奇异值分解(《统计学习方法》)
奇异值分解的定义与性质
定义与定理
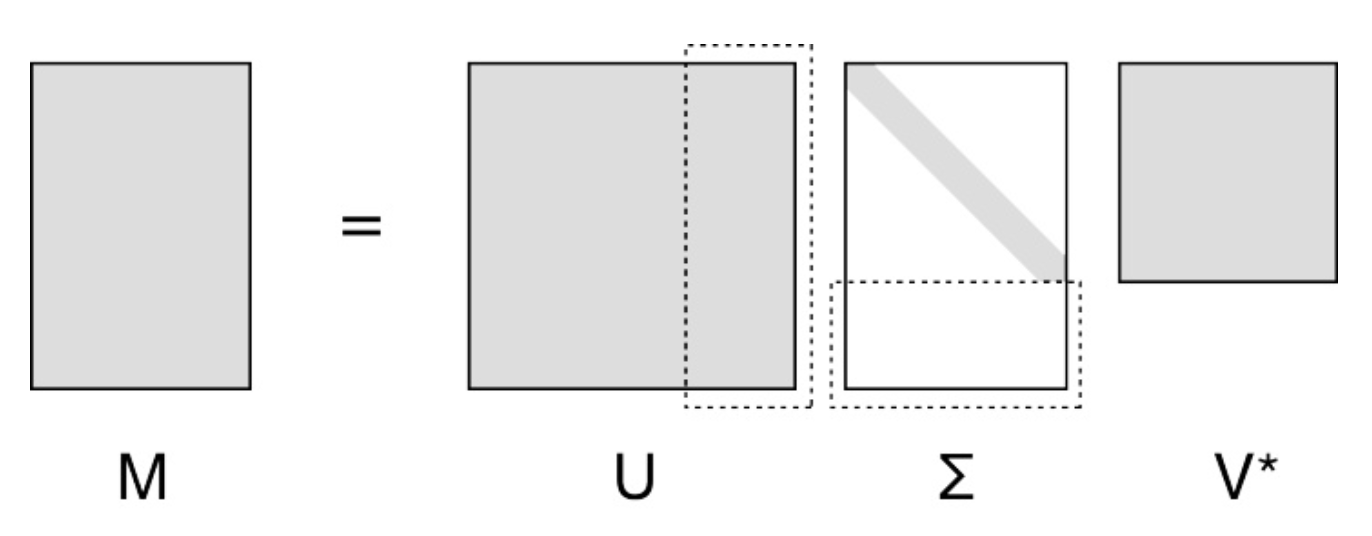
矩阵的奇异值分解是指,将一个非零的m×n实矩阵A,A∈Rm×n,表示为以下三个实矩阵乘积形式的运算,即进行矩阵的因子分解:
A=UΣVT
其中U是m阶正交矩阵(orthogonal matrix),V是n阶正交矩阵,∑是由降序排列的非负的对角线元素组成的m×n矩形对角矩阵(rectangular diagonal matrix),满足
UUT=I
VVT=I
Σ=diag(σ1,σ2,⋯,σp)
σ1⩾σ2⩾⋯⩾σp⩾0
p=min(m,n)
UΣVT称为矩阵A的奇异值分解(singular value decomposition, SVD),σi称为矩阵A的奇异值,U的列向量称为左奇异向量,V的列向量称为右奇异向量。
奇异值分解基本定理:
若A为一m×n实矩阵,A∈Rm×n,则A的奇异值分解存在
A=UΣVT
其中U是m阶正交矩阵,V是n阶正交矩阵,Σ是m×n矩形对角矩阵,其对角线元素非负,且按降序排列。
紧奇异值分解与截断奇异值分解
A=UΣVT又称为矩阵的完全奇异值分解(full singular value decomposition)。实际常用的是奇异值分解的紧凑形式和截断形式。紧奇异值分解是与原始矩阵等秩的奇异值分解,截断奇异值分解是比原始矩阵低秩的奇异值分解。
紧奇异值分解
设有m×n实矩阵A,其秩为rank(A)=r,r⩽min(m,n),则称UrΣrVrT为A的紧奇异值分解(compact singular value decomposition),即:
A=UrΣrVrT
其中Ur是m×r矩阵,Vr是n×r矩阵,Σr是r阶对角矩阵;矩阵Ur由完全奇异值分解中U的前r列,矩阵Vr由V的前r列,矩阵Σr由∑的前r个对角线元素得到。紧奇异值分解的对角矩阵Σr的秩与原始矩阵A的秩相等。
截断奇异值分解
在矩阵的奇异值分解中,只取最大的k个奇异值(k<r,r为矩阵的秩)对应的
部分,就得到矩阵的截断奇异值分解。实际应用中提到矩阵的奇异值分解时,通常指截断奇异值分解。
设A为m×n实矩阵,其秩rank(A)=r,且0<k<r,则称UkΣkVkT为矩阵A的截断奇异值分解(truncated singular value decomposition)
A≈UkΣkVkT
其中Uk是m×k矩阵,Vk是n×k矩阵,Σk是k阶对角矩阵;矩阵Uk由完全奇异值分解中U的前k列,矩阵Vk由V的前k列,矩阵Σk由Σ的前k个对角线元素得到。对角矩阵Σk的秩比原始矩阵A的秩低。
在实际应用中,常常需要对矩阵的数据进行压缩,将其近似表示,奇异值分解提供了一种方法。后面将要叙述,奇异值分解是在平方损失(弗罗贝尼乌斯范数)意义下对矩阵的最优近似。紧奇异值分解对应着无损压缩,截断奇异值分解对应着有损压缩。
几何解释
从线性变换的角度理解奇异值分解,m×n矩阵A表示从n维空间Rn到m维空间Rm的一个线性变换,
T:x→Ax
x∈Rn,Ax∈Rm,x和Ax分别是各自空间的向量。线性变换可以分解为三个简单的变换:一个坐标系的旋转或反射变换、一个坐标轴的缩放变换、另一个坐标系的旋转或反射变换。奇异值定理保证这种分解一定存在。这就是奇异值分解的几何解释。
对矩阵A进行奇异值分解,得到A=UΣVT,V和U都是正交矩阵,所以V的列向量v1,v2,⋯,vn构成Rn空间的一组标准正交基,表示Rn中的正交坐标系的旋转或反射变换;U的列向量u1,u2,⋯,um构成Rm空间的一组标准正交基,表示Rm中的正交坐标系的旋转或反射变换;∑的对角元素σ1,σ2,⋯,σn是一组非负实数,表示Rn中的原始正交坐标系坐标轴的σ1,σ2,⋯,σn倍的缩放变换。
任意一个向量x∈Rn,经过基于A=UΣVT的线性变换,等价于经过坐标系的旋转或反射变换VT,坐标轴的缩放变换∑,以及坐标系的旋转或反射变换U,得到向量Ax∈Rm。下图给出直观的几何解释(见文前彩图)。原始空间的标准正交基(红色与黄色),经过坐标系的旋转变换VT,坐标轴的缩放变换∑(黑色σ1,σ2),坐标系的旋转变换U,得到和经过线性变换A等价的结果。
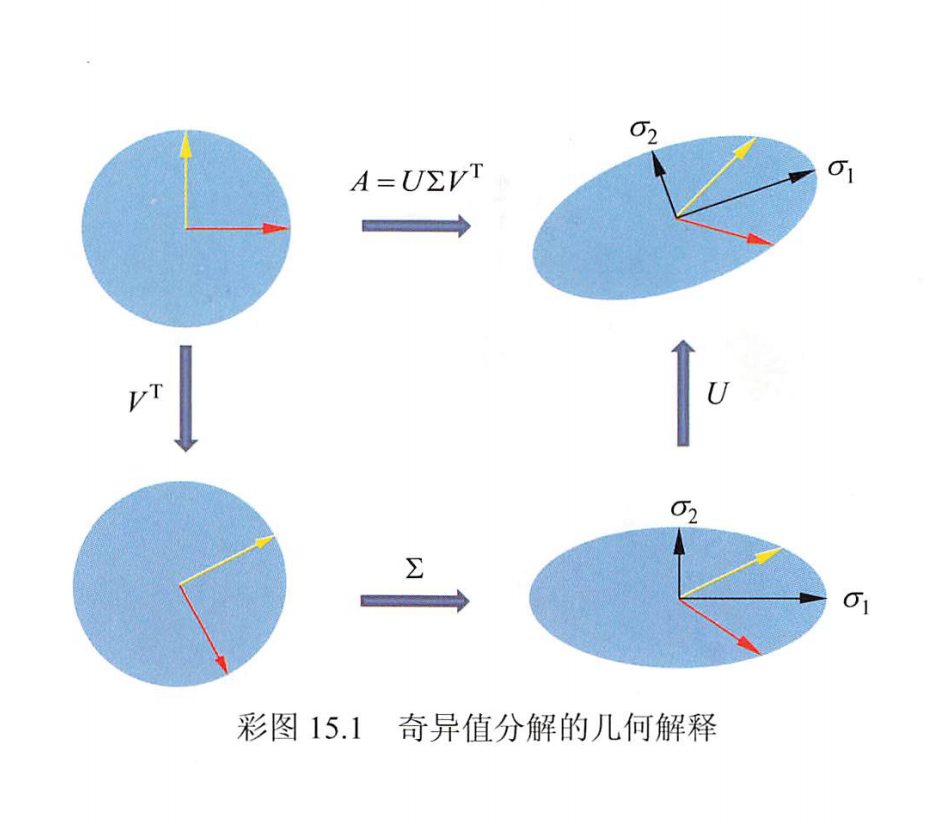
综上,矩阵的奇异值分解也可以看作是将其对应的线性变换分解为旋转变换、缩放变换及旋转变换的组合。根据定理, 这个变换的组合一定存在。
主要性质
- 设矩阵A的奇异值分解为A=UΣVT,则以下关系成立:
ATA=(UΣVT)T(UΣVT)=V(ΣTΣ)VT
AAT=(UΣVT)(UΣVT)T=U(ΣΣT)UT
也就是说,矩阵ATA和AAT的特征分解存在,且可以由矩阵A的奇异值分解的矩阵表示。V的列向量是ATA的特征向量,U的列向量是AAT的特征向量,∑的奇异值是=ATA和AAT的特征值的平方根。
- 在矩阵A的奇异值分解中,奇异值、左奇异向量和右奇异向量之间存在对应关系。
