利用Python进行数据分析
入门
数据结构介绍
Series
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据即可产生最简单的Series:
obj = pd.Series([4, 7, -5, 3])
obj
0 4
1 7
2 -5
3 3
dtype: int64
Series的字符串表现形式为:索引在左边,值在右边。由于我们没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引。你可以通过Series 的values和index属性获取其数组表示形式和索引对象:
obj.values
array([ 4, 7, -5, 3])
obj.index # like range(4)
RangeIndex(start=0, stop=4, step=1)
通常,我们希望所创建的Series带有一个可以对各个数据点进行标记的索引:
obj2 = pd.Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
obj2
d 4
b 7
a -5
c 3
dtype: int64
obj2.index
Index(['d', 'b', 'a', 'c'], dtype='object')
与普通NumPy数组相比,你可以通过索引的方式选取Series中的单个或一组值:
obj2['a']
-5
obj2['d'] = 6
obj2[['c', 'a', 'd']]
c 3
a -5
d 6
dtype: int64
['c', 'a', 'd']是索引列表,即使它包含的是字符串而不是整数。
使用NumPy函数或类似NumPy的运算(如根据布尔型数组进行过滤、标量乘法、应用数学函数等)都会保留索引值的链接:
obj2[obj2 > 0]
d 6
b 7
c 3
dtype: int64
obj2 * 2
d 12
b 14
a -10
c 6
dtype: int64
np.exp(obj2)
d 403.428793
b 1096.633158
a 0.006738
c 20.085537
dtype: float64
还可以将Series看成是一个定长的有序字典,因为它是索引值到数据值的一个映射。它可以用在许多原本需要字典参数的函数中:
'b' in obj2
True
'e' in obj2
False
如果数据被存放在一个Python字典中,也可以直接通过这个字典来创建Series:
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
obj3 = pd.Series(sdata)
obj3
Ohio 35000
Oregon 16000
Texas 71000
Utah 5000
dtype: int64
如果只传入一个字典,则结果Series中的索引就是原字典的键(有序排列)。你可以传入排好序的字典的键以改变顺序:
states = ['California', 'Ohio', 'Oregon', 'Texas']
obj4 = pd.Series(sdata, index=states)
obj4
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
dtype: float64
在这个例子中,sdata中跟states索引相匹配的那3个值会被找出来并放到相应的位置上,但由于"California"所对应的sdata值找不到,所以其结果就为NaN(即“非数字”(not a number),在pandas中,它用于表示缺失或NA值)。因为‘Utah’不在states中,它被从结果中除去。
使用缺失(missing)或NA表示缺失数据。pandas的isnull和notnull函数可用于检测缺失数据:
pd.isnull(obj4)
California True
Ohio False
Oregon False
Texas False
dtype: bool
pd.notnull(obj4)
California False
Ohio True
Oregon True
Texas True
dtype: bool
Series也有类似的实例方法:
obj4.isnull()
California True
Ohio False
Oregon False
Texas False
dtype: bool
对于许多应用而言,Series最重要的一个功能是,它会根据运算的索引标签自动对齐数据:
obj3
Ohio 35000
Oregon 16000
Texas 71000
Utah 5000
dtype: int64
obj4
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
dtype: float64
obj3 + obj4
California NaN
Ohio 70000.0
Oregon 32000.0
Texas 142000.0
Utah NaN
dtype: float64
Series对象本身及其索引都有一个name属性,该属性跟pandas其他的关键功能关系非常密切:
obj4.name = 'population'
obj4.index.name = 'state'
obj4
state
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
Name: population, dtype: float64
Series的索引可以通过赋值的方式就地修改:
obj
0 4
1 7
2 -5
3 3
dtype: int64
obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
obj
Bob 4
Steve 7
Jeff -5
Ryan 3
dtype: int64
DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
建DataFrame的办法有很多,最常用的一种是直接传入一个由等长列表或NumPy数组组成的字典:
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
frame = pd.DataFrame(data)
结果DataFrame会自动加上索引(跟Series一样),且全部列会被有序排列:
frame
pop state year
0 1.5 Ohio 2000
1 1.7 Ohio 2001
2 3.6 Ohio 2002
3 2.4 Nevada 2001
4 2.9 Nevada 2002
5 3.2 Nevada 2003
如果指定了列序列,则DataFrame的列就会按照指定顺序进行排列:
pd.DataFrame(data, columns=['year', 'state', 'pop'])
year state pop
0 2000 Ohio 1.5
1 2001 Ohio 1.7
2 2002 Ohio 3.6
3 2001 Nevada 2.4
4 2002 Nevada 2.9
5 2003 Nevada 3.2
如果传入的列在数据中找不到,就会在结果中产生缺失值:
frame2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'],
index=['one', 'two', 'three', 'four',
'five', 'six'])
frame2
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 NaN
five 2002 Nevada 2.9 NaN
six 2003 Nevada 3.2 NaN
frame2.columns
Index(['year', 'state', 'pop', 'debt'], dtype='object')
通过类似字典标记的方式或属性的方式,可以将DataFrame的列获取为一个Series:
frame2['state']
one Ohio
two Ohio
three Ohio
four Nevada
five Nevada
six Nevada
Name: state, dtype: object
frame2.year
one 2000
two 2001
three 2002
four 2001
five 2002
six 2003
Name: year, dtype: int64
注意,返回的Series拥有原DataFrame相同的索引,且其name属性也已经被相应地设置好了。
行也可以通过位置或名称的方式进行获取,比如用loc属性:
frame2.loc['three']
year 2002
state Ohio
pop 3.6
debt NaN
Name: three, dtype: object
列可以通过赋值的方式进行修改。例如,我们可以给那个空的"debt"列赋上一个标量值或一组值:
frame2['debt'] = 16.5
frame2
year state pop debt
one 2000 Ohio 1.5 16.5
two 2001 Ohio 1.7 16.5
three 2002 Ohio 3.6 16.5
four 2001 Nevada 2.4 16.5
five 2002 Nevada 2.9 16.5
six 2003 Nevada 3.2 16.5
frame2['debt'] = np.arange(6.)
frame2
year state pop debt
one 2000 Ohio 1.5 0.0
two 2001 Ohio 1.7 1.0
three 2002 Ohio 3.6 2.0
four 2001 Nevada 2.4 3.0
five 2002 Nevada 2.9 4.0
six 2003 Nevada 3.2 5.0
将列表或数组赋值给某个列时,其长度必须跟DataFrame的长度相匹配。如果赋值的是一个Series,就会精确匹配DataFrame的索引,所有的空位都将被填上缺失值:
val = pd.Series([-1.2, -1.5, -1.7], index=['two', 'four', 'five'])
frame2['debt'] = val
frame2
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 -1.2
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 -1.5
five 2002 Nevada 2.9 -1.7
six 2003 Nevada 3.2 NaN
为不存在的列赋值会创建出一个新列。关键字del用于删除列。
作为del的例子,先添加一个新的布尔值的列,state是否为'Ohio':
frame2['eastern'] = frame2.state == 'Ohio'
frame2
year state pop debt eastern
one 2000 Ohio 1.5 NaN True
two 2001 Ohio 1.7 -1.2 True
three 2002 Ohio 3.6 NaN True
four 2001 Nevada 2.4 -1.5 False
five 2002 Nevada 2.9 -1.7 False
six 2003 Nevada 3.2 NaN False
注意:不能用frame2.eastern创建新的列。
del方法可以用来删除这列:
del frame2['eastern']
frame2.columns
Index(['year', 'state', 'pop', 'debt'], dtype='object')
注意:通过索引方式返回的列只是相应数据的视图而已,并不是副本。因此,对返回的Series所做的任何就地修改全都会反映到源DataFrame上。通过Series的copy方法即可指定复制列。
另一种常见的数据形式是嵌套字典:
pop = {'Nevada': {2001: 2.4, 2002: 2.9},'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
如果嵌套字典传给DataFrame,pandas就会被解释为:外层字典的键作为列,内层键则作为行索引:
frame3 = pd.DataFrame(pop)
frame3
Nevada Ohio
2000 NaN 1.5
2001 2.4 1.7
2002 2.9 3.6
你也可以使用类似NumPy数组的方法,对DataFrame进行转置(交换行和列):
frame3.T
2000 2001 2002
Nevada NaN 2.4 2.9
Ohio 1.5 1.7 3.6
内层字典的键会被合并、排序以形成最终的索引。如果明确指定了索引,则不会这样:
pd.DataFrame(pop, index=[2001, 2002, 2003])
Nevada Ohio
2001 2.4 1.7
2002 2.9 3.6
2003 NaN NaN
由Series组成的字典差不多也是一样的用法:
pdata = {'Ohio': frame3['Ohio'][:-1],
'Nevada': frame3['Nevada'][:2]}
pd.DataFrame(pdata)
Nevada Ohio
2000 NaN 1.5
2001 2.4 1.7
下表列出了DataFrame构造函数所能接受的各种数据。
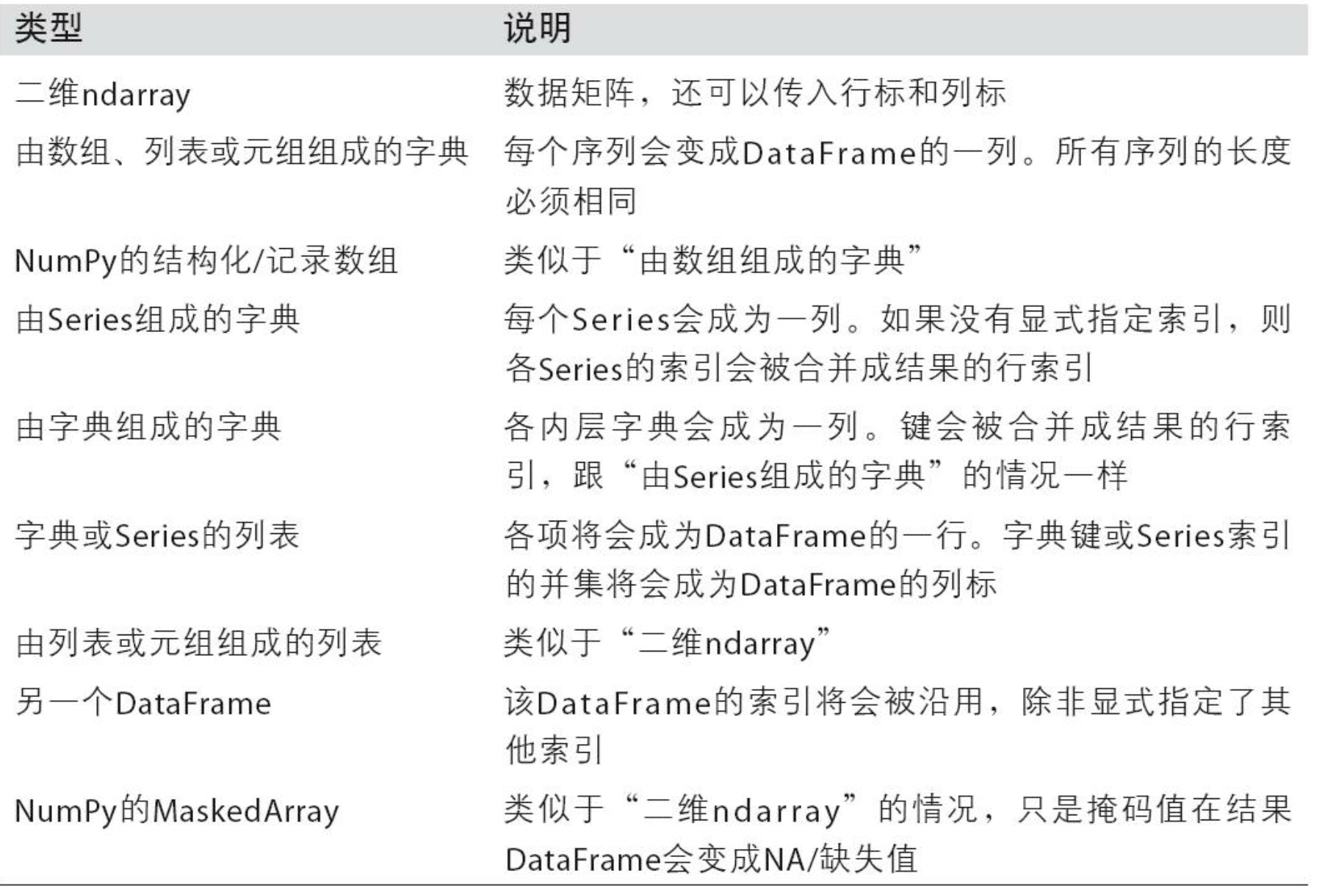
如果设置了DataFrame的index和columns的name属性,则这些信息也会被显示出来:
frame3.index.name = 'year'; frame3.columns.name = 'state'
frame3
state Nevada Ohio
year
2000 NaN 1.5
2001 2.4 1.7
2002 2.9 3.6
跟Series一样,values属性也会以二维ndarray的形式返回DataFrame中的数据:
frame3.values
array([[ nan, 1.5],
[ 2.4, 1.7],
[ 2.9, 3.6]])
如果DataFrame各列的数据类型不同,则值数组的dtype就会选用能兼容所有列的数据类型:
frame2.values
array([[2000, 'Ohio', 1.5, nan],
[2001, 'Ohio', 1.7, -1.2],
[2002, 'Ohio', 3.6, nan],
[2001, 'Nevada', 2.4, -1.5],
[2002, 'Nevada', 2.9, -1.7],
[2003, 'Nevada', 3.2, nan]], dtype=object)
索引对象
pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。构建Series或DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index:
obj = pd.Series(range(3), index=['a', 'b', 'c'])
index = obj.index
index
Index(['a', 'b', 'c'], dtype='object')
index[1:]
Index(['b', 'c'], dtype='object')
Index对象是不可变的,因此用户不能对其进行修改:
index[1] = 'd' # TypeError
不可变可以使Index对象在多个数据结构之间安全共享:
labels = pd.Index(np.arange(3))
labels
Int64Index([0, 1, 2], dtype='int64')
obj2 = pd.Series([1.5, -2.5, 0], index=labels)
obj2
0 1.5
1 -2.5
2 0.0
dtype: float64
obj2.index is labels
True
注意:虽然用户不需要经常使用Index的功能,但是因为一些操作会生成包含被索引化的数据,理解它们的工作原理是很重要的。
除了类似于数组,Index的功能也类似一个固定大小的集合:
frame3
state Nevada Ohio
year
2000 NaN 1.5
2001 2.4 1.7
2002 2.9 3.6
frame3.columns
Index(['Nevada', 'Ohio'], dtype='object', name='state')
'Ohio' in frame3.columns
True
2003 in frame3.index
False
与python的集合不同,pandas的Index可以包含重复的标签:
dup_labels = pd.Index(['foo', 'foo', 'bar', 'bar'])
dup_labels
Index(['foo', 'foo', 'bar', 'bar'], dtype='object')
选择重复的标签,会显示所有的结果。
每个索引都有一些方法和属性,它们可用于设置逻辑并回答有关该索引所包含的数据的常见问题。下表列出了这些函数。

基本功能
重新索引
pandas对象的一个重要方法是reindex,其作用是创建一个新对象,它的数据符合新的索引。看下面的例子:
obj = pd.Series([4.5, 7.2, -5.3, 3.6], index=['d', 'b', 'a', 'c'])
obj
d 4.5
b 7.2
a -5.3
c 3.6
dtype: float64
用该Series的reindex将会根据新索引进行重排。如果某个索引值当前不存在,就引入缺失值:
obj2 = obj.reindex(['a', 'b', 'c', 'd', 'e'])
obj2
a -5.3
b 7.2
c 3.6
d 4.5
e NaN
dtype: float64
对于时间序列这样的有序数据,重新索引时可能需要做一些插值处理。method选项即可达到此目的,例如,使用ffill可以实现前向值填充:
obj3 = pd.Series(['blue', 'purple', 'yellow'], index=[0, 2, 4])
obj3
0 blue
2 purple
4 yellow
dtype: object
obj3.reindex(range(6), method='ffill')
0 blue
1 blue
2 purple
3 purple
4 yellow
5 yellow
dtype: object
借助DataFrame,reindex可以修改(行)索引和列。只传递一个序列时,会重新索引结果的行:
frame = pd.DataFrame(np.arange(9).reshape((3, 3)),index=['a', 'c', 'd'],columns=['Ohio', 'Texas', 'California'])
frame
Ohio Texas California
a 0 1 2
c 3 4 5
d 6 7 8
frame2 = frame.reindex(['a', 'b', 'c', 'd'])
frame2
Ohio Texas California
a 0.0 1.0 2.0
b NaN NaN NaN
c 3.0 4.0 5.0
d 6.0 7.0 8.0
列可以用columns关键字重新索引:
states = ['Texas', 'Utah', 'California']
frame.reindex(columns=states)
Texas Utah California
a 1 NaN 2
c 4 NaN 5
d 7 NaN 8
下表列出了reindex函数的各参数及说明。

丢弃指定轴上的项
丢弃某条轴上的一个或多个项很简单,只要有一个索引数组或列表即可。由于需要执行一些数据整理和集合逻辑,所以drop方法返回的是一个在指定轴上删除了指定值的新对象:
obj = pd.Series(np.arange(5.), index=['a', 'b', 'c', 'd', 'e'])
obj
a 0.0
b 1.0
c 2.0
d 3.0
e 4.0
dtype: float64
new_obj = obj.drop('c')
new_obj
a 0.0
b 1.0
d 3.0
e 4.0
dtype: float64
obj.drop(['d', 'c'])
a 0.0
b 1.0
e 4.0
dtype: float64
对于DataFrame,可以删除任意轴上的索引值。为了演示,先新建一个DataFrame例子:
data = pd.DataFrame(np.arange(16).reshape((4, 4)),index=['Ohio', 'Colorado', 'Utah', 'New York'],columns=['one', 'two', 'three', 'four'])
data
one two three four
Ohio 0 1 2 3
Colorado 4 5 6 7
Utah 8 9 10 11
New York 12 13 14 15
用标签序列调用drop会从行标签(axis 0)删除值:
data.drop(['Colorado', 'Ohio'])
one two three four
Utah 8 9 10 11
New York 12 13 14 15
通过传递axis=1或axis='columns'可以删除列的值:
data.drop('two', axis=1)
one three four
Ohio 0 2 3
Colorado 4 6 7
Utah 8 10 11
New York 12 14 15
data.drop(['two', 'four'], axis='columns')
one three
Ohio 0 2
Colorado 4 6
Utah 8 10
New York 12 14
许多函数,如drop,会修改Series或DataFrame的大小或形状,可以就地修改对象,不会返回新的对象:
obj.drop('c', inplace=True)
obj
a 0.0
b 1.0
d 3.0
e 4.0
dtype: float64
小心使用inplace,它会销毁所有被删除的数据。
索引、选取和过滤
Series索引(obj[...])的工作方式类似于NumPy数组的索引,只不过Series的索引值不只是整数。下面是几个例子:
obj = pd.Series(np.arange(4.), index=['a', 'b', 'c', 'd'])
obj
a 0.0
b 1.0
c 2.0
d 3.0
dtype: float64
obj['b']
1.0
obj[1]
1.0
obj[2:4]
c 2.0
d 3.0
dtype: float64
obj[['b', 'a', 'd']]
b 1.0
a 0.0
d 3.0
dtype: float64
obj[[1, 3]]
b 1.0
d 3.0
dtype: float64
obj[obj < 2]
a 0.0
b 1.0
dtype: float64
利用标签的切片运算与普通的Python切片运算不同,其末端是包含的:
obj['b':'c']
b 1.0
c 2.0
dtype: float64
用切片可以对Series的相应部分进行设置:
obj['b':'c'] = 5
obj
a 0.0
b 5.0
c 5.0
d 3.0
dtype: float64
用一个值或序列对DataFrame进行索引其实就是获取一个或多个列:
data = pd.DataFrame(np.arange(16).reshape((4, 4)),index=['Ohio', 'Colorado', 'Utah', 'New York'],columns=['one', 'two', 'three', 'four'])
data
one two three four
Ohio 0 1 2 3
Colorado 4 5 6 7
Utah 8 9 10 11
New York 12 13 14 15
data['two']
Ohio 1
Colorado 5
Utah 9
New York 13
Name: two, dtype: int64
data[['three', 'one']]
three one
Ohio 2 0
Colorado 6 4
Utah 10 8
New York 14 12
这种索引方式有几个特殊的情况。首先通过切片或布尔型数组选取数据:
data[:2]
one two three four
Ohio 0 1 2 3
Colorado 4 5 6 7
data[data['three'] > 5]
one two three four
Colorado 4 5 6 7
Utah 8 9 10 11
New York 12 13 14 15
选取行的语法data[:2]十分方便。向[ ]传递单一的元素或列表,就可选择列。
另一种用法是通过布尔型DataFrame(比如下面这个由标量比较运算得出的)进行索引:
data < 5
one two three four
Ohio True True True True
Colorado True False False False
Utah False False False False
New York False False False False
data[data < 5] = 0
data
one two three four
Ohio 0 0 0 0
Colorado 0 5 6 7
Utah 8 9 10 11
New York 12 13 14 15
这使得DataFrame的语法与NumPy二维数组的语法很像。
用loc和iloc进行选取
对于DataFrame的行的标签索引,我引入了特殊的标签运算符loc和iloc。它们可以让你用类似NumPy的标记,使用轴标签(loc)或整数索引(iloc),从DataFrame选择行和列的子集。
作为一个初步示例,让我们通过标签选择一行和多列:
data.loc['Colorado', ['two', 'three']]
two 5
three 6
Name: Colorado, dtype: int64
然后用iloc和整数进行选取:
data.iloc[2, [3, 0, 1]]
four 11
one 8
two 9
Name: Utah, dtype: int64
data.iloc[2]
one 8
two 9
three 10
four 11
Name: Utah, dtype: int64
data.iloc[[1, 2], [3, 0, 1]]
four one two
Colorado 7 0 5
Utah 11 8 9
这两个索引函数也适用于一个标签或多个标签的切片:
data.loc[:'Utah', 'two']
Ohio 0
Colorado 5
Utah 9
Name: two, dtype: int64
data.iloc[:, :3][data.three > 5]
one two three
Colorado 0 5 6
Utah 8 9 10
New York 12 13 14
所以,在pandas中,有多个方法可以选取和重新组合数据。对于DataFrame,下表进行了总结。后面会看到,还有更多的方法进行层级化索引。
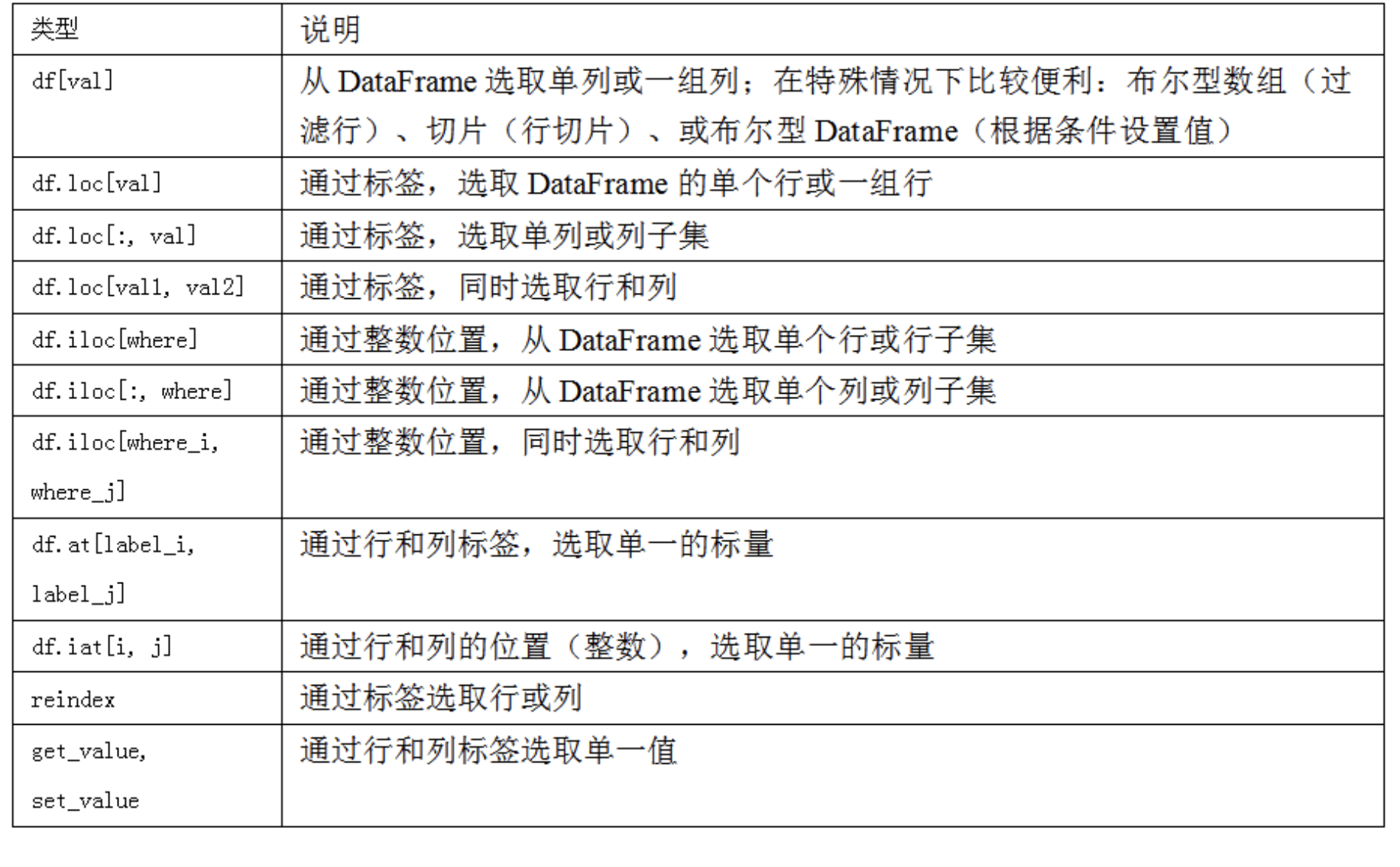
整数索引
处理整数索引的pandas对象常常难住新手,因为它与Python内置的列表和元组的索引语法不同。例如,你可能不认为下面的代码会出错:
ser = pd.Series(np.arange(3.))
ser
ser[-1]
这里,pandas可以勉强进行整数索引,但是会导致小bug。我们有包含0,1,2的索引,但是引入用户想要的东西(基于标签或位置的索引)很难:
In [144]: ser
0 0.0
1 1.0
2 2.0
dtype: float64
另外,对于非整数索引,不会产生歧义:
ser2 = pd.Series(np.arange(3.), index=['a', 'b', 'c'])
ser2[-1]
2.0
为了进行统一,如果轴索引含有整数,数据选取总会使用标签。为了更准确,请使用loc(标签)或iloc(整数):
ser[:1]
0 0.0
dtype: float64
ser.loc[:1]
0 0.0
1 1.0
dtype: float64
ser.iloc[:1]
0 0.0
dtype: float64
算术运算和数据对齐
pandas最重要的一个功能是,它可以对不同索引的对象进行算术运算。在将对象相加时,如果存在不同的索引对,则结果的索引就是该索引对的并集。对于有数据库经验的用户,这就像在索引标签上进行自动外连接。看一个简单的例子:
s1 = pd.Series([7.3, -2.5, 3.4, 1.5], index=['a', 'c', 'd', 'e'])
s2 = pd.Series([-2.1, 3.6, -1.5, 4, 3.1],index=['a', 'c', 'e', 'f', 'g'])
s1
a 7.3
c -2.5
d 3.4
e 1.5
dtype: float64
s2
a -2.1
c 3.6
e -1.5
f 4.0
g 3.1
dtype: float64
将它们相加就会产生:
s1 + s2
a 5.2
c 1.1
d NaN
e 0.0
f NaN
g NaN
dtype: float64
自动的数据对齐操作在不重叠的索引处引入了NA值。缺失值会在算术运算过程中传播。
对于DataFrame,对齐操作会同时发生在行和列上:
df1 = pd.DataFrame(np.arange(9.).reshape((3, 3)), columns=list('bcd'),index=['Ohio', 'Texas', 'Colorado'])
df2 = pd.DataFrame(np.arange(12.).reshape((4, 3)), columns=list('bde'),index=['Utah', 'Ohio', 'Texas', 'Oregon'])
df1
b c d
Ohio 0.0 1.0 2.0
Texas 3.0 4.0 5.0
Colorado 6.0 7.0 8.0
df2
b d e
Utah 0.0 1.0 2.0
Ohio 3.0 4.0 5.0
Texas 6.0 7.0 8.0
Oregon 9.0 10.0 11.0
把它们相加后将会返回一个新的DataFrame,其索引和列为原来那两个DataFrame的并集:
df1 + df2
b c d e
Colorado NaN NaN NaN NaN
Ohio 3.0 NaN 6.0 NaN
Oregon NaN NaN NaN NaN
Texas 9.0 NaN 12.0 NaN
Utah NaN NaN NaN NaN
因为'c'和'e'列均不在两个DataFrame对象中,在结果中以缺省值呈现。行也是同样。
如果DataFrame对象相加,没有共用的列或行标签,结果都会是空:
df1 = pd.DataFrame({'A': [1, 2]})
df2 = pd.DataFrame({'B': [3, 4]})
df1
A
0 1
1 2
df2
B
0 3
1 4
df1 - df2
A B
0 NaN NaN
1 NaN NaN
在算术方法中填充值
在对不同索引的对象进行算术运算时,你可能希望当一个对象中某个轴标签在另一个对象中找不到时填充一个特殊值(比如0):
df1 = pd.DataFrame(np.arange(12.).reshape((3, 4)),columns=list('abcd'))
df2 = pd.DataFrame(np.arange(20.).reshape((4, 5)),columns=list('abcde'))
df2.loc[1, 'b'] = np.nan
df1
a b c d
0 0.0 1.0 2.0 3.0
1 4.0 5.0 6.0 7.0
2 8.0 9.0 10.0 11.0
df2
a b c d e
0 0.0 1.0 2.0 3.0 4.0
1 5.0 NaN 7.0 8.0 9.0
2 10.0 11.0 12.0 13.0 14.0
3 15.0 16.0 17.0 18.0 19.0
将它们相加时,没有重叠的位置就会产生NA值:
df1 + df2
a b c d e
0 0.0 2.0 4.0 6.0 NaN
1 9.0 NaN 13.0 15.0 NaN
2 18.0 20.0 22.0 24.0 NaN
3 NaN NaN NaN NaN NaN
使用df1的add方法,传入df2以及一个fill_value参数:
df1.add(df2, fill_value=0)
a b c d e
0 0.0 2.0 4.0 6.0 4.0
1 9.0 5.0 13.0 15.0 9.0
2 18.0 20.0 22.0 24.0 14.0
3 15.0 16.0 17.0 18.0 19.0
下表列出了Series和DataFrame的算术方法。它们每个都有一个副本,以字母r开头,它会翻转参数。因此这两个语句是等价的:
1 / df1
a b c d
0 inf 1.000000 0.500000 0.333333
1 0.250000 0.200000 0.166667 0.142857
2 0.125000 0.111111 0.100000 0.090909
df1.rdiv(1)
a b c d
0 inf 1.000000 0.500000 0.333333
1 0.250000 0.200000 0.166667 0.142857
2 0.125000 0.111111 0.100000 0.090909
与此类似,在对Series或DataFrame重新索引时,也可以指定一个填充值:
df1.reindex(columns=df2.columns, fill_value=0)
a b c d e
0 0.0 1.0 2.0 3.0 0
1 4.0 5.0 6.0 7.0 0
2 8.0 9.0 10.0 11.0 0
DataFrame和Series之间的运算
跟不同维度的NumPy数组一样,DataFrame和Series之间算术运算也是有明确规定的。先来看一个具有启发性的例子,计算一个二维数组与其某行之间的差:
arr = np.arange(12.).reshape((3, 4))
arr
array([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
arr[0]
array([ 0., 1., 2., 3.])
arr - arr[0]
array([[ 0., 0., 0., 0.],
[ 4., 4., 4., 4.],
[ 8., 8., 8., 8.]])
当我们从arr减去arr[0],每一行都会执行这个操作。这就叫做广播(broadcasting)。DataFrame和Series之间的运算差不多也是如此:
frame = pd.DataFrame(np.arange(12.).reshape((4, 3)),columns=list('bde'),index=['Utah', 'Ohio', 'Texas', 'Oregon'])
series = frame.iloc[0]
frame
b d e
Utah 0.0 1.0 2.0
Ohio 3.0 4.0 5.0
Texas 6.0 7.0 8.0
Oregon 9.0 10.0 11.0
series
b 0.0
d 1.0
e 2.0
Name: Utah, dtype: float64
默认情况下,DataFrame和Series之间的算术运算会将Series的索引匹配到DataFrame的列,然后沿着行一直向下广播:
frame - series
b d e
Utah 0.0 0.0 0.0
Ohio 3.0 3.0 3.0
Texas 6.0 6.0 6.0
Oregon 9.0 9.0 9.0
如果某个索引值在DataFrame的列或Series的索引中找不到,则参与运算的两个对象就会被重新索引以形成并集:
series2 = pd.Series(range(3), index=['b', 'e', 'f'])
frame + series2
b d e f
Utah 0.0 NaN 3.0 NaN
Ohio 3.0 NaN 6.0 NaN
Texas 6.0 NaN 9.0 NaN
Oregon 9.0 NaN 12.0 NaN
如果你希望匹配行且在列上广播,则必须使用算术运算方法。例如:
series3 = frame['d']
frame
b d e
Utah 0.0 1.0 2.0
Ohio 3.0 4.0 5.0
Texas 6.0 7.0 8.0
Oregon 9.0 10.0 11.0
series3
Utah 1.0
Ohio 4.0
Texas 7.0
Oregon 10.0
Name: d, dtype: float64
frame.sub(series3, axis='index')
b d e
Utah -1.0 0.0 1.0
Ohio -1.0 0.0 1.0
Texas -1.0 0.0 1.0
Oregon -1.0 0.0 1.0
传入的轴号就是希望匹配的轴。在本例中,我们的目的是匹配DataFrame的行索引(axis='index' or axis=0)并进行广播。
函数应用和映射
NumPy的ufuncs(元素级数组方法)也可用于操作pandas对象:
frame = pd.DataFrame(np.random.randn(4, 3), columns=list('bde'),index=['Utah', 'Ohio', 'Texas', 'Oregon'])
frame
b d e
Utah -0.204708 0.478943 -0.519439
Ohio -0.555730 1.965781 1.393406
Texas 0.092908 0.281746 0.769023
Oregon 1.246435 1.007189 -1.296221
np.abs(frame)
b d e
Utah 0.204708 0.478943 0.519439
Ohio 0.555730 1.965781 1.393406
Texas 0.092908 0.281746 0.769023
Oregon 1.246435 1.007189 1.296221
另一个常见的操作是,将函数应用到由各列或行所形成的一维数组上。DataFrame的apply方法即可实现此功能:
f = lambda x: x.max() - x.min()
frame.apply(f)
b 1.802165
d 1.684034
e 2.689627
dtype: float64
这里的函数f,计算了一个Series的最大值和最小值的差,在frame的每列都执行了一次。结果是一个Series,使用frame的列作为索引。
如果传递axis='columns'到apply,这个函数会在每行执行:
frame.apply(f, axis='columns')
Utah 0.998382
Ohio 2.521511
Texas 0.676115
Oregon 2.542656
dtype: float64
许多最为常见的数组统计功能都被实现成DataFrame的方法(如sum和mean),因此无需使用apply方法。
传递到apply的函数不是必须返回一个标量,还可以返回由多个值组成的Series:
def f(x):
return pd.Series([x.min(), x.max()], index=['min', 'max'])
frame.apply(f)
b d e
min -0.555730 0.281746 -1.296221
max 1.246435 1.965781 1.393406
元素级的Python函数也是可以用的。假如你想得到frame中各个浮点值的格式化字符串,使用applymap即可:
format = lambda x: '%.2f' % x
frame.applymap(format)
b d e
Utah -0.20 0.48 -0.52
Ohio -0.56 1.97 1.39
Texas 0.09 0.28 0.77
Oregon 1.25 1.01 -1.30
之所以叫做applymap,是因为Series有一个用于应用元素级函数的map方法:
frame['e'].map(format)
Utah -0.52
Ohio 1.39
Texas 0.77
Oregon -1.30
Name: e, dtype: object
排序和排名
根据条件对数据集排序(sorting)也是一种重要的内置运算。要对行或列索引进行排序(按字典顺序),可使用sort_index方法,它将返回一个已排序的新对象:
obj = pd.Series(range(4), index=['d', 'a', 'b', 'c'])
obj.sort_index()
a 1
b 2
c 3
d 0
dtype: int64
对于DataFrame,则可以根据任意一个轴上的索引进行排序:
frame = pd.DataFrame(np.arange(8).reshape((2, 4)),index=['three', 'one'],columns=['d', 'a', 'b', 'c'])
frame.sort_index()
d a b c
one 4 5 6 7
three 0 1 2 3
frame.sort_index(axis=1)
a b c d
three 1 2 3 0
one 5 6 7 4
数据默认是按升序排序的,但也可以降序排序:
frame.sort_index(axis=1, ascending=False)
d c b a
three 0 3 2 1
one 4 7 6 5
若要按值对Series进行排序,可使用其sort_values方法:
obj = pd.Series([4, 7, -3, 2])
obj.sort_values()
2 -3
3 2
0 4
1 7
dtype: int64
在排序时,任何缺失值默认都会被放到Series的末尾:
obj = pd.Series([4, np.nan, 7, np.nan, -3, 2])
obj.sort_values()
4 -3.0
5 2.0
0 4.0
2 7.0
1 NaN
3 NaN
dtype: float64
当排序一个DataFrame时,你可能希望根据一个或多个列中的值进行排序。将一个或多个列的名字传递给sort_values的by选项即可达到该目的:
frame = pd.DataFrame({'b': [4, 7, -3, 2], 'a': [0, 1, 0, 1]})
frame
a b
0 0 4
1 1 7
2 0 -3
3 1 2
frame.sort_values(by='b')
a b
2 0 -3
3 1 2
0 0 4
1 1 7
要根据多个列进行排序,传入名称的列表即可:
frame.sort_values(by=['a', 'b'])
a b
2 0 -3
0 0 4
3 1 2
1 1 7
排名会从1开始一直到数组中有效数据的数量。接下来介绍Series和DataFrame的rank方法。默认情况下,rank是通过“为各组分配一个平均排名”的方式破坏平级关系的:
obj = pd.Series([7, -5, 7, 4, 2, 0, 4])
obj.rank()
0 6.5
1 1.0
2 6.5
3 4.5
4 3.0
5 2.0
6 4.5
dtype: float64
也可以根据值在原数据中出现的顺序给出排名:
obj.rank(method='first')
0 6.0
1 1.0
2 7.0
3 4.0
4 3.0
5 2.0
6 5.0
dtype: float64
这里,条目0和2没有使用平均排名6.5,它们被设成了6和7,因为数据中标签0位于标签2的前面。
你也可以按降序进行排名:
#Assign tie values the maximum rank in the group
obj.rank(ascending=False, method='max')
0 2.0
1 7.0
2 2.0
3 4.0
4 5.0
5 6.0
6 4.0
dtype: float64
下表列出了所有用于破坏平级关系的method选项。DataFrame可以在行或列上计算排名:
frame = pd.DataFrame({'b': [4.3, 7, -3, 2], 'a': [0, 1, 0, 1],'c': [-2, 5, 8, -2.5]})
frame
a b c
0 0 4.3 -2.0
1 1 7.0 5.0
2 0 -3.0 8.0
3 1 2.0 -2.5
frame.rank(axis='columns')
a b c
0 2.0 3.0 1.0
1 1.0 3.0 2.0
2 2.0 1.0 3.0
3 2.0 3.0 1.0

带有重复标签的轴索引
直到目前为止,我所介绍的所有范例都有着唯一的轴标签(索引值)。虽然许多pandas函数(如reindex)都要求标签唯一,但这并不是强制性的。我们来看看下面这个简单的带有重复索引值的Series:
obj = pd.Series(range(5), index=['a', 'a', 'b', 'b', 'c'])
obj
a 0
a 1
b 2
b 3
c 4
dtype: int64
索引的is_unique属性可以告诉你它的值是否是唯一的:
obj.index.is_unique
False
对于带有重复值的索引,数据选取的行为将会有些不同。如果某个索引对应多个值,则返回一个Series;而对应单个值的,则返回一个标量值:
obj['a']
a 0
a 1
dtype: int64
obj['c']
4
这样会使代码变复杂,因为索引的输出类型会根据标签是否有重复发生变化。
对DataFrame的行进行索引时也是如此:
df = pd.DataFrame(np.random.randn(4, 3), index=['a', 'a', 'b', 'b'])
df
0 1 2
a 0.274992 0.228913 1.352917
a 0.886429 -2.001637 -0.371843
b 1.669025 -0.438570 -0.539741
b 0.476985 3.248944 -1.021228
df.loc['b']
0 1 2
b 1.669025 -0.438570 -0.539741
b 0.476985 3.248944 -1.021228
汇总和计算描述统计
pandas对象拥有一组常用的数学和统计方法。它们大部分都属于约简和汇总统计,用于从Series中提取单个值(如sum或mean)或从DataFrame的行或列中提取一个Series。跟对应的NumPy数组方法相比,它们都是基于没有缺失数据的假设而构建的。看一个简单的DataFrame:
df = pd.DataFrame([[1.4, np.nan], [7.1, -4.5],[np.nan, np.nan], [0.75, -1.3]],index=['a', 'b', 'c', 'd'],columns=['one', 'two'])
df
one two
a 1.40 NaN
b 7.10 -4.5
c NaN NaN
d 0.75 -1.3
调用DataFrame的sum方法将会返回一个含有列的和的Series:
df.sum()
one 9.25
two -5.80
dtype: float64
传入axis='columns'或axis=1将会按行进行求和运算:
df.sum(axis=1)
a 1.40
b 2.60
c NaN
d -0.55
NA值会自动被排除,除非整个切片(这里指的是行或列)都是NA。通过skipna选项可以禁用该功能:
df.mean(axis='columns', skipna=False)
a NaN
b 1.300
c NaN
d -0.275
dtype: float64
下表列出了这些约简方法的常用选项。

有些方法(如idxmin和idxmax)返回的是间接统计(比如达到最小值或最大值的索引):
df.idxmax()
one b
two d
dtype: object
另一些方法则是累计型的:
df.cumsum()
one two
a 1.40 NaN
b 8.50 -4.5
c NaN NaN
d 9.25 -5.8
还有一种方法,它既不是约简型也不是累计型。describe就是一个例子,它用于一次性产生多个汇总统计:
df.describe()
one two
count 3.000000 2.000000
mean 3.083333 -2.900000
std 3.493685 2.262742
min 0.750000 -4.500000
25% 1.075000 -3.700000
50% 1.400000 -2.900000
75% 4.250000 -2.100000
max 7.100000 -1.300000
对于非数值型数据,describe会产生另外一种汇总统计:
obj = pd.Series(['a', 'a', 'b', 'c'] * 4)
obj.describe()
count 16
unique 3
top a
freq 8
dtype: object
下表列出了所有与描述统计相关的方法。

相关系数与协方差
有些汇总统计(如相关系数和协方差)是通过参数对计算出来的。我们来看几个DataFrame,它们的数据来自Yahoo!Finance的股票价格和成交量。
我使用pandas_datareader模块下载了一些股票数据:
import pandas_datareader.data as web
all_data = {ticker: web.get_data_yahoo(ticker)
for ticker in ['AAPL', 'IBM', 'MSFT', 'GOOG']}
price = pd.DataFrame({ticker: data['Adj Close']
for ticker, data in all_data.items()})
volume = pd.DataFrame({ticker: data['Volume']
for ticker, data in all_data.items()})
现在计算价格的百分数变化:
returns = price.pct_change()
returns.tail()
AAPL GOOG IBM MSFT
Date
2016-10-17 -0.000680 0.001837 0.002072 -0.003483
2016-10-18 -0.000681 0.019616 -0.026168 0.007690
2016-10-19 -0.002979 0.007846 0.003583 -0.002255
2016-10-20 -0.000512 -0.005652 0.001719 -0.004867
2016-10-21 -0.003930 0.003011 -0.012474 0.042096
Series的corr方法用于计算两个Series中重叠的、非NA的、按索引对齐的值的相关系数。与此类似,cov用于计算协方差:
returns['MSFT'].corr(returns['IBM'])
0.49976361144151144
returns['MSFT'].cov(returns['IBM'])
8.8706554797035462e-05
因为MSTF是一个合理的Python属性,我们还可以用更简洁的语法选择列:
returns.MSFT.corr(returns.IBM)
0.49976361144151144
另一方面,DataFrame的corr和cov方法将以DataFrame的形式分别返回完整的相关系数或协方差矩阵:
returns.corr()
AAPL GOOG IBM MSFT
AAPL 1.000000 0.407919 0.386817 0.389695
GOOG 0.407919 1.000000 0.405099 0.465919
IBM 0.386817 0.405099 1.000000 0.499764
MSFT 0.389695 0.465919 0.499764 1.000000
returns.cov()
AAPL GOOG IBM MSFT
AAPL 0.000277 0.000107 0.000078 0.000095
GOOG 0.000107 0.000251 0.000078 0.000108
IBM 0.000078 0.000078 0.000146 0.000089
MSFT 0.000095 0.000108 0.000089 0.000215
利用DataFrame的corrwith方法,你可以计算其列或行跟另一个Series或DataFrame之间的相关系数。传入一个Series将会返回一个相关系数值Series(针对各列进行计算):
returns.corrwith(returns.IBM)
AAPL 0.386817
GOOG 0.405099
IBM 1.000000
MSFT 0.499764
dtype: float64
传入一个DataFrame则会计算按列名配对的相关系数。这里,我计算百分比变化与成交量的相关系数:
returns.corrwith(volume)
AAPL -0.075565
GOOG -0.007067
IBM -0.204849
MSFT -0.092950
dtype: float64
传入axis='columns'即可按行进行计算。无论如何,在计算相关系数之前,所有的数据项都会按标签对齐。
唯一值、值计数以及成员资格
还有一类方法可以从一维Series的值中抽取信息。看下面的例子:
obj = pd.Series(['c', 'a', 'd', 'a', 'a', 'b', 'b', 'c', 'c'])
第一个函数是unique,它可以得到Series中的唯一值数组:
uniques = obj.unique()
uniques
array(['c', 'a', 'd', 'b'], dtype=object)
返回的唯一值是未排序的,如果需要的话,可以对结果再次进行排序(uniques.sort())。相似的,value_counts用于计算一个Series中各值出现的频率:
obj.value_counts()
c 3
a 3
b 2
d 1
dtype: int64
为了便于查看,结果Series是按值频率降序排列的。value_counts还是一个顶级pandas方法,可用于任何数组或序列:
pd.value_counts(obj.values, sort=False)
a 3
b 2
c 3
d 1
dtype: int64
isin用于判断矢量化集合的成员资格,可用于过滤Series中或DataFrame列中数据的子集:
obj
0 c
1 a
2 d
3 a
4 a
5 b
6 b
7 c
8 c
dtype: object
mask = obj.isin(['b', 'c'])
mask
0 True
1 False
2 False
3 False
4 False
5 True
6 True
7 True
8 True
dtype: bool
obj[mask]
0 c
5 b
6 b
7 c
8 c
dtype: object
与isin类似的是Index.get_indexer方法,它可以给你一个索引数组,从可能包含重复值的数组到另一个不同值的数组:
to_match = pd.Series(['c', 'a', 'b', 'b', 'c', 'a'])
unique_vals = pd.Series(['c', 'b', 'a'])
pd.Index(unique_vals).get_indexer(to_match)
array([0, 2, 1, 1, 0, 2])
下表给出了这几个方法的一些参考信息。

