常用符号表
nndl

线性代数
基变换
二维空间中的向量有它的坐标,例如向量的坐标是[32],它代表着从起点到向量的末端,需要向右移动三个单位,并向上移动两个单位。或者代表缩放三倍的向量i,和两倍的向量j,而它们的和就是坐标所描述的向量。
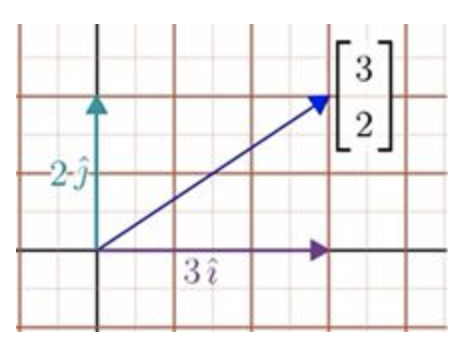
可以把这两个向量看做这个坐标的隐含假设,它们是标量缩放的对象,是标准坐标系的基向量。现在我们要讨论的是选取另一组基向量,比如Jennifer选择另一组向量b1和b2,则她得到的坐标[5/31/3],就与标准坐标系不同。
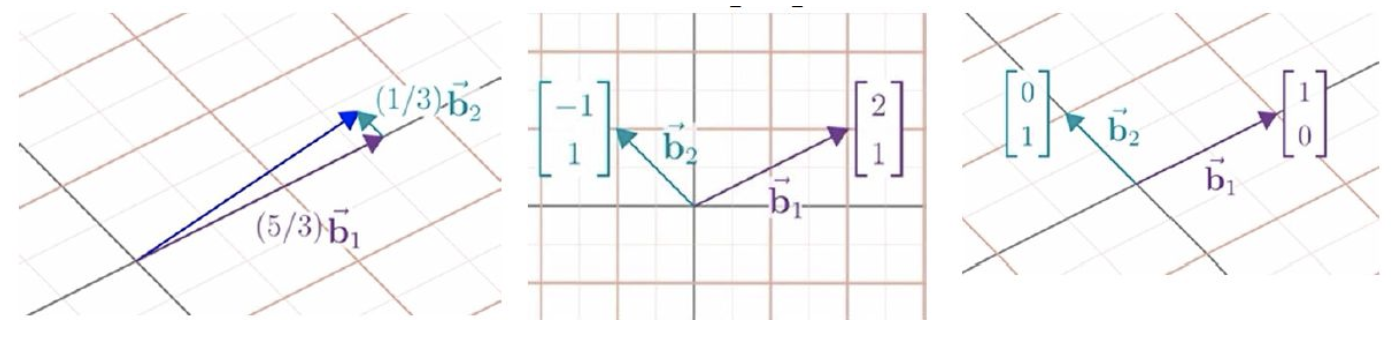
在我们的坐标系中,Jennifer的基向量的坐标分别是[21], [−11] ,但在她自己的坐标系中,基向量的坐标是 [10],[01]。她坐标轴的原点与我们相重合,但是网格的尺寸和方向,依赖于对基向量的选择。那么我们如何在不同的坐标系中进行转变呢?
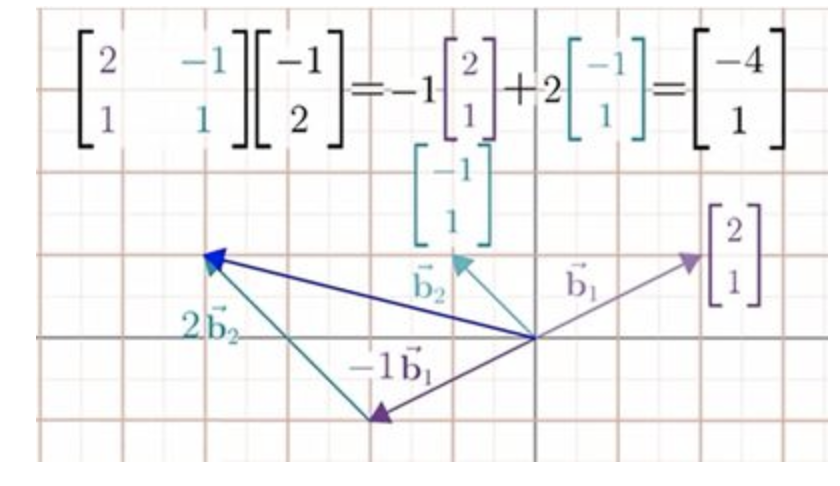
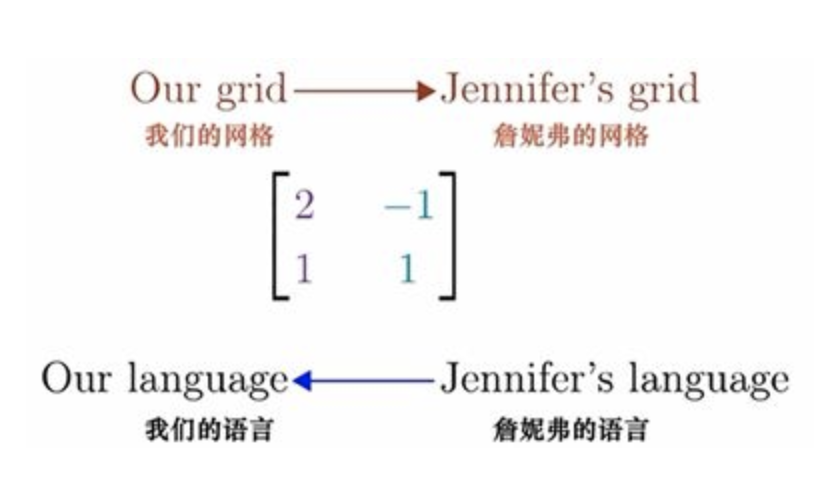
例如,求Jennifer坐标系下的向量[−12],在我们的坐标系(标准坐标系)下的坐标。这过程就是用某个向量的特定坐标与他的基向量数乘,然后将结果相加−1[21]+2[−11]=[−41] ,这就是矩阵向量乘法 [21−11][−12]。矩阵的列向量就是在我们坐标系下所表达的Jennifer的基向量。
作者在这里一顿描述,最后归结为这个矩阵,“把我们误解Jennifer的向量,变成Jennifer真正所想的向量。”
我是这么记的,[21−11][−onetwo]=[−41],说英文的是Jennifer,数字都是我们坐标系下的坐标,列向量线性组合起来得到的也是我们坐标系下的坐标。输入的是Jennifer的 [−onetwo],输出就是我们坐标系下的[−41],Jennifer来我们的坐标系说事,翻译是我们出的,翻译内容就是她的单词在我们这边是啥意思,即她的基向量在我们这里是啥坐标,[21−11] 。没有误解,只有交流。
那么反过来如何操作呢,我们坐标系下的 [32]如何能够变成Jennifer坐标系下的[5/31/3] ?答案是取逆矩阵[21−11]−1=[1/3−1/31/32/3],它意味着一个反向变换。我们坐标系下的 [32],即为Jennifer坐标系下的[5/31/3] 。
[1/3−1/31/32/3]就是我们的基向量在Jennifer坐标系下的坐标,即我们的单词在她那啥意思。
在线性变换过程中,例如90度逆时针旋转,我们追踪基向量i 和j 在线性变换之后的坐标,得到矩阵[01−10],这是用我们的坐标系记录的结果。Jennifer如果要描述90度逆时针旋转,她会追踪她的基向量经过线性变化后的坐标,并且这个坐标是在她的坐标系中记录的。
例如,对于Jennifer坐标系下的向量 [−12],首先翻译成我们坐标系下的坐标 [21−11][−12] ,然后对这个向量施加逆时针旋转[01−10][21−11][−12],最后再翻译回到Jennifer的语言中,[21−11]−1[01−10][21−11][−12] 。
则三个矩阵的复合就是Jennifer坐标体系下的线性变换矩阵:
[21−11]−1[01−10][21−11]=[1/35/3−2/3−1/3]
表达式 A−1MA 暗示着一种数学上的转移作用,中间的矩阵是已了解的一种线性变换,而两侧的矩阵代表着转移作用,也就是视角的转化,三者乘积仍旧代表这种线性变换,但是是从别人的视角。
特征值与特征向量
对一个𝑁 × 𝑁的矩阵𝑨,如果存在一个标量𝜆和一个非零向量𝒗满足Av=λv,则𝜆和𝒗分别称为矩阵𝑨的特征值(Eigenvalue)和特征向量(Eigenvector)
当用矩阵𝑨对它的特征向量𝒗进行线性映射时,得到的新向量只是在𝒗的长度上缩放𝜆倍.给定一个矩阵的特征值,其对应的特征向量的数量是无限多的.令𝒖和𝒗是矩阵𝑨的特征值𝜆对应的特征向量,则𝛼𝒖和𝒖+𝒗也是特征值𝜆对应的特征向量
如果矩阵𝑨是一个𝑁 × 𝑁的实对称矩阵,则存在实数λ1,⋯,λN,以及𝑁个互相正交的单位向量v1,⋯,vN,使得vn为矩阵𝑨的特征值为λn的特征向量(1 ≤ 𝑛 ≤ 𝑁)
二维空间中的一个线性变换将基向量i 变换为[30],基向量j变换为[12] 。如果用矩阵来表达的话就是[3012]。考虑一个特殊的向量以及这个向量张成的一维空间——直线,大部分向量在变换中都会离开了自己张成的空间,而如果向量经过变换后仍能落在这条直线上,就意味着线性变换对它的作用,仅仅是拉伸或者压缩,就如同一个标量一样。
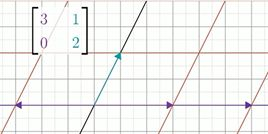
在本例中,向量i所在的方向就是这样一个特殊的方向,它张成的空间是x轴。矩阵对它的线性变换作用,使得向量i变成了原来的三倍,但仍然在x轴上。x轴上的其他向量也都只是被拉伸为原来的三倍。
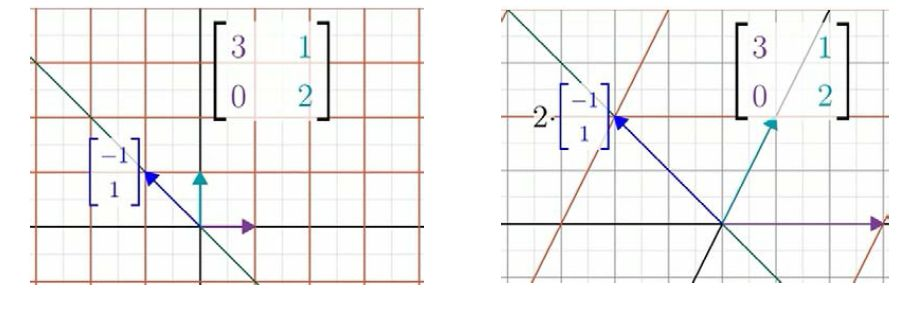
另一个略显隐蔽的向量是[−11],他在变换后也留在自己张成的空间里,被拉伸为原长的两倍。
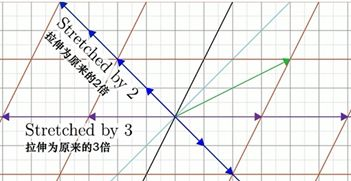
以上就是所有拥有“留在自己张成的空间”这个性质的特殊向量。其他的向量,在变换中都有或多或少的旋转。
这些向量就被称为这个线性变换的特征向量,衡量特征向量在变换中拉伸或压缩的比例因子就是它对应的特征值。如果特征向量为负值,比如-1/2,意味着这个向量被反向,并且压缩到原来的1/2。但它仍旧停留在自身张成的直线上,没有发生旋转。
考虑一个三维空间中的旋转变换。如果能找到该变换的特征向量,那你找到的就是旋转轴。把一个三维旋转看成绕某个轴旋转一定角度,比考虑相应的3×3矩阵直观得多。在这种旋转变换中,特征值为1,因为空间只发生旋转,并不发生拉伸和压缩。
线性变换对应的矩阵,其列向量就是基向量变换后的坐标。但是理解线性变换作用的关键,往往较少依赖于特定的坐标系。最好的方法是求出它的特征向量和特征值。
