Pandas基础- 索引
- 分组
- 变形
- 合并
- 缺失数据
- 文本数据
- 分类数据
- 时序数据
- 速查
Pandas基础
import pandas as pd
import numpy as np
查看Pandas版本
pd.__version__
'1.0.1'
文件读取与写入
读取
csv格式
df = pd.read_csv('data/table.csv')
df.head()
txt格式
df_txt = pd.read_table('data/table.txt') #可设置sep分隔符参数
df_txt
写入
csv格式
df.to_csv('data/new_table.csv')
基本数据结构
Series
创建一个Series
对于一个Series,其中最常用的属性为值(values),索引(index),名字(name),类型(dtype)
s
a -0.282809
b -0.316346
c 0.535802
d 1.802756
e 1.808229
Name: 这是一个Series, dtype: float64
访问Series属性
s.values
array([-0.28280874, -0.31634646, 0.53580237, 1.802756 , 1.8082295 ])
s.name
'这是一个Series'
s.index
Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
s.dtype
dtype('float64')
取出某一个元素
s['a']
-0.2828087433467871
调用方法
s.mean()
0.7095265322328809
Series有相当多的方法可以调用:
print([attr for attr in dir(s) if not attr.startswith('_')])
['T', 'a', 'abs', 'add', 'add_prefix', 'add_suffix', 'agg', 'aggregate', 'align', 'all', 'any', 'append', 'apply', 'argmax', 'argmin', 'argsort', 'array', 'asfreq', 'asof', 'astype', 'at', 'at_time', 'attrs', 'autocorr', 'axes', 'b', 'between', 'between_time', 'bfill', 'bool', 'c', 'clip', 'combine', 'combine_first', 'convert_dtypes', 'copy', 'corr', 'count', 'cov', 'cummax', 'cummin', 'cumprod', 'cumsum', 'd', 'describe', 'diff', 'div', 'divide', 'divmod', 'dot', 'drop', 'drop_duplicates', 'droplevel', 'dropna', 'dtype', 'dtypes', 'duplicated', 'e', 'empty', 'eq', 'equals', 'ewm', 'expanding', 'explode', 'factorize', 'ffill', 'fillna', 'filter', 'first', 'first_valid_index', 'floordiv', 'ge', 'get', 'groupby', 'gt', 'hasnans', 'head', 'hist', 'iat', 'idxmax', 'idxmin', 'iloc', 'index', 'infer_objects', 'interpolate', 'is_monotonic', 'is_monotonic_decreasing', 'is_monotonic_increasing', 'is_unique', 'isin', 'isna', 'isnull', 'item', 'items', 'iteritems', 'keys', 'kurt', 'kurtosis', 'last', 'last_valid_index', 'le', 'loc', 'lt', 'mad', 'map', 'mask', 'max', 'mean', 'median', 'memory_usage', 'min', 'mod', 'mode', 'mul', 'multiply', 'name', 'nbytes', 'ndim', 'ne', 'nlargest', 'notna', 'notnull', 'nsmallest', 'nunique', 'pct_change', 'pipe', 'plot', 'pop', 'pow', 'prod', 'product', 'quantile', 'radd', 'rank', 'ravel', 'rdiv', 'rdivmod', 'reindex', 'reindex_like', 'rename', 'rename_axis', 'reorder_levels', 'repeat', 'replace', 'resample', 'reset_index', 'rfloordiv', 'rmod', 'rmul', 'rolling', 'round', 'rpow', 'rsub', 'rtruediv', 'sample', 'searchsorted', 'sem', 'set_axis', 'shape', 'shift', 'size', 'skew', 'slice_shift', 'sort_index', 'sort_values', 'squeeze', 'std', 'sub', 'subtract', 'sum', 'swapaxes', 'swaplevel', 'tail', 'take', 'to_clipboard', 'to_csv', 'to_dict', 'to_excel', 'to_frame', 'to_hdf', 'to_json', 'to_latex', 'to_list', 'to_markdown', 'to_numpy', 'to_period', 'to_pickle', 'to_sql', 'to_string', 'to_timestamp', 'to_xarray', 'transform', 'transpose', 'truediv', 'truncate', 'tshift', 'tz_convert', 'tz_localize', 'unique', 'unstack', 'update', 'value_counts', 'values', 'var', 'view', 'where', 'xs']
DataFrame
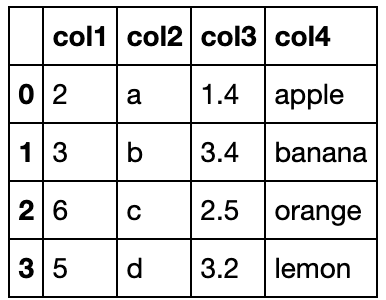
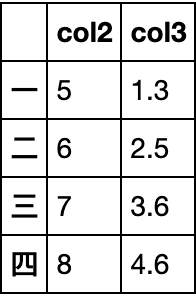
创建一个DataFrame
df = pd.DataFrame({'col1':list('abcde'),'col2':range(5,10),'col3':[1.3,2.5,3.6,4.6,5.8]},
index=list('一二三四五'))
df
从DataFrame取出一列为Series
df['col1']
一 a
二 b
三 c
四 d
五 e
Name: col1, dtype: object
type(df)
pandas.core.frame.DataFrame
type(df['col1'])
pandas.core.series.Series
修改行或列名
df.rename(index={'一':'one'},columns={'col1':'new_col1'})
调用属性和方法
df.index
Index(['一', '二', '三', '四', '五'], dtype='object')
df.columns
Index(['col1', 'col2', 'col3'], dtype='object')
df.values
array([['a', 5, 1.3],
['b', 6, 2.5],
['c', 7, 3.6],
['d', 8, 4.6],
['e', 9, 5.8]], dtype=object)
df.shape
(5, 3)
df.mean() #本质上是一种Aggregation操作
col2 7.00
col3 3.56
dtype: float64
索引对齐特性
这是Pandas中非常强大的特性,不理解这一特性有时就会造成一些麻烦
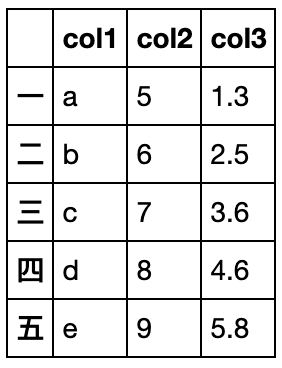
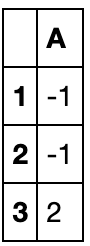
df1 = pd.DataFrame({'A':[1,2,3]},index=[1,2,3])
df2 = pd.DataFrame({'A':[1,2,3]},index=[3,1,2])
df1-df2 #由于索引对齐,因此结果不是0
列的删除与添加
对于删除而言,可以使用drop函数或del或pop
df.drop(index='五',columns='col1') #设置inplace=True后会直接在原DataFrame中改动
df['col1']=[1,2,3,4,5]
del df['col1']
df
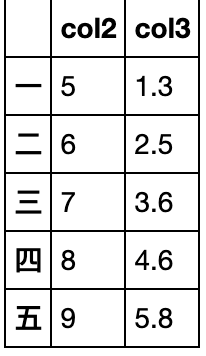
pop方法直接在原来的DataFrame上操作,且返回被删除的列,与python中的pop函数类似
df['col1']=[1,2,3,4,5]
df.pop('col1')
一 1
二 2
三 3
四 4
五 5
Name: col1, dtype: int64
df
col2 col3
一 5 1.3
二 6 2.5
三 7 3.6
四 8 4.6
五 9 5.8
可以直接增加新的列,也可以使用assign方法,但assign方法不会对原DataFrame做修改
df1['B']=list('abc')
df1
A B
1 1 a
2 2 b
3 3 c
df1.assign(C=pd.Series(list('def')))
A B C
1 1 a e
2 2 b f
3 3 c NaN
根据类型选择列
df.select_dtypes(include=['number']).head()
col2 col3
一 5 1.3
二 6 2.5
三 7 3.6
四 8 4.6
五 9 5.8
df.select_dtypes(include=['float']).head()
col3
一 1.3
二 2.5
三 3.6
四 4.6
五 5.8
将Series转换为DataFrame
s = df.mean()
s.name='to_DataFrame'
s
col2 7.00
col3 3.56
Name: to_DataFrame, dtype: float64
s.to_frame()
to_DataFrame
col2 7.00
col3 3.56
使用T符号可以转置
s.to_frame().T
col2 col3
to_DataFrame 7.0 3.56
常用基本函数
从下面开始,包括后面所有章节,我们都会用到这份虚拟的数据集
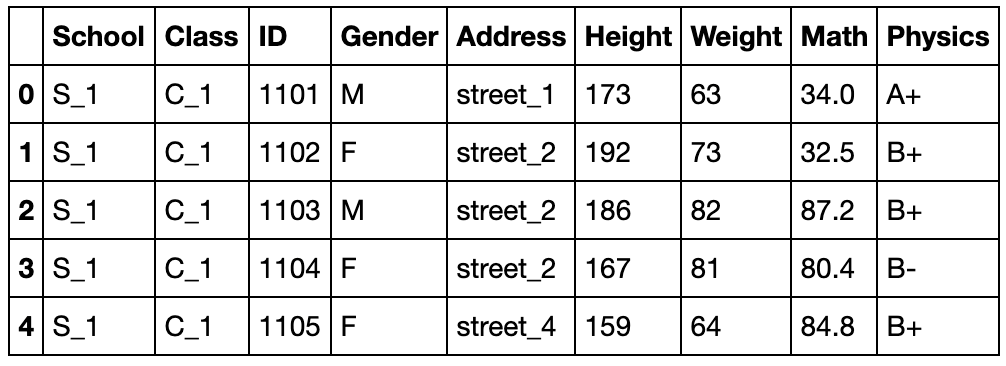
df = pd.read_csv('data/table.csv')
head和tail
df.head()
School Class ID Gender Address Height Weight Math Physics
0 S_1 C_1 1101 M street_1 173 63 34.0 A+
1 S_1 C_1 1102 F street_2 192 73 32.5 B+
2 S_1 C_1 1103 M street_2 186 82 87.2 B+
3 S_1 C_1 1104 F street_2 167 81 80.4 B-
4 S_1 C_1 1105 F street_4 159 64 84.8 B+
df.tail()
School Class ID Gender Address Height Weight Math Physics
30 S_2 C_4 2401 F street_2 192 62 45.3 A
31 S_2 C_4 2402 M street_7 166 82 48.7 B
32 S_2 C_4 2403 F street_6 158 60 59.7 B+
33 S_2 C_4 2404 F street_2 160 84 67.7 B
34 S_2 C_4 2405 F street_6 193 54 47.6 B
可以指定n参数显示多少行
df.head(3)
School Class ID Gender Address Height Weight Math Physics
0 S_1 C_1 1101 M street_1 173 63 34.0 A+
1 S_1 C_1 1102 F street_2 192 73 32.5 B+
2 S_1 C_1 1103 M street_2 186 82 87.2 B+
unique和nunique
nunique显示有多少个唯一值
df['Physics'].nunique()
7
unique显示所有的唯一值
df['Physics'].unique()
array(['A+', 'B+', 'B-', 'A-', 'B', 'A', 'C'], dtype=object)
count和value_counts
count返回非缺失值元素个数
df['Physics'].count()
35
value_counts返回每个元素有多少个
df['Physics'].value_counts()
B+ 9
B 8
B- 6
A 4
A+ 3
A- 3
C 2
Name: Physics, dtype: int64
describe和info
info函数返回有哪些列、有多少非缺失值、每列的类型
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 35 entries, 0 to 34
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 School 35 non-null object
1 Class 35 non-null object
2 ID 35 non-null int64
3 Gender 35 non-null object
4 Address 35 non-null object
5 Height 35 non-null int64
6 Weight 35 non-null int64
7 Math 35 non-null float64
8 Physics 35 non-null object
dtypes: float64(1), int64(3), object(5)
memory usage: 2.6+ KB
describe默认统计数值型数据的各个统计量
df.describe()
ID Height Weight Math
count 35.00000 35.000000 35.000000 35.000000
mean 1803.00000 174.142857 74.657143 61.351429
std 536.87741 13.541098 12.895377 19.915164
min 1101.00000 155.000000 53.000000 31.500000
25% 1204.50000 161.000000 63.000000 47.400000
50% 2103.00000 173.000000 74.000000 61.700000
75% 2301.50000 187.500000 82.000000 77.100000
max 2405.00000 195.000000 100.000000 97.000000
可以自行选择分位数
df.describe(percentiles=[.05, .25, .75, .95])
ID Height Weight Math
count 35.00000 35.000000 35.000000 35.000000
mean 1803.00000 174.142857 74.657143 61.351429
std 536.87741 13.541098 12.895377 19.915164
min 1101.00000 155.000000 53.000000 31.500000
5% 1102.70000 157.000000 56.100000 32.640000
25% 1204.50000 161.000000 63.000000 47.400000
50% 2103.00000 173.000000 74.000000 61.700000
75% 2301.50000 187.500000 82.000000 77.100000
95% 2403.30000 193.300000 97.600000 90.040000
max 2405.00000 195.000000 100.000000 97.000000
对于非数值型也可以用describe函数
df['Physics'].describe()
count 35
unique 7
top B+
freq 9
Name: Physics, dtype: object
idxmax和nlargest
idxmax函数返回最大值,在某些情况下特别适用,idxmin功能类似
df['Math'].idxmax()
5
nlargest函数返回前几个大的元素值,nsmallest功能类似
df['Math'].nlargest(3)
5 97.0
28 95.5
11 87.7
Name: Math, dtype: float64
clip和replace
clip和replace是两类替换函数,clip是对超过或者低于某些值的数进行截断
df['Math'].head()
0 34.0
1 32.5
2 87.2
3 80.4
4 84.8
Name: Math, dtype: float64
df['Math'].clip(33,80).head()
Out[54]:
0 34.0
1 33.0
2 80.0
3 80.0
4 80.0
Name: Math, dtype: float64
df['Math'].mad()
16.924244897959188
replace是对某些值进行替换
df['Address'].head()
0 street_1
1 street_2
2 street_2
3 street_2
4 street_4
Name: Address, dtype: object
df['Address'].replace(['street_1','street_2'],['one','two']).head()
0 one
1 two
2 two
3 two
4 street_4
Name: Address, dtype: object
通过字典,可以直接在表中修改
df.replace({'Address':{'street_1':'one','street_2':'two'}}).head()
School Class ID Gender Address Height Weight Math Physics
0 S_1 C_1 1101 M one 173 63 34.0 A+
1 S_1 C_1 1102 F two 192 73 32.5 B+
2 S_1 C_1 1103 M two 186 82 87.2 B+
3 S_1 C_1 1104 F two 167 81 80.4 B-
4 S_1 C_1 1105 F street_4 159 64 84.8 B+
apply函数
对于Series,它可以迭代每一列的值操作:
df['Math'].apply(lambda x:str(x)+'!').head() #可以使用lambda表达式,也可以使用函数
0 34.0!