有时,你可能希望得到DataFrame中多个相关列的一张柱状图。例如:
data = pd.DataFrame({'Qu1': [1, 3, 4, 3, 4],
'Qu2': [2, 3, 1, 2, 3],
'Qu3': [1, 5, 2, 4, 4]})
data
Qu1 Qu2 Qu3
0 1 2 1
1 3 3 5
2 4 1 2
3 3 2 4
4 4 3 4
将pandas.value_counts传给该DataFrame的apply函数,就会出现:
result = data.apply(pd.value_counts).fillna(0)
result
Qu1 Qu2 Qu3
1 1.0 1.0 1.0
2 0.0 2.0 1.0
3 2.0 2.0 0.0
4 2.0 0.0 2.0
5 0.0 0.0 1.0
这里,结果中的行标签是所有列的唯一值。后面的频率值是每个列中这些值的相应计数。
数据加载、存储与文件格式
读写文本格式的数据
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数。下表对它们进行了总结,其中read_csv和read_table可能会是你今后用得最多的。
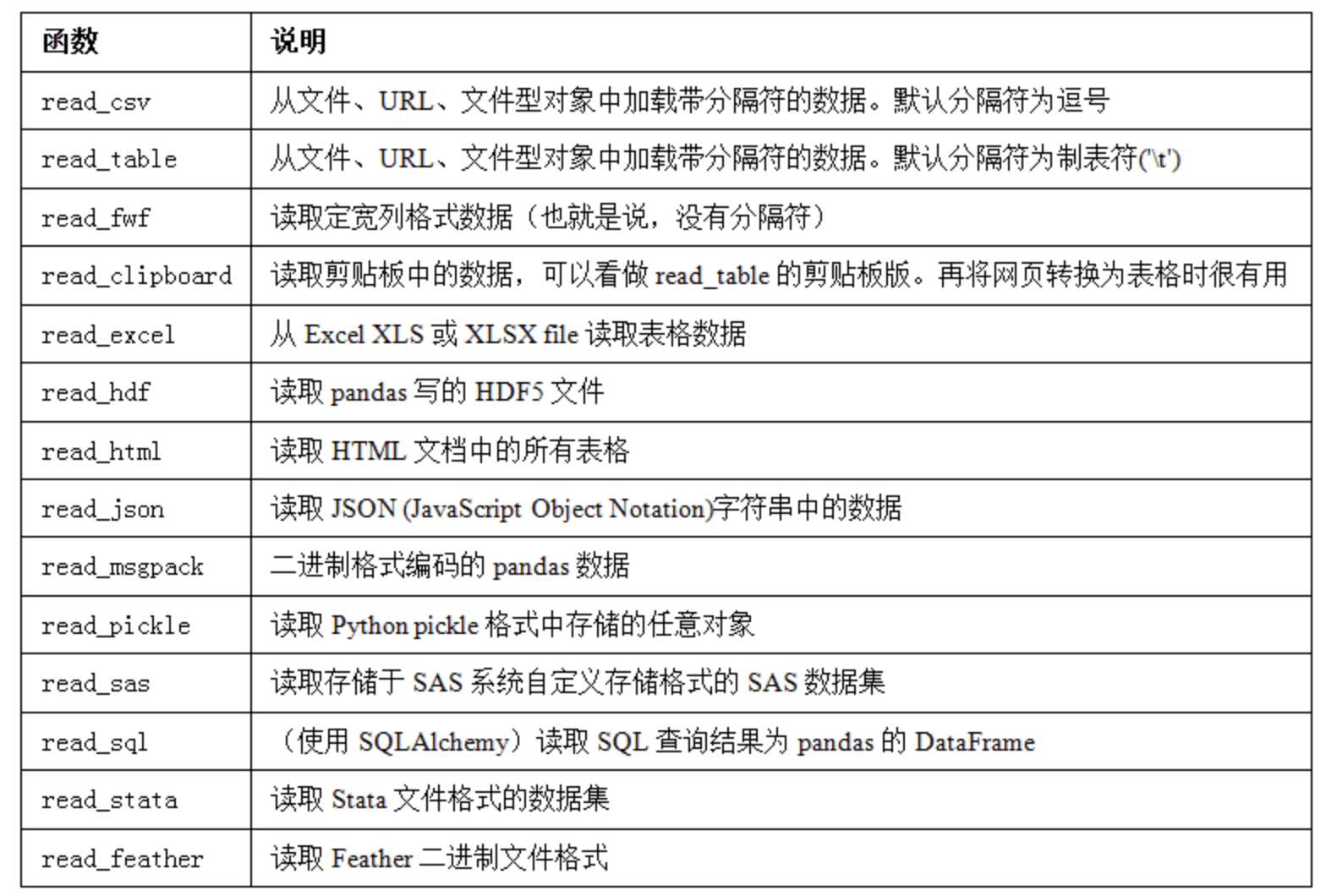
我将大致介绍一下这些函数在将文本数据转换为DataFrame时所用到的一些技术。这些函数的选项可以划分为以下几个大类:
- 索引:将一个或多个列当做返回的
DataFrame处理,以及是否从文件、用户获取列名。 - 类型推断和数据转换:包括用户定义值的转换、和自定义的缺失值标记列表等。
- 日期解析:包括组合功能,比如将分散在多个列中的日期时间信息组合成结果中的单个列。
- 迭代:支持对大文件进行逐块迭代。
- 不规整数据问题:跳过一些行、页脚、注释或其他一些不重要的东西(比如由成千上万个逗号隔开的数值数据)。
因为工作中实际碰到的数据可能十分混乱,一些数据加载函数(尤其是read_csv)的选项逐渐变得复杂起来。面对不同的参数,感到头痛很正常(read_csv有超过50个参数)。pandas文档有这些参数的例子,如果你感到阅读某个文件很难,可以通过相似的足够多的例子找到正确的参数。
其中一些函数,比如pandas.read_csv,有类型推断功能,因为列数据的类型不属于数据类型。也就是说,你不需要指定列的类型到底是数值、整数、布尔值,还是字符串。其它的数据格式,如HDF5、Feather和msgpack,会在格式中存储数据类型。
日期和其他自定义类型的处理需要多花点工夫才行。首先我们来看一个以逗号分隔的(CSV)文本文件:
a,b,c,d,message
1,2,3,4,hello
5,6,7,8,world
9,10,11,12,foo
由于该文件以逗号分隔,所以我们可以使用read_csv将其读入一个DataFrame:
df = pd.read_csv('examples/ex1.csv')
df
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
我们还可以使用read_table,并指定分隔符:
pd.read_table('examples/ex1.csv', sep=',')
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
并不是所有文件都有标题行。看看下面这个文件:
1,2,3,4,hello
5,6,7,8,world
9,10,11,12,foo
读入该文件的办法有两个。你可以让pandas为其分配默认的列名,也可以自己定义列名:
pd.read_csv('examples/ex2.csv', header=None)
0 1 2 3 4
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
pd.read_csv('examples/ex2.csv', names=['a', 'b', 'c', 'd', 'message'])
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
假设你希望将message列做成DataFrame的索引。你可以明确表示要将该列放到索引4的位置上,也可以通过index_col参数指定"message":
names = ['a', 'b', 'c', 'd', 'message']
pd.read_csv('examples/ex2.csv', names=names, index_col='message')
a b c d
message
hello 1 2 3 4
world 5 6 7 8
foo 9 10 11 12
如果希望将多个列做成一个层次化索引,只需传入由列编号或列名组成的列表即可:
key1,key2,value1,value2
one,a,1,2
one,b,3,4
one,c,5,6
one,d,7,8
two,a,9,10
two,b,11,12
two,c,13,14
two,d,15,16
parsed = pd.read_csv('examples/csv_mindex.csv',index_col=['key1', 'key2'])
parsed
value1 value2
key1 key2
one a 1 2
b 3 4
c 5 6
d 7 8
two a 9 10
b 11 12
c 13 14
d 15 16
有些情况下,有些表格可能不是用固定的分隔符去分隔字段的(比如空白符或其它模式)。看看下面这个文本文件:
list(open('examples/ex3.txt'))
[' A B C\n',
'aaa -0.264438 -1.026059 -0.619500\n',
'bbb 0.927272 0.302904 -0.032399\n',
'ccc -0.264273 -0.386314 -0.217601\n',
'ddd -0.871858 -0.348382 1.100491\n']
虽然可以手动对数据进行规整,这里的字段是被数量不同的空白字符间隔开的。这种情况下,你可以传递一个正则表达式作为read_table的分隔符。可以用正则表达式表达为\s+,于是有:
result = pd.read_table('examples/ex3.txt', sep='\s+')
result
A B C
aaa -0.264438 -1.026059 -0.619500
bbb 0.927272 0.302904 -0.032399
ccc -0.264273 -0.386314 -0.217601
ddd -0.871858 -0.348382 1.100491
这里,由于列名比数据行的数量少,所以read_table推断第一列应该是DataFrame的索引。
这些解析器函数还有许多参数可以帮助你处理各种各样的异形文件格式。
缺失值处理是文件解析任务中的一个重要组成部分。缺失数据经常是要么没有(空字符串),要么用某个标记值表示。默认情况下,pandas会用一组经常出现的标记值进行识别,比如NA及NULL:
something,a,b,c,d,message
one,1,2,3,4,NA
two,5,6,,8,world
three,9,10,11,12,foo
result = pd.read_csv('examples/ex5.csv')
result
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 foo
pd.isnull(result)
something a b c d message
0 False False False False False True
1 False False False True False False
2 False False False False False False
na_values可以用一个列表或集合的字符串表示缺失值:
result = pd.read_csv('examples/ex5.csv', na_values=['NULL'])
result
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 foo
字典的各列可以使用不同的NA标记值:
sentinels = {'message': ['foo', 'NA'], 'something': ['two']}
pd.read_csv('examples/ex5.csv', na_values=sentinels)
something a b c d message
0 one 1 2 3.0 4 NaN
1 NaN 5 6 NaN 8 world
2 three 9 10 11.0 12 NaN
下表列出了pandas.read_csv和pandas.read_table常用的选项。
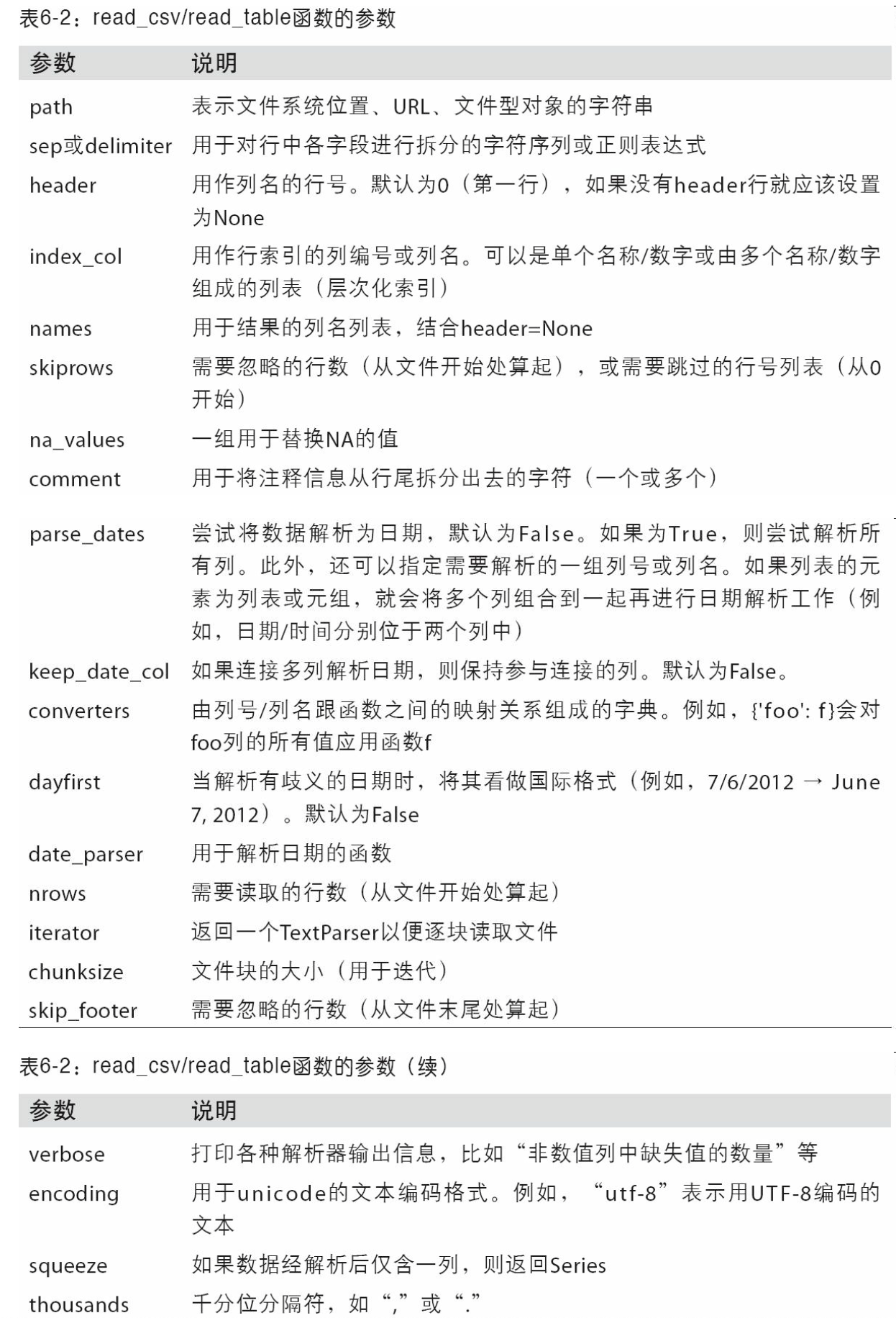
逐块读取文本文件
在处理很大的文件时,或找出大文件中的参数集以便于后续处理时,你可能只想读取文件的一小部分或逐块对文件进行迭代。
在看大文件之前,我们先设置pandas显示地更紧些:
result = pd.read_csv('examples/ex6.csv')
result
one two three four key
0 0.467976 -0.038649 -0.295344 -1.824726 L
1 -0.358893 1.404453 0.704965 -0.200638 B
2 -0.501840 0.659254 -0.421691 -0.057688 G
3 0.204886 1.074134 1.388361 -0.982404 R
4 0.354628 -0.133116 0.283763 -0.837063 Q
... ... ... ... ... ..
9995 2.311896 -0.417070 -1.409599 -0.515821 L
9996 -0.479893 -0.650419 0.745152 -0.646038 E
9997 0.523331 0.787112 0.486066 1.093156 K
9998 -0.362559 0.598894 -1.843201 0.887292 G
9999 -0.096376 -1.012999 -0.657431 -0.573315 0
[10000 rows x 5 columns]
如果只想读取几行(避免读取整个文件),通过nrows进行指定即可:
pd.read_csv('examples/ex6.csv', nrows=5)
one two three four key
0 0.467976 -0.038649 -0.295344 -1.824726 L
1 -0.358893 1.404453 0.704965 -0.200638 B
2 -0.501840 0.659254 -0.421691 -0.057688 G
3 0.204886 1.074134 1.388361 -0.982404 R
4 0.354628 -0.133116 0.283763 -0.837063 Q
要逐块读取文件,可以指定chunksize(行数):
chunker = pd.read_csv('ch06/ex6.csv', chunksize=1000)
chunker
<pandas.io.parsers.TextParser at 0x8398150>
read_csv所返回的这个TextParser对象使你可以根据chunksize对文件进行逐块迭代。比如说,我们可以迭代处理ex6.csv,将值计数聚合到"key"列中,如下所示:
chunker = pd.read_csv('examples/ex6.csv', chunksize=1000)
tot = pd.Series([])
for piece in chunker:
tot = tot.add(piece['key'].value_counts(), fill_value=0)
tot = tot.sort_values(ascending=False)
然后有:
tot[:10]
E 368.0
X 364.0
L 346.0
O 343.0
Q 340.0
M 338.0
J 337.0
F 335.0
K 334.0
H 330.0
dtype: float64
TextParser还有一个get_chunk方法,它使你可以读取任意大小的块。
将数据写出到文本格式
数据也可以被输出为分隔符格式的文本。我们再来看看之前读过的一个CSV文件:
data = pd.read_csv('examples/ex5.csv')
data
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 foo
利用DataFrame的to_csv方法,我们可以将数据写到一个以逗号分隔的文件中:
data.to_csv('examples/out.csv')
,something,a,b,c,d,message
0,one,1,2,3.0,4,
1,two,5,6,,8,world
2,three,9,10,11.0,12,foo
当然,还可以使用其他分隔符(由于这里直接写出到sys.stdout,所以仅仅是打印出文本结果而已):
import sys
data.to_csv(sys.stdout, sep='|')
|something|a|b|c|d|message
0|one|1|2|3.0|4|
1|two|5|6||8|world
2|three|9|10|11.0|12|foo
缺失值在输出结果中会被表示为空字符串。你可能希望将其表示为别的标记值:
data.to_csv(sys.stdout, na_rep='NULL')
,something,a,b,c,d,message
0,one,1,2,3.0,4,NULL
1,two,5,6,NULL,8,world
2,three,9,10,11.0,12,foo
如果没有设置其他选项,则会写出行和列的标签。当然,它们也都可以被禁用:
data.to_csv(sys.stdout, index=False, header=False)
one,1,2,3.0,4,
two,5,6,,8,world
three,9,10,11.0,12,foo
此外,你还可以只写出一部分的列,并以你指定的顺序排列:
data.to_csv(sys.stdout, index=False, columns=['a', 'b', 'c'])
a,b,c
1,2,3.0
5,6,
9,10,11.0
Series也有一个to_csv方法:
dates = pd.date_range('1/1/2000', periods=7)
ts = pd.Series(np.arange(7), index=dates)
ts.to_csv('examples/tseries.csv')
2000-01-01,0
2000-01-02,1
2000-01-03,2
2000-01-04,3
2000-01-05,4
2000-01-06,5
2000-01-07,6
处理分隔符格式
大部分存储在磁盘上的表格型数据都能用pandas.read_table进行加载。然而,有时还是需要做一些手工处理。由于接收到含有畸形行的文件而使read_table出毛病的情况并不少见。为了说明这些基本工具,看看下面这个简单的CSV文件:
"a","b","c"
"1","2","3"
"1","2","3"
对于任何单字符分隔符文件,可以直接使用Python内置的csv模块。将任意已打开的文件或文件型的对象传给csv.reader:
import csv
f = open('examples/ex7.csv')
reader = csv.reader(f)
对这个reader进行迭代将会为每行产生一个元组(并移除了所有的引号):
for line in reader:
print(line)
['a', 'b', 'c']
['1', '2', '3']
['1', '2', '3']
现在,为了使数据格式合乎要求,你需要对其做一些整理工作。我们一步一步来做。首先,读取文件到一个多行的列表中:
with open('examples/ex7.csv') as f:
lines = list(csv.reader(f))
然后,我们将这些行分为标题行和数据行:
header, values = lines[0], lines[1:]
然后,我们可以用字典构造式和zip(*values),后者将行转置为列,创建数据列的字典:
data_dict = {h: v for h, v in zip(header, zip(*values))}
data_dict
{'a': ('1', '1'), 'b': ('2', '2'), 'c': ('3', '3')}
CSV文件的形式有很多。只需定义csv.Dialect的一个子类即可定义出新格式(如专门的分隔符、字符串引用约定、行结束符等):
class my_dialect(csv.Dialect):
lineterminator = '\n'
delimiter = ';'
quotechar = '"'
quoting = csv.QUOTE_MINIMAL
reader = csv.reader(f, dialect=my_dialect)
各个CSV语支的参数也可以用关键字的形式提供给csv.reader,而无需定义子类:
reader = csv.reader(f, delimiter='|')
可用的选项(csv.Dialect的属性)及其功能如下表所示。
笔记:对于那些使用复杂分隔符或多字符分隔符的文件,csv模块就无能为力了。这种情况下,你就只能使用字符串的split方法或正则表达式方法re.split进行行拆分和其他整理工作了。

要手工输出分隔符文件,你可以使用csv.writer。它接受一个已打开且可写的文件对象以及跟csv.reader相同的那些语支和格式化选项:
with open('mydata.csv', 'w') as f:
writer = csv.writer(f, dialect=my_dialect)
writer.writerow(('one', 'two', 'three'))
writer.writerow(('1', '2', '3'))
writer.writerow(('4', '5', '6'))
writer.writerow(('7', '8', '9'))
JSON数据
JSON(JavaScript Object Notation的简称)已经成为通过HTTP请求在Web浏览器和其他应用程序之间发送数据的标准格式之一。它是一种比表格型文本格式(如CSV)灵活得多的数据格式。下面是一个例子:
obj = """
{"name": "Wes",
"places_lived": ["United States", "Spain", "Germany"],
"pet": null,
"siblings": [{"name": "Scott", "age": 30, "pets": ["Zeus", "Zuko"]},
{"name": "Katie", "age": 38,
"pets": ["Sixes", "Stache", "Cisco"]}]
}
"""
除其空值null和一些其他的细微差别(如列表末尾不允许存在多余的逗号)之外,JSON非常接近于有效的Python代码。基本类型有对象(字典)、数组(列表)、字符串、数值、布尔值以及null。对象中所有的键都必须是字符串。许多Python库都可以读写JSON数据。我将使用json,因为它是构建于Python标准库中的。通过json.loads即可将JSON字符串转换成Python形式:
import json
result = json.loads(obj)
result
{'name': 'Wes',
'pet': None,
'places_lived': ['United States', 'Spain', 'Germany'],
'siblings': [{'age': 30, 'name': 'Scott', 'pets': ['Zeus', 'Zuko']},
{'age': 38, 'name': 'Katie', 'pets': ['Sixes', 'Stache', 'Cisco']}]}
json.dumps则将Python对象转换成JSON格式:
asjson = json.dumps(result)
如何将(一个或一组)JSON对象转换为DataFrame或其他便于分析的数据结构就由你决定了。最简单方便的方式是:向DataFrame构造器传入一个字典的列表(就是原先的JSON对象),并选取数据字段的子集:
siblings = pd.DataFrame(result['siblings'], columns=['name', 'age'])
siblings
name age
0 Scott 30
1 Katie 38
pandas.read_json可以自动将特别格式的JSON数据集转换为Series或DataFrame。例如:
[{"a": 1, "b": 2, "c": 3},
{"a": 4, "b": 5, "c": 6},
{"a": 7, "b": 8, "c": 9}]
pandas.read_json的默认选项假设JSON数组中的每个对象是表格中的一行:
data = pd.read_json('examples/example.json')
data
a b c
0 1 2 3
1 4 5 6
2 7 8 9
如果你需要将数据从pandas输出到JSON,可以使用to_json方法:
print(data.to_json())
{"a":{"0":1,"1":4,"2":7},"b":{"0":2,"1":5,"2":8},"c":{"0":3,"1":6,"2":9}}
print(data.to_json(orient='records'))
[{"a":1,"b":2,"c":3},{"a":4,"b":5,"c":6},{"a":7,"b":8,"c":9}]
二进制数据格式
实现数据的高效二进制格式存储最简单的办法之一是使用Python内置的pickle序列化。pandas对象都有一个用于将数据以pickle格式保存到磁盘上的to_pickle方法:
frame = pd.read_csv('examples/ex1.csv')
frame
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
frame.to_pickle('examples/frame_pickle')
你可以通过pickle直接读取被pickle化的数据,或是使用更为方便的pandas.read_pickle:
pd.read_pickle('examples/frame_pickle')
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
注意:pickle仅建议用于短期存储格式。其原因是很难保证该格式永远是稳定的;今天pickle的对象可能无法被后续版本的库unpickle出来。虽然我尽力保证这种事情不会发生在pandas中,但是今后的某个时候说不定还是得“打破”该pickle格式。
pandas内置支持两个二进制数据格式:HDF5和MessagePack。
使用HDF5格式
HDF5是一种存储大规模科学数组数据的非常好的文件格式。它可以被作为C标准库。HDF5中的HDF指的是层次型数据格式(hierarchical data format)。每个HDF5文件都含有一个文件系统式的节点结构,它使你能够存储多个数据集并支持元数据。与其他简单格式相比,HDF5支持多种压缩器的即时压缩,还能更高效地存储重复模式数据。对于那些非常大的无法直接放入内存的数据集,HDF5就是不错的选择,因为它可以高效地分块读写。
虽然可以用PyTables或h5py库直接访问HDF5文件,pandas提供了更为高级的接口,可以简化存储Series和DataFrame对象。HDFStore类可以像字典一样,处理低级的细节:
frame = pd.DataFrame({'a': np.random.randn(100)})
store = pd.HDFStore('mydata.h5')
store['obj1'] = frame
store['obj1_col'] = frame['a']
store
<class 'pandas.io.pytables.HDFStore'>
File path: mydata.h5
/obj1 frame (shape->[100,1])
/obj1_col series (shape->[100])
/obj2 frame_table (typ->appendable,nrows->100,ncols->1,indexers->
[index])
/obj3 frame_table (typ->appendable,nrows->100,ncols->1,indexers->
[index])
HDF5文件中的对象可以通过与字典一样的API进行获取:
store['obj1']
a
0 -0.204708
1 0.478943
2 -0.519439
3 -0.555730
4 1.965781
.. ...
95 0.795253
96 0.118110
97 -0.748532
98 0.584970
99 0.152677
[100 rows x 1 columns]
HDFStore支持两种存储模式,'fixed'和'table'。后者通常会更慢,但是支持使用特殊语法进行查询操作:
store.put('obj2', frame, format='table')
store.select('obj2', where=['index >= 10 and index <= 15'])
a
10 1.007189
11 -1.296221
12 0.274992
13 0.228913
14 1.352917
15 0.886429
store.close()
put是store['obj2'] = frame方法的显示版本,允许我们设置其它的选项,比如格式。
pandas.read_hdf函数可以快捷使用这些工具:
frame.to_hdf('mydata.h5', 'obj3', format='table')
pd.read_hdf('mydata.h5', 'obj3', where=['index < 5'])
a
0 -0.204708
1 0.478943
2 -0.519439
3 -0.555730
4 1.965781
如果需要本地处理海量数据,我建议你好好研究一下PyTables和h5py,看看它们能满足你的哪些需求。。由于许多数据分析问题都是IO密集型(而不是CPU密集型),利用HDF5这样的工具能显著提升应用程序的效率。
注意:HDF5不是数据库。它最适合用作“一次写多次读”的数据集。虽然数据可以在任何时候被添加到文件中,但如果同时发生多个写操作,文件就可能会被破坏。
数据清洗和准备
处理缺失数据
在许多数据分析工作中,缺失数据是经常发生的。pandas的目标之一就是尽量轻松地处理缺失数据。例如,pandas对象的所有描述性统计默认都不包括缺失数据。
缺失数据在pandas中呈现的方式有些不完美,但对于大多数用户可以保证功能正常。对于数值数据,pandas使用浮点值NaN(Not a Number)表示缺失数据。我们称其为哨兵值,可以方便的检测出来:
string_data = pd.Series(['aardvark', 'artichoke', np.nan, 'avocado'])
string_data
0 aardvark
1 artichoke
2 NaN
3 avocado
dtype: object
string_data.isnull()
0 False
1 False
2 True
3 False
dtype: bool
在pandas中,我们采用了R语言中的惯用法,即将缺失值表示为NA,它表示不可用not available。在统计应用中,NA数据可能是不存在的数据或者虽然存在,但是没有观察到(例如,数据采集中发生了问题)。当进行数据清洗以进行分析时,最好直接对缺失数据进行分析,以判断数据采集的问题或缺失数据可能导致的偏差。
Python内置的None值在对象数组中也可以作为NA:
string_data[0] = None
string_data.isnull()
0 True
1 False
2 True
3 False
dtype: bool
pandas项目中还在不断优化内部细节以更好处理缺失数据,像用户API功能,例如pandas.isnull,去除了许多恼人的细节。下表列出了一些关于缺失数据处理的函数。

滤除缺失数据
过滤掉缺失数据的办法有很多种。你可以通过pandas.isnull或布尔索引的手工方法,但dropna可能会更实用一些。对于一个Series,dropna返回一个仅含非空数据和索引值的Series:
from numpy import nan as NA
data = pd.Series([1, NA, 3.5, NA, 7])
data.dropna()
0 1.0
2 3.5
4 7.0
dtype: float64
这等价于:
data[data.notnull()]
0 1.0
2 3.5
4 7.0
dtype: float64
而对于DataFrame对象,事情就有点复杂了。你可能希望丢弃全NA或含有NA的行或列。dropna默认丢弃任何含有缺失值的行:
data = pd.DataFrame([[1., 6.5, 3.], [1., NA, NA],[NA, NA, NA], [NA, 6.5, 3.]])
cleaned = data.dropna()
data
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
cleaned
0 1 2
0 1.0 6.5 3.0
传入how='all'将只丢弃全为NA的那些行:
data.dropna(how='all')
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
3 NaN 6.5 3.0
用这种方式丢弃列,只需传入axis=1即可:
data[4] = NA
data
0 1 2 4
0 1.0 6.5 3.0 NaN
1 1.0 NaN NaN NaN
2 NaN NaN NaN NaN
3 NaN 6.5 3.0 NaN
data.dropna(axis=1, how='all')
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
另一个滤除DataFrame行的问题涉及时间序列数据。假设你只想留下一部分观测数据,可以用thresh参数实现此目的:
df = pd.DataFrame(np.random.randn(7, 3))
df.iloc[:4, 1] = NA
df.iloc[:2, 2] = NA
df
0 1 2
0 -0.204708 NaN NaN
1 -0.555730 NaN NaN
2 0.092908 NaN 0.769023
3 1.246435 NaN -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
df.dropna()
0 1 2
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
df.dropna(thresh=2)
0 1 2
2 0.092908 NaN 0.769023
3 1.246435 NaN -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
填充缺失数据
你可能不想滤除缺失数据(有可能会丢弃跟它有关的其他数据),而是希望通过其他方式填补那些“空洞”。对于大多数情况而言,fillna方法是最主要的函数。通过一个常数调用fillna就会将缺失值替换为那个常数值:
df.fillna(0)
0 1 2
0 -0.204708 0.000000 0.000000
1 -0.555730 0.000000 0.000000
2 0.092908 0.000000 0.769023
3 1.246435 0.000000 -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
若是通过一个字典调用fillna,就可以实现对不同的列填充不同的值:
df.fillna({1: 0.5, 2: 0})
0 1 2
0 -0.204708 0.500000 0.000000
1 -0.555730 0.500000 0.000000
2 0.092908 0.500000 0.769023
3 1.246435 0.500000 -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
fillna默认会返回新对象,但也可以对现有对象进行就地修改:
_ = df.fillna(0, inplace=True)
df
0 1 2
0 -0.204708 0.000000 0.000000
1 -0.555730 0.000000 0.000000
2 0.092908 0.000000 0.769023
3 1.246435 0.000000 -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
对reindexing有效的那些插值方法也可用于fillna:
df = pd.DataFrame(np.random.randn(6, 3))
df.iloc[2:, 1] = NA
df.iloc[4:, 2] = NA
df
0 1 2
0 0.476985 3.248944 -1.021228
1 -0.577087 0.124121 0.302614
2 0.523772 NaN 1.343810
3 -0.713544 NaN -2.370232
4 -1.860761 NaN NaN
5 -1.265934 NaN NaN
df.fillna(method='ffill')
0 1 2
0 0.476985 3.248944 -1.021228
1 -0.577087 0.124121 0.302614
2 0.523772 0.124121 1.343810
3 -0.713544 0.124121 -2.370232
4 -1.860761 0.124121 -2.370232
5 -1.265934 0.124121 -2.370232
df.fillna(method='ffill', limit=2)
0 1 2
0 0.476985 3.248944 -1.021228
1 -0.577087 0.124121 0.302614
2 0.523772 0.124121 1.343810
3 -0.713544 0.124121 -2.370232
4 -1.860761 NaN -2.370232
5 -1.265934 NaN -2.370232
只要有些创新,你就可以利用fillna实现许多别的功能。比如说,你可以传入Series的平均值或中位数:
data = pd.Series([1., NA, 3.5, NA, 7])
data.fillna(data.mean())
0 1.000000
1 3.833333
2 3.500000
3 3.833333
4 7.000000
dtype: float64
下表列出了fillna的参考。