由A=UΣVT易知
AV=UΣ
比较这一等式两端的第j列,得到:
Avj=σjuj,j=1,2,⋯,n
这是矩阵A的右奇异向量和奇异值、左奇异向量的关系。
类似地,由
ATU=VΣT
得到:
ATuj=σjvj,j=1,2,⋯,n
ATuj=0,j=n+1,n+2,⋯,m
这是矩阵A的左奇异向量和奇异值、右奇异向量的关系。
-
矩阵A的奇异值分解中,奇异值σ1,σ2,⋯,σn是唯一的,而矩阵U和V不是唯一的。
-
矩阵A和∑的秩相等,等于正奇异值σi的个数r(包含重复的奇异值)。
-
矩阵A的r个右奇异向量v1,v2,⋯,vr构成AT的值域R(AT)的一组标准正交基。因为矩阵AT是从Rm映射到Rn的线性变换,则AT的值域R(AT)和AT的列空间是相同的,v1,v2,⋯,vr是AT的一组标准正交基,因而也是R(AT)的一组标准正交基。
矩阵A的n−r个右奇异向量vr+1,vr+2,⋯,vn构成A的零空间N(A)的一组标准正交基。
矩阵A的r个左奇异向量u1,u2,⋯,ur构成值域R(A)的一组标准正交基。
矩阵A的m−r个左奇异向量ur+1,ur+2,⋯,um构成AT的零空间N(AT)的一组标准正交基。
奇异值分解的计算
奇异值分解基本定理证明的过程蕴含了奇异值分解的计算方法。矩阵A的奇异值分解可以通过求对称矩阵ATA的特征值和特征向量得到。ATA的特征向量构成正交矩阵V的列,ATA的特征值λjλj的平方根为奇异值σi,即
σj=λj,j=1,2,⋯,n
对其由大到小排列作为对角线元素,构成对角矩阵∑;求正奇异值对应的左奇异向量,再求扩充的AT的标准正交基,构成正交矩阵U的列,从而得到A的奇异值分解A=UΣVT。
给定m×n的矩阵A,可以按照上面的叙述写出矩阵奇异值分解的计算过程。
- 首先求ATA的特征值和特征向量。
计算对称矩阵W=ATA。
求解特征方程
(W−λI)x=0
得到特征值λi,并将特征值由大到小排列:
λ1⩾λ2⩾⋯⩾λn⩾0
将特征值λi(i=1,2,⋯,n)代入特征方程求得对应的特征向量。
- 求n阶正交矩阵V
将特征向量单位化,得到单位特征向量v1,v2,⋯,vn,构成n阶正交矩阵V。
V=[v1v2⋯vn]
- 求m×n对角矩阵∑
计算A的奇异值:
σi=λi,i=1,2,⋯,n
构造m×n矩形对角矩阵Σ,主对角线元素是奇异值,其余元素是零:
Σ=diag(σ1,σ2,⋯,σn)
- 求m阶正交矩阵U
对A的前r个正奇异值,令
uj=σj1Avj,j=1,2,⋯,r
得到:
U1=[u1u2⋯ur]
求AT的零空间的一组标准正交基{ur+1,ur+2,⋯,um},令
U2=[ur+1ur+2⋯um]
并令:
U=[U1U2]
- 得到奇异值分解:
A=UΣVT
奇异值分解与矩阵近似
弗罗贝尼乌斯范数
奇异值分解也是一-种矩阵近似的方法,这个近似是在弗罗贝尼乌斯范数(Frobenius norm)意义下的近似。矩阵的弗罗贝尼乌斯范数是向量的L2范数的直接推广,对应着机器学习中的平方损失函数。
弗罗贝尼乌斯范数:
设矩阵A∈Rm×n,A=[aij]m×n,定义矩阵A的弗罗贝尼乌斯范数为:
∥A∥F=(∑i=1m∑j=1n(aij)2)21
引理:
设矩阵A∈Rm×n,A的奇异值分解为UΣVT,其中Σ=diag(σ1σ2,⋯,σn),则
∥A∥F=(σ12+σ22+⋯+σn2)21
矩阵的最优近似
奇异值分解是在平方损失(弗罗贝尼乌斯范数)意义下对矩阵的最优近似,即数据压缩。
设矩阵A∈Rm×n,矩阵的秩rank(A)=r,并设M为Rm×n中所有秩不超过k的矩阵集合,0<k<r,则存在一个秩为k的矩阵X∈M,使得:
∥A−X∥F=minS∈M∥A−S∥F
称矩阵X为矩阵A在弗罗贝尼乌斯范数意义下的最优近似。
设矩阵A∈Rm×n,矩阵的秩rank(A)=r,有奇异值分解A=UΣVT,并设M为Rm×n中所有秩不超过k的矩阵的集合,0<k<r,若秩为k的矩阵X∈M满足:
∥A−X∥F=minS∈M∥A−S∥F
则:
∥A−X∥F=(σk+12+σk+22+⋯+σn2)21
特别地,若A′=UΣ′VT,其中:
Σ′=⎣⎢⎢⎢⎢⎢⎢⎡σ1⋱0σk00⋱0⎦⎥⎥⎥⎥⎥⎥⎤=[Σk000]
则
∥A−A′∥F=(σk+12+σk+22+⋯+σn2)21=minS∈M∥A−S∥F
在秩不超过k的m×n矩阵的集合中,存在矩阵A的弗罗贝尼乌斯范数意义下的最优近似矩阵X。A′=UΣ′VT是达到最优值的一一个矩阵。
前面定义了矩阵的紧奇异值分解与截断奇异值分解。事实上紧奇异值分解是在弗罗贝尼乌斯范数意义下的无损压缩,截断奇异值分解是有损压缩。截断奇异值分解得到的矩阵的秩为k,通常远小于原始矩阵的秩r,所以是由低秩矩阵实现了对原始矩阵的压缩。
矩阵的外积展开式
下面介绍利用外积展开式对矩阵A的近似。矩阵A的奇异值分解UΣVT也可以由外积形式表示。事实上,若将A的奇异值分解看成矩阵UΣ和VT的乘积,将UΣ按列向量分块,将VT按行向量分块,即得