矩阵、特征向量和特征值的关系为Av=λv,A是矩阵,v是特征向量,λ是该特征向量对应的特征值。特征向量经过矩阵变换后方向不变但被伸缩了λ倍。求解特征值和特征向量就是求解满足于上式的解。
(A−λI)v=0,我们的目标变成寻找一个非零的向量v,使得这个新矩阵与之相乘的结果为零向量。当且仅当这个新矩阵所代表的线性变换将空间压缩到更低维度的时候,这个方程有非零解。而这个矩阵所对应的行列式等于0。求解的过程就变为找到一个λ使得行列式det(A−λI)=0。
例如前面提到的矩阵[3012],求解其特征值,则转变为求解行列式方程det([3−λ012−λ])=(3−λ)(2−λ)=0,求得λ=2,3,代入可求得特征向量,例如代入λ=2,[3−2012−2][xy]=[00],求解得到特征向量[−11] 。
二维线性变换不一定有特征值,比如90度逆时针旋转变换,所有的向量都发生了旋转,没有向量能够保持在其张成空间。逆时针旋转对应矩阵为[01−10],代入计算特征值可得det([−λ1−1−λ])=λ2+1=0,方程的解只有虚数i和−i。
剪切变换对应的矩阵为[1011],行列式方程det([1−λ1−11−λ])=(1−λ)2=0,得唯一解λ=1,这与几何上相一致,只有x轴未发生方向变化,同时缩放比为1。
有时候只有一个特征值,但特征向量不止在一条直线上。例如,拉伸变换[2002],唯一的特征值为2,但平面内的向量都是其特征向量。
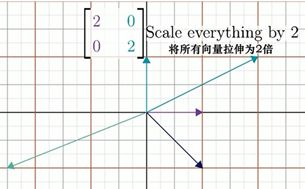
如果基向量是特征向量会发生什么?
比如,向量i变换变为原来的(-1)倍,而向量j变为原来的两倍,则变换对应的矩阵是[−1002] ,它们变换的倍数就是特征值-1和2,这个矩阵是一个对角阵。
除了对角元素,其它元素均为0的矩阵被称为对角阵。对于对角阵,所有的基向量就是其特征向量,而对角元素就是它们所属的特征值。对角阵有很多特点,例如矩阵方幂很容易计算,
[3002]100[xy]=[3100002100][xy]
如果矩阵的特征向量足够多,可以张成整个空间,那么可以通过变换坐标系,使得这些特征向量成为基向量。
矩阵[3012],取其特征向量作为列向量,构建基变换矩阵[10−11],在原矩阵右侧乘上基变换矩阵,左侧乘上逆矩阵,[10−11]−1[3012][10−11]。这个矩阵仍旧描述的是同一个线性变换,但是是从新的基向量构成的坐标系的角度来看的。
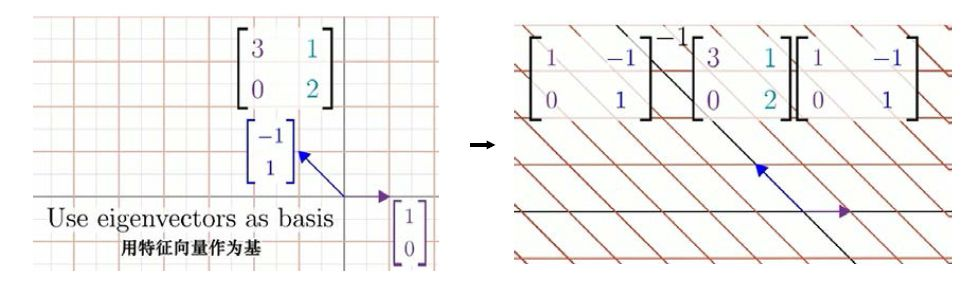
这样做的意义在于,这个矩阵会是对角阵,且对角元就是对应的特征值。
[10−11]−1[3012][10−11]=[3002]
它所处的坐标系的基向量在该线性变换中只进行了缩放。
一组特征向量构成的基向量的集合,称为一组“特征基”。计算矩阵[3012]的100次幂,可以先变换到特征基,在那个坐标系中对对角阵计算100次幂,然后再转换回标准坐标系。
并不是所有的变换都可以完成以上过程,例如剪切变换,它的特征向量不够多,不能张成整个空间。
线性变换
线性映射(Linear Mapping)线性映射也称为线性变换.是指从线性空间𝒳到线性空间𝒴的一个映射函数𝑓 ∶ 𝒳 → 𝒴,并满足:对于𝒳中任何两个向量𝒖和𝒗以及任何标量𝑐,有
- 𝑓(𝒖 + 𝒗) = 𝑓(𝒖) + 𝑓(𝒗)
- 𝑓(𝑐𝒗) = 𝑐𝑓(𝒗)
两个有限维欧氏空间的映射函数f:RN→RM可以表示为:
y=Ax≜⎣⎢⎢⎢⎡a11x1+a12x2+⋯+a1NxNa21x1+a22x2+⋯+a2NxN⋮aM1x1+aM2x2+⋯+aMNxN⎦⎥⎥⎥⎤
其中𝑨是一个由𝑀行𝑁列个元素排列成的矩形阵列,称为𝑀 × 𝑁的矩阵(Ma-trix):
A=⎣⎢⎢⎢⎡a11a21⋮aM1a12a22⋮aM2⋯⋯⋱⋯a1Na2N⋮aMN⎦⎥⎥⎥⎤
向量x∈RN和y∈RM为两个空间中的向量.𝒙和𝒚可以分别表示为𝑁 × 1的矩阵和𝑀 × 1的矩阵:
x=⎣⎢⎢⎢⎡x1x2⋮xN⎦⎥⎥⎥⎤,y=⎣⎢⎢⎢⎡y1y2⋮yM⎦⎥⎥⎥⎤
矩阵A∈RM×N定义了一个从空间RN到空间RM的线性映射
仿射变换
仿射变换(Affine Transformation)是指通过一个线性变换和一个平移,将一个向量空间变换成另一个向量空间的过程.
令A∈RN×N为𝑁 × 𝑁的实数矩阵,x∈RN是𝑁维向量空间中的点,仿射变换可以表示为
y=Ax+b
其中y=Ax+b为平移项.当𝒃 = 0时,仿射变换就退化为线性变换.
仿射变换可以实现线性空间中的旋转、平移、缩放变换.仿射变换不改变原始空间的相对位置关系,具有以下性质.
- 共线性(Collinearity)不变:在同一条直线上的三个或三个以上的点,在变换后依然在一条直线上;
- 比例不变:不同点之间的距离比例在变换后不变;
- 平行性不变:两条平行线在转换后依然平行;
- 凸性不变:一个凸集(Convex Set)在转换后依然是凸的.
矩阵运算
Hadamard积
矩阵𝑨和矩阵𝑩的Hadamard积(Hadamard Product)也称为逐点乘积,为𝑨和𝑩中对应的元素相乘.
[A⊙B]mn=amnbmn
Kronecker积
如果𝑨是𝑀×𝑁的矩阵,𝑩是𝑆×𝑇的矩阵,那么它们的Kronecker积(Kronecker Product)是一个𝑀𝑆 × 𝑁𝑇的矩阵
[A⊗B]=⎣⎢⎢⎢⎡a11Ba21B⋮aM1Ba12Ba22B⋮aM2B⋯⋯⋱⋯a1NBa2NB⋮aMNB⎦⎥⎥⎥⎤
外积
两个向量a∈RM和b∈RN的外积(Outer Product)是一个𝑀 × 𝑁的矩阵,定义为
a⊗b=⎣⎢⎢⎢⎡a1b1a2b1⋮aMb1a1b2a2b2⋮aMb2……⋱…a1bNa2bN⋮aMbN⎦⎥⎥⎥⎤=ab⊤
其中[a⊗b]mn=ambr
外积通常看作矩阵的Kronecker积的一种特例,但两者并不等价.⊗既可以表示Kro-necker积,也可以表示外积,其具体含义不同一般需要在上下文中说明.
迹
方块矩阵𝑨的对角线元素之和称为它的迹(Trace),记为𝑡𝑟(𝑨).尽管矩阵的乘法不满足交换律,但它们的迹相同,即𝑡𝑟(𝑨𝑩) = 𝑡𝑟(𝑩𝑨).
行列式
方块矩阵𝑨的行列式是一个将其映射到标量的函数,记作det(𝑨)或|𝑨|.行列式可以看作有向面积或体积的概念在欧氏空间中的推广.在𝑁维欧氏空间中,行列式描述的是一个线性变换对“体积”所造成的影响.
秩
一个矩阵𝑨的列秩是𝑨的线性无关的列向量数量,行秩是𝑨的线性无关的行向量数量.一个矩阵的列秩和行秩总是相等的,简称为秩(Rank).一个𝑀 × 𝑁的矩阵𝑨的秩最大为min(𝑀,𝑁).若
rank(A)=min(M,N),则称矩阵为满秩的.如果一个矩阵不满秩,说明其包含线性相关的列向量或行向量,其行列式为0.两个矩阵的乘积𝑨𝑩的秩rank(AB)≤min(rank(A),rank(B))
范数
矩阵的范数有很多种形式,其中常用的ℓ𝑝范数定义为
∥A∥p=(∑m=1M∑n=1N∣amn∣p)1/p
有时候我们可能也希望衡量矩阵的大小。在深度学习中,最常见的做法是使用 Frobenius 范数(Frobenius norm):
∥A∥F=∑i,jAi,j2
其类似于向量的L2范数。
矩阵求导
如果f是一元函数,则
其逐元向量函数为: (x)=(f(x1),f(x2),⋯,f(xn))T
其逐矩阵函数为:
f(X)=⎣⎢⎢⎢⎡f(x1,1)f(x2,1)⋮f(xm,1)f(x1,2)f(x2,2)⋮f(xm,2)⋯⋯⋱⋯f(x1,n)f(x2,n)⋮f(xm,n)⎦⎥⎥⎥⎤
其逐元导数分别为:
f′(x)=(f′(x1),f′(x2),⋯,f′(xn))T
f′(X)=⎣⎢⎢⎢⎡f′(x1,1)f′(x2,1)⋮f′(xm,1)f′(x1,2)f′(x2,2)⋮f′(xm,2)⋯⋯⋱⋯f′(x1,n)f′(x2,n)⋮f′(xm,n)⎦⎥⎥⎥⎤
各种类型的偏导数:
标量对向量(n维向量)的偏导数 :
∂v∂u=(∂v1∂u,∂v2∂u,⋯,∂vn∂u)T
对于𝑀维向量x∈RM和函数𝑦 = 𝑓(𝒙) ∈ ℝ,则𝑦关于𝒙的偏导数为:
∂x∂y=[∂x1∂y,⋯,∂xM∂y]⊤
标量对矩阵(m×n阶矩阵)的偏导数:
∂V∂u=⎣⎢⎢⎢⎢⎡∂V1,1∂u∂V2,1∂u⋮∂Vm,1∂u∂V1,2∂u∂V2,2∂u⋮∂Vm,2∂u⋯⋯⋱⋯∂V1,n∂u∂V2,n∂u⋮∂Vm,n∂u⎦⎥⎥⎥⎥⎤
也即∂X∂f=[∂Xij∂f],即f对X逐元素求导排成与X尺寸相同的矩阵.
向量(m维向量)对标量的偏导数:
∂v∂u=(∂v∂u1,∂v∂u2,⋯,∂v∂um)T
对于标量x∈R和函数y=f(x)∈RN,则𝒚关于𝑥的偏导数为
∂x∂y=[∂x∂y1,⋯,∂x∂yN]
向量(m维向量)对向量 (n维向量) 的偏导数(雅可比矩阵)
∂v∂u=⎣⎢⎢⎢⎡∂v1∂u1∂v1∂u2⋮∂v1∂um∂v2∂u1∂v2∂u2⋮∂v2∂um⋯⋯⋱⋯∂vn∂u1∂vn∂u2⋮∂vn∂um⎦⎥⎥⎥⎤
对于𝑀维向量x∈RM和函数y=f(x)∈RN,则𝑓(𝒙)关于𝒙的偏导数(分母布局)为
∂x∂f(x)=⎣⎢⎡∂x1∂y1⋮∂xM∂y1⋯⋱⋯∂x1∂yN⋮∂xM∂yN⎦⎥⎤∈RM×N
称为函数𝑓(𝒙)的雅可比矩阵(Jacobian Matrix)的转置.
对于𝑀维向量x∈RM和函数y=f(x)∈R,则𝑓(𝒙)关于𝒙的二阶偏导数(分母布局)为
H=∂x2∂2f(x)=⎣⎢⎢⎡∂x12∂2y⋮∂xM∂x1∂2y⋯⋱⋯∂x1∂xM∂2y⋮∂xM2∂2y⎦⎥⎥⎤∈RM×M
称为函数𝑓(𝒙)的Hessian矩阵,也写作∇2f(x),其中第𝑚,𝑛个元素为∂xm∂xn∂2y
矩阵(m×n阶矩阵)对标量的偏导数
∂v∂U=⎣⎢⎢⎢⎢⎡∂v∂U1,1∂v∂U2,1⋮∂v∂Um,1∂v∂U1,2∂v∂U2,2⋮∂v∂Um,2⋯⋯⋱⋯∂v∂U1,n∂v∂U2,n⋮∂v∂Um,n⎦⎥⎥⎥⎥⎤
dBdA=⎣⎡dx1dA1dy1dA1dz1dA1dx2dA2dy2dA2dz2dA2⎦⎤
对于向量A=[sinx−ysin3x−4y],可以对x求导,得到另一个向量,dxdA=[cosx3cos3x],如果A要对另一个向量求导,会得到一个矩阵。比如,另一个向量B=⎣⎡xyz⎦⎤,如果A(一个2×1的向量)要对B(一个3×1的向量)求导,会得到如下3×2 的矩阵:
dBdA=⎣⎡cosx−103cos3x−40⎦⎤
加法,乘法法则
若x∈RM,y=f(x)∈RN,z=g(x)∈RN,则:
∂x∂(y+z)=∂x∂y+∂x∂z∈RM×N
若x∈RM,y=f(x)∈RN,z=g(x)∈RN,则:
∂x∂y⊤Az=∂x∂yAz+∂x∂zA⊤y∈RM
若x∈RM,y=f(x)∈RS,z=g(x)∈RT,A∈RS×T 和x无关,则
∂x∂y⊤Az=∂x∂yAz+∂x∂zA⊤y∈RM
若x∈RM,y=f(x)∈R,z=g(x)∈RN,则
∂x∂yz=y∂x∂z+∂x∂yz⊤∈RM×N
链式法则
若x∈R,y=g(x)∈RM,z=f(y)∈RN,则
∂x∂z=∂x∂y∂y∂z∈R1×N
若x∈RM,y=g(x)∈RK,z=f(y)∈RN,则:
∂x∂z=∂x∂y∂y∂z∈RM×N
若X∈RM×N⋙ZEP,y=g(X)∈RK,z=f(y)∈R,则
∂xij∂z=∂xij∂y∂y∂z∈R
向量函数及其导数
对一个向量x有:
∂x∂x=I
∂x∂∥x∥2=2x
∂x∂Ax=A⊤
∂x∂x⊤A=A
向量和矩阵的导数满足乘法法则:
∂x∂xTa∂x∂AB==∂x∂aTx=a∂x∂AB+A∂x∂B
按位计算的向量函数及其导数
假设一个函数𝑓(𝑥)的输入是标量𝑥.对于一组𝐾个标量x1,⋯,xK,我们可以通过𝑓(𝑥)得到另外一组𝐾个标量z1,⋯,zK:
zk=f(xk),∀k=1,⋯,K
为了简便起见,我们定义x=[x1,⋯,xK]⊤,z=[z1,⋯,zK]⊤
z=f(x)
其中𝑓(𝒙)是按位运算的,即[f(x)]k=f(xk)
当𝑥为标量时,𝑓(𝑥)的导数记为𝑓′(𝑥).当输入为𝐾维向量x=[x1,⋯,xK]⊤,其导数为一个对角矩阵.
∂x∂f(x)=[∂xi∂f(xj)]K×K=⎣⎢⎢⎢⎡f′(x1)0⋮00f′(x2)⋮0⋯⋯⋱⋯00⋮f′(xK)⎦⎥⎥⎥⎤=diag(f′(x))
Logistic函数
Logistic函数定义为
logistic(x)=1+exp(−K(x−x0))L
其中exp(⋅)函数表示自然对数,x0是中心点,𝐿是最大值,𝐾是曲线的倾斜度.下图给出了几种不同参数的Logistic函数曲线.当𝑥趋向于−∞时,logistic(𝑥)接近于0;当𝑥趋向于+∞时,logistic(𝑥)接近于𝐿
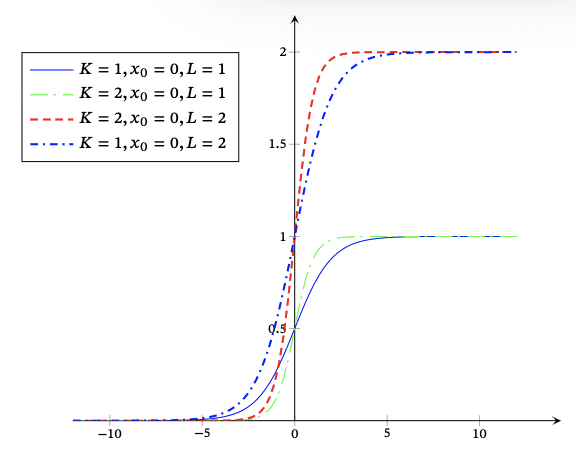
当参数为(𝑘 = 1,x0=0= 0,𝐿 = 1)时,Logistic函数称为标准Logistic函数,记为𝜎(𝑥)
σ(x)=1+exp(−x)1
标准Logistic函数在机器学习中使用得非常广泛,经常用来将一个实数空间的数映射到(0,1)区间
标准Logistic函数的导数为σ′(x)=σ(x)(1−σ(x)),当输入为𝐾维向量x=[x1,⋯,xK]⊤,其导数为σ′(x)=diag(σ(x)⊙(1−σ(x)))
Softmax函数
Softmax函数可以将多个标量映射为一个概率分布.对于𝐾个标量x1,⋯,xK,Softmax函数定义为zk=softmax(xk)=∑i=1Kexp(xi)exp(xk)
这样,我们可以将𝐾个标量x1,⋯,xK转换为一个分布:z1,⋯,zK,满足
zk∈(0,1)
∑k=1Kzk=1
为了简便起见,用𝐾维向量x=[x1;⋯;xK]来表示Softmax函数的输入,Softmax函数可以简写为:
z^=softmax(x)=∑k=1Kexp(xk)1⎣⎢⎡exp(x1)⋮exp(xK)⎦⎥⎤=∑k=1Kexp(xk)exp(x)=1K⊤exp(x)exp(x)
其中1K=[1,⋯,1]K×1,是𝐾维的全1向量.
Softmax函数的导数为
∂x∂softmax(x)=∂x∂(1K⊤exp(x)exp(x))
=1K⊤exp(x)1∂x∂exp(x)+∂x∂(1K⊤exp(x)1)(exp(x))⊤
=1K⊤exp(x)diag(exp(x))−((1K⊤exp(x))21)∂x∂(1K⊤exp(x))(exp(x))⊤
=1K⊤exp(x)diag(exp(x))−((1K⊤exp(x))21)diag(exp(x))1K(exp(x))⊤
=1K⊤exp(x)diag(exp(x))−((1K⊤exp(x))21)exp(x)(exp(x))⊤
=diag(1K⊤exp(x)exp(x))−1K⊤exp(x)exp(x)1K⊤exp(x)(exp(x))⊤
=diag(softmax(x))−softmax(x)softmax(x)⊤
矩阵类型
对角矩阵
一个𝑁 × 𝑁的对角矩阵𝑨也可以记为diag(𝒂),𝒂为一个𝑁维向量,并满足[A]nn=an
𝑁 × 𝑁的对角矩阵𝑨 =diag(𝒂)和𝑁维向量𝒃的乘积为一个𝑁维向量Ab=diag(a)b=a⊙b
正交矩阵
如果一个𝑁 × 𝑁的方块矩阵𝑨的逆矩阵等于其转置矩阵,即A⊤=A−1,则𝑨为正交矩阵(Orthogonal Matrix)
正交矩阵满足A⊤A=AA⊤=IN,即正交矩阵的每一行(列)向量和自身的内积为1,和其他行(列)向量的内积为0.
Gram矩阵
向量空间中一组向量a1,a2,⋯,aN的Gram矩阵(Gram Matrix)𝑮是内积的对称矩阵,其元素[G]mn=am⊤an
矩阵分解
一个矩阵通常可以用一些比较“简单”的矩阵来表示,称为矩阵分解(Ma-trix Decomposition, or Matrix Factorization)
特征分解
一个𝑁 × 𝑁的方块矩阵𝑨的特征分解(Eigendecomposition)定义为A=QΛQ−1,其中𝑸为𝑁 × 𝑁的方块矩阵,其每一列都为𝑨的特征向量,𝚲为对角矩阵,其每一个对角元素分别为𝑨的一个特征值.
如果𝑨为实对称矩阵,那么其不同特征值对应的特征向量相互正交.𝑨可以被分解为A=QΛQ⊤,其中𝑸为正交矩阵
奇异值分解
一个𝑀 ×𝑁的矩阵𝑨的奇异值分解(Singular Value Decomposition,SVD)定义为A=UΣV⊤,其中𝑼和𝑽分别为𝑀 × 𝑀和𝑁 × 𝑁的正交矩阵,𝚺为𝑀 × 𝑁的矩形对角矩阵.𝚺对角线上的元素称为奇异值(Singular Value),一般按从大到小排列.
根据上述公式,AA⊤=UΣV⊤VΣU⊤=UΣ2U⊤,A⊤A=VΣU⊤UΣV⊤=VΣ2V⊤,因此,𝑼和𝑽分别为AA⊤和A⊤A的特征向量,𝑨的非零奇异值为AA⊤或A⊤A的非零特征值的平方根.
一个向量x∈RN左乘一个正交矩阵RN×N,可以看作对𝒙进行坐标旋转,即𝑼中的行向量构成一组正交基向量.
由于一个大小为𝑀 × 𝑁的矩阵𝑨可以表示空间RN到空间RM的一种线性映射,因此奇异值分解相当于将这个线性映射分解为3个简单操作.
- 先使用𝑽在原始空间中进行坐标旋转.
- 用𝚺对旋转后的每一维进行缩放.如果𝑀 > 𝑁,则补𝑀 − 𝑁个0;相反,如果𝑀 < 𝑁,则舍去最后的𝑁 − 𝑀维.
- 使用𝑼进行再一次的坐标旋转.
矩阵的基本子空间
向量空间的子空间
若S是向量空间V的非空子集,且S满足以下条件:
- 对任意实数a,若x∈S,则ax∈S
- 若x∈S且y∈S,则x+y∈S
则S称为V的子空间
设v1,v2,⋯,vn为向量空间V中的向量,则其线性组合a1v1+a2v2+⋯+anvn构成V的子空间,称为v1,v2,⋯,vn张成(span)的子空间,记作span(v1,v2,⋯,vn),如果span{v1,v2,⋯,vn}=V,就说v1,v2,⋯,vn张成V.
向量空间的基和维数
向量空间V中的向量v1,v2,⋯,vn称为空间V的基,如果满足条件
- v1,v2,⋯,vn 线性无关
- v1,v2,⋯,vn 张成V
矩阵的行空间和列空间
设A为一m×n矩阵,A的每一行可看作是Rn中的一个向量,称为A的行向量,类似的,A的每一列可以看作是Rm中的一个向量,称为A的列向量。
设A为一m×n矩阵,则由A的行向量张成的Rn子空间,称为A的行空间。由A的列向量张成的Rm子空间,称为A的列空间。
矩阵A的行空间的维数等于列空间的维数。3
一个矩阵行空间的维数等于矩阵的秩。
矩阵的零空间
设A为m×n矩阵,令N(A)为齐次方程组Ax=0的所有解的集合,则N(A)为Rn的一个子空间,称为A的零空间,即N(A)={x∈Rn∣Ax=0}。
一个矩阵的零空间的维数称为矩阵的零度。
秩-零度定理。设A为一m×n矩阵,则A的秩与A的零度之和为%n%.
子空间的正交补
设X和Y的为Rn的子空间,若对每一x∈X和y∈Y都满足xTy=0,则称X和Y是正交的,记作X⊥Y
令Y为Rn的子空间,Rn中与Y中的每一向量正交的向量集合记作Y⊥,即Y⊥={x∈Rn∣xTy=0,∀y∈Y},集合Y⊥称为Y的正交补。
若Y为Rn的子空间,则Y⊥也是Rn的子空间。
矩阵的基本子空间
设A为一m×n矩阵,可以将A看成是将Rn映射到Rm的线性变换,一个向量z∈Rm在A的列空间的充要条件是存在x∈Rn,使得z=Ax,这样A的列空间和A的值域是相同的,记A的值域为R(A),则R(A)={z∈Rm∣∃x∈Rn,z=Ax}=A的列空间。
一个向量y∈Rn在A的行空间的充要条件是存在x∈Rm,使得y=ATx,这样A的行空间和AT的值域R(AT)是相同的,则R(AT)={y∈Rn∣∃x∈Rm,y=ATx}=A的行空间。
矩阵A有四个基本子空间:列空间,行空间,零空间,A的转置零空间(左零空间)。有下面的定理成立。
若A为一m×n矩阵,则N(A)=R(AT)⊥,且N(AT)=R(A)⊥
数学分析
泰勒公式
如果函数𝑓(𝑥)在𝑎点处𝑛次可导(𝑛 ≥ 1),在一个包含点𝑎的区间上的任意𝑥,都有:
f(x)=f(a)+1!1f′(a)(x−a)+2!1f(2)(a)(x−a)2+⋯+n!1f(n)(a)(x−a)n+Rn(x)
其中f(n)(a)表示函数𝑓(𝑥)在点𝑎的𝑛阶导数,公式中的多项式部分称为函数𝑓(𝑥)在𝑎处的𝑛阶泰勒展开式,剩余的Rn(x)是泰勒公式的余项,是(x−a)n的高阶无穷小.
概率论
事件和概率
随机变量
离散随机变量
伯努利分布:在一次试验中,事件A出现的概率为𝜇,不出现的概率为1 − 𝜇.若用变量𝑋表示事件𝑨出现的次数,则𝑋的取值为0和1,其相应的分布为p(x)=μx(1−μ)(1−x),又名两点分布或者0-1分布.
二项分布:在N次伯努利试验中,若以变量𝑋表示事件A出现的次数,则𝑋的取值为{0,⋯,𝑁},其相应的分布为二项分布(Binomial Distribution),P(X=k)=(Nk)μk(1−μ)N−k,k=0,⋯,N,其中(Nk)为二项式系数,表示从𝑁个元素中取出𝑘个元素而不考虑其顺序的组合的总数
排列组合是组合学最基本的概念.排列是指从给定个数的元素中取出指定个数的元素进行排序.𝑁个不同的元素可以有N!种不同的排列方式,即𝑁的阶乘.N!≜N×(N−1)×⋯×3×2×1.如果从𝑁个元素中取出𝑘个元素,这𝑘个元素的排列总数为PNk≜N×(N−1)×⋯×(N−k+1)=(N−k)!N!,组合则是指从给定个数的元素中仅仅取出指定个数的元素,不考虑排序.从𝑁个元素中取出𝑘个元素,这𝑘个元素可能出现的组合数为CNk≜(Nk)=k!PNk=k!(N−k)!N!