数据转换
移除重复数据
DataFrame中出现重复行有多种原因。下面就是一个例子:
data = pd.DataFrame({'k1': ['one', 'two'] * 3 + ['two'],'k2': [1, 1, 2, 3, 3, 4, 4]})
data
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
6 two 4
DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复行(前面出现过的行):
data.duplicated()
0 False
1 False
2 False
3 False
4 False
5 False
6 True
dtype: bool
还有一个与此相关的drop_duplicates方法,它会返回一个DataFrame,重复的数组会标为False:
data.drop_duplicates()
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
这两个方法默认会判断全部列,你也可以指定部分列进行重复项判断。假设我们还有一列值,且只希望根据k1列过滤重复项:
data['v1'] = range(7)
data.drop_duplicates(['k1'])
k1 k2 v1
0 one 1 0
1 two 1 1
duplicated和drop_duplicates默认保留的是第一个出现的值组合。传入keep='last'则保留最后一个:
data.drop_duplicates(['k1', 'k2'], keep='last')
k1 k2 v1
0 one 1 0
1 two 1 1
2 one 2 2
3 two 3 3
4 one 3 4
6 two 4 6
利用函数或映射进行数据转换
对于许多数据集,你可能希望根据数组、Series或DataFrame列中的值来实现转换工作。我们来看看下面这组有关肉类的数据:
data = pd.DataFrame({'food': ['bacon', 'pulled pork', 'bacon','Pastrami', 'corned beef', 'Bacon','pastrami', 'honey ham', 'nova lox'],'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})
data
food ounces
0 bacon 4.0
1 pulled pork 3.0
2 bacon 12.0
3 Pastrami 6.0
4 corned beef 7.5
5 Bacon 8.0
6 pastrami 3.0
7 honey ham 5.0
8 nova lox 6.0
假设你想要添加一列表示该肉类食物来源的动物类型。我们先编写一个不同肉类到动物的映射:
meat_to_animal = {
'bacon': 'pig',
'pulled pork': 'pig',
'pastrami': 'cow',
'corned beef': 'cow',
'honey ham': 'pig',
'nova lox': 'salmon'
}
Series的map方法可以接受一个函数或含有映射关系的字典型对象,但是这里有一个小问题,即有些肉类的首字母大写了,而另一些则没有。因此,我们还需要使用Series的str.lower方法,将各个值转换为小写:
lowercased = data['food'].str.lower()
lowercased
0 bacon
1 pulled pork
2 bacon
3 pastrami
4 corned beef
5 bacon
6 pastrami
7 honey ham
8 nova lox
Name: food, dtype: object
data['animal'] = lowercased.map(meat_to_animal)
data
food ounces animal
0 bacon 4.0 pig
1 pulled pork 3.0 pig
2 bacon 12.0 pig
3 Pastrami 6.0 cow
4 corned beef 7.5 cow
5 Bacon 8.0 pig
6 pastrami 3.0 cow
7 honey ham 5.0 pig
8 nova lox 6.0 salmon
我们也可以传入一个能够完成全部这些工作的函数:
data['food'].map(lambda x: meat_to_animal[x.lower()])
0 pig
1 pig
2 pig
3 cow
4 cow
5 pig
6 cow
7 pig
8 salmon
Name: food, dtype: object
使用map是一种实现元素级转换以及其他数据清理工作的便捷方式。
替换值
利用fillna方法填充缺失数据可以看做值替换的一种特殊情况。前面已经看到,map可用于修改对象的数据子集,而replace则提供了一种实现该功能的更简单、更灵活的方式。我们来看看下面这个Series:
data = pd.Series([1., -999., 2., -999., -1000., 3.])
data
0 1.0
1 -999.0
2 2.0
3 -999.0
4 -1000.0
5 3.0
-999这个值可能是一个表示缺失数据的标记值。要将其替换为pandas能够理解的NA值,我们可以利用replace来产生一个新的Series(除非传入inplace=True):
data.replace(-999, np.nan)
0 1.0
1 NaN
2 2.0
3 NaN
4 -1000.0
5 3.0
dtype: float64
如果你希望一次性替换多个值,可以传入一个由待替换值组成的列表以及一个替换值::
data.replace([-999, -1000], np.nan)
0 1.0
1 NaN
2 2.0
3 NaN
4 NaN
5 3.0
dtype: float64
要让每个值有不同的替换值,可以传递一个替换列表:
data.replace([-999, -1000], [np.nan, 0])
0 1.0
1 NaN
2 2.0
3 NaN
4 0.0
5 3.0
dtype: float64
传入的参数也可以是字典:
data.replace({-999: np.nan, -1000: 0})
0 1.0
1 NaN
2 2.0
3 NaN
4 0.0
5 3.0
dtype: float64
笔记:data.replace方法与data.str.replace不同,后者做的是字符串的元素级替换。我们会在后面学习Series的字符串方法。
重命名轴索引
跟Series中的值一样,轴标签也可以通过函数或映射进行转换,从而得到一个新的不同标签的对象。轴还可以被就地修改,而无需新建一个数据结构。接下来看看下面这个简单的例子:
data = pd.DataFrame(np.arange(12).reshape((3, 4)),index=['Ohio', 'Colorado', 'New York'],columns=['one', 'two', 'three', 'four'])
跟Series一样,轴索引也有一个map方法:
transform = lambda x: x[:4].upper()
data.index.map(transform)
Index(['OHIO', 'COLO', 'NEW '], dtype='object')
你可以将其赋值给index,这样就可以对DataFrame进行就地修改:
data.index = data.index.map(transform)
data
one two three four
OHIO 0 1 2 3
COLO 4 5 6 7
NEW 8 9 10 11
如果想要创建数据集的转换版(而不是修改原始数据),比较实用的方法是rename:
data.rename(index=str.title, columns=str.upper)
ONE TWO THREE FOUR
Ohio 0 1 2 3
Colo 4 5 6 7
New 8 9 10 11
特别说明一下,rename可以结合字典型对象实现对部分轴标签的更新:
data.rename(index={'OHIO': 'INDIANA'},columns={'three': 'peekaboo'})
one two peekaboo four
INDIANA 0 1 2 3
COLO 4 5 6 7
NEW 8 9 10 11
rename可以实现复制DataFrame并对其索引和列标签进行赋值。如果希望就地修改某个数据集,传入inplace=True即可:
data.rename(index={'OHIO': 'INDIANA'}, inplace=True)
data
one two three four
INDIANA 0 1 2 3
COLO 4 5 6 7
NEW 8 9 10 11
离散化和面元划分
为了便于分析,连续数据常常被离散化或拆分为“面元”(bin)。假设有一组人员数据,而你希望将它们划分为不同的年龄组:
ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]
接下来将这些数据划分为“18到25”、“26到35”、“35到60”以及“60以上”几个面元。要实现该功能,你需要使用pandas的cut函数:
bins = [18, 25, 35, 60, 100]
cats = pd.cut(ages, bins)
cats
[(18, 25], (18, 25], (18, 25], (25, 35], (18, 25], ..., (25, 35], (60, 100], (35,60], (35, 60], (25, 35]]
Length: 12
Categories (4, interval[int64]): [(18, 25] < (25, 35] < (35, 60] < (60, 100]]
pandas返回的是一个特殊的Categorical对象。结果展示了pandas.cut划分的面元。你可以将其看做一组表示面元名称的字符串。它的底层含有一个表示不同分类名称的类型数组,以及一个codes属性中的年龄数据的标签:
cats.codes
array([0, 0, 0, 1, 0, 0, 2, 1, 3, 2, 2, 1], dtype=int8)
cats.categories
IntervalIndex([(18, 25], (25, 35], (35, 60], (60, 100]]closed='right',dtype='interval[int64]')
pd.value_counts(cats)
(18, 25] 5
(35, 60] 3
(25, 35] 3
(60, 100] 1
dtype: int64
pd.value_counts(cats)是pandas.cut结果的面元计数。
跟“区间”的数学符号一样,圆括号表示开端,而方括号则表示闭端(包括)。哪边是闭端可以通过right=False进行修改:
pd.cut(ages, [18, 26, 36, 61, 100], right=False)
[[18, 26), [18, 26), [18, 26), [26, 36), [18, 26), ..., [26, 36), [61, 100), [36,
61), [36, 61), [26, 36)]
Length: 12
Categories (4, interval[int64]): [[18, 26) < [26, 36) < [36, 61) < [61, 100)]
你可 以通过传递一个列表或数组到labels,设置自己的面元名称:
group_names = ['Youth', 'YoungAdult', 'MiddleAged', 'Senior']
pd.cut(ages, bins, labels=group_names)
[Youth, Youth, Youth, YoungAdult, Youth, ..., YoungAdult, Senior, MiddleAged, Mid
dleAged, YoungAdult]
Length: 12
Categories (4, object): [Youth < YoungAdult < MiddleAged < Senior]
如果向cut传入的是面元的数量而不是确切的面元边界,则它会根据数据的最小值和最大值计算等长面元。下面这个例子中,我们将一些均匀分布的数据分成四组:
data = np.random.rand(20)
pd.cut(data, 4, precision=2)
[(0.34, 0.55], (0.34, 0.55], (0.76, 0.97], (0.76, 0.97], (0.34, 0.55], ..., (0.34
, 0.55], (0.34, 0.55], (0.55, 0.76], (0.34, 0.55], (0.12, 0.34]]
Length: 20
Categories (4, interval[float64]): [(0.12, 0.34] < (0.34, 0.55] < (0.55, 0.76] <
(0.76, 0.97]]
选项precision=2,限定小数只有两位。
qcut是一个非常类似于cut的函数,它可以根据样本分位数对数据进行面元划分。根据数据的分布情况,cut可能无法使各个面元中含有相同数量的数据点。而qcut由于使用的是样本分位数,因此可以得到大小基本相等的面元:
data = np.random.randn(1000) # Normally distributed
cats = pd.qcut(data, 4) # Cut into quartiles
cats
[(-0.0265, 0.62], (0.62, 3.928], (-0.68, -0.0265], (0.62, 3.928], (-0.0265, 0.62]
, ..., (-0.68, -0.0265], (-0.68, -0.0265], (-2.95, -0.68], (0.62, 3.928], (-0.68,
-0.0265]]
Length: 1000
Categories (4, interval[float64]): [(-2.95, -0.68] < (-0.68, -0.0265] < (-0.0265,
0.62] <(0.62, 3.928]]
pd.value_counts(cats)
(0.62, 3.928] 250
(-0.0265, 0.62] 250
(-0.68, -0.0265] 250
(-2.95, -0.68] 250
dtype: int64
与cut类似,你也可以传递自定义的分位数(0到1之间的数值,包含端点):
pd.qcut(data, [0, 0.1, 0.5, 0.9, 1.])
[(-0.0265, 1.286], (-0.0265, 1.286], (-1.187, -0.0265], (-0.0265, 1.286], (-0.026
5, 1.286], ..., (-1.187, -0.0265], (-1.187, -0.0265], (-2.95, -1.187], (-0.0265,
1.286], (-1.187, -0.0265]]
Length: 1000
Categories (4, interval[float64]): [(-2.95, -1.187] < (-1.187, -0.0265] < (-0.026
5, 1.286] <(1.286, 3.928]]
本章稍后在讲解聚合和分组运算时会再次用到cut和qcut,因为这两个离散化函数对分位和分组分析非常重要。
检测和过滤异常值
过滤或变换异常值(outlier)在很大程度上就是运用数组运算。来看一个含有正态分布数据的DataFrame:
data = pd.DataFrame(np.random.randn(1000, 4))
data.describe()
0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean 0.049091 0.026112 -0.002544 -0.051827
std 0.996947 1.007458 0.995232 0.998311
min -3.645860 -3.184377 -3.745356 -3.428254
25% -0.599807 -0.612162 -0.687373 -0.747478
50% 0.047101 -0.013609 -0.022158 -0.088274
75% 0.756646 0.695298 0.699046 0.623331
max 2.653656 3.525865 2.735527 3.366626
假设你想要找出某列中绝对值大小超过3的值:
col = data[2]
col[np.abs(col) > 3]
41 -3.399312
136 -3.745356
Name: 2, dtype: float64
要选出全部含有“超过3或-3的值”的行,你可以在布尔型DataFrame中使用any方法:
data[(np.abs(data) > 3).any(1)]
0 1 2 3
41 0.457246 -0.025907 -3.399312 -0.974657
60 1.951312 3.260383 0.963301 1.201206
136 0.508391 -0.196713 -3.745356 -1.520113
235 -0.242459 -3.056990 1.918403 -0.578828
258 0.682841 0.326045 0.425384 -3.428254
322 1.179227 -3.184377 1.369891 -1.074833
544 -3.548824 1.553205 -2.186301 1.277104
635 -0.578093 0.193299 1.397822 3.366626
782 -0.207434 3.525865 0.283070 0.544635
803 -3.645860 0.255475 -0.549574 -1.907459
根据这些条件,就可以对值进行设置。下面的代码可以将值限制在区间-3到3以内:
data[np.abs(data) > 3] = np.sign(data) * 3
data.describe()
0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean 0.050286 0.025567 -0.001399 -0.051765
std 0.992920 1.004214 0.991414 0.995761
min -3.000000 -3.000000 -3.000000 -3.000000
25% -0.599807 -0.612162 -0.687373 -0.747478
50% 0.047101 -0.013609 -0.022158 -0.088274
75% 0.756646 0.695298 0.699046 0.623331
max 2.653656 3.000000 2.735527 3.000000
根据数据的值是正还是负,np.sign(data)可以生成1和-1:
np.sign(data).head()
0 1 2 3
0 -1.0 1.0 -1.0 1.0
1 1.0 -1.0 1.0 -1.0
2 1.0 1.0 1.0 -1.0
3 -1.0 -1.0 1.0 -1.0
4 -1.0 1.0 -1.0 -1.0
排列和随机采样
利用numpy.random.permutation函数可以轻松实现对Series或DataFrame的列的排列工作(permuting,随机重排序)。通过需要排列的轴的长度调用permutation,可产生一个表示新顺序的整数数组:
df = pd.DataFrame(np.arange(5 * 4).reshape((5, 4)))
sampler = np.random.permutation(5)
sampler
array([3, 1, 4, 2, 0])
然后就可以在基于iloc的索引操作或take函数中使用该数组了:
df
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19
df.take(sampler)
0 1 2 3
3 12 13 14 15
1 4 5 6 7
4 16 17 18 19
2 8 9 10 11
0 0 1 2 3
如果不想用替换的方式选取随机子集,可以在Series和DataFrame上使用sample方法:
df.sample(n=3)
0 1 2 3
3 12 13 14 15
4 16 17 18 19
2 8 9 10 11
要通过替换的方式产生样本(允许重复选择),可以传递replace=True到sample:
choices = pd.Series([5, 7, -1, 6, 4])
draws = choices.sample(n=10, replace=True)
draws
4 4
1 7
4 4
2 -1
0 5
3 6
1 7
4 4
0 5
4 4
dtype: int64
计算指标/哑变量
另一种常用于统计建模或机器学习的转换方式是:将分类变量(categorical variable)转换为“哑变量”或“指标矩阵”。
如果DataFrame的某一列中含有k个不同的值,则可以派生出一个k列矩阵或DataFrame(其值全为1和0)。pandas有一个get_dummies函数可以实现该功能(其实自己动手做一个也不难)。使用之前的一个DataFrame例子:
df = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'b'],'data1': range(6)})
pd.get_dummies(df['key'])
a b c
0 0 1 0
1 0 1 0
2 1 0 0
3 0 0 1
4 1 0 0
5 0 1 0
有时候,你可能想给指标DataFrame的列加上一个前缀,以便能够跟其他数据进行合并。get_dummies的prefix参数可以实现该功能:
dummies = pd.get_dummies(df['key'], prefix='key')
df_with_dummy = df[['data1']].join(dummies)
df_with_dummy
data1 key_a key_b key_c
0 0 0 1 0
1 1 0 1 0
2 2 1 0 0
3 3 0 0 1
4 4 1 0 0
5 5 0 1 0
如果DataFrame中的某行同属于多个分类,则事情就会有点复杂。看一下MovieLens 1M数据集,14章会更深入地研究它:
mnames = ['movie_id', 'title', 'genres']
movies = pd.read_table('datasets/movielens/movies.dat', sep='::',header=None, names=mnames)
movies[:10]
movie_id title genres
0 1 Toy Story (1995) Animation|Children's|Comedy
1 2 Jumanji (1995) Adventure|Children's|Fantasy
2 3 Grumpier Old Men (1995) Comedy|Romance
3 4 Waiting to Exhale (1995) Comedy|Drama
4 5 Father of the Bride Part II (1995) Comedy
5 6 Heat (1995) Action|Crime|Thriller
6 7 Sabrina (1995) Comedy|Romance
7 8 Tom and Huck (1995) Adventure|Children's
8 9 Sudden Death (1995) Action
9 10 GoldenEye (1995) Action|Adventure|Thriller
要为每个genre添加指标变量就需要做一些数据规整操作。首先,我们从数据集中抽取出不同的genre值:
all_genres = []
for x in movies.genres:
all_genres.extend(x.split('|'))
genres = pd.unique(all_genres)
genres
array(['Animation', "Children's", 'Comedy', 'Adventure', 'Fantasy',
'Romance', 'Drama', 'Action', 'Crime', 'Thriller','Horror',
'Sci-Fi', 'Documentary', 'War', 'Musical', 'Mystery', 'Film-Noir',
'Western'], dtype=object)
构建指标DataFrame的方法之一是从一个全零DataFrame开始:
zero_matrix = np.zeros((len(movies), len(genres)))
dummies = pd.DataFrame(zero_matrix, columns=genres)
现在,迭代每一部电影,并将dummies各行的条目设为1。要这么做,我们使用dummies.columns来计算每个类型的列索引:
gen = movies.genres[0]
gen.split('|')
['Animation', "Children's", 'Comedy']
dummies.columns.get_indexer(gen.split('|'))
array([0, 1, 2])
然后,根据索引,使用.iloc设定值:
for i, gen in enumerate(movies.genres):
indices = dummies.columns.get_indexer(gen.split('|'))
dummies.iloc[i, indices] = 1
然后,和以前一样,再将其与movies合并起来:
movies_windic = movies.join(dummies.add_prefix('Genre_'))
movies_windic.iloc[0]
movie_id 1
title Toy Story (1995)
genres Animation|Children's|Comedy
Genre_Animation 1
Genre_Children's 1
Genre_Comedy 1
Genre_Adventure 0
Genre_Fantasy 0
Genre_Romance 0
Genre_Drama 0
...
Genre_Crime 0
Genre_Thriller 0
Genre_Horror 0
Genre_Sci-Fi 0
Genre_Documentary 0
Genre_War 0
Genre_Musical 0
Genre_Mystery 0
Genre_Film-Noir 0
Genre_Western 0
Name: 0, Length: 21, dtype: object
笔记:对于很大的数据,用这种方式构建多成员指标变量就会变得非常慢。最好使用更低级的函数,将其写入NumPy数组,然后结果包装在DataFrame中。
一个对统计应用有用的秘诀是:结合get_dummies和诸如cut之类的离散化函数:
np.random.seed(12345)
values = np.random.rand(10)
values
array([ 0.9296, 0.3164, 0.1839, 0.2046, 0.5677, 0.5955, 0.9645,
0.6532, 0.7489, 0.6536])
bins = [0, 0.2, 0.4, 0.6, 0.8, 1]
pd.get_dummies(pd.cut(values, bins))
(0.0, 0.2] (0.2, 0.4] (0.4, 0.6] (0.6, 0.8] (0.8, 1.0]
0 0 0 0 0 1
1 0 1 0 0 0
2 1 0 0 0 0
3 0 1 0 0 0
4 0 0 1 0 0
5 0 0 1 0 0
6 0 0 0 0 1
7 0 0 0 1 0
8 0 0 0 1 0
9 0 0 0 1 0
我们用numpy.random.seed,使这个例子具有确定性。本书后面会介绍pandas.get_dummies。
字符串操作
Python能够成为流行的数据处理语言,部分原因是其简单易用的字符串和文本处理功能。大部分文本运算都直接做成了字符串对象的内置方法。对于更为复杂的模式匹配和文本操作,则可能需要用到正则表达式。pandas对此进行了加强,它使你能够对整组数据应用字符串表达式和正则表达式,而且能处理烦人的缺失数据。
字符串对象方法
对于许多字符串处理和脚本应用,内置的字符串方法已经能够满足要求了。例如,以逗号分隔的字符串可以用split拆分成数段:
val = 'a,b, guido'
val.split(',')
['a', 'b', ' guido']
split常常与strip一起使用,以去除空白符(包括换行符):
pieces = [x.strip() for x in val.split(',')]
pieces
['a', 'b', 'guido']
利用加法,可以将这些子字符串以双冒号分隔符的形式连接起来:
first, second, third = pieces
first + '::' + second + '::' + third
'a::b::guido'
但这种方式并不是很实用。一种更快更符合Python风格的方式是,向字符串"::"的join方法传入一个列表或元组:
'::'.join(pieces)
'a::b::guido'
其它方法关注的是子串定位。检测子串的最佳方式是利用Python的in关键字,还可以使用index和find:
'guido' in val
True
val.index(',')
1
val.find(':')
-1
注意find和index的区别:如果找不到字符串,index将会引发一个异常(而不是返回-1):
val.index(':')
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-144-280f8b2856ce> in <module>()
----> 1 val.index(':')
ValueError: substring not found
与此相关,count可以返回指定子串的出现次数:
val.count(',')
2
replace用于将指定模式替换为另一个模式。通过传入空字符串,它也常常用于删除模式:
val.replace(',', '::')
'a::b:: guido'
val.replace(',', '')
'ab guido'
下表列出了Python内置的字符串方法。
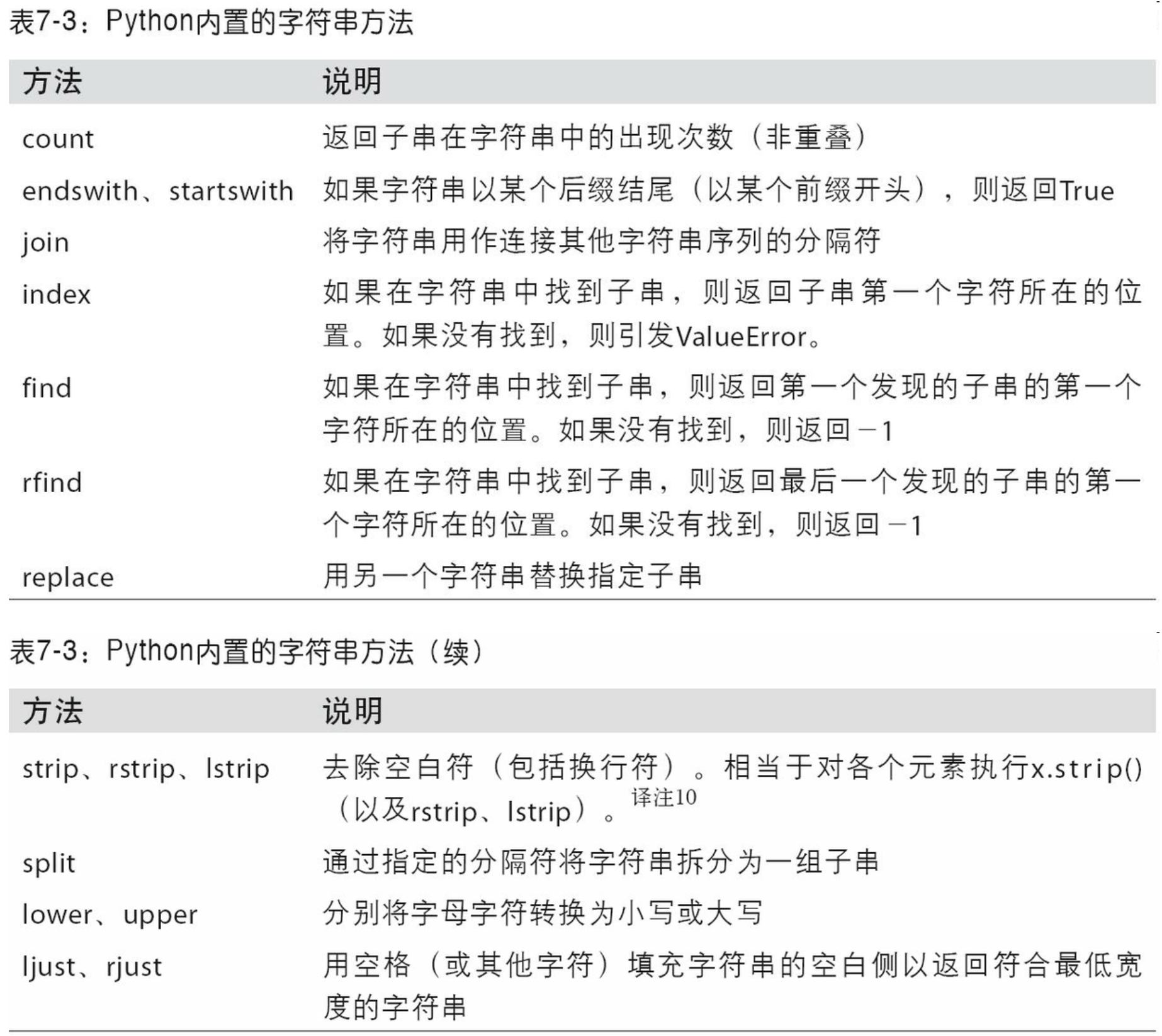
这些运算大部分都能使用正则表达式实现(马上就会看到)。
casefold 将字符转换为小写,并将任何特定区域的变量字符组合转换成一个通用的可比较形式。
正则表达式
正则表达式提供了一种灵活的在文本中搜索或匹配(通常比前者复杂)字符串模式的方式。正则表达式,常称作regex,是根据正则表达式语言编写的字符串。Python内置的re模块负责对字符串应用正则表达式。我将通过一些例子说明其使用方法。
re模块的函数可以分为三个大类:模式匹配、替换以及拆分。当然,它们之间是相辅相成的。一个regex描述了需要在文本中定位的一个模式,它可以用于许多目的。我们先来看一个简单的例子:假设我想要拆分一个字符串,分隔符为数量不定的一组空白符(制表符、空格、换行符等)。描述一个或多个空白符的regex是\s+:
import re
text = "foo bar\t baz \tqux"
re.split('\s+', text)
['foo', 'bar', 'baz', 'qux']
调用re.split('\s+',text)时,正则表达式会先被编译,然后再在text上调用其split方法。你可以用re.compile自己编译regex以得到一个可重用的regex对象:
regex = re.compile('\s+')
regex.split(text)
['foo', 'bar', 'baz', 'qux']
如果只希望得到匹配regex的所有模式,则可以使用findall方法:
regex.findall(text)
[' ', '\t ', ' \t']
笔记:如果想避免正则表达式中不需要的转义(\),则可以使用原始字符串字面量如r'C:\x'(也可以编写其等价式'C:\x')。
如果打算对许多字符串应用同一条正则表达式,强烈建议通过re.compile创建regex对象。这样将可以节省大量的CPU时间。
match和search跟findall功能类似。findall返回的是字符串中所有的匹配项,而search则只返回第一个匹配项。match更加严格,它只匹配字符串的首部。来看一个小例子,假设我们有一段文本以及一条能够识别大部分电子邮件地址的正则表达式:
text = """Dave dave@google.com
Steve steve@gmail.com
Rob rob@gmail.com
Ryan ryan@yahoo.com
"""
pattern = r'[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}'
#re.IGNORECASE makes the regex case-insensitive
regex = re.compile(pattern, flags=re.IGNORECASE)
对text使用findall将得到一组电子邮件地址:
regex.findall(text)
['dave@google.com',
'steve@gmail.com',
'rob@gmail.com',
'ryan@yahoo.com']
search返回的是文本中第一个电子邮件地址(以特殊的匹配项对象形式返回)。对于上面那个regex,匹配项对象只能告诉我们模式在原字符串中的起始和结束位置:
m = regex.search(text)
m
<_sre.SRE_Match object; span=(5, 20), match='dave@google.com'>
text[m.start():m.end()]
'dave@google.com'
regex.match则将返回None,因为它只匹配出现在字符串开头的模式:
print(regex.match(text))
None
相关的,sub方法可以将匹配到的模式替换为指定字符串,并返回所得到的新字符串:
print(regex.sub('REDACTED', text))
Dave REDACTED
Steve REDACTED
Rob REDACTED
Ryan REDACTED
假设你不仅想要找出电子邮件地址,还想将各个地址分成3个部分:用户名、域名以及域后缀。要实现此功能,只需将待分段的模式的各部分用圆括号包起来即可:
pattern = r'([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\.([A-Z]{2,4})'
regex = re.compile(pattern, flags=re.IGNORECASE)
由这种修改过的正则表达式所产生的匹配项对象,可以通过其groups方法返回一个由模式各段组成的元组:
m = regex.match('wesm@bright.net')
m.groups()
('wesm', 'bright', 'net')
对于带有分组功能的模式,findall会返回一个元组列表:
regex.findall(text)
[('dave', 'google', 'com'),
('steve', 'gmail', 'com'),
('rob', 'gmail', 'com'),
('ryan', 'yahoo', 'com')]
sub还能通过诸如\1、\2之类的特殊符号访问各匹配项中的分组。符号\1对应第一个匹配的组,\2对应第二个匹配的组,以此类推:
print(regex.sub(r'Username: \1, Domain: \2, Suffix: \3', text))
Dave Username: dave, Domain: google, Suffix: com
Steve Username: steve, Domain: gmail, Suffix: com
Rob Username: rob, Domain: gmail, Suffix: com
Ryan Username: ryan, Domain: yahoo, Suffix: com
Python中还有许多的正则表达式,但大部分都超出了本书的范围。下表是一个简要概括。

pandas的矢量化字符串函数
清理待分析的散乱数据时,常常需要做一些字符串规整化工作。更为复杂的情况是,含有字符串的列有时还含有缺失数据:
data = {'Dave': 'dave@google.com', 'Steve': 'steve@gmail.com','Rob': 'rob@gmail.com', 'Wes': np.nan}
data = pd.Series(data)
data
Dave dave@google.com
Rob rob@gmail.com
Steve steve@gmail.com
Wes NaN
dtype: object
data.isnull()
Dave False
Rob False
Steve False
Wes True
dtype: bool
通过data.map,所有字符串和正则表达式方法都能被应用于(传入lambda表达式或其他函数)各个值,但是如果存在NA(null)就会报错。为了解决这个问题,Series有一些能够跳过NA值的面向数组方法,进行字符串操作。通过Series的str属性即可访问这些方法。例如,我们可以通过str.contains检查各个电子邮件地址是否含有"gmail":
data.str.contains('gmail')
Dave False
Rob True
Steve True
Wes NaN
dtype: object
也可以使用正则表达式,还可以加上任意re选项(如IGNORECASE):
pattern
'([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\\.([A-Z]{2,4})'
data.str.findall(pattern, flags=re.IGNORECASE)
Dave [(dave, google, com)]
Rob [(rob, gmail, com)]
Steve [(steve, gmail, com)]
Wes NaN
dtype: object
有两个办法可以实现矢量化的元素获取操作:要么使用str.get,要么在str属性上使用索引:
matches = data.str.match(pattern, flags=re.IGNORECASE)
matches
Dave True
Rob True
Steve True
Wes NaN
dtype: object
要访问嵌入列表中的元素,我们可以传递索引到这两个函数中:
matches.str.get(1)
Dave NaN
Rob NaN
Steve NaN
Wes NaN
dtype: float64
matches.str[0]
Dave NaN
Rob NaN
Steve NaN
Wes NaN
dtype: float64
你可以利用这种方法对字符串进行截取:
data.str[:5]
Dave dave@
Rob rob@g
Steve steve
Wes NaN
dtype: object
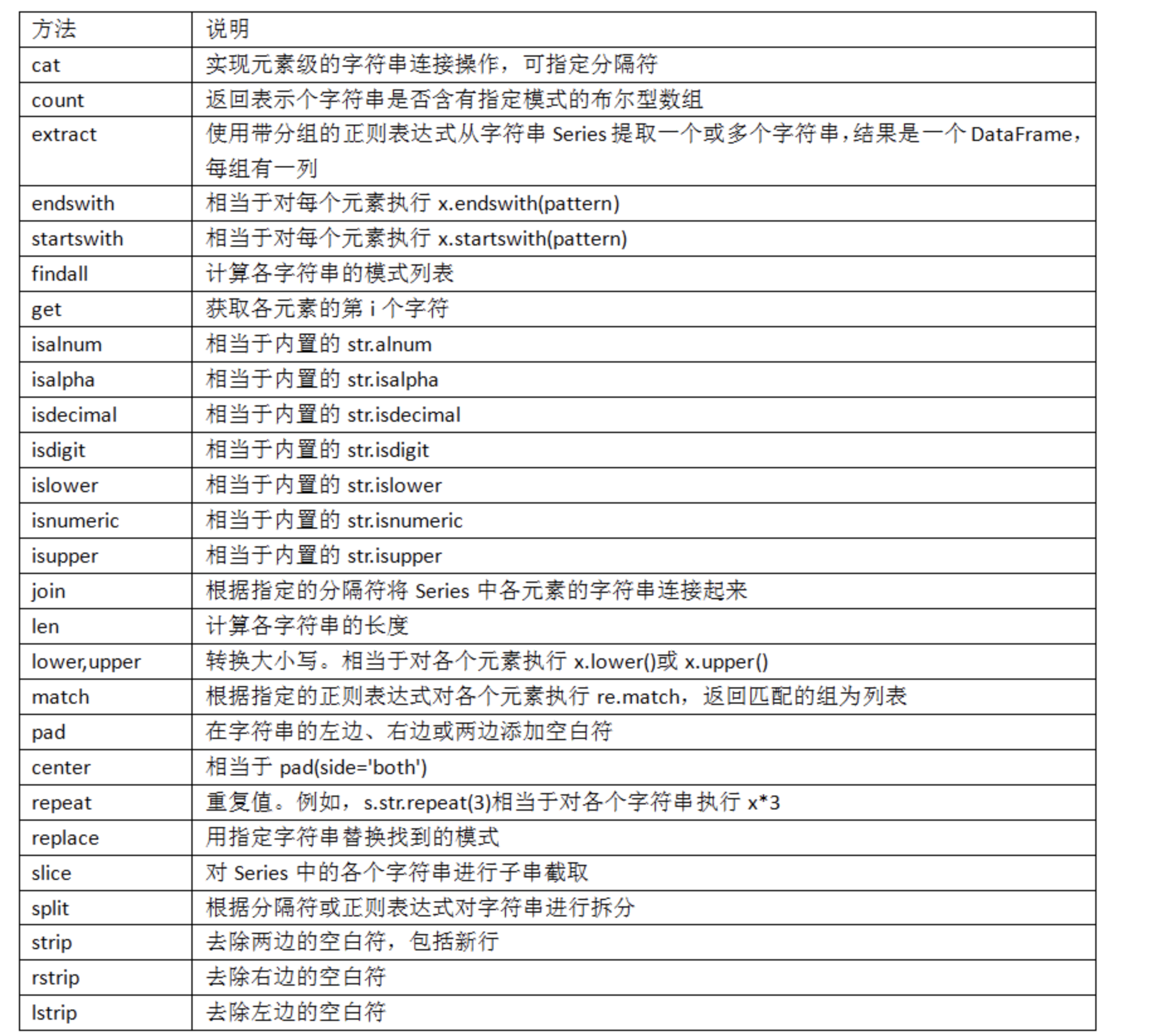
下表介绍了更多的pandas字符串方法。
数据规整:聚合、合并和重塑
层次化索引
层次化索引(hierarchical indexing)是pandas的一项重要功能,它使你能在一个轴上拥有多个(两个以上)索引级别。抽象点说,它使你能以低维度形式处理高维度数据。我们先来看一个简单的例子:创建一个Series,并用一个由列表或数组组成的列表作为索引:
data = pd.Series(np.random.randn(9),index=[['a', 'a', 'a', 'b', 'b', 'c', 'c', 'd', 'd'],[1, 2, 3, 1, 3, 1, 2, 2, 3]])
data
a 1 -0.204708
2 0.478943
3 -0.519439
b 1 -0.555730
3 1.965781
c 1 1.393406
2 0.092908
d 2 0.281746
3 0.769023
dtype: float64
看到的结果是经过美化的带有MultiIndex索引的Series的格式。索引之间的“间隔”表示“直接使用上面的标签”:
data.index
MultiIndex(levels=[['a', 'b', 'c', 'd'], [1, 2, 3]],labels=[[0, 0, 0, 1, 1, 2, 2, 3, 3], [0, 1, 2, 0, 2, 0, 1, 1, 2]])
对于一个层次化索引的对象,可以使用所谓的部分索引,使用它选取数据子集的操作更简单:
data['b']
1 -0.555730
3 1.965781
dtype: float64
data['b':'c']
b 1 -0.555730
3 1.965781
c 1 1.393406
2 0.092908
dtype: float64
data.loc[['b', 'd']]
b 1 -0.555730
3 1.965781
d 2 0.281746
3 0.769023
dtype: float64
有时甚至还可以在“内层”中进行选取:
data.loc[:, 2]
a 0.478943
c 0.092908
d 0.281746
dtype: float64
层次化索引在数据重塑和基于分组的操作(如透视表生成)中扮演着重要的角色。例如,可以通过unstack方法将这段数据重新安排到一个DataFrame中:
data.unstack()
1 2 3
a -0.204708 0.478943 -0.519439
b -0.555730 NaN 1.965781
c 1.393406 0.092908 NaN
d NaN 0.281746 0.769023
unstack的逆运算是stack:
data.unstack().stack()
a 1 -0.204708
2 0.478943
3 -0.519439
b 1 -0.555730
3 1.965781
c 1 1.393406
2 0.092908
d 2 0.281746
3 0.769023
dtype: float64
对于一个DataFrame,每条轴都可以有分层索引:
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),index=[['a', 'a', 'b', 'b'], [1, 2, 1, 2]],columns=[['Ohio', 'Ohio', 'Colorado'],
['Green', 'Red', 'Green']])
frame
Ohio Colorado
Green Red Green
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
各层都可以有名字(可以是字符串,也可以是别的Python对象)。如果指定了名称,它们就会显示在控制台输出中:
frame.index.names = ['key1', 'key2']
frame.columns.names = ['state', 'color']
frame
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
注意:小心区分索引名state、color与行标签。
有了部分列索引,因此可以轻松选取列分组:
frame['Ohio']
color Green Red
key1 key2
a 1 0 1
2 3 4
b 1 6 7
2 9 10
可以单独创建MultiIndex然后复用。上面那个DataFrame中的(带有分级名称)列可以这样创建:
MultiIndex.from_arrays([['Ohio', 'Ohio', 'Colorado'], ['Green', 'Red', 'Green']],
names=['state', 'color'])
重排与分级排序
有时,你需要重新调整某条轴上各级别的顺序,或根据指定级别上的值对数据进行排序。swaplevel接受两个级别编号或名称,并返回一个互换了级别的新对象(但数据不会发生变化):
frame.swaplevel('key1', 'key2')
state Ohio Colorado
color Green Red Green
key2 key1
1 a 0 1 2
2 a 3 4 5
1 b 6 7 8
2 b 9 10 11
而sort_index则根据单个级别中的值对数据进行排序。交换级别时,常常也会用到sort_index,这样最终结果就是按照指定顺序进行字母排序了:
frame.sort_index(level=1)
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 2
b 1 6 7 8
a 2 3 4 5
b 2 9 10 11
frame.swaplevel(0, 1).sort_index(level=0)
state Ohio Colorado
color Green Red Green
key2 key1
1 a 0 1 2
b 6 7 8
2 a 3 4 5
b 9 10 11
根据级别汇总统计
许多对DataFrame和Series的描述和汇总统计都有一个level选项,它用于指定在某条轴上求和的级别。再以上面那个DataFrame为例,我们可以根据行或列上的级别来进行求和:
frame.sum(level='key2')
state Ohio Colorado
color Green Red Green
key2
1 6 8 10
2 12 14 16
frame.sum(level='color', axis=1)
color Green Red
key1 key2
a 1 2 1
2 8 4
b 1 14 7
2 20 10
这其实是利用了pandas的groupby功能。
使用DataFrame的列进行索引
人们经常想要将DataFrame的一个或多个列当做行索引来用,或者可能希望将行索引变成DataFrame的列。以下面这个DataFrame为例:
frame = pd.DataFrame({'a': range(7), 'b': range(7, 0, -1),'c': ['one', 'one', 'one', 'two', 'two','two', 'two'],'d': [0, 1, 2, 0, 1, 2, 3]})
frame
a b c d
0 0 7 one 0
1 1 6 one 1
2 2 5 one 2
3 3 4 two 0
4 4 3 two 1
5 5 2 two 2
6 6 1 two 3
DataFrame的set_index函数会将其一个或多个列转换为行索引,并创建一个新的DataFrame:
frame2 = frame.set_index(['c', 'd'])
frame2
a b
c d
one 0 0 7
1 1 6
2 2 5
two 0 3 4
1 4 3
2 5 2
3 6 1
默认情况下,那些列会从DataFrame中移除,但也可以将其保留下来:
frame.set_index(['c', 'd'], drop=False)
a b c d
c d
one 0 0 7 one 0
1 1 6 one 1
2 2 5 one 2
two 0 3 4 two 0
1 4 3 two 1
2 5 2 two 2
3 6 1 two 3
reset_index的功能跟set_index刚好相反,层次化索引的级别会被转移到列里面:
frame2.reset_index()
c d a b
0 one 0 0 7
1 one 1 1 6
2 one 2 2 5
3 two 0 3 4
4 two 1 4 3
5 two 2 5 2
6 two 3 6 1
合并数据集
pandas对象中的数据可以通过一些方式进行合并:
pandas.merge可根据一个或多个键将不同DataFrame中的行连接起来。SQL或其他关系型数据库的用户对此应该会比较熟悉,因为它实现的就是数据库的join操作。
pandas.concat可以沿着一条轴将多个对象堆叠到一起。
实例方法combine_first可以将重复数据拼接在一起,用一个对象中的值填充另一个对象中的缺失值。
数据库风格的DataFrame合并
数据集的合并(merge)或连接(join)运算是通过一个或多个键将行连接起来的。这些运算是关系型数据库(基于SQL)的核心。pandas的merge函数是对数据应用这些算法的主要切入点。
以一个简单的例子开始:
df1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],'data1': range(7)})
df2 = pd.DataFrame({'key': ['a', 'b', 'd'],'data2': range(3)})
df1
data1 key
0 0 b
1 1 b
2 2 a
3 3 c
4 4 a
5 5 a
6 6 b
df2
data2 key
0 0 a
1 1 b
2 2 d
这是一种多对一的合并。df1中的数据有多个被标记为a和b的行,而df2中key列的每个值则仅对应一行。对这些对象调用merge即可得到:
pd.merge(df1, df2)
data1 key data2
0 0 b 1
1 1 b 1
2 6 b 1
3 2 a 0
4 4 a 0
5 5 a 0
注意,我并没有指明要用哪个列进行连接。如果没有指定,merge就会将重叠列的列名当做键。不过,最好明确指定一下:
pd.merge(df1, df2, on='key')
data1 key data2
0 0 b 1
1 1 b 1
2 6 b 1
3 2 a 0
4 4 a 0
5 5 a 0
如果两个对象的列名不同,也可以分别进行指定:
df3 = pd.DataFrame({'lkey': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],'data1': range(7)})
df4 = pd.DataFrame({'rkey': ['a', 'b', 'd'],'data2': range(3)})
pd.merge(df3, df4, left_on='lkey', right_on='rkey')
data1 lkey data2 rkey
0 0 b 1 b
1 1 b 1 b
2 6 b 1 b
3 2 a 0 a
4 4 a 0 a
5 5 a 0 a
可能你已经注意到了,结果里面c和d以及与之相关的数据消失了。默认情况下,merge做的是“内连接”;结果中的键是交集。其他方式还有"left"、"right"以及"outer"。外连接求取的是键的并集,组合了左连接和右连接的效果:
pd.merge(df1, df2, how='outer')
data1 key data2
0 0.0 b 1.0
1 1.0 b 1.0
2 6.0 b 1.0
3 2.0 a 0.0
4 4.0 a 0.0
5 5.0 a 0.0
6 3.0 c NaN
7 NaN d 2.0
下表对这些选项进行了总结。

多对多的合并有些不直观。看下面的例子:
df1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'b'],'data1': range(6)})
df2 = pd.DataFrame({'key': ['a', 'b', 'a', 'b', 'd'],'data2': range(5)})
df1
data1 key
0 0 b
1 1 b
2 2 a
3 3 c
4 4 a
5 5 b
df2
data2 key
0 0 a
1 1 b
2 2 a
3 3 b
4 4 d
pd.merge(df1, df2, on='key', how='left')
data1 key data2
0 0 b 1.0
1 0 b 3.0
2 1 b 1.0
3 1 b 3.0
4 2 a 0.0
5 2 a 2.0
6 3 c NaN
7 4 a 0.0
8 4 a 2.0
9 5 b 1.0
10 5 b 3.0
多对多连接产生的是行的笛卡尔积。由于左边的DataFrame有3个"b"行,右边的有2个,所以最终结果中就有6个"b"行。连接方式只影响出现在结果中的不同的键的值:
pd.merge(df1, df2, how='inner')
data1 key data2
0 0 b 1
1 0 b 3
2 1 b 1
3 1 b 3
4 5 b 1
5 5 b 3
6 2 a 0
7 2 a 2
8 4 a 0
9 4 a 2
要根据多个键进行合并,传入一个由列名组成的列表即可:
left = pd.DataFrame({'key1': ['foo', 'foo', 'bar'],'key2': ['one', 'two', 'one'],'lval': [1, 2, 3]})
right = pd.DataFrame({'key1': ['foo', 'foo', 'bar', 'bar'],'key2': ['one', 'one', 'one', 'two'],'rval': [4, 5, 6, 7]})
pd.merge(left, right, on=['key1', 'key2'], how='outer')
key1 key2 lval rval
0 foo one 1.0 4.0
1 foo one 1.0 5.0
2 foo two 2.0 NaN
3 bar one 3.0 6.0
4 bar two NaN 7.0
结果中会出现哪些键组合取决于所选的合并方式,你可以这样来理解:多个键形成一系列元组,并将其当做单个连接键(当然,实际上并不是这么回事)。
注意:在进行列-列连接时,DataFrame对象中的索引会被丢弃。
对于合并运算需要考虑的最后一个问题是对重复列名的处理。虽然你可以手工处理列名重叠的问题(查看前面介绍的重命名轴标签),但merge有一个更实用的suffixes选项,用于指定附加到左右两个DataFrame对象的重叠列名上的字符串:
pd.merge(left, right, on='key1')
key1 key2_x lval key2_y rval
0 foo one 1 one 4
1 foo one 1 one 5
2 foo two 2 one 4
3 foo two 2 one 5
4 bar one 3 one 6
5 bar one 3 two 7
pd.merge(left, right, on='key1', suffixes=('_left', '_right'))
key1 key2_left lval key2_right rval
0 foo one 1 one 4
1 foo one 1 one 5
2 foo two 2 one 4
3 foo two 2 one 5
4 bar one 3 one 6
5 bar one 3 two 7
merge的参数请参见下表。使用DataFrame的行索引合并是下一节的主题。


索引上的合并
有时候,DataFrame中的连接键位于其索引中。在这种情况下,你可以传入left_index=True或right_index=True(或两个都传)以说明索引应该被用作连接键:
left1 = pd.DataFrame({'key': ['a', 'b', 'a', 'a', 'b', 'c'],'value': range(6)})
right1 = pd.DataFrame({'group_val': [3.5, 7]}, index=['a', 'b'])
left1
key value
0 a 0
1 b 1
2 a 2
3 a 3
4 b 4
5 c 5
right1
group_val
a 3.5
b 7.0
pd.merge(left1, right1, left_on='key', right_index=True)
key value group_val
0 a 0 3.5
2 a 2 3.5
3 a 3 3.5
1 b 1 7.0
4 b 4 7.0
由于默认的merge方法是求取连接键的交集,因此你可以通过外连接的方式得到它们的并集:
pd.merge(left1, right1, left_on='key', right_index=True, how='outer')
key value group_val
0 a 0 3.5
2 a 2 3.5
3 a 3 3.5
1 b 1 7.0
4 b 4 7.0
5 c 5 NaN
对于层次化索引的数据,事情就有点复杂了,因为索引的合并默认是多键合并:
lefth = pd.DataFrame({'key1': ['Ohio', 'Ohio', 'Ohio','Nevada', 'Nevada'],'key2': [2000, 2001, 2002, 2001, 2002],'data': np.arange(5.)})
righth = pd.DataFrame(np.arange(12).reshape((6, 2)),index=[['Nevada', 'Nevada', 'Ohio', 'Ohio','Ohio', 'Ohio'],[2001, 2000, 2000, 2000, 2001, 2002]],columns=['event1', 'event2'])
lefth
data key1 key2
0 0.0 Ohio 2000
1 1.0 Ohio 2001
2 2.0 Ohio 2002
3 3.0 Nevada 2001
4 4.0 Nevada 2002
righth
event1 event2
Nevada 2001 0 1
2000 2 3
Ohio 2000 4 5
2000 6 7
2001 8 9
2002 10 11
这种情况下,你必须以列表的形式指明用作合并键的多个列(注意用how='outer'对重复索引值的处理):
pd.merge(lefth, righth, left_on=['key1', 'key2'], right_index=True)
data key1 key2 event1 event2
0 0.0 Ohio 2000 4 5
0 0.0 Ohio 2000 6 7
1 1.0 Ohio 2001 8 9
2 2.0 Ohio 2002 10 11
3 3.0 Nevada 2001 0 1
pd.merge(lefth, righth, left_on=['key1', 'key2'],right_index=True, how='outer')
data key1 key2 event1 event2
0 0.0 Ohio 2000 4.0 5.0
0 0.0 Ohio 2000 6.0 7.0
1 1.0 Ohio 2001 8.0 9.0
2 2.0 Ohio 2002 10.0 11.0
3 3.0 Nevada 2001 0.0 1.0
4 4.0 Nevada 2002 NaN NaN
4 NaN Nevada 2000 2.0 3.0
同时使用合并双方的索引也没问题:
left2 = pd.DataFrame([[1., 2.], [3., 4.], [5., 6.]],index=['a', 'c', 'e'],columns=['Ohio', 'Nevada'])
right2 = pd.DataFrame([[7., 8.], [9., 10.], [11., 12.], [13, 14]],index=['b', 'c', 'd', 'e'],columns=['Missouri', 'Alabama'])
left2
Ohio Nevada
a 1.0 2.0
c 3.0 4.0
e 5.0 6.0
right2
Missouri Alabama
b 7.0 8.0
c 9.0 10.0
d 11.0 12.0
e 13.0 14.0
pd.merge(left2, right2, how='outer', left_index=True, right_index=True)
Ohio Nevada Missouri Alabama
a 1.0 2.0 NaN NaN
b NaN NaN 7.0 8.0
c 3.0 4.0 9.0 10.0
d NaN NaN 11.0 12.0
e 5.0 6.0 13.0 14.0
DataFrame还有一个便捷的join实例方法,它能更为方便地实现按索引合并。它还可用于合并多个带有相同或相似索引的DataFrame对象,但要求没有重叠的列。在上面那个例子中,我们可以编写:
left2.join(right2, how='outer')
Ohio Nevada Missouri Alabama
a 1.0 2.0 NaN NaN
b NaN NaN 7.0 8.0
c 3.0 4.0 9.0 10.0
d NaN NaN 11.0 12.0
e 5.0 6.0 13.0 14.0
因为一些历史版本的遗留原因,DataFrame的join方法默认使用的是左连接,保留左边表的行索引。它还支持在调用的DataFrame的列上,连接传递的DataFrame索引:
left1.join(right1, on='key')
key value group_val
0 a 0 3.5
1 b 1 7.0
2 a 2 3.5
3 a 3 3.5
4 b 4 7.0
5 c 5 NaN
最后,对于简单的索引合并,你还可以向join传入一组DataFrame,下一节会介绍更为通用的concat函数,也能实现此功能:
another = pd.DataFrame([[7., 8.], [9., 10.], [11., 12.], [16., 17.]],index=['a', 'c', 'e', 'f'],columns=['New York','Oregon'])
another
New York Oregon
a 7.0 8.0
c 9.0 10.0
e 11.0 12.0
f 16.0 17.0
left2.join([right2, another])
Ohio Nevada Missouri Alabama New York Oregon
a 1.0 2.0 NaN NaN 7.0 8.0
c 3.0 4.0 9.0 10.0 9.0 10.0
e 5.0 6.0 13.0 14.0 11.0 12.0
left2.join([right2, another], how='outer')
Ohio Nevada Missouri Alabama New York Oregon
a 1.0 2.0 NaN NaN 7.0 8.0
b NaN NaN 7.0 8.0 NaN NaN
c 3.0 4.0 9.0 10.0 9.0 10.0
d NaN NaN 11.0 12.0 NaN NaN
e 5.0 6.0 13.0 14.0 11.0 12.0
f NaN NaN NaN NaN 16.0 17.0
轴向连接
另一种数据合并运算也被称作连接(concatenation)、绑定(binding)或堆叠(stacking)。NumPy的concatenation函数可以用NumPy数组来做:
arr = np.arange(12).reshape((3, 4))
arr
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
np.concatenate([arr, arr], axis=1)
array([[ 0, 1, 2, 3, 0, 1, 2, 3],
[ 4, 5, 6, 7, 4, 5, 6, 7],
[ 8, 9, 10, 11, 8, 9, 10, 11]])
对于pandas对象(如Series和DataFrame),带有标签的轴使你能够进一步推广数组的连接运算。具体点说,你还需要考虑以下这些东西:
- 如果对象在其它轴上的索引不同,我们应该合并这些轴的不同元素还是只使用交集?
- 连接的数据集是否需要在结果对象中可识别?
- 连接轴中保存的数据是否需要保留?许多情况下,
DataFrame默认的整数标签最好在连接时删掉。
pandas的concat函数提供了一种能够解决这些问题的可靠方式。我将给出一些例子来讲解其使用方式。假设有三个没有重叠索引的Series:
s1 = pd.Series([0, 1], index=['a', 'b'])
s2 = pd.Series([2, 3, 4], index=['c', 'd', 'e'])
s3 = pd.Series([5, 6], index=['f', 'g'])
对这些对象调用concat可以将值和索引粘合在一起:
pd.concat([s1, s2, s3])
a 0
b 1
c 2
d 3
e 4
f 5
g 6
dtype: int64
默认情况下,concat是在axis=0上工作的,最终产生一个新的Series。如果传入axis=1,则结果就会变成一个DataFrame(axis=1是列):
pd.concat([s1, s2, s3], axis=1)
0 1 2
a 0.0 NaN NaN
b 1.0 NaN NaN
c NaN 2.0 NaN
d NaN 3.0 NaN
e NaN 4.0 NaN
f NaN NaN 5.0
g NaN NaN 6.0
这种情况下,另外的轴上没有重叠,从索引的有序并集(外连接)上就可以看出来。传入join='inner'即可得到它们的交集:
s4 = pd.concat([s1, s3])
s4
a 0
b 1
f 5
g 6
dtype: int64
pd.concat([s1, s4], axis=1)
0 1
a 0.0 0
b 1.0 1
f NaN 5
g NaN 6
pd.concat([s1, s4], axis=1, join='inner')
0 1
a 0 0
b 1 1
在这个例子中,f和g标签消失了,是因为使用的是join='inner'选项。
你可以通过join_axes指定要在其它轴上使用的索引:
pd.concat([s1, s4], axis=1, join_axes=[['a', 'c', 'b', 'e']])
0 1
a 0.0 0.0
c NaN NaN
b 1.0 1.0
e NaN NaN
不过有个问题,参与连接的片段在结果中区分不开。假设你想要在连接轴上创建一个层次化索引。使用keys参数即可达到这个目的:
result = pd.concat([s1, s1, s3], keys=['one','two', 'three'])
result
one a 0
b 1
two a 0
b 1
three f 5
g 6
dtype: int64
result.unstack()
a b f g
one 0.0 1.0 NaN NaN
two 0.0 1.0 NaN NaN
three NaN NaN 5.0 6.0
如果沿着axis=1对Series进行合并,则keys就会成为DataFrame的列头:
pd.concat([s1, s2, s3], axis=1, keys=['one','two', 'three'])
one two three
a 0.0 NaN NaN
b 1.0 NaN NaN
c NaN 2.0 NaN
d NaN 3.0 NaN
e NaN 4.0 NaN
f NaN NaN 5.0
g NaN NaN 6.0
同样的逻辑也适用于DataFrame对象:
df1 = pd.DataFrame(np.arange(6).reshape(3, 2), index=['a', 'b', 'c'],columns=['one', 'two'])
df2 = pd.DataFrame(5 + np.arange(4).reshape(2, 2), index=['a', 'c'],columns=['three', 'four'])
df1
one two
a 0 1
b 2 3
c 4 5
df2
three four
a 5 6
c 7 8
pd.concat([df1, df2], axis=1, keys=['level1', 'level2'])
level1 level2
one two three four
a 0 1 5.0 6.0
b 2 3 NaN NaN
c 4 5 7.0 8.0
如果传入的不是列表而是一个字典,则字典的键就会被当做keys选项的值:
pd.concat({'level1': df1, 'level2': df2}, axis=1)
level1 level2
one two three four
a 0 1 5.0 6.0
b 2 3 NaN NaN
c 4 5 7.0 8.0
此外还有两个用于管理层次化索引创建方式的参数(参见下表)。举个例子,我们可以用names参数命名创建的轴级别:
pd.concat([df1, df2], axis=1, keys=['level1', 'level2'],names=['upper', 'lower'])
upper level1 level2
lower one two three four
a 0 1 5.0 6.0
b 2 3 NaN NaN
c 4 5 7.0 8.0
最后一个关于DataFrame的问题是,DataFrame的行索引不包含任何相关数据:
df1 = pd.DataFrame(np.random.randn(3, 4), columns=['a', 'b', 'c', 'd'])
df2 = pd.DataFrame(np.random.randn(2, 3), columns=['b', 'd', 'a'])
df1
a b c d
0 1.246435 1.007189 -1.296221 0.274992
1 0.228913 1.352917 0.886429 -2.001637
2 -0.371843 1.669025 -0.438570 -0.539741
df2
b d a
0 0.476985 3.248944 -1.021228
1 -0.577087 0.124121 0.302614
在这种情况下,传入ignore_index=True即可:
pd.concat([df1, df2], ignore_index=True)
a b c d
0 1.246435 1.007189 -1.296221 0.274992
1 0.228913 1.352917 0.886429 -2.001637
2 -0.371843 1.669025 -0.438570 -0.539741
3 -1.021228 0.476985 NaN 3.248944
4 0.302614 -0.577087 NaN 0.124121
合并重叠数据
还有一种数据组合问题不能用简单的合并(merge)或连接(concatenation)运算来处理。比如说,你可能有索引全部或部分重叠的两个数据集。举个有启发性的例子,我们使用NumPy的where函数,它表示一种等价于面向数组的if-else:
a = pd.Series([np.nan, 2.5, np.nan, 3.5, 4.5, np.nan],index=['f', 'e', 'd', 'c', 'b', 'a'])
b = pd.Series(np.arange(len(a), dtype=np.float64),index=['f', 'e', 'd', 'c', 'b', 'a'])
b[-1] = np.nan
a
f NaN
e 2.5
d NaN
c 3.5
b 4.5
a NaN
dtype: float64
b
f 0.0
e 1.0
d 2.0
c 3.0
b 4.0
a NaN
dtype: float64
np.where(pd.isnull(a), b, a)
array([ 0. , 2.5, 2. , 3.5, 4.5, nan])
Series有一个combine_first方法,实现的也是一样的功能,还带有pandas的数据对齐:
b[:-2].combine_first(a[2:])
a NaN
b 4.5
c 3.0
d 2.0
e 1.0
f 0.0
dtype: float64
对于DataFrame,combine_first自然也会在列上做同样的事情,因此你可以将其看做:用传递对象中的数据为调用对象的缺失数据“打补丁”:
df1 = pd.DataFrame({'a': [1., np.nan, 5., np.nan],'b': [np.nan, 2., np.nan, 6.],'c': range(2, 18, 4)})
df2 = pd.DataFrame({'a': [5., 4., np.nan, 3., 7.],'b': [np.nan, 3., 4., 6., 8.]})
df1
a b c
0 1.0 NaN 2
1 NaN 2.0 6
2 5.0 NaN 10
3 NaN 6.0 14
df2
a b
0 5.0 NaN
1 4.0 3.0
2 NaN 4.0
3 3.0 6.0
4 7.0 8.0
df1.combine_first(df2)
a b c
0 1.0 NaN 2.0
1 4.0 2.0 6.0
2 5.0 4.0 10.0
3 3.0 6.0 14.0
4 7.0 8.0 NaN
重塑和轴向旋转
有许多用于重新排列表格型数据的基础运算。这些函数也称作重塑(reshape)或轴向旋转(pivot)运算。
重塑层次化索引
层次化索引为DataFrame数据的重排任务提供了一种具有良好一致性的方式。主要功能有二:
stack:将数据的列“旋转”为行。unstack:将数据的行“旋转”为列。
我将通过一系列的范例来讲解这些操作。接下来看一个简单的DataFrame,其中的行列索引均为字符串数组:
data = pd.DataFrame(np.arange(6).reshape((2, 3)),index=pd.Index(['Ohio','Colorado'], name='state'),columns=pd.Index(['one', 'two', 'three'],name='number'))
data
number one two three
state
Ohio 0 1 2
Colorado 3 4 5
对该数据使用stack方法即可将列转换为行,得到一个Series:
result = data.stack()
result
state number
Ohio one 0
two 1
three 2
Colorado one 3
two 4
three 5
dtype: int64
对于一个层次化索引的Series,你可以用unstack将其重排为一个DataFrame:
result.unstack()
number one two three
state
Ohio 0 1 2
Colorado 3 4 5
默认情况下,unstack操作的是最内层(stack也是如此)。传入分层级别的编号或名称即可对其它级别进行unstack操作:
result.unstack(0)
state Ohio Colorado
number
one 0 3
two 1 4
three 2 5
result.unstack('state')
state Ohio Colorado
number
one 0 3
two 1 4
three 2 5
如果不是所有的级别值都能在各分组中找到的话,则unstack操作可能会引入缺失数据:
s1 = pd.Series([0, 1, 2, 3], index=['a', 'b', 'c', 'd'])
s2 = pd.Series([4, 5, 6], index=['c', 'd', 'e'])
data2 = pd.concat([s1, s2], keys=['one', 'two'])
data2
one a 0
b 1
c 2
d 3
two c 4
d 5
e 6
dtype: int64
data2.unstack()
a b c d e
one 0.0 1.0 2.0 3.0 NaN
two NaN NaN 4.0 5.0 6.0
stack默认会滤除缺失数据,因此该运算是可逆的:
data2.unstack()
a b c d e
one 0.0 1.0 2.0 3.0 NaN
two NaN NaN 4.0 5.0 6.0
data2.unstack().stack()
one a 0.0
b 1.0
c 2.0
d 3.0
two c 4.0
d 5.0
e 6.0
dtype: float64
data2.unstack().stack(dropna=False)
one a 0.0
b 1.0
c 2.0
d 3.0
e NaN
two a NaN
b NaN
c 4.0
d 5.0
e 6.0
dtype: float64
在对DataFrame进行unstack操作时,作为旋转轴的级别将会成为结果中的最低级别:
df = pd.DataFrame({'left': result, 'right': result + 5},columns=pd.Index(['left', 'right'], name='side'))
df
side left right
state number
Ohio one 0 5
two 1 6
three 2 7
Colorado one 3 8
two 4 9
three 5 10
df.unstack('state')
side left right
state Ohio Colorado Ohio Colorado
number
one 0 3 5 8
two 1 4 6 9
three 2 5 7 10
当调用stack,我们可以指明轴的名字:
df.unstack('state').stack('side')
state Colorado Ohio
number side
one left 3 0
right 8 5
two left 4 1
right 9 6
three left 5 2
right 10 7
将“长格式”旋转为“宽格式”
多个时间序列数据通常是以所谓的“长格式”(long)或“堆叠格式”(stacked)存储在数据库和CSV中的。我们先加载一些示例数据,做一些时间序列规整和数据清洗:
data = pd.read_csv('examples/macrodata.csv')
data.head()
year quarter realgdp realcons realinv realgovt realdpi cpi \
0 1959.0 1.0 2710.349 1707.4 286.898 470.045 1886.9 28.98
1 1959.0 2.0 2778.801 1733.7 310.859 481.301 1919.7 29.15
2 1959.0 3.0 2775.488 1751.8 289.226 491.260 1916.4 29.35
3 1959.0 4.0 2785.204 1753.7 299.356 484.052 1931.3 29.37
4 1960.0 1.0 2847.699 1770.5 331.722 462.199 1955.5 29.54
m1 tbilrate unemp pop infl realint
0 139.7 2.82 5.8 177.146 0.00 0.00
1 141.7 3.08 5.1 177.830 2.34 0.74
2 140.5 3.82 5.3 178.657 2.74 1.09
3 140.0 4.33 5.6 179.386 0.27 4.06
4 139.6 3.50 5.2 180.007 2.31 1.19
periods = pd.PeriodIndex(year=data.year, quarter=data.quarter,name='date')
columns = pd.Index(['realgdp', 'infl', 'unemp'], name='item')
data = data.reindex(columns=columns)
data.index = periods.to_timestamp('D', 'end')
ldata = data.stack().reset_index().rename(columns={0: 'value'})
这就是多个时间序列(或者其它带有两个或多个键的可观察数据,这里,我们的键是date和item)的长格式。表中的每行代表一次观察。
关系型数据库(如MySQL)中的数据经常都是这样存储的,因为固定架构(即列名和数据类型)有一个好处:随着表中数据的添加,item列中的值的种类能够增加。在前面的例子中,date和item通常就是主键(用关系型数据库的说法),不仅提供了关系完整性,而且提供了更为简单的查询支持。有的情况下,使用这样的数据会很麻烦,你可能会更喜欢DataFrame,不同的item值分别形成一列,date列中的时间戳则用作索引。DataFrame的pivot方法完全可以实现这个转换:
pivoted = ldata.pivot('date', 'item', 'value')
pivoted
item infl realgdp unemp
date
1959-03-31 0.00 2710.349 5.8
1959-06-30 2.34 2778.801 5.1
1959-09-30 2.74 2775.488 5.3
1959-12-31 0.27 2785.204 5.6
1960-03-31 2.31 2847.699 5.2
1960-06-30 0.14 2834.390 5.2
1960-09-30 2.70 2839.022 5.6
1960-12-31 1.21 2802.616 6.3
1961-03-31 -0.40 2819.264 6.8
1961-06-30 1.47 2872.005 7.0
... ... ... ...
2007-06-30 2.75 13203.977 4.5
2007-09-30 3.45 13321.109 4.7
2007-12-31 6.38 13391.249 4.8
2008-03-31 2.82 13366.865 4.9
2008-06-30 8.53 13415.266 5.4
2008-09-30 -3.16 13324.600 6.0
2008-12-31 -8.79 13141.920 6.9
2009-03-31 0.94 12925.410 8.1
2009-06-30 3.37 12901.504 9.2
2009-09-30 3.56 12990.341 9.6
[203 rows x 3 columns]
前两个传递的值分别用作行和列索引,最后一个可选值则是用于填充DataFrame的数据列。假设有两个需要同时重塑的数据列:
ldata['value2'] = np.random.randn(len(ldata))
ldata[:10]
date item value value2
0 1959-03-31 realgdp 2710.349 0.523772
1 1959-03-31 infl 0.000 0.000940
2 1959-03-31 unemp 5.800 1.343810
3 1959-06-30 realgdp 2778.801 -0.713544
4 1959-06-30 infl 2.340 -0.831154
5 1959-06-30 unemp 5.100 -2.370232
6 1959-09-30 realgdp 2775.488 -1.860761
7 1959-09-30 infl 2.740 -0.860757
8 1959-09-30 unemp 5.300 0.560145
9 1959-12-31 realgdp 2785.204 -1.265934
如果忽略最后一个参数,得到的DataFrame就会带有层次化的列:
pivoted = ldata.pivot('date', 'item')
pivoted[:5]
value value2
item infl realgdp unemp infl realgdp unemp
date
1959-03-31 0.00 2710.349 5.8 0.000940 0.523772 1.343810
1959-06-30 2.34 2778.801 5.1 -0.831154 -0.713544 -2.370232
1959-09-30 2.74 2775.488 5.3 -0.860757 -1.860761 0.560145
1959-12-31 0.27 2785.204 5.6 0.119827 -1.265934 -1.063512
1960-03-31 2.31 2847.699 5.2 -2.359419 0.332883 -0.199543
pivoted['value'][:5]
item infl realgdp unemp
date
1959-03-31 0.00 2710.349 5.8
1959-06-30 2.34 2778.801 5.1
1959-09-30 2.74 2775.488 5.3
1959-12-31 0.27 2785.204 5.6
1960-03-31 2.31 2847.699 5.2
注意,pivot其实就是用set_index创建层次化索引,再用unstack重塑:
unstacked = ldata.set_index(['date', 'item']).unstack('item')
unstacked[:7]
value value2
item infl realgdp unemp infl realgdp unemp
date
1959-03-31 0.00 2710.349 5.8 0.000940 0.523772 1.343810
1959-06-30 2.34 2778.801 5.1 -0.831154 -0.713544 -2.370232
1959-09-30 2.74 2775.488 5.3 -0.860757 -1.860761 0.560145
1959-12-31 0.27 2785.204 5.6 0.119827 -1.265934 -1.063512
1960-03-31 2.31 2847.699 5.2 -2.359419 0.332883 -0.199543
1960-06-30 0.14 2834.390 5.2 -0.970736 -1.541996 -1.307030
1960-09-30 2.70 2839.022 5.6 0.377984 0.286350 -0.753887
将“宽格式”旋转为“长格式”
旋转DataFrame的逆运算是pandas.melt。它不是将一列转换到多个新的DataFrame,而是合并多个列成为一个,产生一个比输入长的DataFrame。看一个例子:
df = pd.DataFrame({'key': ['foo', 'bar', 'baz'],'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]})
df
A B C key
0 1 4 7 foo
1 2 5 8 bar
2 3 6 9 baz
key列可能是分组指标,其它的列是数据值。当使用pandas.melt,我们必须指明哪些列是分组指标。下面使用key作为唯一的分组指标:
melted = pd.melt(df, ['key'])
melted
key variable value
0 foo A 1
1 bar A 2
2 baz A 3
3 foo B 4
4 bar B 5
5 baz B 6
6 foo C 7
7 bar C 8
8 baz C 9
使用pivot,可以重塑回原来的样子:
reshaped = melted.pivot('key', 'variable', 'value')
reshaped
variable A B C
key
bar 2 5 8
baz 3 6 9
foo 1 4 7
因为pivot的结果从列创建了一个索引,用作行标签,我们可以使用reset_index将数据移回列:
reshaped.reset_index()
variable key A B C
0 bar 2 5 8
1 baz 3 6 9
2 foo 1 4 7
你还可以指定列的子集,作为值的列:
pd.melt(df, id_vars=['key'], value_vars=['A', 'B'])
key variable value
0 foo A 1
1 bar A 2
2 baz A 3
3 foo B 4
4 bar B 5
5 baz B 6
pandas.melt也可以不用分组指标:
pd.melt(df, value_vars=['A', 'B', 'C'])
variable value
0 A 1
1 A 2
2 A 3
3 B 4
4 B 5
5 B 6
6 C 7
7 C 8
8 C 9
pd.melt(df, value_vars=['key', 'A', 'B'])
variable value
0 key foo
1 key bar
2 key baz
3 A 1
4 A 2
5 A 3
6 B 4
7 B 5
8 B 6
数据聚合与分组运算
在本章中,你将会学到:
- 使用一个或多个键(形式可以是函数、数组或
DataFrame列名)分割pandas对象。 - 计算分组的概述统计,比如数量、平均值或标准差,或是用户定义的函数。
- 应用组内转换或其他运算,如规格化、线性回归、排名或选取子集等。
- 计算透视表或交叉表。
- 执行分位数分析以及其它统计分组分析。
笔记:对时间序列数据的聚合(
groupby的特殊用法之一)也称作重采样(resampling)
GroupBy机制
Hadley Wickham(许多热门R语言包的作者)创造了一个用于表示分组运算的术语"split-apply-combine"(拆分-应用-合并)。第一个阶段,pandas对象(无论是Series、DataFrame还是其他的)中的数据会根据你所提供的一个或多个键被拆分(split)为多组。拆分操作是在对象的特定轴上执行的。例如,DataFrame可以在其行(axis=0)或列(axis=1)上进行分组。然后,将一个函数应用(apply)到各个分组并产生一个新值。最后,所有这些函数的执行结果会被合并(combine)到最终的结果对象中。结果对象的形式一般取决于数据上所执行的操作。下图大致说明了一个简单的分组聚合过程。
分组键可以有多种形式,且类型不必相同:
- 列表或数组,其长度与待分组的轴一样。
- 表示
DataFrame某个列名的值。 - 字典或
Series,给出待分组轴上的值与分组名之间的对应关系。 - 函数,用于处理轴索引或索引中的各个标签。
后三种都只是快捷方式而已,其最终目的仍然是产生一组用于拆分对象的值。首先来看看下面这个非常简单的表格型数据集(以DataFrame的形式):
df = pd.DataFrame({'key1' : ['a', 'a', 'b', 'b', 'a'],'key2' : ['one', 'two', 'one', 'two', 'one'],'data1' : np.random.randn(5),'data2' : np.random.randn(5)})
df
data1 data2 key1 key2
0 -0.204708 1.393406 a one
1 0.478943 0.092908 a two
2 -0.519439 0.281746 b one
3 -0.555730 0.769023 b two
4 1.965781 1.246435 a one
假设你想要按key1进行分组,并计算data1列的平均值。实现该功能的方式有很多,而我们这里要用的是:访问data1,并根据key1调用groupby:
grouped = df['data1'].groupby(df['key1'])
grouped
<pandas.core.groupby.SeriesGroupBy object at 0x7faa31537390>
变量grouped是一个GroupBy对象。它实际上还没有进行任何计算,只是含有一些有关分组键df['key1']的中间数据而已。换句话说,该对象已经有了接下来对各分组执行运算所需的一切信息。例如,我们可以调用GroupBy的mean方法来计算分组平均值:
grouped.mean()
key1
a 0.746672
b -0.537585
Name: data1, dtype: float64
稍后我将详细讲解.mean()的调用过程。这里最重要的是,数据(Series)根据分组键进行了聚合,产生了一个新的Series,其索引为key1列中的唯一值。之所以结果中索引的名称为key1,是因为原始DataFrame的列df['key1']就叫这个名字。
如果我们一次传入多个数组的列表,就会得到不同的结果:
means = df['data1'].groupby([df['key1'], df['key2']]).mean()
means
key1 key2
a one 0.880536
two 0.478943
b one -0.519439
two -0.555730
Name: data1, dtype: float64
这里,我通过两个键对数据进行了分组,得到的Series具有一个层次化索引(由唯一的键对组成):
means.unstack()
key2 one two
key1
a 0.880536 0.478943
b -0.519439 -0.555730
在这个例子中,分组键均为Series。实际上,分组键可以是任何长度适当的数组:
states = np.array(['Ohio', 'California', 'California', 'Ohio', 'Ohio'])
years = np.array([2005, 2005, 2006, 2005, 2006])
df['data1'].groupby([states, years]).mean()
California 2005 0.478943
2006 -0.519439
Ohio 2005 -0.380219
2006 1.965781
Name: data1, dtype: float64
通常,分组信息就位于相同的要处理DataFrame中。这里,你还可以将列名(可以是字符串、数字或其他Python对象)用作分组键:
df.groupby('key1').mean()
data1 data2
key1
a 0.746672 0.910916
b -0.537585 0.525384
df.groupby(['key1', 'key2']).mean()
data1 data2
key1 key2
a one 0.880536 1.319920
two 0.478943 0.092908
b one -0.519439 0.281746
two -0.555730 0.769023
你可能已经注意到了,第一个例子在执行df.groupby('key1').mean()时,结果中没有key2列。这是因为df['key2']不是数值数据(俗称“麻烦列”),所以被从结果中排除了。默认情况下,所有数值列都会被聚合,虽然有时可能会被过滤为一个子集,稍后就会碰到。
无论你准备拿groupby做什么,都有可能会用到GroupBy的size方法,它可以返回一个含有分组大小的Series:
df.groupby(['key1', 'key2']).size()
key1 key2
a one 2
two 1
b one 1
two 1
dtype: int64
注意,任何分组关键词中的缺失值,都会被从结果中除去。
对分组进行迭代
GroupBy对象支持迭代,可以产生一组二元元组(由分组名和数据块组成)。
for name, group in df.groupby('key1'):
print(name)
print(group)
a
data1 data2 key1 key2
0 -0.204708 1.393406 a one
1 0.478943 0.092908 a two
4 1.965781 1.246435 a one
b
data1 data2 key1 key2
2 -0.519439 0.281746 b one
3 -0.555730 0.769023 b two
对于多重键的情况,元组的第一个元素将会是由键值组成的元组:
for (k1, k2), group in df.groupby(['key1', 'key2']):
print((k1, k2))
print(group)
('a', 'one')
data1 data2 key1 key2
0 -0.204708 1.393406 a one
4 1.965781 1.246435 a one
('a', 'two')
data1 data2 key1 key2
1 0.478943 0.092908 a two
('b', 'one')
data1 data2 key1 key2
2 -0.519439 0.281746 b one
('b', 'two')
data1 data2 key1 key2
3 -0.55573 0.769023 b two
当然,你可以对这些数据片段做任何操作。有一个你可能会觉得有用的运算:将这些数据片段做成一个字典:
pieces = dict(list(df.groupby('key1')))
pieces['b']
data1 data2 key1 key2
2 -0.519439 0.281746 b one
3 -0.555730 0.769023 b two
groupby默认是在axis=0上进行分组的,通过设置也可以在其他任何轴上进行分组。拿上面例子中的df来说,我们可以根据dtype对列进行分组:
df.dtypes
data1 float64
data2 float64
key1 object
key2 object
dtype: object
grouped = df.groupby(df.dtypes, axis=1)
可以如下打印分组:
for dtype, group in grouped:
print(dtype)
print(group)
float64
data1 data2
0 -0.204708 1.393406
1 0.478943 0.092908
2 -0.519439 0.281746
3 -0.555730 0.769023
4 1.965781 1.246435
object
key1 key2
0 a one
1 a two
2 b one
3 b two
4 a one
选取一列或列的子集
对于由DataFrame产生的GroupBy对象,如果用一个(单个字符串)或一组(字符串数组)列名对其进行索引,就能实现选取部分列进行聚合的目的。也就是说:
df.groupby('key1')['data1']
df.groupby('key1')[['data2']]
是以下代码的语法糖:
df['data1'].groupby(df['key1'])
df[['data2']].groupby(df['key1'])
尤其对于大数据集,很可能只需要对部分列进行聚合。例如,在前面那个数据集中,如果只需计算data2列的平均值并以DataFrame形式得到结果,可以这样写:
df.groupby(['key1', 'key2'])[['data2']].mean()
data2
key1 key2
a one 1.319920
two 0.092908
b one 0.281746
two 0.769023
这种索引操作所返回的对象是一个已分组的DataFrame(如果传入的是列表或数组)或已分组的Series(如果传入的是标量形式的单个列名):
s_grouped = df.groupby(['key1', 'key2'])['data2']
s_grouped
<pandas.core.groupby.SeriesGroupBy object at 0x7faa30c78da0>
s_grouped.mean()
key1 key2
a one 1.319920
two 0.092908
b one 0.281746
two 0.769023
Name: data2, dtype: float64
通过字典或Series进行分组 除数组以外,分组信息还可以其他形式存在。来看另一个示例DataFrame:
people = pd.DataFrame(np.random.randn(5, 5),columns=['a', 'b', 'c', 'd', 'e'],index=['Joe', 'Steve', 'Wes', 'Jim', 'Travis'])
people.iloc[2:3, [1, 2]] = np.nan # Add a few NA values
people
a b c d e
Joe 1.007189 -1.296221 0.274992 0.228913 1.352917
Steve 0.886429 -2.001637 -0.371843 1.669025 -0.438570
Wes -0.539741 NaN NaN -1.021228 -0.577087
Jim 0.124121 0.302614 0.523772 0.000940 1.343810
Travis -0.713544 -0.831154 -2.370232 -1.860761 -0.860757
现在,假设已知列的分组关系,并希望根据分组计算列的和:
mapping = {'a': 'red', 'b': 'red', 'c': 'blue','d': 'blue', 'e': 'red', 'f' : 'orange'}
现在,你可以将这个字典传给groupby,来构造数组,但我们可以直接传递字典(我包含了键“f”来强调,存在未使用的分组键是可以的):
by_column = people.groupby(mapping, axis=1)
by_column.sum()
blue red
Joe 0.503905 1.063885
Steve 1.297183 -1.553778
Wes -1.021228 -1.116829
Jim 0.524712 1.770545
Travis -4.230992 -2.405455
Series也有同样的功能,它可以被看做一个固定大小的映射:
map_series = pd.Series(mapping)
map_series
a red
b red
c blue
d blue
e red
f orange
dtype: object
people.groupby(map_series, axis=1).count()
blue red
Joe 2 3
Steve 2 3
Wes 1 2
Jim 2 3
Travis 2 3
通过函数进行分组 比起使用字典或Series,使用Python函数是一种更原生的方法定义分组映射。任何被当做分组键的函数都会在各个索引值上被调用一次,其返回值就会被用作分组名称。具体点说,以上一小节的示例DataFrame为例,其索引值为人的名字。你可以计算一个字符串长度的数组,更简单的方法是传入len函数:
people.groupby(len).sum()
a b c d e
3 0.591569 -0.993608 0.798764 -0.791374 2.119639
5 0.886429 -2.001637 -0.371843 1.669025 -0.438570
6 -0.713544 -0.831154 -2.370232 -1.860761 -0.860757
将函数跟数组、列表、字典、Series混合使用也不是问题,因为任何东西在内部都会被转换为数组:
key_list = ['one', 'one', 'one', 'two', 'two']
people.groupby([len, key_list]).min()
a b c d e
3 one -0.539741 -1.296221 0.274992 -1.021228 -0.577087
two 0.124121 0.302614 0.523772 0.000940 1.343810
5 one 0.886429 -2.001637 -0.371843 1.669025 -0.438570
6 two -0.713544 -0.831154 -2.370232 -1.860761 -0.860757
根据索引级别分组
层次化索引数据集最方便的地方就在于它能够根据轴索引的一个级别进行聚合:
columns = pd.MultiIndex.from_arrays([['US', 'US', 'US', 'JP', 'JP'],[1, 3, 5, 1, 3]],names=['cty', 'tenor'])
hier_df = pd.DataFrame(np.random.randn(4, 5), columns=columns)
hier_df
cty US JP
tenor 1 3 5 1 3
0 0.560145 -1.265934 0.119827 -1.063512 0.332883
1 -2.359419 -0.199543 -1.541996 -0.970736 -1.307030
2 0.286350 0.377984 -0.753887 0.331286 1.349742
3 0.069877 0.246674 -0.011862 1.004812 1.327195
要根据级别分组,使用level关键字传递级别序号或名字:
hier_df.groupby(level='cty', axis=1).count()
cty JP US
0 2 3
1 2 3
2 2 3
3 2 3
数据聚合
聚合指的是任何能够从数组产生标量值的数据转换过程。之前的例子已经用过一些,比如mean、count、min以及sum等。你可能想知道在GroupBy对象上调用mean()时究竟发生了什么。许多常见的聚合运算(如下表所示)都有进行优化。然而,除了这些方法,你还可以使用其它的。
经过优化的groupby方法:

你可以使用自己发明的聚合运算,还可以调用分组对象上已经定义好的任何方法。例如,quantile可以计算Series或DataFrame列的样本分位数。
虽然quantile并没有明确地实现于GroupBy,但它是一个Series方法,所以这里是能用的。实际上,GroupBy会高效地对Series进行切片,然后对各片调用piece.quantile(0.9),最后将这些结果组装成最终结果:
df
data1 data2 key1 key2
0 -0.204708 1.393406 a one
1 0.478943 0.092908 a two
2 -0.519439 0.281746 b one
3 -0.555730 0.769023 b two
4 1.965781 1.246435 a one
grouped = df.groupby('key1')
grouped['data1'].quantile(0.9)
key1
a 1.668413
b -0.523068
Name: data1, dtype: float64
如果要使用你自己的聚合函数,只需将其传入aggregate或agg方法即可:
def peak_to_peak(arr):
return arr.max() - arr.min()
grouped.agg(peak_to_peak)
data1 data2
key1
a 2.170488 1.300498
b 0.036292 0.487276
你可能注意到注意,有些方法(如describe)也是可以用在这里的,即使严格来讲,它们并非聚合运算:
grouped.describe()
data1 \
count mean std min 25% 50% 75%
key1
a 3.0 0.746672 1.109736 -0.204708 0.137118 0.478943 1.222362
b 2.0 -0.537585 0.025662 -0.555730 -0.546657 -0.537585 -0.528512
data2 \
max count mean std min 25% 50%
key1
a 1.965781 3.0 0.910916 0.712217 0.092908 0.669671 1.246435
b -0.519439 2.0 0.525384 0.344556 0.281746 0.403565 0.525384
75% max
key1
a 1.319920 1.393406
b 0.647203 0.769023
笔记:自定义聚合函数要比上表中那些经过优化的函数慢得多。这是因为在构造中间分组数据块时存在非常大的开销(函数调用、数据重排等)。
面向列的多函数应用
回到前面小费的例子。使用read_csv导入数据之后,我们添加了一个小费百分比的列tip_pct:
tips = pd.read_csv('examples/tips.csv')
#Add tip percentage of total bill
tips['tip_pct'] = tips['tip'] / tips['total_bill']
tips[:6]
total_bill tip smoker day time size tip_pct
0 16.99 1.01 No Sun Dinner 2 0.059447
1 10.34 1.66 No Sun Dinner 3 0.160542
2 21.01 3.50 No Sun Dinner 3 0.166587
3 23.68 3.31 No Sun Dinner 2 0.139780
4 24.59 3.61 No Sun Dinner 4 0.146808
5 25.29 4.71 No Sun Dinner 4 0.186240
你已经看到,对Series或DataFrame列的聚合运算其实就是使用aggregate(使用自定义函数)或调用诸如mean、std之类的方法。然而,你可能希望对不同的列使用不同的聚合函数,或一次应用多个函数。其实这也好办,我将通过一些示例来进行讲解。首先,我根据天和smoker对tips进行分组:
grouped = tips.groupby(['day', 'smoker'])
注意,对于上表中的那些描述统计,可以将函数名以字符串的形式传入:
grouped_pct = grouped['tip_pct']
grouped_pct.agg('mean')
day smoker
Fri No 0.151650
Yes 0.174783
Sat No 0.158048
Yes 0.147906
Sun No 0.160113
Yes 0.187250
Thur No 0.160298
Yes 0.163863
Name: tip_pct, dtype: float64
如果传入一组函数或函数名,得到的DataFrame的列就会以相应的函数命名:
grouped_pct.agg(['mean', 'std', peak_to_peak])
mean std peak_to_peak
day smoker
Fri No 0.151650 0.028123 0.067349
Yes 0.174783 0.051293 0.159925
Sat No 0.158048 0.039767 0.235193
Yes 0.147906 0.061375 0.290095
Sun No 0.160113 0.042347 0.193226
Yes 0.187250 0.154134 0.644685
Thur No 0.160298 0.038774 0.193350
Yes 0.163863 0.039389 0.151240
这里,我们传递了一组聚合函数进行聚合,独立对数据分组进行评估。
你并非一定要接受GroupBy自动给出的那些列名,特别是lambda函数,它们的名称是'',这样的辨识度就很低了(通过函数的__name__属性看看就知道了)。因此,如果传入的是一个由(name,function)元组组成的列表,则各元组的第一个元素就会被用作DataFrame的列名(可以将这种二元元组列表看做一个有序映射):
grouped_pct.agg([('foo', 'mean'), ('bar', np.std)])
foo bar
day smoker
Fri No 0.151650 0.028123
Yes 0.174783 0.051293
Sat No 0.158048 0.039767
Yes 0.147906 0.061375
Sun No 0.160113 0.042347
Yes 0.187250 0.154134
Thur No 0.160298 0.038774
Yes 0.163863 0.039389
对于DataFrame,你还有更多选择,你可以定义一组应用于全部列的一组函数,或不同的列应用不同的函数。假设我们想要对tip_pct和total_bill列计算三个统计信息:
functions = ['count', 'mean', 'max']
result = grouped['tip_pct', 'total_bill'].agg(functions)
result
tip_pct total_bill
count mean max count mean max
day smoker
Fri No 4 0.151650 0.187735 4 18.420000 22.75
Yes 15 0.174783 0.263480 15 16.813333 40.17
Sat No 45 0.158048 0.291990 45 19.661778 48.33
Yes 42 0.147906 0.325733 42 21.276667 50.81
Sun No 57 0.160113 0.252672 57 20.506667 48.17
Yes 19 0.187250 0.710345 19 24.120000 45.35
Thur No 45 0.160298 0.266312 45 17.113111 41.19
Yes 17 0.163863 0.241255 17 19.190588 43.11
如你所见,结果DataFrame拥有层次化的列,这相当于分别对各列进行聚合,然后用concat将结果组装到一起,使用列名用作keys参数:
result['tip_pct']
count mean max
day smoker
Fri No 4 0.151650 0.187735
Yes 15 0.174783 0.263480
Sat No 45 0.158048 0.291990
Yes 42 0.147906 0.325733
Sun No 57 0.160113 0.252672
Yes 19 0.187250 0.710345
Thur No 45 0.160298 0.266312
Yes 17 0.163863 0.241255
跟前面一样,这里也可以传入带有自定义名称的一组元组:
ftuples = [('Durchschnitt', 'mean'),('Abweichung', np.var)]
grouped['tip_pct', 'total_bill'].agg(ftuples)
tip_pct total_bill
Durchschnitt Abweichung Durchschnitt Abweichung
day smoker
Fri No 0.151650 0.000791 18.420000 25.596333
Yes 0.174783 0.002631 16.813333 82.562438
Sat No 0.158048 0.001581 19.661778 79.908965
Yes 0.147906 0.003767 21.276667 101.387535
Sun No 0.160113 0.001793 20.506667 66.099980
Yes 0.187250 0.023757 24.120000 109.046044
Thur No 0.160298 0.001503 17.113111 59.625081
Yes 0.163863 0.001551 19.190588 69.808518
现在,假设你想要对一个列或不同的列应用不同的函数。具体的办法是向agg传入一个从列名映射到函数的字典:
grouped.agg({'tip' : np.max, 'size' : 'sum'})
tip size
day smoker
Fri No 3.50 9
Yes 4.73 31
Sat No 9.00 115
Yes 10.00 104
Sun No 6.00 167
Yes 6.50 49
Thur No 6.70 112
Yes 5.00 40
grouped.agg({'tip_pct' : ['min', 'max', 'mean', 'std'],'size' : 'sum'})
tip_pct size
min max mean std sum
day smoker
Fri No 0.120385 0.187735 0.151650 0.028123 9
Yes 0.103555 0.263480 0.174783 0.051293 31
Sat No 0.056797 0.291990 0.158048 0.039767 115
Yes 0.035638 0.325733 0.147906 0.061375 104
Sun No 0.059447 0.252672 0.160113 0.042347 167
Yes 0.065660 0.710345 0.187250 0.154134 49
Thur No 0.072961 0.266312 0.160298 0.038774 112
Yes 0.090014 0.241255 0.163863 0.039389 40
只有将多个函数应用到至少一列时,DataFrame才会拥有层次化的列。
以“没有行索引”的形式返回聚合数据
到目前为止,所有示例中的聚合数据都有由唯一的分组键组成的索引(可能还是层次化的)。由于并不总是需要如此,所以你可以向groupby传入as_index=False以禁用该功能:
tips.groupby(['day', 'smoker'], as_index=False).mean()
day smoker total_bill tip size tip_pct
0 Fri No 18.420000 2.812500 2.250000 0.151650
1 Fri Yes 16.813333 2.714000 2.066667 0.174783
2 Sat No 19.661778 3.102889 2.555556 0.158048
3 Sat Yes 21.276667 2.875476 2.476190 0.147906
4 Sun No 20.506667 3.167895 2.929825 0.160113
5 Sun Yes 24.120000 3.516842 2.578947 0.187250
6 Thur No 17.113111 2.673778 2.488889 0.160298
7 Thur Yes 19.190588 3.030000 2.352941 0.163863
当然,对结果调用reset_index也能得到这种形式的结果。使用as_index=False方法可以避免一些不必要的计算。
apply:一般性的“拆分-应用-合并”
最通用的GroupBy方法是apply,本节剩余部分将重点讲解它。如下图所示,apply会将待处理的对象拆分成多个片段,然后对各片段调用传入的函数,最后尝试将各片段组合到一起。
回到之前那个小费数据集,假设你想要根据分组选出最高的5个tip_pct值。首先,编写一个选取指定列具有最大值的行的函数:
def top(df, n=5, column='tip_pct'):
return df.sort_values(by=column)[-n:]
top(tips, n=6)
total_bill tip smoker day time size tip_pct
109 14.31 4.00 Yes Sat Dinner 2 0.279525
183 23.17 6.50 Yes Sun Dinner 4 0.280535
232 11.61 3.39 No Sat Dinner 2 0.291990
67 3.07 1.00 Yes Sat Dinner 1 0.325733
178 9.60 4.00 Yes Sun Dinner 2 0.416667
172 7.25 5.15 Yes Sun Dinner 2 0.710345
现在,如果对smoker分组并用该函数调用apply,就会得到:
tips.groupby('smoker').apply(top)
total_bill tip smoker day time size tip_pct
smoker
No 88 24.71 5.85 No Thur Lunch 2 0.236746
185 20.69 5.00 No Sun Dinner 5 0.241663
51 10.29 2.60 No Sun Dinner 2 0.252672
149 7.51 2.00 No Thur Lunch 2 0.266312
232 11.61 3.39 No Sat Dinner 2 0.291990
Yes 109 14.31 4.00 Yes Sat Dinner 2 0.279525
183 23.17 6.50 Yes Sun Dinner 4 0.280535
67 3.07 1.00 Yes Sat Dinner 1 0.325733
178 9.60 4.00 Yes Sun Dinner 2 0.416667
172 7.25 5.15 Yes Sun Dinner 2 0.710345
这里发生了什么?top函数在DataFrame的各个片段上调用,然后结果由pandas.concat组装到一起,并以分组名称进行了标记。于是,最终结果就有了一个层次化索引,其内层索引值来自原DataFrame。
如果传给apply的函数能够接受其他参数或关键字,则可以将这些内容放在函数名后面一并传入:
tips.groupby(['smoker', 'day']).apply(top, n=1, column='total_bill')
total_bill tip smoker day time size tip_pct
smoker day
No Fri 94 22.75 3.25 No Fri Dinner 2 0.142857
Sat 212 48.33 9.00 No Sat Dinner 4 0.186220
Sun 156 48.17 5.00 No Sun Dinner 6 0.103799
Thur 142 41.19 5.00 No Thur Lunch 5 0.121389
Yes Fri 95 40.17 4.73 Yes Fri Dinner 4 0.117750
Sat 170 50.81 10.00 Yes Sat Dinner 3 0.196812
Sun 182 45.35 3.50 Yes Sun Dinner 3 0.077178
Thur 197 43.11 5.00 Yes Thur Lunch 4 0.115982
笔记:除这些基本用法之外,能否充分发挥
apply的威力很大程度上取决于你的创造力。传入的那个函数能做什么全由你说了算,它只需返回一个pandas对象或标量值即可。本章后续部分的示例主要用于讲解如何利用groupby解决各种各样的问题。
可能你已经想起来了,之前我在GroupBy对象上调用过describe:
result = tips.groupby('smoker')['tip_pct'].describe()
result
count mean std min 25% 50% 75% \
smoker
No 151.0 0.159328 0.039910 0.056797 0.136906 0.155625 0.185014
Yes 93.0 0.163196 0.085119 0.035638 0.106771 0.153846 0.195059
max
smoker
No 0.291990
Yes 0.710345
result.unstack('smoker')
smoker
count No 151.000000
Yes 93.000000
mean No 0.159328
Yes 0.163196
std No 0.039910
Yes 0.085119
min No 0.056797
Yes 0.035638
25% No 0.136906
Yes 0.106771
50% No 0.155625
Yes 0.153846
75% No 0.185014
Yes 0.195059
max No 0.291990
Yes 0.710345
dtype: float64
在GroupBy中,当你调用诸如describe之类的方法时,实际上只是应用了下面两条代码的快捷方式而已:
f = lambda x: x.describe()
grouped.apply(f)
禁止分组键
从上面的例子中可以看出,分组键会跟原始对象的索引共同构成结果对象中的层次化索引。将group_keys=False传入groupby即可禁止该效果:
tips.groupby('smoker', group_keys=False).apply(top)
total_bill tip smoker day time size tip_pct
88 24.71 5.85 No Thur Lunch 2 0.236746
185 20.69 5.00 No Sun Dinner 5 0.241663
51 10.29 2.60 No Sun Dinner 2 0.252672
149 7.51 2.00 No Thur Lunch 2 0.266312
232 11.61 3.39 No Sat Dinner 2 0.291990
109 14.31 4.00 Yes Sat Dinner 2 0.279525
183 23.17 6.50 Yes Sun Dinner 4 0.280535
67 3.07 1.00 Yes Sat Dinner 1 0.325733
178 9.60 4.00 Yes Sun Dinner 2 0.416667
172 7.25 5.15 Yes Sun Dinner 2 0.710345
分位数和桶分析
pandas有一些能根据指定面元或样本分位数将数据拆分成多块的工具(比如cut和qcut)。将这些函数跟groupby结合起来,就能非常轻松地实现对数据集的桶(bucket)或分位数(quantile)分析了。以下面这个简单的随机数据集为例,我们利用cut将其装入长度相等的桶中:
frame = pd.DataFrame({'data1': np.random.randn(1000),'data2': np.random.randn(1000)})
quartiles = pd.cut(frame.data1, 4)
quartiles[:10]
0 (-1.23, 0.489]
1 (-2.956, -1.23]
2 (-1.23, 0.489]
3 (0.489, 2.208]
4 (-1.23, 0.489]
5 (0.489, 2.208]
6 (-1.23, 0.489]
7 (-1.23, 0.489]
8 (0.489, 2.208]
9 (0.489, 2.208]
Name: data1, dtype: category
Categories (4, interval[float64]): [(-2.956, -1.23] < (-1.23, 0.489] < (0.489, 2.
208] < (2.208, 3.928]]
由cut返回的Categorical对象可直接传递到groupby。因此,我们可以像下面这样对data2列做一些统计计算:
def get_stats(group):
return {'min': group.min(), 'max': group.max(),'count': group.count(), 'mean': group.mean()}
grouped = frame.data2.groupby(quartiles)
grouped.apply(get_stats).unstack()
count max mean min
data1
(-2.956, -1.23] 95.0 1.670835 -0.039521 -3.399312
(-1.23, 0.489] 598.0 3.260383 -0.002051 -2.989741
(0.489, 2.208] 297.0 2.954439 0.081822 -3.745356
(2.208, 3.928] 10.0 1.765640 0.024750 -1.929776
这些都是长度相等的桶。要根据样本分位数得到大小相等的桶,使用qcut即可。传入labels=False即可只获取分位数的编号:
#Return quantile numbers
grouping = pd.qcut(frame.data1, 10, labels=False)
grouped = frame.data2.groupby(grouping)
grouped.apply(get_stats).unstack()
count max mean min
data1
0 100.0 1.670835 -0.049902 -3.399312
1 100.0 2.628441 0.030989 -1.950098
2 100.0 2.527939 -0.067179 -2.925113
3 100.0 3.260383 0.065713 -2.315555
4 100.0 2.074345 -0.111653 -2.047939
5 100.0 2.184810 0.052130 -2.989741
6 100.0 2.458842 -0.021489 -2.223506
7 100.0 2.954439 -0.026459 -3.056990
8 100.0 2.735527 0.103406 -3.745356
9 100.0 2.377020 0.220122 -2.064111
示例:用特定于分组的值填充缺失值
对于缺失数据的清理工作,有时你会用dropna将其替换掉,而有时则可能会希望用一个固定值或由数据集本身所衍生出来的值去填充NA值。这时就得使用fillna这个工具了。在下面这个例子中,我用平均值去填充NA值:
s = pd.Series(np.random.randn(6))
s[::2] = np.nan
s
0 NaN
1 -0.125921
2 NaN
3 -0.884475
4 NaN
5 0.227290
dtype: float64
s.fillna(s.mean())
0 -0.261035
1 -0.125921
2 -0.261035
3 -0.884475
4 -0.261035
5 0.227290
dtype: float64
假设你需要对不同的分组填充不同的值。一种方法是将数据分组,并使用apply和一个能够对各数据块调用fillna的函数即可。下面是一些有关美国几个州的示例数据,这些州又被分为东部和西部:
states = ['Ohio', 'New York', 'Vermont', 'Florida','Oregon', 'Nevada', 'California', 'Idaho']
group_key = ['East'] * 4 + ['West'] * 4
data = pd.Series(np.random.randn(8), index=states)
data
Ohio 0.922264
New York -2.153545
Vermont -0.365757
Florida -0.375842
Oregon 0.329939
Nevada 0.981994
California 1.105913
Idaho -1.613716
dtype: float64
['East'] * 4产生了一个列表,包括了['East']中元素的四个拷贝。将这些列表串联起来。
将一些值设为缺失:
data[['Vermont', 'Nevada', 'Idaho']] = np.nan
data
Ohio 0.922264
New York -2.153545
Vermont NaN
Florida -0.375842
Oregon 0.329939
Nevada NaN
California 1.105913
Idaho NaN
dtype: float64
data.groupby(group_key).mean()
East -0.535707
West 0.717926
dtype: float64
我们可以用分组平均值去填充NA值:
fill_mean = lambda g: g.fillna(g.mean())
data.groupby(group_key).apply(fill_mean)
Ohio 0.922264
New York -2.153545
Vermont -0.535707
Florida -0.375842
Oregon 0.329939
Nevada 0.717926
California 1.105913
Idaho 0.717926
dtype: float64
另外,也可以在代码中预定义各组的填充值。由于分组具有一个name属性,所以我们可以拿来用一下:
fill_values = {'East': 0.5, 'West': -1}
fill_func = lambda g: g.fillna(fill_values[g.name])
data.groupby(group_key).apply(fill_func)
Ohio 0.922264
New York -2.153545
Vermont 0.500000
Florida -0.375842
Oregon 0.329939
Nevada -1.000000
California 1.105913
Idaho -1.000000
dtype: float64
示例:随机采样和排列
假设你想要从一个大数据集中随机抽取(进行替换或不替换)样本以进行蒙特卡罗模拟(Monte Carlo simulation)或其他分析工作。“抽取”的方式有很多,这里使用的方法是对Series使用sample方法:
#Hearts, Spades, Clubs, Diamonds
suits = ['H', 'S', 'C', 'D']
card_val = (list(range(1, 11)) + [10] * 3) * 4
base_names = ['A'] + list(range(2, 11)) + ['J', 'K', 'Q']
cards = []
for suit in ['H', 'S', 'C', 'D']:
cards.extend(str(num) + suit for num in base_names)
deck = pd.Series(card_val, index=cards)
现在我有了一个长度为52的Series,其索引包括牌名,值则是21点或其他游戏中用于计分的点数(为了简单起见,我当A的点数为1):
deck[:13]
AH 1
2H 2
3H 3
4H 4
5H 5
6H 6
7H 7
8H 8
9H 9
10H 10
JH 10
KH 10
QH 10
dtype: int64
现在,根据我上面所讲的,从整副牌中抽出5张,代码如下:
def draw(deck, n=5):
return deck.sample(n)
draw(deck)
AD 1
8C 8
5H 5
KC 10
2C 2
dtype: int64
假设你想要从每种花色中随机抽取两张牌。由于花色是牌名的最后一个字符,所以我们可以据此进行分组,并使用apply:
get_suit = lambda card: card[-1] # last letter is suit
deck.groupby(get_suit).apply(draw, n=2)
C 2C 2
3C 3
D KD 10
8D 8
H KH 10
3H 3
S 2S 2
4S 4
dtype: int64
或者,也可以这样写:
deck.groupby(get_suit, group_keys=False).apply(draw, n=2)
KC 10
JC 10
AD 1
5D 5
5H 5
6H 6
7S 7
KS 10
dtype: int64
示例:分组加权平均数和相关系数
根据groupby的“拆分-应用-合并”范式,可以进行DataFrame的列与列之间或两个Series之间的运算(比如分组加权平均)。以下面这个数据集为例,它含有分组键、值以及一些权重值:
df = pd.DataFrame({'category': ['a', 'a', 'a', 'a','b', 'b', 'b', 'b'],'data': np.random.randn(8),'weights': np.random.rand(8)})
df
category data weights
0 a 1.561587 0.957515
1 a 1.219984 0.347267
2 a -0.482239 0.581362
3 a 0.315667 0.217091
4 b -0.047852 0.894406
5 b -0.454145 0.918564
6 b -0.556774 0.277825
7 b 0.253321 0.955905
然后可以利用category计算分组加权平均数:
grouped = df.groupby('category')
get_wavg = lambda g: np.average(g['data'], weights=g['weights'])
grouped.apply(get_wavg)
category
a 0.811643
b -0.122262
dtype: float64
另一个例子,考虑一个来自Yahoo!Finance的数据集,其中含有几只股票和标准普尔500指数(符号SPX)的收盘价:
close_px = pd.read_csv('examples/stock_px_2.csv', parse_dates=True,index_col=0)
close_px.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 2214 entries, 2003-01-02 to 2011-10-14
Data columns (total 4 columns):
AAPL 2214 non-null float64
MSFT 2214 non-null float64
XOM 2214 non-null float64
SPX 2214 non-null float64
dtypes: float64(4)
memory usage: 86.5 KB
close_px[-4:]
AAPL MSFT XOM SPX
2011-10-11 400.29 27.00 76.27 1195.54
2011-10-12 402.19 26.96 77.16 1207.25
2011-10-13 408.43 27.18 76.37 1203.66
2011-10-14 422.00 27.27 78.11 1224.58
来做一个比较有趣的任务:计算一个由日收益率(通过百分数变化计算)与SPX之间的年度相关系数组成的DataFrame。下面是一个实现办法,我们先创建一个函数,用它计算每列和SPX列的成对相关系数:
spx_corr = lambda x: x.corrwith(x['SPX'])
接下来,我们使用pct_change计算close_px的百分比变化:
rets = close_px.pct_change().dropna()
最后,我们用年对百分比变化进行分组,可以用一个一行的函数,从每行的标签返回每个datetime标签的year属性:
get_year = lambda x: x.year
by_year = rets.groupby(get_year)
by_year.apply(spx_corr)
AAPL MSFT XOM SPX
2003 0.541124 0.745174 0.661265 1.0
2004 0.374283 0.588531 0.557742 1.0
2005 0.467540 0.562374 0.631010 1.0
2006 0.428267 0.406126 0.518514 1.0
2007 0.508118 0.658770 0.786264 1.0
2008 0.681434 0.804626 0.828303 1.0
2009 0.707103 0.654902 0.797921 1.0
2010 0.710105 0.730118 0.839057 1.0
2011 0.691931 0.800996 0.859975 1.0
当然,你还可以计算列与列之间的相关系数。这里,我们计算Apple和Microsoft的年相关系数:
by_year.apply(lambda g: g['AAPL'].corr(g['MSFT']))
2003 0.480868
2004 0.259024
2005 0.300093
2006 0.161735
2007 0.417738
2008 0.611901
2009 0.432738
2010 0.571946
2011 0.581987
dtype: float64
示例:组级别的线性回归
顺着上一个例子继续,你可以用groupby执行更为复杂的分组统计分析,只要函数返回的是pandas对象或标量值即可。例如,我可以定义下面这个regress函数(利用statsmodels计量经济学库)对各数据块执行普通最小二乘法(Ordinary Least Squares,OLS)回归:
import statsmodels.api as sm
def regress(data, yvar, xvars):
Y = data[yvar]
X = data[xvars]
X['intercept'] = 1.
result = sm.OLS(Y, X).fit()
return result.params
现在,为了按年计算AAPL对SPX收益率的线性回归,执行:
by_year.apply(regress, 'AAPL', ['SPX'])
SPX intercept
2003 1.195406 0.000710
2004 1.363463 0.004201
2005 1.766415 0.003246
2006 1.645496 0.000080
2007 1.198761 0.003438
2008 0.968016 -0.001110
2009 0.879103 0.002954
2010 1.052608 0.001261
2011 0.806605 0.001514
透视表和交叉表
透视表(pivot table)是各种电子表格程序和其他数据分析软件中一种常见的数据汇总工具。它根据一个或多个键对数据进行聚合,并根据行和列上的分组键将数据分配到各个矩形区域中。在Python和pandas中,可以通过本章所介绍的groupby功能以及(能够利用层次化索引的)重塑运算制作透视表。DataFrame有一个pivot_table方法,此外还有一个顶级的pandas.pivot_table函数。除能为groupby提供便利之外,pivot_table还可以添加分项小计,也叫做margins。
回到小费数据集,假设我想要根据day和smoker计算分组平均数(pivot_table的默认聚合类型),并将day和smoker放到行上:
tips.pivot_table(index=['day', 'smoker'])
size tip tip_pct total_bill
day smoker
Fri No 2.250000 2.812500 0.151650 18.420000
Yes 2.066667 2.714000 0.174783 16.813333
Sat No 2.555556 3.102889 0.158048 19.661778
Yes 2.476190 2.875476 0.147906 21.276667
Sun No 2.929825 3.167895 0.160113 20.506667
Yes 2.578947 3.516842 0.187250 24.120000
Thur No 2.488889 2.673778 0.160298 17.113111
Yes 2.352941 3.030000 0.163863 19.190588
可以用groupby直接来做。现在,假设我们只想聚合tip_pct和size,而且想根据time进行分组。我将smoker放到列上,把day放到行上:
tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'],columns='smoker')
size tip_pct
smoker No Yes No Yes
time day
Dinner Fri 2.000000 2.222222 0.139622 0.165347
Sat 2.555556 2.476190 0.158048 0.147906
Sun 2.929825 2.578947 0.160113 0.187250
Thur 2.000000 NaN 0.159744 NaN
Lunch Fri 3.000000 1.833333 0.187735 0.188937
Thur 2.500000 2.352941 0.160311 0.163863
还可以对这个表作进一步的处理,传入margins=True添加分项小计。这将会添加标签为All的行和列,其值对应于单个等级中所有数据的分组统计:
tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'],columns='smoker', margins=True)
size tip_pct
smoker No Yes All No Yes All
time day
Dinner Fri 2.000000 2.222222 2.166667 0.139622 0.165347 0.158916
Sat 2.555556 2.476190 2.517241 0.158048 0.147906 0.153152
Sun 2.929825 2.578947 2.842105 0.160113 0.187250 0.166897
Thur 2.000000 NaN 2.000000 0.159744 NaN 0.159744
Lunch Fri 3.000000 1.833333 2.000000 0.187735 0.188937 0.188765
Thur 2.500000 2.352941 2.459016 0.160311 0.163863 0.161301
All 2.668874 2.408602 2.569672 0.159328 0.163196 0.160803
这里,All值为平均数:不单独考虑烟民与非烟民(All列),不单独考虑行分组两个级别中的任何单项(All行)。
要使用其他的聚合函数,将其传给aggfunc即可。例如,使用count或len可以得到有关分组大小的交叉表(计数或频率):
tips.pivot_table('tip_pct', index=['time', 'smoker'], columns='day',aggfunc=len, margins=True)
day Fri Sat Sun Thur All
time smoker
Dinner No 3.0 45.0 57.0 1.0 106.0
Yes 9.0 42.0 19.0 NaN 70.0
Lunch No 1.0 NaN NaN 44.0 45.0
Yes 6.0 NaN NaN 17.0 23.0
All 19.0 87.0 76.0 62.0 244.0
如果存在空的组合(也就是NA),你可能会希望设置一个fill_value:
tips.pivot_table('tip_pct', index=['time', 'size', 'smoker'],columns='day', aggfunc='mean', fill_value=0)
day Fri Sat Sun Thur
time size smoker
Dinner 1 No 0.000000 0.137931 0.000000 0.000000
Yes 0.000000 0.325733 0.000000 0.000000
2 No 0.139622 0.162705 0.168859 0.159744
Yes 0.171297 0.148668 0.207893 0.000000
3 No 0.000000 0.154661 0.152663 0.000000
Yes 0.000000 0.144995 0.152660 0.000000
4 No 0.000000 0.150096 0.148143 0.000000
Yes 0.117750 0.124515 0.193370 0.000000
5 No 0.000000 0.000000 0.206928 0.000000
Yes 0.000000 0.106572 0.065660 0.000000
... ... ... ... ...
Lunch 1 No 0.000000 0.000000 0.000000 0.181728
Yes 0.223776 0.000000 0.000000 0.000000
2 No 0.000000 0.000000 0.000000 0.166005
Yes 0.181969 0.000000 0.000000 0.158843
3 No 0.187735 0.000000 0.000000 0.084246
Yes 0.000000 0.000000 0.000000 0.204952
4 No 0.000000 0.000000 0.000000 0.138919
Yes 0.000000 0.000000 0.000000 0.155410
5 No 0.000000 0.000000 0.000000 0.121389
6 No 0.000000 0.000000 0.000000 0.173706
[21 rows x 4 columns]
pivot_table的参数说明请参见下表。
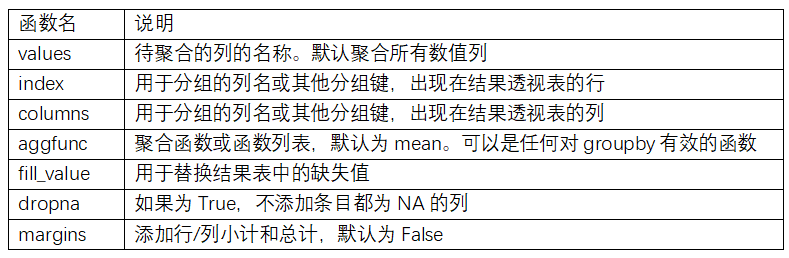
交叉表(cross-tabulation,简称crosstab)是一种用于计算分组频率的特殊透视表。看下面的例子:
data
Sample Nationality Handedness
0 1 USA Right-handed
1 2 Japan Left-handed
2 3 USA Right-handed
3 4 Japan Right-handed
4 5 Japan Left-handed
5 6 Japan Right-handed
6 7 USA Right-handed
7 8 USA Left-handed
8 9 Japan Right-handed
9 10 USA Right-handed
作为调查分析的一部分,我们可能想要根据国籍和用手习惯对这段数据进行统计汇总。虽然可以用pivot_table实现该功能,但是pandas.crosstab函数会更方便:
pd.crosstab(data.Nationality, data.Handedness, margins=True)
Handedness Left-handed Right-handed All
Nationality
Japan 2 3 5
USA 1 4 5
All 3 7 10
crosstab的前两个参数可以是数组或Series,或是数组列表。就像小费数据:
pd.crosstab([tips.time, tips.day], tips.smoker, margins=True)
smoker No Yes All
time day
Dinner Fri 3 9 12
Sat 45 42 87
Sun 57 19 76
Thur 1 0 1
Lunch Fri 1 6 7
Thur 44 17 61
All 151 93 244
时间序列
时间序列数据的意义取决于具体的应用场景,主要有以下几种:
- 时间戳(
timestamp),特定的时刻。 - 固定时期(
period),如2007年1月或2010年全年。 - 时间间隔(
interval),由起始和结束时间戳表示。时期(period)可以被看做间隔(interval)的特例。
许多技术都可用于处理实验型时间序列,其索引可能是一个整数或浮点数(表示从实验开始算起已经过去的时间)。最简单也最常见的时间序列都是用时间戳进行索引的。pandas也支持基于timedeltas的指数,它可以有效代表实验或经过的时间。
日期和时间数据类型及工具
Python标准库包含用于日期(date)和时间(time)数据的数据类型,而且还有日历方面的功能。我们主要会用到datetime、time以及calendar模块。datetime.datetime(也可以简写为datetime)是用得最多的数据类型:
from datetime import datetime
now = datetime.now()
now
datetime.datetime(2017, 9, 25, 14, 5, 52, 72973)
now.year, now.month, now.day
(2017, 9, 25)
datetime以毫秒形式存储日期和时间。timedelta表示两个datetime对象之间的时间差:
delta = datetime(2011, 1, 7) - datetime(2008, 6, 24, 8, 15)
delta
datetime.timedelta(926, 56700)
delta.days
926
delta.seconds
56700
可以给datetime对象加上(或减去)一个或多个timedelta,这样会产生一个新对象:
from datetime import timedelta
start = datetime(2011, 1, 7)
start + timedelta(12)
datetime.datetime(2011, 1, 19, 0, 0)
start - 2 * timedelta(12)
datetime.datetime(2010, 12, 14, 0, 0)
datetime模块中的数据类型参见下表。

字符串和datetime的相互转换
利用str或strftime方法(传入一个格式化字符串),datetime对象和pandas的Timestamp对象可以被格式化为字符串:
stamp = datetime(2011, 1, 3)
str(stamp)
'2011-01-03 00:00:00'
stamp.strftime('%Y-%m-%d')
'2011-01-03'

datetime.strptime可以用这些格式化编码将字符串转换为日期:
value = '2011-01-03'
datetime.strptime(value, '%Y-%m-%d')
datetime.datetime(2011, 1, 3, 0, 0)
datestrs = ['7/6/2011', '8/6/2011']
[datetime.strptime(x, '%m/%d/%Y') for x in datestrs]
[datetime.datetime(2011, 7, 6, 0, 0),
datetime.datetime(2011, 8, 6, 0, 0)]
datetime.strptime是通过已知格式进行日期解析的最佳方式。但是每次都要编写格式定义是很麻烦的事情,尤其是对于一些常见的日期格式。这种情况下,你可以用dateutil这个第三方包中的parser.parse方法(pandas中已经自动安装好了):
from dateutil.parser import parse
parse('2011-01-03')
datetime.datetime(2011, 1, 3, 0, 0)
dateutil可以解析几乎所有人类能够理解的日期表示形式:
parse('Jan 31, 1997 10:45 PM')
datetime.datetime(1997, 1, 31, 22, 45)
在国际通用的格式中,日出现在月的前面很普遍,传入dayfirst=True即可解决这个问题:
parse('6/12/2011', dayfirst=True)
datetime.datetime(2011, 12, 6, 0, 0)
pandas通常是用于处理成组日期的,不管这些日期是DataFrame的轴索引还是列。to_datetime方法可以解析多种不同的日期表示形式。对标准日期格式(如ISO8601)的解析非常快:
datestrs = ['2011-07-06 12:00:00', '2011-08-06 00:00:00']
pd.to_datetime(datestrs)
DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00'], dtype='datetime64[ns]', freq=None)
它还可以处理缺失值(None、空字符串等):
idx = pd.to_datetime(datestrs + [None])
idx
DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00', 'NaT'], dtype='datetime64[ns]', freq=None)
idx[2]
NaT
pd.isnull(idx)
array([False, False, True], dtype=bool)
NaT(Not a Time)是pandas中时间戳数据的null值。
注意:
dateutil.parser是一个实用但不完美的工具。比如说,它会把一些原本不是日期的字符串认作是日期(比如"42"会被解析为2042年的今天)。

时间序列基础
pandas最基本的时间序列类型就是以时间戳(通常以Python字符串或datatime对象表示)为索引的Series:
from datetime import datetime
dates = [datetime(2011, 1, 2), datetime(2011, 1, 5),datetime(2011, 1, 7), datetime(2011, 1, 8),datetime(2011, 1, 10), datetime(2011, 1, 12)]
ts = pd.Series(np.random.randn(6), index=dates)
ts
2011-01-02 -0.204708
2011-01-05 0.478943
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
2011-01-12 1.393406
dtype: float64
这些datetime对象实际上是被放在一个DatetimeIndex中的:
ts.index
DatetimeIndex(['2011-01-02', '2011-01-05', '2011-01-07', '2011-01-08',
'2011-01-10', '2011-01-12'],
dtype='datetime64[ns]', freq=None)
跟其他Series一样,不同索引的时间序列之间的算术运算会自动按日期对齐:
ts + ts[::2]
2011-01-02 -0.409415
2011-01-05 NaN
2011-01-07 -1.038877
2011-01-08 NaN
2011-01-10 3.931561
2011-01-12 NaN
dtype: float64
ts[::2] 是每隔两个取一个。
pandas用NumPy的datetime64数据类型以纳秒形式存储时间戳:
ts.index.dtype
dtype('<M8[ns]')
DatetimeIndex中的各个标量值是pandas的Timestamp对象:
stamp = ts.index[0]
stamp
Timestamp('2011-01-02 00:00:00')
只要有需要,TimeStamp可以随时自动转换为datetime对象。此外,它还可以存储频率信息(如果有的话)。
索引、选取、子集构造
当你根据标签索引选取数据时,时间序列和其它的pandas.Series很像:
stamp = ts.index[2]
ts[stamp]
-0.51943871505673811
还有一种更为方便的用法:传入一个可以被解释为日期的字符串:
ts['1/10/2011']
1.9657805725027142
ts['20110110']
1.9657805725027142
对于较长的时间序列,只需传入“年”或“年月”即可轻松选取数据的切片:
longer_ts = pd.Series(np.random.randn(1000),index=pd.date_range('1/1/2000', periods=1000))
longer_ts
2000-01-01 0.092908
2000-01-02 0.281746
2000-01-03 0.769023
2000-01-04 1.246435
2000-01-05 1.007189
2000-01-06 -1.296221
2000-01-07 0.274992
2000-01-08 0.228913
2000-01-09 1.352917
2000-01-10 0.886429
...
2002-09-17 -0.139298
2002-09-18 -1.159926
2002-09-19 0.618965
2002-09-20 1.373890
2002-09-21 -0.983505
2002-09-22 0.930944
2002-09-23 -0.811676
2002-09-24 -1.830156
2002-09-25 -0.138730
2002-09-26 0.334088
Freq: D, Length: 1000, dtype: float64
longer_ts['2001']
2001-01-01 1.599534
2001-01-02 0.474071
2001-01-03 0.151326
2001-01-04 -0.542173
2001-01-05 -0.475496
2001-01-06 0.106403
2001-01-07 -1.308228
2001-01-08 2.173185
2001-01-09 0.564561
2001-01-10 -0.190481
...
2001-12-22 0.000369
2001-12-23 0.900885
2001-12-24 -0.454869
2001-12-25 -0.864547
2001-12-26 1.129120
2001-12-27 0.057874
2001-12-28 -0.433739
2001-12-29 0.092698
2001-12-30 -1.397820
2001-12-31 1.457823
Freq: D, Length: 365, dtype: float64
这里,字符串“2001”被解释成年,并根据它选取时间区间。指定月也同样奏效:
longer_ts['2001-05']
2001-05-01 -0.622547
2001-05-02 0.936289
2001-05-03 0.750018
2001-05-04 -0.056715
2001-05-05 2.300675
2001-05-06 0.569497
2001-05-07 1.489410
2001-05-08 1.264250
2001-05-09 -0.761837
2001-05-10 -0.331617
...
2001-05-22 0.503699
2001-05-23 -1.387874
2001-05-24 0.204851
2001-05-25 0.603705
2001-05-26 0.545680
2001-05-27 0.235477
2001-05-28 0.111835
2001-05-29 -1.251504
2001-05-30 -2.949343
2001-05-31 0.634634
Freq: D, Length: 31, dtype: float64
datetime对象也可以进行切片:
ts[datetime(2011, 1, 7):]
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
2011-01-12 1.393406
dtype: float64
由于大部分时间序列数据都是按照时间先后排序的,因此你也可以用不存在于该时间序列中的时间戳对其进行切片(即范围查询):
ts
2011-01-02 -0.204708
2011-01-05 0.478943
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
2011-01-12 1.393406
dtype: float64
ts['1/6/2011':'1/11/2011']
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
dtype: float64
跟之前一样,你可以传入字符串日期、datetime或Timestamp。注意,这样切片所产生的是原时间序列的视图,跟NumPy数组的切片运算是一样的。
这意味着,没有数据被复制,对切片进行修改会反映到原始数据上。
此外,还有一个等价的实例方法也可以截取两个日期之间TimeSeries:
ts.truncate(after='1/9/2011')
2011-01-02 -0.204708
2011-01-05 0.478943
2011-01-07 -0.519439
2011-01-08 -0.555730
dtype: float64
面这些操作对DataFrame也有效。例如,对DataFrame的行进行索引:
dates = pd.date_range('1/1/2000', periods=100, freq='W-WED')
long_df = pd.DataFrame(np.random.randn(100, 4),index=dates,columns=['Colorado', 'Texas','New York', 'Ohio'])
long_df.loc['5-2001']
Colorado Texas New York Ohio
2001-05-02 -0.006045 0.490094 -0.277186 -0.707213
2001-05-09 -0.560107 2.735527 0.927335 1.513906
2001-05-16 0.538600 1.273768 0.667876 -0.969206
2001-05-23 1.676091 -0.817649 0.050188 1.951312
2001-05-30 3.260383 0.963301 1.201206 -1.852001
带有重复索引的时间序列
在某些应用场景中,可能会存在多个观测数据落在同一个时间点上的情况。下面就是一个例子:
dates = pd.DatetimeIndex(['1/1/2000', '1/2/2000', '1/2/2000','1/2/2000', '1/3/2000'])
dup_ts = pd.Series(np.arange(5), index=dates)
dup_ts
2000-01-01 0
2000-01-02 1
2000-01-02 2
2000-01-02 3
2000-01-03 4
dtype: int64
通过检查索引的is_unique属性,我们就可以知道它是不是唯一的:
dup_ts.index.is_unique
False
对这个时间序列进行索引,要么产生标量值,要么产生切片,具体要看所选的时间点是否重复:
dup_ts['1/3/2000'] # not duplicated
4
dup_ts['1/2/2000'] # duplicated
2000-01-02 1
2000-01-02 2
2000-01-02 3
dtype: int64
假设你想要对具有非唯一时间戳的数据进行聚合。一个办法是使用groupby,并传入level=0:
grouped = dup_ts.groupby(level=0)
grouped.mean()
2000-01-01 0
2000-01-02 2
2000-01-03 4
dtype: int64
grouped.count()
2000-01-01 1
2000-01-02 3
2000-01-03 1
dtype: int64
日期的范围、频率以及移动
pandas中的原生时间序列一般被认为是不规则的,也就是说,它们没有固定的频率。对于大部分应用程序而言,这是无所谓的。但是,它常常需要以某种相对固定的频率进行分析,比如每日、每月、每15分钟等(这样自然会在时间序列中引入缺失值)。幸运的是,pandas有一整套标准时间序列频率以及用于重采样、频率推断、生成固定频率日期范围的工具。例如,我们可以将之前那个时间序列转换为一个具有固定频率(每日)的时间序列,只需调用resample即可:
ts
2011-01-02 -0.204708
2011-01-05 0.478943
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
2011-01-12 1.393406
dtype: float64
resampler = ts.resample('D')
字符串“D”是每天的意思。
这里,我将告诉你如何使用基本的频率和它的倍数。
生成日期范围
虽然我之前用的时候没有明说,但你可能已经猜到pandas.date_range可用于根据指定的频率生成指定长度的DatetimeIndex:
index = pd.date_range('2012-04-01', '2012-06-01')
index
DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20',
'2012-04-21', '2012-04-22', '2012-04-23', '2012-04-24',
'2012-04-25', '2012-04-26', '2012-04-27', '2012-04-28',
'2012-04-29', '2012-04-30', '2012-05-01', '2012-05-02',
'2012-05-03', '2012-05-04', '2012-05-05', '2012-05-06',
'2012-05-07', '2012-05-08', '2012-05-09', '2012-05-10',
'2012-05-11', '2012-05-12', '2012-05-13', '2012-05-14',
'2012-05-15', '2012-05-16', '2012-05-17', '2012-05-18',
'2012-05-19', '2012-05-20', '2012-05-21', '2012-05-22',
'2012-05-23', '2012-05-24', '2012-05-25', '2012-05-26',
'2012-05-27', '2012-05-28', '2012-05-29', '2012-05-30',
'2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')
默认情况下,date_range会产生按天计算的时间点。如果只传入起始或结束日期,那就还得传入一个表示一段时间的数字:
pd.date_range(start='2012-04-01', periods=20)
DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20'],
dtype='datetime64[ns]', freq='D')
pd.date_range(end='2012-06-01', periods=20)
DatetimeIndex(['2012-05-13', '2012-05-14', '2012-05-15', '2012-05-16',
'2012-05-17', '2012-05-18', '2012-05-19', '2012-05-20',
'2012-05-21', '2012-05-22', '2012-05-23', '2012-05-24',
'2012-05-25', '2012-05-26', '2012-05-27','2012-05-28',
'2012-05-29', '2012-05-30', '2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')
起始和结束日期定义了日期索引的严格边界。例如,如果你想要生成一个由每月最后一个工作日组成的日期索引,可以传入"BM"频率(表示business end of month,下表是频率列表),这样就只会包含时间间隔内(或刚好在边界上的)符合频率要求的日期:
pd.date_range('2000-01-01', '2000-12-01', freq='BM')
DatetimeIndex(['2000-01-31', '2000-02-29', '2000-03-31', '2000-04-28',
'2000-05-31', '2000-06-30', '2000-07-31', '2000-08-31',
'2000-09-29', '2000-10-31', '2000-11-30'],
dtype='datetime64[ns]', freq='BM')
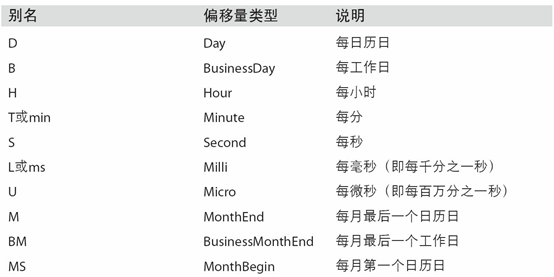
date_range默认会保留起始和结束时间戳的时间信息(如果有的话):
pd.date_range('2012-05-02 12:56:31', periods=5)
DatetimeIndex(['2012-05-02 12:56:31', '2012-05-03 12:56:31',
'2012-05-04 12:56:31', '2012-05-05 12:56:31',
'2012-05-06 12:56:31'],
dtype='datetime64[ns]', freq='D')
有时,虽然起始和结束日期带有时间信息,但你希望产生一组被规范化(normalize)到午夜的时间戳。normalize选项即可实现该功能:
pd.date_range('2012-05-02 12:56:31', periods=5, normalize=True)
DatetimeIndex(['2012-05-02', '2012-05-03', '2012-05-04', '2012-05-05',
'2012-05-06'],
dtype='datetime64[ns]', freq='D')
频率和日期偏移量
pandas中的频率是由一个基础频率(base frequency)和一个乘数组成的。基础频率通常以一个字符串别名表示,比如"M"表示每月,"H"表示每小时。对于每个基础频率,都有一个被称为日期偏移量(date offset)的对象与之对应。例如,按小时计算的频率可以用Hour类表示:
rom pandas.tseries.offsets import Hour, Minute
hour = Hour()
hour
<Hour>
传入一个整数即可定义偏移量的倍数:
four_hours = Hour(4)
four_hours
<4 * Hours>
一般来说,无需明确创建这样的对象,只需使用诸如"H"或"4H"这样的字符串别名即可。在基础频率前面放上一个整数即可创建倍数:
pd.date_range('2000-01-01', '2000-01-03 23:59', freq='4h')
DatetimeIndex(['2000-01-01 00:00:00', '2000-01-01 04:00:00',
'2000-01-01 08:00:00', '2000-01-01 12:00:00',
'2000-01-01 16:00:00', '2000-01-01 20:00:00',
'2000-01-02 00:00:00', '2000-01-02 04:00:00',
'2000-01-02 08:00:00', '2000-01-02 12:00:00',
'2000-01-02 16:00:00', '2000-01-02 20:00:00',
'2000-01-03 00:00:00', '2000-01-03 04:00:00',
'2000-01-03 08:00:00', '2000-01-03 12:00:00',
'2000-01-03 16:00:00', '2000-01-03 20:00:00'],
dtype='datetime64[ns]', freq='4H')
大部分偏移量对象都可通过加法进行连接:
Hour(2) + Minute(30)
<150 * Minutes>
同理,你也可以传入频率字符串(如"2h30min"),这种字符串可以被高效地解析为等效的表达式:
pd.date_range('2000-01-01', periods=10, freq='1h30min')
DatetimeIndex(['2000-01-01 00:00:00', '2000-01-01 01:30:00',
'2000-01-01 03:00:00', '2000-01-01 04:30:00',
'2000-01-01 06:00:00', '2000-01-01 07:30:00',
'2000-01-01 09:00:00', '2000-01-01 10:30:00',
'2000-01-01 12:00:00', '2000-01-01 13:30:00'],
dtype='datetime64[ns]', freq='90T')
有些频率所描述的时间点并不是均匀分隔的。例如,"M"(日历月末)和"BM"(每月最后一个工作日)就取决于每月的天数,对于后者,还要考虑月末是不是周末。由于没有更好的术语,我将这些称为锚点偏移量(anchored offset)。
下表列出了pandas中的频率代码和日期偏移量类。


