估计沃尔玛零售商品的单位销售量
概览
使用沃尔玛的分级销售数据来预测未来28天的日销售额。 该数据涵盖了美国三个州(加利福尼亚州、德克萨斯州和威斯康星州)的商店,包括商品级别(item level)、部门(department)、产品类别(product categories)和商店细节(store details)。 此外,它还有解释性变量,如价格(price),促销活动(promotions),星期几(day of the week),和特别活动(special events)。 总之,这个稳健的数据集可以用来提高预测的准确性。
数据
在这个挑战中,你要预测不同地点的商店在两个28天时间段内的商品销售情况。
数据特点:
- 它使用沃尔玛慷慨提供的分级销售数据,从商品级别开始,汇总到美国三个地理区域的部门、产品类别、商店: 加利福尼亚、德克萨斯和威斯康星
- 除了时间序列数据,它还包括解释性变量,如价格,促销,星期几,和特殊事件(如超级碗,情人节,东正教复活节) ,影响销售,用来提高预测准确性
- 超过42,840个时间序列的大部分显示间歇性(零星销售包括零)
- 它首次将重点放在显示间歇性的序列上,即包含0的零星需求
由沃尔玛慷慨提供的M5数据集涉及在美国销售的各种产品的单位销售,以分组时间序列的形式组织。 更具体地说,该数据集涉及3,049种产品的单位销售额,分为3个产品类别(爱好,食品和家庭)和7个产品部门,其中上述类别被分解。 这些产品在三个州(CA,TX和WI)的十家商店中销售。 在这方面,可以跨产品类别或地理区域映射层次结构的底层,即产品商店的销售量,如下所示:
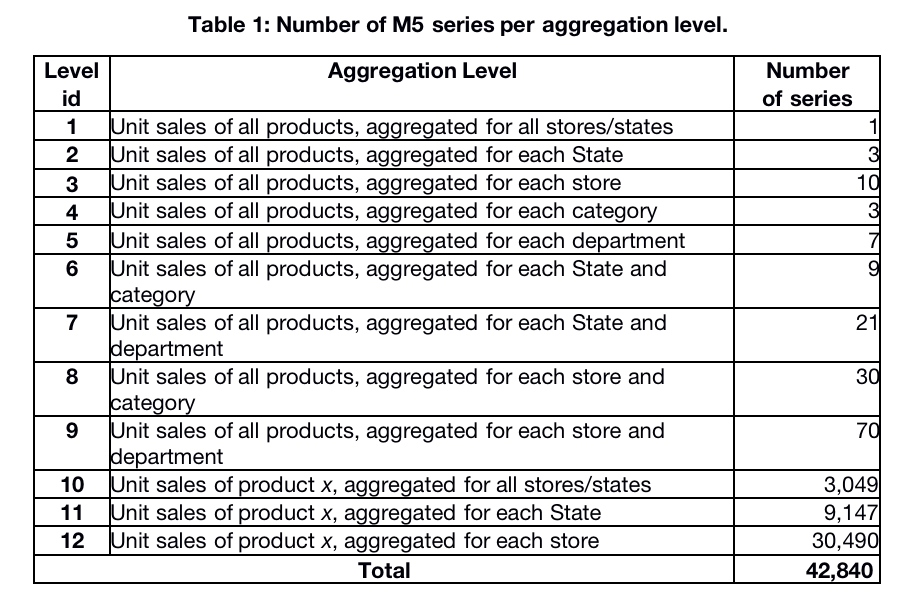

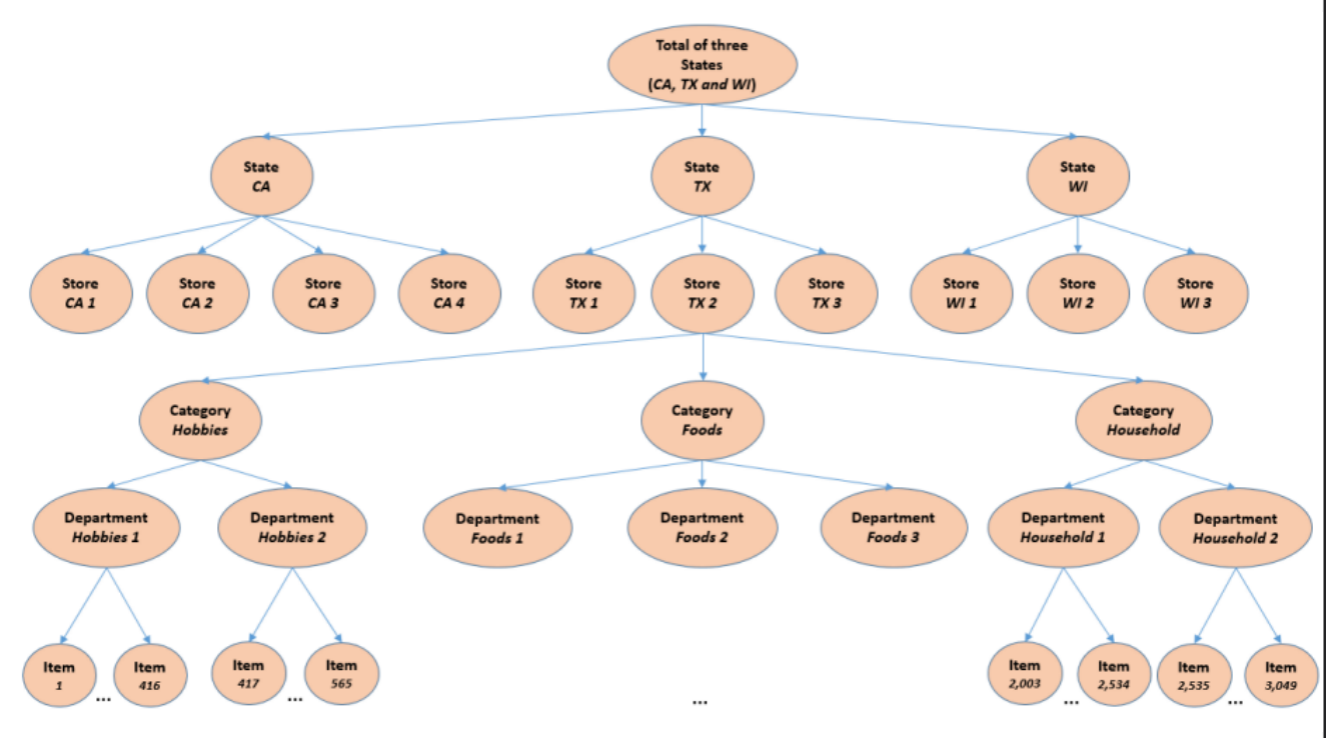
历史数据范围为2011-01-29至2016-06-19。 因此,这些产品的(最大)销售历史为1,941 [。此数字指的是2020年6月1日提供的最终培训数据集的历史。在验证阶段,可以少用28天,如“ 日期和托管”部分。]天/ 5.4年(不包括h = 28天的测试数据)。
文件:
calendar.csv:包含有关产品销售日期的信息date:“y-m-d”格式的日期,2011-01-30wm_yr_wk:日期所属的星期的ID,11101,每个星期的标识weekday:日期的类型(星期六,星期日,…,星期五)。Sundaywday:工作日的ID,从星期六开始。2month:日期的月份。1year:日期的年份。2011event_name_1:如果日期包含事件,则为事件的名称。SuperBowlevent_type_1:如果日期包含事件,则为事件的类型。Sportingevent_name_2:如果日期中包含第二个事件,则此事件的名称。Easterevent_type_2:如果日期包括第二个事件,则此事件的类型。Culturalsnap_CA, snap_TX, and snap_WI:指示CA,TX或WI商店是否允许在检查日期购买SNAP3的二进制变量(0或1)。 1表示允许购买SNAP。1
sell_prices.csv:包含每个商店和日期出售的产品的价格信息store_id:销售产品的商店的IDitem_id:产品的IDwm_yr_wk:日期所属的星期的ID,11325,每个星期的标识sell_price:给定周/商店的产品价格。 价格每周提供一次(平均7天)。 如果没有,则表示在检查的一周内没有出售该产品。 请注意,尽管每周价格不变,但价格可能会随时间而变化(训练和测试集)
sales_train_validation.csv:包含每个产品和商店的历史每日单位销售数据[d_1 - d_1913]id:每条记录的ID,HOBBIES_1_001_CA_1_validationitem_id:产品的ID。HOBBIES_1_001dept_id:产品所属部门的ID。HOBBIES_1cat_id:产品所属类别的ID.HOBBIESstore_id:销售产品的商店的ID。CA_1state_id:商店所在的州。CAd_1, d_2, …, d_i, … d_1941: 从2011-01-29开始,在第i天售出的商品数量。
sales_train_evaluation.csv:在比赛截止日期前每月发售一次,包括销售额[d_1 - d_1941]sample_submission.csv:提交文件的正确格式
评估
预测范围
点预测所需的预测数量为h = 28天(提前4周)。