连续随机变量
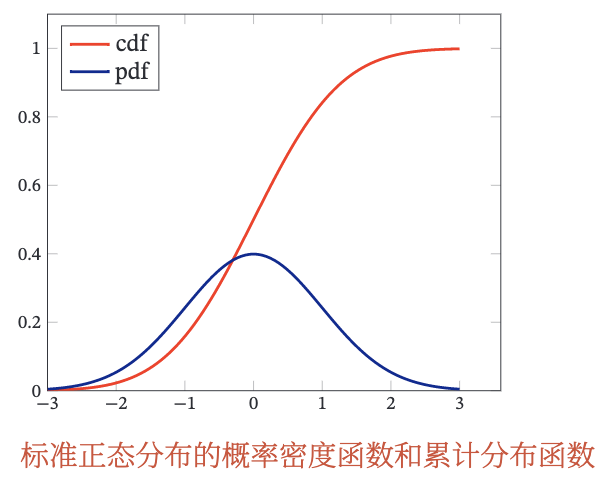
正态分布(Normal Distribution),又名高斯分布(Gaussian Distri-bution),是自然界最常见的一种分布,并且具有很多良好的性质,在很多领域都有非常重要的影响力,其概率密度函数为p(x)=2πσ1exp(−2σ2(x−μ)2),其中𝜎 > 0,𝜇和𝜎均为常数.若随机变量𝑋服从一个参数为𝜇和𝜎的概率分布,简记为X∼N(μ,σ2),当𝜇 = 0,𝜎 = 1时,称为标准正态分布。
采用正态分布在很多应用中都是一个明智的选择。当我们由于缺乏关于某个实数上分布的先验知识而不知道该选择怎样的形式时,正态分布是默认的比较好的选
择,其中有两个原因。
第一,我们想要建模的很多分布的真实情况是比较接近正态分布的。 中心极限定理(central limit theorem)说明很多独立随机变量的和近似服从正态分布。这意味着在实际中,很多复杂系统都可以被成功地建模成正态分布的噪声,即使系统可以被分解成一些更结构化的部分。
第二,在具有相同方差的所有可能的概率分布中,正态分布在实数上具有最大的不确定性。因此,我们可以认为正态分布是对模型加入的先验知识量最少的分布。
累积分布函数
对于一个随机变量𝑋,其累积分布函数(Cumulative Distribution Func-tion,CDF)是随机变量𝑋的取值小于等于𝑥的概率cdf(x)=P(X≤x),以连续随机变量𝑋为例,累积分布函数定义为cdf(x)=∫−∞xp(t)dt,其中𝑝(𝑥)为概率密度函数。
随机向量
随机向量是指一组随机变量构成的向量.如果X1,X2,⋯,XK为𝐾个随机变量,那么称X=[X1,X2,⋯,XK]为一个𝐾维随机向量.一维随机向量即随机变量.随机向量也分为离散随机向量和连续随机向量。
离散随机向量
离散随机向量的联合概率分布(Joint Probability Distribution)为P(X1=x1,X2=x2,⋯,XK=xK)=p(x1,x2,⋯,xK),其中xk∈Ωk为变量Xk的取值,Ωk为变量Xk的样本空间
和离散随机变量类似,离散随机向量的概率分布满足
p(x1,x2,⋯,xK)≥0,∀x1∈Ω1,x2∈Ω2,⋯,xK∈ΩK
∑x1∈Ω1∑x2∈Ω2⋯∑xK∈ΩKp(x1,x2,⋯,xK)=1
一个最常见的离散向量概率分布为多项分布(Multinomial Distri-bution).多项分布是二项分布在随机向量的推广.假设一个袋子中装了很多球,总共有𝐾个不同的颜色.我们从袋子中取出𝑁个球.每次取出一个球时,就在袋子中放入一个同样颜色的球.这样保证同一颜色的球在不同试验中被取出的概率是相等的.令𝑿为一个𝐾维随机向量,每个元素Xk(k=1,⋯,K)为取出的𝑁个球中颜色为𝑘的球的数量,则𝑋服从多项分布,其概率分布为
p(x1,…,xK∣μ)=x1!⋯xK!N!μ1x1⋯μKxK
其中μ=[μ1,⋯,μK]⊤,分别为每次抽取的球的颜色为1,⋯,𝐾的概率,x1,⋯,xK为非负整数,并且满足∑k=1Kxk=N。
多项分布的概率分布也可以用gamma函数表示:
p(x1,⋯,xK∣μ)=∏kΓ(xk+1)Γ(∑kxk+1)∏k=1Kμkxk
其中Γ(z)=∫0∞exp(t)tz−1dt为gamma函数,这种表示形式和狄利克雷分布类似,而狄利克雷分布可以作为多项分布的共轭先验。
连续随机向量
一个𝐾维连续随机向量𝑿的联合概率密度函数(Joint Probability DensityFunction)满足
p(x)=p(x1,⋯,xK)≥0
∫−∞+∞⋯∫−∞+∞p(x1,⋯,xK)dx1⋯dxK=1
使用最广泛的连续随机向量分布为多元正态分布(MultivariateNormal Distribution),也称为多元高斯分布(Multivariate Gaussian Distribu-tion).若𝐾维随机向量X=[X1,…,XK]⊤服从𝐾元正态分布,其密度函数为
p(x)=(2π)K/2∣Σ∣1/21exp(−21(x−μ)⊤Σ−1(x−μ))
其中μ∈RK为多元正态分布的均值向量,Σ∈RK×K为多元正态分布的协方差矩阵,|𝚺|表示𝚺的行列式
如果一个多元高斯分布的协方差矩阵简化为Σ=σ2I,即每一个维随机变量都独立并且方差相同,那么这个多元高斯分布称为各向同性高斯分布(Isotropic Gaussian Distribution)。
如果一个𝐾维随机向量𝑿服从狄利克雷分布(Dirichlet Distri-bution),其密度函数为
p(x∣α)=Γ(α1)⋯Γ(αK)Γ(α0)∏k=1Kxkαk−1
其中α=[α1,…,αK]⊤为狄利克雷分布的参数。
共轭分布
假设变量x服从分布P(x∣Θ),其中Θ为参数,X={x1,x2,…,xm},为变量x的观测样本,假设参数Θ服从先验分布Π(Θ),r若由先验分布Π(Θ)和抽样分布P(x∣Θ)决定的后验分布F(Θ∣X)与Π(Θ)是同种类型的分布,则称先验分布Π(Θ)为分布P(x∣Θ)或P(X∣Θ)的共轭分布。
先验分布反映了某种先验信息,后验分布既反映了先验分布提供的信息、又反映了样本提供的信息。当先验分布与抽样分布共轭时,后验分布与先验分布属于同种类型,这意味着先验信息与样本提供的信息具有某种同一性。于是,若使用后验分布作为进一步抽样的先验分布,则新的后验分布仍将属于同种类型。因此,共轭分布在不少情形下会使问题得以简化。
边际分布
对于二维离散随机向量(𝑋,𝑌),假设𝑋取值空间为Ωx,𝑌取值空间为Ωy,其联合概率分布满足:
p(x,y)≥0,∑x∈Ωx∑y∈Ωyp(x,y)=1
对于联合概率分布𝑝(𝑥,𝑦),我们可以分别对𝑥和𝑦进行求和
对于固定的𝑥
∑y∈Ωyp(x,y)=p(x)
对于固定的𝑦
∑x∈Ωxp(x,y)=p(y)
由离散随机向量(𝑋,𝑌)的联合概率分布,对𝑌的所有取值进行求和得到𝑋的概率分布;而对𝑋的所有取值进行求和得到𝑌的概率分布.这里𝑝(𝑥)和𝑝(𝑦)就称为𝑝(𝑥,𝑦)的边际分布(Marginal Distribution)
对于二维连续随机向量(𝑋,𝑌),其边际分布为
p(x)=∫−∞+∞p(x,y)dy
p(y)=∫−∞+∞p(x,y)dx
一个二元正态分布的边际分布仍为正态分布。
条件概率分布
对于离散随机向量(𝑋,𝑌),已知𝑋 = 𝑥的条件下,随机变量𝑌 = 𝑦的条件概率(Conditional Probability)为p(y∣x)≜P(Y=y∣X=x)=p(x)p(x,y),这个公式定义了随机变量𝑌关于随机变量𝑋的条件概率分布(ConditionalProb-ability Distribution),简称条件分布.
对于二维连续随机向量(𝑋,𝑌),已知𝑋 = 𝑥的条件下,随机变量𝑌 = 𝑦的条件概率密度函数(Conditional Probability Density Function)为p(y∣x)=p(x)p(x,y),同理,已知𝑌 = 𝑦的条件下,随机变量𝑋 = 𝑥的条件概率密度函数为p(x∣y)=p(y)p(x,y)
贝叶斯定理
两个条件概率𝑝(𝑦|𝑥)和𝑝(𝑥|𝑦)之间的关系为p(y∣x)=p(x)p(x∣y)p(y)
独立与条件独立
对于两个离散(或连续)随机变量𝑋和𝑌,如果其联合概率(或联合概率密度函数)𝑝(𝑥,𝑦)满足p(x,y)=p(x)p(y),则称𝑋和𝑌互相独立(Independence),记为𝑋⟂⟂𝑌
对于三个离散(或连续)随机变量𝑋、𝑌和𝑍,如果条件概率(或联合概率密度函数)𝑝(𝑥,𝑦|𝑧)满足p(x,y∣z)=p(x∣z)p(y∣z),则称在给定变量𝑍时,𝑋和𝑌条件独立(Conditional Independence),记为𝑋⟂⟂𝑌|𝑍
期望和方差
随机变量𝑋的方差(Variance)用来定义它的概率分布的离散程度:
var(X)=E[(X−E[X])2]
随机变量𝑋的方差也称为它的二阶矩。var(X)则称为𝑋的根方差或标准差。
两个连续随机变量𝑋和𝑌的协方差(Covariance)用来衡量两个随机变量的分布之间的总体变化性,定义为
cov(X,Y)=E[(X−E[X])(Y−E[Y])]
协方差经常也用来衡量两个随机变量之间的线性相关性.如果两个随机变量的协方差为0,那么称这两个随机变量是线性不相关.这里的线性相关和线性代数中的线性相关含义不同.两个随机变量之间没有线性相关性,并非表示它们之间是独立的,可能存在某种非线性的函数关系.反之,如果𝑋与𝑌是统计独立的,那么它们之间的协方差一定为0.
协方差的绝对值如果很大则意味着变量值变化很大并且它们同时距离各自的均值很远。如果协方差是正的,那么两个变量都倾向于同时取得相对较大的值。如果协方差是负的,那么其中一个变量倾向于取得相对较大的值的同时,另一个变量倾向于取得相对较小的值,反之亦然。
两个𝑀和𝑁维的连续随机向量𝑿和𝒀,它们的协方差(Covari-ance)为𝑀 × 𝑁的矩阵,定义为
cov(X,Y)=E[(X−E[X])(Y−E[Y])⊤]
协方差矩阵cov(𝑿,𝒀)的第(𝑚,𝑛)个元素等于随机变量Xm和Yn的协方差.两个随机向量的协方差cov(𝑿,𝒀)与cov(𝒀,𝑿)互为转置关系.