笔记:用户可以根据实际需求自定义一些频率类以便提供pandas所没有的日期逻辑,但具体的细节超出了本书的范围。
WOM日期
WOM(Week Of Month)是一种非常实用的频率类,它以WOM开头。它使你能获得诸如“每月第3个星期五”之类的日期
rng = pd.date_range('2012-01-01', '2012-09-01', freq='WOM-3FRI')
list(rng)
[Timestamp('2012-01-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-02-17 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-03-16 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-04-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-05-18 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-06-15 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-07-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-08-17 00:00:00', freq='WOM-3FRI')]
移动(超前和滞后)数据
移动(shifting)指的是沿着时间轴将数据前移或后移。Series和DataFrame都有一个shift方法用于执行单纯的前移或后移操作,保持索引不变:
ts = pd.Series(np.random.randn(4),index=pd.date_range('1/1/2000', periods=4, freq='M'))
ts
2000-01-31 -0.066748
2000-02-29 0.838639
2000-03-31 -0.117388
2000-04-30 -0.517795
Freq: M, dtype: float64
ts.shift(2)
2000-01-31 NaN
2000-02-29 NaN
2000-03-31 -0.066748
2000-04-30 0.838639
Freq: M, dtype: float64
ts.shift(-2)
2000-01-31 -0.117388
2000-02-29 -0.517795
2000-03-31 NaN
2000-04-30 NaN
Freq: M, dtype: float64
当我们这样进行移动时,就会在时间序列的前面或后面产生缺失数据。
shift通常用于计算一个时间序列或多个时间序列(如DataFrame的列)中的百分比变化。可以这样表达:
ts / ts.shift(1) - 1
由于单纯的移位操作不会修改索引,所以部分数据会被丢弃。因此,如果频率已知,则可以将其传给shift以便实现对时间戳进行位移而不是对数据进行简单位移:
ts.shift(2, freq='M')
2000-03-31 -0.066748
2000-04-30 0.838639
2000-05-31 -0.117388
2000-06-30 -0.517795
Freq: M, dtype: float64
这里还可以使用其他频率,于是你就能非常灵活地对数据进行超前和滞后处理了:
ts.shift(3, freq='D')
2000-02-03 -0.066748
2000-03-03 0.838639
2000-04-03 -0.117388
2000-05-03 -0.517795
dtype: float64
ts.shift(1, freq='90T')
2000-01-31 01:30:00 -0.066748
2000-02-29 01:30:00 0.838639
2000-03-31 01:30:00 -0.117388
2000-04-30 01:30:00 -0.517795
Freq: M, dtype: float64
通过偏移量对日期进行位移
pandas的日期偏移量还可以用在datetime或Timestamp对象上:
from pandas.tseries.offsets import Day, MonthEnd
now = datetime(2011, 11, 17)
now + 3 * Day()
Timestamp('2011-11-20 00:00:00')
如果加的是锚点偏移量(比如MonthEnd),第一次增量会将原日期向前滚动到符合频率规则的下一个日期:
now + MonthEnd()
Timestamp('2011-11-30 00:00:00')
now + MonthEnd(2)
Timestamp('2011-12-31 00:00:00')
通过锚点偏移量的rollforward和rollback方法,可明确地将日期向前或向后“滚动”:
offset = MonthEnd()
offset.rollforward(now)
Timestamp('2011-11-30 00:00:00')
offset.rollback(now)
Timestamp('2011-10-31 00:00:00')
日期偏移量还有一个巧妙的用法,即结合groupby使用这两个“滚动”方法:
ts = pd.Series(np.random.randn(20),index=pd.date_range('1/15/2000', periods=20, freq='4d'))
ts
2000-01-15 -0.116696
2000-01-19 2.389645
2000-01-23 -0.932454
2000-01-27 -0.229331
2000-01-31 -1.140330
2000-02-04 0.439920
2000-02-08 -0.823758
2000-02-12 -0.520930
2000-02-16 0.350282
2000-02-20 0.204395
2000-02-24 0.133445
2000-02-28 0.327905
2000-03-03 0.072153
2000-03-07 0.131678
2000-03-11 -1.297459
2000-03-15 0.997747
2000-03-19 0.870955
2000-03-23 -0.991253
2000-03-27 0.151699
2000-03-31 1.266151
Freq: 4D, dtype: float64
ts.groupby(offset.rollforward).mean()
2000-01-31 -0.005833
2000-02-29 0.015894
2000-03-31 0.150209
dtype: float64
当然,更简单、更快速地实现该功能的办法是使用resample:
ts.resample('M').mean()
2000-01-31 -0.005833
2000-02-29 0.015894
2000-03-31 0.150209
Freq: M, dtype: float64
时期及其算术运算
时期(period)表示的是时间区间,比如数日、数月、数季、数年等。Period类所表示的就是这种数据类型,其构造函数需要用到一个字符串或整数,以及频率:
p = pd.Period(2007, freq='A-DEC')
p
Period('2007', 'A-DEC')
这里,这个Period对象表示的是从2007年1月1日到2007年12月31日之间的整段时间。只需对Period对象加上或减去一个整数即可达到根据其频率进行位移的效果:
p + 5
Period('2012', 'A-DEC')
p - 2
Period('2005', 'A-DEC')
如果两个Period对象拥有相同的频率,则它们的差就是它们之间的单位数量:
pd.Period('2014', freq='A-DEC') - p
7
period_range函数可用于创建规则的时期范围:
rng = pd.period_range('2000-01-01', '2000-06-30', freq='M')
rng
PeriodIndex(['2000-01', '2000-02', '2000-03', '2000-04', '2000-05', '20
00-06'], dtype='period[M]', freq='M')
PeriodIndex类保存了一组Period,它可以在任何pandas数据结构中被用作轴索引:
pd.Series(np.random.randn(6), index=rng)
2000-01 -0.514551
2000-02 -0.559782
2000-03 -0.783408
2000-04 -1.797685
2000-05 -0.172670
2000-06 0.680215
Freq: M, dtype: float64
如果你有一个字符串数组,你也可以使用PeriodIndex类:
values = ['2001Q3', '2002Q2', '2003Q1']
index = pd.PeriodIndex(values, freq='Q-DEC')
index
PeriodIndex(['2001Q3', '2002Q2', '2003Q1'], dtype='period[Q-DEC]', freq
='Q-DEC')
时期的频率转换
Period和PeriodIndex对象都可以通过其asfreq方法被转换成别的频率。假设我们有一个年度时期,希望将其转换为当年年初或年末的一个月度时期。该任务非常简单:
p = pd.Period('2007', freq='A-DEC')
p
Period('2007', 'A-DEC')
p.asfreq('M', how='start')
Period('2007-01', 'M')
p.asfreq('M', how='end')
Period('2007-12', 'M')
你可以将Period('2007','A-DEC')看做一个被划分为多个月度时期的时间段中的游标。对于一个不以12月结束的财政年度,月度子时期的归属情况就不一样了:
p = pd.Period('2007', freq='A-JUN')
p
Period('2007', 'A-JUN')
p.asfreq('M', 'start')
Period('2006-07', 'M')
p.asfreq('M', 'end')
Period('2007-06', 'M')
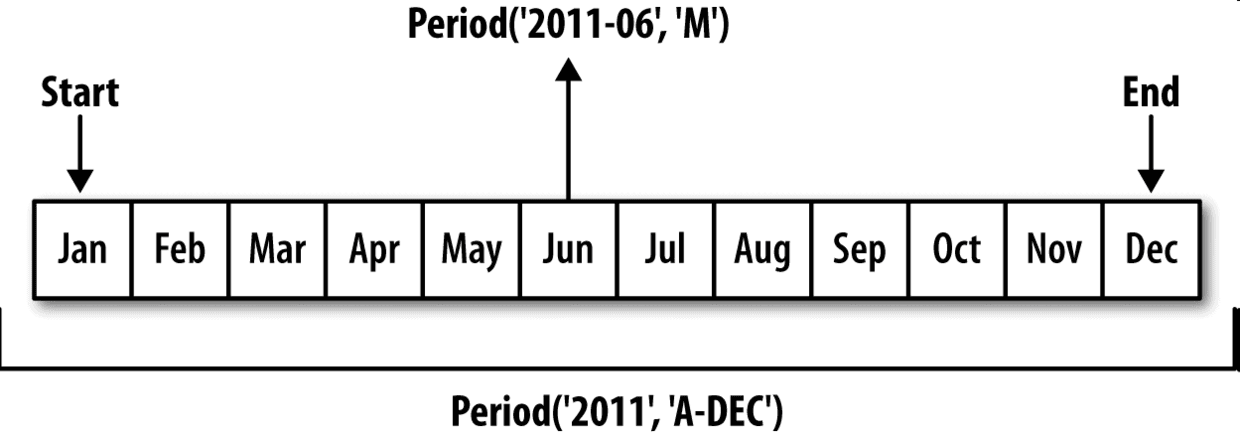
在将高频率转换为低频率时,超时期(superperiod)是由子时期(subperiod)所属的位置决定的。例如,在A-JUN频率中,月份“2007年8月”实际上是属于周期“2008年”的:
p = pd.Period('Aug-2007', 'M')
p.asfreq('A-JUN')
Period('2008', 'A-JUN')
完整的PeriodIndex或TimeSeries的频率转换方式也是如此:
rng = pd.period_range('2006', '2009', freq='A-DEC')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts
2006 1.607578
2007 0.200381
2008 -0.834068
2009 -0.302988
Freq: A-DEC, dtype: float64
ts.asfreq('M', how='start')
2006-01 1.607578
2007-01 0.200381
2008-01 -0.834068
2009-01 -0.302988
Freq: M, dtype: float64
这里,根据年度时期的第一个月,每年的时期被取代为每月的时期。如果我们想要每年的最后一个工作日,我们可以使用“B”频率,并指明想要该时期的末尾:
ts.asfreq('B', how='end')
2006-12-29 1.607578
2007-12-31 0.200381
2008-12-31 -0.834068
2009-12-31 -0.302988
Freq: B, dtype: float64
按季度计算的时期频率
季度型数据在会计、金融等领域中很常见。许多季度型数据都会涉及“财年末”的概念,通常是一年12个月中某月的最后一个日历日或工作日。就这一点来说,时期"2012Q4"根据财年末的不同会有不同的含义。pandas支持12种可能的季度型频率,即Q-JAN到Q-DEC:
p = pd.Period('2012Q4', freq='Q-JAN')
p
Period('2012Q4', 'Q-JAN')
在以1月结束的财年中,2012Q4是从11月到1月(将其转换为日型频率就明白了)。
p.asfreq('D', 'start')
Period('2011-11-01', 'D')
p.asfreq('D', 'end')
Period('2012-01-31', 'D')
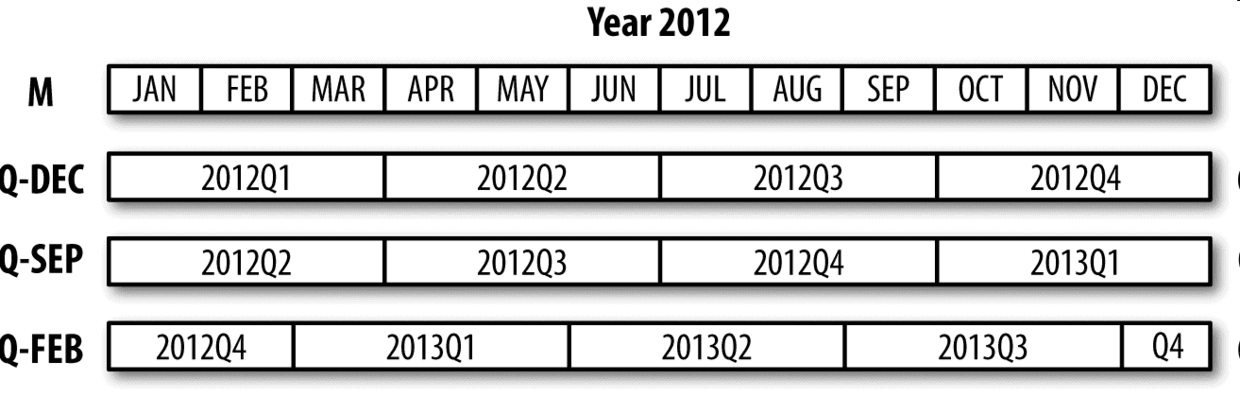
因此,Period之间的算术运算会非常简单。例如,要获取该季度倒数第二个工作日下午4点的时间戳,你可以这样:
p4pm = (p.asfreq('B', 'e') - 1).asfreq('T', 's') + 16 * 60
p4pm
Period('2012-01-30 16:00', 'T')
p4pm.to_timestamp()
Timestamp('2012-01-30 16:00:00')
period_range可用于生成季度型范围。季度型范围的算术运算也跟上面是一样的:
rng = pd.period_range('2011Q3', '2012Q4', freq='Q-JAN')
ts = pd.Series(np.arange(len(rng)), index=rng)
ts
2011Q3 0
2011Q4 1
2012Q1 2
2012Q2 3
2012Q3 4
2012Q4 5
Freq: Q-JAN, dtype: int64
new_rng = (rng.asfreq('B', 'e') - 1).asfreq('T', 's') + 16 * 60
ts.index = new_rng.to_timestamp()
ts
2010-10-28 16:00:00 0
2011-01-28 16:00:00 1
2011-04-28 16:00:00 2
2011-07-28 16:00:00 3
2011-10-28 16:00:00 4
2012-01-30 16:00:00 5
dtype: int64
将Timestamp转换为Period(及其反向过程)
通过使用to_period方法,可以将由时间戳索引的Series和DataFrame对象转换为以时期索引:
rng = pd.date_range('2000-01-01', periods=3, freq='M')
ts = pd.Series(np.random.randn(3), index=rng)
ts
2000-01-31 1.663261
2000-02-29 -0.996206
2000-03-31 1.521760
Freq: M, dtype: float64
pts = ts.to_period()
pts
2000-01 1.663261
2000-02 -0.996206
2000-03 1.521760
Freq: M, dtype: float64
由于时期指的是非重叠时间区间,因此对于给定的频率,一个时间戳只能属于一个时期。新PeriodIndex的频率默认是从时间戳推断而来的,你也可以指定任何别的频率。结果中允许存在重复时期:
rng = pd.date_range('1/29/2000', periods=6, freq='D')
ts2 = pd.Series(np.random.randn(6), index=rng)
ts2
2000-01-29 0.244175
2000-01-30 0.423331
2000-01-31 -0.654040
2000-02-01 2.089154
2000-02-02 -0.060220
2000-02-03 -0.167933
Freq: D, dtype: float64
ts2.to_period('M')
2000-01 0.244175
2000-01 0.423331
2000-01 -0.654040
2000-02 2.089154
2000-02 -0.060220
2000-02 -0.167933
Freq: M, dtype: float64
要转换回时间戳,使用to_timestamp即可:
pts = ts2.to_period()
pts
2000-01-29 0.244175
2000-01-30 0.423331
2000-01-31 -0.654040
2000-02-01 2.089154
2000-02-02 -0.060220
2000-02-03 -0.167933
Freq: D, dtype: float64
pts.to_timestamp(how='end')
2000-01-29 0.244175
2000-01-30 0.423331
2000-01-31 -0.654040
2000-02-01 2.089154
2000-02-02 -0.060220
2000-02-03 -0.167933
Freq: D, dtype: float64
通过数组创建PeriodIndex
固定频率的数据集通常会将时间信息分开存放在多个列中。例如,在下面这个宏观经济数据集中,年度和季度就分别存放在不同的列中:
data = pd.read_csv('examples/macrodata.csv')
data.head(5)
year quarter realgdp realcons realinv realgovt realdpi cpi \
0 1959.0 1.0 2710.349 1707.4 286.898 470.045 1886.9 28.98
1 1959.0 2.0 2778.801 1733.7 310.859 481.301 1919.7 29.15
2 1959.0 3.0 2775.488 1751.8 289.226 491.260 1916.4 29.35
3 1959.0 4.0 2785.204 1753.7 299.356 484.052 1931.3 29.37
4 1960.0 1.0 2847.699 1770.5 331.722 462.199 1955.5 29.54
m1 tbilrate unemp pop infl realint
0 139.7 2.82 5.8 177.146 0.00 0.00
1 141.7 3.08 5.1 177.830 2.34 0.74
2 140.5 3.82 5.3 178.657 2.74 1.09
3 140.0 4.33 5.6 179.386 0.27 4.06
4 139.6 3.50 5.2 180.007 2.31 1.19
data.year
0 1959.0
1 1959.0
2 1959.0
3 1959.0
4 1960.0
5 1960.0
6 1960.0
7 1960.0
8 1961.0
9 1961.0
...
193 2007.0
194 2007.0
195 2007.0
196 2008.0
197 2008.0
198 2008.0
199 2008.0
200 2009.0
201 2009.0
202 2009.0
Name: year, Length: 203, dtype: float64
data.quarter
0 1.0
1 2.0
2 3.0
3 4.0
4 1.0
5 2.0
6 3.0
7 4.0
8 1.0
9 2.0
...
193 2.0
194 3.0
195 4.0
196 1.0
197 2.0
198 3.0
199 4.0
200 1.0
201 2.0
202 3.0
Name: quarter, Length: 203, dtype: float64
通过将这些数组以及一个频率传入PeriodIndex,就可以将它们合并成DataFrame的一个索引:
index = pd.PeriodIndex(year=data.year, quarter=data.quarter,freq='Q-DEC')
index
PeriodIndex(['1959Q1', '1959Q2', '1959Q3', '1959Q4', '1960Q1', '1960Q2',
'1960Q3', '1960Q4', '1961Q1', '1961Q2',
...
'2007Q2', '2007Q3', '2007Q4', '2008Q1', '2008Q2', '2008Q3',
'2008Q4', '2009Q1', '2009Q2', '2009Q3'],
dtype='period[Q-DEC]', length=203, freq='Q-DEC')
data.index = index
data.infl
1959Q1 0.00
1959Q2 2.34
1959Q3 2.74
1959Q4 0.27
1960Q1 2.31
1960Q2 0.14
1960Q3 2.70
1960Q4 1.21
1961Q1 -0.40
1961Q2 1.47
...
2007Q2 2.75
2007Q3 3.45
2007Q4 6.38
2008Q1 2.82
2008Q2 8.53
2008Q3 -3.16
2008Q4 -8.79
2009Q1 0.94
2009Q2 3.37
2009Q3 3.56
Freq: Q-DEC, Name: infl, Length: 203, dtype: float64
重采样及频率转换
重采样(resampling)指的是将时间序列从一个频率转换到另一个频率的处理过程。将高频率数据聚合到低频率称为降采样(downsampling),而将低频率数据转换到高频率则称为升采样(upsampling)。并不是所有的重采样都能被划分到这两个大类中。例如,将W-WED(每周三)转换为W-FRI既不是降采样也不是升采样。
pandas对象都带有一个resample方法,它是各种频率转换工作的主力函数。resample有一个类似于groupby的API,调用resample可以分组数据,然后会调用一个聚合函数:
rng = pd.date_range('2000-01-01', periods=100, freq='D')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts
2000-01-01 0.631634
2000-01-02 -1.594313
2000-01-03 -1.519937
2000-01-04 1.108752
2000-01-05 1.255853
2000-01-06 -0.024330
2000-01-07 -2.047939
2000-01-08 -0.272657
2000-01-09 -1.692615
2000-01-10 1.423830
...
2000-03-31 -0.007852
2000-04-01 -1.638806
2000-04-02 1.401227
2000-04-03 1.758539
2000-04-04 0.628932
2000-04-05 -0.423776
2000-04-06 0.789740
2000-04-07 0.937568
2000-04-08 -2.253294
2000-04-09 -1.772919
Freq: D, Length: 100, dtype: float64
ts.resample('M').mean()
2000-01-31 -0.165893
2000-02-29 0.078606
2000-03-31 0.223811
2000-04-30 -0.063643
Freq: M, dtype: float64
ts.resample('M', kind='period').mean()
2000-01 -0.165893
2000-02 0.078606
2000-03 0.223811
2000-04 -0.063643
Freq: M, dtype: float64
resample是一个灵活高效的方法,可用于处理非常大的时间序列。
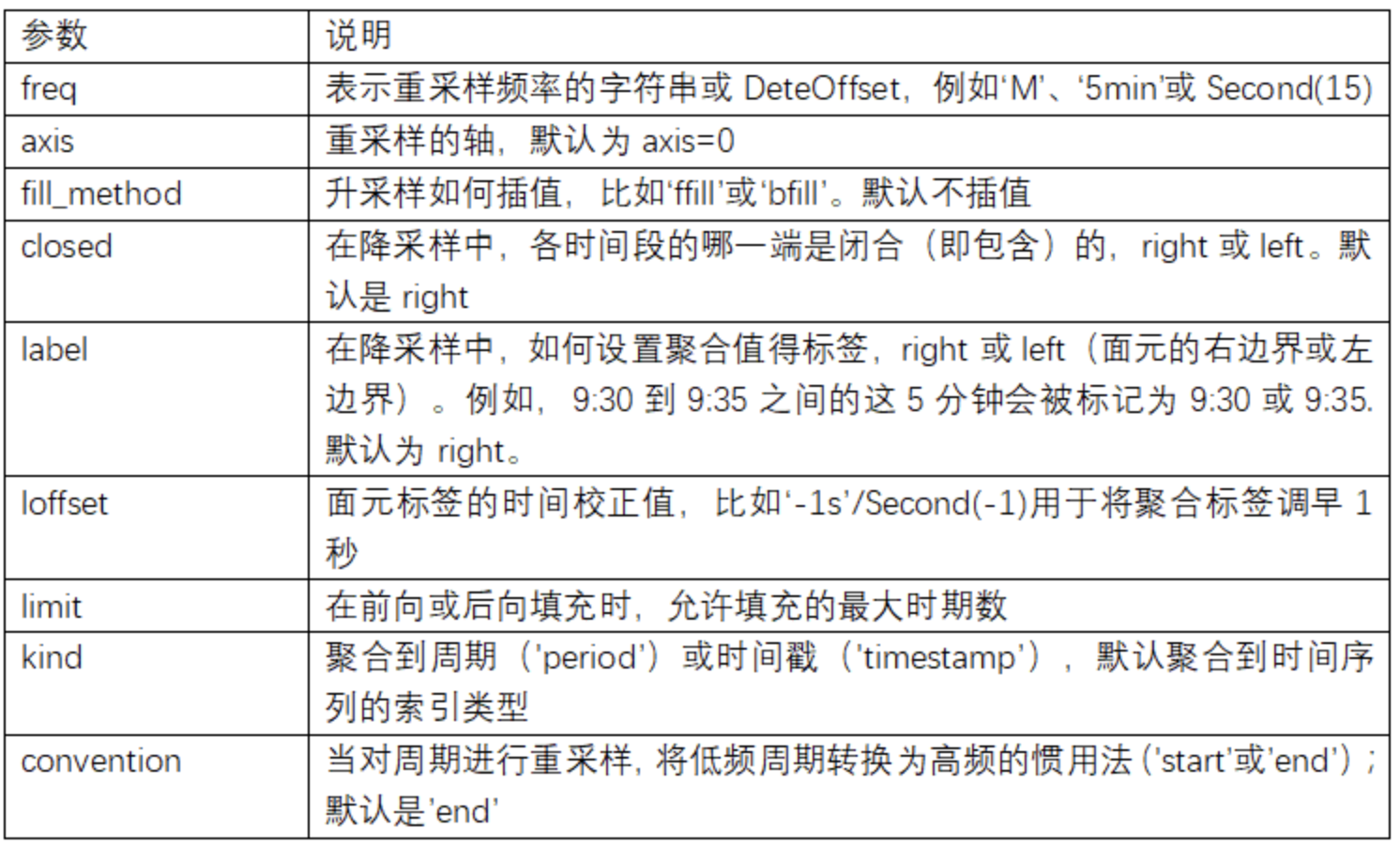
降采样
将数据聚合到规律的低频率是一件非常普通的时间序列处理任务。待聚合的数据不必拥有固定的频率,期望的频率会自动定义聚合的面元边界,这些面元用于将时间序列拆分为多个片段。例如,要转换到月度频率('M'或'BM'),数据需要被划分到多个单月时间段中。各时间段都是半开放的。一个数据点只能属于一个时间段,所有时间段的并集必须能组成整个时间帧。在用resample对数据进行降采样时,需要考虑两样东西:
- 各区间哪边是闭合的。
- 如何标记各个聚合面元,用区间的开头还是末尾。
为了说明,我们来看一些“1分钟”数据:
rng = pd.date_range('2000-01-01', periods=12, freq='T')
ts = pd.Series(np.arange(12), index=rng)
ts
2000-01-01 00:00:00 0
2000-01-01 00:01:00 1
2000-01-01 00:02:00 2
2000-01-01 00:03:00 3
2000-01-01 00:04:00 4
2000-01-01 00:05:00 5
2000-01-01 00:06:00 6
2000-01-01 00:07:00 7
2000-01-01 00:08:00 8
2000-01-01 00:09:00 9
2000-01-01 00:10:00 10
2000-01-01 00:11:00 11
Freq: T, dtype: int64
假设你想要通过求和的方式将这些数据聚合到“5分钟”块中:
ts.resample('5min', closed='right').sum()
1999-12-31 23:55:00 0
2000-01-01 00:00:00 15
2000-01-01 00:05:00 40
2000-01-01 00:10:00 11
Freq: 5T, dtype: int64
传入的频率将会以“5分钟”的增量定义面元边界。默认情况下,面元的右边界是包含的,因此00:00到00:05的区间中是包含00:05的。传入closed='left'会让区间以左边界闭合:
ts.resample('5min', closed='right').sum()
1999-12-31 23:55:00 0
2000-01-01 00:00:00 15
2000-01-01 00:05:00 40
2000-01-01 00:10:00 11
Freq: 5T, dtype: int64
如你所见,最终的时间序列是以各面元右边界的时间戳进行标记的。传入label='right'即可用面元的邮编界对其进行标记:
ts.resample('5min', closed='right', label='right').sum()
2000-01-01 00:00:00 0
2000-01-01 00:05:00 15
2000-01-01 00:10:00 40
2000-01-01 00:15:00 11
Freq: 5T, dtype: int64
下图说明了“1分钟”数据被转换为“5分钟”数据的处理过程。
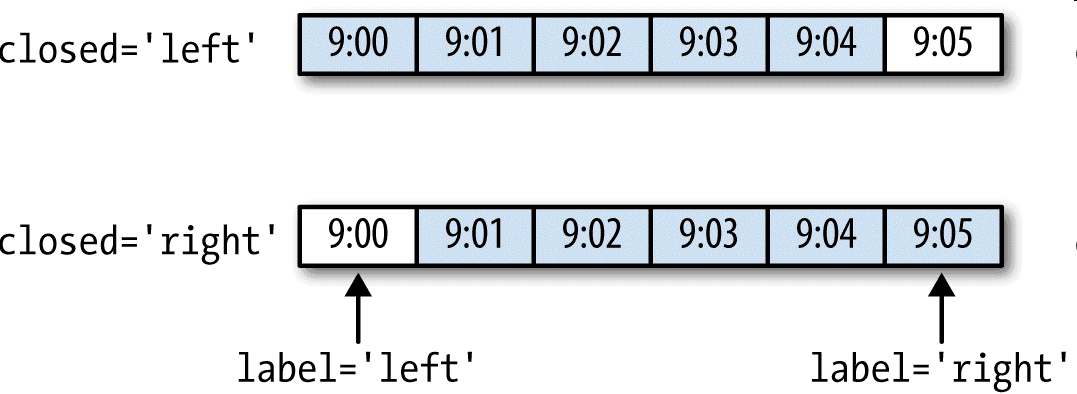
最后,你可能希望对结果索引做一些位移,比如从右边界减去一秒以便更容易明白该时间戳到底表示的是哪个区间。只需通过loffset设置一个字符串或日期偏移量即可实现这个目的:
ts.resample('5min', closed='right',label='right', loffset='-1s').sum()
1999-12-31 23:59:59 0
2000-01-01 00:04:59 15
ts.resample('5min', closed='right',label='right', loffset='-1s').sum()
1999-12-31 23:59:59 0
2000-01-01 00:04:59 15
此外,也可以通过调用结果对象的shift方法来实现该目的,这样就不需要设置loffset了。
OHLC重采样
金融领域中有一种无所不在的时间序列聚合方式,即计算各面元的四个值:第一个值(open,开盘)、最后一个值(close,收盘)、最大值(high,最高)以及最小值(low,最低)。传入how='ohlc'即可得到一个含有这四种聚合值的DataFrame。整个过程很高效,只需一次扫描即可计算出结果:
ts.resample('5min').ohlc()
open high low close
2000-01-01 00:00:00 0 4 0 4
2000-01-01 00:05:00 5 9 5 9
2000-01-01 00:10:00 10 11 10 11
升采样和插值
在将数据从低频率转换到高频率时,就不需要聚合了。我们来看一个带有一些周型数据的DataFrame:
frame = pd.DataFrame(np.random.randn(2, 4),index=pd.date_range('1/1/2000', periods=2,freq='W-WED'),columns=['Colorado', 'Texas', 'New York', 'Ohio'])
frame
Colorado Texas New York Ohio
2000-01-05 -0.896431 0.677263 0.036503 0.087102
2000-01-12 -0.046662 0.927238 0.482284 -0.867130
当你对这个数据进行聚合,每组只有一个值,这样就会引入缺失值。我们使用asfreq方法转换成高频,不经过聚合:
df_daily = frame.resample('D').asfreq()
df_daily
Colorado Texas New York Ohio
2000-01-05 -0.896431 0.677263 0.036503 0.087102
2000-01-06 NaN NaN NaN NaN
2000-01-07 NaN NaN NaN NaN
2000-01-08 NaN NaN NaN NaN
2000-01-09 NaN NaN NaN NaN
2000-01-10 NaN NaN NaN NaN
2000-01-11 NaN NaN NaN NaN
2000-01-12 -0.046662 0.927238 0.482284 -0.867130
假设你想要用前面的周型值填充“非星期三”。resampling的填充和插值方式跟fillna和reindex的一样:
frame.resample('D').ffill()
Colorado Texas New York Ohio
2000-01-05 -0.896431 0.677263 0.036503 0.087102
2000-01-06 -0.896431 0.677263 0.036503 0.087102
2000-01-07 -0.896431 0.677263 0.036503 0.087102
2000-01-08 -0.896431 0.677263 0.036503 0.087102
2000-01-09 -0.896431 0.677263 0.036503 0.087102
2000-01-10 -0.896431 0.677263 0.036503 0.087102
2000-01-11 -0.896431 0.677263 0.036503 0.087102
2000-01-12 -0.046662 0.927238 0.482284 -0.867130
同样,这里也可以只填充指定的时期数(目的是限制前面的观测值的持续使用距离):
frame.resample('D').ffill(limit=2)
Colorado Texas New York Ohio
2000-01-05 -0.896431 0.677263 0.036503 0.087102
2000-01-06 -0.896431 0.677263 0.036503 0.087102
2000-01-07 -0.896431 0.677263 0.036503 0.087102
2000-01-08 NaN NaN NaN NaN
2000-01-09 NaN NaN NaN NaN
2000-01-10 NaN NaN NaN NaN
2000-01-11 NaN NaN NaN NaN
2000-01-12 -0.046662 0.927238 0.482284 -0.867130
注意,新的日期索引完全没必要跟旧的重叠:
frame.resample('W-THU').ffill()
Colorado Texas New York Ohio
2000-01-06 -0.896431 0.677263 0.036503 0.087102
2000-01-13 -0.046662 0.927238 0.482284 -0.867130
通过时期进行重采样
对那些使用时期索引的数据进行重采样与时间戳很像:
frame = pd.DataFrame(np.random.randn(24, 4),index=pd.period_range('1-2000', '12-2001',freq='M'),columns=['Colorado', 'Texas', 'New York', 'Ohio'])
frame[:5]
Colorado Texas New York Ohio
2000-01 0.493841 -0.155434 1.397286 1.507055
2000-02 -1.179442 0.443171 1.395676 -0.529658
2000-03 0.787358 0.248845 0.743239 1.267746
2000-04 1.302395 -0.272154 -0.051532 -0.467740
2000-05 -1.040816 0.426419 0.312945 -1.115689
annual_frame = frame.resample('A-DEC').mean()
annual_frame
Colorado Texas New York Ohio
2000 0.556703 0.016631 0.111873 -0.027445
2001 0.046303 0.163344 0.251503 -0.157276
升采样要稍微麻烦一些,因为你必须决定在新频率中各区间的哪端用于放置原来的值,就像asfreq方法那样。convention参数默认为'start',也可设置为'end':
#Q-DEC: Quarterly, year ending in December
annual_frame.resample('Q-DEC').ffill()
Colorado Texas New York Ohio
2000Q1 0.556703 0.016631 0.111873 -0.027445
2000Q2 0.556703 0.016631 0.111873 -0.027445
2000Q3 0.556703 0.016631 0.111873 -0.027445
2000Q4 0.556703 0.016631 0.111873 -0.027445
2001Q1 0.046303 0.163344 0.251503 -0.157276
2001Q2 0.046303 0.163344 0.251503 -0.157276
2001Q3 0.046303 0.163344 0.251503 -0.157276
2001Q4 0.046303 0.163344 0.251503 -0.157276
annual_frame.resample('Q-DEC', convention='end').ffill()
Colorado Texas New York Ohio
2000Q4 0.556703 0.016631 0.111873 -0.027445
2001Q1 0.556703 0.016631 0.111873 -0.027445
2001Q2 0.556703 0.016631 0.111873 -0.027445
2001Q3 0.556703 0.016631 0.111873 -0.027445
2001Q4 0.046303 0.163344 0.251503 -0.157276
由于时期指的是时间区间,所以升采样和降采样的规则就比较严格:
- 在降采样中,目标频率必须是源频率的子时期(
subperiod)。 - 在升采样中,目标频率必须是源频率的超时期(
superperiod)。
如果不满足这些条件,就会引发异常。这主要影响的是按季、年、周计算的频率。例如,由Q-MAR定义的时间区间只能升采样为A-MAR、A-JUN、A-SEP、A-DEC等:
annual_frame.resample('Q-MAR').ffill()
Colorado Texas New York Ohio
2000Q4 0.556703 0.016631 0.111873 -0.027445
2001Q1 0.556703 0.016631 0.111873 -0.027445
2001Q2 0.556703 0.016631 0.111873 -0.027445
2001Q3 0.556703 0.016631 0.111873 -0.027445
2001Q4 0.046303 0.163344 0.251503 -0.157276
2002Q1 0.046303 0.163344 0.251503 -0.157276
2002Q2 0.046303 0.163344 0.251503 -0.157276
2002Q3 0.046303 0.163344 0.251503 -0.157276
移动窗口函数
在移动窗口(可以带有指数衰减权数)上计算的各种统计函数也是一类常见于时间序列的数组变换。这样可以圆滑噪音数据或断裂数据。我将它们称为移动窗口函数(moving window function),其中还包括那些窗口不定长的函数(如指数加权移动平均)。跟其他统计函数一样,移动窗口函数也会自动排除缺失值。
开始之前,我们加载一些时间序列数据,将其重采样为工作日频率:
close_px_all = pd.read_csv('examples/stock_px_2.csv',parse_dates=True, index_col=0)
close_px = close_px_all[['AAPL', 'MSFT', 'XOM']]
close_px = close_px.resample('B').ffill()
现在引入rolling运算符,它与resample和groupby很像。可以在TimeSeries或DataFrame以及一个window(表示期数,见下图)上调用它:
close_px.AAPL.plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7f2f2570cf98>
close_px.AAPL.rolling(250).mean().plot()
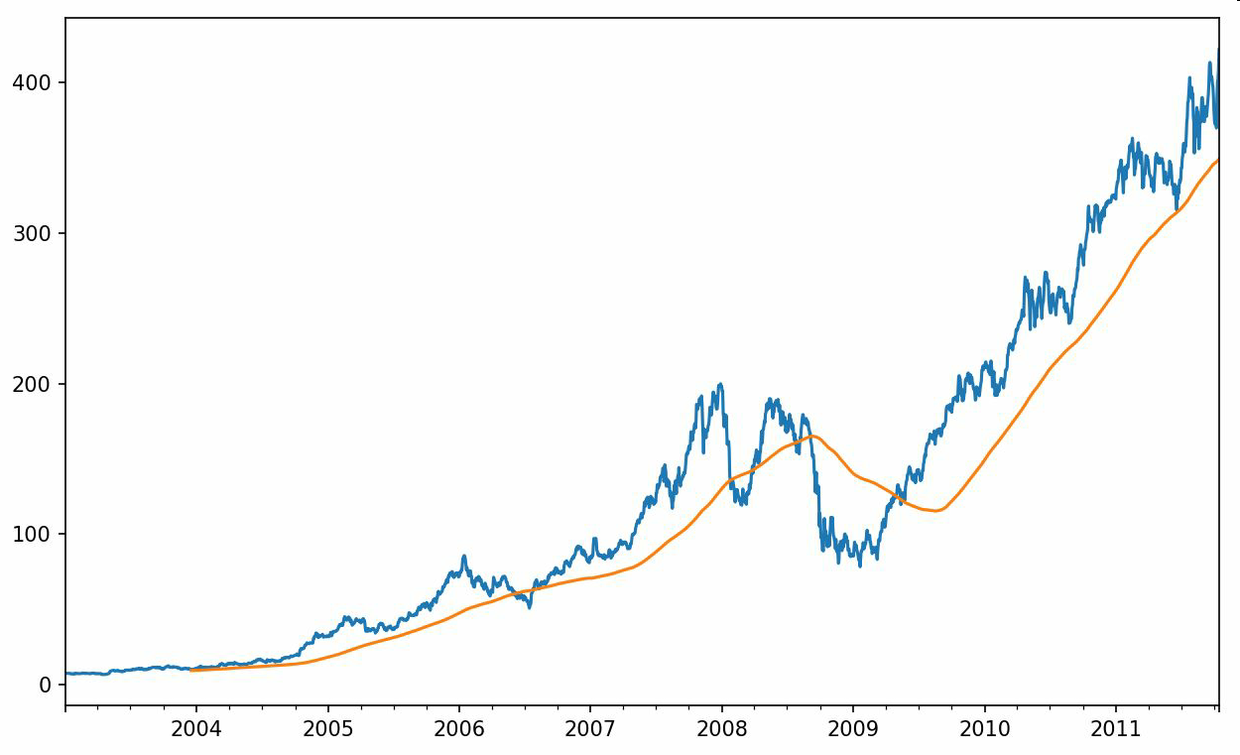
表达式rolling(250)与groupby很像,但不是对其进行分组,而是创建一个按照250天分组的滑动窗口对象。然后,我们就得到了苹果公司股价的250天的移动窗口。
默认情况下,rolling函数需要窗口中所有的值为非NA值。可以修改该行为以解决缺失数据的问题。其实,在时间序列开始处尚不足窗口期的那些数据就是个特例(见下图):
appl_std250 = close_px.AAPL.rolling(250, min_periods=10).std()
appl_std250[5:12]
2003-01-09 NaN
2003-01-10 NaN
2003-01-13 NaN
2003-01-14 NaN
2003-01-15 0.077496
2003-01-16 0.074760
2003-01-17 0.112368
Freq: B, Name: AAPL, dtype: float64
appl_std250.plot()
要计算扩展窗口平均(expanding window mean),可以使用expanding而不是rolling。“扩展”意味着,从时间序列的起始处开始窗口,增加窗口直到它超过所有的序列。apple_std250时间序列的扩展窗口平均如下所示:
expanding_mean = appl_std250.expanding().mean()
对DataFrame调用rolling_mean(以及与之类似的函数)会将转换应用到所有的列上(见下图):
close_px.rolling(60).mean().plot(logy=True)
rolling函数也可以接受一个指定固定大小时间补偿字符串,而不是一组时期。这样可以方便处理不规律的时间序列。这些字符串也可以传递给resample。例如,我们可以计算20天的滚动均值,如下所示:
close_px.rolling('20D').mean()
AAPL MSFT XOM
2003-01-02 7.400000 21.110000 29.220000
2003-01-03 7.425000 21.125000 29.230000
2003-01-06 7.433333 21.256667 29.473333
2003-01-07 7.432500 21.425000 29.342500
2003-01-08 7.402000 21.402000 29.240000
2003-01-09 7.391667 21.490000 29.273333
2003-01-10 7.387143 21.558571 29.238571
2003-01-13 7.378750 21.633750 29.197500
2003-01-14 7.370000 21.717778 29.194444
2003-01-15 7.355000 21.757000 29.152000
... ... ... ...
2011-10-03 398.002143 25.890714 72.413571
2011-10-04 396.802143 25.807857 72.427143
2011-10-05 395.751429 25.729286 72.422857
2011-10-06 394.099286 25.673571 72.375714
2011-10-07 392.479333 25.712000 72.454667
2011-10-10 389.351429 25.602143 72.527857
2011-10-11 388.505000 25.674286 72.835000
2011-10-12 388.531429 25.810000 73.400714
2011-10-13 388.826429 25.961429 73.905000
2011-10-14 391.038000 26.048667 74.185333
[2292 rows x 3 columns]
指数加权函数
另一种使用固定大小窗口及相等权数观测值的办法是,定义一个衰减因子(decay factor)常量,以便使近期的观测值拥有更大的权数。衰减因子的定义方式有很多,比较流行的是使用时间间隔(span),它可以使结果兼容于窗口大小等于时间间隔的简单移动窗口(simple moving window)函数。
由于指数加权统计会赋予近期的观测值更大的权数,因此相对于等权统计,它能“适应”更快的变化。
除了rolling和expanding,pandas还有ewm运算符。下面这个例子对比了苹果公司股价的30日移动平均和span=30的指数加权移动平均(如下图所示):
aapl_px = close_px.AAPL['2006':'2007']
ma60 = aapl_px.rolling(30, min_periods=20).mean()
ewma60 = aapl_px.ewm(span=30).mean()
ma60.plot(style='k--', label='Simple MA')
<matplotlib.axes._subplots.AxesSubplot at 0x7f2f252161d0>
ewma60.plot(style='k-', label='EW MA')
<matplotlib.axes._subplots.AxesSubplot at 0x7f2f252161d0>
plt.legend()
二元移动窗口函数
有些统计运算(如相关系数和协方差)需要在两个时间序列上执行。例如,金融分析师常常对某只股票对某个参考指数(如标准普尔500指数)的相关系数感兴趣。要进行说明,我们先计算我们感兴趣的时间序列的百分数变化:
spx_px = close_px_all['SPX']
spx_rets = spx_px.pct_change()
returns = close_px.pct_change()
调用rolling之后,corr聚合函数开始计算与spx_rets滚动相关系数(结果见下图):
corr = returns.AAPL.rolling(125, min_periods=100).corr(spx_rets)
corr.plot()
假设你想要一次性计算多只股票与标准普尔500指数的相关系数。虽然编写一个循环并新建一个DataFrame不是什么难事,但比较啰嗦。其实,只需传入一个TimeSeries和一个DataFrame,rolling_corr就会自动计算TimeSeries(本例中就是spx_rets)与DataFrame各列的相关系数。结果如图11-9所示:
corr = returns.rolling(125, min_periods=100).corr(spx_rets)
corr.plot()
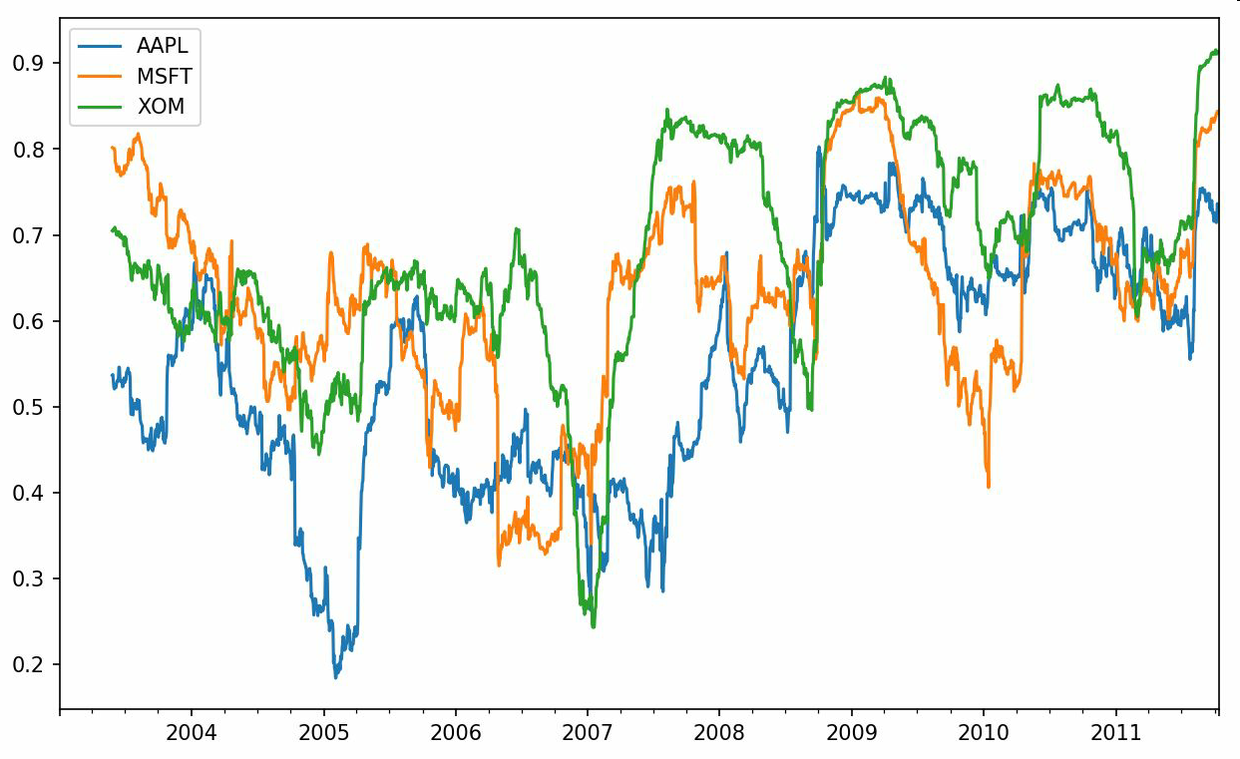
用户定义的移动窗口函数
rolling_apply函数使你能够在移动窗口上应用自己设计的数组函数。唯一要求的就是:该函数要能从数组的各个片段中产生单个值(即约简)。比如说,当我们用rolling(...).quantile(q)计算样本分位数时,可能对样本中特定值的百分等级感兴趣。scipy.stats.percentileofscore函数就能达到这个目的(结果见下图):
from scipy.stats import percentileofscore
score_at_2percent = lambda x: percentileofscore(x, 0.02)
result = returns.AAPL.rolling(250).apply(score_at_2percent)
result.plot()
pandas高级应用
分类数据
表中的一列通常会有重复的包含不同值的小集合的情况。我们已经学过了unique和value_counts,它们可以从数组提取出不同的值,并分别计算频率:
import numpy as np; import pandas as pd
values = pd.Series(['apple', 'orange', 'apple','apple'] * 2)
values
0 apple
1 orange
2 apple
3 apple
4 apple
5 orange
6 apple
7 apple
dtype: object
pd.unique(values)
array(['apple', 'orange'], dtype=object)
pd.value_counts(values)
apple 6
orange 2
dtype: int64
许多数据系统(数据仓库、统计计算或其它应用)都发展出了特定的表征重复值的方法,以进行高效的存储和计算。在数据仓库中,最好的方法是使用所谓的包含不同值的维表(Dimension Table),将主要的参数存储为引用维表整数键:
values = pd.Series([0, 1, 0, 0] * 2)
dim = pd.Series(['apple', 'orange'])
values
0 0
1 1
2 0
3 0
4 0
5 1
6 0
7 0
dtype: int64
dim
0 apple
1 orange
dtype: object
可以使用take方法存储原始的字符串Series:
dim.take(values)
0 apple
1 orange
0 apple
0 apple
0 apple
1 orange
0 apple
0 apple
dtype: object
这种用整数表示的方法称为分类或字典编码表示法。不同值得数组称为分类、字典或数据级。本书中,我们使用分类的说法。表示分类的整数值称为分类编码或简单地称为编码。
分类表示可以在进行分析时大大的提高性能。你也可以在保持编码不变的情况下,对分类进行转换。一些相对简单的转变例子包括:
- 重命名分类。
- 加入一个新的分类,不改变已经存在的分类的顺序或位置。
pandas的分类类型
pandas有一个特殊的分类类型,用于保存使用整数分类表示法的数据。看一个之前的Series例子:
fruits = ['apple', 'orange', 'apple', 'apple'] * 2
N = len(fruits)
df = pd.DataFrame({'fruit': fruits,'basket_id': np.arange(N),'count': np.random.randint(3, 15, size=N),'weight': np.random.uniform(0, 4, size=N)},columns=['basket_id', 'fruit', 'count', 'weight'])
df
basket_id fruit count weight
0 0 apple 5 3.858058
1 1 orange 8 2.612708
2 2 apple 4 2.995627
3 3 apple 7 2.614279
4 4 apple 12 2.990859
5 5 orange 8 3.845227
6 6 apple 5 0.033553
7 7 apple 4 0.425778
这里,df['fruit']是一个Python字符串对象的数组。我们可以通过调用它,将它转变为分类:
fruit_cat = df['fruit'].astype('category')
fruit_cat
0 apple
1 orange
2 apple
3 apple
4 apple
5 orange
6 apple
7 apple
Name: fruit, dtype: category
Categories (2, object): [apple, orange]
fruit_cat的值不是NumPy数组,而是一个pandas.Categorical实例:
c = fruit_cat.values
type(c)
pandas.core.categorical.Categorical
分类对象有categories和codes属性:
c.categories
Index(['apple', 'orange'], dtype='object')
c.codes
array([0, 1, 0, 0, 0, 1, 0, 0], dtype=int8)
你可将DataFrame的列通过分配转换结果,转换为分类:
df['fruit'] = df['fruit'].astype('category')
df.fruit
0 apple
1 orange
2 apple
3 apple
4 apple
5 orange
6 apple
7 apple
Name: fruit, dtype: category
Categories (2, object): [apple, orange]
你还可以从其它Python序列直接创建pandas.Categorical:
my_categories = pd.Categorical(['foo', 'bar', 'baz', 'foo', 'bar'])
my_categories
[foo, bar, baz, foo, bar]
Categories (3, object): [bar, baz, foo]
如果你已经从其它源获得了分类编码,你还可以使用from_codes构造器:
categories = ['foo', 'bar', 'baz']
codes = [0, 1, 2, 0, 0, 1]
my_cats_2 = pd.Categorical.from_codes(codes, categories)
my_cats_2
[foo, bar, baz, foo, foo, bar]
Categories (3, object): [foo, bar, baz]
与显示指定不同,分类变换不认定指定的分类顺序。因此取决于输入数据的顺序,categories数组的顺序会不同。当使用from_codes或其它的构造器时,你可以指定分类一个有意义的顺序:
ordered_cat = pd.Categorical.from_codes(codes, categories,ordered=True)
ordered_cat
[foo, bar, baz, foo, foo, bar]
Categories (3, object): [foo < bar < baz]
输出[foo < bar < baz]指明‘foo’位于‘bar’的前面,以此类推。无序的分类实例可以通过as_ordered排序:
my_cats_2.as_ordered()
[foo, bar, baz, foo, foo, bar]
Categories (3, object): [foo < bar < baz]
最后要注意,分类数据不需要字符串,尽管我仅仅展示了字符串的例子。分类数组可以包括任意不可变类型。
用分类进行计算
与非编码版本(比如字符串数组)相比,使用pandas的Categorical有些类似。某些pandas组件,比如groupby函数,更适合进行分类。还有一些函数可以使用有序标志位。
来看一些随机的数值数据,使用pandas.qcut面元函数。它会返回pandas.Categorical,我们之前使用过pandas.cut,但没解释分类是如何工作的:
np.random.seed(12345)
draws = np.random.randn(1000)
draws[:5]
array([-0.2047, 0.4789, -0.5194, -0.5557, 1.9658])
计算这个数据的分位面元,提取一些统计信息:
bins = pd.qcut(draws, 4)
bins
[(-0.684, -0.0101], (-0.0101, 0.63], (-0.684, -0.0101], (-0.684, -0.0101], (0.63,
3.928], ..., (-0.0101, 0.63], (-0.684, -0.0101], (-2.95, -0.684], (-0.0101, 0.63
], (0.63, 3.928]]
Length: 1000
Categories (4, interval[float64]): [(-2.95, -0.684] < (-0.684, -0.0101] < (-0.010
1, 0.63] <(0.63, 3.928]]
虽然有用,确切的样本分位数与分位的名称相比,不利于生成汇总。我们可以使用labels参数qcut,实现目的:
bins = pd.qcut(draws, 4, labels=['Q1', 'Q2', 'Q3', 'Q4'])
bins
[Q2, Q3, Q2, Q2, Q4, ..., Q3, Q2, Q1, Q3, Q4]
Length: 1000
Categories (4, object): [Q1 < Q2 < Q3 < Q4]
bins.codes[:10]
array([1, 2, 1, 1, 3, 3, 2, 2, 3, 3], dtype=int8)
加上标签的面元分类不包含数据面元边界的信息,因此可以使用groupby提取一些汇总信息:
bins = pd.Series(bins, name='quartile')
results = (pd.Series(draws).groupby(bins).agg(['count', 'min', 'max']).reset_index())
results
quartile count min max
0 Q1 250 -2.949343 -0.685484
1 Q2 250 -0.683066 -0.010115
2 Q3 250 -0.010032 0.628894
3 Q4 250 0.634238 3.927528
分位数列保存了原始的面元分类信息,包括排序:
results['quartile']
0 Q1
1 Q2
2 Q3
3 Q4
Name: quartile, dtype: category
Categories (4, object): [Q1 < Q2 < Q3 < Q4]
用分类提高性能
如果你是在一个特定数据集上做大量分析,将其转换为分类可以极大地提高效率。DataFrame列的分类使用的内存通常少的多。来看一些包含一千万元素的Series,和一些不同的分类:
N = 10000000
draws = pd.Series(np.random.randn(N))
labels = pd.Series(['foo', 'bar', 'baz', 'qux'] * (N // 4))
现在,将标签转换为分类:
categories = labels.astype('category')
这时,可以看到标签使用的内存远比分类多:
labels.memory_usage()
80000080
categories.memory_usage()
10000272
转换为分类不是没有代价的,但这是一次性的代价:
%time _ = labels.astype('category')
CPU times: user 490 ms, sys: 240 ms, total: 730 ms
Wall time: 726 ms
GroupBy使用分类操作明显更快,是因为底层的算法使用整数编码数组,而不是字符串数组。
分类方法
包含分类数据的Series有一些特殊的方法,类似于Series.str字符串方法。它还提供了方便的分类和编码的使用方法。看下面的Series:
s = pd.Series(['a', 'b', 'c', 'd'] * 2)
cat_s = s.astype('category')
cat_s
0 a
1 b
2 c
3 d
4 a
5 b
6 c
7 d
dtype: category
Categories (4, object): [a, b, c, d]
特别的cat属性提供了分类方法的入口:
cat_s.cat.codes
0 0
1 1
2 2
3 3
4 0
5 1
6 2
7 3
dtype: int8
cat_s.cat.categories
Index(['a', 'b', 'c', 'd'], dtype='object')
假设我们知道这个数据的实际分类集,超出了数据中的四个值。我们可以使用set_categories方法改变它们:
actual_categories = ['a', 'b', 'c', 'd', 'e']
cat_s2 = cat_s.cat.set_categories(actual_categories)
cat_s2
0 a
1 b
2 c
3 d
4 a
5 b
6 c
7 d
dtype: category
Categories (5, object): [a, b, c, d, e]
虽然数据看起来没变,新的分类将反映在它们的操作中。例如,如果有的话,value_counts表示分类:
cat_s.value_counts()
d 2
c 2
b 2
a 2
dtype: int64
cat_s2.value_counts()
d 2
c 2
b 2
a 2
e 0
dtype: int64
在大数据集中,分类经常作为节省内存和高性能的便捷工具。过滤完大DataFrame或Series之后,许多分类可能不会出现在数据中。我们可以使用remove_unused_categories方法删除没看到的分类:
cat_s3 = cat_s[cat_s.isin(['a', 'b'])]
cat_s3
0 a
1 b
4 a
5 b
dtype: category
Categories (4, object): [a, b, c, d]
cat_s3.cat.remove_unused_categories()
0 a
1 b
4 a
5 b
dtype: category
Categories (2, object): [a, b]
下表列出了可用的分类方法。
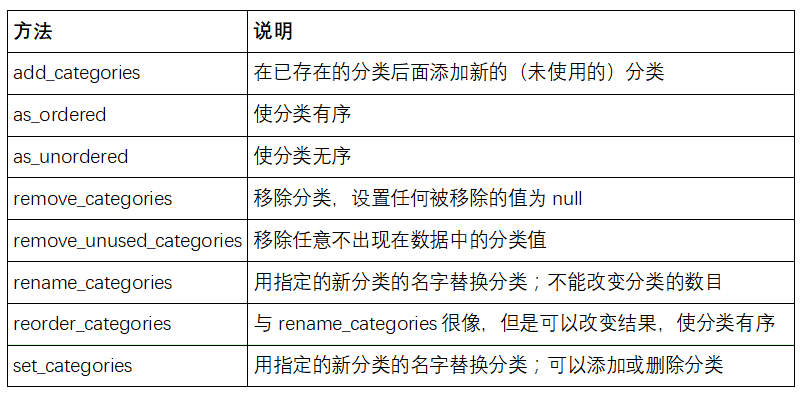