首先通过在预测范围内对每个系列的值进行平均,然后分别对每个系列的绩效指标进行计算,然后以加权方式(请参见下文)再次对整个系列进行平均,以获得最终分数。
点预测
点预测的准确性将使用均方根比例误差(RMSSE)进行评估,针对每个系列的度量计算如下:
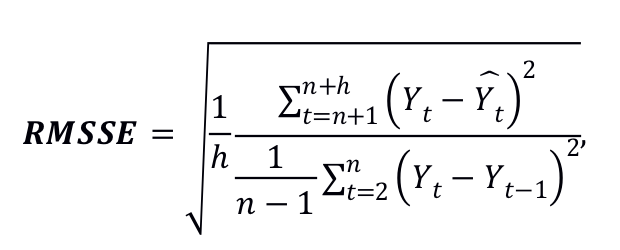
其中是在时间点上检查的时间序列的实际未来值,是生成的预测,是训练样本的长度(历史观测值的数量),是预测范围。
注意,RMSSE的分母仅针对被出售产品的有效销售时间段进行计算,即针对评估系列观察到的第一个非零需求之后的时间段。
选择措施的理由如下:
- M5系列的特点是间歇性,涉及零散的零星销售。 这意味着针对中位数进行了优化的绝对误差会为得出接近零的预测的预测方法分配较低的分数(更好的性能)。 但是,M5的目的是准确预测平均需求,因此,所使用的精度度量基于平方误差,该误差针对均值进行了优化。
- 该度量是独立于尺度的,这意味着它可以有效地用于比较不同尺度系列的预测。
- 与其他度量相比,它可以安全地计算,因为它不依赖于等于或接近于零的值的除法(例如,当时以百分比误差表示,或当基准误差用于 缩放比例为零)
- 该措施对正,负预测误差以及大小预测均进行了惩罚,因此是对称的。
在估算了所有42,840个时间序列的RMSSE之后,将使用加权RMSSE(WRMSSE)对参赛方法进行排名,如本指南后面所述,使用以下公式:
其中是比赛系列的权重。 WRMSSE分数越低越好。
请注意,每个系列的权重将基于数据集训练样本的最后28个观察值来计算,即每个系列在特定时期内显示的累计实际美元销售额(售出单位的总和乘以其各自的价格) 。
权重
与以前的M竞赛相比,M5涉及以分层方式组织的具有不同销售量和价格的各种产品的单位销售。 这意味着,从业务角度来说,为了使一种方法表现良好,它必须在所有层次结构级别上提供准确的预测,尤其是对于重要度较高的系列(即代表重要销售额的系列,以美元为单位)。 换句话说,我们期望从效果最佳的预测方法中得出对该系列更有价值的较低预测误差,从而为公司带来更大的价值。