1 32.5!
2 87.2!
3 80.4!
4 84.8!
Name: Math, dtype: object
对于DataFrame,它可以迭代每一个列操作:
df.apply(lambda x:x.apply(lambda x:str(x)+'!')).head() #这是一个稍显复杂的例子,有利于理解apply的功能
School Class ID Gender Address Height Weight Math Physics
0 S_1! C_1! 1101! M! street_1! 173! 63! 34.0! A+!
1 S_1! C_1! 1102! F! street_2! 192! 73! 32.5! B+!
2 S_1! C_1! 1103! M! street_2! 186! 82! 87.2! B+!
3 S_1! C_1! 1104! F! street_2! 167! 81! 80.4! B-!
4 S_1! C_1! 1105! F! street_4! 159! 64! 84.8! B+!
排序
索引排序
df.set_index('Math').head() #set_index函数可以设置索引
School Class ID Gender Address Height Weight Physics
Math
34.0 S_1 C_1 1101 M street_1 173 63 A+
32.5 S_1 C_1 1102 F street_2 192 73 B+
87.2 S_1 C_1 1103 M street_2 186 82 B+
80.4 S_1 C_1 1104 F street_2 167 81 B-
84.8 S_1 C_1 1105 F street_4 159 64 B+
df.set_index('Math').sort_index().head() #可以设置ascending参数,默认为升序,True
School Class ID Gender Address Height Weight Physics
Math
31.5 S_1 C_3 1301 M street_4 161 68 B+
32.5 S_1 C_1 1102 F street_2 192 73 B+
32.7 S_2 C_3 2302 M street_5 171 88 A
33.8 S_1 C_2 1204 F street_5 162 63 B
34.0 S_1 C_1 1101 M street_1 173 63 A+
值排序
df.sort_values(by='Class').head()
School Class ID Gender Address Height Weight Math Physics
0 S_1 C_1 1101 M street_1 173 63 34.0 A+
19 S_2 C_1 2105 M street_4 170 81 34.2 A
18 S_2 C_1 2104 F street_5 159 97 72.2 B+
16 S_2 C_1 2102 F street_6 161 61 50.6 B+
15 S_2 C_1 2101 M street_7 174 84 83.3 C
多个值排序,即先对第一层排,在第一层相同的情况下对第二层排序
df.sort_values(by=['Address','Height']).head()
School Class ID Gender Address Height Weight Math Physics
0 S_1 C_1 1101 M street_1 173 63 34.0 A+
11 S_1 C_3 1302 F street_1 175 57 87.7 A-
23 S_2 C_2 2204 M street_1 175 74 47.2 B-
33 S_2 C_4 2404 F street_2 160 84 67.7 B
3 S_1 C_1 1104 F street_2 167 81 80.4 B-
练习
练习一
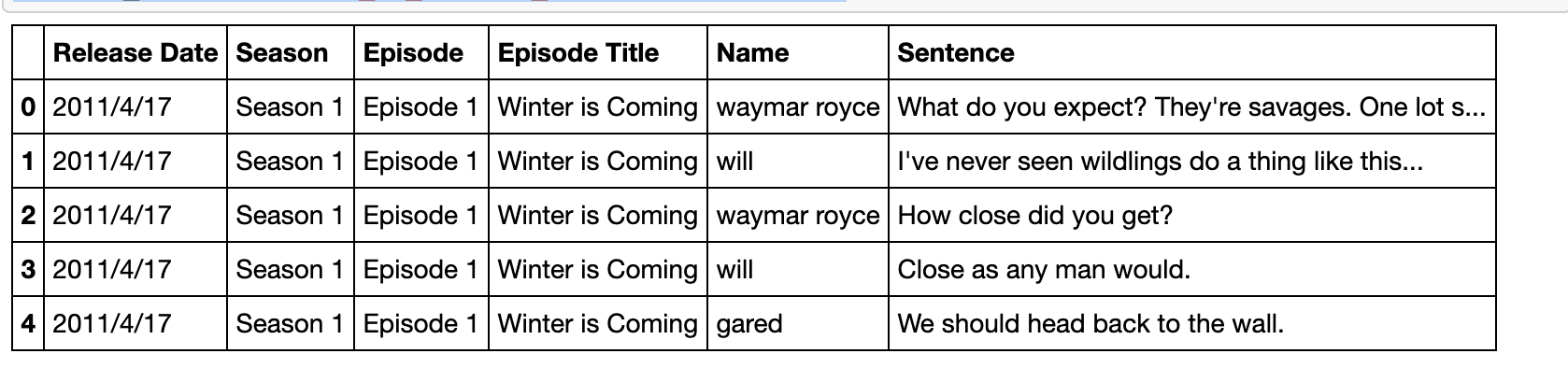
现有一份关于美剧《权力的游戏》剧本的数据集,请解决以下问题:
pd.read_csv('data/Game_of_Thrones_Script.csv').head()
- 在所有的数据中,一共出现了多少人物?
df['Name'].nunique()
564
- 以单元格计数(即简单把一个单元格视作一句),谁说了最多的话?
df['Name'].value_counts().index[0]
'tyrion lannister'
- 以单词计数,谁说了最多的单词?
由于还没有学分组,因此方法繁琐
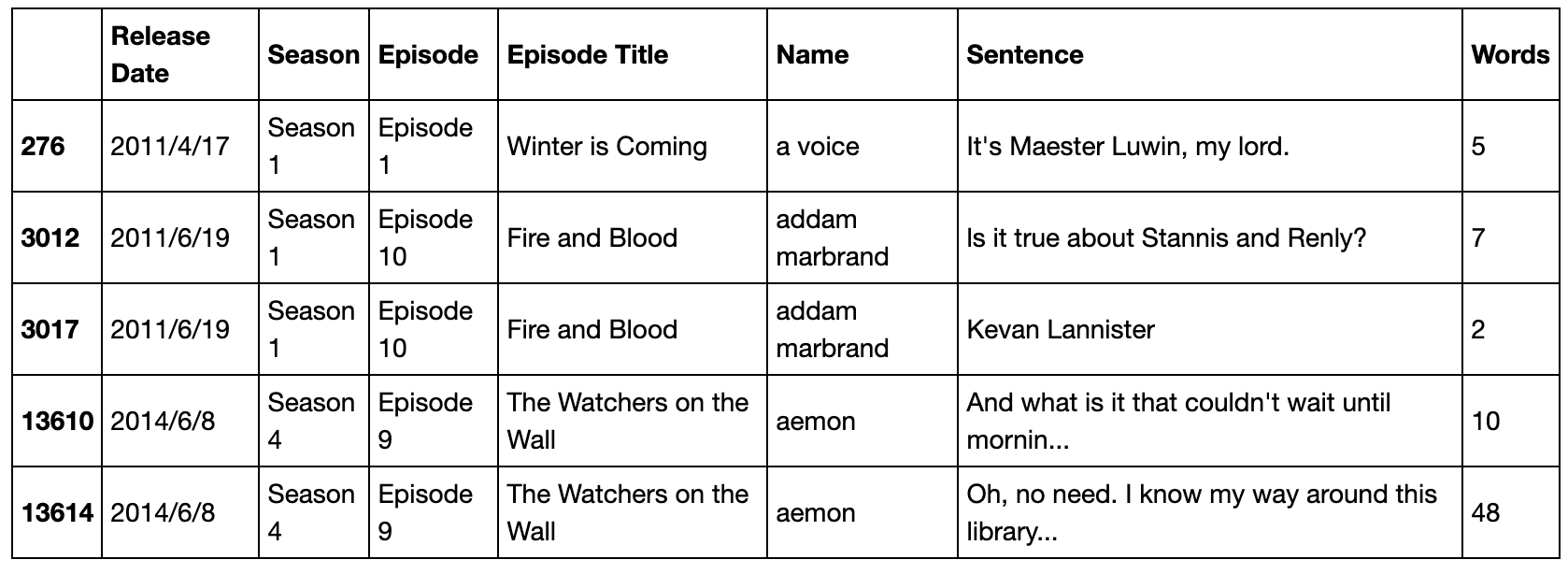
df_words = df.assign(Words=df['Sentence'].apply(lambda x:len(x.split()))).sort_values(by='Name')
df_words.head()
L_count = []
N_words = list(zip(df_words['Name'],df_words['Words']))
for i in N_words:
if i == N_words[0]:
L_count.append(i[1])
last = i[0]
else:
L_count.append(L_count[-1]+i[1] if i[0]==last else i[1])
last = i[0]
df_words['Count']=L_count
df_words['Name'][df_words['Count'].idxmax()]
'tyrion lannister'
练习二
现有一份关于科比的投篮数据集,请解决如下问题:
pd.read_csv('data/Kobe_data.csv',index_col='shot_id').head()
#index_col的作用是将某一列作为行索引
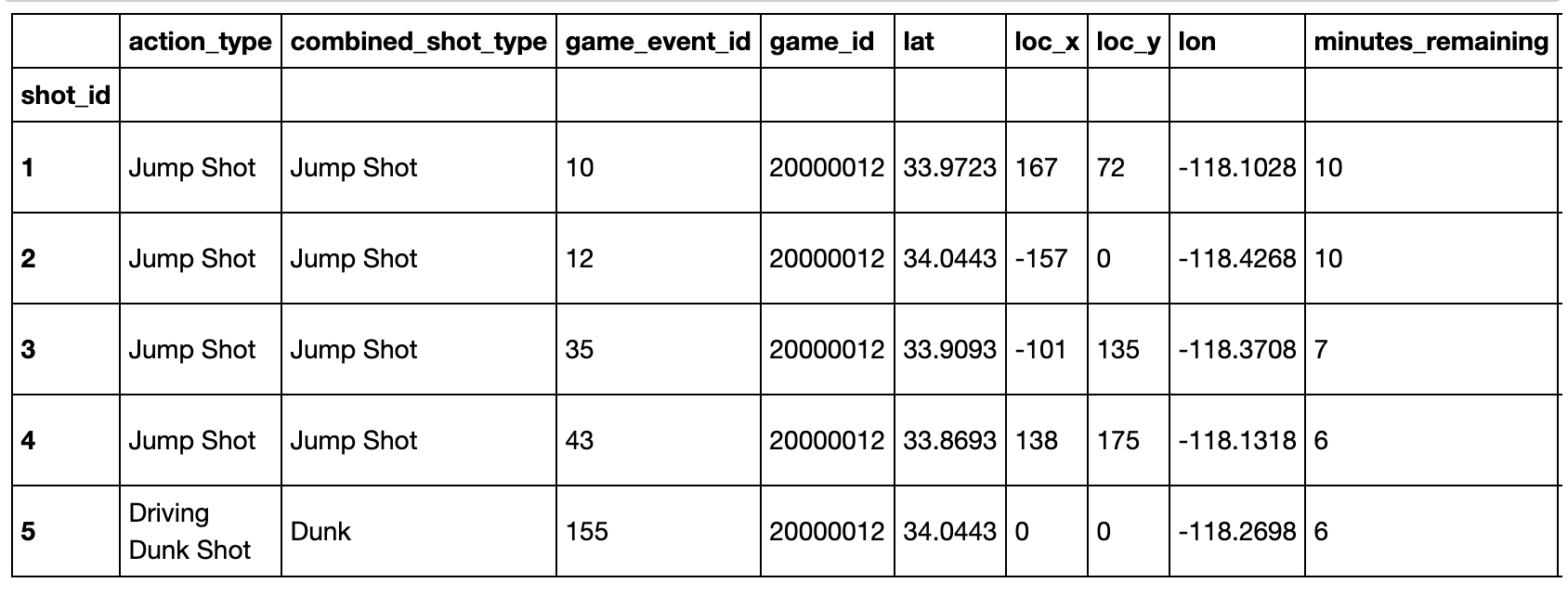
- 哪种action_type和combined_shot_type的组合是最多的?
pd.Series(list(zip(df['action_type'],df['combined_shot_type']))).value_counts().index[0]
('Jump Shot', 'Jump Shot')
- 在所有被记录的game_id中,遭遇到最多的opponent是一个支?
pd.Series(list(list(zip(*(pd.Series(list(zip(df['game_id'],df['opponent']))).unique()).tolist()))[1])).value_counts().index[0]
'SAS'
索引
import pandas as pd
df = pd.read_csv('data/table.csv',index_col='ID')
df.head()
School Class Gender Address Height Weight Math Physics
ID
1101 S_1 C_1 M street_1 173 63 34.0 A+
1102 S_1 C_1 F street_2 192 73 32.5 B+
1103 S_1 C_1 M street_2 186 82 87.2 B+
1104 S_1 C_1 F street_2 167 81 80.4 B-
1105 S_1 C_1 F street_4 159 64 84.8 B+
单级索引
loc方法、iloc方法、[]操作符
最常用的索引方法可能就是这三类,其中iloc表示位置索引,loc表示标签索引,[]也具有很大的便利性,各有特点
loc方法
注意:所有在loc中使用的切片全部包含右端点!