为建模创建虚拟变量
当你使用统计或机器学习工具时,通常会将分类数据转换为虚拟变量,也称为one-hot编码。这包括创建一个不同类别的列的DataFrame;这些列包含给定分类的1s,其它为0。
看前面的例子:
cat_s = pd.Series(['a', 'b', 'c', 'd'] * 2, dtype='category')
pandas.get_dummies函数可以转换这个分类数据为包含虚拟变量的DataFrame:
pd.get_dummies(cat_s)
a b c d
0 1 0 0 0
1 0 1 0 0
2 0 0 1 0
3 0 0 0 1
4 1 0 0 0
5 0 1 0 0
6 0 0 1 0
7 0 0 0 1
GroupBy高级应用
分组转换和“解封”GroupBy
我们在分组操作中学习了apply方法,进行转换。还有另一个transform方法,它与apply很像,但是对使用的函数有一定限制:
- 它可以产生向分组形状广播标量值
- 它可以产生一个和输入组形状相同的对象
- 它不能修改输入
来看一个简单的例子:
df = pd.DataFrame({'key': ['a', 'b', 'c'] * 4,'value': np.arange(12.)})
df
key value
0 a 0.0
1 b 1.0
2 c 2.0
3 a 3.0
4 b 4.0
5 c 5.0
6 a 6.0
7 b 7.0
8 c 8.0
9 a 9.0
10 b 10.0
11 c 11.0
按键进行分组:
g = df.groupby('key').value
g.mean()
key
a 4.5
b 5.5
c 6.5
Name: value, dtype: float64
假设我们想产生一个和df['value']形状相同的Series,但值替换为按键分组的平均值。我们可以传递函数lambda x: x.mean()进行转换:
g.transform(lambda x: x.mean())
0 4.5
1 5.5
2 6.5
3 4.5
4 5.5
5 6.5
6 4.5
7 5.5
8 6.5
9 4.5
10 5.5
11 6.5
Name: value, dtype: float64
对于内置的聚合函数,我们可以传递一个字符串假名作为GroupBy的agg方法:
g.transform('mean')
0 4.5
1 5.5
2 6.5
3 4.5
4 5.5
5 6.5
6 4.5
7 5.5
8 6.5
9 4.5
10 5.5
11 6.5
Name: value, dtype: float64
与apply类似,transform的函数会返回Series,但是结果必须与输入大小相同。举个例子,我们可以用lambda函数将每个分组乘以2:
g.transform(lambda x: x * 2)
0 0.0
1 2.0
2 4.0
3 6.0
4 8.0
5 10.0
6 12.0
7 14.0
8 16.0
9 18.0
10 20.0
11 22.0
Name: value, dtype: float64
再举一个复杂的例子,我们可以计算每个分组的降序排名:
g.transform(lambda x: x.rank(ascending=False))
0 4.0
1 4.0
2 4.0
3 3.0
4 3.0
5 3.0
6 2.0
7 2.0
8 2.0
9 1.0
10 1.0
11 1.0
Name: value, dtype: float64
看一个由简单聚合构造的的分组转换函数:
def normalize(x):
return (x - x.mean()) / x.std()
我们用transform或apply可以获得等价的结果:
g.transform(normalize)
0 -1.161895
1 -1.161895
2 -1.161895
3 -0.387298
4 -0.387298
5 -0.387298
6 0.387298
7 0.387298
8 0.387298
9 1.161895
10 1.161895
11 1.161895
Name: value, dtype: float64
g.apply(normalize)
0 -1.161895
1 -1.161895
2 -1.161895
3 -0.387298
4 -0.387298
5 -0.387298
6 0.387298
7 0.387298
8 0.387298
9 1.161895
10 1.161895
11 1.161895
Name: value, dtype: float64
内置的聚合函数,比如mean或sum,通常比apply函数快,也比transform快。这允许我们进行一个所谓的解封(unwrapped)分组操作:
g.transform('mean')
0 4.5
1 5.5
2 6.5
3 4.5
4 5.5
5 6.5
6 4.5
7 5.5
8 6.5
9 4.5
10 5.5
11 6.5
Name: value, dtype: float64
normalized = (df['value'] - g.transform('mean')) / g.transform('std')
normalized
0 -1.161895
1 -1.161895
2 -1.161895
3 -0.387298
4 -0.387298
5 -0.387298
6 0.387298
7 0.387298
8 0.387298
9 1.161895
10 1.161895
11 1.161895
Name: value, dtype: float64
解封分组操作可能包括多个分组聚合,但是矢量化操作还是会带来收益。
分组的时间重采样
对于时间序列数据,resample方法从语义上是一个基于内在时间的分组操作。下面是一个示例表:
N = 15
times = pd.date_range('2017-05-20 00:00', freq='1min', periods=N)
df = pd.DataFrame({'time': times,'value': np.arange(N)})
df
time value
0 2017-05-20 00:00:00 0
1 2017-05-20 00:01:00 1
2 2017-05-20 00:02:00 2
3 2017-05-20 00:03:00 3
4 2017-05-20 00:04:00 4
5 2017-05-20 00:05:00 5
6 2017-05-20 00:06:00 6
7 2017-05-20 00:07:00 7
8 2017-05-20 00:08:00 8
9 2017-05-20 00:09:00 9
10 2017-05-20 00:10:00 10
11 2017-05-20 00:11:00 11
12 2017-05-20 00:12:00 12
13 2017-05-20 00:13:00 13
14 2017-05-20 00:14:00 14
这里,我们可以用time作为索引,然后重采样:
df.set_index('time').resample('5min').count()
value
time
2017-05-20 00:00:00 5
2017-05-20 00:05:00 5
2017-05-20 00:10:00 5
假设DataFrame包含多个时间序列,用一个额外的分组键的列进行标记:
df2 = pd.DataFrame({'time': times.repeat(3),'key': np.tile(['a', 'b', 'c'], N),'value': np.arange(N * 3.)})
df2[:7]
key time value
0 a 2017-05-20 00:00:00 0.0
1 b 2017-05-20 00:00:00 1.0
2 c 2017-05-20 00:00:00 2.0
3 a 2017-05-20 00:01:00 3.0
4 b 2017-05-20 00:01:00 4.0
5 c 2017-05-20 00:01:00 5.0
6 a 2017-05-20 00:02:00 6.0
要对每个key值进行相同的重采样,我们引入pandas.TimeGrouper对象:
time_key = pd.TimeGrouper('5min')
我们然后设定时间索引,用key和time_key分组,然后聚合:
resampled = (df2.set_index('time').groupby(['key', time_key]).sum())
resampled
value
key time
a 2017-05-20 00:00:00 30.0
2017-05-20 00:05:00 105.0
2017-05-20 00:10:00 180.0
b 2017-05-20 00:00:00 35.0
2017-05-20 00:05:00 110.0
2017-05-20 00:10:00 185.0
c 2017-05-20 00:00:00 40.0
2017-05-20 00:05:00 115.0
2017-05-20 00:10:00 190.0
resampled.reset_index()
key time value
0 a 2017-05-20 00:00:00 30.0
1 a 2017-05-20 00:05:00 105.0
2 a 2017-05-20 00:10:00 180.0
3 b 2017-05-20 00:00:00 35.0
4 b 2017-05-20 00:05:00 110.0
5 b 2017-05-20 00:10:00 185.0
6 c 2017-05-20 00:00:00 40.0
7 c 2017-05-20 00:05:00 115.0
8 c 2017-05-20 00:10:00 190.0
使用TimeGrouper的限制是时间必须是Series或DataFrame的索引。
链式编程技术
当对数据集进行一系列变换时,你可能发现创建的多个临时变量其实并没有在分析中用到。看下面的例子:
df = load_data()
df2 = df[df['col2'] < 0]
df2['col1_demeaned'] = df2['col1'] - df2['col1'].mean()
result = df2.groupby('key').col1_demeaned.std()
虽然这里没有使用真实的数据,这个例子却指出了一些新方法。首先,DataFrame.assign方法是一个df[k] = v形式的函数式的列分配方法。它不是就地修改对象,而是返回新的修改过的DataFrame。因此,下面的语句是等价的:
#Usual non-functional way
df2 = df.copy()
df2['k'] = v
#Functional assign way
df2 = df.assign(k=v)
就地分配可能会比assign快,但是assign可以方便地进行链式编程:
result = (df2.assign(col1_demeaned=df2.col1 - df2.col2.mean()).groupby('key').col1_demeaned.std())
我使用外括号,这样便于添加换行符。
使用链式编程时要注意,你可能会需要涉及临时对象。在前面的例子中,我们不能使用load_data的结果,直到它被赋值给临时变量df。为了这么做,assign和许多其它pandas函数可以接收类似函数的参数,即可调用对象(callable)。为了展示可调用对象,看一个前面例子的片段:
df = load_data()
df2 = df[df['col2'] < 0]
它可以重写为:
df = (load_data()
[lambda x: x['col2'] < 0])
这里,load_data的结果没有赋值给某个变量,因此传递到[ ]的函数在这一步被绑定到了对象。
我们可以把整个过程写为一个单链表达式:
result = (load_data()
[lambda x: x.col2 < 0]
.assign(col1_demeaned=lambda x: x.col1 - x.col1.mean())
.groupby('key')
.col1_demeaned.std())
是否将代码写成这种形式只是习惯而已,将它分开成若干步可以提高可读性。
管道方法
你可以用Python内置的pandas函数和方法,用带有可调用对象的链式编程做许多工作。但是,有时你需要使用自己的函数,或是第三方库的函数。这时就要用到管道方法。
看下面的函数调用:
a = f(df, arg1=v1)
b = g(a, v2, arg3=v3)
c = h(b, arg4=v4)
当使用接收、返回Series或DataFrame对象的函数式,你可以调用pipe将其重写:
result = (df.pipe(f, arg1=v1)
.pipe(g, v2, arg3=v3)
.pipe(h, arg4=v4))
f(df)和df.pipe(f)是等价的,但是pipe使得链式声明更容易。
pipe的另一个有用的地方是提炼操作为可复用的函数。看一个从列减去分组方法的例子:
g = df.groupby(['key1', 'key2'])
df['col1'] = df['col1'] - g.transform('mean')
假设你想转换多列,并修改分组的键。另外,你想用链式编程做这个转换。下面就是一个方法:
def group_demean(df, by, cols):
result = df.copy()
g = df.groupby(by)
for c in cols:
result[c] = df[c] - g[c].transform('mean')
return result
然后可以写为:
result = (df[df.col1 < 0]
.pipe(group_demean, ['key1', 'key2'], ['col1']))
Python建模库
pandas与模型代码的接口
模型开发的通常工作流是使用pandas进行数据加载和清洗,然后切换到建模库进行建模。开发模型的重要一环是机器学习中的“特征工程”。它可以描述从原始数据集中提取信息的任何数据转换或分析,这些数据集可能在建模中有用。本书中学习的数据聚合和GroupBy工具常用于特征工程中。
优秀的特征工程超出了本书的范围,我会尽量直白地介绍一些用于数据操作和建模切换的方法。
pandas与其它分析库通常是靠NumPy的数组联系起来的。将DataFrame转换为NumPy数组,可以使用.values属性:
import pandas as pd
import numpy as np
data = pd.DataFrame({'x0': [1, 2, 3, 4, 5],'x1': [0.01, -0.01, 0.25, -4.1, 0.],'y': [-1.5, 0., 3.6, 1.3, -2.]})
data
x0 x1 y
0 1 0.01 -1.5
1 2 -0.01 0.0
2 3 0.25 3.6
3 4 -4.10 1.3
4 5 0.00 -2.0
data.columns
Index(['x0', 'x1', 'y'], dtype='object')
data.values
array([[ 1. , 0.01, -1.5 ],
[ 2. , -0.01, 0. ],
[ 3. , 0.25, 3.6 ],
[ 4. , -4.1 , 1.3 ],
[ 5. , 0. , -2. ]])
要转换回DataFrame,可以传递一个二维ndarray,可带有列名:
df2 = pd.DataFrame(data.values, columns=['one', 'two', 'three'])
df2
one two three
0 1.0 0.01 -1.5
1 2.0 -0.01 0.0
2 3.0 0.25 3.6
3 4.0 -4.10 1.3
4 5.0 0.00 -2.0
笔记:最好当数据是均匀的时候使用
.values属性。例如,全是数值类型。如果数据是不均匀的,结果会是Python对象的ndarray:
df3 = data.copy()
df3['strings'] = ['a', 'b', 'c', 'd', 'e']
df3
x0 x1 y strings
0 1 0.01 -1.5 a
1 2 -0.01 0.0 b
2 3 0.25 3.6 c
3 4 -4.10 1.3 d
4 5 0.00 -2.0 e
df3.values
array([[1, 0.01, -1.5, 'a'],
[2, -0.01, 0.0, 'b'],
[3, 0.25, 3.6, 'c'],
[4, -4.1, 1.3, 'd'],
[5, 0.0, -2.0, 'e']], dtype=object)
对于一些模型,你可能只想使用列的子集。我建议你使用loc,用values作索引:
model_cols = ['x0', 'x1']
data.loc[:, model_cols].values
array([[ 1. , 0.01],
[ 2. , -0.01],
[ 3. , 0.25],
[ 4. , -4.1 ],
[ 5. , 0. ]])
一些库原生支持pandas,会自动完成工作:从DataFrame转换到NumPy,将模型的参数名添加到输出表的列或Series。其它情况,你可以手工进行“元数据管理”。
data['category'] = pd.Categorical(['a', 'b', 'a', 'a', 'b'],categories=['a', 'b'])
data
x0 x1 y category
0 1 0.01 -1.5 a
1 2 -0.01 0.0 b
2 3 0.25 3.6 a
3 4 -4.10 1.3 a
4 5 0.00 -2.0 b
如果我们想替换category列为虚变量,我们可以创建虚变量,删除category列,然后添加到结果:
dummies = pd.get_dummies(data.category, prefix='category')
data_with_dummies = data.drop('category', axis=1).join(dummies)
data_with_dummies
x0 x1 y category_a category_b
0 1 0.01 -1.5 1 0
1 2 -0.01 0.0 0 1
2 3 0.25 3.6 1 0
3 4 -4.10 1.3 1 0
4 5 0.00 -2.0 0 1
用虚变量拟合某些统计模型会有一些细微差别。
scikit-learn介绍
scikit-learn是一个广泛使用、用途多样的Python机器学习库。它包含多种标准监督和非监督机器学习方法和模型选择和评估、数据转换、数据加载和模型持久化工具。这些模型可以用于分类、聚合、预测和其它任务。
机器学习方面的学习和应用scikit-learn和TensorFlow解决实际问题的线上和纸质资料很多。本节中,我会简要介绍scikit-learn API的风格。
写作此书的时候,scikit-learn并没有和pandas深度结合,但是有些第三方包在开发中。尽管如此,pandas非常适合在模型拟合前处理数据集。
举个例子,我用一个Kaggle竞赛的经典数据集,关于泰坦尼克号乘客的生还率。我们用pandas加载测试和训练数据集:
train = pd.read_csv('datasets/titanic/train.csv')
test = pd.read_csv('datasets/titanic/test.csv')
train[:4]
PassengerId Survived Pclass \
0 1 0 3
1 2 1 1
2 3 1 3
3 4 1 1
Name Sex Age SibSp \
0 Braund, Mr. Owen Harris male 22.0 1
1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1
2 Heikkinen, Miss. Laina female 26.0 0
3 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1
Parch Ticket Fare Cabin Embarked
0 0 A/5 21171 7.2500 NaN S
1 0 PC 17599 71.2833 C85 C
2 0 STON/O2. 3101282 7.9250 NaN S
3 0 113803 53.1000 C123 S
statsmodels和scikit-learn通常不能接收缺失数据,因此我们要查看列是否包含缺失值:
train.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
test.isnull().sum()
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64
在统计和机器学习的例子中,根据数据中的特征,一个典型的任务是预测乘客能否生还。模型现在训练数据集中拟合,然后用样本外测试数据集评估。
我想用年龄作为预测值,但是它包含缺失值。缺失数据补全的方法有多种,我用的是一种简单方法,用训练数据集的中位数补全两个表的空值:
impute_value = train['Age'].median()
train['Age'] = train['Age'].fillna(impute_value)
test['Age'] = test['Age'].fillna(impute_value)
现在我们需要指定模型。我增加了一个列IsFemale,作为“Sex”列的编码:
train['IsFemale'] = (train['Sex'] == 'female').astype(int)
test['IsFemale'] = (test['Sex'] == 'female').astype(int)
然后,我们确定一些模型变量,并创建NumPy数组:
predictors = ['Pclass', 'IsFemale', 'Age']
X_train = train[predictors].values
X_test = test[predictors].values
y_train = train['Survived'].values
X_train[:5]
array([[ 3., 0., 22.],
[ 1., 1., 38.],
[ 3., 1., 26.],
[ 1., 1., 35.],
[ 3., 0., 35.]])
y_train[:5]
array([0, 1, 1, 1, 0])
我不能保证这是一个好模型,但它的特征都符合。我们用scikit-learn的LogisticRegression模型,创建一个模型实例:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
与statsmodels类似,我们可以用模型的fit方法,将它拟合到训练数据:
model.fit(X_train, y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
现在,我们可以用model.predict,对测试数据进行预测:
y_predict = model.predict(X_test)
y_predict[:10]
array([0, 0, 0, 0, 1, 0, 1, 0, 1, 0])
如果你有测试数据集的真实值,你可以计算准确率或其它错误度量值:
(y_true == y_predict).mean()
在实际中,模型训练经常有许多额外的复杂因素。许多模型有可以调节的参数,有些方法(比如交叉验证)可以用来进行参数调节,避免对训练数据过拟合。这通常可以提高预测性或对新数据的健壮性。
交叉验证通过分割训练数据来模拟样本外预测。基于模型的精度得分(比如均方差),可以对模型参数进行网格搜索。有些模型,如logistic回归,有内置的交叉验证的估计类。例如,logisticregressioncv类可以用一个参数指定网格搜索对模型的正则化参数C的粒度:
from sklearn.linear_model import LogisticRegressionCV
model_cv = LogisticRegressionCV(10)
model_cv.fit(X_train, y_train)
LogisticRegressionCV(Cs=10, class_weight=None, cv=None, dual=False,
fit_intercept=True, intercept_scaling=1.0, max_iter=100,
multi_class='ovr', n_jobs=1, penalty='l2', random_state=None,
refit=True, scoring=None, solver='lbfgs', tol=0.0001, verbose=0)
要手动进行交叉验证,你可以使用cross_val_score帮助函数,它可以处理数据分割。例如,要交叉验证我们的带有四个不重叠训练数据的模型,可以这样做:
from sklearn.model_selection import cross_val_score
model = LogisticRegression(C=10)
scores = cross_val_score(model, X_train, y_train, cv=4)
scores
array([ 0.7723, 0.8027, 0.7703, 0.7883])
默认的评分指标取决于模型本身,但是可以明确指定一个评分。交叉验证过的模型需要更长时间来训练,但会有更高的模型性能。
数据分析案例
来自Bitly的USA.gov数据
2011年,URL缩短服务Bitly跟美国政府网站USA.gov合作,提供了一份从生成.gov或.mil短链接的用户那里收集来的匿名数据。在2011年,除实时数据之外,还可以下载文本文件形式的每小时快照。
以每小时快照为例,文件中各行的格式为JSON(即JavaScript Object Notation,这是一种常用的Web数据格式)。例如,如果我们只读取某个文件中的第一行,那么所看到的结果应该是下面这样:
path = 'datasets/bitly_usagov/example.txt'
open(path).readline()
'{ "a": "Mozilla\\/5.0 (Windows NT 6.1; WOW64) AppleWebKit\\/535.11
(KHTML, like Gecko) Chrome\\/17.0.963.78 Safari\\/535.11", "c": "US", "nk": 1,
"tz": "America\\/New_York", "gr": "MA", "g": "A6qOVH", "h": "wfLQtf", "l":
"orofrog", "al": "en-US,en;q=0.8", "hh": "1.usa.gov", "r":
"http:\\/\\/www.facebook.com\\/l\\/7AQEFzjSi\\/1.usa.gov\\/wfLQtf", "u":
"http:\\/\\/www.ncbi.nlm.nih.gov\\/pubmed\\/22415991", "t": 1331923247, "hc":
1331822918, "cy": "Danvers", "ll": [ 42.576698, -70.954903 ] }\n'
Python有内置或第三方模块可以将JSON字符串转换成Python字典对象。这里,我将使用json模块及其loads函数逐行加载已经下载好的数据文件:
import json
path = 'datasets/bitly_usagov/example.txt'
records = [json.loads(line) for line in open(path)]
现在,records对象就成为一组Python字典了:
records[0]
{'a': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko)
Chrome/17.0.963.78 Safari/535.11',
'al': 'en-US,en;q=0.8',
'c': 'US',
'cy': 'Danvers',
'g': 'A6qOVH',
'gr': 'MA',
'h': 'wfLQtf',
'hc': 1331822918,
'hh': '1.usa.gov',
'l': 'orofrog',
'll': [42.576698, -70.954903],
'nk': 1,
'r': 'http://www.facebook.com/l/7AQEFzjSi/1.usa.gov/wfLQtf',
't': 1331923247,
'tz': 'America/New_York',
'u': 'http://www.ncbi.nlm.nih.gov/pubmed/22415991'}
用纯Python代码对时区进行计数
假设我们想要知道该数据集中最常出现的是哪个时区(即tz字段),得到答案的办法有很多。首先,我们用列表推导式取出一组时区:
time_zones = [rec['tz'] for rec in records]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-12-db4fbd348da9> in <module>()
----> 1 time_zones = [rec['tz'] for rec in records]
<ipython-input-12-db4fbd348da9> in <listcomp>(.0)
----> 1 time_zones = [rec['tz'] for rec in records]
KeyError: 'tz'
晕!原来并不是所有记录都有时区字段。这个好办,只需在列表推导式末尾加上一个if 'tz'in rec判断即可:
time_zones = [rec['tz'] for rec in records if 'tz' in rec]
time_zones[:10]
['America/New_York',
'America/Denver',
'America/New_York',
'America/Sao_Paulo',
'America/New_York',
'America/New_York',
'Europe/Warsaw',
'',
'',
'']
只看前10个时区,我们发现有些是未知的(即空的)。虽然可以将它们过滤掉,但现在暂时先留着。接下来,为了对时区进行计数,这里介绍两个办法:一个较难(只使用标准Python库),另一个较简单(使用pandas)。计数的办法之一是在遍历时区的过程中将计数值保存在字典中:
def get_counts(sequence):
counts = {}
for x in sequence:
if x in counts:
counts[x] += 1
else:
counts[x] = 1
return counts
如果使用Python标准库的更高级工具,那么你可能会将代码写得更简洁一些:
from collections import defaultdict
def get_counts2(sequence):
counts = defaultdict(int) # values will initialize to 0
for x in sequence:
counts[x] += 1
return counts
我将逻辑写到函数中是为了获得更高的复用性。要用它对时区进行处理,只需将time_zones传入即可:
counts = get_counts(time_zones)
counts['America/New_York']
1251
len(time_zones)
3440
如果想要得到前10位的时区及其计数值,我们需要用到一些有关字典的处理技巧:
def top_counts(count_dict, n=10):
value_key_pairs = [(count, tz) for tz, count in count_dict.items()]
value_key_pairs.sort()
return value_key_pairs[-n:]
然后有:
top_counts(counts)
[(33, 'America/Sao_Paulo'),
(35, 'Europe/Madrid'),
(36, 'Pacific/Honolulu'),
(37, 'Asia/Tokyo'),
(74, 'Europe/London'),
(191, 'America/Denver'),
(382, 'America/Los_Angeles'),
(400, 'America/Chicago'),
(521, ''),
(1251, 'America/New_York')]
如果你搜索Python的标准库,你能找到collections.Counter类,它可以使这项工作更简单:
from collections import Counter
counts = Counter(time_zones)
counts.most_common(10)
[('America/New_York', 1251),
('', 521),
('America/Chicago', 400),
('America/Los_Angeles', 382),
('America/Denver', 191),
('Europe/London', 74),
('Asia/Tokyo', 37),
('Pacific/Honolulu', 36),
('Europe/Madrid', 35),
('America/Sao_Paulo', 33)]
用pandas对时区进行计数
从原始记录的集合创建DateFrame,与将记录列表传递到pandas.DataFrame一样简单:
import pandas as pd
frame = pd.DataFrame(records)
frame.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3560 entries, 0 to 3559
Data columns (total 18 columns):
_heartbeat_ 120 non-null float64
a 3440 non-null object
al 3094 non-null object
c 2919 non-null object
cy 2919 non-null object
g 3440 non-null object
gr 2919 non-null object
h 3440 non-null object
hc 3440 non-null float64
hh 3440 non-null object
kw 93 non-null object
l 3440 non-null object
ll 2919 non-null object
nk 3440 non-null float64
r 3440 non-null object
t 3440 non-null float64
tz 3440 non-null object
u 3440 non-null object
dtypes: float64(4), object(14)
memory usage: 500.7+ KB
frame['tz'][:10]
0 America/New_York
1 America/Denver
2 America/New_York
3 America/Sao_Paulo
4 America/New_York
5 America/New_York
6 Europe/Warsaw
7
8
9
Name: tz, dtype: object
这里frame的输出形式是摘要视图(summary view),主要用于较大的DataFrame对象。我们然后可以对Series使用value_counts方法:
tz_counts = frame['tz'].value_counts()
tz_counts[:10]
America/New_York 1251
521
America/Chicago 400
America/Los_Angeles 382
America/Denver 191
Europe/London 74
Asia/Tokyo 37
Pacific/Honolulu 36
Europe/Madrid 35
America/Sao_Paulo 33
Name: tz, dtype: int64
我们可以用matplotlib可视化这个数据。为此,我们先给记录中未知或缺失的时区填上一个替代值。fillna函数可以替换缺失值(NA),而未知值(空字符串)则可以通过布尔型数组索引加以替换:
clean_tz = frame['tz'].fillna('Missing')
clean_tz[clean_tz == ''] = 'Unknown'
tz_counts = clean_tz.value_counts()
tz_counts[:10]
America/New_York 1251
Unknown 521
America/Chicago 400
America/Los_Angeles 382
America/Denver 191
Missing 120
Europe/London 74
Asia/Tokyo 37
Pacific/Honolulu 36
Europe/Madrid 35
Name: tz, dtype: int64
此时,我们可以用seaborn包创建水平柱状图(结果见下图):
import seaborn as sns
subset = tz_counts[:10]
sns.barplot(y=subset.index, x=subset.values)
a字段含有执行URL短缩操作的浏览器、设备、应用程序的相关信息:
frame['a'][1]
'GoogleMaps/RochesterNY'
frame['a'][50]
'Mozilla/5.0 (Windows NT 5.1; rv:10.0.2)
Gecko/20100101 Firefox/10.0.2'
frame['a'][51][:50] # long line
'Mozilla/5.0 (Linux; U; Android 2.2.2; en-us; LG-P9'
将这些"agent"字符串中的所有信息都解析出来是一件挺郁闷的工作。一种策略是将这种字符串的第一节(与浏览器大致对应)分离出来并得到另外一份用户行为摘要:
results = pd.Series([x.split()[0] for x in frame.a.dropna()])
results[:5]
0 Mozilla/5.0
1 GoogleMaps/RochesterNY
2 Mozilla/4.0
3 Mozilla/5.0
4 Mozilla/5.0
dtype: object
results.value_counts()[:8]
Mozilla/5.0 2594
Mozilla/4.0 601
GoogleMaps/RochesterNY 121
Opera/9.80 34
TEST_INTERNET_AGENT 24
GoogleProducer 21
Mozilla/6.0 5
BlackBerry8520/5.0.0.681 4
dtype: int64
现在,假设你想按Windows和非Windows用户对时区统计信息进行分解。为了简单起见,我们假定只要agent字符串中含有"Windows"就认为该用户为Windows用户。由于有的agent缺失,所以首先将它们从数据中移除:
cframe = frame[frame.a.notnull()]
然后计算出各行是否含有Windows的值:
cframe['os'] = np.where(cframe['a'].str.contains('Windows'),'Windows', 'Not Windows')
cframe['os'][:5]
0 Windows
1 Not Windows
2 Windows
3 Not Windows
4 Windows
Name: os, dtype: object
接下来就可以根据时区和新得到的操作系统列表对数据进行分组了:
by_tz_os = cframe.groupby(['tz', 'os'])
分组计数,类似于value_counts函数,可以用size来计算。并利用unstack对计数结果进行重塑:
agg_counts = by_tz_os.size().unstack().fillna(0)
agg_counts[:10]
os Not Windows Windows
tz
245.0 276.0
Africa/Cairo 0.0 3.0
Africa/Casablanca 0.0 1.0
Africa/Ceuta 0.0 2.0
Africa/Johannesburg 0.0 1.0
Africa/Lusaka 0.0 1.0
America/Anchorage 4.0 1.0
America/Argentina/Buenos_Aires 1.0 0.0
America/Argentina/Cordoba 0.0 1.0
America/Argentina/Mendoza 0.0 1.0
最后,我们来选取最常出现的时区。为了达到这个目的,我根据agg_counts中的行数构造了一个间接索引数组:
#Use to sort in ascending order
indexer = agg_counts.sum(1).argsort()
indexer[:10]
tz
24
Africa/Cairo 20
Africa/Casablanca 21
Africa/Ceuta 92
Africa/Johannesburg 87
Africa/Lusaka 53
America/Anchorage 54
America/Argentina/Buenos_Aires 57
America/Argentina/Cordoba 26
America/Argentina/Mendoza 55
dtype: int64
然后我通过take按照这个顺序截取了最后10行最大值:
count_subset = agg_counts.take(indexer[-10:])
count_subset
os Not Windows Windows
tz
America/Sao_Paulo 13.0 20.0
Europe/Madrid 16.0 19.0
Pacific/Honolulu 0.0 36.0
Asia/Tokyo 2.0 35.0
Europe/London 43.0 31.0
America/Denver 132.0 59.0
America/Los_Angeles 130.0 252.0
America/Chicago 115.0 285.0
245.0 276.0
America/New_York 339.0 912.0
pandas有一个简便方法nlargest,可以做同样的工作:
agg_counts.sum(1).nlargest(10)
tz
America/New_York 1251.0
521.0
America/Chicago 400.0
America/Los_Angeles 382.0
America/Denver 191.0
Europe/London 74.0
Asia/Tokyo 37.0
Pacific/Honolulu 36.0
Europe/Madrid 35.0
America/Sao_Paulo 33.0
dtype: float64
然后,如这段代码所示,可以用柱状图表示。我传递一个额外参数到seaborn的barpolt函数,来画一个堆积条形图(见下图):
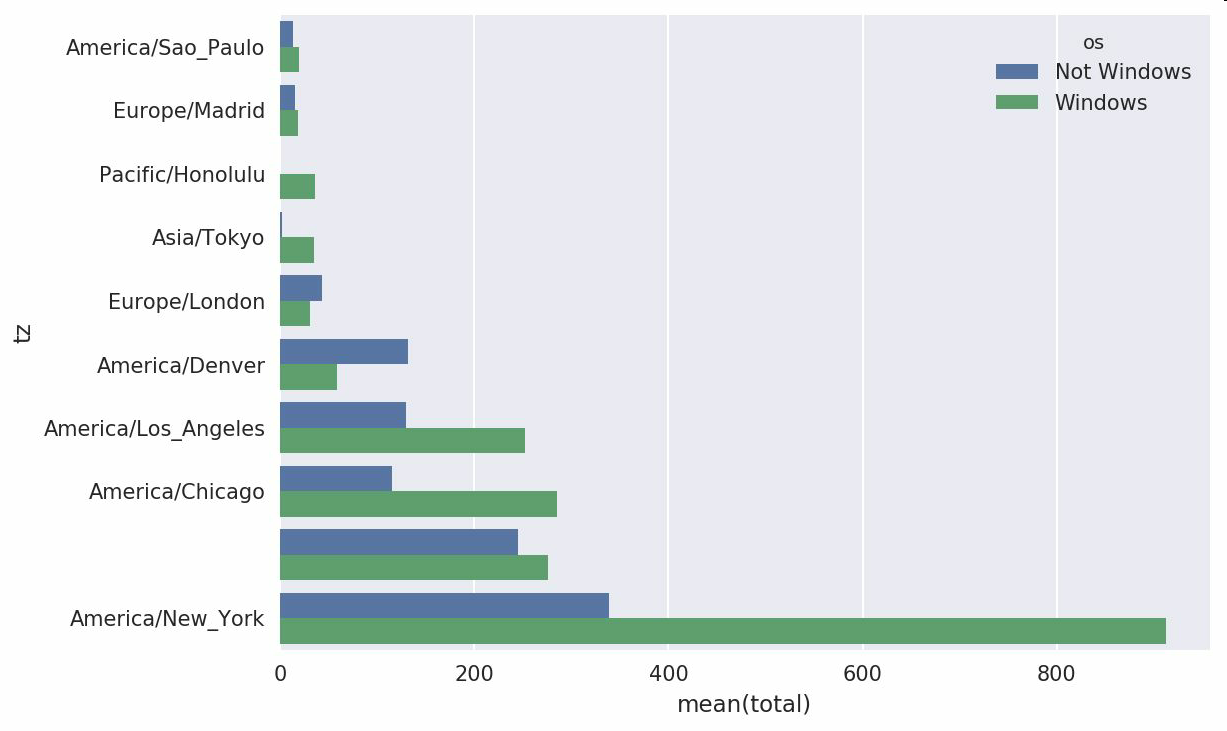
#Rearrange the data for plotting
count_subset = count_subset.stack()
count_subset.name = 'total'
count_subset = count_subset.reset_index()
count_subset[:10]
tz os total
0 America/Sao_Paulo Not Windows 13.0
1 America/Sao_Paulo Windows 20.0
2 Europe/Madrid Not Windows 16.0
3 Europe/Madrid Windows 19.0
4 Pacific/Honolulu Not Windows 0.0
5 Pacific/Honolulu Windows 36.0
6 Asia/Tokyo Not Windows 2.0
7 Asia/Tokyo Windows 35.0
8 Europe/London Not Windows 43.0
9 Europe/London Windows 31.0
sns.barplot(x='total', y='tz', hue='os', data=count_subset)
这张图不容易看出Windows用户在小分组中的相对比例,因此标准化分组百分比之和为1:
def norm_total(group):
group['normed_total'] = group.total / group.total.sum()
return group
results = count_subset.groupby('tz').apply(norm_total)
再次画图,见下图:
sns.barplot(x='normed_total', y='tz', hue='os', data=results)
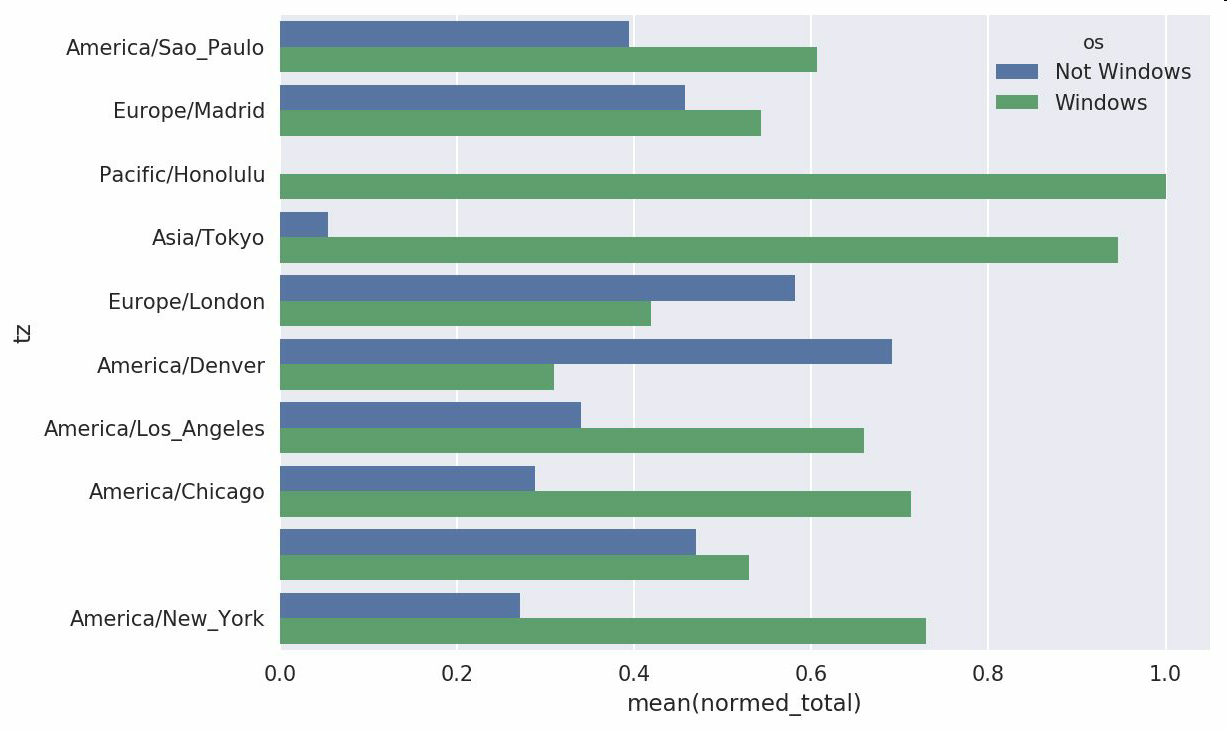
我们还可以用groupby的transform方法,更高效的计算标准化的和:
g = count_subset.groupby('tz')
results2 = count_subset.total / g.total.transform('sum')
MovieLens 1M数据集
GroupLens Research采集了一组从20世纪90年末到21世纪初由MovieLens用户提供的电影评分数据。这些数据中包括电影评分、电影元数据(风格类型和年代)以及关于用户的人口统计学数据(年龄、邮编、性别和职业等)。基于机器学习算法的推荐系统一般都会对此类数据感兴趣。虽然我不会在本书中详细介绍机器学习技术,但我会告诉你如何对这种数据进行切片切块以满足实际需求。
MovieLens 1M数据集含有来自6000名用户对4000部电影的100万条评分数据。它分为三个表:评分、用户信息和电影信息。将该数据从zip文件中解压出来之后,可以通过pandas.read_table将各个表分别读到一个pandas DataFrame对象中:
import pandas as pd
#Make display smaller
pd.options.display.max_rows = 10
unames = ['user_id', 'gender', 'age', 'occupation', 'zip']
users = pd.read_table('datasets/movielens/users.dat', sep='::',header=None, names=unames)
rnames = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_table('datasets/movielens/ratings.dat', sep='::',header=None, names=rnames)
mnames = ['movie_id', 'title', 'genres']
movies = pd.read_table('datasets/movielens/movies.dat', sep='::',header=None, names=mnames)
利用Python的切片语法,通过查看每个DataFrame的前几行即可验证数据加载工作是否一切顺利:
users[:5]
user_id gender age occupation zip
0 1 F 1 10 48067
1 2 M 56 16 70072
2 3 M 25 15 55117
3 4 M 45 7 02460
4 5 M 25 20 55455
ratings[:5]
user_id movie_id rating timestamp
0 1 1193 5 978300760
1 1 661 3 978302109
2 1 914 3 978301968
3 1 3408 4 978300275
4 1 2355 5 978824291
movies[:5]
movie_id title genres
0 1 Toy Story (1995) Animation|Children's|Comedy
1 2 Jumanji (1995) Adventure|Children's|Fantasy
2 3 Grumpier Old Men (1995) Comedy|Romance
3 4 Waiting to Exhale (1995) Comedy|Drama
4 5 Father of the Bride Part II (1995) Comedy
ratings
user_id movie_id rating timestamp
0 1 1193 5 978300760
1 1 661 3 978302109
2 1 914 3 978301968
3 1 3408 4 978300275
4 1 2355 5 978824291
... ... ... ... ...
1000204 6040 1091 1 956716541
1000205 6040 1094 5 956704887
1000206 6040 562 5 956704746
1000207 6040 1096 4 956715648
1000208 6040 1097 4 956715569
[1000209 rows x 4 columns]
注意,其中的年龄和职业是以编码形式给出的,它们的具体含义请参考该数据集的README文件。分析散布在三个表中的数据可不是一件轻松的事情。假设我们想要根据性别和年龄计算某部电影的平均得分,如果将所有数据都合并到一个表中的话问题就简单多了。我们先用pandas的merge函数将ratings跟users合并到一起,然后再将movies也合并进去。pandas会根据列名的重叠情况推断出哪些列是合并(或连接)键:
data = pd.merge(pd.merge(ratings, users), movies)
data
user_id movie_id rating timestamp gender age occupation zip \
0 1 1193 5 978300760 F 1 10 48067
1 2 1193 5 978298413 M 56 16 70072
2 12 1193 4 978220179 M 25 12 32793
3 15 1193 4 978199279 M 25 7 22903
4 17 1193 5 978158471 M 50 1 95350
... ... ... ... ... ... ... ... ...
1000204 5949 2198 5 958846401 M 18 17 47901
1000205 5675 2703 3 976029116 M 35 14 30030
1000206 5780 2845 1 958153068 M 18 17 92886
1000207 5851 3607 5 957756608 F 18 20 55410
1000208 5938 2909 4 957273353 M 25 1 35401
title genres
0 One Flew Over the Cuckoo's Nest (1975) Drama
1 One Flew Over the Cuckoo's Nest (1975) Drama
2 One Flew Over the Cuckoo's Nest (1975) Drama
3 One Flew Over the Cuckoo's Nest (1975) Drama
4 One Flew Over the Cuckoo's Nest (1975) Drama
... ... ...
1000204 Modulations (1998) Documentary
1000205 Broken Vessels (1998) Drama
1000206 White Boys (1999) Drama
1000207 One Little Indian (1973) Comedy|Drama|Western
1000208 Five Wives, Three Secretaries and Me (1998) Documentary
[1000209 rows x 10 columns]
data.iloc[0]
user_id 1
movie_id 1193
rating 5
timestamp 978300760
gender F
age 1
occupation 10
zip 48067
title One Flew Over the Cuckoo's Nest (1975)
genres Drama
Name: 0, dtype: object
为了按性别计算每部电影的平均得分,我们可以使用pivot_table方法:
mean_ratings = data.pivot_table('rating', index='title',columns='gender', aggfunc='mean')
mean_ratings[:5]
gender F M
title
$1,000,000 Duck (1971) 3.375000 2.761905
'Night Mother (1986) 3.388889 3.352941
'Til There Was You (1997) 2.675676 2.733333
'burbs, The (1989) 2.793478 2.962085
...And Justice for All (1979) 3.828571 3.689024
该操作产生了另一个DataFrame,其内容为电影平均得分,行标为电影名称(索引),列标为性别。现在,我打算过滤掉评分数据不够250条的电影(随便选的一个数字)。为了达到这个目的,我先对title进行分组,然后利用size()得到一个含有各电影分组大小的Series对象:
ratings_by_title = data.groupby('title').size()
ratings_by_title[:10]
title
$1,000,000 Duck (1971) 37
'Night Mother (1986) 70
'Til There Was You (1997) 52
'burbs, The (1989) 303
...And Justice for All (1979) 199
1-900 (1994) 2
10 Things I Hate About You (1999) 700
101 Dalmatians (1961) 565
101 Dalmatians (1996) 364
12 Angry Men (1957) 616
dtype: int64
active_titles = ratings_by_title.index[ratings_by_title >= 250]
active_titles
Index([''burbs, The (1989)', '10 Things I Hate About You (1999)',
'101 Dalmatians (1961)', '101 Dalmatians (1996)', '12 Angry Men (1957)',
'13th Warrior, The (1999)', '2 Days in the Valley (1996)',
'20,000 Leagues Under the Sea (1954)', '2001: A Space Odyssey (1968)',
'2010 (1984)',
...
'X-Men (2000)', 'Year of Living Dangerously (1982)',
'Yellow Submarine (1968)', 'You've Got Mail (1998)',
'Young Frankenstein (1974)', 'Young Guns (1988)',
'Young Guns II (1990)', 'Young Sherlock Holmes (1985)',
'Zero Effect (1998)', 'eXistenZ (1999)'],
dtype='object', name='title', length=1216)
标题索引中含有评分数据大于250条的电影名称,然后我们就可以据此从前面的mean_ratings中选取所需的行了:
#Select rows on the index
mean_ratings = mean_ratings.loc[active_titles]
mean_ratings
gender F M
title
'burbs, The (1989) 2.793478 2.962085
10 Things I Hate About You (1999) 3.646552 3.311966
101 Dalmatians (1961) 3.791444 3.500000
101 Dalmatians (1996) 3.240000 2.911215
12 Angry Men (1957) 4.184397 4.328421
... ... ...
Young Guns (1988) 3.371795 3.425620
Young Guns II (1990) 2.934783 2.904025
Young Sherlock Holmes (1985) 3.514706 3.363344
Zero Effect (1998) 3.864407 3.723140
eXistenZ (1999) 3.098592 3.289086
[1216 rows x 2 columns]
为了了解女性观众最喜欢的电影,我们可以对F列降序排列:
top_female_ratings = mean_ratings.sort_values(by='F', ascending=False)
top_female_ratings[:10]
gender F M
title
Close Shave, A (1995) 4.644444 4.473795
Wrong Trousers, The (1993) 4.588235 4.478261
Sunset Blvd. (a.k.a. Sunset Boulevard) (1950) 4.572650 4.464589
Wallace & Gromit: The Best of Aardman Animation... 4.563107 4.385075
Schindler's List (1993) 4.562602 4.491415
Shawshank Redemption, The (1994) 4.539075 4.560625
Grand Day Out, A (1992) 4.537879 4.293255
To Kill a Mockingbird (1962) 4.536667 4.372611
Creature Comforts (1990) 4.513889 4.272277
Usual Suspects, The (1995) 4.513317 4.518248
计算评分分歧
假设我们想要找出男性和女性观众分歧最大的电影。一个办法是给mean_ratings加上一个用于存放平均得分之差的列,并对其进行排序:
mean_ratings['diff'] = mean_ratings['M'] - mean_ratings['F']
按"diff"排序即可得到分歧最大且女性观众更喜欢的电影:
sorted_by_diff = mean_ratings.sort_values(by='diff')
sorted_by_diff[:10]
gender F M diff
title
Dirty Dancing (1987) 3.790378 2.959596 -0.830782
Jumpin' Jack Flash (1986) 3.254717 2.578358 -0.676359
Grease (1978) 3.975265 3.367041 -0.608224
Little Women (1994) 3.870588 3.321739 -0.548849
Steel Magnolias (1989) 3.901734 3.365957 -0.535777
Anastasia (1997) 3.800000 3.281609 -0.518391