如果两个随机向量的协方差矩阵为对角矩阵,那么称这两个随机向量是无关的。
单个随机向量𝑿的协方差矩阵定义为
cov(X)=cov(X,X)
Jensen不等式
如果𝑋是随机变量,𝑔是凸函数,则g(E[X])≤E[g(X)],等式当且仅当𝑋是一个常数或𝑔是线性时成立,这个性质称为Jensen不等式。特别地,对于凸函数𝑔定义域上的任意两点x1,x2和一个标量λ∈[0,1],有
g(λx1+(1−λ)x2)≤λg(x1)+(1−λ)g(x2)
即凸函数𝑔上的任意两点的连线位于这两点之间函数曲线的上方。
大数定律
大数定律(Law of Large Numbers)是指𝑁个样本X1,⋯,XN是独立同分布的,即E[X1]=⋯=E[XN]=μ,那么其均值XˉN=N1(X1+⋯+XN)收敛于期望值𝜇,即XˉN→μ for N→∞
中心极限定理
设随机变量X1,X2,⋯,Xn,⋯相互独立,服从同一分布,且具有数学期望和方差:E(Xk)=μ,D(Xk)=σ2>0(k=1,2,⋯),则随机变量之和∑k=1nXk的标准化变量:
Yn=D(∑k=1nXk)∑k=1nXk−E(∑k=1nXk)=nσ∑k=1nXk−nμ
的分布函数Fn(x)对于任意x满足n→∞limFn(x)=n→∞limP{nσ∑k=1nXk−nμ⩽x}=∫−∞x2π1e−ı/2dt=Φ(x)
这就是说,均值为μ,方差为σ2>0的独立同分布的随机变量X1,X2,⋯,Xn∑k=1nXk的标准化变量,当n充分大时,有
nσ∑k=1nXk−nμ~N(0,1)。
上式左端改写成σ/nn1∑k=1nXk−μ=σ/nXˉ−μ,上述结果可写成,当n充分大时,σ/nXˉ−μ$N(0,1)$或$\bar{X}$N(μ,σ2/n)
这就是说,均值为μ,方差为σ2>0的独立同分布随机变量,X1,X2,⋯,Xn的算术平均Xˉ=n1∑k=1nXk,当n充分大时,近似地服从均值为μ,方差为σ2/n的正态分布。
随机过程
随机过程(Stochastic Process)是一组随机变量Xt的集合,其中𝑡属于一个索引(index)集合𝒯.索引集合𝒯可以定义在时间域或者空间域,但一般为时间域,以实数或正数表示.当𝑡为实数时,随机过程为连续随机过程;当𝑡为整数时,为离散随机过程.日常生活中的很多例子包括股票的波动、语音信号、身高的变化等都可以看作随机过程.常见的和时间相关的随机过程模型包括伯努利过程、随机游走(Random Walk)、马尔可夫过程等.和空间相关的随机过程通常称为随机场(Random Field).比如一张二维的图片,每个像素点(变量)通过空间的位置进行索引,这些像素就组成了一个随机过程。
马尔可夫过程
在随机过程中,马尔可夫性质(Markov Property)是指一个随机过程在给定现在状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态.以离散随机过程为例,假设随机变量X0,X1,⋯,XT构成一个随机过程.这些随机变量的所有可能取值的集合被称为状态空间(State Space).如果Xt+1对于过去状态的条件概率分布仅是Xt的一个函数,则
P(Xt+1=xt+1∣X0:t=x0:t)=P(Xt+1=xt+1∣Xt=xt)
其中X0:t表示变量集合X0,X1,⋯,Xt,x0:t为在状态空间中的状态序列。
马尔可夫性质也可以描述为给定当前状态时,将来的状态与过去状态是条件独立的。
马尔可夫链
离散时间的马尔可夫过程也称为马尔可夫链(Markov Chain).如果一个马尔可夫链的条件概率P(Xt+1=s∣Xt=s′)=mss′,只和状态𝑠和𝑠′相关,和时间𝑡无关,则称为时间同质的马尔可夫链(Time-Homogeneous Markov Chain),其中mSS′称为状态转移概率.如果状态空间大小𝐾是有限的,状态转移概率可以用一个矩阵M∈RK×K表示,称为状态转移矩阵(Transition Matrix),其中元素mij表示状态Si转移到状态Sj的概率。
假设状态空间大小为𝐾,向量π=[π1,⋯,πK]⊤为状态空间中的一个分布,满足0≤πk≤1和∑k=1Kπk=1。
对于状态转移矩阵为𝑴的时间同质的马尔可夫链,若存在一个分布𝝅满足π=Mπ,则称分布𝝅为该马尔可夫链的平稳分布(Stationary Distribution).根据特征向量的定义可知,𝝅为矩阵𝑴的(归一化)的对应特征值为1的特征向量。
如果一个马尔可夫链的状态转移矩阵𝑴满足所有状态可遍历性以及非周期性,那么对于任意一个初始状态分布π(0),在经过一定时间的状态转移之后,都会收敛到平稳分布,即π=limT→∞MTπ(0)。
细致平稳条件(Detailed Balance Condition):给定一个状态空间中的分布π∈[0,1]K,如果一个状态转移矩阵为M∈RK×K的马尔可夫链满足πimij=πjmji,∀1≤i,j≤K,则该马尔可夫链经过一定时间的状态转移后一定会收敛到分布𝝅.细致平稳条件只是马尔可夫链收敛的充分条件,不是必要条件.细致平稳条件保证了从状态𝑖转移到状态𝑗的数量和从状态𝑗转移到状态𝑖的数量相一致,互相抵消,所以数量不发生改变.
高斯过程
高斯过程(Gaussian Process)也是一种应用广泛的随机过程模型.假设有一组连续随机变量X0,X1,⋯,XT,如果由这组随机变量构成的任一有限集合Xt1,⋯,tN=[Xt1,⋯,XtN]⊤,1≤N≤T都服从一个多元正态分布,那么这组随机变量为一个随机过程.高斯过程也可以定义为:如果Xt1,⋯,tN的任一线性组合都服从一元正态分布,那么这组随机变量为一个随机过程.
高斯过程回归(Gaussian Process Regression)是利用高斯过程来对一个函数分布进行建模.和机器学习中参数化建模(比如贝叶斯线性回归)相比,高斯过程是一种非参数模型,可以拟合一个黑盒函数,并给出拟合结果的置信度。
假设一个未知函数𝑓(𝒙)服从高斯过程,且为平滑函数.如果两个样本x1,x2比较接近,那么对应的f(x1),f(x2)也比较接近.假设从函数𝑓(𝒙)中采样有限个样本X=[x1,x2,⋯,xN],这𝑁个点服从一个多元正态分布,
[f(x1),f(x2),⋯,f(xN)]⊤∼N(μ(X),K(X,X))
其中μ(X)=[μ(x1),μ(x2),⋯,μ(xN)]⊤是均值向量,K(X,X)=[k(xi,xj)]N×N是协方差矩阵,k(xi,xj)为核函数,可以衡量两个样本的相似度。
在高斯过程回归中,一个常用的核函数是平方指数(Squared Exponential)核函数:
k(xi,xj)=exp(2l2−∥xi−xj∥2)
其中𝑙为超参数.当xi和xj越接近,其函数值越大,表明f(xi)和f(xj)越相关.
信息论
自信息和熵
自信息(Self Information)表示一个随机事件所包含的信息量.一个随机事件发生的概率越高,其自信息越低.如果一个事件必然发生,其自信息为0
对于一个随机变量𝑋(取值集合为𝒳,概率分布为𝑝(𝑥),𝑥 ∈ 𝒳),当𝑋 = 𝑥时的自信息𝐼(𝑥)定义为I(x)=−logp(x),对于分布为𝑝(𝑥)的随机变量𝑋,其自信息的数学期望,即熵𝐻(𝑋)定义为(𝐻(𝑋)也 经 常 写 作𝐻(𝑝)):
H(X)=EX[I(x)]=EX[−logp(x)]=−x∈X∑p(x)logp(x)
熵越高,则随机变量的信息越多;熵越低,则随机变量的信息越少.如果变量𝑋当且仅当在𝑥时𝑝(𝑥) = 1,则熵为0.也就是说,对于一个确定的信息,其熵为0,信息量也为0.如果其概率分布为一个均匀分布,则熵最大.
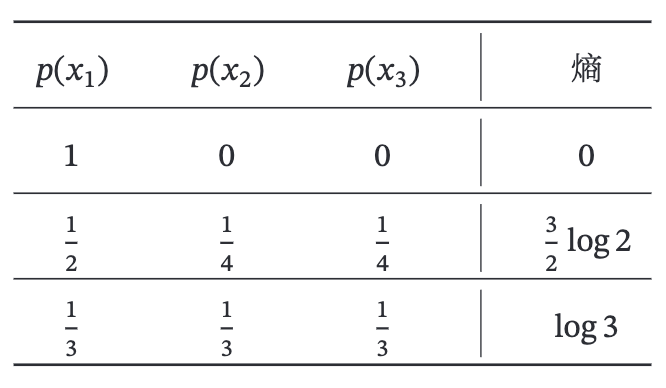
假设一个随机变量𝑋有三种可能值x1,x2,x3,不同概率分布对应的熵如下:
熵编码
在对分布𝑝(𝑥)的符号进行编码时,熵𝐻(𝑝)也是理论上最优的平均编码长度,这种编码方式称为熵编码(Entropy Encoding)
联合熵和条件熵
对于两个离散随机变量𝑋和𝑌,假设𝑋取值集合为𝒳;𝑌取值集合为𝒴,其联合概率分布满足为𝑝(𝑥,𝑦),则𝑋和𝑌的联合熵(Joint Entropy)为
H(X,Y)=−∑x∈x∑y∈yp(x,y)logp(x,y)
𝑋和𝑌的条件熵(Conditional Entropy)为:
H(X∣Y)=−x∈x∑y∈Y∑p(x,y)logp(x∣y)=−x∈X∑y∈Y∑p(x,y)logp(y)p(x,y)
根据其定义,条件熵也可以写为H(X∣Y)=H(X,Y)−H(Y)
互信息
互信息(Mutual Information)是衡量已知一个变量时,另一个变量不确定性的减少程度.两个离散随机变量𝑋和𝑌的互信息定义为
I(X;Y)=∑x∈x∑y∈yp(x,y)logp(x)p(y)p(x,y)
互信息的一个性质为:
I(X;Y)=H(X)−H(X∣Y)=H(Y)−H(Y∣X)
如果变量𝑋和𝑌互相独立,它们的互信息为零.
交叉熵和散度
交叉熵
对于分布为𝑝(𝑥)的随机变量,熵𝐻(𝑝)表示其最优编码长度.交叉熵(CrossEntropy)是按照概率分布𝑞的最优编码对真实分布为𝑝的信息进行编码的长度,定义为H(p,q)=Ep[−logq(x)]=−x∑p(x)logq(x)
在给定𝑝的情况下,如果𝑞和𝑝越接近,交叉熵越小;如果𝑞和𝑝越远,交叉熵就越大.