单行索引
df.loc[1103]
School S_1
Class C_1
Gender M
Address street_2
Height 186
Weight 82
Math 87.2
Physics B+
Name: 1103, dtype: object
多行索引
df.loc[[1102,2304]]
School Class Gender Address Height Weight Math Physics
ID
1102 S_1 C_1 F street_2 192 73 32.5 B+
2304 S_2 C_3 F street_6 164 81 95.5 A-
df.loc[1304:].head()
School Class Gender Address Height Weight Math Physics
ID
1304 S_1 C_3 M street_2 195 70 85.2 A
1305 S_1 C_3 F street_5 187 69 61.7 B-
2101 S_2 C_1 M street_7 174 84 83.3 C
2102 S_2 C_1 F street_6 161 61 50.6 B+
2103 S_2 C_1 M street_4 157 61 52.5 B-
df.loc[2402::-1].head()
School Class Gender Address Height Weight Math Physics
ID
2402 S_2 C_4 M street_7 166 82 48.7 B
2401 S_2 C_4 F street_2 192 62 45.3 A
2305 S_2 C_3 M street_4 187 73 48.9 B
2304 S_2 C_3 F street_6 164 81 95.5 A-
2303 S_2 C_3 F street_7 190 99 65.9 C
单列索引
df.loc[:,'Height'].head()
ID
1101 173
1102 192
1103 186
1104 167
1105 159
Name: Height, dtype: int64
多列索引:
df.loc[:,['Height','Math']].head()
Height Math
ID
1101 173 34.0
1102 192 32.5
1103 186 87.2
1104 167 80.4
1105 159 84.8
df.loc[:,'Height':'Math'].head()
Height Weight Math
ID
1101 173 63 34.0
1102 192 73 32.5
1103 186 82 87.2
1104 167 81 80.4
1105 159 64 84.8
联合索引
df.loc[1102:2401:3,'Height':'Math'].head()
Height Weight Math
ID
1102 192 73 32.5
1105 159 64 84.8
1203 160 53 58.8
1301 161 68 31.5
1304 195 70 85.2
函数式索引
df.loc[lambda x:x['Gender']=='M'].head()#loc中使用的函数,传入参数就是前面的df
School Class Gender Address Height Weight Math Physics
ID
1101 S_1 C_1 M street_1 173 63 34.0 A+
1103 S_1 C_1 M street_2 186 82 87.2 B+
1201 S_1 C_2 M street_5 188 68 97.0 A-
1203 S_1 C_2 M street_6 160 53 58.8 A+
1301 S_1 C_3 M street_4 161 68 31.5 B+
def f(x):
return [1101,1103]
df.loc[f]
School Class Gender Address Height Weight Math Physics
ID
1101 S_1 C_1 M street_1 173 63 34.0 A+
1103 S_1 C_1 M street_2 186 82 87.2 B+
布尔索引
df.loc[df['Address'].isin(['street_7','street_4'])].head()
School Class Gender Address Height Weight Math Physics
ID
1105 S_1 C_1 F street_4 159 64 84.8 B+
1202 S_1 C_2 F street_4 176 94 63.5 B-
1301 S_1 C_3 M street_4 161 68 31.5 B+
1303 S_1 C_3 M street_7 188 82 49.7 B
2101 S_2 C_1 M street_7 174 84 83.3 C
df.loc[[True if i[-1]=='4' or i[-1]=='7' else False for i in df['Address'].values]].head()
School Class Gender Address Height Weight Math Physics
ID
1105 S_1 C_1 F street_4 159 64 84.8 B+
1202 S_1 C_2 F street_4 176 94 63.5 B-
1301 S_1 C_3 M street_4 161 68 31.5 B+
1303 S_1 C_3 M street_7 188 82 49.7 B
2101 S_2 C_1 M street_7 174 84 83.3 C
本质上说,loc中能传入的只有布尔列表和索引子集构成的列表,只要把握这个原则就很容易理解上面那些操作
iloc方法
注意与loc不同,切片右端点不包含
单行索引
df.iloc[3]
School S_1
Class C_1
Gender F
Address street_2
Height 167
Weight 81
Math 80.4
Physics B-
Name: 1104, dtype: object
多行索引
df.iloc[3:5]
School Class Gender Address Height Weight Math Physics
ID
1104 S_1 C_1 F street_2 167 81 80.4 B-