Rocky Horror Picture Show, The (1975) 3.673016 3.160131 -0.512885
Color Purple, The (1985) 4.158192 3.659341 -0.498851
Age of Innocence, The (1993) 3.827068 3.339506 -0.487561
Free Willy (1993) 2.921348 2.438776 -0.482573
对排序结果反序并取出前10行,得到的则是男性观众更喜欢的电影:
#Reverse order of rows, take first 10 rows
sorted_by_diff[::-1][:10]
gender F M diff
title
Good, The Bad and The Ugly, The (1966) 3.494949 4.221300 0.726351
Kentucky Fried Movie, The (1977) 2.878788 3.555147 0.676359
Dumb & Dumber (1994) 2.697987 3.336595 0.638608
Longest Day, The (1962) 3.411765 4.031447 0.619682
Cable Guy, The (1996) 2.250000 2.863787 0.613787
Evil Dead II (Dead By Dawn) (1987) 3.297297 3.909283 0.611985
Hidden, The (1987) 3.137931 3.745098 0.607167
Rocky III (1982) 2.361702 2.943503 0.581801
Caddyshack (1980) 3.396135 3.969737 0.573602
For a Few Dollars More (1965) 3.409091 3.953795 0.544704
如果只是想要找出分歧最大的电影(不考虑性别因素),则可以计算得分数据的方差或标准差:
#Standard deviation of rating grouped by title
rating_std_by_title = data.groupby('title')['rating'].std()
#Filter down to active_titles
rating_std_by_title = rating_std_by_title.loc[active_titles]
#Order Series by value in descending order
rating_std_by_title.sort_values(ascending=False)[:10]
title
Dumb & Dumber (1994) 1.321333
Blair Witch Project, The (1999) 1.316368
Natural Born Killers (1994) 1.307198
Tank Girl (1995) 1.277695
Rocky Horror Picture Show, The (1975) 1.260177
Eyes Wide Shut (1999) 1.259624
Evita (1996) 1.253631
Billy Madison (1995) 1.249970
Fear and Loathing in Las Vegas (1998) 1.246408
Bicentennial Man (1999) 1.245533
Name: rating, dtype: float64
可能你已经注意到了,电影分类是以竖线(|)分隔的字符串形式给出的。如果想对电影分类进行分析的话,就需要先将其转换成更有用的形式才行。
1880-2010年间全美婴儿姓名
美国社会保障总署(SSA)提供了一份从1880年到现在的婴儿名字频率数据。
我们要做一些数据规整才能加载这个数据集,这么做就会产生一个如下的DataFrame:
names.head(10)
name sex births year
0 Mary F 7065 1880
1 Anna F 2604 1880
2 Emma F 2003 1880
3 Elizabeth F 1939 1880
4 Minnie F 1746 1880
5 Margaret F 1578 1880
6 Ida F 1472 1880
7 Alice F 1414 1880
8 Bertha F 1320 1880
9 Sarah F 1288 1880
你可以用这个数据集做很多事,例如:
- 计算指定名字(可以是你自己的,也可以是别人的)的年度比例。
- 计算某个名字的相对排名。
- 计算各年度最流行的名字,以及增长或减少最快的名字。
- 分析名字趋势:元音、辅音、长度、总体多样性、拼写变化、首尾字母等。
- 分析外源性趋势:圣经中的名字、名人、人口结构变化等。
利用前面介绍过的那些工具,这些分析工作都能很轻松地完成,我会讲解其中的一些。
到编写本书时为止,美国社会保障总署将该数据库按年度制成了多个数据文件,其中给出了每个性别/名字组合的出生总数。
下载"National data"文件names.zip,解压后的目录中含有一组文件(如yob1880.txt)。我用UNIX的head命令查看了其中一个文件的前10行(在Windows上,你可以用more命令,或直接在文本编辑器中打开):
!head -n 10 datasets/babynames/yob1880.txt
Mary,F,7065
Anna,F,2604
Emma,F,2003
Elizabeth,F,1939
Minnie,F,1746
Margaret,F,1578
Ida,F,1472
Alice,F,1414
Bertha,F,1320
Sarah,F,1288
由于这是一个非常标准的以逗号隔开的格式,所以可以用pandas.read_csv将其加载到DataFrame中:
import pandas as pd
names1880 =pd.read_csv('datasets/babynames/yob1880.txt',names=['name', 'sex', 'births'])
names1880
name sex births
0 Mary F 7065
1 Anna F 2604
2 Emma F 2003
3 Elizabeth F 1939
4 Minnie F 1746
... ... .. ...
1995 Woodie M 5
1996 Worthy M 5
1997 Wright M 5
1998 York M 5
1999 Zachariah M 5
[2000 rows x 3 columns]
这些文件中仅含有当年出现超过5次的名字。为了简单起见,我们可以用births列的sex分组小计表示该年度的births总计:
names1880.groupby('sex').births.sum()
sex
F 90993
M 110493
Name: births, dtype: int64
由于该数据集按年度被分隔成了多个文件,所以第一件事情就是要将所有数据都组装到一个DataFrame里面,并加上一个year字段。使用pandas.concat即可达到这个目的:
years = range(1880, 2011)
pieces = []
columns = ['name', 'sex', 'births']
for year in years:
path = 'datasets/babynames/yob%d.txt' % year
frame = pd.read_csv(path, names=columns)
frame['year'] = year
pieces.append(frame)
#Concatenate everything into a single DataFrame
names = pd.concat(pieces, ignore_index=True)
这里需要注意几件事情。第一,concat默认是按行将多个DataFrame组合到一起的;第二,必须指定ignore_index=True,因为我们不希望保留read_csv所返回的原始行号。现在我们得到了一个非常大的DataFrame,它含有全部的名字数据:
names
name sex births year
0 Mary F 7065 1880
1 Anna F 2604 1880
2 Emma F 2003 1880
3 Elizabeth F 1939 1880
4 Minnie F 1746 1880
... ... .. ... ...
1690779 Zymaire M 5 2010
1690780 Zyonne M 5 2010
1690781 Zyquarius M 5 2010
1690782 Zyran M 5 2010
1690783 Zzyzx M 5 2010
[1690784 rows x 4 columns]
有了这些数据之后,我们就可以利用groupby或pivot_table在year和sex级别上对其进行聚合了,如下图所示:
total_births = names.pivot_table('births', index='year',columns='sex', aggfunc=sum)
total_births.tail()
sex F M
year
2006 1896468 2050234
2007 1916888 2069242
2008 1883645 2032310
2009 1827643 1973359
2010 1759010 1898382
total_births.plot(title='Total births by sex and year')
下面我们来插入一个prop列,用于存放指定名字的婴儿数相对于总出生数的比例。prop值为0.02表示每100名婴儿中有2名取了当前这个名字。因此,我们先按year和sex分组,然后再将新列加到各个分组上:
def add_prop(group):
group['prop'] = group.births / group.births.sum()
return group
names = names.groupby(['year', 'sex']).apply(add_prop)
现在,完整的数据集就有了下面这些列:
names
name sex births year prop
0 Mary F 7065 1880 0.077643
1 Anna F 2604 1880 0.028618
2 Emma F 2003 1880 0.022013
3 Elizabeth F 1939 1880 0.021309
4 Minnie F 1746 1880 0.019188
... ... .. ... ... ...
1690779 Zymaire M 5 2010 0.000003
1690780 Zyonne M 5 2010 0.000003
1690781 Zyquarius M 5 2010 0.000003
1690782 Zyran M 5 2010 0.000003
1690783 Zzyzx M 5 2010 0.000003
[1690784 rows x 5 columns]
在执行这样的分组处理时,一般都应该做一些有效性检查,比如验证所有分组的prop的总和是否为1:
names.groupby(['year', 'sex']).prop.sum()
year sex
1880 F 1.0
M 1.0
1881 F 1.0
M 1.0
1882 F 1.0
...
2008 M 1.0
2009 F 1.0
M 1.0
2010 F 1.0
M 1.0
Name: prop, Length: 262, dtype: float64
工作完成。为了便于实现更进一步的分析,我需要取出该数据的一个子集:每对sex/year组合的前1000个名字。这又是一个分组操作:
def get_top1000(group):
return group.sort_values(by='births', ascending=False)[:1000]
grouped = names.groupby(['year', 'sex'])
top1000 = grouped.apply(get_top1000)
#Drop the group index, not needed
top1000.reset_index(inplace=True, drop=True)
如果你喜欢DIY的话,也可以这样:
pieces = []
for year, group in names.groupby(['year', 'sex']):
pieces.append(group.sort_values(by='births', ascending=False)[:1000])
top1000 = pd.concat(pieces, ignore_index=True)
现在的结果数据集就小多了:
top1000
name sex births year prop
0 Mary F 7065 1880 0.077643
1 Anna F 2604 1880 0.028618
2 Emma F 2003 1880 0.022013
3 Elizabeth F 1939 1880 0.021309
4 Minnie F 1746 1880 0.019188
... ... .. ... ... ...
261872 Camilo M 194 2010 0.000102
261873 Destin M 194 2010 0.000102
261874 Jaquan M 194 2010 0.000102
261875 Jaydan M 194 2010 0.000102
261876 Maxton M 193 2010 0.000102
[261877 rows x 5 columns]
接下来的数据分析工作就针对这个top1000数据集了。
分析命名趋势
有了完整的数据集和刚才生成的top1000数据集,我们就可以开始分析各种命名趋势了。首先将前1000个名字分为男女两个部分:
boys = top1000[top1000.sex == 'M']
girls = top1000[top1000.sex == 'F']
这是两个简单的时间序列,只需稍作整理即可绘制出相应的图表(比如每年叫做John和Mary的婴儿数)。我们先生成一张按year和name统计的总出生数透视表:
total_births = top1000.pivot_table('births', index='year',columns='name',aggfunc=sum)
现在,我们用DataFrame的plot方法绘制几个名字的曲线图(见下图):
total_births.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 131 entries, 1880 to 2010
Columns: 6868 entries, Aaden to Zuri
dtypes: float64(6868)
memory usage: 6.9 MB
subset = total_births[['John', 'Harry', 'Mary', 'Marilyn']]
subset.plot(subplots=True, figsize=(12, 10), grid=False,title="Number of births per year")
从图中可以看出,这几个名字在美国人民的心目中已经风光不再了。但事实并非如此简单,我们在下一节中就能知道是怎么一回事了。
评估命名多样性的增长
一种解释是父母愿意给小孩起常见的名字越来越少。这个假设可以从数据中得到验证。一个办法是计算最流行的1000个名字所占的比例,我按year和sex进行聚合并绘图(见下图):
table = top1000.pivot_table('prop', index='year',columns='sex', aggfunc=sum)
table.plot(title='Sum of table1000.prop by year and sex',yticks=np.linspace(0, 1.2, 13), xticks=range(1880, 2020, 10))
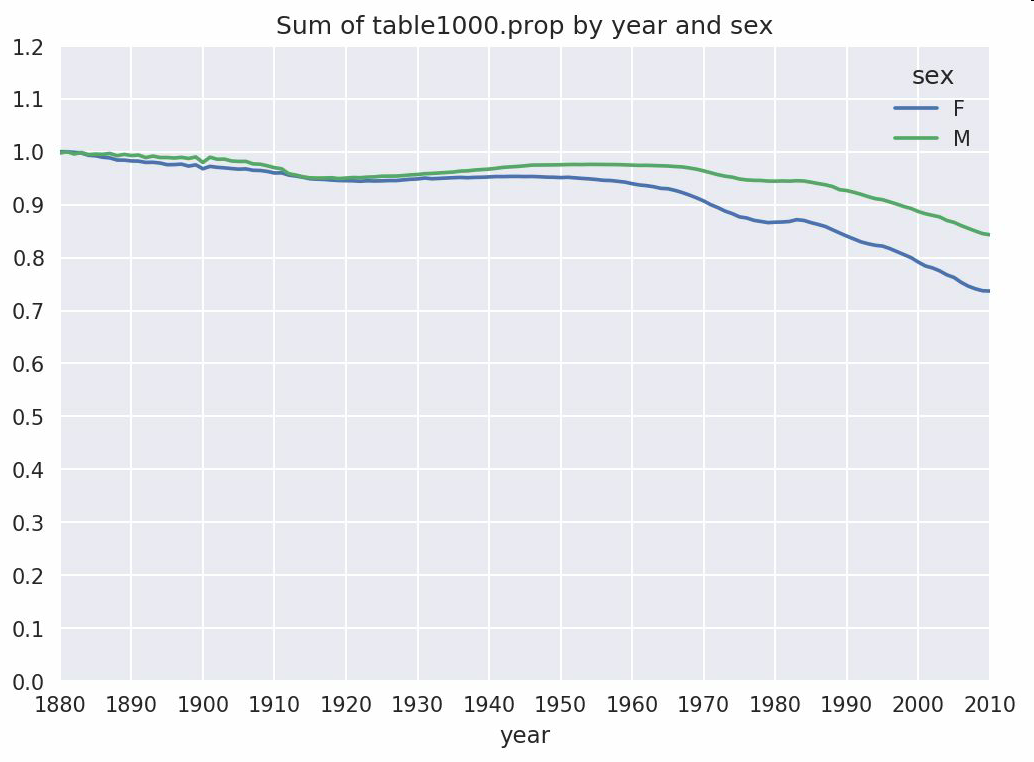
从图中可以看出,名字的多样性确实出现了增长(前1000项的比例降低)。另一个办法是计算占总出生人数前50%的不同名字的数量,这个数字不太好计算。我们只考虑2010年男孩的名字:
df = boys[boys.year == 2010]
df
name sex births year prop
260877 Jacob M 21875 2010 0.011523
260878 Ethan M 17866 2010 0.009411
260879 Michael M 17133 2010 0.009025
260880 Jayden M 17030 2010 0.008971
260881 William M 16870 2010 0.008887
... ... .. ... ... ...
261872 Camilo M 194 2010 0.000102
261873 Destin M 194 2010 0.000102
261874 Jaquan M 194 2010 0.000102
261875 Jaydan M 194 2010 0.000102
261876 Maxton M 193 2010 0.000102
[1000 rows x 5 columns]
在对prop降序排列之后,我们想知道前面多少个名字的人数加起来才够50%。虽然编写一个for循环确实也能达到目的,但NumPy有一种更聪明的矢量方式。先计算prop的累计和cumsum,然后再通过searchsorted方法找出0.5应该被插入在哪个位置才能保证不破坏顺序:
prop_cumsum = df.sort_values(by='prop', ascending=False).prop.cumsum()
prop_cumsum[:10]
260877 0.011523
260878 0.020934
260879 0.029959
260880 0.038930
260881 0.047817
260882 0.056579
260883 0.065155
260884 0.073414
260885 0.081528
260886 0.089621
Name: prop, dtype: float64
prop_cumsum.values.searchsorted(0.5)
116
由于数组索引是从0开始的,因此我们要给这个结果加1,即最终结果为117。拿1900年的数据来做个比较,这个数字要小得多:
df = boys[boys.year == 1900]
in1900 = df.sort_values(by='prop', ascending=False).prop.cumsum()
in1900.values.searchsorted(0.5) + 1
25
现在就可以对所有year/sex组合执行这个计算了。按这两个字段进行groupby处理,然后用一个函数计算各分组的这个值:
def get_quantile_count(group, q=0.5):
group = group.sort_values(by='prop', ascending=False)
return group.prop.cumsum().values.searchsorted(q) + 1
diversity = top1000.groupby(['year', 'sex']).apply(get_quantile_count)
diversity = diversity.unstack('sex')
现在,diversity这个DataFrame拥有两个时间序列(每个性别各一个,按年度索引)。如下图所示:
diversity.head()
sex F M
year
1880 38 14
1881 38 14
1882 38 15
1883 39 15
1884 39 16
diversity.plot(title="Number of popular names in top 50%")
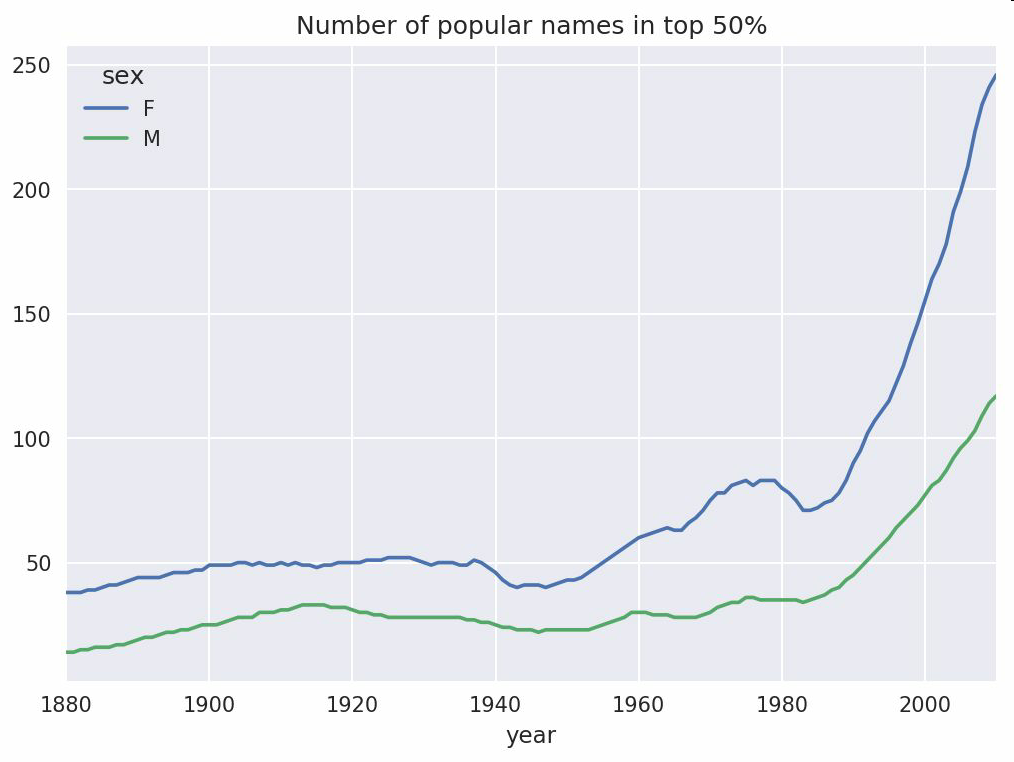
从图中可以看出,女孩名字的多样性总是比男孩的高,而且还在变得越来越高。读者们可以自己分析一下具体是什么在驱动这个多样性(比如拼写形式的变化)。
“最后一个字母”的变革
2007年,一名婴儿姓名研究人员Laura Wattenberg在她自己的网站上指出:近百年来,男孩名字在最后一个字母上的分布发生了显著的变化。为了了解具体的情况,我首先将全部出生数据在年度、性别以及末字母上进行了聚合:
#extract last letter from name column
get_last_letter = lambda x: x[-1]
last_letters = names.name.map(get_last_letter)
last_letters.name = 'last_letter'
table = names.pivot_table('births', index=last_letters,
columns=['sex', 'year'], aggfunc=sum)
然后,我选出具有一定代表性的三年,并输出前面几行:
subtable = table.reindex(columns=[1910, 1960, 2010], level='year')
subtable.head()
sex F M
year 1910 1960 2010 1910 1960 2010
last_letter
a 108376.0 691247.0 670605.0 977.0 5204.0 28438.0
b NaN 694.0 450.0 411.0 3912.0 38859.0
c 5.0 49.0 946.0 482.0 15476.0 23125.0
d 6750.0 3729.0 2607.0 22111.0 262112.0 44398.0
e 133569.0 435013.0 313833.0 28655.0 178823.0 129012.0
接下来我们需要按总出生数对该表进行规范化处理,以便计算出各性别各末字母占总出生人数的比例:
subtable.sum()
sex year
F 1910 396416.0
1960 2022062.0
2010 1759010.0
M 1910 194198.0
1960 2132588.0
2010 1898382.0
dtype: float64
letter_prop = subtable / subtable.sum()
letter_prop
sex F M
year 1910 1960 2010 1910 1960 2010
last_letter
a 0.273390 0.341853 0.381240 0.005031 0.002440 0.014980
b NaN 0.000343 0.000256 0.002116 0.001834 0.020470
c 0.000013 0.000024 0.000538 0.002482 0.007257 0.012181
d 0.017028 0.001844 0.001482 0.113858 0.122908 0.023387
e 0.336941 0.215133 0.178415 0.147556 0.083853 0.067959
... ... ... ... ... ... ...
v NaN 0.000060 0.000117 0.000113
0.000037 0.001434
w 0.000020 0.000031 0.001182 0.006329 0.007711 0.016148
x 0.000015 0.000037 0.000727 0.003965 0.001851 0.008614
y 0.110972 0.152569 0.116828 0.077349 0.160987 0.058168
z 0.002439 0.000659 0.000704 0.000170 0.000184 0.001831
[26 rows x 6 columns]
有了这个字母比例数据之后,就可以生成一张各年度各性别的条形图了,如下图所示:
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
letter_prop['M'].plot(kind='bar', rot=0, ax=axes[0], title='Male')
letter_prop['F'].plot(kind='bar', rot=0, ax=axes[1], title='Female',legend=False)
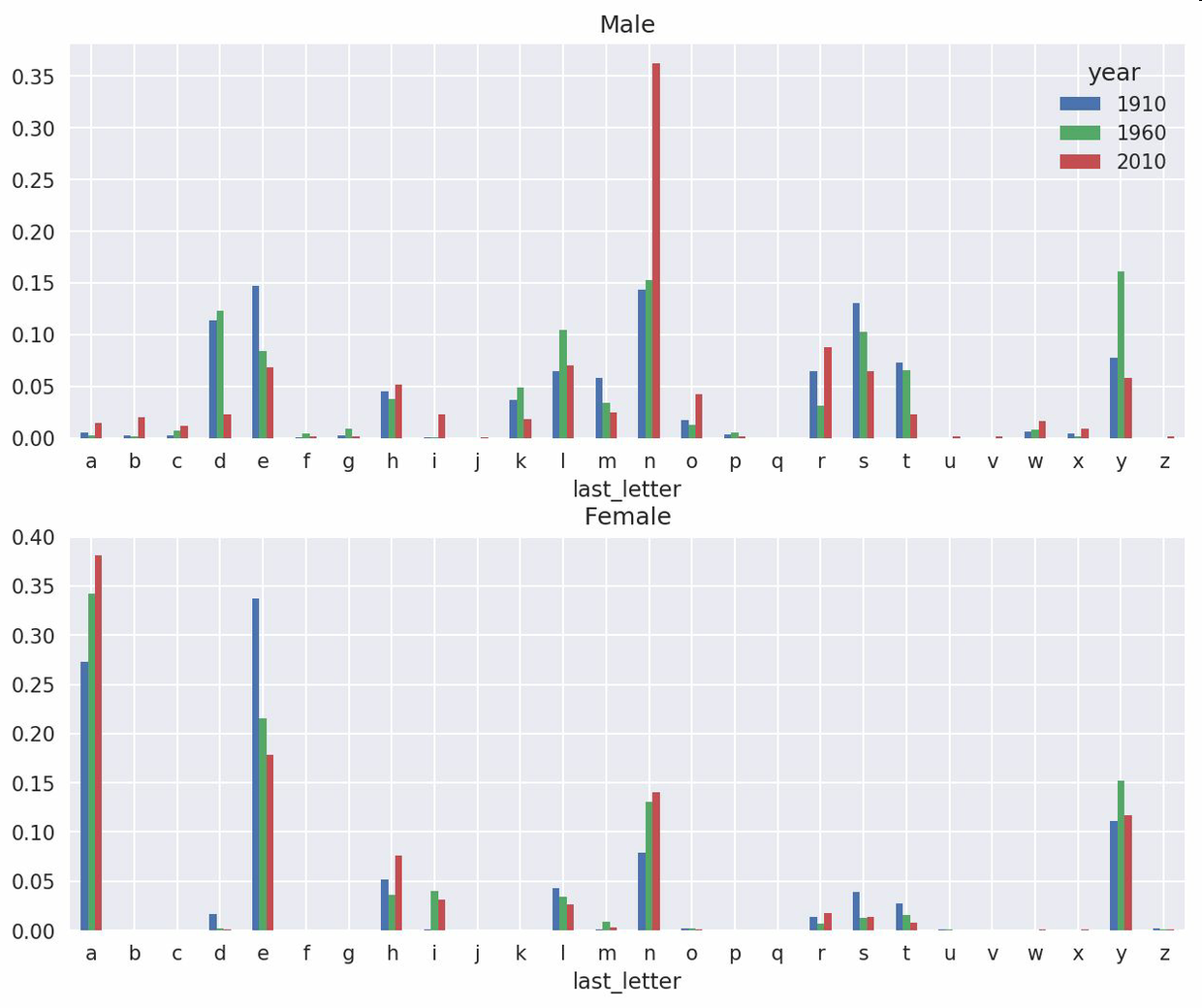
可以看出,从20世纪60年代开始,以字母"n"结尾的男孩名字出现了显著的增长。回到之前创建的那个完整表,按年度和性别对其进行规范化处理,并在男孩名字中选取几个字母,最后进行转置以便将各个列做成一个时间序列:
letter_prop = table / table.sum()
dny_ts = letter_prop.loc[['d', 'n', 'y'], 'M'].T
dny_ts.head()
last_letter d n y
year
1880 0.083055 0.153213 0.075760
1881 0.083247 0.153214 0.077451
1882 0.085340 0.149560 0.077537
1883 0.084066 0.151646 0.079144
1884 0.086120 0.149915 0.080405
有了这个时间序列的DataFrame之后,就可以通过其plot方法绘制出一张趋势图了(如下图所示):
dny_ts.plot()
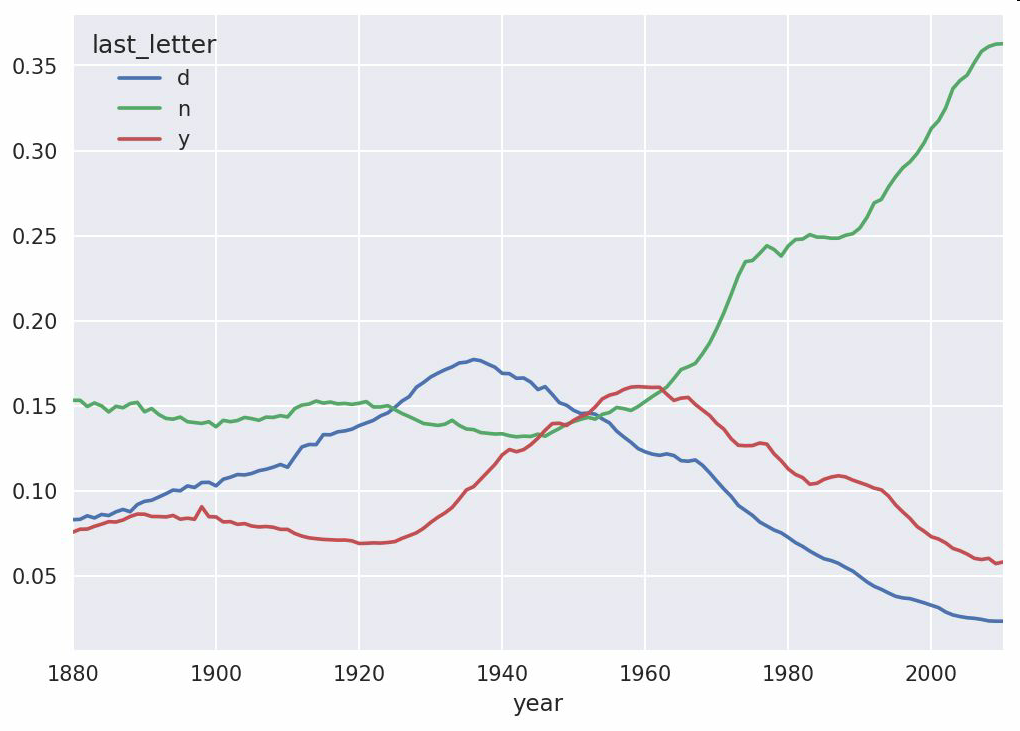
变成女孩名字的男孩名字(以及相反的情况)
另一个有趣的趋势是,早年流行于男孩的名字近年来“变性了”,例如Lesley或Leslie。回到top1000数据集,找出其中以"lesl"开头的一组名字:
all_names = pd.Series(top1000.name.unique())
lesley_like = all_names[all_names.str.lower().str.contains('lesl')]
lesley_like
632 Leslie
2294 Lesley
4262 Leslee
4728 Lesli
6103 Lesly
dtype: object
然后利用这个结果过滤其他的名字,并按名字分组计算出生数以查看相对频率:
filtered = top1000[top1000.name.isin(lesley_like)]
filtered.groupby('name').births.sum()
name
Leslee 1082
Lesley 35022
Lesli 929
Leslie 370429
Lesly 10067
Name: births, dtype: int64
接下来,我们按性别和年度进行聚合,并按年度进行规范化处理:
table = filtered.pivot_table('births', index='year',columns='sex', aggfunc='sum')
table = table.div(table.sum(1), axis=0)
table.tail()
sex F M
year
2006 1.0 NaN
2007 1.0 NaN
2008 1.0 NaN
2009 1.0 NaN
2010 1.0 NaN
最后,就可以轻松绘制一张分性别的年度曲线图了(如下图所示):
table.plot(style={'M': 'k-', 'F': 'k--'})
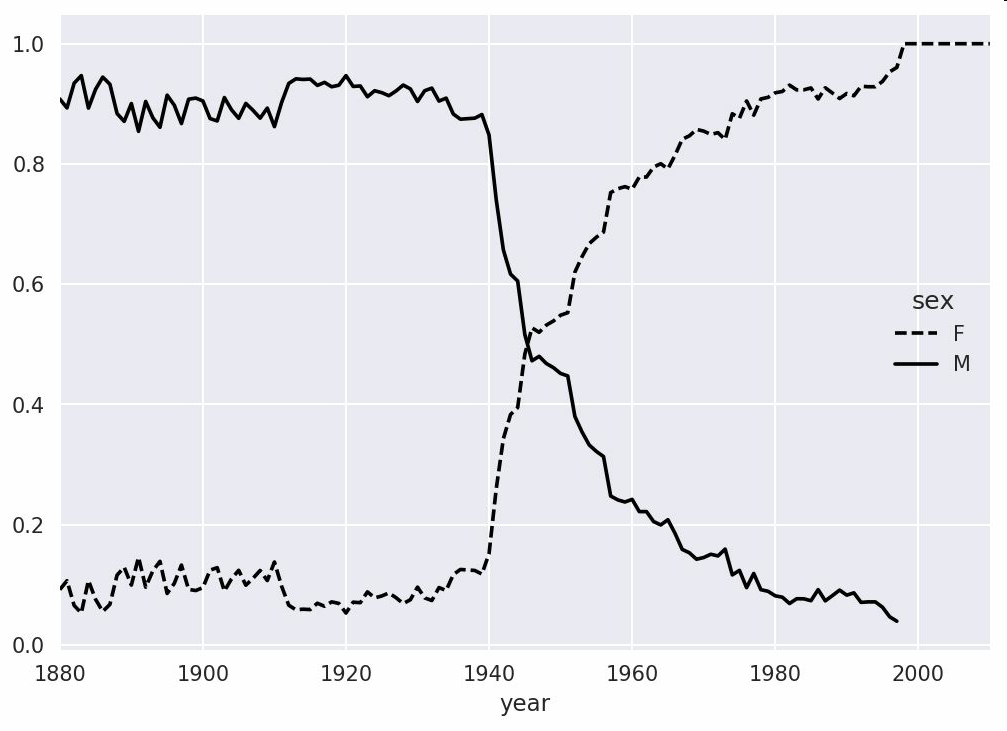
USDA食品数据库
美国农业部(USDA)制作了一份有关食物营养信息的数据库。Ashley Williams制作了该数据的JSON版
{
"id": 21441,
"description": "KENTUCKY FRIED CHICKEN, Fried Chicken, EXTRA CRISPY,
Wing, meat and skin with breading",
"tags": ["KFC"],
"manufacturer": "Kentucky Fried Chicken",
"group": "Fast Foods",
"portions": [
{
"amount": 1,
"unit": "wing, with skin",
"grams": 68.0
},
...
],
"nutrients": [
{
"value": 20.8,
"units": "g",
"description": "Protein",
"group": "Composition"
},
...
]
}
每种食物都带有若干标识性属性以及两个有关营养成分和分量的列表。这种形式的数据不是很适合分析工作,因此我们需要做一些规整化以使其具有更好用的形式。
从上面列举的那个网址下载并解压数据之后,你可以用任何喜欢的JSON库将其加载到Python中。我用的是Python内置的json模块:
import json
db = json.load(open('datasets/usda_food/database.json'))
len(db)
6636
db中的每个条目都是一个含有某种食物全部数据的字典。nutrients字段是一个字典列表,其中的每个字典对应一种营养成分:
db[0].keys()
dict_keys(['id', 'description', 'tags', 'manufacturer', 'group', 'portions', 'nutrients'])
db[0]['nutrients'][0]
{'description': 'Protein',
'group': 'Composition',
'units': 'g',
'value': 25.18}
nutrients = pd.DataFrame(db[0]['nutrients'])
nutrients[:7]
description group units value
0 Protein Composition g 25.18
1 Total lipid (fat) Composition g 29.20
2 Carbohydrate, by difference Composition g 3.06
3 Ash Other g 3.28
4 Energy Energy kcal 376.00
5 Water Composition g 39.28
6 Energy Energy kJ 1573.00
在将字典列表转换为DataFrame时,可以只抽取其中的一部分字段。这里,我们将取出食物的名称、分类、编号以及制造商等信息:
info_keys = ['description', 'group', 'id', 'manufacturer']
info = pd.DataFrame(db, columns=info_keys)
info[:5]
description group id \
0 Cheese, caraway Dairy and Egg Products 1008
1 Cheese, cheddar Dairy and Egg Products 1009
2 Cheese, edam Dairy and Egg Products 1018
3 Cheese, feta Dairy and Egg Products 1019
4 Cheese, mozzarella, part skim milk Dairy and Egg Products 1028
manufacturer
0
1
2
3
4
info.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6636 entries, 0 to 6635
Data columns (total 4 columns):
description 6636 non-null object
group 6636 non-null object
id 6636 non-null int64
manufacturer 5195 non-null object
dtypes: int64(1), object(3)
memory usage: 207.5+ KB
通过value_counts,你可以查看食物类别的分布情况:
pd.value_counts(info.group)[:10]
Vegetables and Vegetable Products 812
Beef Products 618
Baked Products 496
Breakfast Cereals 403
Fast Foods 365
Legumes and Legume Products 365
Lamb, Veal, and Game Products 345
Sweets 341
Pork Products 328
Fruits and Fruit Juices 328
Name: group, dtype: int64
现在,为了对全部营养数据做一些分析,最简单的办法是将所有食物的营养成分整合到一个大表中。我们分几个步骤来实现该目的。首先,将各食物的营养成分列表转换为一个DataFrame,并添加一个表示编号的列,然后将该DataFrame添加到一个列表中。最后通过concat将这些东西连接起来就可以了:
顺利的话,nutrients的结果是:
nutrients
description group units value id
0 Protein Composition g 25.180 1008
1 Total lipid (fat) Composition g 29.200 1008
2 Carbohydrate, by difference Composition g 3.060 1008
3 Ash Other g 3.280 1008
4 Energy Energy kcal 376.000 1008
... ... ...
... ... ...
389350 Vitamin B-12, added Vitamins mcg 0.000 43546
389351 Cholesterol Other mg 0.000 43546
389352 Fatty acids, total saturated Other g 0.072 43546
389353 Fatty acids, total monounsaturated Other g 0.028 43546
389354 Fatty acids, total polyunsaturated Other g 0.041 43546
[389355 rows x 5 columns]
我发现这个DataFrame中无论如何都会有一些重复项,所以直接丢弃就可以了:
nutrients.duplicated().sum() # number of duplicates
14179
nutrients = nutrients.drop_duplicates()
由于两个DataFrame对象中都有"group"和"description",所以为了明确到底谁是谁,我们需要对它们进行重命名:
col_mapping = {'description' : 'food','group' : 'fgroup'}
info = info.rename(columns=col_mapping, copy=False)
info.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6636 entries, 0 to 6635
Data columns (total 4 columns):
food 6636 non-null object
fgroup 6636 non-null object
id 6636 non-null int64
manufacturer 5195 non-null object
dtypes: int64(1), object(3)
memory usage: 207.5+ KB
col_mapping = {'description' : 'nutrient','group' : 'nutgroup'}
nutrients = nutrients.rename(columns=col_mapping, copy=False)
nutrients
nutrient nutgroup units value id
0 Protein Composition g 25.180 1008
1 Total lipid (fat) Composition g 29.200 1008
2 Carbohydrate, by difference Composition g 3.060 1008
3 Ash Other g 3.280 1008
4 Energy Energy kcal 376.000 1008
... ... ... ... ... ...
389350 Vitamin B-12, added Vitamins mcg 0.000 43546
389351 Cholesterol Other mg 0.000 43546
389352 Fatty acids, total saturated Other g 0.072 43546
389353 Fatty acids, total monounsaturated Other g 0.028 43546
389354 Fatty acids, total polyunsaturated Other g 0.041 43546
[375176 rows x 5 columns]
做完这些,就可以将info跟nutrients合并起来:
ndata = pd.merge(nutrients, info, on='id', how='outer')
ndata.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 375176 entries, 0 to 375175
Data columns (total 8 columns):
nutrient 375176 non-null object
nutgroup 375176 non-null object
units 375176 non-null object
value 375176 non-null float64
id 375176 non-null int64
food 375176 non-null object
fgroup 375176 non-null object
manufacturer 293054 non-null object
dtypes: float64(1), int64(1), object(6)
memory usage: 25.8+ MB
ndata.iloc[30000]
nutrient Glycine
nutgroup Amino Acids
units g
value 0.04
id 6158
food Soup, tomato bisque, canned, condensed
fgroup Soups, Sauces, and Gravies
manufacturer
Name: 30000, dtype: object
我们现在可以根据食物分类和营养类型画出一张中位值图(如下图所示):
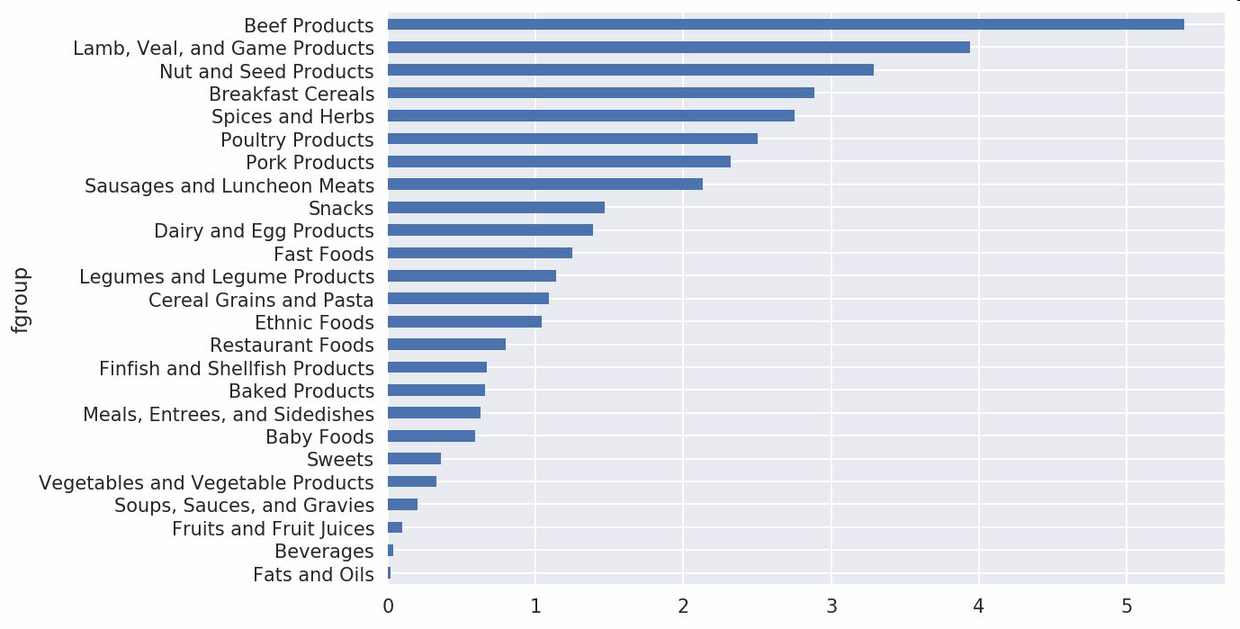
只要稍微动一动脑子,就可以发现各营养成分最为丰富的食物是什么了:
by_nutrient = ndata.groupby(['nutgroup', 'nutrient'])
get_maximum = lambda x: x.loc[x.value.idxmax()]
get_minimum = lambda x: x.loc[x.value.idxmin()]
max_foods = by_nutrient.apply(get_maximum)[['value', 'food']]
#make the food a little smaller
max_foods.food = max_foods.food.str[:50]
由于得到的DataFrame很大,所以不方便在书里面全部打印出来。这里只给出"Amino Acids"营养分组:
max_foods.loc['Amino Acids']['food']
nutrient
Alanine Gelatins, dry powder, unsweetened
Arginine Seeds, sesame flour, low-fat
Aspartic acid Soy protein isolate
Cystine Seeds, cottonseed flour, low fat (glandless)
Glutamic acid Soy protein isolate
...
Serine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Threonine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Tryptophan Sea lion, Steller, meat with fat (Alaska Native)
Tyrosine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Valine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Name: food, Length: 19, dtype: object
2012联邦选举委员会数据库
美国联邦选举委员会发布了有关政治竞选赞助方面的数据。其中包括赞助者的姓名、职业、雇主、地址以及出资额等信息。我们对2012年美国总统大选的数据集比较感兴趣。我在2012年6月下载的数据集是一个150MB的CSV文件(P00000001-ALL.csv),我们先用pandas.read_csv将其加载进来:
fec = pd.read_csv('datasets/fec/P00000001-ALL.csv')
fec.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1001731 entries, 0 to 1001730
Data columns (total 16 columns):
cmte_id 1001731 non-null object
cand_id 1001731 non-null object
cand_nm 1001731 non-null object
contbr_nm 1001731 non-null object
contbr_city 1001712 non-null object
contbr_st 1001727 non-null object
contbr_zip 1001620 non-null object
contbr_employer 988002 non-null object
contbr_occupation 993301 non-null object
contb_receipt_amt 1001731 non-null float64
contb_receipt_dt 1001731 non-null object
receipt_desc 14166 non-null object
memo_cd 92482 non-null object
memo_text 97770 non-null object
form_tp 1001731 non-null object
file_num 1001731 non-null int64
dtypes: float64(1), int64(1), object(14)
memory usage: 122.3+ MB
该DataFrame中的记录如下所示:
fec.iloc[123456]
cmte_id C00431445
cand_id P80003338
cand_nm Obama, Barack
contbr_nm ELLMAN, IRA
contbr_city TEMPE
...
receipt_desc NaN
memo_cd NaN
memo_text NaN
form_tp SA17A
file_num 772372
Name: 123456, Length: 16, dtype: object
你可能已经想出了许多办法从这些竞选赞助数据中抽取有关赞助人和赞助模式的统计信息。我将在接下来的内容中介绍几种不同的分析工作(运用到目前为止已经学到的方法)。
不难看出,该数据中没有党派信息,因此最好把它加进去。通过unique,你可以获取全部的候选人名单:
unique_cands = fec.cand_nm.unique()
unique_cands
array(['Bachmann, Michelle', 'Romney, Mitt', 'Obama, Barack',
"Roemer, Charles E. 'Buddy' III", 'Pawlenty, Timothy',
'Johnson, Gary Earl', 'Paul, Ron', 'Santorum, Rick', 'Cain, Herman',
'Gingrich, Newt', 'McCotter, Thaddeus G', 'Huntsman, Jon',
'Perry, Rick'], dtype=object)
unique_cands[2]
'Obama, Barack'
指明党派信息的方法之一是使用字典:
parties = {'Bachmann, Michelle': 'Republican',
'Cain, Herman': 'Republican',
'Gingrich, Newt': 'Republican',
'Huntsman, Jon': 'Republican',
'Johnson, Gary Earl': 'Republican',
'McCotter, Thaddeus G': 'Republican',
'Obama, Barack': 'Democrat',
'Paul, Ron': 'Republican',
'Pawlenty, Timothy': 'Republican',
'Perry, Rick': 'Republican',
"Roemer, Charles E. 'Buddy' III": 'Republican',
'Romney, Mitt': 'Republican',
'Santorum, Rick': 'Republican'}
现在,通过这个映射以及Series对象的map方法,你可以根据候选人姓名得到一组党派信息:
fec.cand_nm[123456:123461]
123456 Obama, Barack
123457 Obama, Barack
123458 Obama, Barack
123459 Obama, Barack
123460 Obama, Barack
Name: cand_nm, dtype: object
fec.cand_nm[123456:123461].map(parties)
123456 Democrat
123457 Democrat
123458 Democrat
123459 Democrat
123460 Democrat
Name: cand_nm, dtype: object
#Add it as a column
fec['party'] = fec.cand_nm.map(parties)
fec['party'].value_counts()
Democrat 593746
Republican 407985
Name: party, dtype: int64
这里有两个需要注意的地方。第一,该数据既包括赞助也包括退款(负的出资额):
(fec.contb_receipt_amt > 0).value_counts()
True 991475
False 10256
Name: contb_receipt_amt, dtype: int64
为了简化分析过程,我限定该数据集只能有正的出资额:
fec = fec[fec.contb_receipt_amt > 0]
由于Barack Obama和Mitt Romney是最主要的两名候选人,所以我还专门准备了一个子集,只包含针对他们两人的竞选活动的赞助信息:
fec_mrbo = fec[fec.cand_nm.isin(['Obama, Barack','Romney, Mitt'])]
根据职业和雇主统计赞助信息
基于职业的赞助信息统计是另一种经常被研究的统计任务。例如,律师们更倾向于资助民主党,而企业主则更倾向于资助共和党。你可以不相信我,自己看那些数据就知道了。首先,根据职业计算出资总额,这很简单:
fec.contbr_occupation.value_counts()[:10]
RETIRED 233990
INFORMATION REQUESTED 35107
ATTORNEY 34286
HOMEMAKER 29931
PHYSICIAN 23432
INFORMATION REQUESTED PER BEST EFFORTS 21138
ENGINEER 14334
TEACHER 13990
CONSULTANT 13273
PROFESSOR 12555
Name: contbr_occupation, dtype: int64
不难看出,许多职业都涉及相同的基本工作类型,或者同一样东西有多种变体。下面的代码片段可以清理一些这样的数据(将一个职业信息映射到另一个)。注意,这里巧妙地利用了dict.get,它允许没有映射关系的职业也能“通过”:
occ_mapping = {
'INFORMATION REQUESTED PER BEST EFFORTS' : 'NOT PROVIDED',
'INFORMATION REQUESTED' : 'NOT PROVIDED',
'INFORMATION REQUESTED (BEST EFFORTS)' : 'NOT PROVIDED',
'C.E.O.': 'CEO'
}
#If no mapping provided, return x
f = lambda x: occ_mapping.get(x, x)
fec.contbr_occupation = fec.contbr_occupation.map(f)
我对雇主信息也进行了同样的处理:
emp_mapping = {
'INFORMATION REQUESTED PER BEST EFFORTS' : 'NOT PROVIDED',
'INFORMATION REQUESTED' : 'NOT PROVIDED',
'SELF' : 'SELF-EMPLOYED',
'SELF EMPLOYED' : 'SELF-EMPLOYED',
}
#If no mapping provided, return x
f = lambda x: emp_mapping.get(x, x)
fec.contbr_employer = fec.contbr_employer.map(f)
现在,你可以通过pivot_table根据党派和职业对数据进行聚合,然后过滤掉总出资额不足200万美元的数据:
by_occupation = fec.pivot_table('contb_receipt_amt',index='contbr_occupation',columns='party', aggfunc='sum')
over_2mm = by_occupation[by_occupation.sum(1) > 2000000]
over_2mm
party Democrat Republican
contbr_occupation
ATTORNEY 11141982.97 7.477194e+06
CEO 2074974.79 4.211041e+06
CONSULTANT 2459912.71 2.544725e+06
ENGINEER 951525.55 1.818374e+06
EXECUTIVE 1355161.05 4.138850e+06
... ... ...
PRESIDENT 1878509.95 4.720924e+06
PROFESSOR 2165071.08 2.967027e+05
REAL ESTATE 528902.09 1.625902e+06
RETIRED 25305116.38 2.356124e+07
SELF-EMPLOYED 672393.40 1.640253e+06
[17 rows x 2 columns]
把这些数据做成柱状图看起来会更加清楚('barh'表示水平柱状图,如下图所示):
over_2mm.plot(kind='barh')
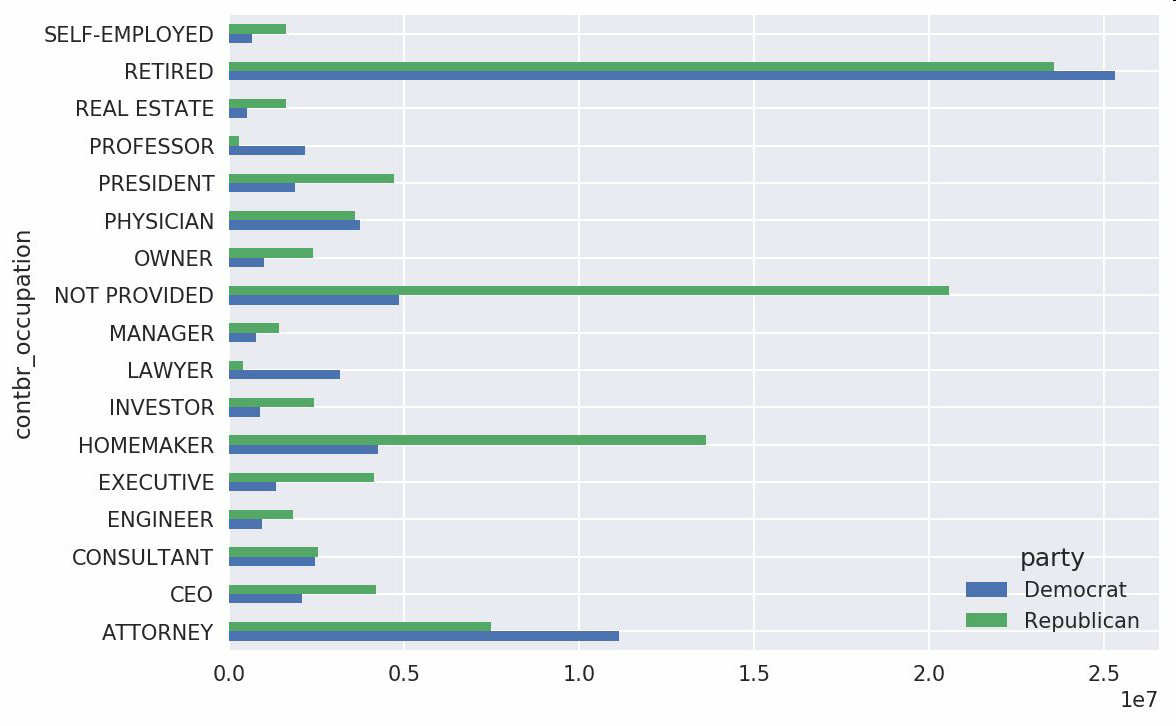
你可能还想了解一下对Obama和Romney总出资额最高的职业和企业。为此,我们先对候选人进行分组,然后使用本章前面介绍的类似top的方法:
def get_top_amounts(group, key, n=5):
totals = group.groupby(key)['contb_receipt_amt'].sum()
return totals.nlargest(n)
然后根据职业和雇主进行聚合:
grouped = fec_mrbo.groupby('cand_nm')
grouped.apply(get_top_amounts, 'contbr_occupation', n=7)
cand_nm contbr_occupation
Obama, Barack RETIRED 25305116.38
ATTORNEY 11141982.97
INFORMATION REQUESTED 4866973.96
HOMEMAKER 4248875.80
PHYSICIAN 3735124.94
...
Romney, Mitt HOMEMAKER 8147446.22
ATTORNEY 5364718.82
PRESIDENT 2491244.89
EXECUTIVE 2300947.03
C.E.O. 1968386.11
Name: contb_receipt_amt, Length: 14, dtype: float64
grouped.apply(get_top_amounts, 'contbr_employer', n=10)
cand_nm contbr_employer
Obama, Barack RETIRED 22694358.85
SELF-EMPLOYED 17080985.96
NOT EMPLOYED 8586308.70
INFORMATION REQUESTED 5053480.37
HOMEMAKER 2605408.54
...
Romney, Mitt CREDIT SUISSE 281150.00
MORGAN STANLEY 267266.00
GOLDMAN SACH & CO. 238250.00
BARCLAYS CAPITAL 162750.00
H.I.G. CAPITAL 139500.00
Name: contb_receipt_amt, Length: 20, dtype: float64
对出资额分组
还可以对该数据做另一种非常实用的分析:利用cut函数根据出资额的大小将数据离散化到多个面元中:
bins = np.array([0, 1, 10, 100, 1000, 10000,100000, 1000000, 10000000])
labels = pd.cut(fec_mrbo.contb_receipt_amt, bins)
labels
411 (10, 100]
412 (100, 1000]
413 (100, 1000]
414 (10, 100]
415 (10, 100]
...
701381 (10, 100]
701382 (100, 1000]
701383 (1, 10]
701384 (10, 100]
701385 (100, 1000]
Name: contb_receipt_amt, Length: 694282, dtype: category
Categories (8, interval[int64]): [(0, 1] < (1, 10] < (10, 100] < (100, 1000] < (1
000, 10000] <
(10000, 100000] < (100000, 1000000] < (1000000,
10000000]]
现在可以根据候选人姓名以及面元标签对奥巴马和罗姆尼数据进行分组,以得到一个柱状图:
grouped = fec_mrbo.groupby(['cand_nm', labels])
grouped.size().unstack(0)
cand_nm Obama, Barack Romney, Mitt
contb_receipt_amt
(0, 1] 493.0 77.0
(1, 10] 40070.0 3681.0
(10, 100] 372280.0 31853.0
(100, 1000] 153991.0 43357.0
(1000, 10000] 22284.0 26186.0
(10000, 100000] 2.0 1.0
(100000, 1000000] 3.0 NaN
(1000000, 10000000] 4.0 NaN
从这个数据中可以看出,在小额赞助方面,Obama获得的数量比Romney多得多。你还可以对出资额求和并在面元内规格化,以便图形化显示两位候选人各种赞助额度的比例(见下图):
bucket_sums = grouped.contb_receipt_amt.sum().unstack(0)
normed_sums = bucket_sums.div(bucket_sums.sum(axis=1), axis=0)
normed_sums
cand_nm Obama, Barack Romney, Mitt
contb_receipt_amt
(0, 1] 0.805182 0.194818
(1, 10] 0.918767 0.081233
(10, 100] 0.910769 0.089231
(100, 1000] 0.710176 0.289824
(1000, 10000] 0.447326 0.552674
(10000, 100000] 0.823120 0.176880
(100000, 1000000] 1.000000 NaN
(1000000, 10000000] 1.000000 NaN
normed_sums[:-2].plot(kind='barh')
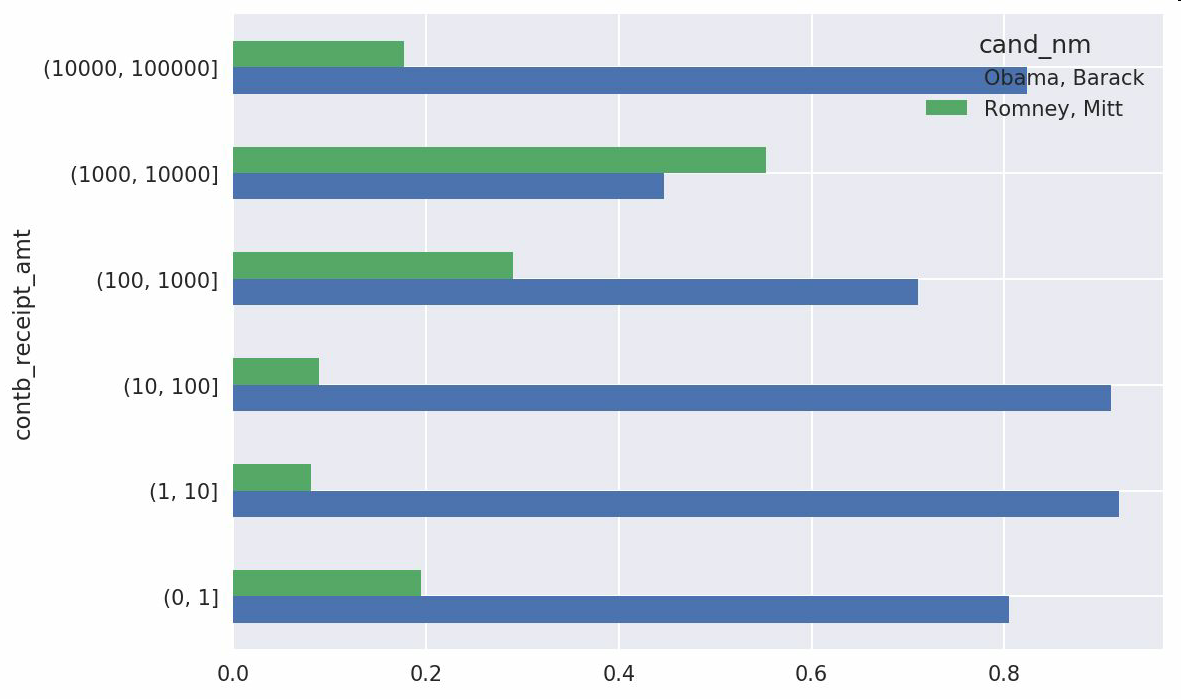
我排除了两个最大的面元,因为这些不是由个人捐赠的。
还可以对该分析过程做许多的提炼和改进。比如说,可以根据赞助人的姓名和邮编对数据进行聚合,以便找出哪些人进行了多次小额捐款,哪些人又进行了一次或多次大额捐款。我强烈建议你下载这些数据并自己摸索一下。
根据州统计赞助信息
根据候选人和州对数据进行聚合是常规操作:
grouped = fec_mrbo.groupby(['cand_nm', 'contbr_st'])
totals = grouped.contb_receipt_amt.sum().unstack(0).fillna(0)
totals = totals[totals.sum(1) > 100000]
totals[:10]
cand_nm Obama, Barack Romney, Mitt
contbr_st
AK 281840.15 86204.24
AL 543123.48 527303.51
AR 359247.28 105556.00
AZ 1506476.98 1888436.23
CA 23824984.24 11237636.60
CO 2132429.49 1506714.12
CT 2068291.26 3499475.45
DC 4373538.80 1025137.50
DE 336669.14 82712.00
FL 7318178.58 8338458.81
如果对各行除以总赞助额,就会得到各候选人在各州的总赞助额比例:
percent = totals.div(totals.sum(1), axis=0)
percent[:10]
cand_nm Obama, Barack Romney, Mitt
contbr_st
AK 0.765778 0.234222
AL 0.507390 0.492610
AR 0.772902 0.227098
AZ 0.443745 0.556255
CA 0.679498 0.320502
CO 0.585970 0.414030
CT 0.371476 0.628524
DC 0.810113 0.189887
DE 0.802776 0.197224
FL 0.467417 0.532583