UΣ=[σ1u1σ2u2⋯σnun]
VT=⎣⎢⎢⎢⎡v1Tv2T⋮vnT⎦⎥⎥⎥⎤
A=σ1u1v1T+σ2u2v2T+⋯+σnunvnT
称为矩阵A的外积展开式,其中ukvkT为m×n矩阵,是列向量uk和行向量vkT的外积,其第i行第j列元素为uk的第i个元素与vkT的第j个元素的乘积。即
uivjT=⎣⎢⎢⎢⎡u1iu2i⋮umi⎦⎥⎥⎥⎤[v1jv2j⋯vnj]=⎣⎢⎢⎢⎡u1iv1ju2iv1j⋮umiv1ju1iv2ju2iv2j⋮umiv2j⋯⋯⋯u1ivnju2ivnj⋮umivnj⎦⎥⎥⎥⎤
A的外积展开式也可以写成下面的形式
A=∑k=1nAk=∑k=1nσkukvkT
其中Ak=σkukvkT是m×n矩阵。
由矩阵A的外积展开式知,若A的秩为n,则
A=σ1u1v1T+σ2u2v2T+⋯+σnunvnT
一般地,设矩阵
Ak=σ1u1v1T+σ2u2v2T+⋯+σkukvkT
则Ak的秩为k,并且Ak是秩为k的矩阵中在弗罗贝尼乌斯范数意义下A的最优近似矩阵。矩阵Ak就是A的截断奇异值分解。
由于通常奇异值σi递减很快,所以k取很小值时,Ak也可以对A有很好的近似。
主成分分析(《统计学习方法》)
主成分分析(principal component analysis, PCA)是一种常用的无监督学习方法,这一方法利用正交变换把由线性相关变量表示的观测数据转换为少数几个由线性无关变量表示的数据,线性无关的变量称为主成分。主成分的个数通常小于原始变量的个数,所以主成分分析属于降维方法。主成分分析主要用于发现数据中的基本结构,即数据中变量之间的关系,是数据分析的有力工具,也用于其他机器学习方法的前处理。
总体主成分分析
基本想法
统计分析中,数据的变量之间可能存在相关性,以致增加了分析的难度。于是,考虑由少数不相关的变量来代替相关的变量,用来表示数据,并且要求能够保留数据中的大部分信息。
主成分分析中,首先对给定数据进行规范化,使得数据每一变量的平均值为 0, 方差为 1。之后对数据进行正交变换,原来由线性相关变量表示的数据,通过正交变换变成由若千个线性无关的新变量表示的数据。新变量是可能的正交变换中变量的方差的和(信息保存)最大的,方差表示在新变量上信息的大小。将新变量依次称为第一主成分、第二主成分等。这就是主成分分析的基本思想。通过主成分分析,可以利用主成分近似地表示原始数据,这可理解为发现数据的“基本结构”;也可以把数据由少数主成分表示,这可理解为对数据降维。
下面给出主成分分析的直观解释。数据集合中的样本由实数空间(正交坐标系)中的点表示,空间的一个坐标轴表示一个变量,规范化处理后得到的数据分布在原点附近。对原坐标系中的数据进行主成分分析等价于进行坐标系旋转变换,将数据投影到新坐标系的坐标轴上;新坐标系的第一坐标轴、第二坐标轴等分别表示第一主成分、第二主成分等,数据在每- -轴上的坐标值的平方表示相应变量的方差;并且,这个坐标系是在所有可能的新的坐标系中,坐标轴上的方差的和最大的。
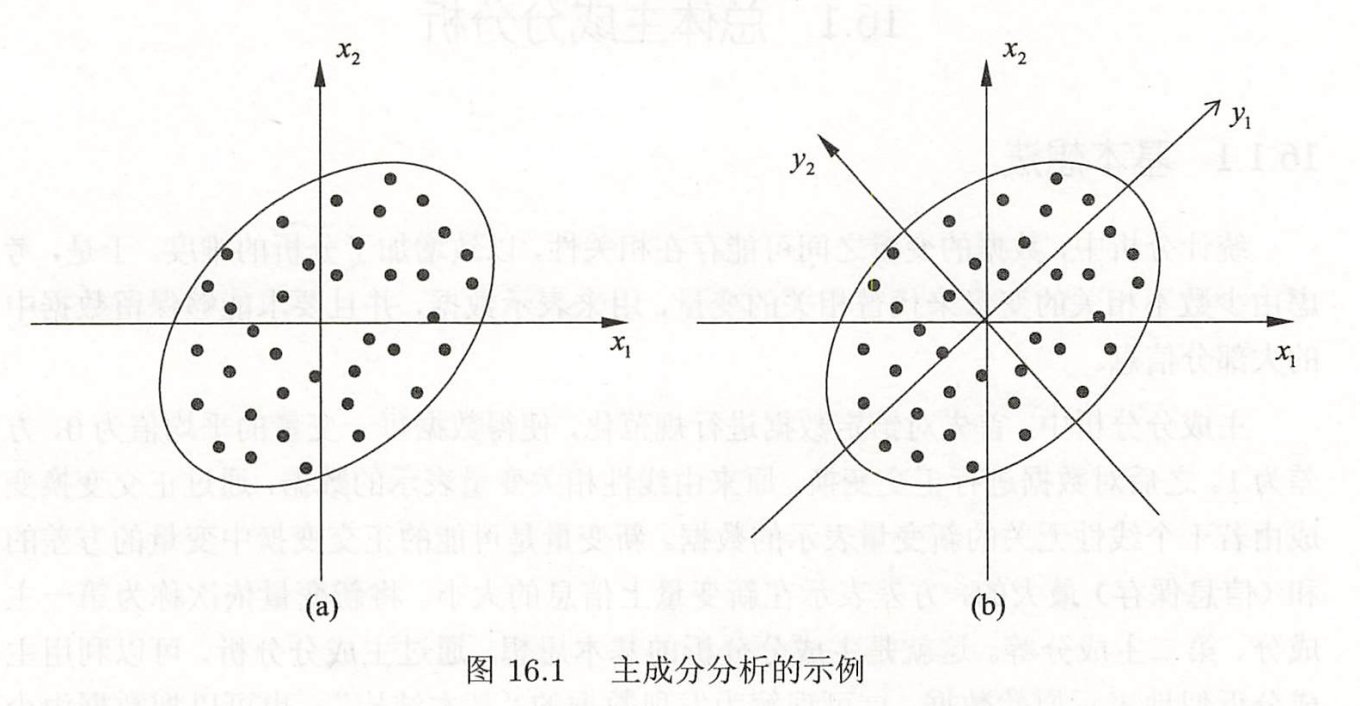
例如,数据由两个变量x1和x2表示,存在于二维空间中,每个点表示一个样本,如下图所示。对数据已做规范化处理,可以看出,这些数据分布在以原点为中心的左下至右上倾斜的椭圆之内。很明显在这个数据中的变量x1和x2是线性相关的,具体地,当知道其中一个变量x1的取值时,对另一个变量x2的预测不是完全随机的,反之亦然。
主成分分析对数据进行正交变换,具体地,对原坐标系进行旋转变换,并将数据在新坐标系表示,如图所示。数据在原坐标系由变量x1 和x2表示,通过正交变换后,在新坐标系里,由变量y1和y2表示。主成分分析选择方差最大的方向(第一主成分)作为新坐标系的第一坐标轴,即y1 轴,在这里意味着选择椭圆的长轴作为新坐标系的第一坐标轴;之后选择与第一坐标轴正交,且方差次之的方向(第二主成分)作为新坐标系的第二坐标轴,即 y2轴,在这里意味着选择椭圆的短轴作为新坐标系的第二坐标轴。在新坐标系里,数据中的变量y1和y2 是线性无关的,当知道其中一个变量 y1的取值时,对另一个变量y2的预测是完全随机的;反之亦然。如果主成分分析只取第一主成分,即新坐标系的y1轴,那么等价于将数据投影在椭圆长轴上,用这个主轴表示数据,将二维空间的数据压缩到一维空间中。
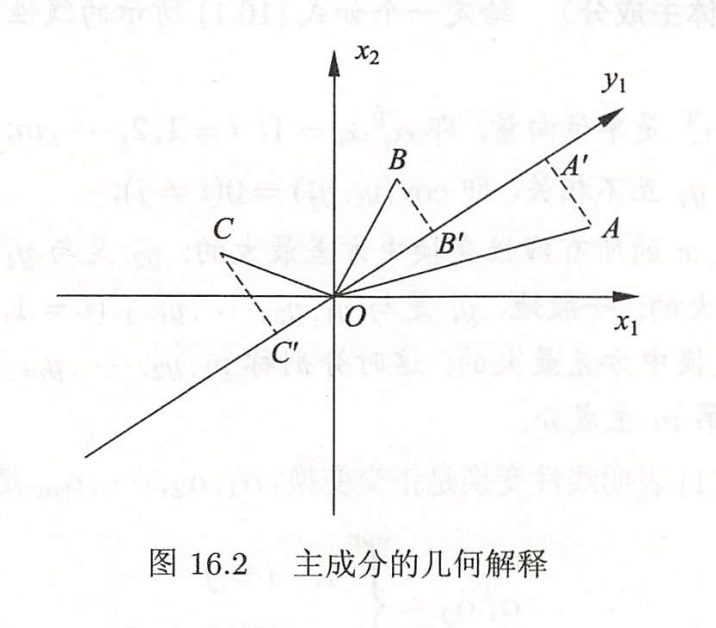
下面再看方差最大的解释。假设有两个变量x1和x2,三个样本点A、B、C,样本分布在由x2和x2轴组成的坐标系中,如图所示。对坐标系进行旋转变换,得到新的坐标轴y1,表示新的变量y1, 样本点A,B,C在y1轴上投影,得到y1轴的坐标值,A′,B′,C′。坐标值的平方和OA′2+OB′2+OC′2表示样本在变量y1比的方差和。主成分分析旨在选取正交变换中方差最大的变量,作为第一主成分,也就是旋转变换中坐标值的平方和最大的轴。注意到旋转变换中样本点到原点的距离的平方和OA2+OB2+OC2保持不变,根据勾股定理,坐标值的平方和OA′2+OB′2+OC′2最大等价于样本点到y1轴的距离的平方和AA′2+BB′2+CC′2最小,所以,等价地,主成分分析在旋转变换中选取离样本点的距离平方和最小的轴,作为第一主成分。第二主成分等的选取,在保证与已选坐标轴正交的条件下,类似地进行。
在数据总体(population)。上进行的主成分分析称为总体主成分分析,在有限样本进行的主成分分析称为样本主成分分析,前者是后者的基础。以下分别予以介绍。
定义和导出
假设 x=(x1,x2,…,xm)T是m维随机变量,其均值向量是μ:
μ=E(x)=(μ1,μ2,⋯,μm)T
协方差矩阵是∑:
Σ=cov(x,x)=E[(x−μ)(x−μ)T]
考虑由m维随机变量x到m维随机变量y=(y1,y2,⋯,ym)T的线性变换:
yi=αiTx=α1ix1+α2ix2+⋯+αmixm
由随机变量的性质可知,
E(yi)=αiTμ,i=1,2,⋯,m
var(yi)=αiTΣαi,i=1,2,⋯,m
cov(yi,yj)=αiTΣαj,i=1,2,⋯,m;j=1,2,⋯,m
下面给出总体主成分的定义。
给定一个如式yi=αiTx=α1ix1+α2ix2+⋯+αmixm所示的线性变换,如果它们满足下列条件:
- 系数向量αiT是单位向量,即αiTαi=1,i=1,2,⋯,m
- 变量yi与yj互不相关,即cov(yi,yj)=0(i=j)
- 变量y1是x的所有线性变换中方差最大的;y2是与y1不相关的x的所有线性变换中方差最大的;一般地,yi是与y1,y2,⋯,yi−1(i=1,2,⋯,m)都不相关的x的所有线性变换中方差最大的;这时分别称y1,y2,⋯,ym为x的第一主成分、第二主成分、。... 第m主成分。
定义中的条件(1) 表明线性变换是正交变换,α1,α2,⋯,αm是其一组标准正交基,
αiTαj={1,0,i=ji=j
条件(2) (3) 给出了一个求主成分的方法:第一步,在x的所有线性变换
α1Tx=∑i=1mαi1xi
中,在α1Tα1=1条件下,求方差最大的,得到x的第一主成分;第二步,在与α1Tx不相关的x的所有线性变换
α2Tx=∑i=1mαi2xi
中,在α2Tα2=1条件下,求方差最大的,得到x的第二主成分;第k步,在与α1Tx,α2Tx,⋯,αk−1Tx不相关的x的所有线性变换
αkTx=∑i=1mαikxi
中,在αkTαk=1条件下,求方差最大的,得到L的第k主成分;如此继续下去,直到得到x的第m主成分。
主要性质
设x是m维随机变量,∑是x的协方差矩阵,∑的特征值分别是λ1⩾λ2⩾⋯⩾λm⩾0,特征值对应的单位特征向量分别是α1,α2,⋯,αm,则x的第k主成分是:
yk=αkTx=α1kx1+α2kx2+⋯+αmkxm,k=1,2,⋯,m
x的第k主成分的方差是:
var(yk)=αkTΣαk=λk,k=1,2,⋯,m
即协方差矩阵∑的第k个特征值。
若特征值有重根,对应的特征向量组成m维空间Rm的一个子空间,子空间的维数等于重根数,在子空间任取一-个正交坐标系,这个坐标系的单位向量就可作为特征向量。这时坐标系的取法不唯一。
m维随机变量y=(y1,y2,⋯,ym)T的分量依次是x的第一主成分到第m主成分的充要条件是:
- y=ATx,A为正交矩阵
A=⎣⎢⎢⎢⎡α11α21⋮αm1α12α22⋮αm2⋯⋯⋯α1mα2m⋮αmm⎦⎥⎥⎥⎤
- y的协方差矩阵为对角矩阵
cov(y)=diag(λ1,λ2,⋯,λm)
λ1⩾λ2⩾⋯⩾λm
其中λk是∑的第k个特征值,αk是对应的单位特征向量,k=1,2,⋯,m
下面叙述总体主成分的性质:
- 总体主成分y的协方差矩阵是对角矩阵
cov(y)=Λ=diag(λ1,λ2,⋯,λm)
- 总体主成分y的方差之和等于随机变量x的方差之和,即
∑i=1mλi=∑i=1mσii
其中σii是随机变量Li的方差,即协方差矩阵∑的对角元素。
- 第k个主成分yk与变量xi的相关系数ρ(yk,xi)称为因子负荷量(factor loading),它表示第k个主成分yk与变量Xi的相关关系。计算公式是
ρ(yk,xi)=σiiλkαik,k,i=1,2,⋯,m
- 第k个主成分yk与m个变量的因子负荷量满足
∑i=1mσiiρ2(yk,xi)=λk
- m个主成分与第i个变量i的因子负荷量满足
∑k=1mρ2(yk,xi)=1
主成分的个数
主成分分析的主要目的是降维,所以一般选择k(k≪m)个主成分(线性无关变量)来代替m个原有变量(线性相关变量),使问题得以简化,并能保留原有变量的大部分信息。这里所说的信息是指原有变量的方差。为此,先给出一个定理,说明选择k个主成分是最优选择。
对任意正整数q,1⩽q⩽m,考虑正交线性变换
y=BTx
其中y是q维向量,BT是q×m矩阵,令y的协方差矩阵为:
Σy=BTΣB
则Σy的迹tr(Σy)在B=Aq时取得最大值,其中矩阵Aq由正交矩阵A的前q列组成。
定理表明,当x的线性变换y在B=Aq时,其协方差矩阵Σy的迹tr(Σy)取得最大值,这就是说,当取A的前q列取x的前q个主成分时,能够最大限度地保留原有变量方差的信息。
考虑正交变换
y=BTx
这里BT是p×m矩阵,A和Σy的定义与前相同,则tr(Σy)在B=Ap时取得最小值,其中矩阵Ap由A的后p列组成。
该定理可以理解为,当舍弃A的后p列,即舍弃变量x的后p个主成分时,原有变量的方差的信息损失最少。
以上两个定理可以作为选择k个主成分的理论依据。具体选择k的方法,通常利用方差贡献率。
第k主成分yk的方差贡献率定义为yk的方差与所有方差之和的比,记作ηk:
ηk=∑i=1mλiλk
k个主成分y1,y2,⋯,yk的累计方差贡献率定义为k个方差之和与所有方差之和的比:
∑i=1kηi=∑i=1mλi∑i=1kλi
通常取k使得累计方差贡献率达到规定的百分比以上,例如 70%~80%以上。累计方差贡献率反映了主成分保留信息的比例,但它不能反映对某个原有变量xi保留信息的比例,这时通常利用k个主成分y1,y2,⋯,yk对原有变量xi的贡献率。
规范化变量的总体主成分
在实际问题中,不同变量可能有不同的量纲,直接求主成分有时会产生不合理的结果。为了消除这个影响,常常对各个随机变量实施规范化,使其均值为 0, 方差为 1。
设x=(x1,x2,⋯,xm)T为m维随机变量,xi为第i个随机变量,i=1,2,⋯,m,令
xi∗=var(xi)xi−E(xi),i=1,2,⋯,m,令
xi∗=var(xi)xi−E(xi),i=1,2,⋯,m
其中E(xi),var(xi)分别是随机变量xi的均值和方差,这时xi∗就是xi的规范化随机变量。
显然,规范化随机变量的协方差矩阵就是相关矩阵R。主成分分析通常在规范化随机变量的协方差矩阵即相关矩阵上进行。
对照总体主成分的性质可知,规范化随机变量的总体主成分有以下性质:
- 规范化变量主成分的协方差矩阵是
Λ∗=diag(λ1∗,λ2∗,⋯,λm∗)
其中λ1∗⩾λ2∗⩾⋯⩾λm∗⩾0是相关矩阵R的特征值。
- 协方差矩阵的特征值之和m
∑k=1mλk∗=m
- 规范化随机变量Li∗与主成分yk∗的相关系数的平方和等于λk∗:
∑i=1mρ2(yk∗,xi∗)=∑i=1mλk∗eik∗2=λk∗,k=1,2,⋯,m
- 规范化随机变量xi∗与所有主成分yk∗的相关系数的平方和等于 1
∑k=1mρ2(yk∗,xi∗)=∑k=1mλk∗eik∗2=1,i=1,2,⋯,m
样本主成分分析
在实际问题中,需要在观测数据上进行主成分分析,这就是样本主成分分析。有了总体主成分的概念,容易理解样本主成分的概念。样本主成分也和总体主成分具有相同的性质。
样本主成分的定义和性质
假设对m维随机变量x=(x1,x2,⋯,xm)T进行n次独立观测,x1,x2,⋯,xn表示观测样本,其中:xj=(x1j,x2j,⋯,xmj)T表示第j个观测样本,xij表示第j个观测样本的第i个变量,j=1,2,⋯,n。观测数据用样本矩阵X表示,记作
X=[x1x2⋯xn]=⎣⎢⎢⎢⎡x11x21⋮xm1x12x22⋮xm2⋯⋯⋯x1nx2n⋮xmn⎦⎥⎥⎥⎤
给定样本矩阵X,可以估计样本均值,以及样本协方差。样本均值向量xˉ为:
xˉ=n1∑j=1nxj
样本协方差矩阵S为:
S=[sij]m×m
sij=n−11∑k=1n(xik−xˉi)(xjk−xˉj),i,j=1,2,⋯,m
其中xˉi=n1∑k=1nxik为第i个变量的样本均值,xˉj=n1∑k=1nxjk为第j个变量的样本均值。
样本相关矩阵R为:
R=[rij]m×m,rij=siisjjsij,i,j=1,2,⋯,m
定义m维向量x=(x1,x2,⋯,xm)T到m维向量y=(y1,y2,…,yn)T的线性变换:
y=ATx
其中
A=[a1a2⋯am]=⎣⎢⎢⎢⎡a11a21⋮am1a12a22⋮am2⋯⋯⋯a1ma2m⋮amm⎦⎥⎥⎥⎤ai=(a1i,a2i,⋯,ami)T,i=1,2,⋯,m
考虑任意一个线性变换:
yi=aiTx=a1ix1+a2ix2+⋯+amixm,i=1,2,⋯,m
其中yi是m维向量y的第i个变量,相应于容量为n的样本x1,x2,⋯,xn,yi的样本均值yˉi为:
yˉi=n1∑j=1naiTxj=aiTx
其中x是随机向量x的样本均值:
x=n1∑j=1nxj
yi的样本方差var(yi)为:
var(yi)=n−11j=1∑n(aiTxj−aiTx)2=aiT[n−11j=1∑n(xj−x)(xj−x)T]ai=aiTSai
对任意两个线性变换yi=αiTx,yk=αkTx,相应于容量为 n的样本x1,x2,⋯,xn,yk的样本协方差为
cov(yi,yk)=aiTSak
样本主成分:
给定样本矩阵X。样本第一主成分y1=a1Tx是在a1Ta1=1是在a1Ta1=1条件下,使得a1Txj(j=1,2,⋯,n)的样本方差a1TSa1最大的x的线性变换;一般地,样本第i主成分yi=aiTx是在aiTai=1和aiTxj与akTxj(k<i,j=1,2,⋯,n)的样本协方差akTSai=0条件下,使得aiTxj(j=1,2,⋯,n)的样本方差aiTSai最大的x的线性变换。
样本主成分与总体主成分具有同样的性质。这从样本主成分的定义容易看出。只要以样本协方差矩阵S代替总体协方差矩阵∑即可。总体主成分的定理对样本主成分依然成立。
在使用样本主成分时,-般假设样本数据是规范化的,即对样本矩阵作如下变换:
xij∗=siixij−xˉi,i=1,2,⋯,m;j=1,2,⋯,n
其中:
xˉi=n1∑j=1nxij,i=1,2,⋯,m
sii=n−11∑j=1n(xij−xˉi)2,i=1,2,⋯,m
为了方便,以下将规范化变量xij∗仍记作xij,规范化的样本矩阵仍记作X。这时,样本协方差矩阵S就是样本相关矩阵R
样本协方差矩阵S是总体协方差矩阵Σ的无偏估计,样本相关矩阵R是总体相关矩阵的无偏估计S的特征值和特征向量是Σ的特征值和特征向量的极大似然估计。
相关矩阵的特征值分解算法
传统的主成分分析通过数据的协方差矩阵或相关矩阵的特征值分解进行,现在常用的方法是通过数据矩阵的奇异值分解进行。首先叙述数据的协方差矩阵或相关矩阵的特征值分解方法。
给定样本矩阵X,利用数据的样本协方差矩阵或者样本相关矩阵的特征值分解进行主成分分析。具体步骤如下:
- 对观测数据按式
xij∗=siixij−xˉi,i=1,2,⋯,m;j=1,2,⋯,n
进行规范化处理,得到规范化数据矩阵,仍以X表示。
2. 依据规范化数据矩阵,计算样本相关矩阵R:
R=[rij]m×m=n−11XXT
其中:
rij=n−11∑l=1nxilxlj,i,j=1,2,⋯,m
- 求样本相关矩阵R的k个特征值和对应的k个单位特征向量。
求解R的特征方程:
∣R−λI∣=0
得R的m个特征值:
λ1⩾λ2⩾⋯⩾λm
求方差贡献率∑i=1kηi达到预定值的主成分个数k:
求前k个特征值对应的单位特征向量:
ai=(a1i,a2i,⋯,ami)T,i=1,2,⋯,k
- 求k个样本主成分
以k个单位特征向量为系数进行线性变换,求出k个样本主成分:
yi=aiTx,i=1,2,⋯,k
-
计算k个主成分yj与原变量xi的相关系数ρ(xi,yj),以及k个主成分对原变量xi的贡献率vi。
-
计算n个样本的k个主成分值:
将规范化样本数据代入k个主成分式yi=aiTx,i=1,2,⋯,k,得到n个样本的主成分值。
第j个样本xj=(x1j,x2j,⋯,xmj)T的第i主成分值是:
yij=(a1i,a2i,⋯,ami)(x1j,x2j,⋯,xmj)T=∑l=1malixlj
i=1,2,⋯,m,j=1,2,⋯,n
主成分分析得到的结果可以用于其他机器学习方法的输入。比如,将样本点投影到以主成分为坐标轴的空间中,然后应用聚类算法,就可以对样本点进行聚类。
数据矩阵的奇异值分解算法
给定样本矩阵X,利用数据矩阵奇异值分解进行主成分分析。具体过程如下。这里假设有k个主成分。
对于mxn实矩阵A,假设其秩为r,0<k<r,则可以将矩阵解A进行截断奇异值分解
A≈UkΣkVkT
式中Uk是m×k矩阵,Vk是n×k矩阵,∑k是k阶对角矩阵;Uk,Vk分别由取A的完全奇异值分解的矩阵U,V的前k列,∑k由取A的完全奇异值分解的矩阵∑的前k个对角线元素得到。
定义一个新的n×m矩阵X′:
X′=n−11XT
X′的每一列均值为零。不难得知,
X′TX′=(n−11XT)T(n−11XT)=n−11XXT
即X′TX′等于X的协方差矩阵SX。
主成分分析归结于求协方差矩阵SX的特征值和对应的单位特征向量,所以问题转化为求矩阵=X′TX′的特征值和对应的单位特征向量。
假设X′的截断奇异值分解为X′=UΣVT,那么V的列向量就是SX=X′TX′的单位特征向量。因此,V的列向量就是X的主成分。于是,求X主成分可以通过求X′的奇异值分解来实现。具体算法如下。
主成分分析算法:
输入:mxn样本矩阵X,其每一-行元素的均值为零;
输出:kxn样本主成分矩阵Y。
参数:主成分个数k
- 构造新的n×m矩阵:
X′=n−11XT
X′每一列的均值为零。
- 对矩阵X′进行截断奇异值分解,得到:
X′=UΣVT
有k个奇异值、奇异向量。矩阵V的前k列构成k个样本主成分。
- 求kxn样本主成分矩阵
Y=VTX
主成分分析(《机器学习》)
主成分分析(Principal Component Analysis,简称 PCA)是最常用的一种降维方法。在介绍 PCA 之前,不妨先考虑这样一个问题:对于正交属性空间中的样本点,如何用一个超平面(直线的高维推广)对所有样本进行恰当的表达?