1105 S_1 C_1 F street_4 159 64 84.8 B+
单列索引
df.iloc[:,3].head()
ID
1101 street_1
1102 street_2
1103 street_2
1104 street_2
1105 street_4
Name: Address, dtype: object
多列索引
df.iloc[:,7::-2].head()
Physics Weight Address Class
ID
1101 A+ 63 street_1 C_1
1102 B+ 73 street_2 C_1
1103 B+ 82 street_2 C_1
1104 B- 81 street_2 C_1
1105 B+ 64 street_4 C_1
混合索引
df.iloc[3::4,7::-2].head()
Physics Weight Address Class
ID
1104 B- 81 street_2 C_1
1203 A+ 53 street_6 C_2
1302 A- 57 street_1 C_3
2101 C 84 street_7 C_1
2105 A 81 street_4 C_1
函数式索引
df.iloc[lambda x:[3]].head()
School Class Gender Address Height Weight Math Physics
ID
1104 S_1 C_1 F street_2 167 81 80.4 B-
小节:由上所述,iloc中接收的参数只能为整数或整数列表,不能使用布尔索引
[]操作符
如果不想陷入困境,请不要在行索引为浮点时使用[]操作符,因为在Series中的浮点[]并不是进行位置比较,而是值比较,非常特殊
Series的[]操作
单元素索引
s = pd.Series(df['Math'],index=df.index)
s[1101]#使用的是索引标签
34.0
多行索引
s[0:4]#使用的是绝对位置的整数切片,与元素无关,这里容易混淆
ID
1101 34.0
1102 32.5
1103 87.2
1104 80.4
Name: Math, dtype: float64
函数式索引
s[lambda x: x.index[16::-6]]#注意使用lambda函数时,直接切片(如:s[lambda x: 16::-6])就报错,此时使用的不是绝对位置切片,而是元素切片,非常易错
ID
2102 50.6
1301 31.5
1105 84.8
Name: Math, dtype: float64
布尔索引
s[s>80]
ID
1103 87.2
1104 80.4
1105 84.8
1201 97.0
1302 87.7
1304 85.2
2101 83.3
2205 85.4
2304 95.5
Name: Math, dtype: float64
DataFrame的[]操作
单行索引
df[1:2]
#这里非常容易写成df['label'],会报错
#同Series使用了绝对位置切片
#如果想要获得某一个元素,可用如下get_loc方法:
School Class Gender Address Height Weight Math Physics
ID
1102 S_1 C_1 F street_2 192 73 32.5 B+
row = df.index.get_loc(1102)
df[row:row+1]
School Class Gender Address Height Weight Math Physics
ID
1102 S_1 C_1 F street_2 192 73 32.5 B+
多行索引
#用切片,如果是选取指定的某几行,推荐使用loc,否则很可能报错
df[3:5]
School Class Gender Address Height Weight Math Physics
ID
1104 S_1 C_1 F street_2 167 81 80.4 B-
1105 S_1 C_1 F street_4 159 64 84.8 B+
单列索引
df['School'].head()
ID
1101 S_1
1102 S_1
1103 S_1
1104 S_1
1105 S_1
Name: School, dtype: object
多列索引
df[['School','Math']].head()
School Math
ID
1101 S_1 34.0
1102 S_1 32.5
1103 S_1 87.2
1104 S_1 80.4
1105 S_1 84.8
函数式索引
df[lambda x:['Math','Physics']].head()
Math Physics
ID
1101 34.0 A+
1102 32.5 B+
1103 87.2 B+
1104 80.4 B-
1105 84.8 B+
布尔索引
df[df['Gender']=='F'].head()
School Class Gender Address Height Weight Math Physics
ID
1102 S_1 C_1 F street_2 192 73 32.5 B+
1104 S_1 C_1 F street_2 167 81 80.4 B-
1105 S_1 C_1 F street_4 159 64 84.8 B+
1202 S_1 C_2 F street_4 176 94 63.5 B-
1204 S_1 C_2 F street_5 162 63 33.8 B
一般来说,[]操作符常用于列选择或布尔选择,尽量避免行的选择
布尔索引
布尔符号
&,|,~:分别代表和and,或or,取反not
df[(df['Gender']=='F')&(df['Address']=='street_2')].head()
School Class Gender Address Height Weight Math Physics
ID
1102 S_1 C_1 F street_2 192 73 32.5 B+
1104 S_1 C_1 F street_2 167 81 80.4 B-
2401 S_2 C_4 F street_2 192 62 45.3 A
2404 S_2 C_4 F street_2 160 84 67.7 B
df[(df['Math']>85)|(df['Address']=='street_7')].head()
School Class Gender Address Height Weight Math Physics
ID
1103 S_1 C_1 M street_2 186 82 87.2 B+
1201 S_1 C_2 M street_5 188 68 97.0 A-
1302 S_1 C_3 F street_1 175 57 87.7 A-
1303 S_1 C_3 M street_7 188 82 49.7 B
1304 S_1 C_3 M street_2 195 70 85.2 A
df[~((df['Math']>75)|(df['Address']=='street_1'))].head()
School Class Gender Address Height Weight Math Physics
ID
1102 S_1 C_1 F street_2 192 73 32.5 B+
1202 S_1 C_2 F street_4 176 94 63.5 B-
1203 S_1 C_2 M street_6 160 53 58.8 A+
1204 S_1 C_2 F street_5 162 63 33.8 B
1205 S_1 C_2 F street_6 167 63 68.4 B-
loc和[]中相应位置都能使用布尔列表选择:
df.loc[df['Math']>60,(df[:8]['Address']=='street_6').values].head()
#如果不加values就会索引对齐发生错误,Pandas中的索引对齐是一个重要特征,很多时候非常实用
#但是若不加以留意,就会埋下隐患
Physics
ID
1103 B+
1104 B-
1105 B+
1201 A-
1202 B-
isin方法
df[df['Address'].isin(['street_1','street_4'])&df['Physics'].isin(['A','A+'])]
School Class Gender Address Height Weight Math Physics
ID
1101 S_1 C_1 M street_1 173 63 34.0 A+
2105 S_2 C_1 M street_4 170 81 34.2 A
2203 S_2 C_2 M street_4 155 91 73.8 A+
#上面也可以用字典方式写:
df[df[['Address','Physics']].isin({'Address':['street_1','street_4'],'Physics':['A','A+']}).all(1)]
#all与&的思路是类似的,其中的1代表按照跨列方向判断是否全为True
School Class Gender Address Height Weight Math Physics
ID
1101 S_1 C_1 M street_1 173 63 34.0 A+
2105 S_2 C_1 M street_4 170 81 34.2 A
2203 S_2 C_2 M street_4 155 91 73.8 A+
快速标量索引
当只需要取一个元素时,at和iat方法能够提供更快的实现:
display(df.at[1101,'School'])
display(df.loc[1101,'School'])
display(df.iat[0,0])
display(df.iloc[0,0])
#可尝试去掉注释对比时间
#%timeit df.at[1101,'School']
#%timeit df.loc[1101,'School']
#%timeit df.iat[0,0]
#%timeit df.iloc[0,0]
'S_1'
'S_1'
'S_1'
'S_1'
区间索引
此处介绍并不是说只能在单级索引中使用区间索引,只是作为一种特殊类型的索引方式,在此处先行介绍
利用interval_range方法
pd.interval_range(start=0,end=5)
#closed参数可选'left''right''both''neither',默认左开右闭
IntervalIndex([(0, 1], (1, 2], (2, 3], (3, 4], (4, 5]],
closed='right',
dtype='interval[int64]')
pd.interval_range(start=0,periods=8,freq=5)
#periods参数控制区间个数,freq控制步长
IntervalIndex([(0, 5], (5, 10], (10, 15], (15, 20], (20, 25], (25, 30], (30, 35], (35, 40]],
closed='right',
dtype='interval[int64]')
利用cut将数值列转为区间为元素的分类变量,例如统计数学成绩的区间情况:
math_interval = pd.cut(df['Math'],bins=[0,40,60,80,100])
#注意,如果没有类型转换,此时并不是区间类型,而是category类型
math_interval.head()
ID
1101 (0, 40]
1102 (0, 40]
1103 (80, 100]
1104 (80, 100]
1105 (80, 100]
Name: Math, dtype: category
Categories (4, interval[int64]): [(0, 40] < (40, 60] < (60, 80] < (80, 100]]
区间索引的选取
df_i = df.join(math_interval,rsuffix='_interval')[['Math','Math_interval']]\
.reset_index().set_index('Math_interval')
df_i.head()
ID Math
Math_interval
(0, 40] 1101 34.0
(0, 40] 1102 32.5
(80, 100] 1103 87.2
(80, 100] 1104 80.4
(80, 100] 1105 84.8
df_i.loc[65].head()
#包含该值就会被选中
ID Math
Math_interval
(60, 80] 1202 63.5
(60, 80] 1205 68.4
(60, 80] 1305 61.7
(60, 80] 2104 72.2
(60, 80] 2202 68.5
df_i.loc[[65,90]].head()
ID Math
Math_interval
(60, 80] 1202 63.5
(60, 80] 1205 68.4
(60, 80] 1305 61.7
(60, 80] 2104 72.2
(60, 80] 2202 68.5
如果想要选取某个区间,先要把分类变量转为区间变量,再使用overlap方法:
#df_i.loc[pd.Interval(70,75)].head() 报错
df_i[df_i.index.astype('interval').overlaps(pd.Interval(70, 85))].head()
ID Math
Math_interval
(80, 100] 1103 87.2
(80, 100] 1104 80.4
(80, 100] 1105 84.8
(80, 100] 1201 97.0
(60, 80] 1202 63.5
多级索引
创建多级索引
通过from_tuple或from_arrays
直接创建元组
tuples = [('A','a'),('A','b'),('B','a'),('B','b')]
mul_index = pd.MultiIndex.from_tuples(tuples, names=('Upper', 'Lower'))
mul_index
MultiIndex([('A', 'a'),
('A', 'b'),
('B', 'a'),
('B', 'b')],
names=['Upper', 'Lower'])
pd.DataFrame({'Score':['perfect','good','fair','bad']},index=mul_index)
Score
Upper Lower
A a perfect
b good
B a fair
b bad
利用zip创建元组
L1 = list('AABB')
L2 = list('abab')
tuples = list(zip(L1,L2))
mul_index = pd.MultiIndex.from_tuples(tuples, names=('Upper', 'Lower'))
pd.DataFrame({'Score':['perfect','good','fair','bad']},index=mul_index)
Score
Upper Lower
A a perfect
b good
B a fair
b bad
通过Array创建
arrays = [['A','a'],['A','b'],['B','a'],['B','b']]
mul_index = pd.MultiIndex.from_tuples(arrays, names=('Upper', 'Lower'))
pd.DataFrame({'Score':['perfect','good','fair','bad']},index=mul_index)
Score
Upper Lower
A a perfect
b good
B a fair
b bad
mul_index
#由此看出内部自动转成元组
MultiIndex([('A', 'a'),
('A', 'b'),
('B', 'a'),
('B', 'b')],
names=['Upper', 'Lower'])
通过from_product
L1 = ['A','B']
L2 = ['a','b']
pd.MultiIndex.from_product([L1,L2],names=('Upper', 'Lower'))
#两两相乘
MultiIndex([('A', 'a'),
('A', 'b'),
('B', 'a'),
('B', 'b')],
names=['Upper', 'Lower'])
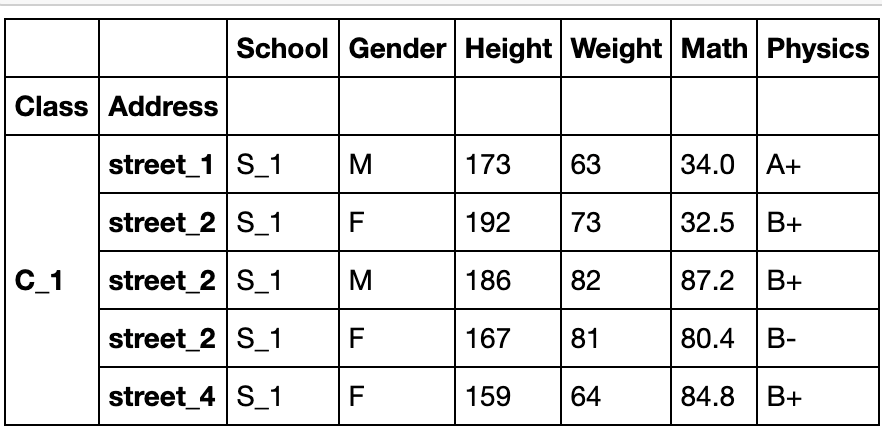
指定df中的列创建(set_index方法)
df_using_mul = df.set_index(['Class','Address'])
df_using_mul.head()
多层索引切片
df_using_mul.head()
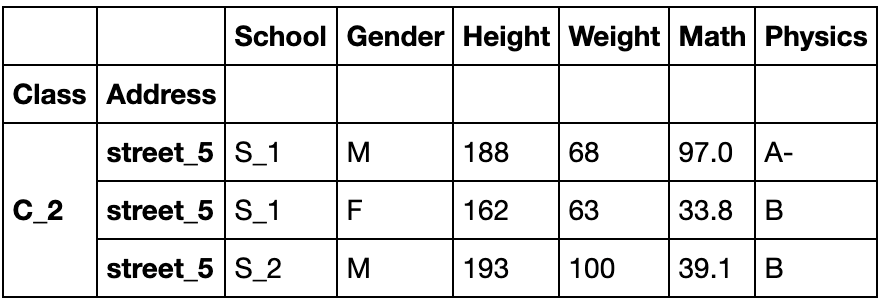
一般切片
#df_using_mul.loc['C_2','street_5']
#当索引不排序时,单个索引会报出性能警告
#df_using_mul.index.is_lexsorted()
#该函数检查是否排序
df_using_mul.sort_index().loc['C_2','street_5']
#df_using_mul.sort_index().index.is_lexsorted()
#df_using_mul.loc[('C_2','street_5'):] 报错
#当不排序时,不能使用多层切片
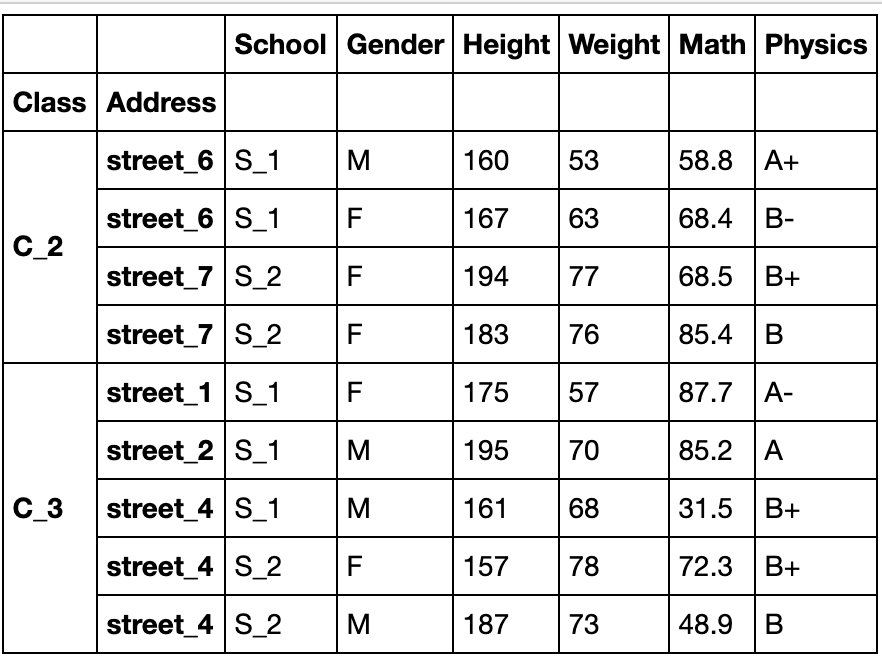
df_using_mul.sort_index().loc[('C_2','street_6'):('C_3','street_4')]
#注意此处由于使用了loc,因此仍然包含右端点
df_using_mul.sort_index().loc[('C_2','street_7'):'C_3'].head()
#非元组也是合法的,表示选中该层所有元素
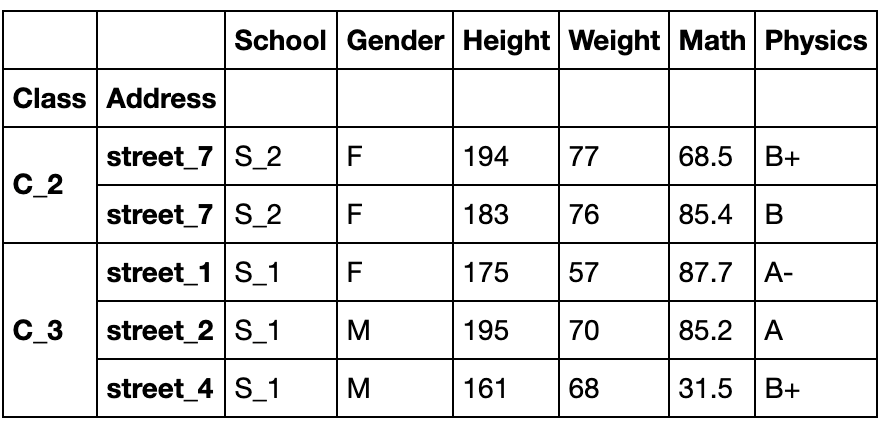
第一类特殊情况:由元组构成列表
df_using_mul.sort_index().loc[[('C_2','street_7'),('C_3','street_2')]]
#表示选出某几个元素,精确到最内层索引
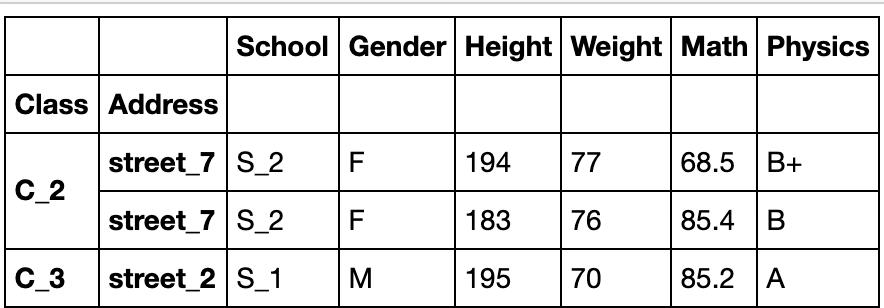
第二类特殊情况:由列表构成元组
df_using_mul.sort_index().loc[(['C_2','C_3'],['street_4','street_7']),:]
#选出第一层在‘C_2’和'C_3'中且第二层在'street_4'和'street_7'中的行
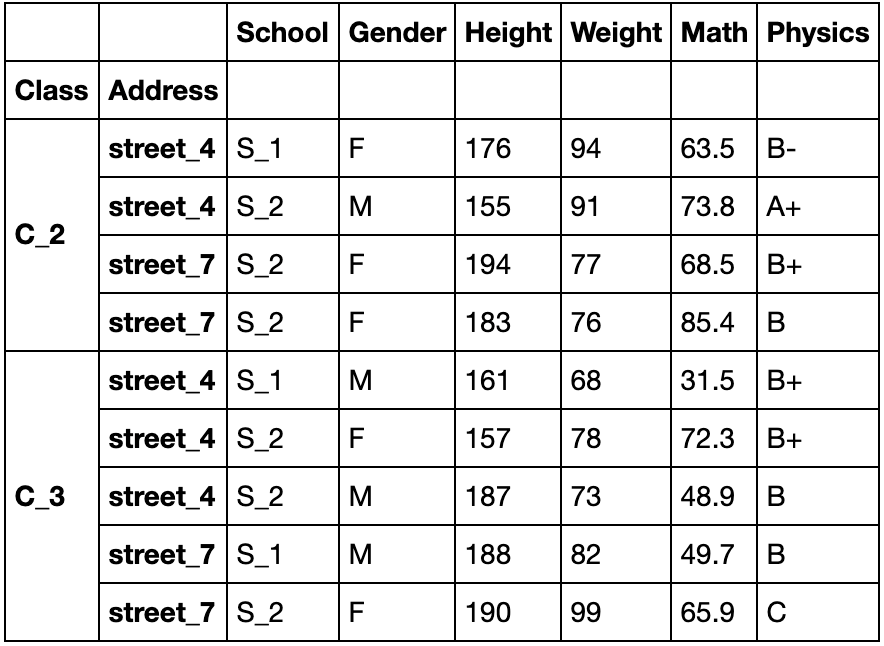
多层索引中的slice对象
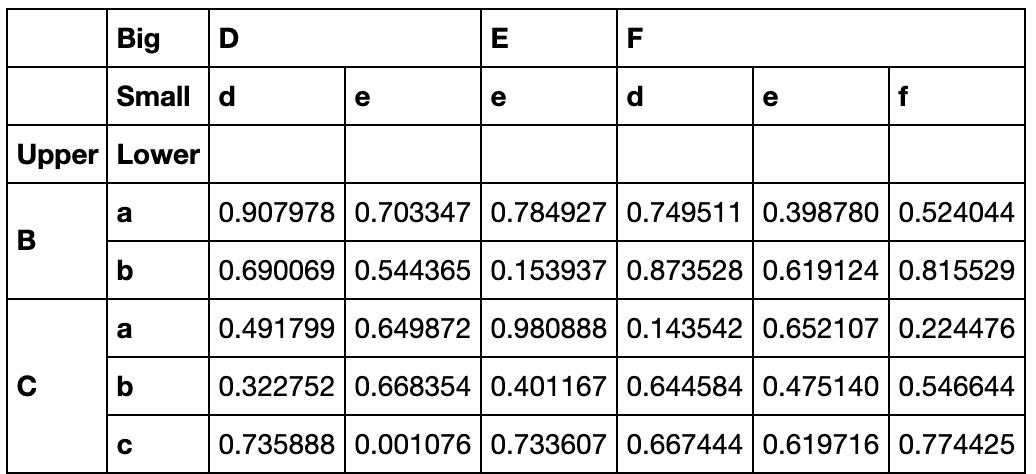
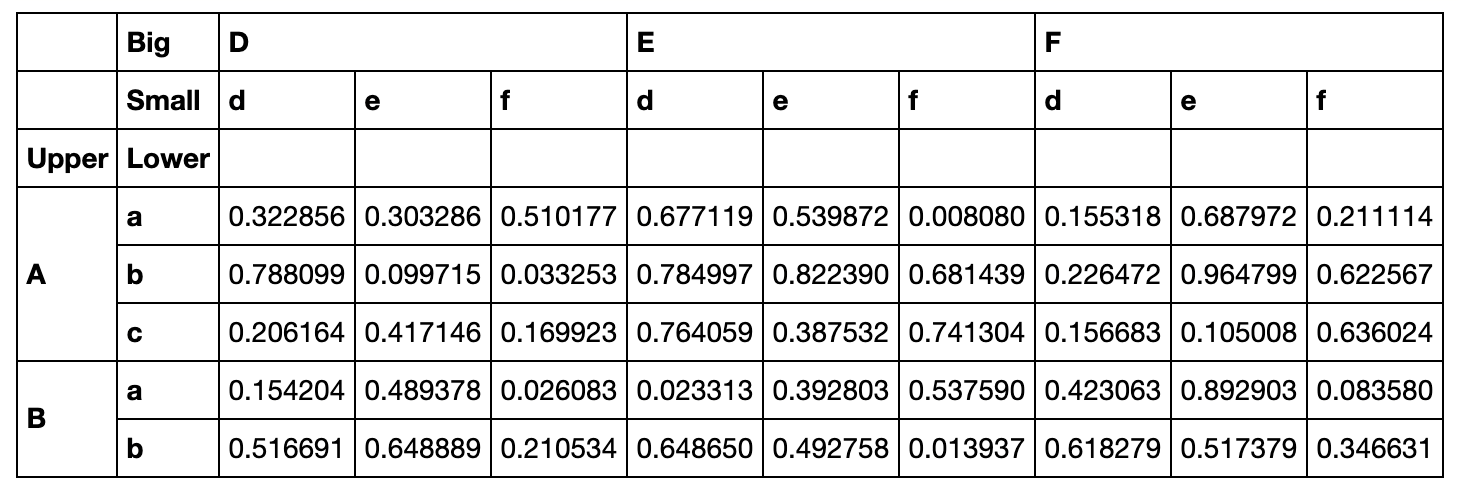
L1,L2 = ['A','B','C'],['a','b','c']
mul_index1 = pd.MultiIndex.from_product([L1,L2],names=('Upper', 'Lower'))
L3,L4 = ['D','E','F'],['d','e','f']
mul_index2 = pd.MultiIndex.from_product([L3,L4],names=('Big', 'Small'))
df_s = pd.DataFrame(np.random.rand(9,9),index=mul_index1,columns=mul_index2)
df_s
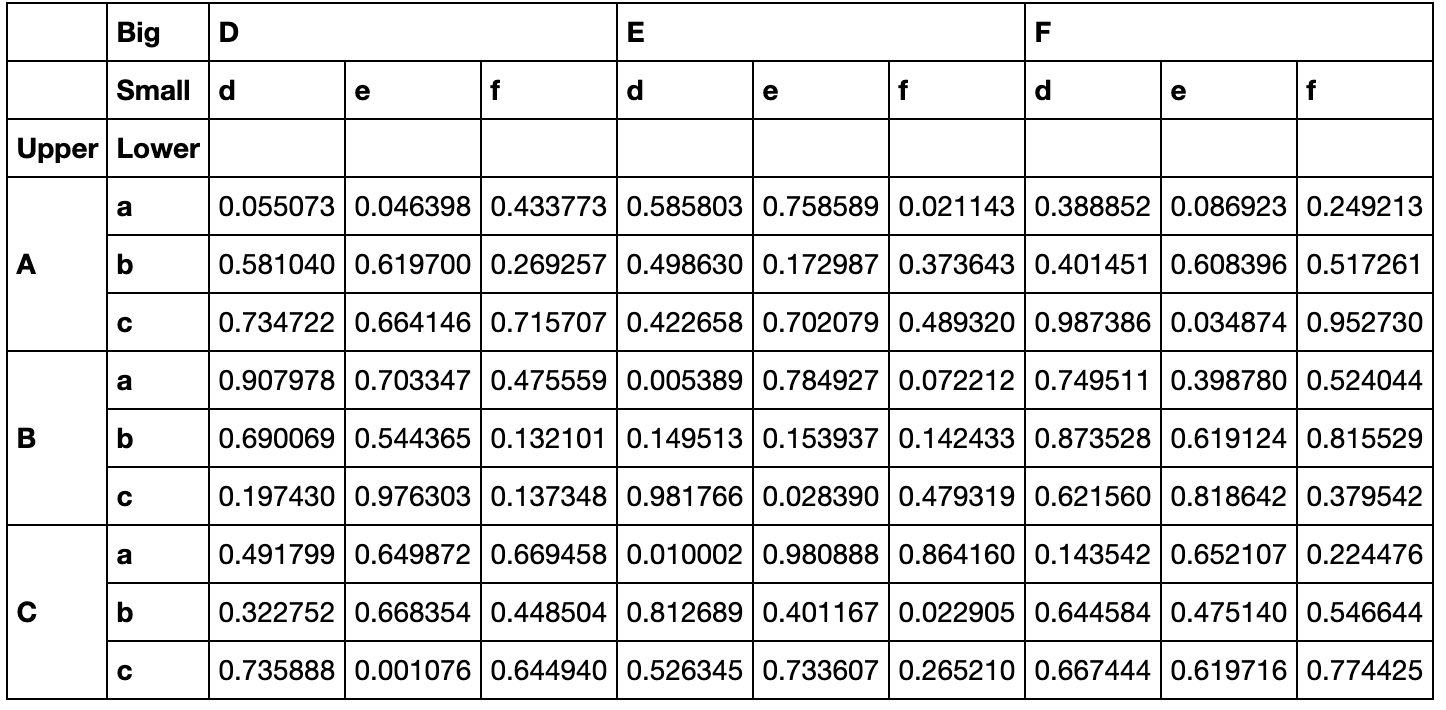
索引Slice的使用非常灵活:
df_s.loc[idx['B':,df_s['D']['d']>0.3],idx[df_s.sum()>4]]
#df_s.sum()默认为对列求和,因此返回一个长度为9的数值列表
索引层的交换
swaplevel方法(两层交换)
df_using_mul.head()
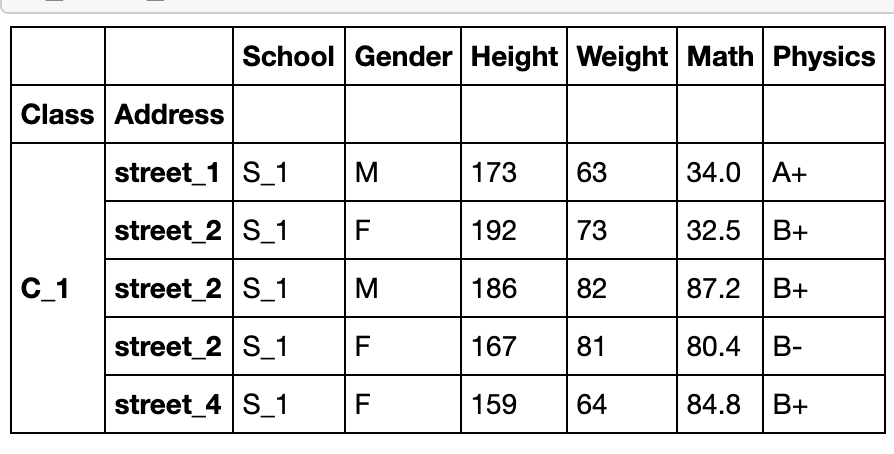
df_using_mul.swaplevel(i=1,j=0,axis=0).sort_index().head()
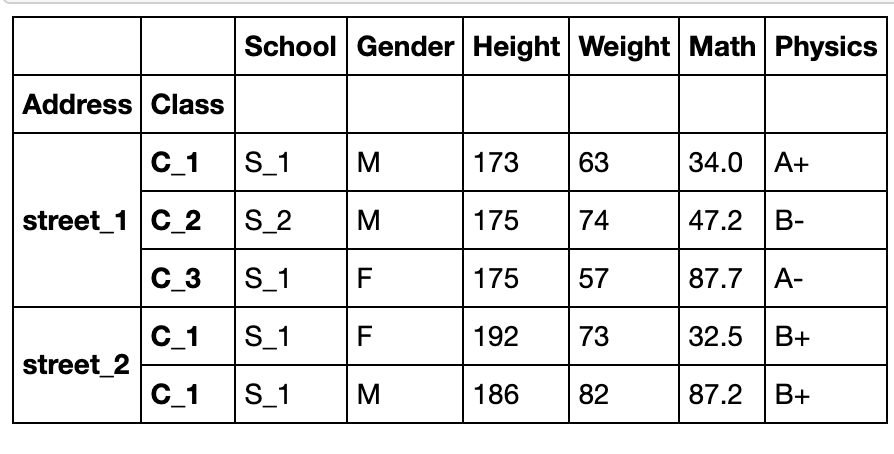
reorder_levels方法(多层交换)
df_muls = df.set_index(['School','Class','Address'])
df_muls.head()
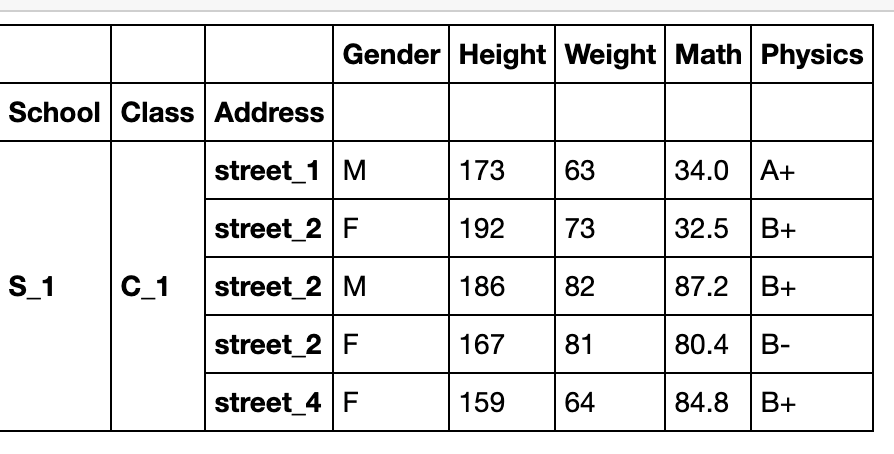
df_muls.reorder_levels([2,0,1],axis=0).sort_index().head()
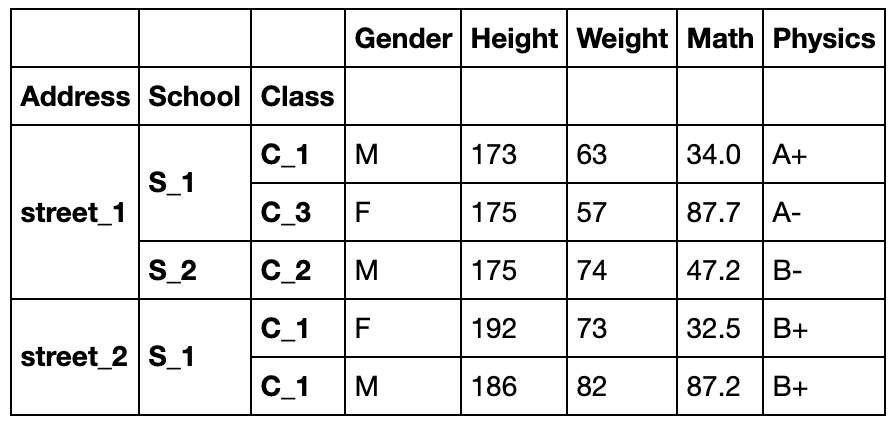
#如果索引有name,可以直接使用name
df_muls.reorder_levels(['Address','School','Class'],axis=0).sort_index().head()
索引设定
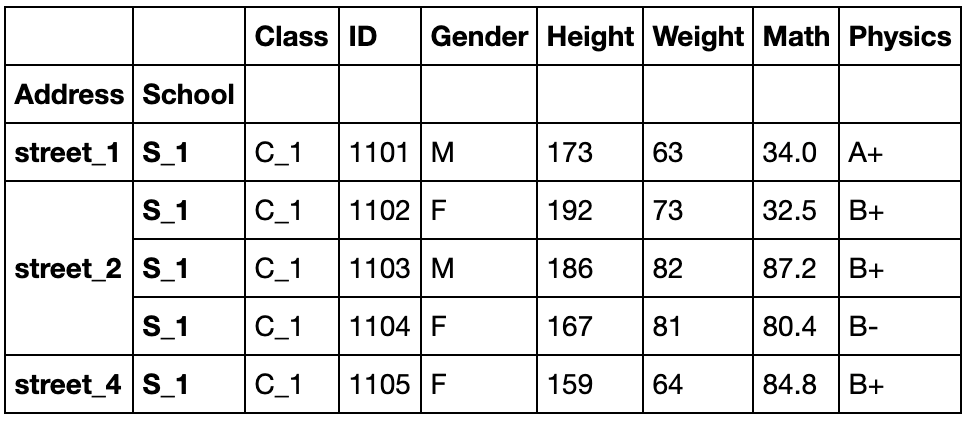
index_col参数
index_col是read_csv中的一个参数,而不是某一个方法:
pd.read_csv('data/table.csv',index_col=['Address','School']).head()
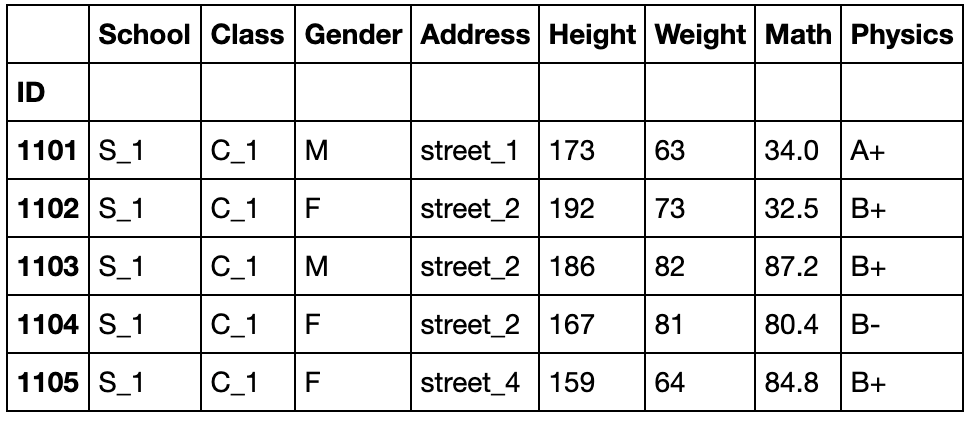
reindex和reindex_like
reindex是指重新索引,它的重要特性在于索引对齐,很多时候用于重新排序
df.head()
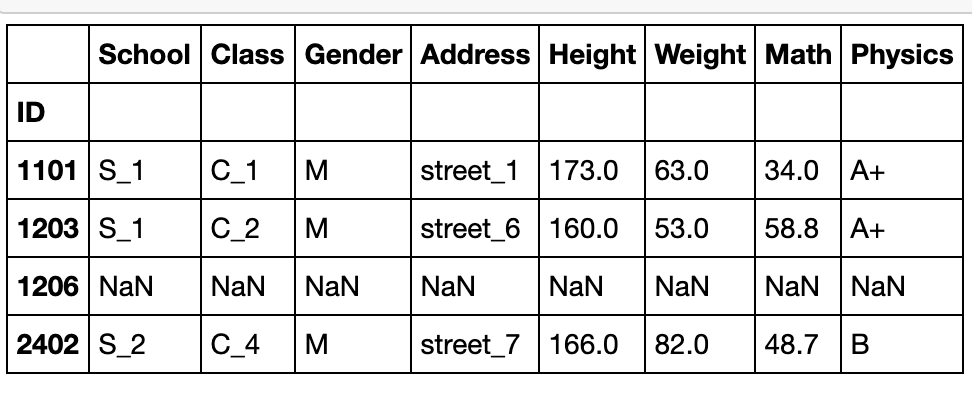
df.reindex(index=[1101,1203,1206,2402])
df.reindex(columns=['Height','Gender','Average']).head()
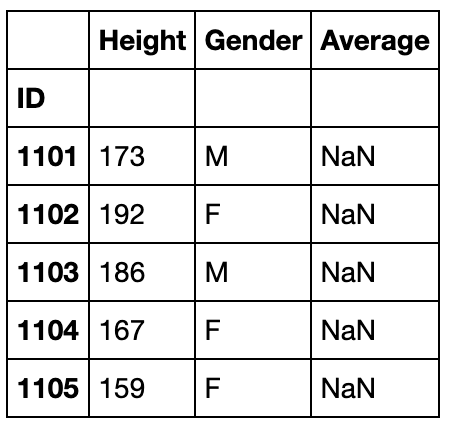
可以选择缺失值的填充方法:fill_value和method(bfill/ffill/nearest),其中method参数必须索引单调
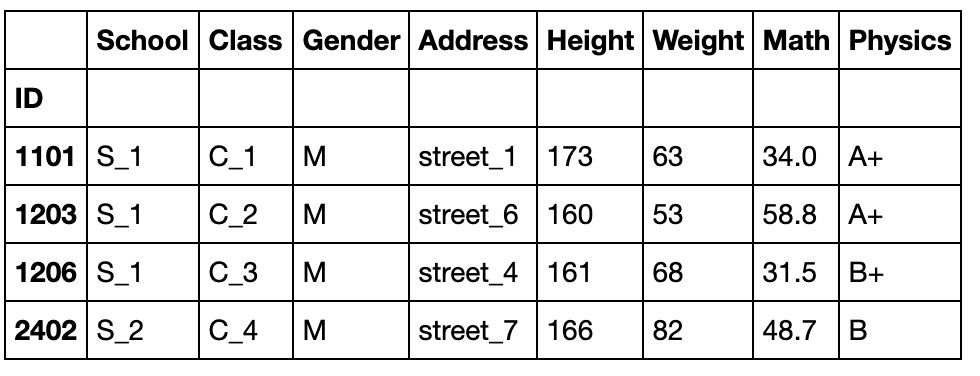
df.reindex(index=[1101,1203,1206,2402],method='bfill')
#bfill表示用所在索引1206的后一个有效行填充,ffill为前一个有效行,nearest是指最近的
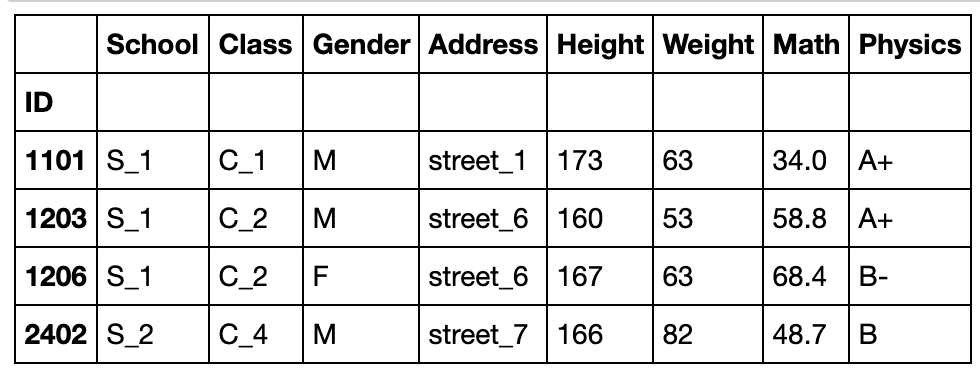
df.reindex(index=[1101,1203,1206,2402],method='nearest')
#数值上1205比1301更接近1206,因此用前者填充
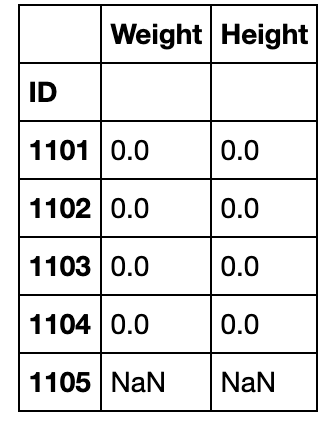
reindex_like的作用为生成一个横纵索引完全与参数列表一致的DataFrame,数据使用被调用的表
df_temp = pd.DataFrame({'Weight':np.zeros(5),
'Height':np.zeros(5),
'ID':[1101,1104,1103,1106,1102]}).set_index('ID')
df_temp.reindex_like(df[0:5][['Weight','Height']])
set_index和reset_index
先介绍set_index:从字面意思看,就是将某些列作为索引
使用表内列作为索引:
df.head()
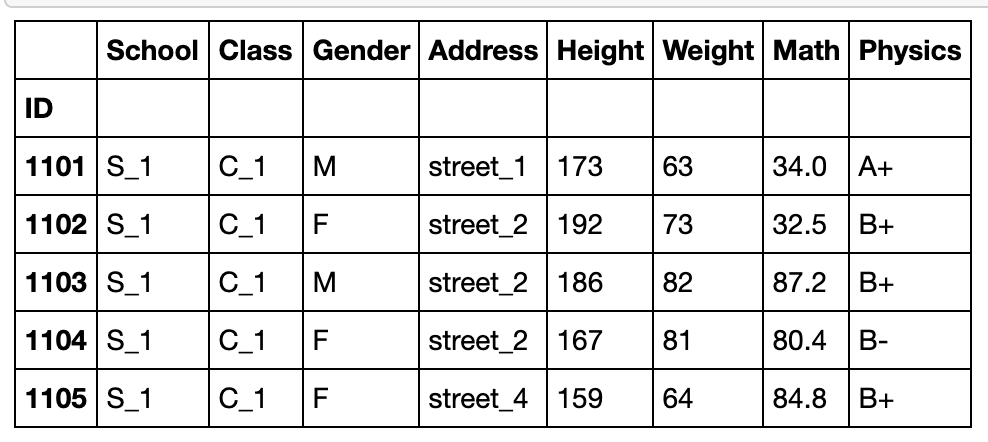
df.set_index('Class').head()
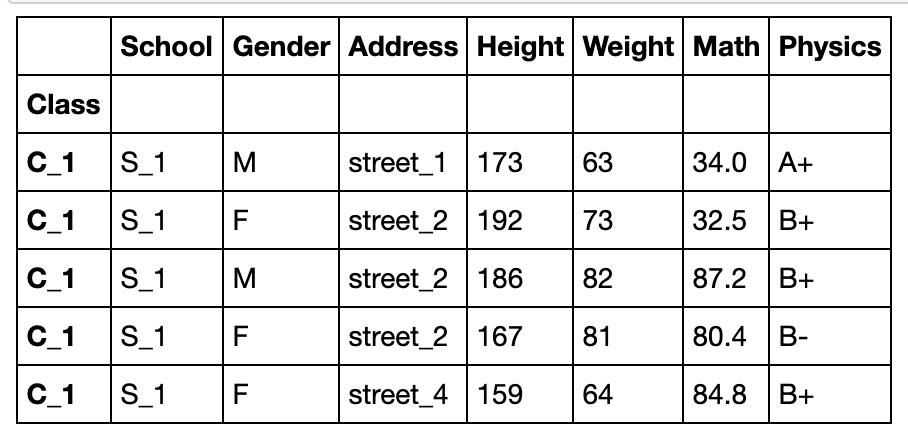
利用append参数可以将当前索引维持不变
df.set_index('Class',append=True).head()
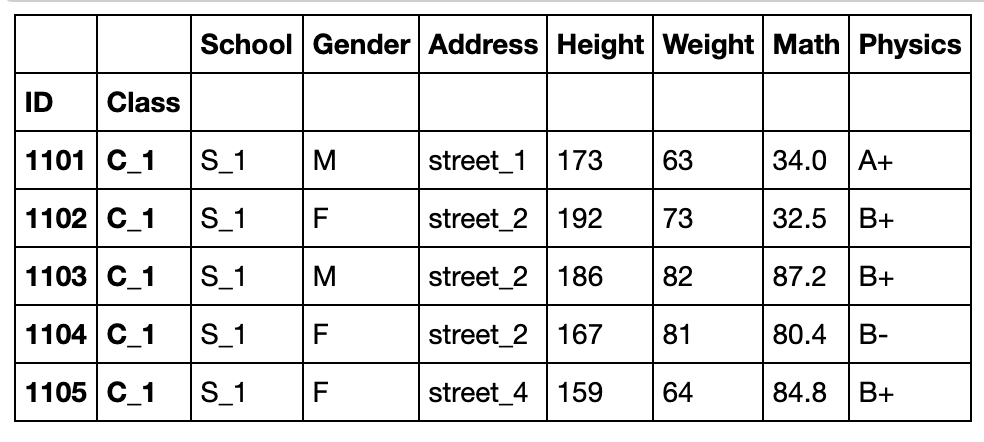
当使用与表长相同的列作为索引(需要先转化为Series,否则报错):
df.set_index(pd.Series(range(df.shape[0]))).head()
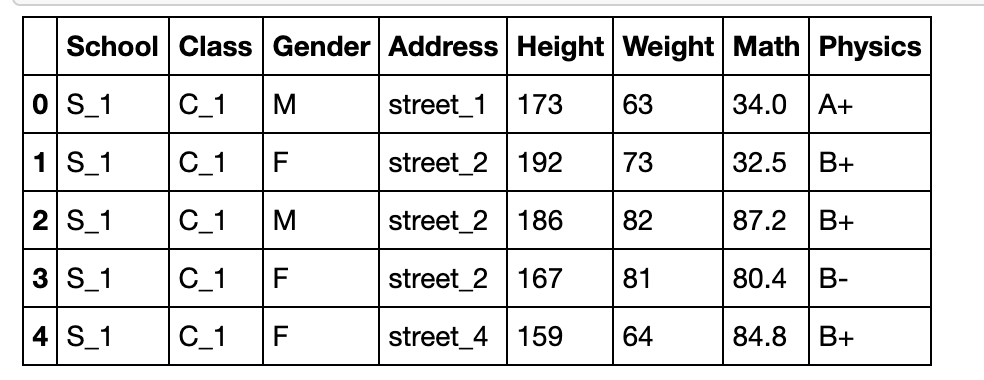
可以直接添加多级索引
df.set_index([pd.Series(range(df.shape[0])),pd.Series(np.ones(df.shape[0]))]).head()
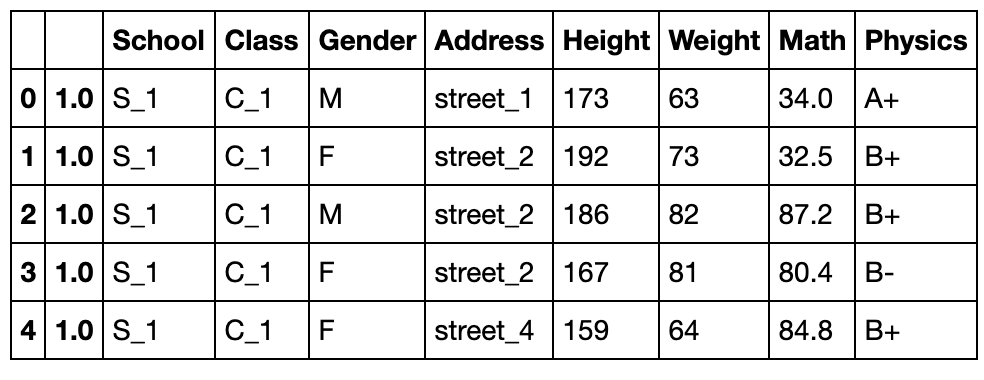
下面介绍reset_index方法,它的主要功能是将索引重置
默认状态直接恢复到自然数索引:
df.reset_index().head()
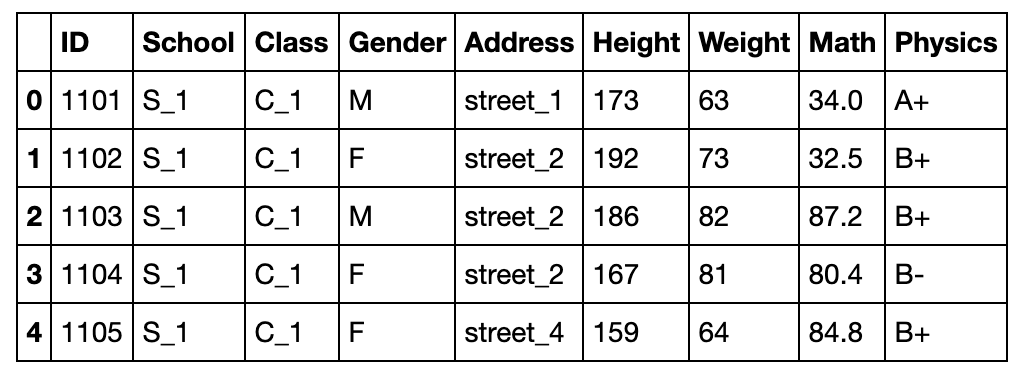
用level参数指定哪一层被reset,用col_level参数指定set到哪一层
L1,L2 = ['A','B','C'],['a','b','c']
mul_index1 = pd.MultiIndex.from_product([L1,L2],names=('Upper', 'Lower'))
L3,L4 = ['D','E','F'],['d','e','f']