为此,将根据M5系列的累计实际美元销售额对每种参与方法(RMSSE和SPL)计算出的预测误差进行加权,这可以很好地客观地反映其以货币表示的公司实际价值 。 累积的美元销售额将使用培训样本的最后28个观察值(已售商品总和乘以其各自的价格)来计算,即等于预测范围的时间段。 请注意,由于所售出的产品数量及其各自的价格会随时间变化,因此此估算是基于相应的每日美元销售额的总和。
在下面,您可以找到一个简单的但具有指示性的示例,说明如何计算这些权重:
假设同一个部门的两个产品A和B在WI的一家商店中出售,我们有兴趣预测这两个产品的单位销售额及其总销售额。 因此,在此示例中,我们考虑了两个不同的聚合级别(K = 2),第一级别由两个系列(系列A和B)组成,第二个级别为单个系列(系列A和B的总和)。
在训练样本的最后28天中,产品A的销售总额为10美元,而产品B的销售总额为12美元。 因此,过去28天产品A和B的总美元销售额为22美元。 还假定使用一种预测方法来推导产品A,产品B及其总单位销售的积分预测,分别显示误差RMSSEA = 0.8,RMSSEB = 0.7和RMSSE = 0.77。 如果M5数据集仅涉及这三个系列,则该方法的最终WRMSSE得分为
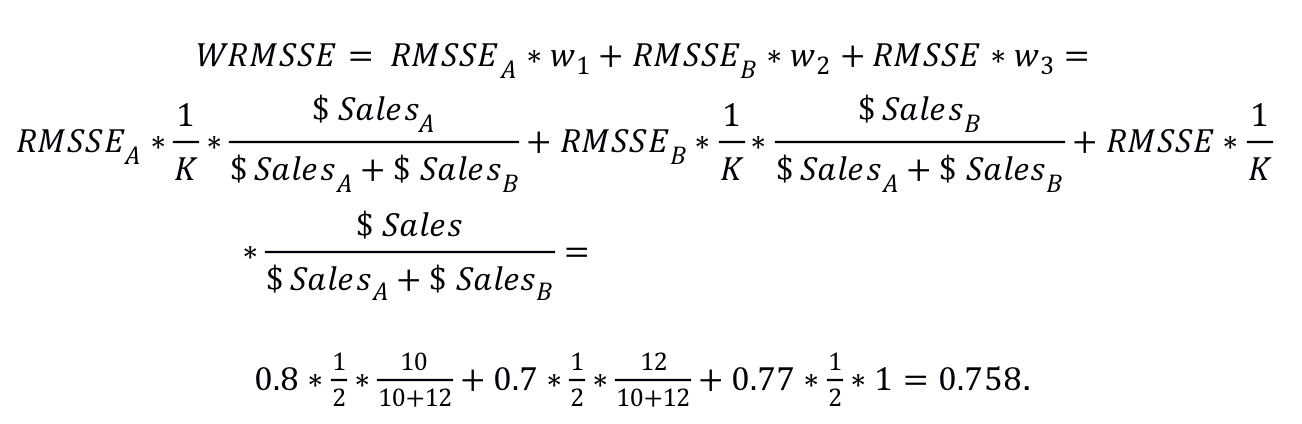
如前所述,可以扩展此加权方案,以考虑更多的商店,地理区域,产品类别和产品部门。 由于M5竞赛涉及十二个聚合级别,因此将K设置为等于12,并计算系列的权重,以使它们在每个聚合级别上的总和为1。
请注意,所有层次结构级别被平衡加权。 原因是,在三个州中衡量的产品总销售额等于在十个商店中衡量的该产品的销售额之和。 同样,因为商店的产品类别的总美元销售额等于该类别所组成部门的美元销售额之和,以及相应部门产品的美元销售额之和。 而且,如先前针对概率预测的情况所讨论的那样,M5并不关注特定的决策问题,这意味着没有理由不平等地对层次结构的各个级别进行加权。
提交文件
每行包含一个ID,该ID是item_id和store_id的串联,它可以是验证(对应于Public排行榜)或评估(对应于Private排行榜)。 您预计每行售出的物品有28个预测天(F1-F28)。 对于验证行,这对应于d_1914-d_1941,对于评估行,这对应于d_1942-d_1969。 (注意:比赛结束前一个月,将提供验证行的基本信息。)
这些文件必须具有标题,并且应如下所示:
