有子模型的预测值之和与真实值之间的残差,每轮训练都可以使整体模型的预测值更趋近于真实值,从而使模型最终达到较好的预测效果。至此,我们对Gradient Boosting已经有了一个整体的了解,下面来看一下Gradient Boosting算法,其流程如算法所示。
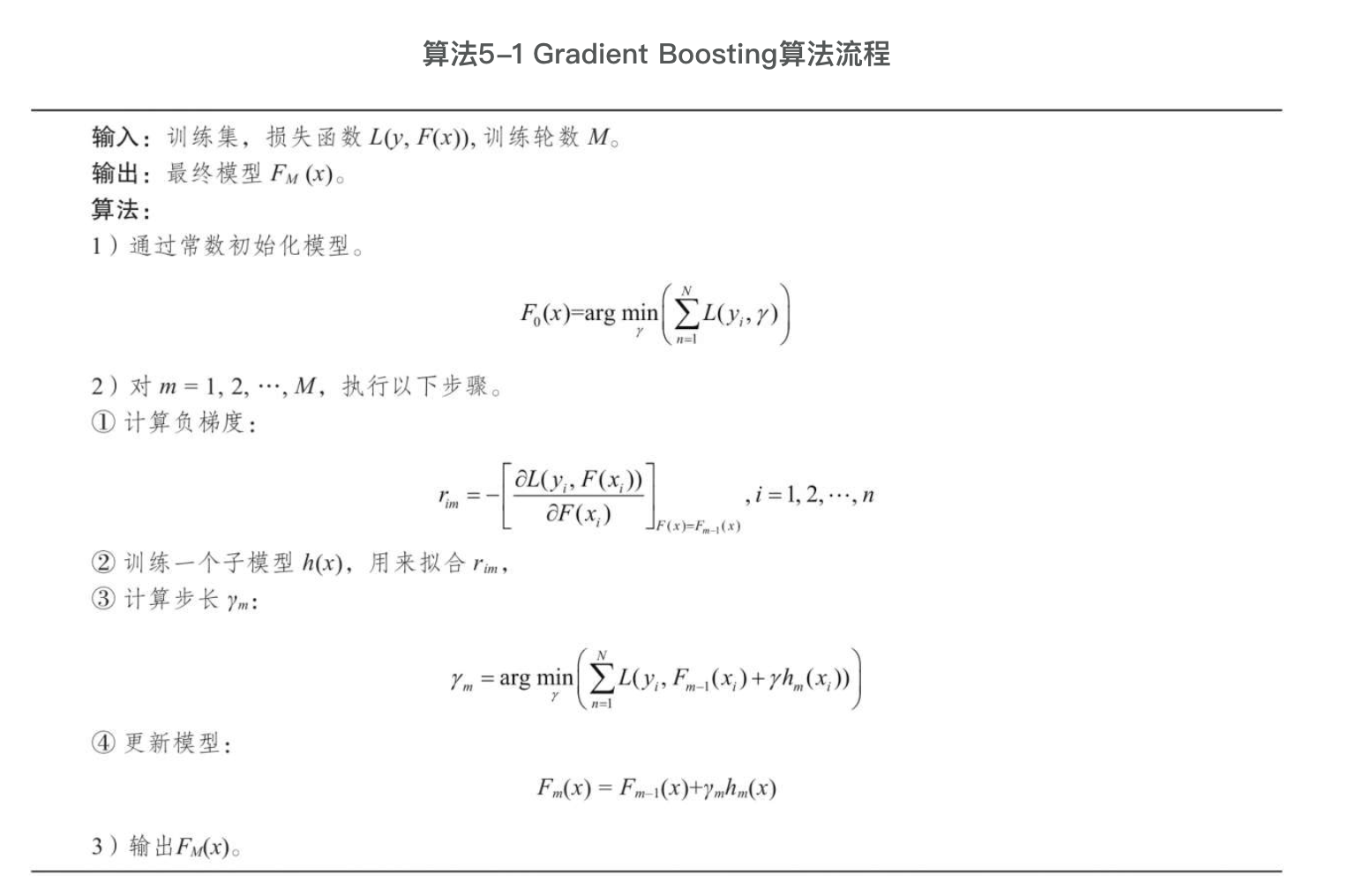
算法第1步初始化一个常数作为初始模型。在第2步中,每一轮均在前面训练的基础上训练一个新的子模型。第2步①计算损失函数的负梯度,将其作为残差;第2步②训练一个子模型,以拟合第2步①中的残差;第2步③通过线性搜索找到最优,使得损失函数最小。最后,经过轮训练更新模型,第3步输出最终模型。
缩减
缩减(shrinkage)的思想是每次沿梯度下降的方向走一小步,逐步逼近最优结果,而不是一步到位,这样可以有效地避免模型过拟合。缩减会为每一轮训练的新模型增加一个类似于“学习率”的系数,用来减小每轮在梯度下降方向的“步长”,具体如下:
Freidman等人发现,较小的缩减系数ν可以减少测试集的错误率,从而提高模型的泛化能力。而对于同一个训练集,当缩减系数ν减小时,训练轮数M会增大,因此ν取值较小意味着要花费更多的时间训练模型。针对上述问题,一种比较好的策略是先选取较小的ν,然后通过设定合适的停止条件停止训练,从而控制训练轮数M。
Gradient Tree Boosting
Gradient Tree Boosting是Gradient Boosting应用最为广泛的一种实现,它以决策树作为子模型,其中最具代表性的以CART作为子模型。Gradient Tree Boosting主要具有如下优势:
- 可以有效挖掘特征及特征组合;
- 模型具有更好的泛化能力;
- 能够达到较高的预测准确率。
Gradient Tree Boosting算法和Gradient Boosting类似,区别只在于Gradient Tree Boosting子模型为树模型。Gradient Tree Boosting算法的执行过程如算法5-2所示。

该算法与Gradient Boosting算法的不同之处在于第2步②,Gradient Tree Boosting算法通过拟合一棵回归树去拟合负梯度,终端区域可以理解为叶子节点。在第2步③生成新的回归树时,对于每个终端区域均计算一个。
XGBoost中的Tree Boosting
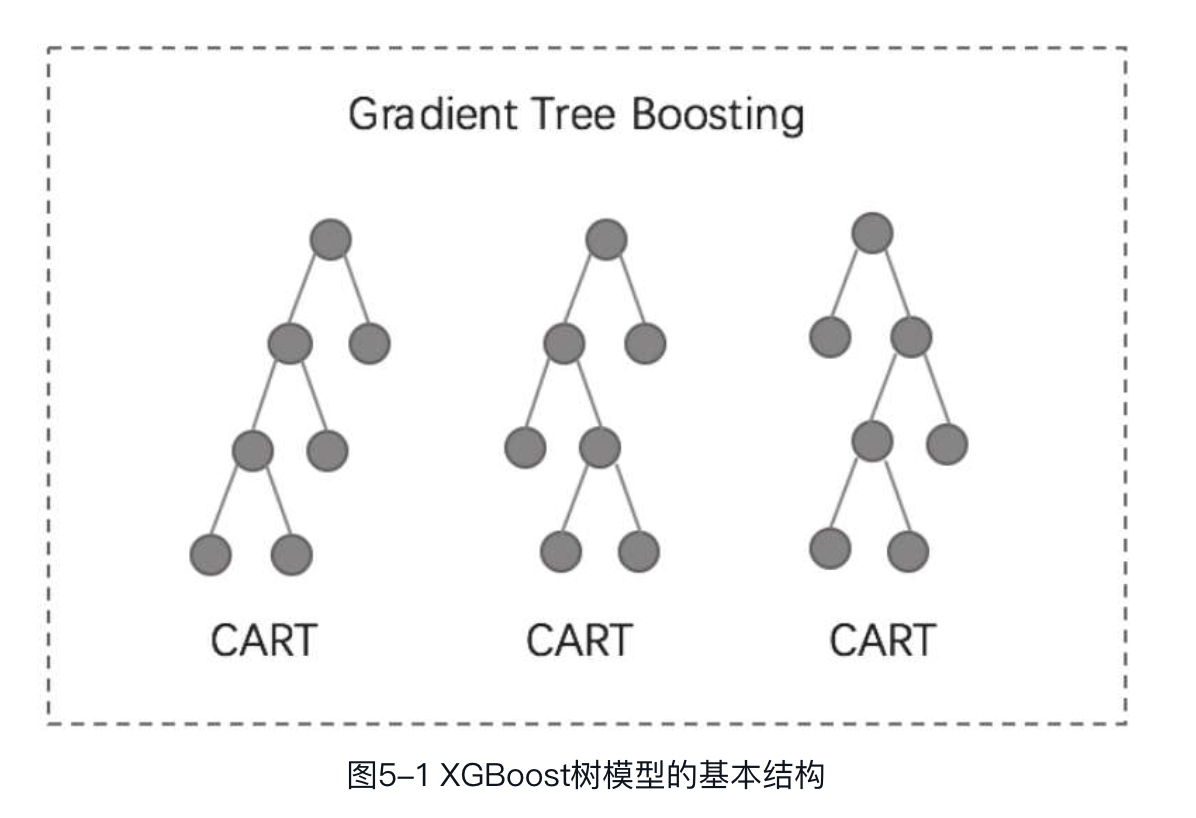
由前述内容可知,XGBoost树模型以CART作为子模型,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。其基本结构如图5-1所示。
XGBoost训练时的树生成算法与CART算法是一致的,即通过计算节点分裂后与分裂前是否产生“增益”来确定节点是否分裂,并且通过参数控制树的深度。当一棵树生成完毕之后,再对其进行剪枝,防止过拟合。第轮生成的树会学习真实值和轮模型的预测值的“残差”,使得模型预测结果逐步逼近真实值。以上便是XGBoost树模型的基本训练方法,下面对XGBoost中的各个环节进行详细介绍。
模型定义
XGBoost是一种通过Gradient Tree Boosting实现的有监督学习算法,可以解决分类、回归等机器学习问题。与Gradient Boosting类似,假设训练采用的数据集样本为,其中 ,表示具有维的特征向量,表示样本标签,模型包含棵树,则XGBoost模型的定义如下:
表示第棵决策树,决策树会对样本特征进行映射,使每个样本落在该树的某个叶子节点上。每个叶子节点均包含一个权重分数,作为落在此叶子节点的样本在本棵树的预测值。计算样本在每棵树的预测值(即)之和,并将其作为样本的最终预测值。
在训练模型之前,首先应有一个目标函数,这样模型训练时才有优化的方向,才知道怎样训练能得到更好的模型。XGBoost的目标函数定义如下:
目标函数Obj由两项组成:第一项为损失函数,用于评估模型预测值和真实值之间的损失或误差,该函数必须是可微分的凸函数(原因后续解释);第二项为正则化项,用来控制模型的复杂度,正则化项倾向于选择简单的模型,避免过拟合。正则化项的定义如下:
第一项通过叶子节点数及其系数控制树的复杂度,值越大则目标函数越大,从而抑制模型的复杂程度。第二项为L2正则项,用于控制叶子节点的权重分数。如果正则项设置为0,则目标函数为传统的Gradient TreeBoosting。
目标函数中,其中为迭代轮数,第轮模型为轮模型加上一个新的子模型。因此,模型的优化目标是找到最优的,使得目标函数Obj最小。
XGBoost中的Gradient Tree Boosting
Gradient Tree Boosting采用的方法是计算目标函数的负梯度,子模型以负梯度作为目标值进行训练,从而保证模型优化的方向。XGBoost也应用了Gradient Tree Boosing的思想,并在其基础上做了优化。
目标函数近似
由上节可知,我们需要找到一个最优的使目标函数最优,但对于公式中的目标函数,用传统的方法很难在欧氏空间中对其进行优化,因此,XGBoost采用了近似的方法解决这个问题。首先对目标函数进行改写:
式中,为第轮样本的模型预测值,为第轮训练的新子模型。
XGBoost引入泰勒公式来近似和简化目标函数。首先来看一下泰勒公式的定义。泰勒公式是一个用函数某点的信息描述其附近取值的公式,如果函数曲线足够平滑,则可通过某一点的各阶导数值构建一个多项式来近似表示函数在该点邻域的值。此处只取泰勒展开式的两阶,定义如下:
将看作,将看作,即可对XGBoost目标函数进行泰勒展开:
式中,为损失函数的一阶梯度统计;为二阶梯度统计:
因为常数项并不影响优化结果,因此可以进行进一步简化,去掉常数项,并将表达式带入公式,则转换为
可以看到,XGBoost的目标函数与传统Gradient Tree Boosting方法有所不同,XGBoost在一定程度上作了近似,并通过一阶梯度统计和二阶梯度统计来表示,这就要求XGBoost的损失函数需满足二次可微条件。
最优目标函数和叶子权重
在上式中,前半部分的为一个子模型,表示叶子节点的权重。为了更好地进行后续推导,我们需要将这两者进行统一。实质上是树模型,每个样本必定会被划分到该树模型的某一叶子节点上。因此,可以将上式改写为:
式中,为叶子节点的样本集,即落在叶子节点上的所有样本。将样本划分到叶子节点,计算得到该叶子节点的分数,因此当时,可以用代替。
可以看作一个自变量为、因变量为Obj 的一元二次函数,根据一元二次函数最值公式,对于固定的树结构,叶子节点的最优为:
叶子权重不仅取决于一阶、二阶统计信息,还和L2正则系数相关。此时L2正则起到缩小叶子节点权重的效果,减少其对整个预测结果的影响,从而防止过拟合。得到叶子节点的最优后,对于固定的树结构,可以求得最优的目标函数值,即
与 类似,最优目标函数Obj (s)同样会被L2正则系数影响,除此之外,Obj 还与控制树复杂度的有关,防止生成的决策树过于复杂,导致过拟合。
用表示,用表示,则有
利用评分函数即可对一个确定的树模型进行评价。在每一轮训练过程中,只要对所有候选的树模型分别计算评价得分,从中选出最优的即可。但候选树的个数是无穷的,我们不可能得到所有候选树的评价得分。XGBoost采用了贪心算法,即先从树的根节点开始,计算节点分裂后比分裂前目标函数值是否减少,假设当前分裂前节点为,则其对目标函数的贡献为
因为其只有一个节点,因此其对树复杂度的贡献是。而该节点分裂后,两个子节点的目标函数贡献为
则目标函数变化为
则最终可得到节点分裂的目标函数变化,公式如下:
式中,和表示当前节点的一阶、二阶梯度统计和;和分别表示由当前节点分裂出的左子节点和右子节点样本集的一阶梯度统计和;和分别为左子节点和右子节点样本集的二阶梯度统计和。是所有叶子节点目标函数值的和,一个节点分裂前后的两棵树,目标函数的区别只在于分裂节点分裂出两个新节点,其他节点均无变化,因此前后两棵树的目标函数之差为,即原节点目标函数贡献值减去分裂后的左子节点与右子节点的目标函数贡献值。在一个叶子节点的分裂过程中,计算所有特征及其切分点的,选取最大的特征及其切分点作为最优特征和最优切分点,使叶子节点按最优特征和最优切分点进行分裂。
在一棵新树生成后,XGBoost会对其进行剪枝,判断当前节点的收益是否小于定义的最小收益,若比最小收益小,则进行剪枝。剪枝完成之后,将新生成的树模型加入当前模型中,如下:
式中,系数为新生成树模型的缩减系数。
XGBoost也引入了缩减的思想,和之前介绍的缩减方法相同,在XGBoost的每一轮训练过程中,会在新的子模型前加一个参数,。参数η和学习率类似,可以限制每棵树对模型的影响,使得在模型优化过程中每次只前进一小步,逐步达到最优,有效避免过拟合。
通过上面的介绍,我们对XGBoost的Gradient Tree Boosting算法有了一个比较深入的了解,下面对该算法的训练过程进行简要概括。
- 每轮训练增加一个新的树模型。
- 在每轮训练开始,首先计算梯度统计:
-
根据贪心算法及梯度统计信息生成一棵完整树。
- 节点分裂通过如下公式评估,选择最优切分点。
- 最终树叶子节点的权重为
- 将新生成的树模型加入模型中:
- 节点分裂通过如下公式评估,选择最优切分点。
另外,XGBoost还支持行采样和列采样。行采样是对样本进行有放回的采样,即多次采样的集合中可能出现相同的样本。对这样的采样集合进行训练,每棵树训练的样本都不是全部样本,从而避免过拟合。列采样是从个特征中选取个特征(),用于对采样后的数据建立模型进行训练,而非采用所有特征。列采样最初被应用在随机森林算法中,XGBoost借鉴该方法,既能避免模型过拟合,也减少了计算量。根据实践经验,列采样比行采样更能有效避免模型过拟合。
切分点查找算法
XGBoost在每轮训练生成新的树模型时,首先计算所有特征在所有切分点分裂前后的,然后选取最大的特征及其切分点作为最优特征和最优切分点。XGBoost提供了多种最优特征和最优切分点的查找算法,统称为切分点查找算法。
精确贪心算法
XGBoost在生成新树的过程中,最基本的操作是节点分裂。节点分裂中最重要的环节是找到最优特征及最优切分点,然后将叶子节点按照最优特征和最优切分点进行分裂。选取最优特征和最优切分点的一种思路如下:首先找到所有的候选特征及所有的候选切分点,一一求得其,然后选择最大的特征及对应切分点作为最优特征和最优切分点。我们称此种方法为精确贪心算法。该算法是一种启发式算法,因为在节点分裂时只选择当前最优的分裂策略,而非全局最优的分裂策略。精确贪心算法的计算过程如图所示。

此算法会对所有的特征进行遍历。在遍历过程中,对于每个特征,都会将该节点包含的样本按该特征值进行排序,排序后按照
这种方式对左子节点和右子节点求梯度统计,因为、由该节点所有样本的、求和所得,因此当节点分裂条件由变为时,左子节点的特征统计变为和,右子节点的特征统计变为和,其中和是更新后的值,即在原来 和 和的基础上减去了和。最后,找到收益最大的特征和分裂点,进行分裂。此算法排序的时间复杂度为O ( nlogn),需要处理个特征,进行轮,因此算法的时间复杂度为。
基于直方图的近似算法
精确贪心算法在选择最优特征和最优切分点时是一种十分有效的方法。它计算了所有特征、所有切分点的收益,并从中选择了最优的,从而保证模型能比较好地拟合了训练数据。但是当数据不能完全加载到内存时,精确贪心算法会变得非常低效,算法在计算过程中需要不断在内存与磁盘之间进行数据交换,这是一个非常耗时的过程,并且在分布式环境中面临同样的问题。为了能够更高效地选择最优特征及切分点,XGBoost提出一种近似算法来解决该问题。
基于直方图的近似算法的主要思想是:对某一特征寻找最优切分点时,首先对该特征的所有切分点按分位数(如百分位)分桶,得到一个候选切分点集。特征的每一个切分点都可以分到对应的分桶;然后,对每个桶计算特征统计和得到直方图,为该桶内所有样本一阶特征统计之和,为该桶内所有样本二阶特征统计之和;最后,选择所有候选特征及候选切分点中对应桶的特征统计收益最大的作为最优特征及最优切分点。基于直方图的近似算法的计算过程如图所示。

近似算法也可以用在分布式树学习的环境中。其基本思想如下:首先将数据划分到多个worker节点上,在每轮训练过程中,worker计算本节点上数据梯度统计生成直方图,并将数据直方图传给主节点;主节点依据各个节点梯度统计数据对节点进行分裂生成新的一层;主节点将下一层信息发送给worker节点,worker节点再在新一层的基础上生成数据直方图;重复上述过程,直至决策树达到预定的深度后停止。
近似算法实现了两种候选切分点的构建策略:全局策略和本地策略。全局策略是在树构建的初始阶段对每一个特征确定一个候选切分点的集合,并在该树每一层的节点分裂中均采用此集合计算收益,整个过程候选切分点集合不改变。本地策略则是在每一次节点分裂时均重新确定候选切分点。全局策略需要更细的分桶才能达到本地策略的精确度,但全局策略在选取候选切分点集合时比本地策略更简单。在XGBoost系统中,用户可以根据需求自由选择使用精确贪心算法、近似算法全局策略、近似算法本地策略,算法均可通过参数进行配置。
快速直方图算法
除了基于直方图的近似算法之外,XGBoost还实现了另外一种基于直方图的算法—快速直方图算法。快速直方图算法实质上是在近似算法的基础上的优化。通过前面的学习可知,基于直方图的近似算法将每个切分点划分到对应的分桶中,构建直方图数据,然后根据直方图数据近似求解最优特征和最优切分点,从而减少内存与磁盘之间的数据交换,提高计算效率。虽然近似算法相比精确贪心算法在计算性能上提升了很多,但直方图聚合仍是构建树的过程中的一个主要计算瓶颈,因此XGBoost参考LightGBM实现了快速直方图算法。
基于直方图的近似算法也会通过将连续的特征分为离散的桶来加速训练,该方法是每次迭代生成一组新的桶(包括本地策略和全局策略),而快速直方图算法则是在多次迭代中重用之前的分桶,并以此为基础进行了一些优化。
- 数据预处理:连续型特征一般用浮点数表示,但在树分裂过程中一般仅会用到梯度统计信息,而算法仅仅对值进行相互比较,并不会用到值本身。因此,可以将浮点数数据均匀映射为整型数据,一般以直方图的索引作为映射值。因为CPU对整型运算的效率要比浮点型运算的效率高很多,因此算法性能相比之前可以提高很多,另外这样将输入特征的分布映射到均匀分布,通常也能提高划分的质量。
- 桶缓存:将上述数据结构进行缓存,在模型拟合过程中进行复用,提升计算效率。
- 直方图减法技巧:简化节点直方图的计算,直接取父节点和兄弟节点的差。
除了以上改进外,该算法还有一些其他亮点,如稀疏矩阵的有效表示,不但支持稀疏矩阵,而且对于混合稀疏+稠密矩阵也能够有效加速计算,并且可以扩展到XGBoost的其他现有功能。
前面介绍的XGBoost树构建算法均是以深度(depth-wise)的方式构建决策树,简单来讲,即建立新树时首先构建树的第一层节点,第一层节点构建完成之后再开始第二层。而快速直方图算法提供了另外一种树构建形式,即以损失函数收益变化(loss-guide)作为参考指标进行树的构建,不再拘泥于前层节点构建完成再进行下层节点的构建的形式,而是会选择最大收益增量的叶子节点进行分裂,从而获取到更多的收益,提高精确度。下图分别为depth-wise和loss-guide的分裂过程。
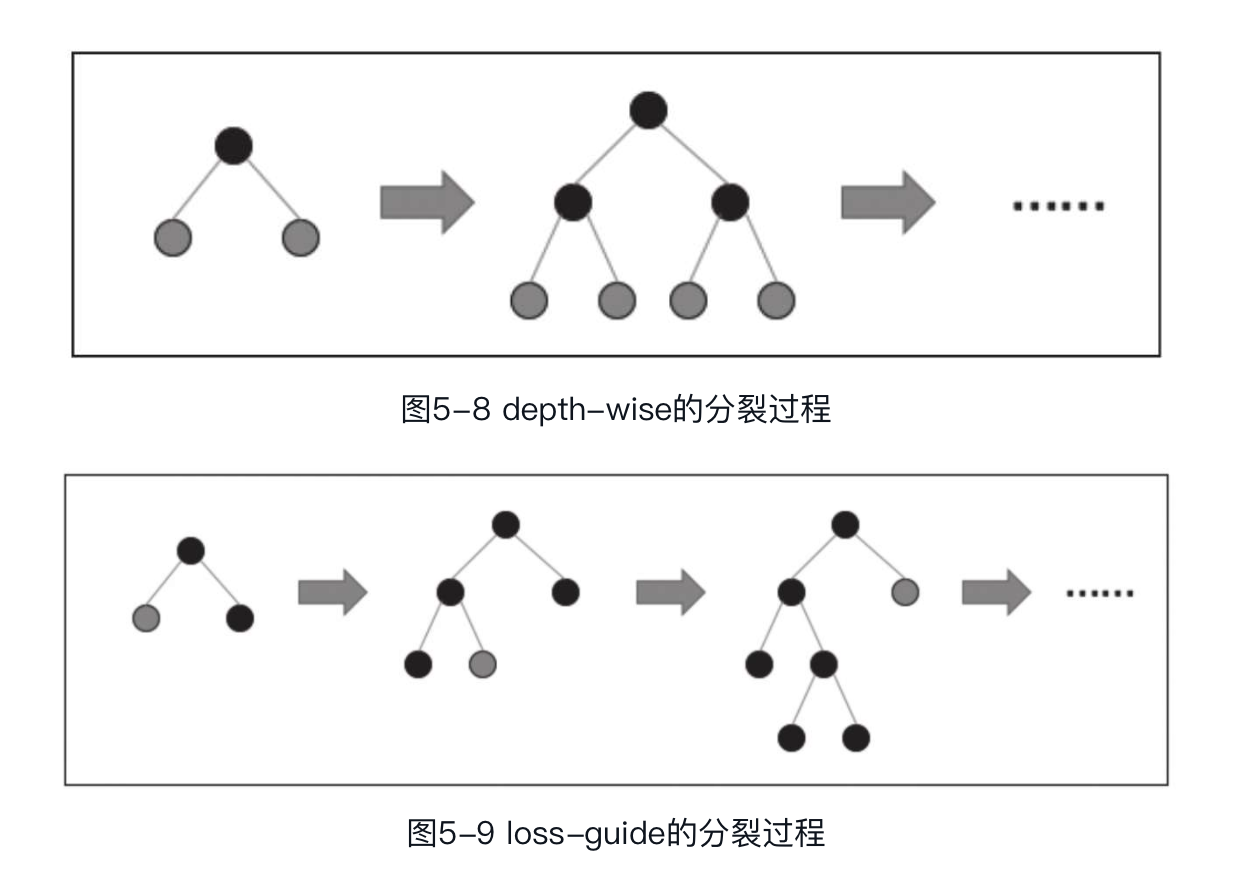
值得注意的是,loss-guide方法可以使模型更快收敛,但是同时带来了过拟合的风险,尤其是在数据量较少的情况下。因此,在使用loss-guide的过程中,读者可通过XGBoost中的max_leaves参数对分裂过程加以限制,防止过拟合。
用户将参数tree_method设置为hist,即可使用快速直方图算法查找切分点,grow_policy参数设置为depthwise和lossguide则分别表示采用depth-wise或loss-guide树构建方式。
加权分位数概要算法
上节介绍了通过近似算法来确定最优特征和最优切分点。近似算法对特征的所有切分点按分位数取值得到一个候选切分点集,每个候选切分点对应一个分桶。计算桶的梯度统计信息和收益,将收益最大的桶的候选切分点作为该特征的最优切分点。此算法的关键在于怎么得到候选切分点集。分位数的方法经常会被用作特征数据选择候选切分点的依据。针对此问题,XGBoost提出了带权值数据求分位数的近似算法——加权分位数概要算法,因为该算法并非本章介绍的重点,这里不详细介绍,感兴趣的读者可以参见相关资料。
稀疏感知切分点查找算法
在很多应用场景下,样本的特征是非常稀疏的。例如,在文本挖掘中,需要统计每篇文章中关键字出现的频率。关键字有几千个,但每篇文章一般只包含几十或者几百个关键字,那么这样产生的数据就会是一个稀疏数据。造成样本稀疏的原因很多,一方面来自于数据本身,如数据缺失。特征值为0的样本比较多等,另一方面在数据处理的过程中也有可能会产生稀疏数据,如对类别型特征进行独热编码处理。稀疏数据绝不是无用数据,因此我们需要一个算法能够快速、有效地处理稀疏数据。
XGBoost处理稀疏数据的方法是给每棵树指定一个默认方向,即当特征值缺失时,该样本会被划分到默认方向的节点上。
CART树的每个节点都会分裂为两个方向,选哪个方向作为默认方向呢?XGBoost借助一种稀疏敏感的算法对数据进行学习,从而选择出默认方向,这种算法称作稀疏感知切分点查找算法。稀疏感知切分点查找算法的计算过程如图所示。

该算法会遍历所有候选特征的所有候选切分点。对于每个切分点,算法首先将缺失值划分到右子节点,即计算划分到左子节点非缺失值的梯度统计,然后用总的梯度统计减去左子节点的梯度统计(相当于缺失值划到了右子节点中),计算收益,选出收益最大的;将缺失值划分到左子节点,重复上述步骤;最终选出收益最大的节点分裂及默认方向。此算法也适用于近似算法的情况,仅将非缺失值的样本统计划分到桶中即可。相较于不考虑稀疏数据的普通算法而言,稀疏感知切分点查找算法在每棵树的训练速度提高近50倍。
上述算法需要从左到右和从右到左两次扫描来完成缺省值默认方向的学习。XGBoost GPU版本采用了一种替代算法,即先求得缺失值梯度对总和,然后通过一次扫描完成上述操作。
排序学习
排序学习的常用方法:pointwise、pairwise和listwise。本节将会深入介绍pairwise方法的3种重要实现:RankNet、LambdaRank和LambdaMART。XGBoost的排序学习采用的是LambdaMART方法,而LambdaMART方法是RankNet和LambdaRank这两种方法的延伸与拓展,因此为了便于读者理解,本节首先介绍RankNet和LambdaRank,在此基础上介绍LambdaMART。
RankNet
RankNet是一种pairwise的排序方法,它将排序问题转换为比较对的排序概率问题,即比较排在前面的概率。RankNet提出了一种概率损失函数来学习排序模型,并通过排序模型对文档进行排序。这里的排序模型可以是任意对参数可微的模型,如增强树、神经网络等。
在监督学习过程中,每个样本都有一个标签值(用于指导模型的训练过程),模型训练完毕后模型对每个样本给出一个预测值,然后通过计算损失函数来对模型进行调整。RankNet中定义了两个概率来分别表示预测值和标签值,分别是预测相关性概率和真实相关性概率。首先来介绍一下RankNet如何得到预测相关性概率。一般训练数据是按查询划分的,对每个查询内部数据进行排序,RankNet通过评分函数对输入的特征向量进行评分。对于给定的查询,选择具有不同标签的文档和,并将其特征向量和输入给模型,分别计算得分和,通过函数将两得分映射为一个学习概率,即比更相关的预测概率为
式中,表示排在前面;参数确定函数形状,由此便得到了预测相关性概率。下面看一下如何定义真实相关性概率。对于给定的查询,每个文档对中的文档和均包含一个表征与该查询相关性的标签,如关于该查询的标签为非常相关,为不相关,很明显比更相关。因此,真实相关性概率定义为
式中,。如果比更相关,则; 如果比更相关,则; 若其标签值相等,则。
至此,我们已经得到RankNet相对关系的预测相关性概率和真实相关性概率。像其他pairwise方法一样,RankNet会评估所有文档对的相对关系,以错误的文档对最少作为优化目标。RankNet引入了概率的思想,优化目标转换为预测相关性概率与真实相关性概率的差距最小。RankNet采用交叉熵作为损失函数,公式如下:
将预测相关性概率公式和真实相关性概率公式代入损失函数,则有:
当时,有:
当时,有:
当时,有:
由此可以看出,两个排序不同的文档即使评估分值相同,损失函数也会对其进行惩罚。并且如果分数与实际排名不符,则损失函数为类线性函数;如果相符,则损失函数为0。对和分别求导:
以上梯度可以用于更新模型参数,RankNet采用随机梯度下降对参数进行更新。如下:
式中,为学习率。另外,可以求得损失函数增量为
,表明当沿负梯度方向变化时损失函数会越来越小。可针对上述过程进行优化以加速训练。由每个文档对均需要更新一次模型参数,转变为每个文档更新一次,即min-batch学习,极大加速了模型的学习过程。由前述可知,对于输入样本,模型参数的梯度为:
将以表示可得:
其中
对于一个查询,排序不同的和,用表示索引对的集合,每个索引对只包含一个,即和等价。为了方便,假设包含的索引对均满足,即。因为RankNet从概率分布中学习输出概率,并不需要每个文档都标记标签,只需通过收集文档对的相对顺序关系即可,然后通过相对关系对参数进行更新,计算:
此处引入了,对应文档,一个文档对应一个。是由两个项求和得到的,首先找到所有与组成文档对的和所有与组成文档对的。其中前一项和作为增量,后一项和作为减量。计算公式如下:
公式的第二项将也用表示,意义是一样的。下面通过一个例子进行说明。假设有3个文档,其真实相关性满足,集合包含3个索引对{{1,2},{1,3},{2,3}},则
我们可以将看作文档在迭代更新中移动的方向和幅度。因为是通过所有包含的文档对计算得到的,所以可以认为文档的移动方向和幅度取决于所有与其组成文档对的其他文档。经过改写后,由之前每个文档对进行一次参数更新转为每个查询所有文档进行一次参数更新,即mini-batch学习,极大加速了模型的学习过程。
LambdaRank
由前述内容可知,RankNet主要针对文档对相对顺序关系的错误数量进行优化,而并不区分不同文档在优化时的权重。在重点关注头部排序的场景下,效果并不理想,如以NDCG作为评估指标,此时模型拟合应更关注于排序靠前的文档,但RankNet的优化目标与实际的优化目标是有偏差的,因此不能取得很好的效果,RankNet没办法以NDCG这些指标作为优化目标进行迭代。以图5-11为例,其表示一个给定查询的二分类有序文档集,圆形表示与查询相关的文档,正方形表示与查询不相关的文档。对于RankNet而言,其损失函数cost通过文档对的错误数量来衡量。在图5-11a中,cost为6(通过排序错误对数量计算得到);在图5-11b(经过一轮优化后)中,将排序最靠前的相关文档下调2个位置,将底部的相关文档上调3个位置,此时cost为5。但是对于像NDCG等更注重头部排序的指标,这并不是其想要的结果。图5-11b中的左边箭头代表RankNet的梯度方向和幅度,右边箭头代表真正需要的梯度方向和幅度,即更关注靠前位置的文档的提升。
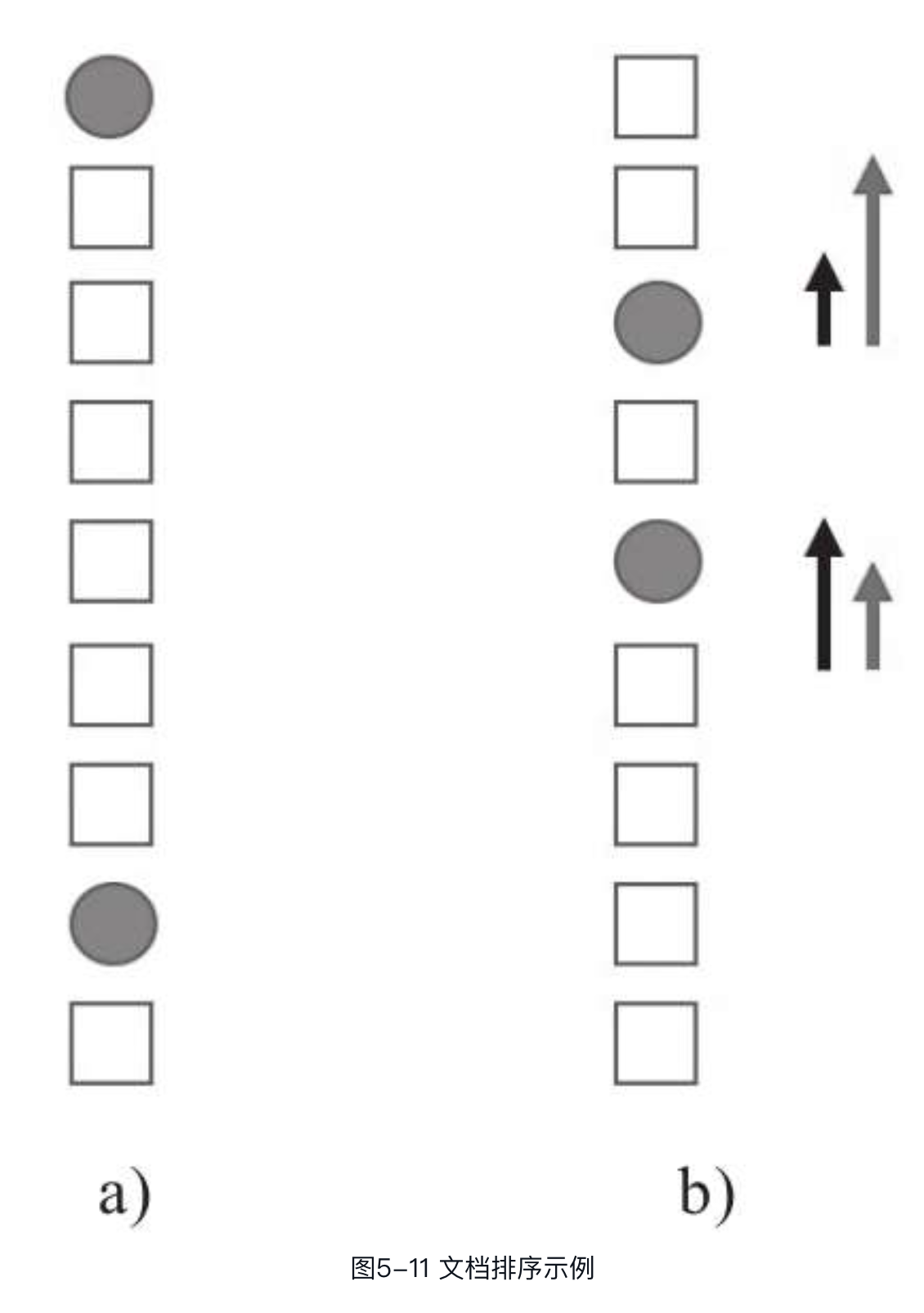
LambdaRank针对上述问题提出了一种经验算法,它不再像RankNet一样通过定义损失函数再求梯度的方式处理排序问题,而是直接定义梯度,即Lambda梯度,这样便可以解决大部分评估指标带来的问题。在训练模型时,我们不需要知道损失函数计算的代价本身,而只需要代价的梯度即可,在前面讨论的即为这样的梯度。可以将形象地看作物理学中的力(一种潜在函数的梯度),假设为对应的,则:如果比更相关,则将被推下个单位,而则会被方向相反、大小相等的力推上个单位;如果比更相关,则被推上个单位,被推下个单位。
LambdaRank在RankNet的基础上引入了评价指标。这里以NDCG为例,假设将交换位置且其他文档的位置不变,NDCG指标变化大小为,对式进行修改,乘以,如下:
此处假设包含的索引对均满足,即。损失函数的梯度代表了文档下一次的移动方向和幅度,引入评估指标之后,可以使其更关注排序靠前的文档,避免下调排序靠前文档的情况。另外,对于其他评估指标如MAP、MRR等也可采用此方法,只需将替换为相应指标即可。实验表明,LambdaRank引入评估指标的方式对模型的提升效果非常显著。
LambdaMART
有了RankNet和LambdaRank的基础,下面来学习另外一种排序算法——LambdaMART,XGBoost的排序学习框架是基于LambdaMART算法实现的。LambdaMART是一种将LambdaRank和MART结合的排序算法。MART全称为Multiple Additive Regression Trees,即前面介绍过的Gradient Tree Boosting模型,模型输出为一组回归树输出的线性组合。MART定义了一种增强树的框架,针对不同的问题可定义不同的梯度,而LambdaRank便提供了这样的梯度定义方法。因此,可以简单地认为LambdaMART是将LambdaRank定义的梯度应用到了MART的增强树框架中。下面来看LambdaMART算法。假设决策树数量为N,训练样本数为m,每棵树叶子数量为L,学习率为η。LambdaMART算法的计算过程如算法5-6所示。

由算法5-6可知,LambdaMART首先通过初始模型对每个样本进行预测,若无初始模型则置0;然后进行模型迭代,在每一轮迭代中,求得每个样本的和对上一轮模型预测值的一阶导;接着在数据集的基础上创建决策树,通过牛顿法计算叶子节点权重;最后将新树加入模型中,进行下一轮迭代。
XGBoost排序学习的实现原理基本和LambdaMART的类似,是LambdaMART的一种变形,区别仅在于XGBoost对目标函数进行了泰勒展开,通过一阶梯度和二阶梯度计算分裂节点的收益和叶子节点的权重。
DART
由前述内容可知,XGBoost是多棵决策树共同决策,即所有决策树的结果累加起来作为最终结果。这种方式在多种机器学习应用场景中取得了不错的效果,但是也存在一些问题。在这种情况下,首先加入模型的决策树对模型的贡献是非常大的,但是较为靠后的树则只影响少部分样本,而对大部分样本的贡献则微乎其微。这容易导致模型过拟合并且对少数初始生成的树过度敏感。XGBoost采用缩减方法为每棵树设定一个很小的学习率,这在一定程度上缓解了此问题,但问题仍然存在。MART(Multiple Additive Regkession Trees)中亦是如此。2015年,Rasmi等人借鉴深度神经网络中的dropout技术(将神经网络单元按照一定概率暂时从网络中丢弃,从而达到防止过拟合的效果),将其应用到了增强树中,这种技术称为DART。DART在一些场景下取得了不错的效果,因此XGBoost后续也引入了该项技术,作为可选项供用户使用。
MART在每一轮迭代中会计算当前模型的损失函数的负梯度,然后通过训练一个新的回归树去拟合它,计算出步长(学习率)后更新模型。DART成功将dropout技术引入MART,在训练过程中暂时丢弃部分已生成的树,使模型中树的贡献更加均衡,防止模型过拟合。总结来说,DART在MART的基础上做了两处优化。
第一处优化是在计算梯度时,仅仅从现有模型的所有树中随机选择一个子集。假设在经过n轮迭代后当前模型为,,为第轮训练得到的树。DART首先随机在现有模型中选择一个树的子集,通过该树子集创建模型,对于模型,计算损失函数的负梯度,并通过一个新的回归树去拟合该负梯度。
第二处优化是对新增加的树进行标准化。因为新训练的树会尽力缩小模型和理想模型的差距,而丢弃树集也会缩小该差距,两者如果共同作用会导致模型超出拟合目标。为了解决该问题,DART会对新训练的树进行标准化。假设模型中丢弃树的数量为,则新树相当于丢弃树集中的每棵树的倍,因此DART会对新树乘以一个的系数,以保证其和丢弃树集中的树在相同数量级。然后新树和丢弃树按比例进行缩放,确保丢弃树和新树的组合效果与单独丢弃树的效果是一致的,最后将新树加入模型中。
假设为需要训练的树的总数量:

其中,为样本特征,为损失函数,表示模型作用于样本特征损失函数的负梯度。DART可以看作通过控制丢弃树数量来实现的一种正则。一种极端情况是当没有树被丢弃时,DART等同于MART;另一种极端情况是丢弃了当前模型的所有树,此时DART相当于随机森林。可见,DART其实是介于MART和随机森林之间的一种权衡实现。关于丢弃树的选择方法有很多种,DART采用的方法是通过一个丢弃概率来选择已存在于模型的树是否丢弃。若通过上述方法没有树被丢弃,则随机选择一棵树丢弃,保证每轮至少有一棵树被丢弃。
XGBoost也实现了DART,设置参数为booster,参数值为dart即可。DART在XGBoost中随机选择丢弃树(参数为sample_type)的方法有两种。
- Uniform:该方法会随机选择相应的树丢弃,为默认方法。
- Weighted:该方法会依据权重比例选择相应的树丢弃。
假设在轮有棵树被丢弃,定义为丢弃树集的叶子节点值,其中为被丢弃树的集合。为新树的叶子节点值,则XGBoost目标函数可以改写为
和是超调的(overshooting),因此需要对其进行标准化:
在XGBoost中,DART标准化的方法(参数为normalize_type)有两种。
一种为新树和丢弃树集中的每一棵树具有相同的权重(参数为tree):
另一种为新树和丢弃树集具有相同的权重(参数为forest):
另外还有一些其他的参数,例如:rate_drop用来指定dropout的概率,范围为[0.0,1.0];skip_drop用来指定跳过dropout的概率,如果dropout被跳过,则采用gbtree方式构建新树,skip_drop的取值范围为[0,0,1.0]。
引入DART也会带来一些问题,例如,DART在训练中引入了随机性,随机选择丢弃树会导致预测缓存失效,因此DART训练时会比gbtree慢,另外提前结束训练的功能也会变得不稳定。
系统优化
基于列存储数据块的并行学习
XGBoost在构建树的过程中需对候选特征值进行排序,而排序往往十分花费时间和计算资源,为优化排序阶段的性能XGBoost提出了基于列存储数据块的并行学习方法。对于减少排序开销最直接的想法是对数据进行预处理,提前进行排序,然后在每轮训练时均复用此数据。XGBoost正是采用了此思路,提出了一种特殊的内存单元来存储数据,我们将该内存单元称为块(在本节中,块均代表此内存单元)。每个块中的数据都是以CSC(Compressed Sparse Column)列压缩格式进行存储的。
CSC是一种稀疏矩阵的存储格式,它通过压缩的手段减少矩阵的存储空间。将特征数据存储为CSC格式,能大大减少特征缺失值所占的存储空间,节省资源。在介绍CSC格式之前,首先介绍一下CSR(Compressed SparseRow,行压缩格式)的实现原理。CSR格式由3类数据表达:行偏移、列索引、数值。列索引和数值均存储的是非零元素的列索引和数值,行偏移表示在每一行第一个元素在数值中的偏移位置。现有矩阵如下:

用CSR格式表示则为
行偏移:[0 2 4 7 9]
列索引:[0 1 1 2 0 2 3 1 3]
数值:[1 7 2 8 5 3 9 6 4]
可见,数值中存储的是非零元素的值,列索引中是这些非零元素所在的列号。行偏移的生成过程如下:
第1行元素1的行偏移为0;第2行元素0的行偏移为2,因为在数值中第一行非零元素有2个(1、7);第3行元素5的行偏移为4,因为数值中第一行和第二行的非零元素总共有4个(1、7、2、8)。依次类推,最后会在行偏移加上矩阵的元素(非零元素)个数,上述矩阵中是9。
CSC与CSR的不同只在于CSC是按列压缩的,仍以上述矩阵为例,用CSC表示为
列偏移:[0 2 5 7 9]
行索引:[0 2 0 1 3 1 2 2 3]
数值:[1 5 7 2 6 8 3 9 4]
CSC列压缩格式,也通过3类数据来表达:列偏移、行索引和数值。类似的,数值即矩阵中非零元素的值;行索引表示数的元素中值对应的行号;列偏移表示每一列的第一个元素在数值中的偏移量。由切分点查找算法可知,不同特征之间是独立的,可以并行处理,而CSC正是按列进行存储的,因此可以提升列数据的读取效率,从而加速算法计算过程。另外,其列存储的特性使得列采样变得更加便捷和高效。
块中每个特征的特征值都是有序的,在训练之前对特征值进行一次排序,之后每轮训练均可复用此有序数据,而不需要再重新排序,大大提高了训练过程中的计算效率,如图所示。
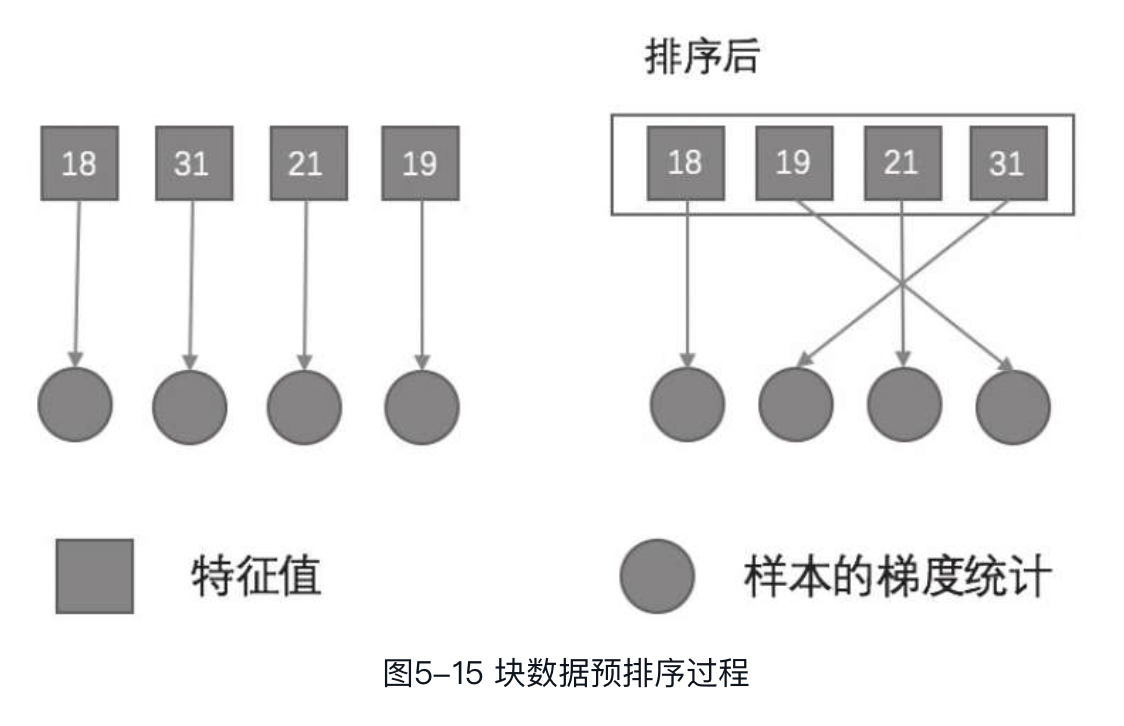
上图展现了排序前和排序后的特征值和样本梯度统计之间的关系。了解了块的存储结构和实现原理后,下面来看一下其如何在算法中发挥作用。对于精确贪心算法,将数据存储在单个块中,然后对已排序的数据进行扫描,通过切分点查找算法选出最优切分点。该过程可以并行进行,因为每棵树在训练过程中,各个叶子节点的分裂是相互不影响的。因此,一棵树的所有叶子节点可以同时通过切分点查找算法选取最优切分点,这样就大大提高了训练效率,减少了训练时间。这样对于块只需进行一次扫描即可计算出所有叶子节点的统计信息。而对于近似算法,同样可以通过上述方法进行训练。这种情况下可以同时应用多个块,每个块存储样本集的一个子集,可以将不同的块分布到不同机器或者存储于外存。通过预先排序的数据块,分位数计算只需进行一次线性扫描即可。我们知道近似算法有两种策略:全局策略和本地策略。本地策略中候选特征在每个分支的计算要比采用全局策略频繁得多,因此通过块结构效果会更加明显。针对直方图聚合的二分查找算法变为一个线性时间的合并算法。例如,在近似算法中,将数据按分位数分桶,对于某个特征值属于哪个桶,我们需要进行二分查找,通过值找到其对应的桶。而现在因为特征值是有序的,我们只需要按段进行合并即可得到相应的分桶。
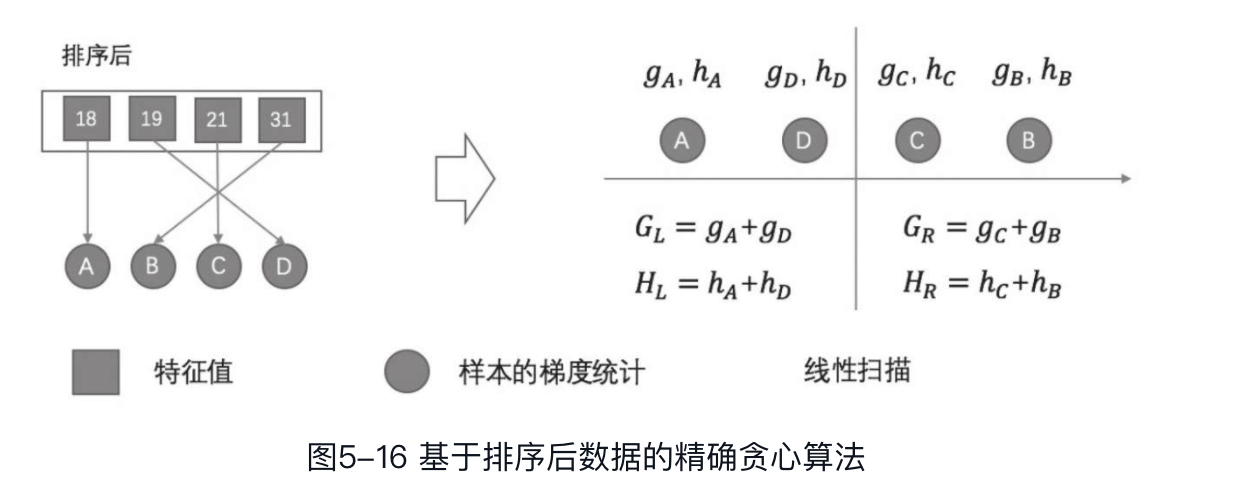
下面对上述算法进行时间复杂度分析,从时间复杂度的角度来理解其对算法效率的提升。假设为树的最大深度,为树的数量,为样本数,代表训练集中非缺失值的数量。对于精确贪心算法,初始空间感知算法(即不采用块结构)的时间复杂度为,树与树之间的训练是串行的,每棵树的所有叶子节点进行分裂时是并行的,因此时间复杂度为O (Kd)。而对于特征值进行排序的时间复杂度为,因此总时间复杂度为。基于块结构的算法的时间复杂度为,其中是进行一次预处理数据的代价。由此可以看到,基于块结构的算法的时间复杂度可以少一个额外的因子,这在很大的情况下效果是非常明显的。对于近似算法,通过二分查找的初始算法的时间复杂度为,其中q为数据集中候选特征值的数量,或者可以理解为桶的数量,通常取值为32~100,因此log因子仍然带来了额外的开销。通过块结构,时间复杂度可降为,其中B是每个块中样本的最大数量,我们仍然可以节省带来的额外计算代价。
缓存感知访问
通过块结构优化切分点查找算法的计算复杂度。但新算法同时带来了新问题,因为数据是按特征值排序的,此时通过索引获取梯度统计时,会导致非连续内存访问的问题。通常的做法是通过非连续内存fetch操作直接读写,但这种方法在此场景下会有较多的梯度统计数据不能被CPU缓存命中,大大降低了算法的计算速度。
对于精确贪心算法,XGBoost通过一种缓存感知预取算法解决上述问题。XGBoost会给每个线程分配一个内部缓存,获取的梯度统计数据均放入该缓存中,通过mini-batch的方式聚合在一起。上述操作在XGBoost中的实现也很简单,当遍历某特征计算切分收益时,初始化一个缓存大小为Kbuffer的数组,并将待处理的Kbuffer个特征值对应的梯度统计信息存入该数组,在计算时直接调用该缓存数组即可。另外,样本所在节点等信息也会被缓存,实现原理类似。这种预取的方法将直接读写依赖变为一个更长的依赖,当行数量比较大时可有效减少运行时的额外开销。
对于近似算法,XGBoost通过选择一个合适的块大小来解决缓存命中率低的问题。我们定义块大小为一个块中实例数量的最大值,因为其反映了梯度统计的缓存存储代价。如果块比较小,则每个线程的负载较小,但是会导致不能充分并行;如果块比较大,则会因为梯度统计无法进入CPU的缓存而导致缓存没有命中。因此,我们需要平衡这两个因素,选择一个合适的块大小。
外存块计算
基于块结构、缓存感知等算法可以有效提高模型训练的效率,解决缓存命中率低的问题。但在模型训练中还有另外一部分代价不容忽视,即无法完全加载到内存的数据每次在进行计算时需先由磁盘读取到内存。由于磁盘读取相比CPU计算及内存读取慢很多,因此这一过程会带来很大的时间开销。为了使模型训练更加高效,我们将数据划分为多个块结构。在计算过程中,XGBoost通过一个独立的线程将块结构加载到内存缓存,即计算线程和数据读取线程分离,从而实现了数据读取和计算并行处理,提高了计算效率。然而,这种方法虽然实现了读取与计算并行,但仍然没有解决数据读取时间代价过大的问题。为了解决这个问题,提高磁盘I/O的吞吐量就变得十分必要了,XGBoost采用两种方法实现。
块压缩
XGBoost首先采用的技术是对块结构进行压缩。因为块结构是列存储的,因此很容易应用压缩算法,压缩率也会较高。压缩后的块结构存储于磁盘,当块结构被加载到内存时,采用一个独立的线程对其解压。这样可以使磁盘读取和解压两个阶段按流水线的方式运行,实现一定程度的并行。我们采用通用压缩算法对特征值进行压缩。用块头部的索引和块内的偏移量来表示行索引,经实验验证,该算法对大部分数据集均有效。
块分片
XGBoost采用的第二项技术是对块结构进行分片,将分片后的块结构分别存储到不同的磁盘上。在每一块磁盘上单独指定一个预取线程,将数据从硬盘读到内存缓存中,训练的线程再交替从每个缓存中读取数据。这样多个磁盘同时读取有助于提高磁盘I/O的吞吐量,减少数据读取时间。
模型选择与优化
偏差与方差
模型的泛化能力用来表征模型对未知数据的预测能力,它可以为最终选择高质量模型提供指导,因此模型泛化能力的评估十分重要。本节将从偏差-方差分解(bias-variance decomposition)的角度来对模型泛化能力进行解释,通过优化偏差和方差来更好地拟合数据,得到更为精确的模型。
偏差描述的是模型期望(或平均)预测值与真实值之间的差异,方差描述的是预测值作为随机变量的离散程度。可以认为模型不止一次重复整个构建过程,每次收集新数据拟合新的模型,由于数据集的随机性,最终的模型会有一系列预测值,偏差可衡量平均预测值与真实值之间的差异,而方差则可衡量这些预测值之间的偏离程度。
假设待预测的变量为,其对应的自变量为(训练样本),服从,其中为噪声,服从。通过算法学习可以得到一个模型来近似进行预测,对于给定的变量值,为真实值,为其预测值。假设模型采用均方误差进行评估,则在点的整体预测值和真实值的均方误差为
在模型学习过程中,需尽量使最小化,从而使得模型的准确性更高。由上述内容可知,偏差描述的是模型期望预测值与真实值之间的差异,其数学表示如下(为后续表示方便,此处采用的是偏差的平方):
方差的数学表示如下:
下面对均方误差公式进行分解,则可得到
Noise
可以看出,均方误差的计算公式可以由偏差、方差来表示,其中第三项为噪声,其刻画了模型期望泛化误差的下界,决定了学习问题本身的难度。噪声是不可避免的,因此只需要在偏差和方差两方面对进行优化。
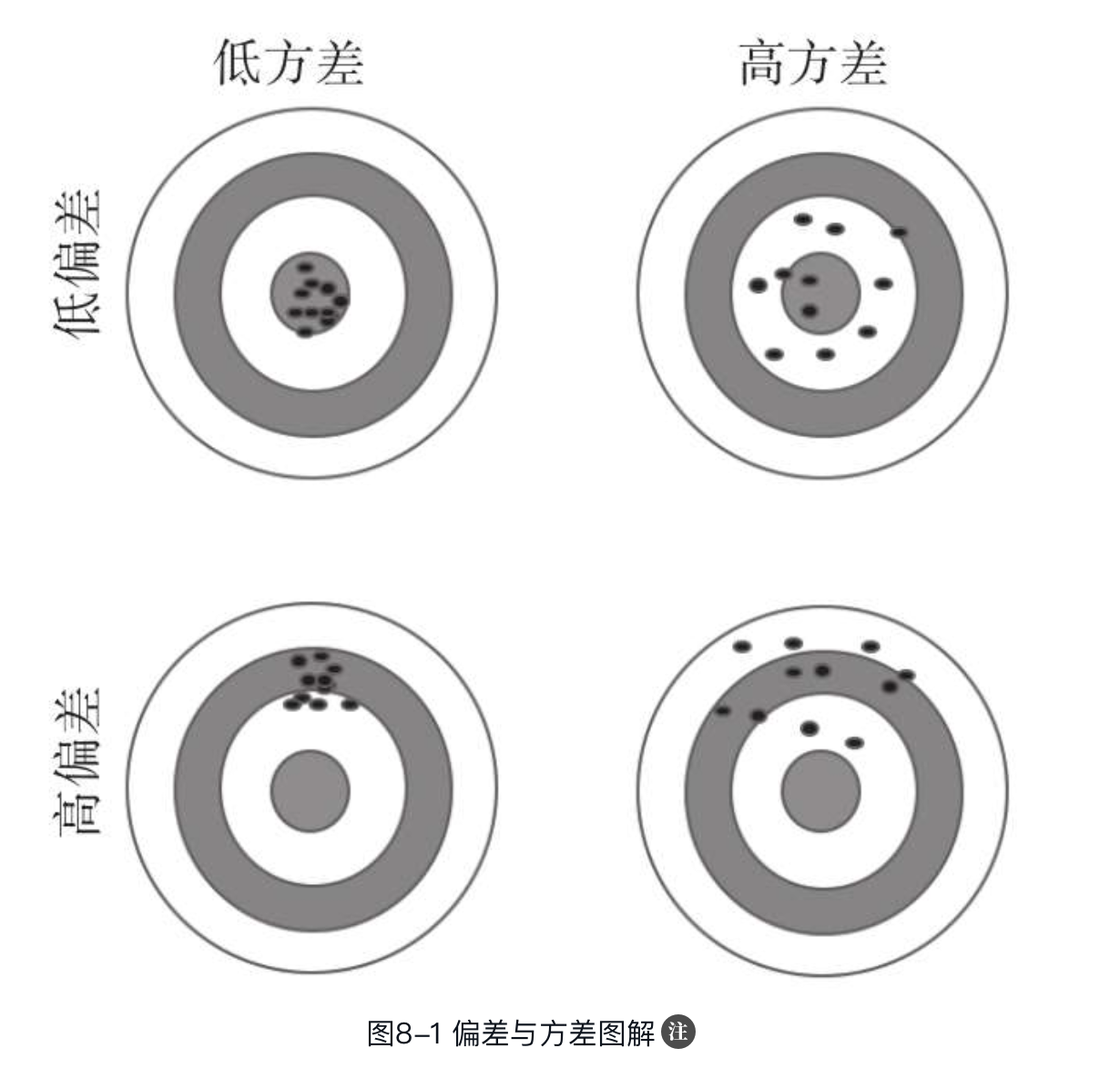
由图可知,低偏差、低方差的模型会次次命中靶心,预测结果较好,这是比较理想的结果。低偏差、高方差的命中点分散,很多并没有命中靶心,但其平均值会命中靶心。而高偏差、低方差的大部分命中点比较聚合,但是偏离靶心。高偏差、高方差是最糟糕的情况,命中点分散且偏离靶心。由此可知,低偏差、低方差是我们模型优化的目标,但是低偏差、低方差往往是不可兼得的,降低模型偏差会在一定程度上提高方差,降低方差则会导致偏差变大。
从根本上来说,处理偏差与方差的问题就是处理欠拟合与过拟合的问题。当我们通过有限的训练样本去拟合一个模型来模拟理想模型时,为了降低模型的预测误差,越来越多的参数会被加入模型,使模型变得越来越复杂。这样,模型在训练样本的偏差减小了,但方差变大了,导致模型的泛化能力较差,对于新的预测样本而言,预测结果会变得糟糕,即模型出现了过拟合。为了避免过拟合,我们减少模型复杂度,并增加一些正则项以限制模型在训练过程中对训练数据的过度依赖,提高模型的稳定性,降低方差。与此同时,模型偏差也会增大,若模型拟合不充分,则会导致模型预测能力下降,出现欠拟合。因此,我们需要在两者之间找到一个平衡,即偏差-方差权衡(bias-variance tradeoff)。在模型最佳的平衡位置上,随着模型复杂度的变化,偏差的增加和方差的减少相等。如果超过了该最佳平衡点,模型即会出现过拟合,若未达到该平衡点,则说明模型欠拟合。偏差、方差和总误差的变化关系如图所示。
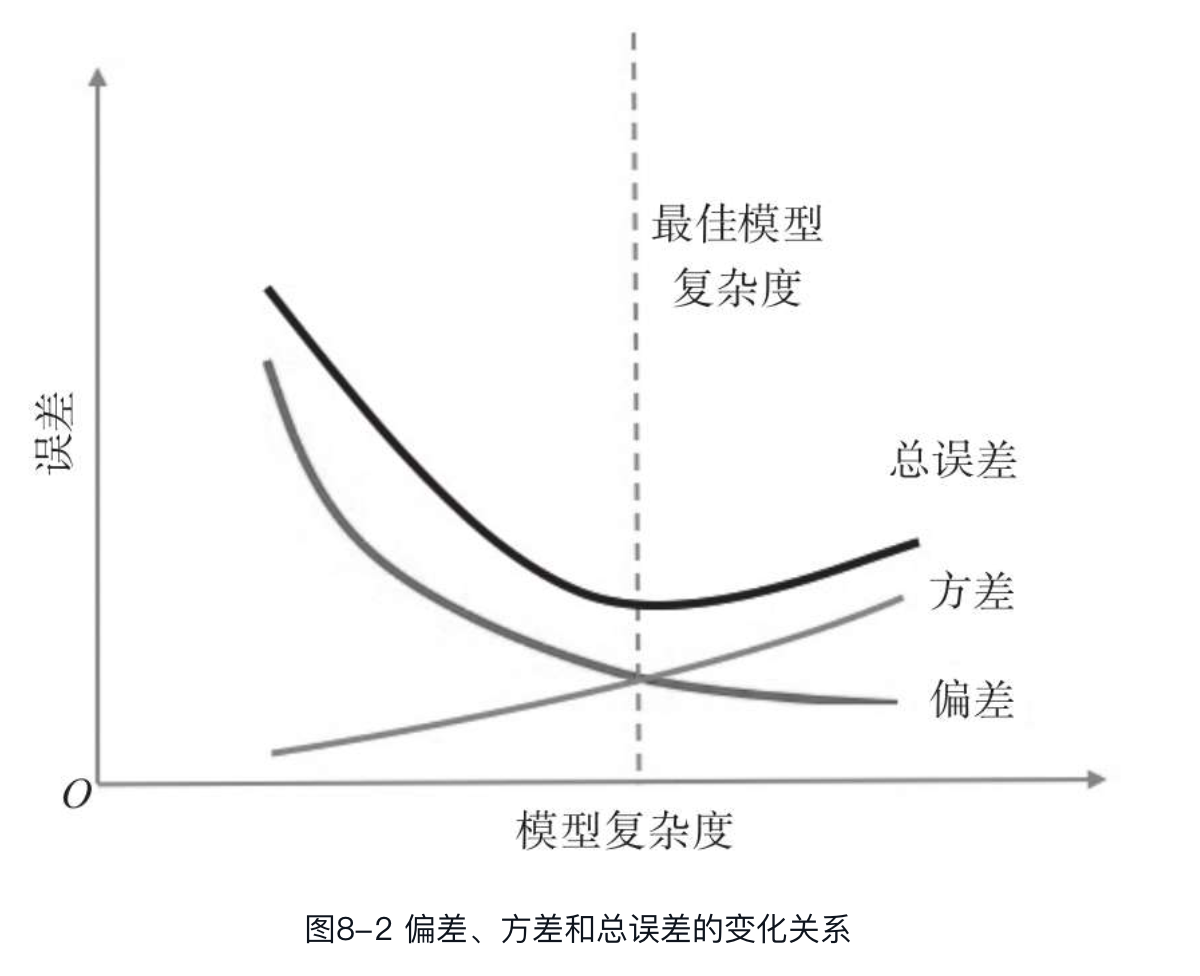
模型选择
简而言之,模型选择是面对不同复杂度的模型,选择其中性能最好的一个。通过偏差-方差介绍可知,模型复杂度对最终获得较优的预测模型是十分重要的。
此处模型选择要和模型评估区分开,模型选择是估计不同模型的性能,以便选择最佳模型,而模型评估是对最后选择的模型进行性能评估。针对模型选择和模型评估两个阶段特性,目前比较普遍的做法是将数据集分为3部分处理,分别为训练集、验证集和测试集。