容易想到,若存在这样的超平面,那么它大概应具有这样的性质:
- 最近重构性:样本点到这个超平面的距离都足够近;
- 最大可分性:样本点在这个超平面上的投影能尽可能分开。
有趣的是,基于最近重构性和最大可分性,能分别得到主成分分析的两种等价推导。我们先从最近重构性来推导。
假定数据样本进行了中心化,即∑ixi=0; 再假定投影变换后得到的新坐标系为{w1,w2,…,wd},其中Ui是标准正交基向量,∥wi∥2=1,wiTwj=0。若丢弃新坐标系中的部分坐标,即将维度降低到d′<d,则样本点xi在低维坐标系中的投影是zi=(zi1;zi2;…;zid′),其中zij=wjTxi是xi在低维坐标系下第j维的坐标。若基于zi来重构 xi,则会得到x^i=∑j=1d′zijwj.
考虑整个训练集,原样本点xi与基于投影重构的样本点x^i之间的距离为:
∑i=1m∥∥∥∑j=1d′zijwj−xi∥∥∥22=∑i=1mziTzi−2∑i=1mziTWTxi+const
∝−tr(WT(∑i=1mxixiT)W)
根据最近重构性,上式应被最小化,考虑到wj是标准正交基,∑ixixiT是协方差矩阵,有
minw−tr(WTXXTW)
s.t. WTW=I
这就是主成分分析的优化目标。
从最大可分性出发,能得到主成分分析的另一种解释。我们知道,样本点xi在新空间中超平面上的投影是WTxi,若所有样本点的投影能尽可能分开,则应该使投影后样本点的方差最大化,如图所示。
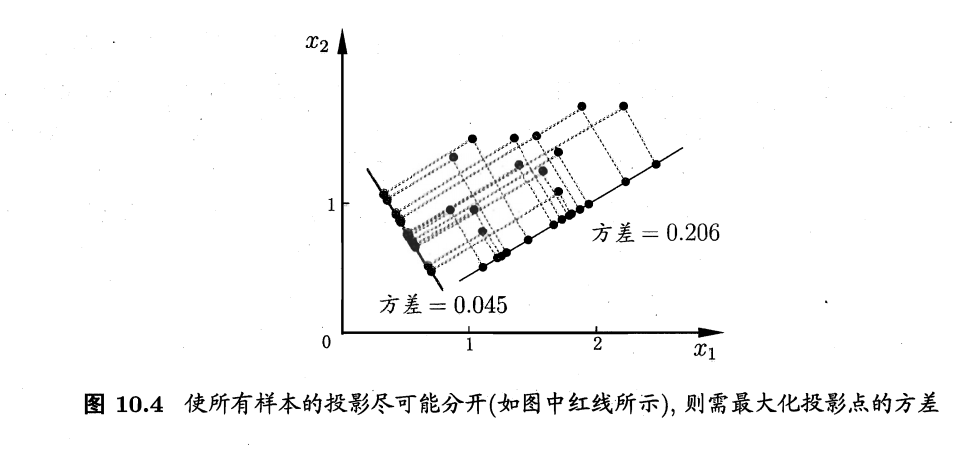
投影后样本点的方差是∑iWTxixiTW,于是优化目标可写为:
maxWtr(WTXXTW)
s.t. WTW=I
使用拉格朗日乘子法可得:
xxTW=λW
于是,只需对协方差矩阵XXT进行特征值分解,将求得的特征值排序:λ1⩾λ2⩾…⩾λd,再取前d′个特征值对应的特征向量构成 W=(w1w2,…,wd′)。这就是主成分分析的解。PCA 算法描述如图所示。

实践中常通过对X进行奇异值分解来代替协方差矩阵的特征值分解。
PCA也可看作是逐一选取方差最大方向,即先对协方差矩阵∑ixixiT做特征值分解,取最大特征值对应的特征向量w1; 再对∑ixixiT−λ1w1w1T做特征值分解,取最大特征值对应的特征向量w2...由W各分量正交及∑i=1mxixiT=∑j=1dλjwjwjT可知,上述逐一选取方差最大方向的做法与直接选取最大d′个特征值等价。
降维后低维空间的维数d′通常是由用户事先指定,或通过在d′值不同的低维空间中对k近邻分类器(或其他开销较小的学习器)进行交叉验证来选取较好的d′值。对 PCA,还可从重构的角度设置一个重构阈值,例如 t= 95%,然后选取使下式成立的最小d′值:
∑i=1dλi∑i=1d′λi⩾t
PCA 仅需保留W与样本的均值向量即可通过简单的向量减法和矩阵-向量乘法将新样本投影至低维空间中。显然,低维空间与原始高维空间必有不同,因为对应于最小的d−d′个特征值的特征向量被舍弃了,这是降维导致的结果。但舍弃这部分信息往往是必要的:一方面,舍弃这部分信息之后能使样本的采样密度增大,这正是降维的重要动机;另一方面,当数据受到噪声影响时,最小的特征值所对应的特征向量往往与噪声有关,将它们舍弃能在一定程度上起到去噪的效果。
线性判别分析(《机器学习》)
线性判别分析(Linear Discriminant Analysis,简称 LDA)是-种经典的线性学习方法。