KL散度
KL散度(Kullback-Leibler Divergence),也叫KL距离或相对熵(RelativeEntropy),是用概率分布𝑞来近似𝑝时所造成的信息损失量.KL散度是按照概率分布𝑞的最优编码对真实分布为𝑝的信息进行编码,其平均编码长度(即交叉熵)𝐻(𝑝,𝑞)和𝑝的最优平均编码长度(即熵)𝐻(𝑝)之间的差异.对于离散概率分布𝑝和𝑞,从𝑞到𝑝的KL散度定义为
KL(p,q)=H(p,q)−H(p)=x∑p(x)logq(x)p(x)
其中为了保证连续性,定义0log00=0,0logq0=0。
KL散度总是非负的,KL(𝑝,𝑞) ≥ 0,可以衡量两个概率分布之间的距离.KL散度只有当𝑝 = 𝑞时,KL(𝑝,𝑞) = 0.如果两个分布越接近,KL散度越小;如果两个分布越远,KL散度就越大.但KL散度并不是一个真正的度量或距离,一是KL散度不满足距离的对称性,二是KL散度不满足距离的三角不等式性质
JS散度
JS散度(Jensen-Shannon Divergence)是一种对称的衡量两个分布相似度的度量方式,定义为JS(p,q)=21KL(p,m)+21KL(q,m),
其中m=21(p+q)。
JS散度是KL散度一种改进.但两种散度都存在一个问题,即如果两个分布𝑝,𝑞没有重叠或者重叠非常少时,KL散度和JS散度都很难衡量两个分布的距离。
Wasserstein距离
Wasserstein距离(Wasserstein Distance)也用于衡量两个分布之间的距离.对于两个分布q1,q2,pth -Wasserstein距离定义为
Wp(q1,q2)=(infγ(x,y)∈Γ(q1,q2)E(x,y)∼γ(x,y)[d(x,y)p])p1
其中Γ(q1,q2)是边际分布为q1和q2的所有可能的联合分布集合,d(x,y)为𝑥和𝑦的距离,比如ℓp距离等。
如果将两个分布看作两个土堆,联合分布γ(x,y)看作从土堆q1的位置𝑥到土堆q2的位置𝑦的搬运土的数量
∑xγ(x,y)=q2(y)
∑yγ(x,y)=q1(x)
q1和q2为γ(x,y)的两个边际分布。
E(x,y)∼γ(x,y)[d(x,y)p]可以理解为在联合分布𝛾(𝑥,𝑦)下把形状为q1,的土堆搬运到形状为q2的工作量,
E(x,y)∼γ(x,y)[d(x,y)p]=∑(x,y)γ(x,y)d(x,y)p
其中从土堆q1中的点𝑥到土堆q2中的点𝑦的移动土的数量和距离分别为𝛾(𝑥,𝑦)和d(x,y)p因此,Wasserstein距离可以理解为搬运土堆的最小工作量,也称为推土机距离(Earth-Mover’s Distance,EMD),图E.1给出了两个离散变量分布的Wasserstein距离示例.图E.1c中同颜色方块表示在分布q1中为相同位置。
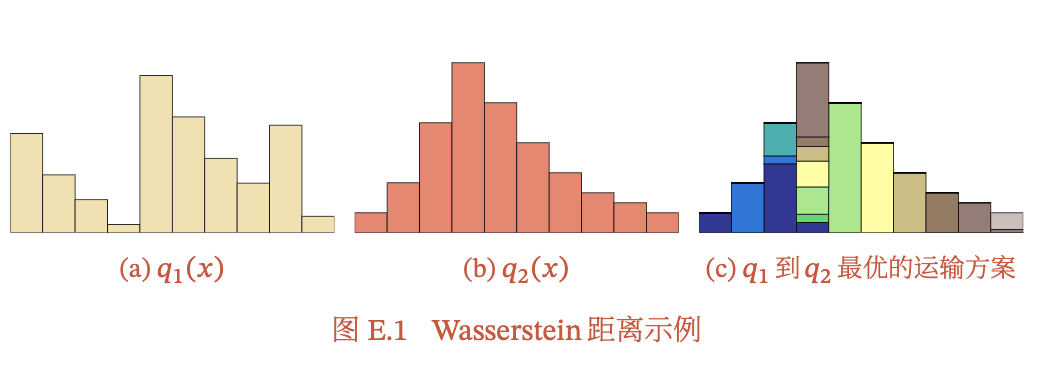
Wasserstein距离相比KL散度和JS散度的优势在于:即使两个分布没有重叠或者重叠非常少,Wasserstein距离仍然能反映两个分布的远近.
对于RD空间中的两个高斯分布p=N(μ1,Σ1)和q=N(μ2,Σ2),它们的2nd -Wasserstein,W2(p,q)=∥μ1−μ2∥22+tr(Σ1+Σ2−2(Σ21/2Σ1Σ21/2)1/2)。
当两个分布的方差为0时,2nd− Wasserstein距离等价于欧氏距离。
最优化
如果目标函数或任何一个约束函数为非线性函数,则该问题为非线性规划(Nonlinear Programming)问题。
在非线性优化问题中,有一类比较特殊的问题是凸优化(Convex Optimiza-tion)问题.在凸优化问题中,变量𝒙的可行域为凸集(Convex Set),即对于集合中任意两点,它们的连线全部位于集合内部.目标函数𝑓也必须为凸函数,即满足
f(αx+(1−α)y)≤αf(x)+(1−α)f(y),∀α∈[0,1]
凸优化问题是一种特殊的约束优化问题,需满足目标函数为凸函数,并且等式约束函数为线性函数,不等式约束函数为凸函数.
优化算法
优化问题一般都可以通过迭代的方式来求解:通过猜测一个初始的估计x0,然后不断迭代产生新的估计x1,x2,⋯xt,希望xt最终收敛到期望的最优解x∗,一个好的优化算法应该是在一定的时间或空间复杂度下能够快速准确地找到最优解.同时,好的优化算法受初始猜测点的影响较小,通过迭代能稳定地找到最优解x∗,然后迅速收敛于x∗。
优化算法中常用的迭代方法有线性搜索和置信域方法等.线性搜索的策略是寻找方向和步长,具体算法有梯度下降法、牛顿法、共轭梯度法等
全局最小解和局部最小解
对于很多非线性优化问题,会存在若干个局部最小值(Local Minima),其对应的解称为局部最小解(Local Minimizer).局部最小解也称为局部最小值点,或更一般性地称为局部最优解.局部最小解x∗定义为:存在一个𝛿 > 0,对于所有的满足∥x−x∗∥≤δ的𝒙,都有f(x∗)≤f(x).也就是说,在x∗的邻域内,所有的函数值都大于或者等于f(x∗)。
对于所有的x∈D,都有f(x∗)≤f(x)成立,则x∗为全局最小解(GlobalMinimizer)
求局部最小解一般是比较容易的,但很难保证其为全局最小解.对于线性规划或凸优化问题,局部最小解就是全局最小解.
要确认一个点x∗是否为局部最小解,通过比较它的邻域内有没有更小的函数值是不现实的.如果函数f(x)是二次连续可微的,我们可以通过检查目标函数在点x∗和Hessian矩阵∇2f(x∗)来判断。
局部最小解的一阶必要条件:如果x∗为局部最小解并且函数𝑓在x∗的邻域内一阶可微,则在∇f(x∗)=0。
函数𝑓(𝒙)的一阶偏导数为0的点也称为驻点(Stationary Point)或临界点(Critical Point).驻点不一定为局部最小解.
局部最小解的二阶必要条件:如果x∗为局部最小解并且函数𝑓在x∗的邻域内二阶可微,则在∇f(x∗)=0,∇2f(x∗)为半正定矩阵.
梯度下降法
对于函数𝑓(𝒙),如果𝑓(𝒙)在点𝒙𝑡附近是连续可微的,那么𝑓(𝒙)下降最快的方向是𝑓(𝒙)在xt点的梯度方法的反方向
根据泰勒一阶展开公式,有
f(xt+1)=f(xt+Δx)≈f(xt)+Δx⊤∇f(xt)
要使得f(xt+1)<f(xt),就得使Δx⊤∇f(xt)<0,我们取Δx=−α∇f(xt)。如果𝛼 > 0为一个够小数值时,那么f(xt+1)<f(xt)成立,这样我们就可以从一个初始值x0出发,通过迭代公式xt+1=xt−αt∇f(xt),t≥0,生成序列x0,x1,x2,…,使得f(x0)≥f(x1)≥f(x2)≥⋯
如果顺利的话,序列(xn)收敛到局部最小解x∗,注意,每次迭代步长𝛼可以改变,但其取值必须合适,如果过大就不会收敛,如果过小则收敛速度太慢.
梯度下降法的过程如图C.1所示.曲线是等高线(水平集),即函数𝑓为不同常数的集合构成的曲线.红色的箭头指向该点梯度的反方向(梯度方向与通过该点的等高线垂直).沿着梯度下降方向,将最终到达函数𝑓值的局部最小解.
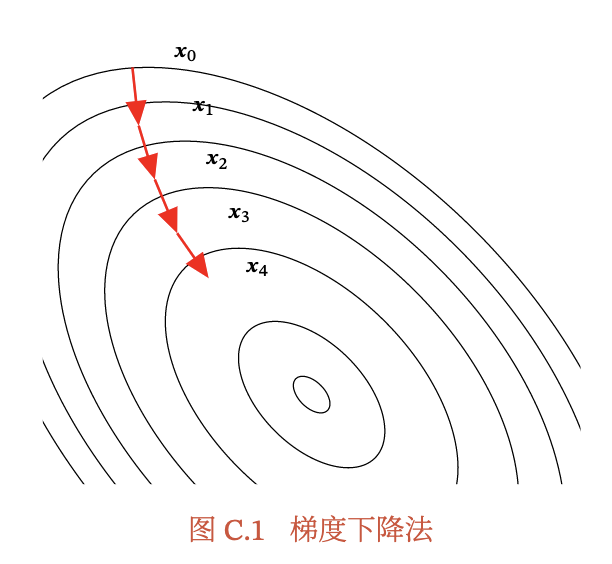
梯度下降法为一阶收敛算法,当靠近局部最小解时梯度变小,收敛速度会变慢,并且可能以“之字形”的方式下降.如果目标函数为二阶连续可微,我们可以采用牛顿法.牛顿法(Newton’s method)为二阶收敛算法,收敛速度更快,但是每次迭代需要计算Hessian矩阵的逆矩阵,复杂度较高.
梯度下降法步骤:
输入:目标函数f(x),梯度函数g(x)=∇f(x),计算精度ε
输出:f(x)的极小点,x∗
- 取初始值x(0)∈Rn,置k=0。
- 计算f(x(k))
- 计算梯度gk=g(x(k)),当∥gk∥<ε时,停止迭代,令x∗=x(k),否则,令pk=−g(x(k)),求λk,使f(x(k)+λkpk)=minλ⩾0f(x(k)+λpk)
- 置x(k+1)=x(k)+λkpk,计算f(x(k+1)),当∥∥f(x(k+1))−f(x(k))∥∥<ε或∥∥x(k+1)−x(k)∥∥<ε时,停止迭代,令x∗=x(k+1)。
- 否则,置k=k+1,转3.