训练集用于拟合模型,得到不同模型和训练误差。验证集用于估计模型选择的预测误差,选出最好的模型。测试集用于模型评估,通过相应的评估指标对选择的模型进行评估。3个数据集是相互独立的。由此,我们可以得出模型选择的完整流程:首先通过训练集训练模型,然后在验证集上对训练的模型进行验证,获取预测误差,最后选择预测误差小的模型作为最终的模型。
上述只是模型选择的完整步骤,但在很多场景下,我们可能并没有一个独立的验证集进行验证,可获取的数据仅有一个训练集。此时,一般可以从训练集数据中划分部分数据形成验证集,其中比较具有代表性的方法有交叉验证(cross validation)、自助法(Bootstrap)等,下面详细介绍交叉验证和自助法。
交叉验证
交叉验证是一种用来验证模型性能的统计分析方法,用于评估机器学习算法的预测误差,分析泛化能力,是目前最常采用的评估预测误差的方法。它的基本思想是对数据集进行划分,一部分作为训练集,另一部分作为验证集。利用训练集拟合模型;利用验证集验证模型,评估预测误差。交叉验证按类型不同可分为K-折交叉验证(K-foldcross-validation)、leave-one-out交叉验证(LOOCV)等,下面主要以K-折交叉验证为例进行介绍,其他类型均为K-折交叉验证中的特殊情况。
K-折交叉验证首先会将数据集随机分为K份,然后选择第i份作为验证集,另外的K-1份作为训练集;对每一份数据子集进行遍历,将其作为验证集,其他K-1份作为训练集用于训练模型,这样最终可以得到K个模型和K个预测误差结果;对K个误差结果求平均值,即可得到最后的交叉验证值(CV值);计算模型空间中不同复杂度模型的CV值,最后选择CV值最优的模型作为最终模型。
由交叉验证的定义可知,划分的份数K取值不同,对平均预测误差的估计效果也不同。如何选择K值主要是偏差、方差和计算效率三者的权衡。
当K取值较大时,如K=N,则交叉验证为leave-one-out交叉验证,其中N为数据集中的样本数,每个样本会单独作为一次验证集,其余的N-1个样本作为训练集进行训练,最终会得到N个模型。此时,交叉验证得到的CV值是平均预测误差的近似无偏估计,但由于N个训练集十分相似且每次评估只评估一个样本,使得每个验证集上的预测误差较大,因此CV估计的方差较大。另外,需要训练的模型数量和数据集样本数量相同,当样本数量很多时,所需计算量是巨大的。
当K取值较小时,如K=2,此时数据集中的一半数据作为训练集,另外一半作为验证集,新生成的训练集和原来的训练集相比变化较大,因此可能会导致两个训练集之间产生较大差异,因此训练出的模型具有较大的偏差。但因为验证集具有充足的样本,若其与训练集在数据分布上无较大不同,则CV估计的方差一般会比较小。另外,因为只需要训练两个模型,所需计算量较小,执行效率高。
由此可知,当K取值较大时,CV值对平均预测误差的估计偏差较小,但方差和计算量较大;当K取值较小时,CV值方差和模型计算量较小,但对平均预测误差的估计偏差较大。交叉验证对平均预测误差的估计和数据量相关,若样本数据较少,则由交叉验证对数据进行切分后的数据集会更小,容易导致较大的估计偏差,所以一般而言,若样本数据量充足,5折交叉验证是一个比较好的选择,其对平均预测误差的估计已经足够,而且计算量也不会很大。
了解了交叉验证的原理后,下面通过一个示例来介绍如何使用交叉验证,以scikit-learn中的交叉验证为例,代码如下:
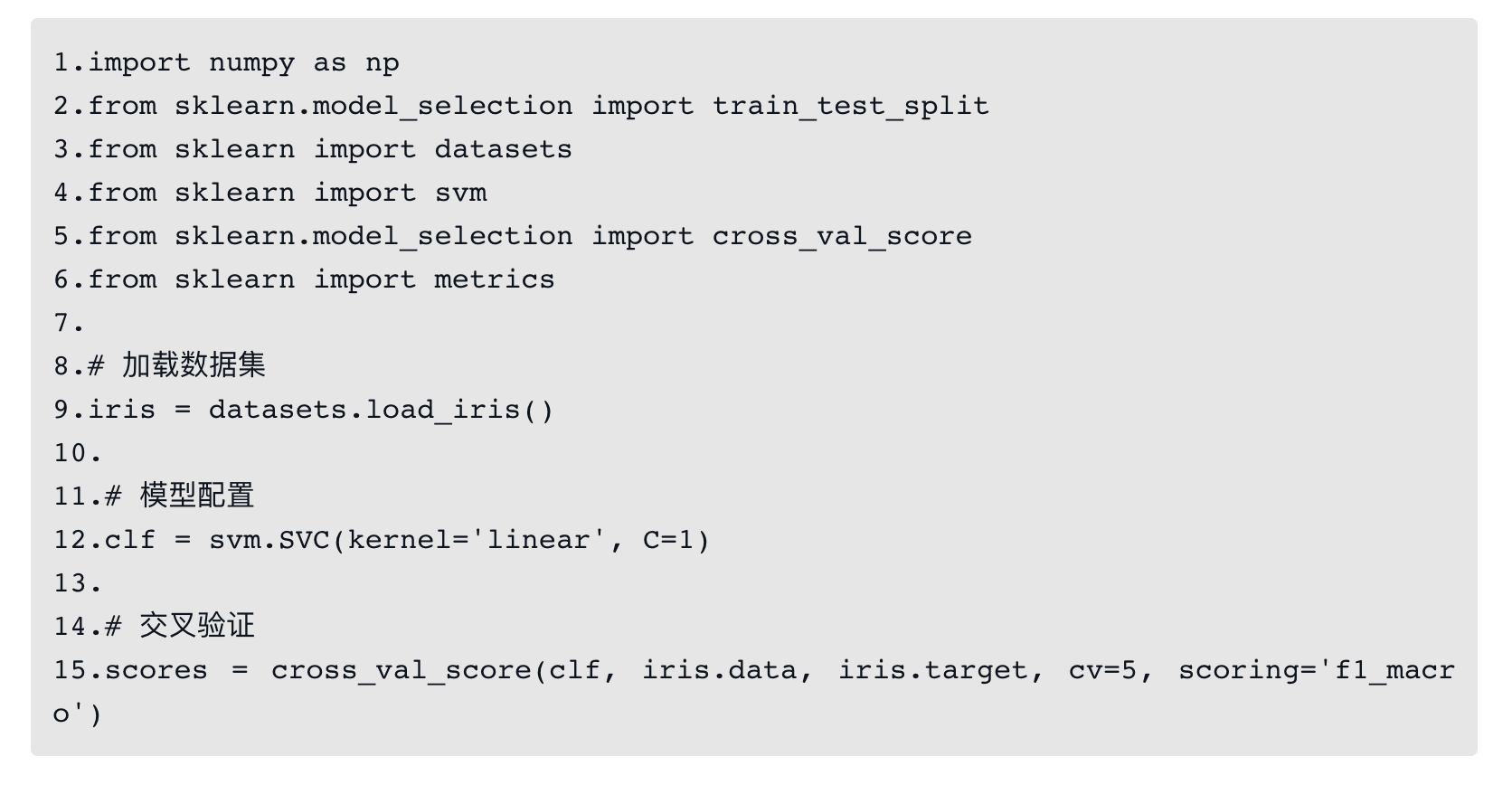
上述代码的逻辑非常简单,首先加载数据集,然后配置模型参数(SVM模型),最后调用cross_val_score函数进行交叉验证。其中cv=5表示将数据集划分为5份,即K=5。其默认采用的是KFold或StratifiedKFold策略,也可指定其他交叉验证策略,如LeaveOneOut、ShuffleSplit等。scoring代表评估指标,这里为f1_macro,也可以选择其他指标。将交叉验证后的分数scores输出,结果如下:

对结果中代表5次不同分割的评估分数求平均值,便可得到平均预测误差的估计。另外,通过cross_validate函数可实现同时指定多个评估指标。代码示例如下:

其中,评估指标指定了precision_macro和recall_macro两个指标,return_train_score指定是否返回训练集的评估结果。cross_validate返回结果是一个dict数据结构,如果只有一个评估指标,则交叉验证结果中的key为

若包含多个评估指标,则交叉验证结果中的key为

将上述示例中的交叉验证结果scores输出,显示如下:

Bootstrap
Bootstrap是一个评估统计准确性的通用工具。Bootstrap于1993年由Efron提出,在统计学领域得到广泛应用。Breiman于1994年提出Bagging方法,将Bootstrap方法应用于机器学习中,其实际是一种模型组合方法,用于获取更准确且稳定的分类结果。Bootstrap算法的思想比较简单,其算法过程如下。
假设现有数据集表示训练集,其中。首先对训练数据进行有放回地随机抽样,抽取后的数据集大小和原数据集相同,重复次,得到个Bootstrap数据集。然后用这m个Bootstrap数据集分别训练模型,并通过评估指标进行评估。对于分类问题,通过Bootstrap训练多个分类模型,然后对这个分类模型的新样本进行预测,最后通过某种投票机制得到样本最终的预测分类,这就是Bagging的实现原理。
那么如何通过Bootstrap进行模型选择呢?一种思路是,个模型均在原数据集上进行评估,即模型对每个样本都会进行评估,这样可以得到个模型分别对应的评估误差,然后求平均值作为最终拟合平均预测误差的值。这种方法看似合理,但其实存在一个比较大的缺陷。因为大部分样本既是训练样本又是验证样本,而不像交叉验证中训练集与验证集相互独立,数据重合比较严重,所以拟合的误差与训练误差较为接近,而与平均预测误差有较大的偏差。因此,仅仅采用以上思路进行模型选择显然不是一种有效的方法。
因为每个Bootstrap数据集都是通过N次重复有放回的采样获得的,因此样本至少被抽到一次的概率为:
式中,为训练样本;B为Bootstrap数据集。可知,一般情况下,总会有一些样本没有被抽到Bootstrap数据集中,那么这部分没有被抽中的数据集便可作为验证集来进行平均预测误差的估计。随机森林中的OOB(Out OfBag)就是采用这种思路,区别是随机森林对未采样样本投票后再预计平均预测误差,而Bootstrap直接对未采样样本通过相应模型进行预测,再求平均,求得平均预测误差的估计。那在极端情况下,如果有样本被所有Bootstrap数据集抽中,那么如何进行处理?直接跳过该样本就可以了,在实际应用中,大一点很容易避免这种情况的出现。
超参数优化
模型参数一般分为两类:一类是可以通过学习获得的参数,另一类是在开始学习过程之前设定的参数,而没办法通过训练得到的,这类参数就是超参数。比如,决策树的数量和深度、学习率及神经网络中的隐藏层数等,这些都是比较常见的超参数。通常在模型选择的过程中,需要通过调整超参数改变模型复杂度,选出其中最优的超参数组合,使模型具有更好的学习性能和效果。
超参数优化的目的是提高模型在独立数据集上的性能。通常使用交叉验证来评估不同超参数下模型泛化性能,因此,一般采用超参数空间中交叉验证值最优的超参数作为最优超参数,模型构建的参数基本都可以采用此方式进行优化。下面以scikit-learn为例对超参数优化方法进行介绍。
在scikit-learn中,搜索的参数一般包含如下几部分:
estimator(分类器等);- 参数空间;
- 一种搜索或采样方法,以获得候选参数;
- 一种交叉验证策略;
- 一个评分函数。
其中,参数estimator为需要进行超参数优化的模型;参数空间为需要优化的超参数及其值域;scikit-learn提供了两种获得候选参数的搜索方法;网格搜索(GridSearchCV)和随机搜索(RandomizedSearchCV);其交叉验证策略和评分函数均可自行指定。下面详细介绍scikit-learn中网格搜索和随机搜索的实现原理。
网格搜索
网格搜索是超参数优化中比较传统的方法,它通过手工指定超参数空间中的一个子集进行详尽搜索,以达到参数优化的目的。网格搜索会对给定超参数的所有组合进行穷举,试图找到一组最优超参数。值得注意的是,一般情况下,参数中只有一小部分对模型预测或计算性能产生较大影响,其他参数保留为默认值即可。由于某些模型的参数空间可能包括实数或无界值空间,因此在网络搜索前可能需要手工指定参数边界和离散化。
在scikit-learn中,GridSearchCV从参数param_grid指定的参数网格中穷举获得最优参数来实现网格搜索。param_grid格式如下:

param_grid指定了两个待搜索的网格:一个网格为线性内核,C值为[1,10,100,1000];第二个网格为RBF内核,需要搜索C值与gamma值的所有组合。
下面通过一个示例来介绍GridSearchCV的使用方法。该示例通过GridSearchCV对一个分类器进行超参数优化,然后通过优化阶段未使用的验证集进行评估。示例代码如下:

示例采用了乳腺癌数据集,该数据集是一个二分类问题,因此采用AUC作为评估函数,模型采用的是随机森林。可以看到,上述网格搜索的实现代码还是比较简单的,主要包括定义搜索参数范围,初始化GridSearchCV,拟合训练集(即进行网格搜索)等过程,最终得到最优参数组合。代码运行结果如图所示。

另外,除了上述最终调优结果外,还可以输出调优过程中不同参数组合下评估指标的均值和标准差,实现代码如下:


得到最优参数组合后,通过最优参数组合拟合的模型对测试集进行预测,代码如下:

网格搜索比较适合于小数据集,因为对于大数据集,一旦参数组合较多,网格搜索方法便很难得出结果。目前有一些研究者尝试通过坐标下降法来解决大数据集调参的问题。该算法实际是一种贪心算法,每次贪心地选取对整体模型性能影响最大的参数,在该参数上进行调优,使模型在该参数上最优化,然后选取下一个影响最大的参数,以此类推,直到所有参数调整完毕。因为参数对模型的影响是动态变化的,因此在每轮选取坐标的过程中,都会在每个坐标的方向上进行一次线性搜索(line search)。在选取参数时,也需确保该参数对整体模型性能的提升是单调的或近似单调的,即最终选取的参数对模型整体性能有正向影响,且这种影响并非偶然,避免训练过程中的随机性对参数选择产生的干扰。
随机搜索
虽然网格搜索是目前超参数优化中使用最广泛的方法,但是其他一些搜索方法也有其独特的优势。scikit-learn还实现了另外一种搜索方法——随机搜索RandomizedSearchCV。
RandomizedSearchCV实现了参数空间中的随机搜索,其中参数的取值是通过某种概率分布抽取的,这个概率分布描述了参数所有取值的可能性。随机搜索相比网格搜索有如下两个优势:
- 相比于整体的参数空间,可以选择较少的参数组合数量;
- 添加不影响模型性能的参数不会降低效率。
指定参数的采样范围和分布可以通过字典完成,这和网格搜索类似。另外,计算预算用参数n_iter来指定,此处预算指的是总共采样多少参数组合或迭代多少次。对于每个参数,既可以使用值的分布,也可以指定一个离散的取值列表(离散列表将会被均匀采样)。

示例中的C值和gamma值均服从指数分布,可以看到,示例引用了scipy.stats模块来表示指数分布。scipy.stats模块包含许多采样参数常用的分布,如指数分布(expon)、gamma分布等。原则上,该模块可以传递任何函数,只需提供一个rvs(random variate sample)函数返回采样值,且连续调用rvs函数产生的样本是独立同分布的。

可以看到,随机搜索与网格搜索的调用方法类似,唯一不同之处在于参数范围可采用值的分布,并且需要指定随机搜索迭代轮数。

随机搜索也可以输出调优过程中各指标的变化,实现代码和网格搜索是一样的.