LDA 的思想非常朴素:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。下图给出了一个二维示意图。
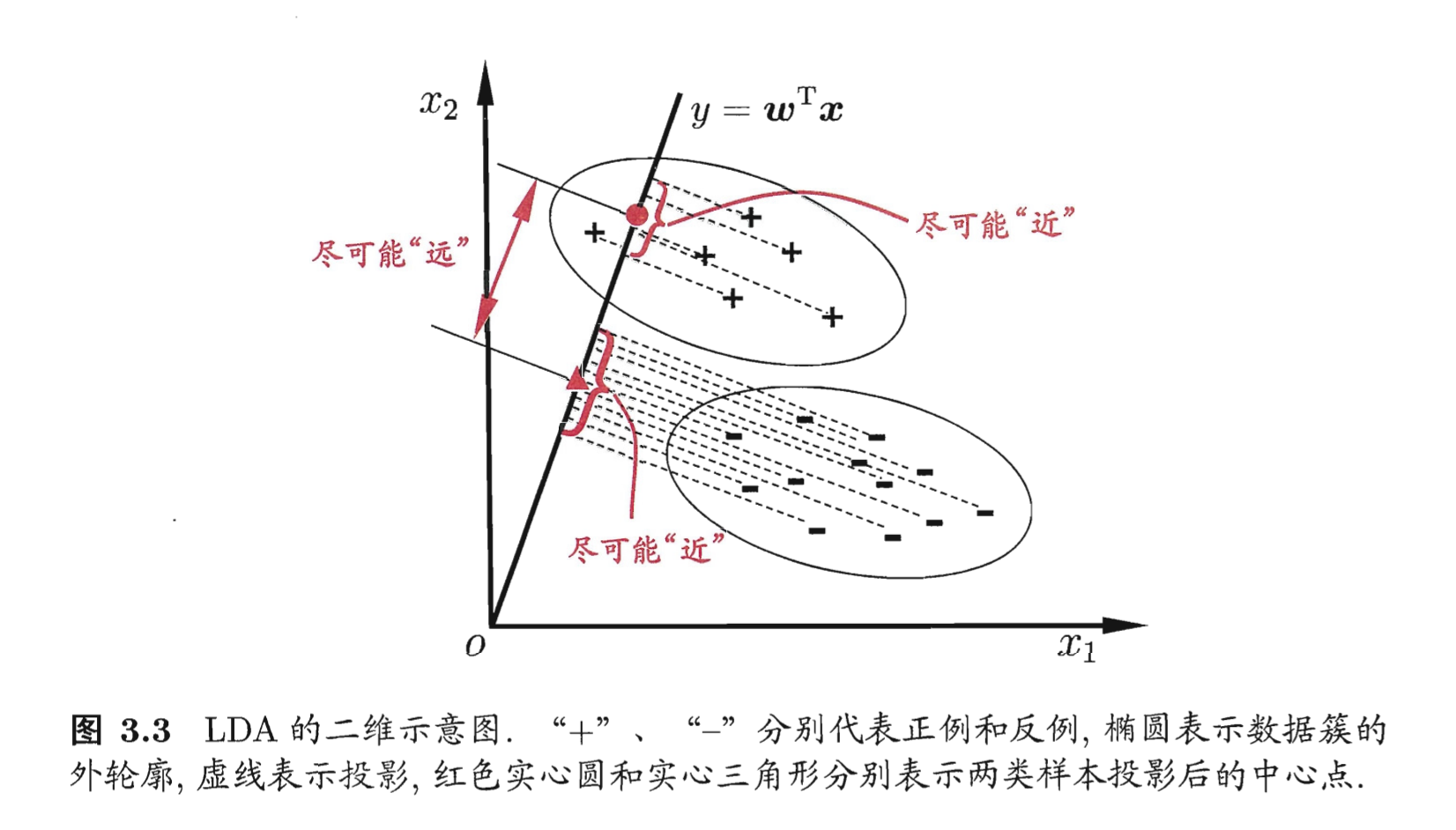
给定数据集D={(xi,yi)}i=1m,yi∈{0,1},令Xi,μi,Σi分别表示第i∈{0,1}类示例的集合、均值向量、协方差矩阵。若将数据投影到直线w上,则两类样本的中心在直线上的投影分别为wTμ0和wTμ1,若将所有样本点都投影到直线w上,则两类样本的协方差分别为wTΣ0w和wTΣ1w。由于直线是维空间,因此wTμ0,wTμ1,wTΣ0w和wTΣ1w均为实数。
欲使同类样例的投影点尽可能接近,可以让同类样例投影点的协方差尽可能小,即wTΣ0w+wTΣ1w尽可能小;而欲使异类样例的投影点尽可能远离,
可以让类中心之间的距离尽可能大,即∥∥wTμ0−wTμ1∥∥22尽可能大。同时考虑二者,则可得到欲最大化的目标
J=wTΣ0w+wTΣ1w∥∥wTμ0−wTμ1∥∥22=wT(Σ0+Σ1)wwT(μ0−μ1)(μ0−μ1)Tw
定义“类内散度矩阵”(within-class scatter matrix):
Sw=Σ0+Σ1=x∈X0∑(x−μ0)(x−μ0)T+x∈X1∑(x−μ1)(x−μ1)T
以及“类间散度矩阵”(between class scatter matrix):
Sb=(μ0−μ1)(μ0−μ1)T
则有:
J=wTSwwwTSbw
这就是 LDA 欲最大化的目标,即Sb和Sw的‘“广义瑞利熵”(generalizedRayleigh quotient).
如何确定w呢?注意到分子和分母都是关于w的二次项,因此解与w的长度无关,只与其方向有关。不失一般性,令wTSww=1, 则式等价于:
若w是一个解,则对于任意常数α,αw也是式的解。
minw s.t. −wTSbwwTSww=1
由拉格朗日乘子法,上式等价于
Sbw=λSww
其中λ是拉格朗日乘子。注意到Sbw的方向恒为μ0−μ1,不妨令:
Sbw=λ(μ0−μ1)
得:
w=Sw−1(μ0−μ1)
考虑到数值解的稳定性,在实践中通常是对Sw进行奇异值分解,即Sw=UΣVT这里Σ是一个实对角矩阵,其对角线上的元素是Sw的奇异值,然后再由Sw−1=VΣ−1UT得到Sw−1。
值得一提的是,LDA 可从贝叶斯决策理论的角度来阐释,并可证明,当两类数据同先验、满足高斯分布且协方差相等时,LDA 可达到最优分类。
可以将 LDA 推广到多分类任务中。. 假定存在N个类,且第i类示例数为mi。我们先定义“全局散度矩阵”:
St=Sb+Sw=i=1∑m(xi−μ)(xi−μ)T
其中μ是所有示例的均值向量。将类内散度矩阵Sw重定义为每个类别的散度矩阵之和,即
Sw=∑i=1NSwi
其中
Swi=∑x∈Xi(x−μi)(x−μi)T
Sb=St−Sw=i=1∑Nmi(μi−μ)(μi−μ)T
显然,多分类 LDA 可以有多种实现方法:使用Sb,Sw,St三者中的任何两个即可。常见的一种实现是采用优化目标
maxWtr(WTSwW)tr(WTSbW)
其中W∈Rd×(N−1),tr(⋅)表示矩阵的迹(trace).可通过如下广义特征值问题求解:
SbW=λSwW
W的闭式解则是Sw−1Sb的N−1个最大广义特征值所对应的特征向量组成的矩阵。
若将W视为一个投影矩阵,则多分类 LDA 将样本投影到N−1维空间N−1通常远小于数据原有的属性数。于是,可通过这个投影来减小样本点的维数,且投影过程中使用了类别信息,因此 LDA 也常被视为-一种经典的监督降维技术。