牛顿法
考虑无约束最优化问题,minx∈Rnf(x),其中x∗为目标函数的极小点。
假设f(x)具有二阶连续偏导数,若第k次送代值为x(k),则可将f(x)在x(k)附近进行二阶泰勒展开:
f(x)=f(x(k))+gkT(x−x(k))+21(x−x(k))TH(x(k))(x−x(k))
这里,gk=g(x(k))=∇f(x(k))是f(x)的梯度向量在点x(k)的值,H(x(k))是f(x)的海森矩阵:
H(x)=[∂xi∂xj∂2f]n×n
在点x(k)的值。函数f(x)s有极值的必要条件是在极值点处一阶导数为 0, 即梯度向量为 0。特别是当H(x(k))是正定矩阵时,函数f(x)的极值为极小值。
牛顿法利用极小点的必要条件∇f(x)=0,每次迭代中从点x(k)开始,求目标函数的极小点,作为第k+1次迭代值x(k+1),具体地,假设x(k+1)满足∇f(x(k+1))=0,,又有∇f(x)=gk+Hk(x−x(k)),其中Hk=H(x(k)),得
gk+Hk(x(k+1)−x(k))=0
x(k+1)=x(k)−Hk−1gk
算法步骤:
输入:目标函数f(x),梯度g(x)=∇f(x),海森矩阵H(x),精度要求ε
输出:f(x)的极小点,x∗
- 取初始点x(0),置k=0
- 计算gk=g(x(k))
- 若∥gk∥<ε,则停止计算,得近似解x∗=x(k)
- 计算Hk=H(x(k)),并求pk,Hkpk=−gk
- 置x(k+1)=x(k)+pk
- 置k=k+1,转2
步骤4求pk,pk=−Hk−1gk,要求Hk−1,计算较复杂,固有其他解决方法,如拟牛顿法。
拉格朗日乘数法与KKT条件(nndl)
拉格朗日乘数法(Lagrange Multiplier)以数学家约瑟夫·拉格朗日命名.是一种有效求解约束优化问题的优化方法,约束优化问题可以表示为:
minxf(x)
s.t. hm(x)=0,m=1,…,M
gn(x)≤0,n=1,…,N
其中hm(x)为等式约束函数,gn(x)为不等式约束函数.𝒙的可行域为
D=dom(f)∩⋂m=1Mdom(hm)∩⋂n=1Ndom(gn)⊆RD
其中dom(f)是函数𝑓的定义域。
等式约束优化问题
如果公式中只有等式约束,我们可以构造一个拉格朗日函数Λ(x,λ):
Λ(x,λ)=f(x)+∑m=1Mλmhm(x)
其中𝜆为拉格朗日乘数,可以是正数或负数.如果f(x∗)是原始约束优化问题的局部最优值,那么存在一个λ∗使得(x∗,λ∗)为拉格朗日函数Λ(x,λ)的驻点,.因此,只需要令∂x∂Λ(x,λ)=0和∂λ∂Λ(x,λ)=0,得到:
∇f(x)+∑m=1Mλm∇hm(x)=0
hm(x)=0,∀m=1,⋯,M
上面方程组的解即为原始问题的可能解.因为驻点不一定是最小解,所以在实际应用中需根据具体问题来验证是否为最小解。
拉格朗日乘数法是将一个有𝐷个变量和𝑀个等式约束条件的最优化问题转换为一个有𝐷 + 𝑀个变量的函数求驻点的问题.拉格朗日乘数法所得的驻点会包含原问题的所有最小解,但并不保证每个驻点都是原问题的最小解。
不等式约束优化问题
对于公式中定义的一般约束优化问题,其拉格朗日函数为:
Λ(x,a,b)=f(x)+∑m=1Mamhm(x)+∑n=1Nbngn(x)
其中a=[a1,⋯,aM]⊤为等式约束的拉格朗日乘数,b=[b1,⋯,bN]⊤为不等式约束的拉格朗日乘数。
不等式约束优化问题中的拉格朗日乘数也称为KKT乘数。
当约束条件不满足时,有maxa,bΛ(x,a,b)=∞,当约束条件满足时并且b≥0时,maxa,bΛ(x,a,b)=f(x),因此,原始约束优化问题等价于:
minxmaxa,b s.t. Λ(x,a,b)b≥0
这个min-max优化问题称为主问题
主问题的优化一般比较困难,我们可以通过交换min-max的顺序来简化.定义拉格朗日对偶函数为
Γ(a,b)=infx∈DΛ(x,a,b)
Γ(𝒂,𝒃)是一个凹函数,即使𝑓(𝒙)是非凸的。
当𝒃 ≥ 0时,对于任意的x~∈D,有
Γ(a,b)=infx∈DΛ(x,a,b)≤Λ(x~,a,b)≤f(x~)
令p∗是原问题的最优值,则有:
Γ(a,b)≤p∗
即拉格朗日对偶函数Γ(𝒂,𝒃)为原问题最优值的下界。
优化拉格朗日对偶函数Γ(𝒂,𝒃)并得到原问题的最优下界,称为拉格朗日对偶问题(Lagrange Dual Problem)
maxa,bΓ(a,b)
s.t. b≥0
拉格朗日对偶函数为凹函数,因此拉格朗日对偶问题为凸优化问题.
令d∗表示拉格朗日对偶问题的最优值,则有d∗≤p∗,这个性质称为弱对偶性(Weak Duality).如果d∗=p∗,这个性质称为强对偶性(Strong Duality)。
当强对偶性成立时,令x∗和a∗,b∗分别是原问题和对偶问题的最优解,那么它们满足以下条件:
∇f(x∗)+hm(x∗)gn(x∗)bn∗gn(x∗)bn∗m=1∑Mam∗∇hm(x∗)+n=1∑Nbn∗∇gn(x∗)=0=0,m=1,⋯,M≤0,n=1,⋯,N=0,n=1,⋯,N≥0,n=1,⋯,N
这5个条件称为不等式约束优化问题的KKT条件(Karush-Kuhn-Tucker Con-dition).KKT条件是拉格朗日乘数法在不等式约束优化问题上的泛化.当原问题是凸优化问题时,满足KKT条件的解也是原问题和对偶问题的最优解.
在KKT条件中,需要关注的是公式bn∗gn(x∗)=0,n=1,⋯,N,称为互补松弛(ComplementarySlackness)条件.如果最优解x∗出现在不等式约束的边界上gn(x)=0,则bn∗>0。如果最优解x∗出现在不等式约束的内部gn(x)<0,则bn∗=0.互补松弛条件说明当最优解出现在不等式约束的内部,则约束失效.
拉格朗日乘数法与KKT条件(统计学习方法)
原始问题
假设f(x),ci(x),hj(x)是定义在Rn上的连续可微函数。考虑约束最优化问题:
minx∈Rnf(x)
s.t. ci(x)⩽0,i=1,2,⋯,k
hj(x)=0,j=1,2,⋯,l
称此约束最优化问题为原始最优化问题或原始问题。
首先,引进广义拉格朗日函数(generalized Lagrange function)
L(x,α,β)=f(x)+∑i=1kαici(x)+∑j=1lβjhj(x)
这里,x=(x(1),x(2),⋯,x(n))T∈Rn,αi,βj是拉格朗日乘子,αi⩾0,考虑x的函数:
θP(x)=maxα,β:αi⩾0L(x,α,β)
这里,下标P表示原始问题。
假设给定某个x。如果x违反原始问题的约束条件,即存在某个i使得ci(x)>0或者存在某个j使得hj(x)=0, 那么就有
θP(x)=maxα,β:αi⩾0[f(x)+∑i=1kαici(x)+∑j=1lβjhj(x)]=+∞
因为若某个i使约束ci(x)>0,则可令αi→+∞,若某个j使hj(x)=0,则可令βj使βjhj(x)→+∞,而将其余各αi,βj均取为0.
相反地,如果满足约束条件式,则有:
θP(x)={f(x),x满足原始问题约束+∞
所以如果考虑极小化问题,
minxθP(x)=minxmaxα,β:αi⩾0L(x,α,β)
它是与原始最优化问题等价的,即它们有相同的解。问题minxmaxα,β:αi⩾0L(x,α,β)称为广义拉格朗日函数的极小极大问题。这样一来,就把原始最优化问题表示为广义拉格朗日函数的极小极大问题。为了方便,定义原始问题的最优值:
p∗=minxθP(x)
称为原始问题的值。
对偶问题
定义θD(α,β)=minxL(x,α,β)再考虑极大化θD(α,β)=minxL(x,α,β),即maxα,β:αi⩾0θD(α,β)=maxα,β:αi⩾0minxL(x,α,β)
问题maxα,β:αi⩾0minxL(x,α,β)称为广义拉格朗日函数的极大极小问题。
可以将广义拉格朗日函数的极大极小问题表示为约束最优化问题:
α,βmaxθD(α,β)= s.t. α,βmaxxminL(x,α,β)αi⩾0,i=1,2,⋯,k
称为原始问题的对偶问题。定义对偶问题的最优值
d∗=maxα,β:αi⩾0θD(α,β)
称为对偶问题的值。
原始问题和对偶问题的值
定理一:若原始问题和对偶问题都有最优值,则
d∗=maxα,β:αi⩾0minxL(x,α,β)⩽minxmaxα,β:αi⩾0L(x,α,β)=p∗
证明:由maxα,βθD(α,β)=maxα,βminxL(x,α,β)和θP(x)=maxα,β:αi⩾0L(x,α,β),对任意的α,β和x,有
θD(α,β)=minxL(x,α,β)⩽L(x,α,β)⩽maxα,β:αi⩾0L(x,α,β)=θP(x),即
θD(α,β)⩽θP(x),
由于原始问题和对偶问题均有最优值,所以,maxα,β:αi⩾0θD(α,β)⩽minxθP(x)
即d∗=maxα,β:αi⩾0minxL(x,α,β)⩽minxmaxα,β:αi⩾0L(x,α,β)=p∗
推论:设x∗和α∗,β∗分别是原始问题和对偶问题的可行解,并且d∗=p∗,则x∗和α∗,β∗分别是原始问题和对偶问题的最优解。
定理二:考虑原始问题和对偶问题,假设函数f(x)和ci(x)是凸函数,hj(x)是仿射函数,并且假设不等式约束ci(x)是严格可行的,即存在x,对所有i有ci(x)<0,则存在x∗,α∗,β∗,使x∗是原始问题的解,α∗,β∗是对偶问题的解,并且:
p∗=d∗=L(x∗,α∗,β∗)
定理三:考虑原始问题和对偶问题,假设函数f(x)和ci(x)是凸函数,hj(x)是仿射函数,并且不等式约束ci(x)是严格可行的,则x∗和α∗,β∗分别是原始问题和对偶问题的解的充分必要条件是x∗,α∗,β∗满足下面的KKT条件:
∇xL(x∗,α∗,β∗)=0
αi∗ci(x∗)=0,i=1,2,⋯,k
ci(x∗)⩽0,i=1,2,⋯,k
αi∗⩾0,i=1,2,⋯,k
hj(x∗)=0j=1,2,⋯,l
αi∗ci(x∗)=0,i=1,2,⋯,k称为KKT的对偶互补条件,由此条件可知,若αi∗>0,则ci(x∗)=0。