从上述搜索过程结果可以看出,随机搜索不再遍历每个参数组合。下面采用最优参数组合训练得到的模型对测试集进行预测:

可以看到,随机搜索最终得到的结果要比网格搜索差一些,但这并不能说明随机搜索就没有使用价值,例如,随机搜索在运行时间上相比网格搜索是大大降低的,在某些训练代价较大的应用场景下,随机搜索可能比网格搜索更为适用。
贝叶斯优化
前面我们学习了利用网格搜索和随机搜索两种方法进行超参数调优。网格搜索本质上是在人工置顶参数范围后,对该范围内的各种参数组合进行穷举,遍历所有参数组合,将得到的最优性能模型对应的参数作为最优参数。该方法的优点是算法较为简单,在所给参数范围内一定可以找到最大值或者最小值,但其也存在一些问题。比如,当遍历的参数组合较多时,该方法耗时较长,需要花费大量计算资源。另外,当使用网格搜索时,为了节省时间一般会采用粒度先粗后细的方式,这样有可能出现如下情况:当目标函数是非凸函数时,粗粒度调参可能只得到一个局部最优值,此时精细化调参时只是在这个局部最优值附近进行调优。而随机搜索虽然不遍历所有的参数组合,只是在搜索范围内随机抽取,相比网格搜索可以节省计算时间,提高运行效率,但该方法也有一定的缺陷,即每一次采样都是相互独立的,并不会利用先验知识来得到下一次的采样参数,而本节介绍的贝叶斯优化方法可以较好地解决上述问题。
贝叶斯优化是利用贝叶斯技术先对目标函数的先验分布模型进行假设,然后通过样本获取相关信息,不断优化该模型,最终得到目标函数的后验分布模型。超参数调优是一个黑盒优化问题,即事先并不知道优化目标函数的具体形式,只能通过参数样本获取输入和输出,最终得到目标函数最优的超参数。例如,在超参数调优问题中,事先并不知道超参数和最终指标结果之间关系函数的具体形式,但可以通过每次尝试不同的参数组合得到不同的结果。现假设需要优化的目标函数为,有限样本集合为,则该优化问题的数学表示形式为
优化目标是在候选集中选择一个样本使得最大。在超参数优化问题中,为不同的参数组合,的值为最终评估指标的得分。
对目标函数先假设一个先验分布模型,一般常采用的假设是其满足高斯过程。高斯过程可以看作多元高斯分布在无限维的广义扩展(如时间),其任何有限维度的组合仍满足高斯分布,实践证明,高斯过程可以灵活地对目标函数进行建模,而超参数优化的过程便可假设为一个高斯过程。
在得到先验分布函数后,下面即可开始通过样本点采样对模型进行修正。理论上,采样样本点越多,模型越精确,但是通常情况下得到一个样本点的成本比较高,例如,尝试一个参数组合到最终得到评估结果会花费较大的时间成本,因此需要在有限样本的情况下选择那些能为模型提供更多信息的样本点。贝叶斯优化中定义了一个采集函数(acquisition function)来确定下一个采样点。采集函数实际是在探索(exploration)和开发(exploitation)之间权衡。探索表示在未采样的区域进行采样,可以避免持续在某些局部最优区域采样,陷入局部最优的状况。开发是在目前后验分布的基础上选取当前认为的全局最优解进行采样。采集函数有许多实现方法,如PI、EI、GP-UCB等。
通过采集函数确定下一个采样点后,就可以进行一次实验或观察(即通过得到),在超参数调优的场景中,即尝试一个参数组合,得到评估结果。若该采样点结果已经达到任务要求,则算法终止;若未达到任务要求,则将该采样点加入当前已观察的样本点集中,然后对当前的高斯过程模型进行更新。
下图所示为贝叶斯优化过程的示例,该图展示了经过几轮迭代后目标函数的高斯过程近似。其中,实线表示高斯过程近似模型;虚线表示真实的目标函数,该函数在实际优化过程中是未知的;实线两侧的阴影区域表示置信区间,小的实心点表示已观察的样本点。另外,图下方还展示了采集函数,可以看到每一轮迭代的新样本点的选取均为采集函数最大值处,通过新样本点对GP模型进行更新,可以使其更接近真实目标函数。
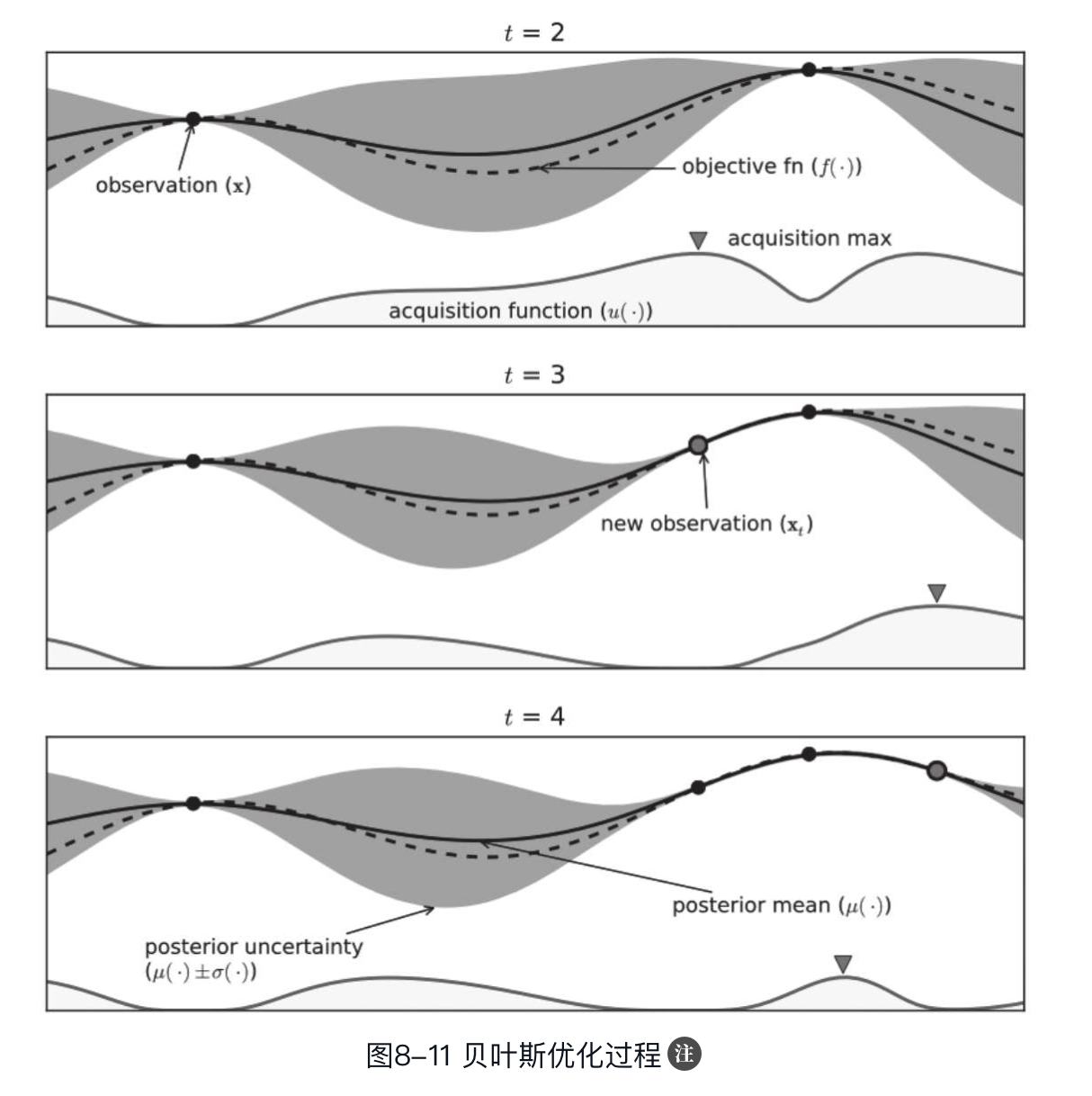
综上,可以将贝叶斯优化算法流程总结如下:

XGBoost超参数优化
通过前面的学习可知,构建一个初步的XGBoost模型是很容易的,但在实际应用中,仅仅构建一个初步的模型是不够的,还需要对模型进行优化,提升模型效果。XGBoost中有许多参数,为了提升模型性能,超参数优化是必需的。针对不同的应用,很难说应该调整哪些参数,参数的理想值是多少,不同的问题可能情况并不一样,本节将会介绍一些XGBoost的通用调参技巧,并结合示例进行说明,使读者更好地理解XGBoost超参数优化。
XGBoost参数介绍
在介绍XGBoost超参数优化之前,首先介绍一下XGBoost包含的参数。XGBoost中的参数分为通用参数、Treebooster参数和学习任务参数3种类型。
- 通用参数:宏观函数控制,主要包括类型指定、并发线程数等。
Tree Booster参数:控制每一步的Booster。- 学习任务参数:决定了学习的场景。不同的学习场景使用不同的参数,如回归、排序等。
XGBoost这3类参数分别从宏观、Tree Booster、学习场景的角度对XGBoost训练过程进行控制,下面对XGBoost的常用参数进行介绍。
通用参数
通用参数从宏观的角度对XGBoost进行函数控制。
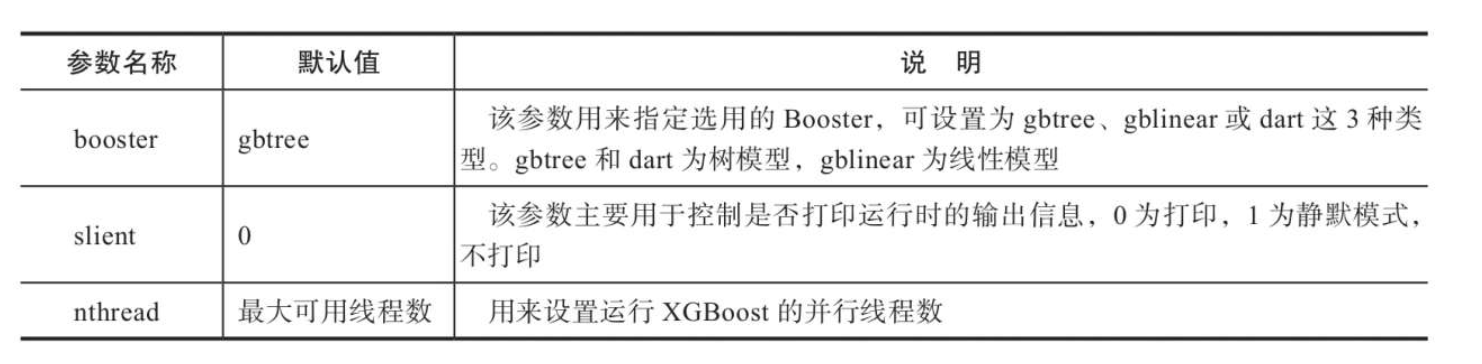
另外,还有两个参数由XGboost自动设置,无须用户手动设置。
num_pbuffer:预测缓存的大小,通常设置为训练样本的数量。该缓存用于存储上一轮boosting的预测结果。num_feature:进行boosting时的特征维度,一般设置为特征的最大维度。
Tree Booster参数
Booster参数包括Tree Booster、Linear Booster等多种,此处主要介绍Tree Booster。Tree Booster参数是树模型训练时采用的学习参数.
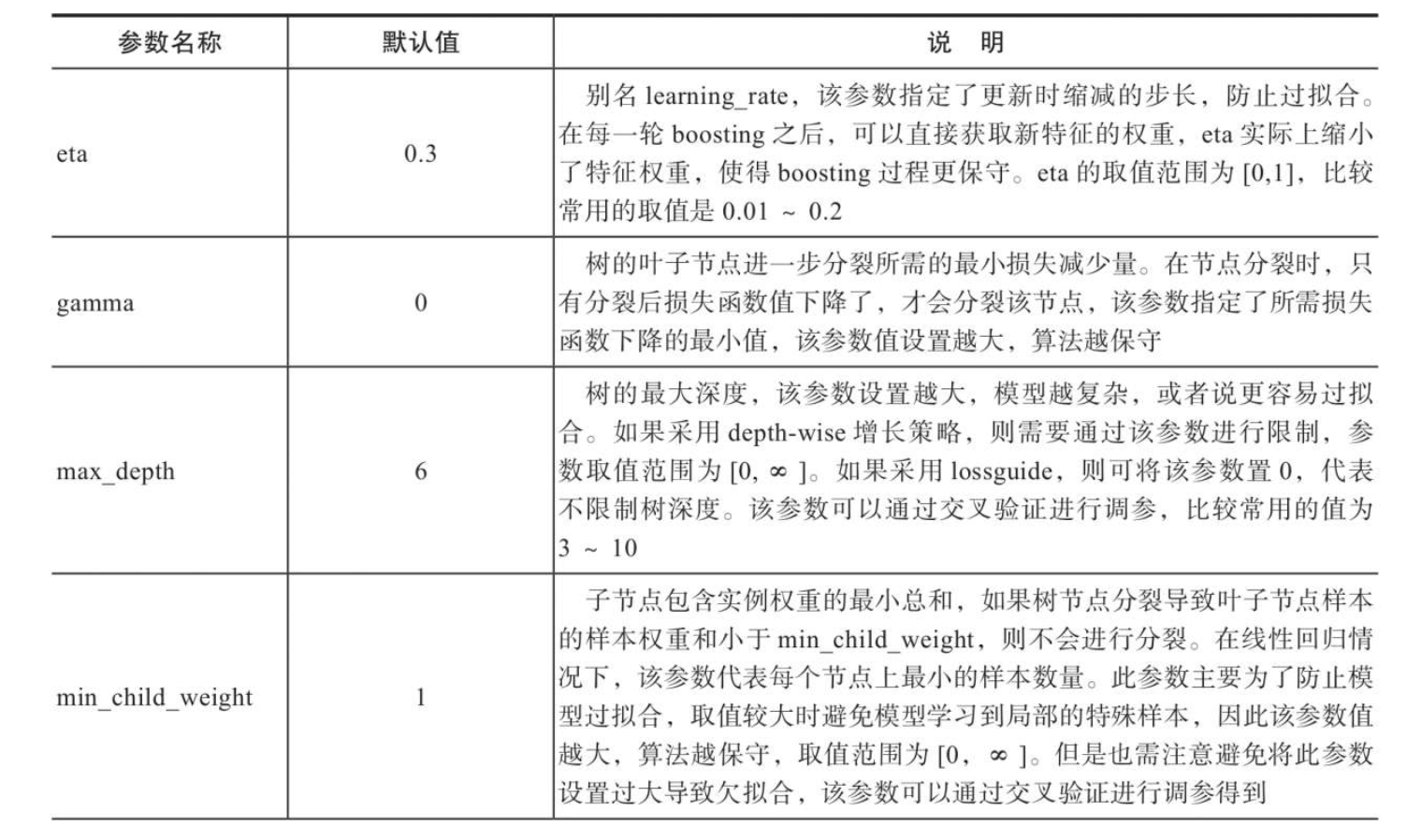
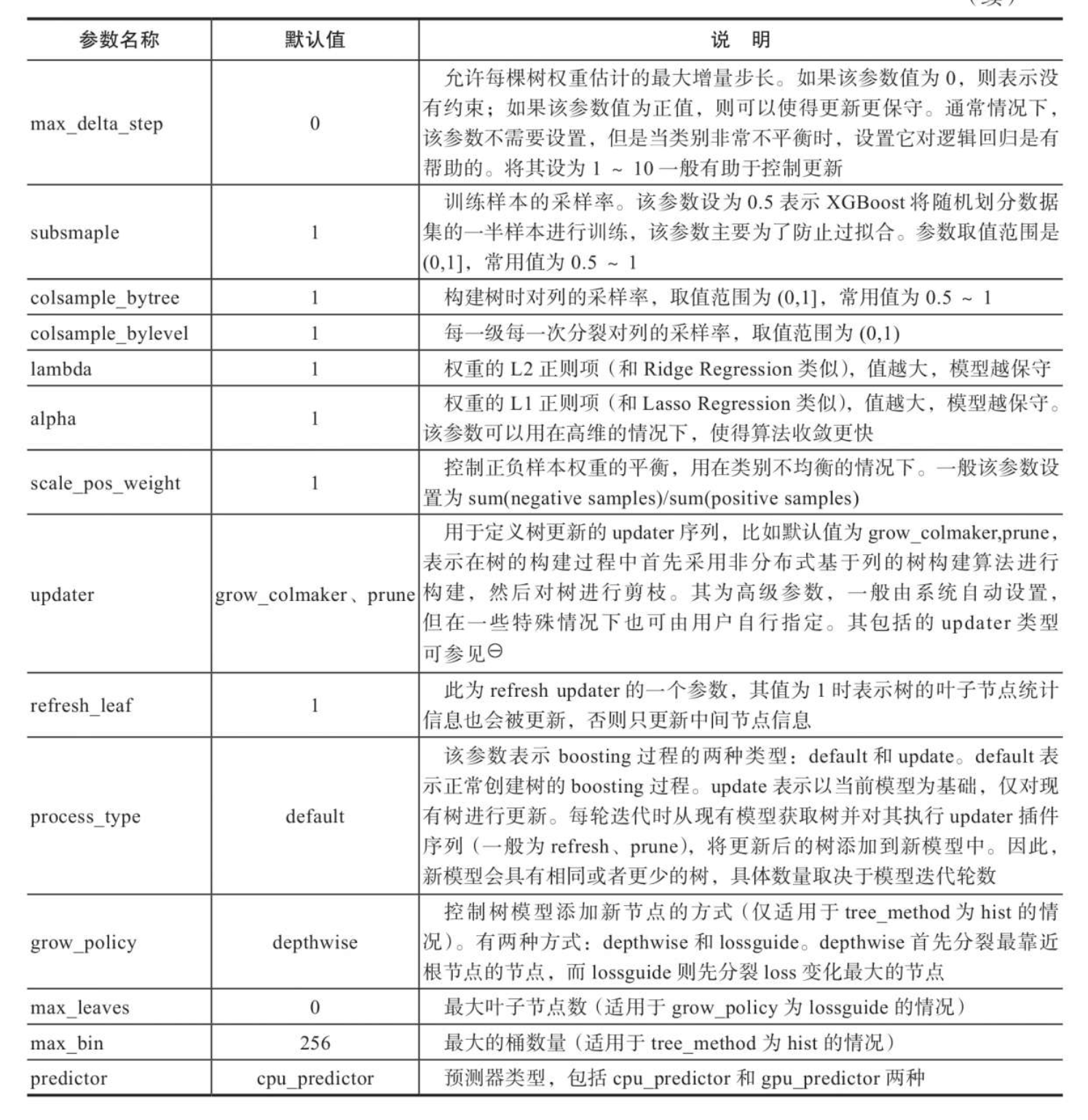
Tree Booster参数是树模型训练过程中非常重要的一类参数,其中学习率参数eta、行采样参数subsample、列采样参数colsample_bytree,以及L1、L2正则项权重alpha和lambda等参数在防止模型过拟合方面起到了关键作用,而更新器updater、boosting过程参数process_type、节点分裂策略grow_policy等为模型训练提供了更加丰富的选择,以适应不同场景的应用,达到更好的模型效果。
学习任务参数
学习任务参数主要是机器学习任务相关的参数,主要包括目标函数、评估指标等参数.
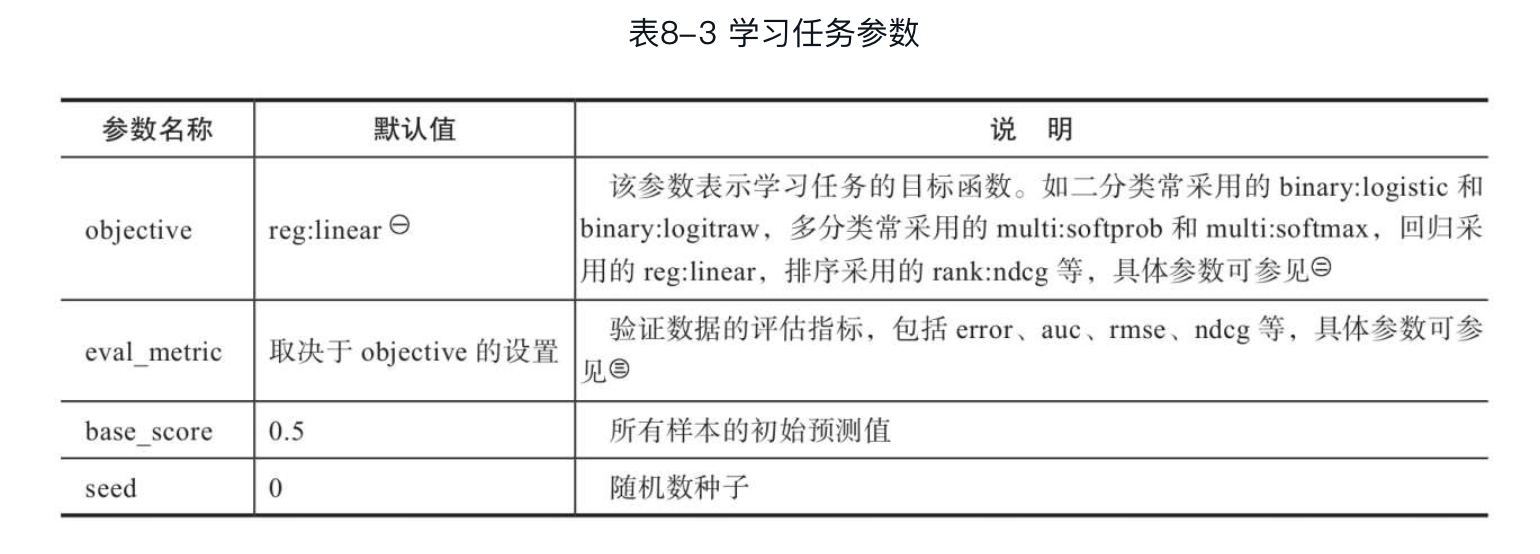
注:目前XGBoost官方名称已更改为reg:squarederror。
通过前面的介绍可知,当模型变得复杂时,可以更好地拟合训练数据,获得偏差较小的模型,但这种复杂的模型需要更多的数据来支持,否则容易导致模型泛化能力差,出现过拟合。XGBoost中大部分参数的调整是偏差与方差的权衡。好的模型应该能够平衡复杂度与泛化能力,从而达到一个最优的状态。
控制过拟合
判断模型是否过拟合的方法很简单,典型表现是模型对训练集的训练精度很高,但对测试集很低,这种情况下很可能出现了过拟合。在XGBoost中有两种比较通用的方法控制过拟合。
- 直接控制模型的复杂度,如调整
max_depth、min_child_weight、gamma等参数。 - 增加模型随机性,有效避免噪声的干扰,如调整
subsample、colsample_bytree等参数。
另外,也可以通过减小eta的步长控制过拟合,但采用此种方法时需注意调大num_round。
不平衡数据集
在实际应用中,数据集极不平衡的情况是经常发生的,如广告点击日志等。这会在一定程度上影响模型训练,通常有两种方法解决该问题。
- 如果仅仅关心预测样本的排序顺序(如
AUC),则可通过scale_pos_weight参数平衡正负样本权重,并用AUC进行评估。 - 如果比较关心预测值的准确性,在这种情况下可能无法重新平衡数据集,可以尝试将
max_delta_step设置为一个有助于模型收敛的有限值(如1)
XGBoost调参示例
下面以一个具体的调参示例来演示XGBoost的一般调参过程。该示例取自UCI的Wine Quality数据集,该数据集是关于预测葡萄酒品质的问题。label字段(quality字段)取值范围是0~10,是一个多分类问题。为了方便演示,将问题简化为一个二分类问题,定义quality大于等于6的为高品质葡萄酒(用1表示),将quality小于6的为低品质葡萄酒(用0表示)。数据集包含如下特征:
- fixed acidity(固定酸度);
- volatile acidity(挥发性酸度);
- citric acid(柠檬酸);
- residual sugar(残糖);
- chlorides(氯化物);
- free sulfur dioxide(游离二氧化硫);
- total sulfur dioxide(总二氧化硫);
- density(密度);
- pH;
- sulphates(硫酸盐);
- alcohol(酒精)。
网格搜索调优
数据加载和预处理
引入scikit-learn交叉验证cross_validation、评估指标metrics和网格搜索GridSearchCV,并通过pandas的read_csv加载数据。具体代码如下:

对数据集进行预处理,将其转化为二分类问题并划分训练集和测试集。处理代码如下:


可以看到,数据预处理完毕后训练集的正负样本数量相差并不大。
定义交叉验证、模型拟合函数
下面定义model_cv函数,用以创建XGBoost模型和执行交叉验证,代码如下:

定义model_fit函数执行模型拟合、测试集预测等操作:

参数bst表示模型分类器;train、test分别表示训练集和测试集;features为特征字段集(去除了label列和ID类字段);cv_folds表示K-折交叉验证中K的值;early_stopping_round表示在n(n为该参数设置值)轮训练中,若模型都没有提升则结束训练。函数model_cv通过训练集进行交叉验证,得到较优的模型迭代轮数(即n_estimators)。函数model_fit可以采用交叉验证后的参数拟合模型,用拟合好的模型对训练集和测试集进行预测,并计算准确率和AUC
网格搜索调参
前面介绍过XGBoost总共有3类参数,其中通用参数主要用于指定Booster类型等训练前已确定的参数,无须调节,而Tree Booster参数和学习任务参数则需用户根据应用环境进行调优。学习率(eta)参数没有特别的调节方法,如果训练的树足够多,一般eta调小一些比较好,因为eta过高容易导致过拟合。但是如果一味地降低eta而增加树的数量,则会增大模型训练的计算量。因此,针对这些问题一般采取如下策略。
- 选择一个相对较高的
eta。一般情况下为0.1。但是根据不同的应用场景,较为理想的eta会在0.05~0.3波动,然后选择对该eta最优的决策树数量。可以利用XGBoost中的交叉验证函数cv来选取最佳数量。 - 选定学习率和决策树数量后,进行决策树特定参数调优(max_depth、min_child_weight、gamma、subsmple、colsample_bytree)。
- 调整XGBoost的正则项参数(
lambda、alpha)。 - 降低学习率,确定最优参数。
下面将以示例的形式详细介绍上述步骤。
- 确定学习率和决策树数量
为了确定boosting参数,需要先给其他参数设置初始值,初始值设置如下。
max_depth:该值一般设置为3~10,此处初始值为4,也可以选择其他初始值,一般4~6都是不错的选择。min_child_weight:初始值为1。gamma:初始值为0,一般该参数开始时会选择一个比较小的值,如0.1~0.2,后续根据需要再调整。subsmaple、colsample_bytree:这两个参数默认值都设为0.8,这是比较常见的初始值,一般都会设置在0.5~0.9。scale_pos_weight:初始值为1,因为正样本和负样本数量并不悬殊。
上述参数只是一个初始的估计值,后续会根据需要进行调整。这里采用的默认学习率为0.1,并用交叉验证函数cv获取该值最佳决策树数量,这一过程可通过model_cv函数来实现,代码如下:


max_depth、min_child_weight参数调优
max_depth和min_child_weight两个参数对模型产出结果的影响很大,我们先对这两个参数进行调优。增大树深度max_depth可以增加模型的复杂度,一般设置为3~10。如果该值设置太小,则模型不容易捕获非线性特征,导致欠拟合;如果该值设置太大,则模型会过于复杂而导致过拟合。参数min_child_weight为子节点包含样本的最小权重和,该参数越大,则树分裂越保守,但欠拟合风险也随之增大。对于这两个参数,首先进行大范围粗调,缩小参数范围,确定范围后再进行微调。代码如下:

上述代码通过GridSearchCV对max_depth和min_child_weight进行粗粒度搜索,max_depth搜索值范围是[3,5,7,9],min_child_weight搜索值范围是[1,3,5],输出grid_search1.best_params_和grid_search1.best_score_:

可以看到,理想max_depth和min_child_weight分别为7、1,然后可以在这两个值附近进行微调:


微调后发现,max_depth和min_child_weight的取值并未改变,说明7和1为这两个参数的理想取值。
gamma参数调优
在调整完max_depth和min_child_weight后,便可以对gamma参数进行调优了。参数gamma是决策树节点分裂时最小的损失减少量,该参数越大,决策树分裂越保守。gamma参数的取值范围很大,这里为提高调参效率把取值范围设置在0.5以内,读者在使用时也可以取更精确的gamma值。

输出grid_search3.best_params_和grid_search3.best_score_:

结果表明最佳的gamma值为0.4,此时交叉验证的指标平均值也由0.8027上升到了0.8054。截至目前,已经完成了max_depth、min_child_weight和gamma这3个参数的调优,下面利用调整好的参数重新训练模型,代码如下:


可以看到,测试集AUC由0.8489上升到了0.8534,说明上述参数调整对模型产生了正向影响,提升了模型精度。
subsample和colsample_bytree参数调优
下面对subsample和colsample_bytree进行调整。参数subsample定义了数据集样本上的子样本的比例,而参数colsample_bytree则定义构建决策树时列采样的比例,两者均可防止模型过拟合。和前面一样,这两个参数采用先粗后细的调参步骤。首先取0.6、0.7、0.8、0.9、1.0作为初始值(range函数是左开右闭区间,因此代码中是range(6,11))。具体代码如下:

输出grid_search4.best_params_和grid_search4.best_score_如下:

最终得到subsample和colsample_bytree的理想值为0.8与0.75。
- 正则参数调优
参数gamma和正则参数都用于防止模型过拟合,其中gamma参数更为常用,正则参数用得较少,但这里也会对正则参数调优进行说明,用户根据任务需求选择是否调整该参数。正则参数包括L1正则参数reg_alpha和L2正则参数reg_lambda,这里以reg_alpha为例介绍,reg_lambda调参过程和reg_alpha类似。代码如下:

得到reg_alpha的理想值0后,进行更细粒度的调优。代码如下:

输出grid_search7.best_params_和grid_search7.best_score_如下:

最终得到reg_alpha的理想值为0。针对上述优化的参数,再训练一次模型:


可以看到,在这一轮调参中,正则参数无变化,采样参数相比上一轮只有colsample_bytree由0.8降为了0.75,但从交叉验证的结果来看,该变化并未对测试集AUC产生影响。
- 降低学习率
最后,可以尝试调低学习率,使用更多的决策树进行测试。代码如下:

至此,便完成了一次较完整的调参过程,最终模型结果相比于最开始已经有了比较明显的提升。但是与此同时应该清楚,参数调优只能让模型有小幅提高,而并不能使模型有质的提升,想要模型效果有大幅提高,还需要依赖特征工程、模型融合等手段。
XGBoost应用
PCA
PCA的实现原理
在机器学习过程中,有时我们也需要对数据进行“降维打击”,当然降维的目的不是“消灭”数据,而是将数据最重要的一些特征保留下来,去除噪声和不重要的特征,更好地为数据分析、模型训练服务。另外,降维还有助于实现数据可视化。对二维或三维的数据进行可视化相对容易,但随着数据的生成和维度的不断上升,对数据进行可视化变得越来越困难。因此,可通过降维来实现可视化。降维有助于减少模型计算量和训练时间,另外,一些算法可能不太适用于高维数据,这时即可通过降维提升算法的可用性。
PCA是一种常用的数据降维方法。PCA通过线性变换减少原始数据的维度,将原始数据由原来的坐标系映射为一组新的线性无关的坐标系(称作主成分)。具体做法:首先找出方差最大的第一主成分,然后在与前面成分正交的基础上找到方差次大的成分,依次类推。PCA可以有效提取数据中的主要特征,去除冗余特征和噪声,将原有复杂数据降维,找到隐藏在原始数据中的简单模式。
降维一般会带来信息丢失,那如何在损失最小的情况下实现将高维数据映射到低维空间呢?下面以二维降到一维为例,如图9-1所示。图9-1a中的点是一些存在于二维空间中的样本,分别以图9-1b和图9-1c两种形式进行降维。
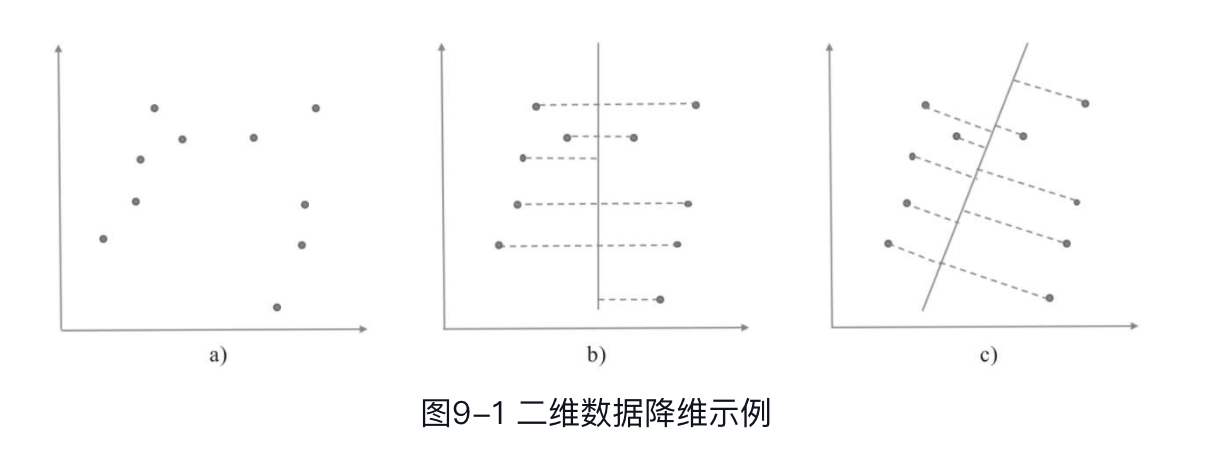
高维数据的降维过程可以用矩阵的形式来表示,如二维降到一维,假设有(1,1)、(2,2)、(3,3)3个样本,将其降维到(1,1)一维直线上,则可通过如下矩阵运算表示:
可以看到,经过图9-1b的方式降维之后,一些样本映射到一维直线上会与其他样本重合,导致某些样本信息损失。而经过图9-1c的方式,样本信息基本未损失。图9-1c所示降维的特点是让样本投影后的值尽可能分散,在数学上可以用方差来描述这种分散程度。因此,对于上述将二维降到一维的问题,只需要找到降维后方差最大的维度即可。但是对于大于一维的情况,方差便不再适用了。例如,将维降到维(),此时首先找到一个方向(其方差最大)作为一个维度,若第二个方向仍旧以方差最大作为选择标准,则可以预想到其应该和前一个方向是基本重合的,因此在确定第二个方向时应当与之前方向正交,即两个方向线性无关,此时便需要引入协方差。协方差可以表示两个变量间的相关性,协方差为0,表示两者之间线性无关。协方差公式如下:
现有一样本矩阵,大小为,每一列表示一个数据样本,样本特征维度为两维,如下:
首先对样本矩阵进行中心化处理,使特征均值为0,可以得到:
将乘以的转置,然后除以样本量,则可得到其协方差矩阵,如下:
可以看到,协方差矩阵的对角线上为特征的方差,而非对角线上为两个特征维度之间的协方差。因此,降维后数据的协方差矩阵应满足除对角线外的其他值为0。假设原始样本矩阵为,个维向量,为变换矩阵,为降维后的矩阵,其中。为的协方差矩阵,为的协方差矩阵。此时的优化目标为降维后的Y每一维的方差足够大,并且维度之间是线性无关的,反映到协方差矩阵上,即对角线上的值足够大,且非对角线的值为0,此时该优化问题转变为了协方差矩阵对角化的问题。熟悉线性代数的读者对矩阵的对角化问题应该并不陌生,此处不再详述,下面介绍一下PCA的具体求解过程。首先求出协方差矩阵的特征值和对应的特征向量,将特征值按从大到小的顺序沿对角线排列,取前个特征值即可得到协方差矩阵,将特征向量按相应的特征值从上到下排列,取前行,即可得到转换矩阵。
总结PCA的求解方法如下:
- 对原始矩阵进行中心化处理;
- 计算原始矩阵的协方差矩阵;
- 计算协方差矩阵的特征值和特征向量,将特征值从大到小排列;
- 取前个特征值对应的特征向量组成转换矩阵;
- 得到降维后的矩阵。
通过PCA对人脸识别数据降维
scikit-learn可通过接口获取LFW数据集,代码如下:

通过fetch_lfw_people函数获取数据集,其中参数min_faces_per_person表示提取的图片数据集中仅保留图片数大于等于min_faces_per_person的图片,参数resize用于调整每张图片的大小。数据集下载完成后,统计数据集中样本数量、特征数及包含类别(label)的数量:


可以看到,该数据集包含1288个样本,特征数为1850,总共有7个类别,即包含了7个人的人脸图像。下面对数据集进行划分,将其划分为训练集和测试集:

完成上述操作后,下面开始定义PCA模型。scikit-learn中的PCA包含多个参数,如n_components、svd_solver等。本例主要用到参数n_components,它表示需保留的成分数量,即降维后的维度数,此处设为200,其他参数均采用默认值。定义PCA模型,并对训练集进行拟合,代码如下:

模型拟合完毕后,用拟合好的PCA模型对训练集和测试集进行降维:

下面用XGBoost分别对降维前和降维后的训练集进行训练,并对测试集进行预测,观察降维前后训练时长及模型精度的变化。定义XGBoost模型训练参数如下:

因为此问题是一个多分类问题,因此将参数objective设为'multi:softmax',类别数num_class设为7。另外为了方便比较,降维前后采用相同的参数进行训练,训练轮数均为1500轮。首先对降维前的数据集进行训练和预测:

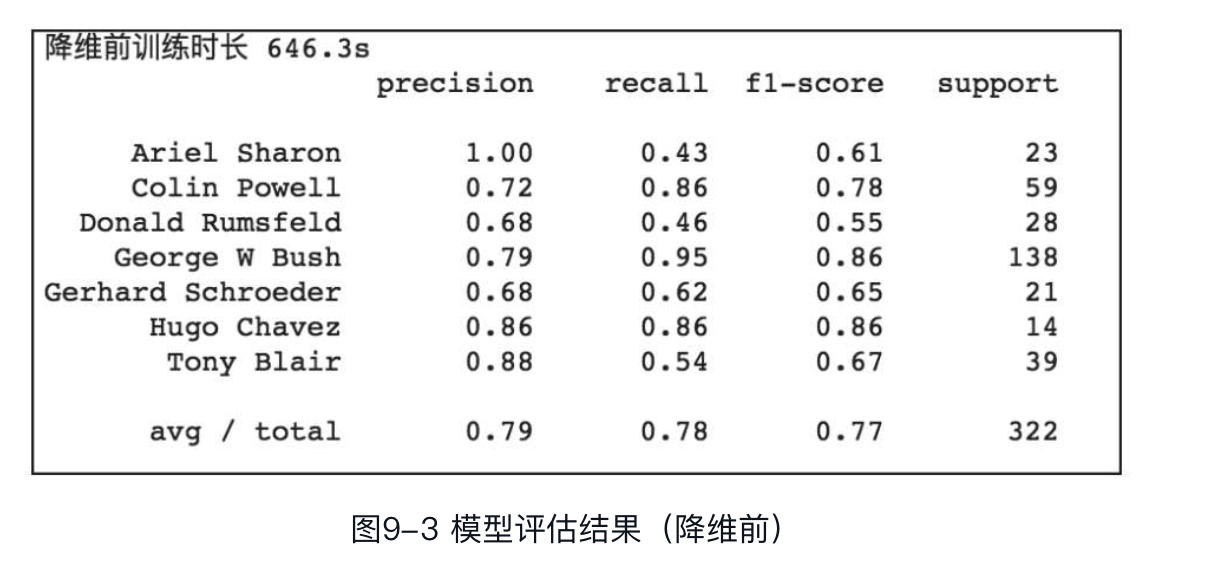
可以看到,降维前数据集的训练总时长为646.3s,平均准确率、召回率及F1-Score分别为0.79、0.78、0.77。
下面对降维后的数据集进行训练及预测:

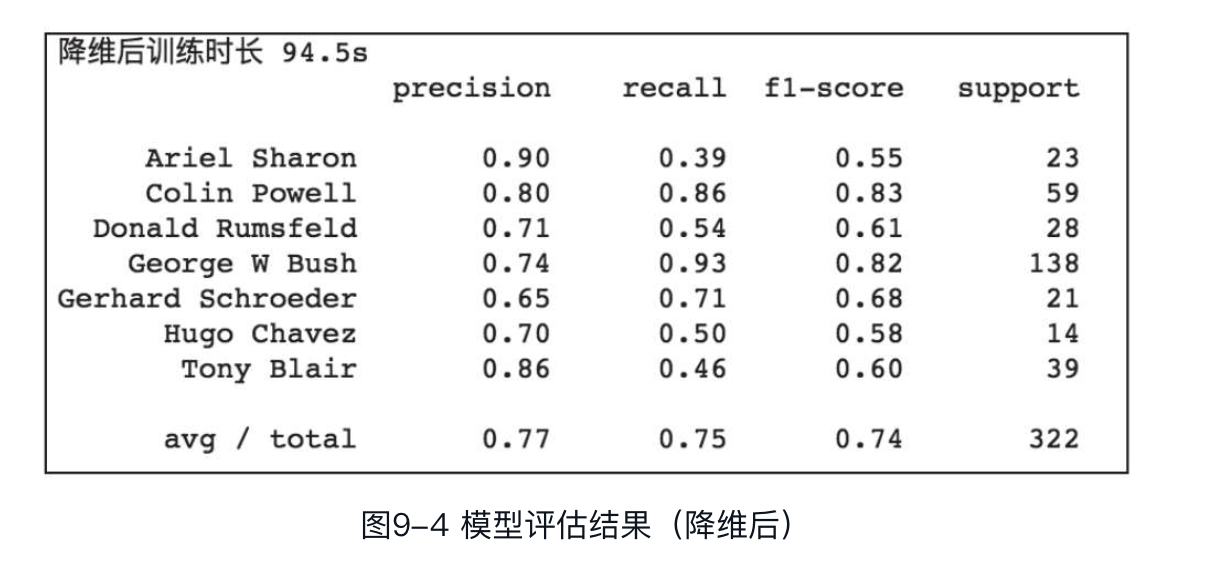
可以看到,降维后数据集的训练时长相比降维前由646.3s缩短为94.5s,而模型评估指标相比降维前略有下降,平均准确率、召回率及F1-Score分别为0.77、0.75、0.74,表明PCA在降维的过程中也带来了一些信息损失。
通过XGBoost实现广告分类器
该数据集是由UCI发布的一个互联网广告数据集,总共包含3279张图片,其中2820张为正常网页内容,459张为广告。每个样本包含1558个特征,其中包含3个连续特征,分别为height、width和ratio,其他均为二值特征。另外,样本还有一个字段用于标明该样本是否为广告(ad.—广告,nonad.—非广告)。
数据分析
本节会通过一些常用的数据分析方法对数据集进行分析。首先读取数据集,因为数据文件并不包含表头,因此将header置为None,此处通过设置参数error_bad_lines忽略无效数据。代码如下:

数据加载完毕后,可通过data.shape查看数据集的大小。可以看到,数据集包含3279个样本,共1559个字段,和数据集描述是一致的。另外,可以通过head()函数输出部分数据来查看数据格式,如图9-6所示。
可以看到,因为数据不包含表头,因此默认以数字索引作为列名。为了后续处理方便,我们将数据集中的0~2、1558列分别用height、width、ratio(width/height)和label作为列名,另外,数据集中缺失值以“?”表示,此处将其替换为np.nan。处理代码如下:

数据值缺失是数据分析中经常遇到的问题之一。当缺失比例很小时,可直接对缺失记录进行舍弃或手工处理。当缺失数据占有一定比例时,可以采取如特殊值填充、平均值填充等方法进行填充。因为XGBoost本身实现了对缺失值的处理算法,此处缺省值不再进行填充处理。因为某些包含“?”的列的字段类型为object(可通过dtypes查看),为方便处理,将其转化为float,转化代码如下:

目前数据集label字段取值为ad.和nonad.,分别表示样本为广告和非广告,将其转化为1和0表示,代码如下:

将数据集划分为训练集和测试集,此处采用4:1的划分比例:

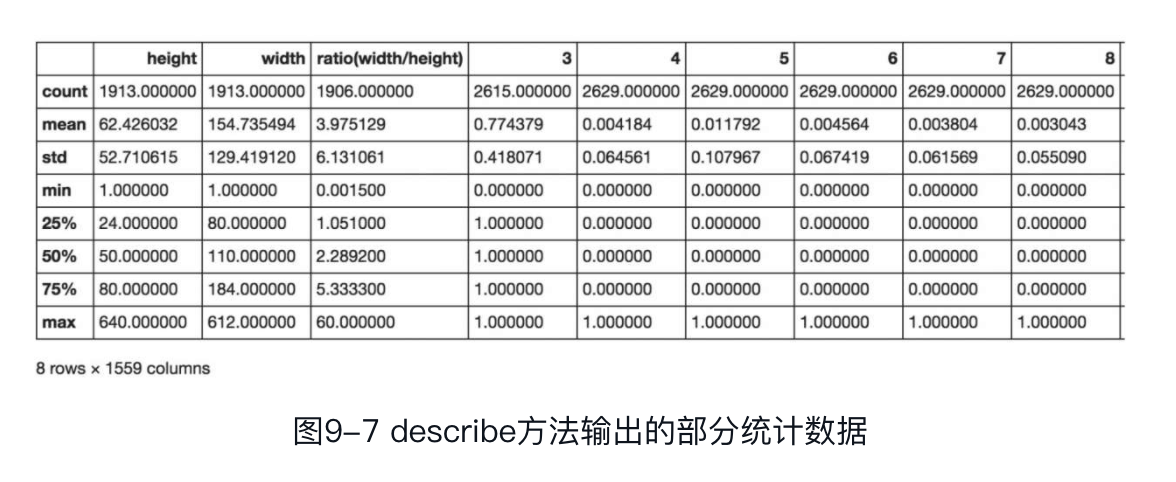
为了更准确地理解数据,我们通过train.describe()对特征进行简单的统计计算。
describe方法可计算数值特征的计数、平均值、标准差、最小值、最大值及25、50、75的百分位数。describe输出如图9-7所示(数据输出较多,此处为部分数据)。
目标特征
下面看一下label特征的取值分布,因为该问题为二分类问题,因此label取值只有两种。通过plot绘制不同label样本数量柱状图,代码如下

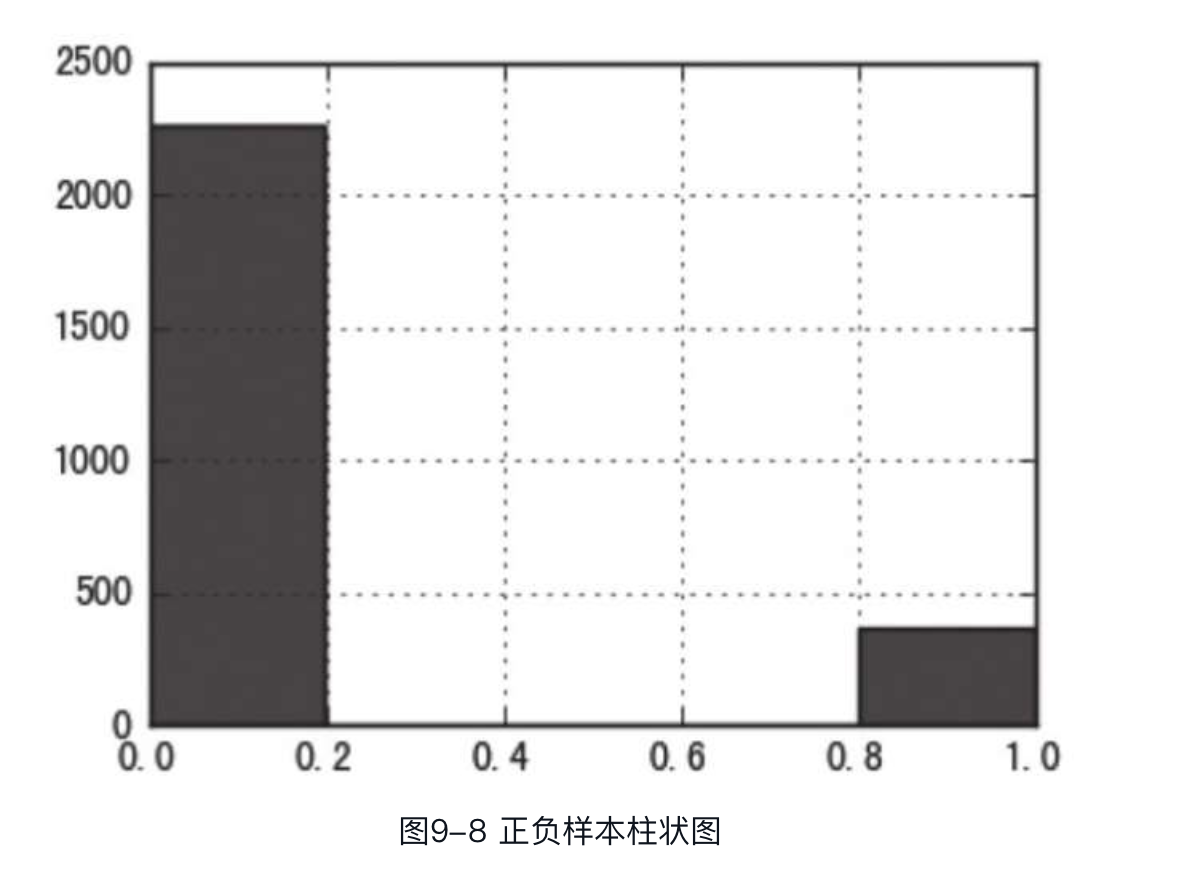
可以看到,训练数据中的正样本与负样本的比例大概是1:7,正负样本并不均衡,后续处理应考虑平衡正负样本。
连续型特征
分析完目标特征后,下面对数据集的其他特征进行分析。此数据集包含3个连续型特征:

绘制数据分布直方图,方便直观地分析每个特征的分布情况:
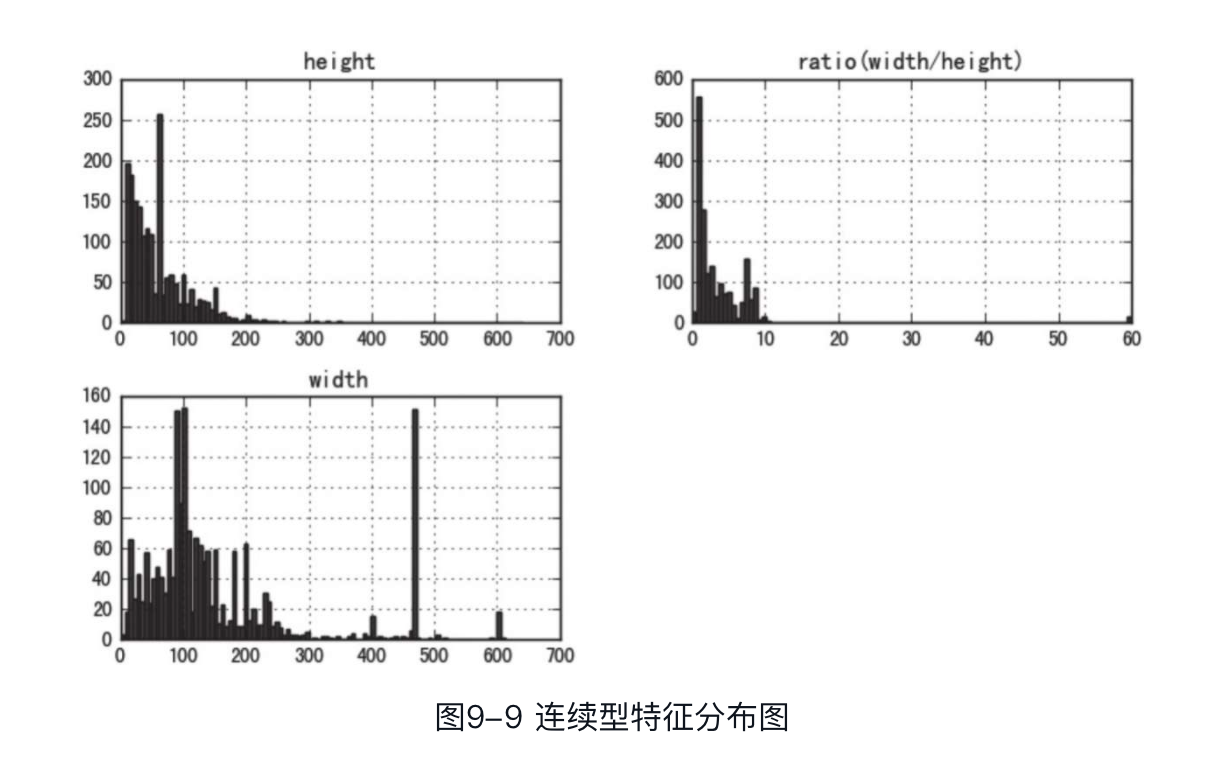
可以看到,分布图中有些特征并未遵循任何可解释的概率分布函数,读者可以尝试转化一些特征使其更接近于高斯分布,但这种方法并非一定奏效。另外,还可以对连续特征在正负样本的不同分布上进行对比,这里通过seaborn库中的violinplot绘制小提琴图来达到上述效果。小提琴图可以可视化一个或者多个组的数字变量的分布,此处以width这个特征为例,代码如下:

其中,参数data为dataframe或者数组格式的数据;x和y分别为绘制的x轴和y轴的特征。输出结果如图9-10所示。
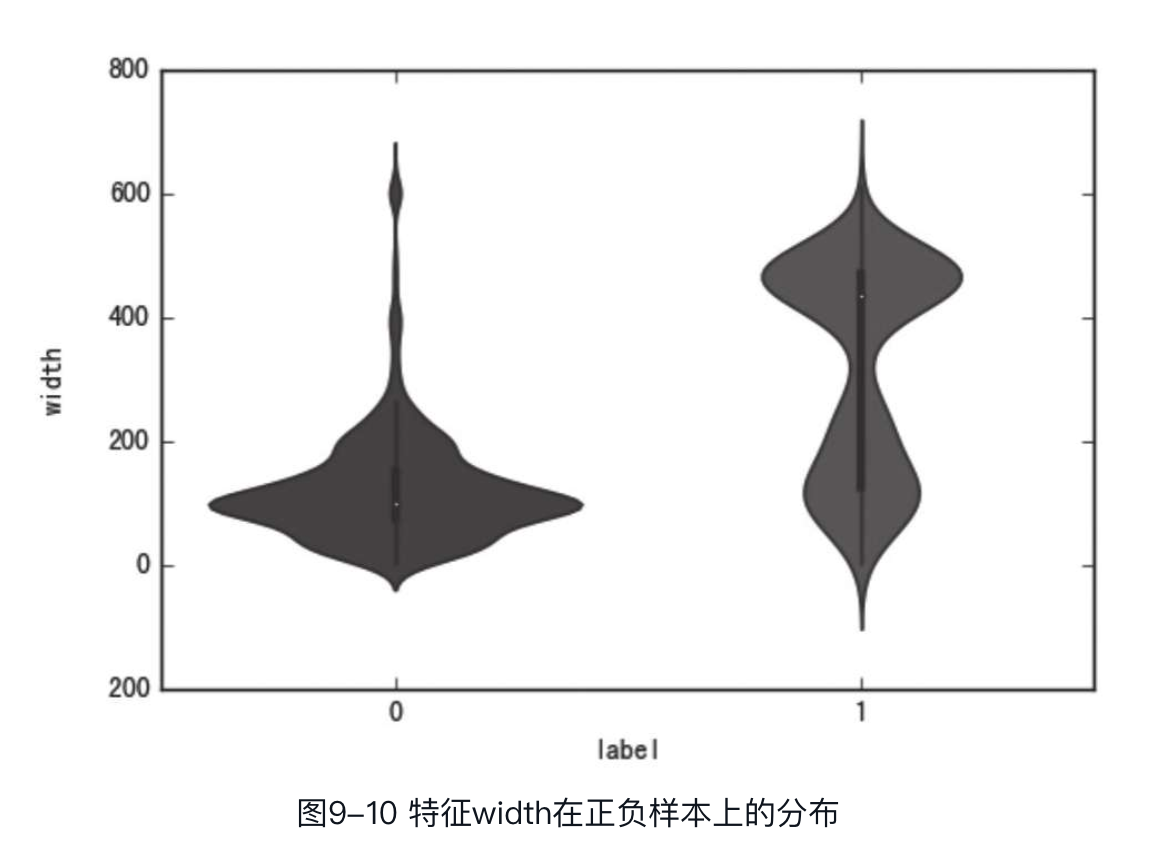
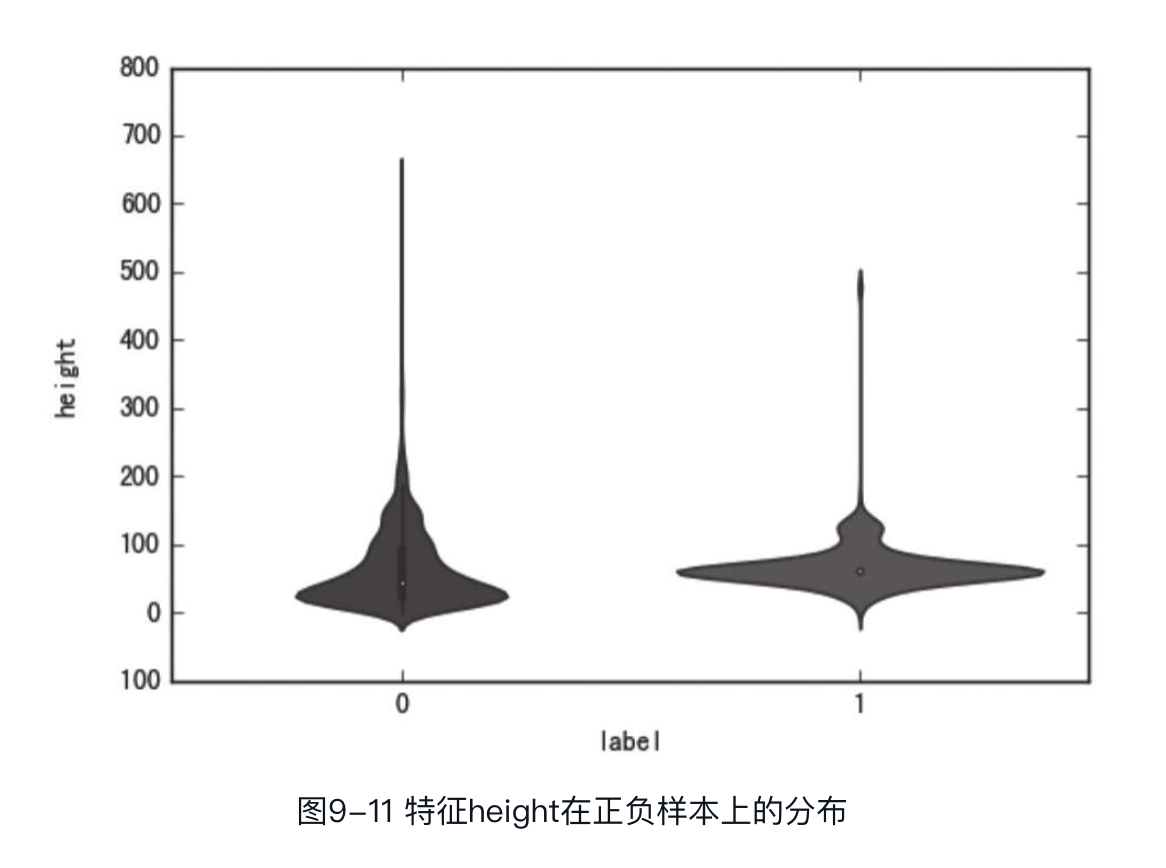
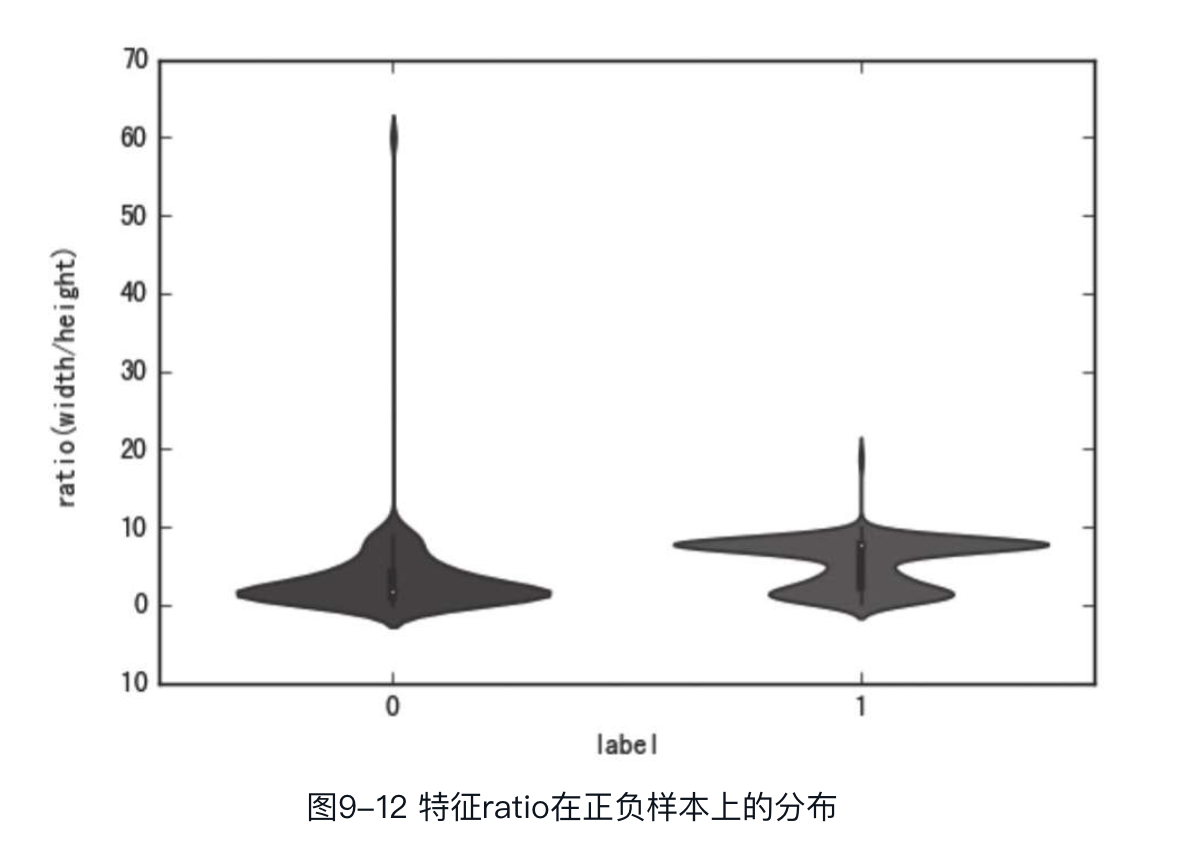
其中,横坐标为label,有两个取值,即0和1;纵坐标为width,图9-10中小提琴图两边是对称的,可以看出样本在特征width上的分布。可以看到,特征width在正负样本上的分布的差别还是很大的,因此可以推测该特征可能是一个对模型较为有用的特征。同理,可以绘制出特征height和特征ratio在正负样本上的分布,如图9-11和图9-12所示。
下面看一下这些连续型特征彼此之间是否具有相关性,此处通过皮尔逊(Pearson)系数来度量两个特征之间的相关性。皮尔逊相关系数为两个变量之间的协方差和标准差的商,取值范围为(-1~+1)。估算样本的协方差和标准差,可得到皮尔逊相关系数,公式如下:
式中,是样本数量;和表示第个样本的不同变量;和表示两个变量的均值。pandas提供的方法可以方便地计算列之间的皮尔逊相关系数,pandas也提供了kendall和spearman相关系数的计算,读者可根据需要进行选择。另外,这里通过seaborn库中的heatmap来绘制皮尔逊相关系数的热点图,代码如下:

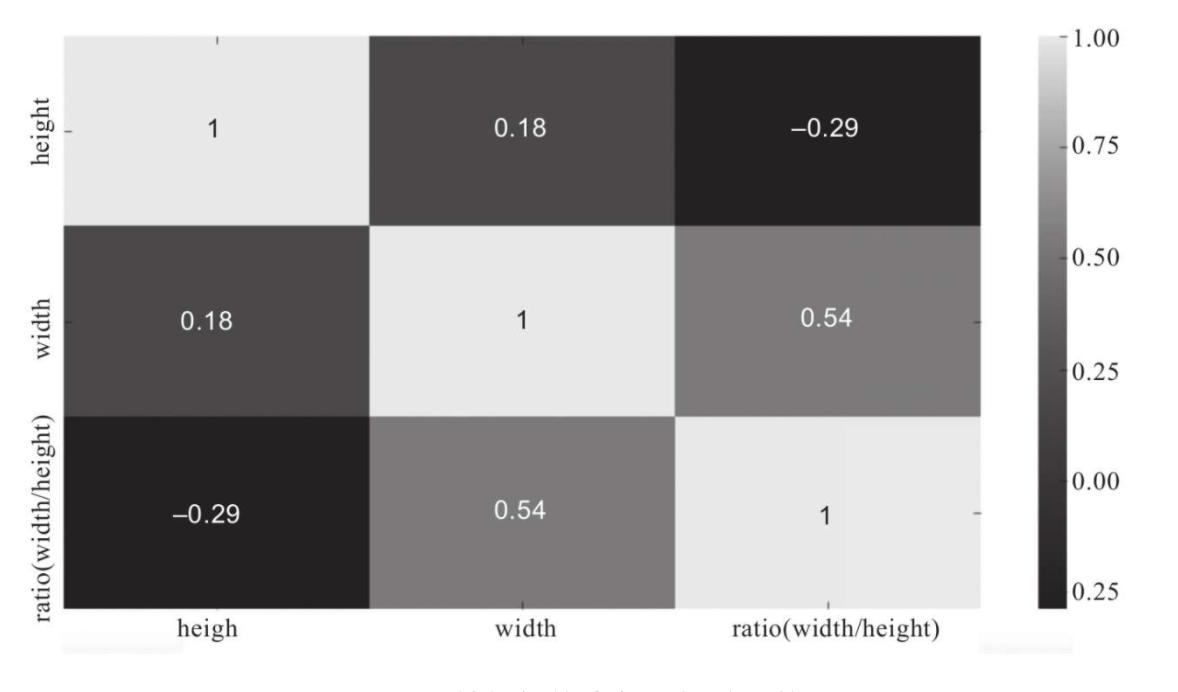
因为本例中的连续特征较少,因此相关系数的表现并不是很明显。在某些应用中,通过相关系数可以清楚地看到某些特征之间具有高度相关性,这有可能是基于数据的多重共线性导致的。回归模型中多个特征具有高度相关性,会导致很多问题,因此对数据集应用线性回归模型时要十分注意。
训练集、测试集分布比较
在一些情况下,训练集和测试集并不完全相似,此时通过训练集选择的验证集并不能很好地代表测试集。为了使测试集预测得更准确,需要对训练集和测试集进行分布比较,确保它们的数据分布相同。如果确定训练集和测试集分布是相同的,那么便可以在训练集上实施交叉验证。
此处我们采用机器学习算法来检验训练集和测试集是否有明显区别。理想情况下,对于来自相同分布的训练集和测试集,训练的分类器区分情况应与随机差不多,即AUC应为0.5左右。
首先,将训练集和测试集样本进行混合。将训练集和测试集的原label字段丢弃,新增一列字段作为训练集和测试集的label特征。label字段为1表示训练集,为0表示测试集。代码如下:

处理完毕后,将所有数据的顺序随机打乱,重新创建新的训练集和测试集,此处训练集样本数设定为总样本数的1/2。代码如下:

通过分类模型检验
生成新的训练集和测试集后,即可拟合分类模型了,此处选取逻辑回归和决策树这两种模型作为分类器,分别拟合新生成的训练集,对新测试集进行预测,最后计算预测结果的AUC。代码如下:


可以看到,通过逻辑回归和决策树拟合后的模型对新测试集进行预测,得到的预测结果AUC均接近于0.5,说明原始训练集和测试集的分布是基本相同的。
通过交叉验证检验
除了上述方法之外,我们也可以对整个数据集进行交叉验证,即通过交叉验证来划分训练集和测试集(而非人工随机划分)来进行测试,此处以简单的2折交叉验证为例。代码如下:


可以看到,AUC均值也在0.5附近,并且标准差为0,也可以验证上述得到的结论。
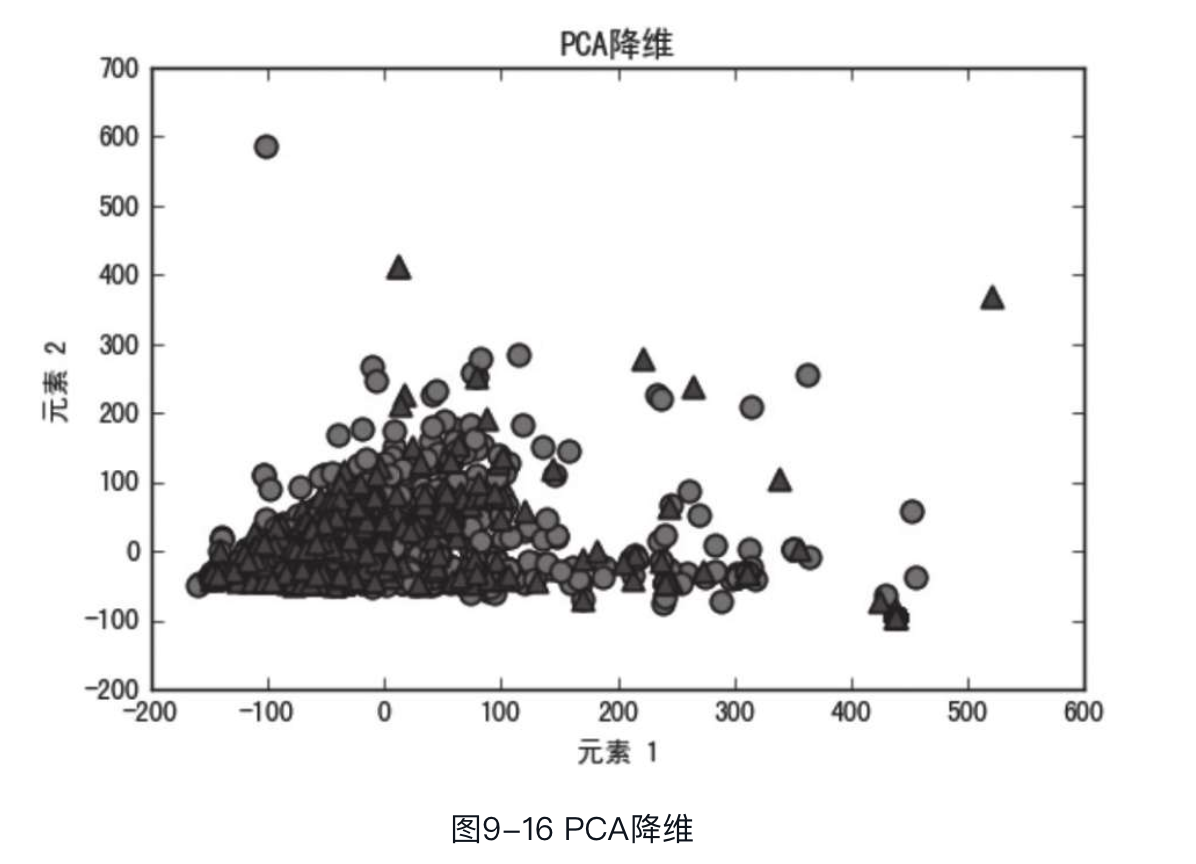
通过PCA降维检验
除了采用分类模型、交叉验证检验训练集和测试集的分布外,我们还可通过PCA对训练集和测试集的集合数据进行降维(降到二维或三维),然后对降维后的数据进行可视化,观察训练集和测试集数据分布是否具有明显差别。下面将上述合并数据集特征映射到二维平面上,并将其可视化。代码如下:

在图9-16中,圆形表示训练集,三角形表示测试集。两种形状以相似的方式分散在整个空间中,我们从中未能发现任何规律能够将两者很好地分开。因此,从这一角度也可以印证训练集和测试集分布是基本相同的。
平衡正负样本
该数据集中的正负样本十分不均衡,需要平衡正负样本的权重和。由前述内容可知,XGBoost可通过设置参数scale_pos_weight平衡正负样本的权重。若训练数据集样本之间无权重高低之分,则直接可以以负样本数/正样本数作为参数scale_pos_weight值。统计正负样本的代码如下:

因此,scale_pos_weight值设置为neg_num/pos_num。
训练参数定义
我们先按照经验为模型指定一个初始版本的参数,以此训练一个基准模型。本例为一个二分类任务,因此objective采用binary:logistic,评估函数采用auc。学习率eta设置为0.1,max_depth设置为6,模型迭代轮数为50轮,scale_pos_weight采用上述统计的neg_num/pos_num。代码如下:

模型训练
首先通过数据集构造满足XGBoost输入的DMatrix,然后通过上述定义的模型参数训练模型,设置模型训练过程中的监控列表watchlist,监控训练集和测试集在训练过程中的AUC指标。代码如下:


训练完成后,保存模型:

下面通过训练得到的模型对测试集进行预测,并计算预测结果的AUC得分:

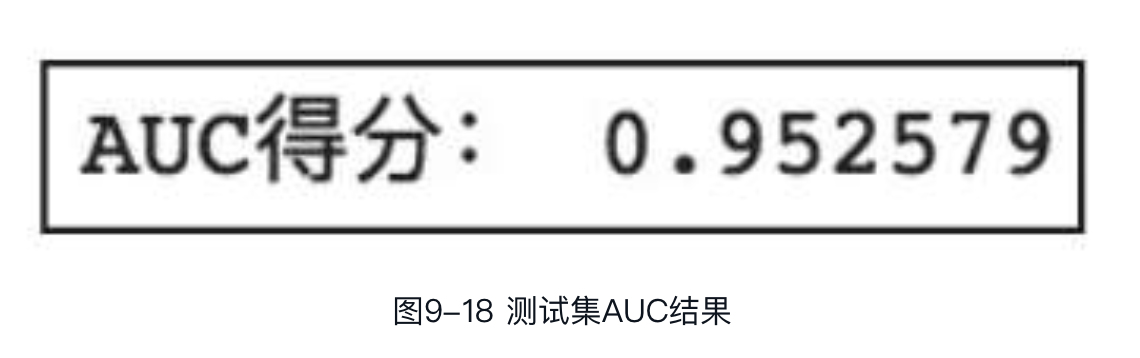
可以看到,模型对测试集预测结果的AUC约为0.95,是一个还不错的结果。此结果作为我们的基准指标,为后续模型调优提供参考依据。
特征重要性排名
模型训练完毕后,可以通过plot_importance来得到可视化的特征重要性排名,此处选择排名前20的特征。代码如下:
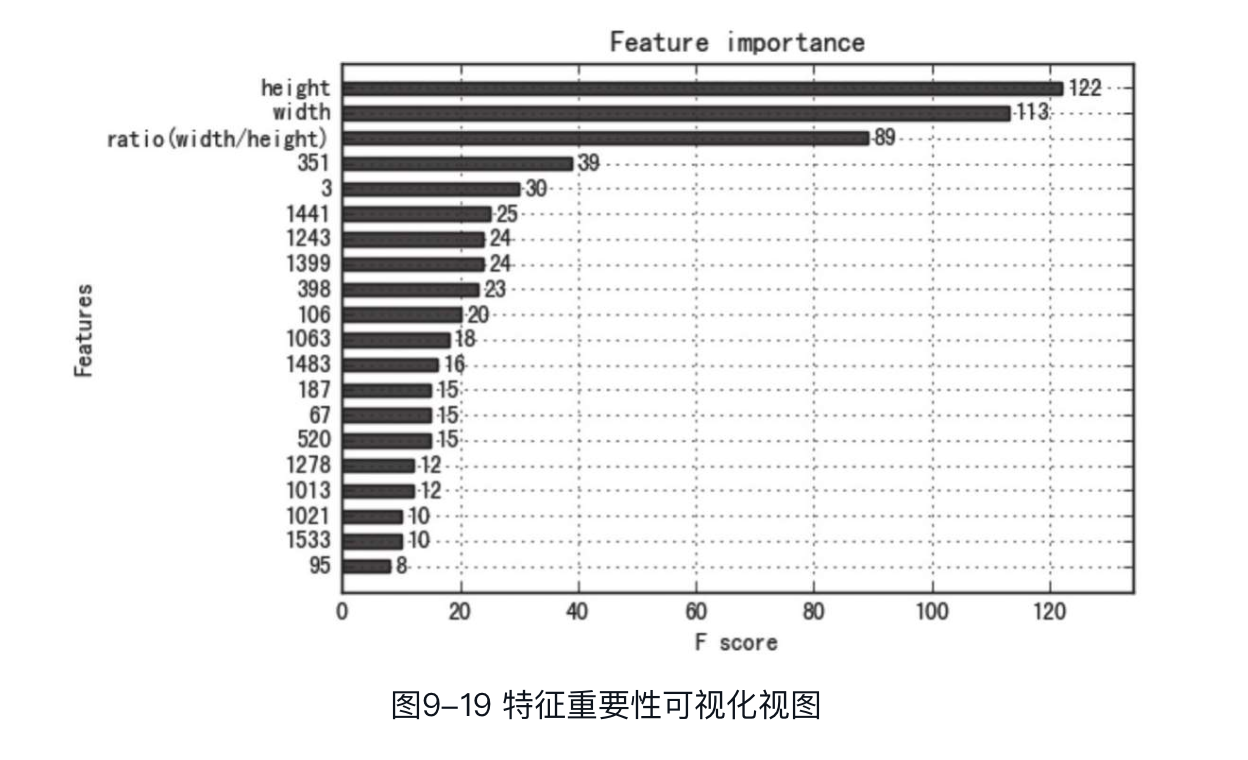
可以看到,3个连续型特征排名最高,其中height作为分裂特征达122次。
超参数调优
通过自定义模型参数,我们已经得到了一个基准模型。因为上述模型的参数均是根据经验人工设定的,因此该模型显然并非最优模型。下面我们就通过超参数调优来优化上述模型,本例采用的优化方法为贝叶斯优化法。
BayesianOptimization包是基于函数优化的,因此首先定义优化函数。代码如下:

优化函数中的learning_rate、cosample_bytree、subsample、gamma、alpha为浮点型的连续值,min_child_weight、max_depth为整型的离散值,objective为固定值binary:logistic。优化函数完成定义后,即可指定贝叶斯优化的参数范围。代码如下:

下面实例化BayesianOptimization对象,开始贝叶斯优化过程。代码如下:

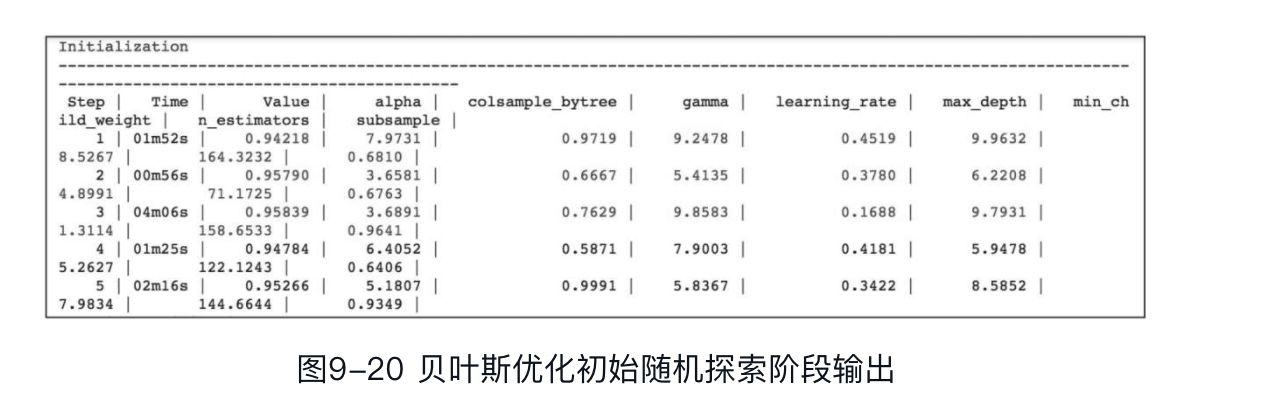
此处设置初始阶段随机探索步骤数为5,贝叶斯优化迭代次数为30。当然读者也可尝试其他值,迭代次数越大,越可能探索到最优值,当然花费的时间代价会相应增大。贝叶斯优化初始随机探索阶段输出如图9-20所示。
贝叶斯优化迭代阶段部分输出如图9-21所示。
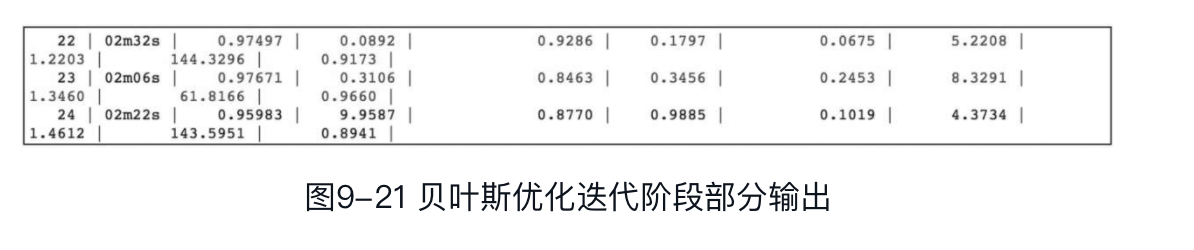
根据输出结果,我们可以得到,最优轮为第23轮,最优交叉验证值为0.97671。下面用贝叶斯优化的参数训练XGBoost模型,并对测试集进行预测。代码如下:

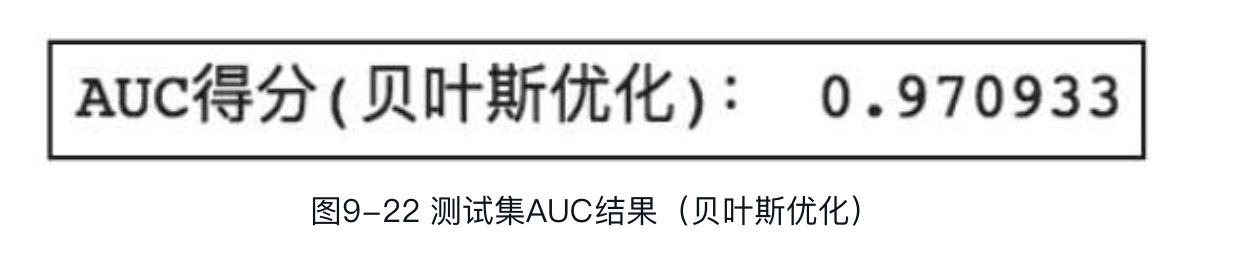
可以看到,通过贝叶斯优化调参之后,测试集AUC相比基准模型有明显提升,由之前的0.95提升到了0.97,证明贝叶斯优化对模型结果的影响是正向的。
GBDT、LR融合提升广告点击率
互联网广告有一个重要的衡量指标——点击通过率(Click-Through Rate,CTR),它是广告点击次数与广告展示次数的比值,可以用来衡量一个广告的热门程度。因为选择正确的广告和显示次序可以极大地影响用户查看和点击广告,进而影响广告产生的收入,因此准确预估CTR就显得至关重要了。Facebook针对本身在线广告CTR的预测场景,提出了一种决策树(GBDT)与逻辑回归(LR)相结合的模型。
GBDT基于boosting思想实现多棵决策树的集成学习,其中每棵树拟合的是当前模型的残差。GBDT具有比较强大的特征表达能力,可以有效地发现具有区分性的特征和特征组合,得到非线性映射的高阶特征。因此,可以将GBDT作为一个天然的特征处理器。LR模型实现简单,容易迭代和并行化,非常适用于类似广告这种具有海量样本的应用场景,因此LR是CTR预估最常用的模型。然而也正是因为LR实现简单,学习能力比较有限,需要强大的特征工程提供支持,才能保证模型效果,而大量的特征工程又十分依赖于人工经验,从而需要巨大的人力成本,由此Facebook提出一种GBDT与LR融合的方法,以GBDT作为特征处理器,将得到的新特征作为特征输入训练LR模型。GBDT+LR模型结构如图10-1所示。
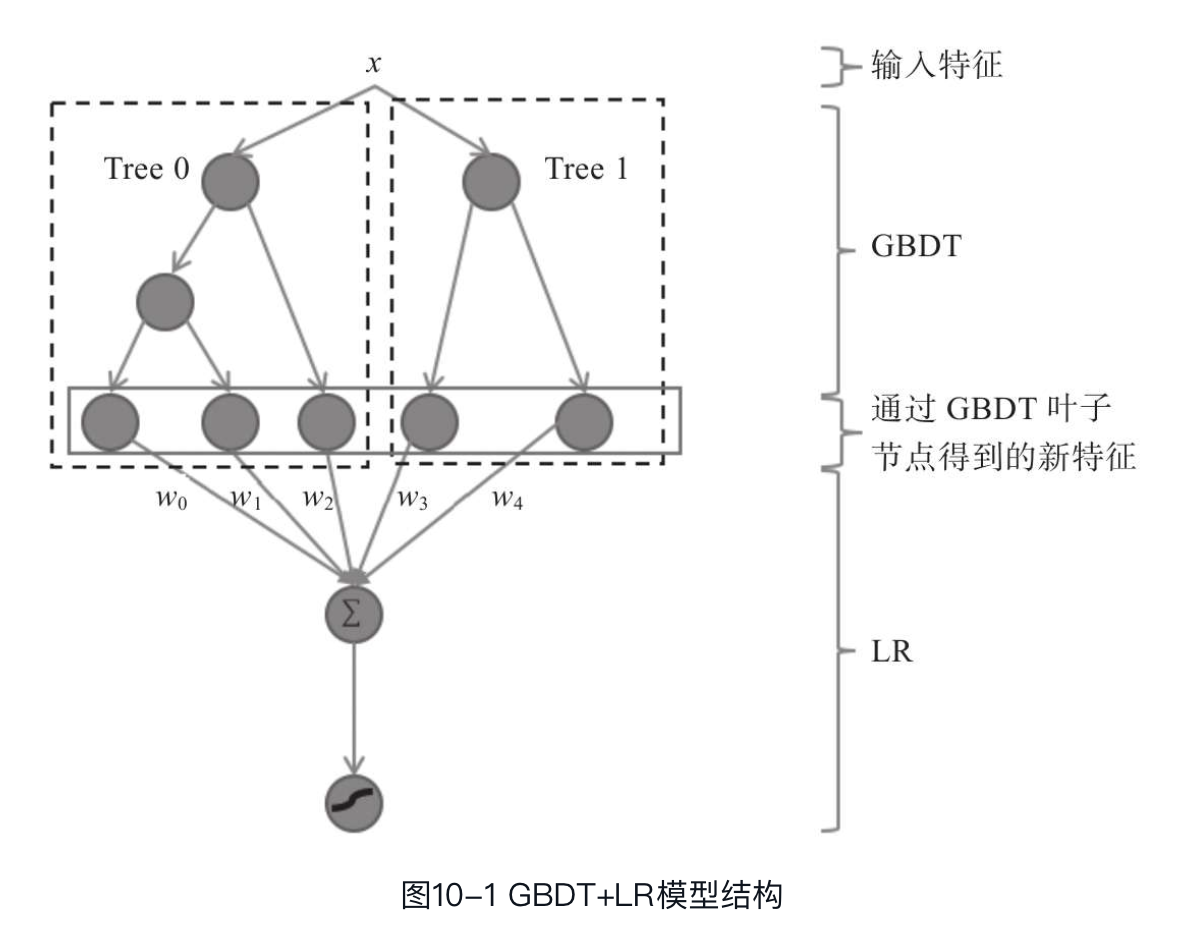
如图所示,为样本的原始特征,其先经过GBDT模型,此处GBDT模型包含两棵树,即tree0和tree1,其中tree0有3个叶子节点,tree1有2个叶子节点,每个叶子节点对应LR的一维特征。每个样本均会落到这两棵树的某个叶子节点上。假设某样本落到了第一棵树的第三个叶子节点和第二棵树的第一个叶子节点上,则可用一个特征向量表示为[0,0,1,1,0]。然后将得到的特征向量作为特征输入对LR模型进行训练。可以看出,该方法采用的是stacking模型融合的思想,通过模型融合提升模型精度。Facebook将此方法应用到其在线广告CTR预估,取得了不错的效果。另外,2014年,在Kaggle的Display Advertising Challenge比赛中,冠军方案也采用了类似的方法,不过该方案用FM(Factorization Machine)模型(确切地说是FFM)代替了LR。传统线性模型(如LR等)的各个特征之间都是相互独立的,若需要考虑特征与特征之间的相互作用,则需要人工提取交叉特征,而FM模型通过交叉向量的方式挖掘特征之间的相关性,解决了高维稀疏数据下的特征组合问题。