mul_index2 = pd.MultiIndex.from_product([L3,L4],names=('Big', 'Small'))
df_temp = pd.DataFrame(np.random.rand(9,9),index=mul_index1,columns=mul_index2)
df_temp.head()
df_temp1 = df_temp.reset_index(level=1,col_level=1)
df_temp1.head()
df_temp1.columns
#看到的确插入了level2
MultiIndex([( '', 'Lower'),
('D', 'd'),
('D', 'e'),
('D', 'f'),
('E', 'd'),
('E', 'e'),
('E', 'f'),
('F', 'd'),
('F', 'e'),
('F', 'f')],
names=['Big', 'Small'])
df_temp1.index
#最内层索引被移出
Index(['A', 'A', 'A', 'B', 'B', 'B', 'C', 'C', 'C'], dtype='object', name='Upper')
rename_axis和rename
rename_axis是针对多级索引的方法,作用是修改某一层的索引名,而不是索引标签
df_temp.rename_axis(index={'Lower':'LowerLower'},columns={'Big':'BigBig'})
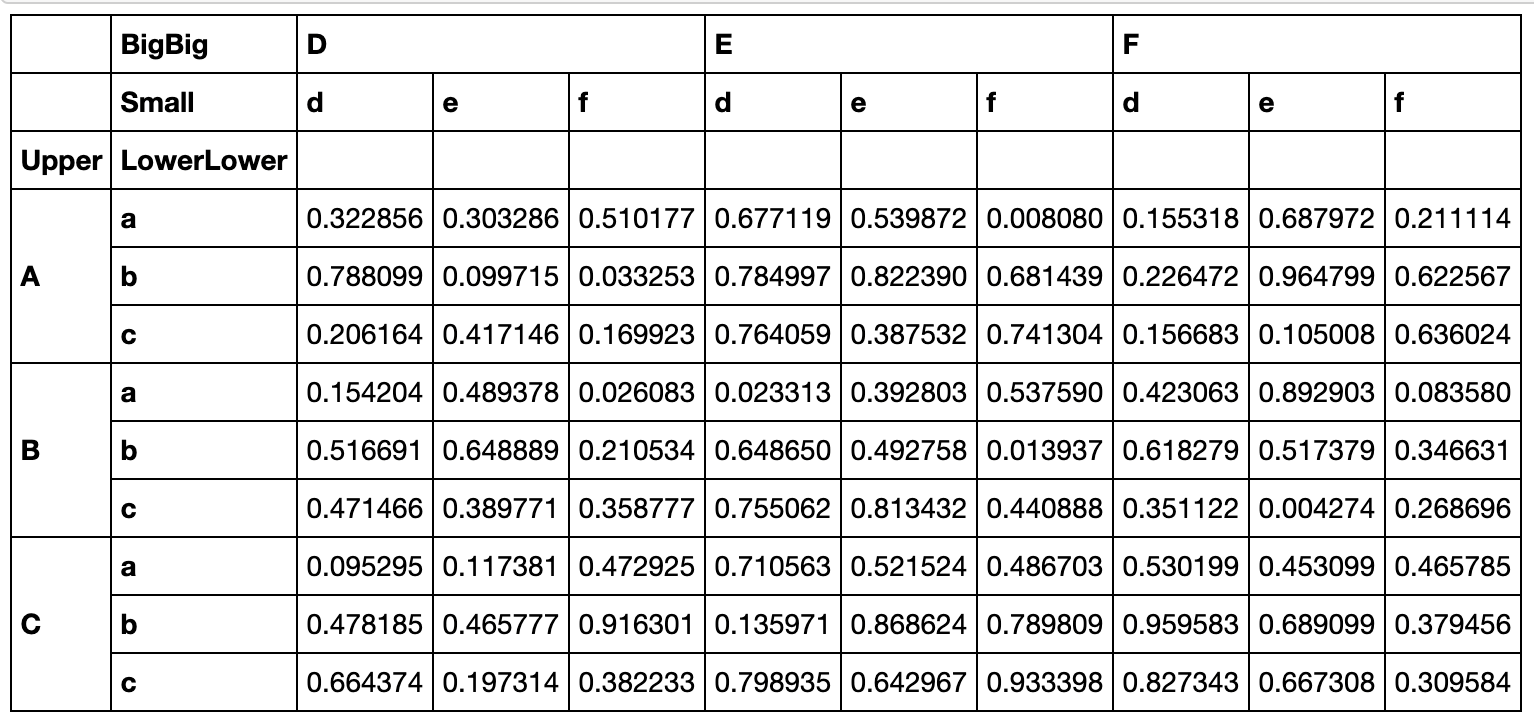
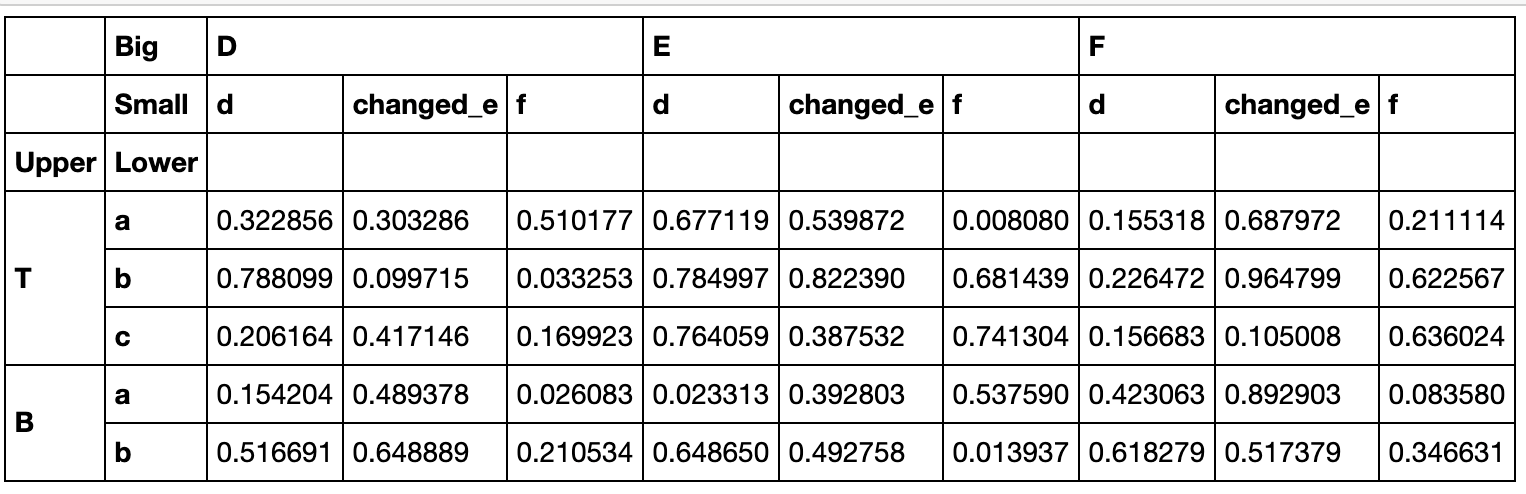
rename方法用于修改列或者行索引标签,而不是索引名:
df_temp.rename(index={'A':'T'},columns={'e':'changed_e'}).head()
常用索引型函数
where函数
当对条件为False的单元进行填充:
df.head()
df.where(df['Gender']=='M').head()
#不满足条件的行全部被设置为NaN

通过这种方法筛选结果和[]操作符的结果完全一致:
df.where(df['Gender']=='M').dropna().head()
第一个参数为布尔条件,第二个参数为填充值:
df.where(df['Gender']=='M',np.random.rand(df.shape[0],df.shape[1])).head()
mask函数
mask函数与where功能上相反,其余完全一致,即对条件为True的单元进行填充
df.mask(df['Gender']=='M').dropna().head()
df.mask(df['Gender']=='M',np.random.rand(df.shape[0],df.shape[1])).head()
query函数
df.head()
query函数中的布尔表达式中,下面的符号都是合法的:行列索引名、字符串、and/not/or/&/|/~/not in/in/==/!=、四则运算符
df.query('(Address in ["street_6","street_7"])&(Weight>(70+10))&(ID in [1303,2304,2402])')
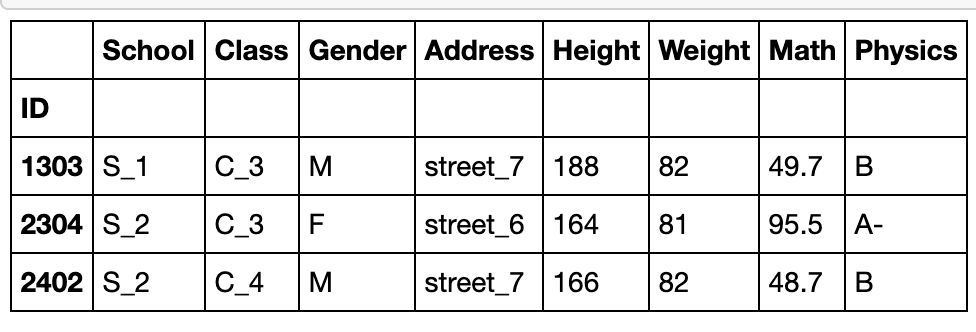
重复元素处理
duplicated方法
该方法返回了是否重复的布尔列表
df.duplicated('Class').head()
ID
1101 False
1102 True
1103 True
1104 True
1105 True
dtype: bool
可选参数keep默认为first,即首次出现设为不重复,若为last,则最后一次设为不重复,若为False,则所有重复项为False
df.duplicated('Class',keep='last').tail()
ID
2401 True
2402 True
2403 True
2404 True
2405 False
dtype: bool
df.duplicated('Class',keep=False).head()
ID
1101 True
1102 True
1103 True
1104 True
1105 True
dtype: bool
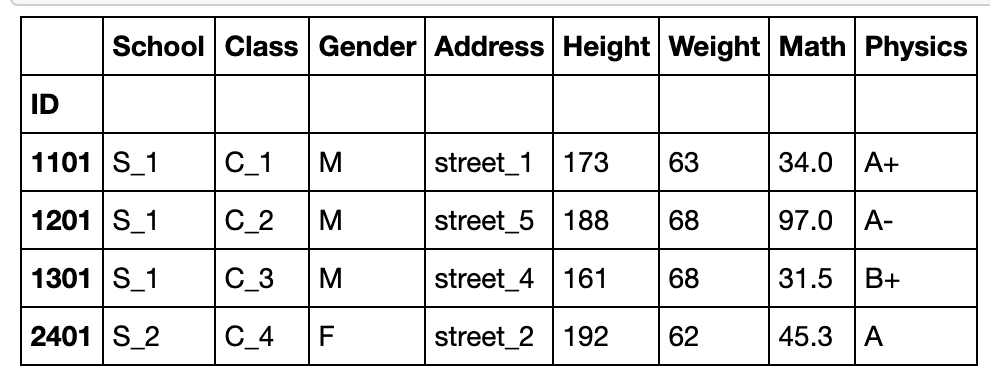
drop_duplicates方法
从名字上看出为剔除重复项,这在后面章节中的分组操作中可能是有用的,例如需要保留每组的第一个值
df.drop_duplicates('Class')
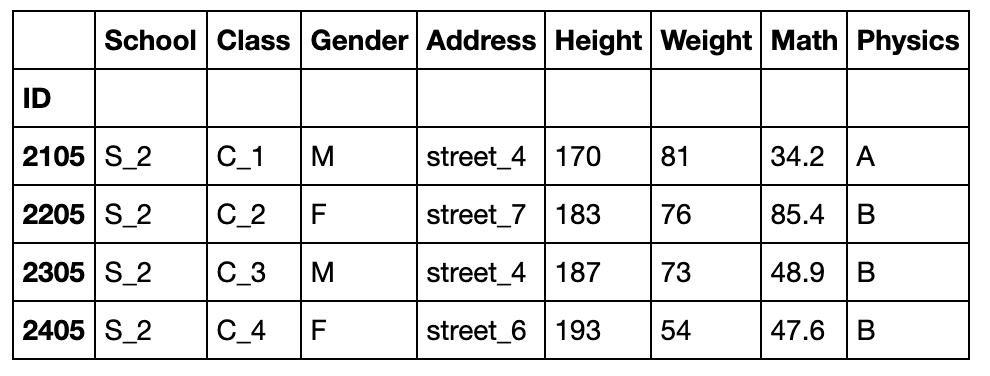
参数与duplicate函数类似:
df.drop_duplicates('Class',keep='last')
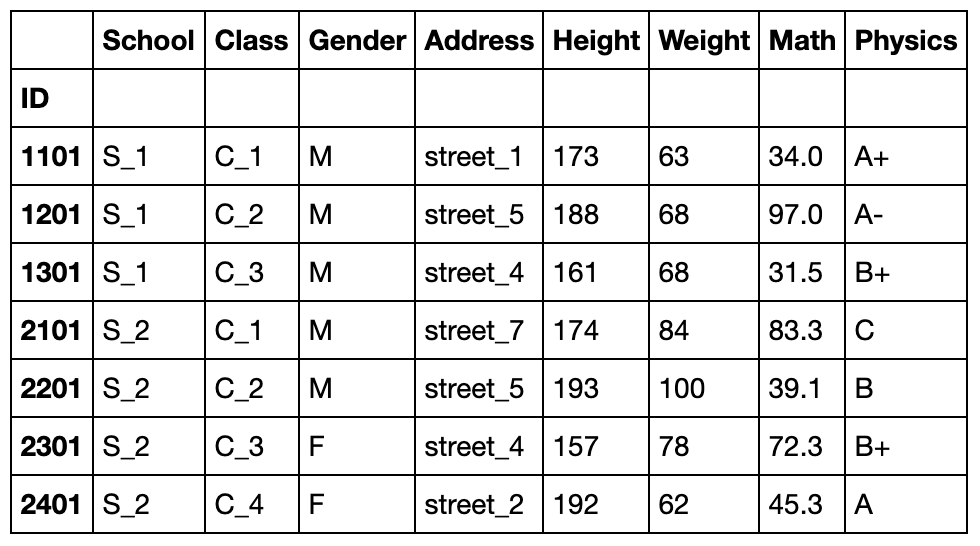
在传入多列时等价于将多列共同视作一个多级索引,比较重复项:
df.drop_duplicates(['School','Class'])
抽样函数
这里的抽样函数指的就是sample函数
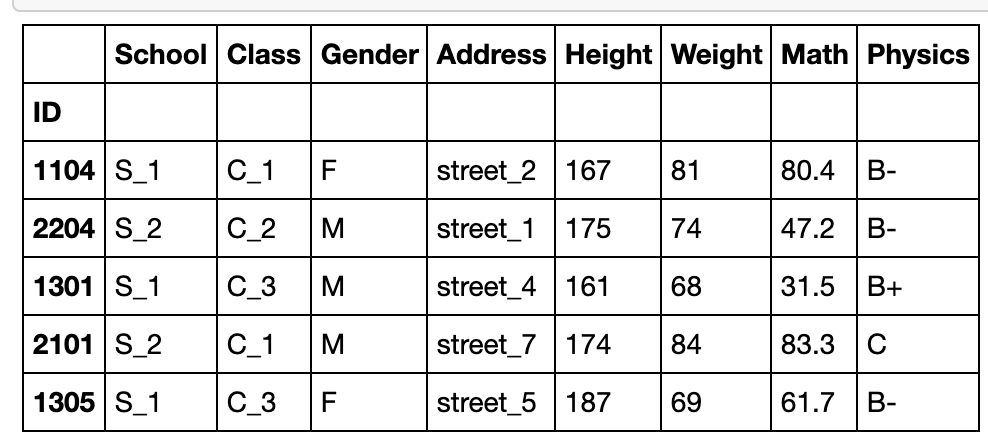
n为样本量
df.sample(n=5)
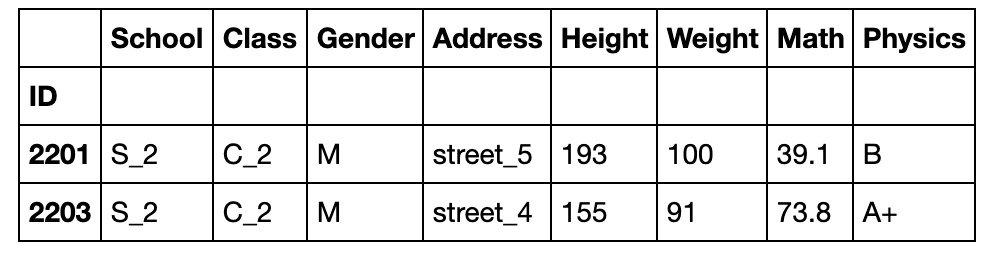
frac为抽样比
df.sample(frac=0.05)
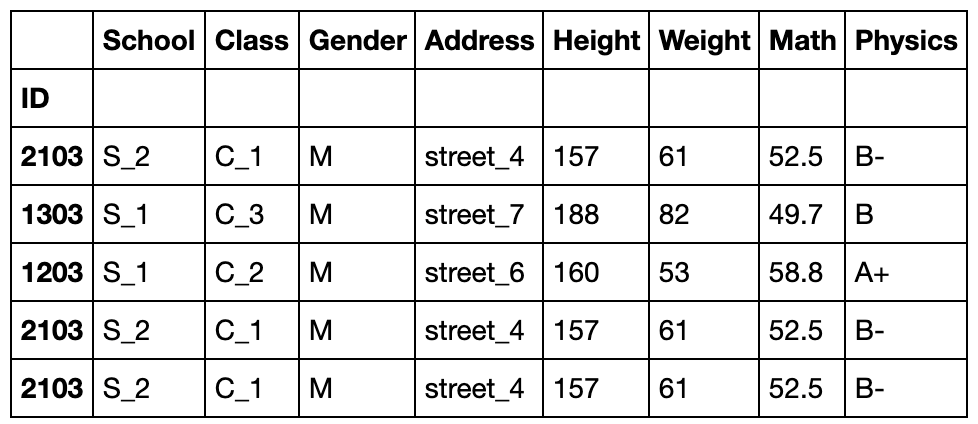
replace为是否放回
df.sample(n=df.shape[0],replace=True).head()
df.sample(n=35,replace=True).index.is_unique
False
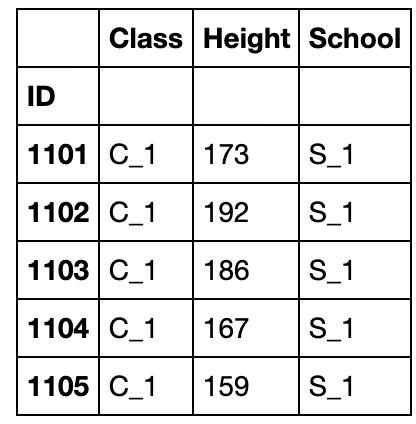
axis为抽样维度,默认为0,即抽行
df.sample(n=3,axis=1).head()
weights为样本权重,自动归一化
df.sample(n=3,weights=np.random.rand(df.shape[0])).head()
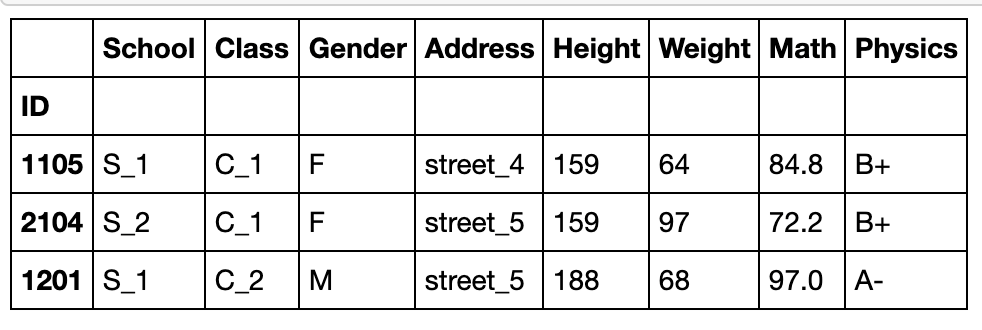
#以某一列为权重,这在抽样理论中很常见
df.sample(n=3,weights=df['Math']).head()
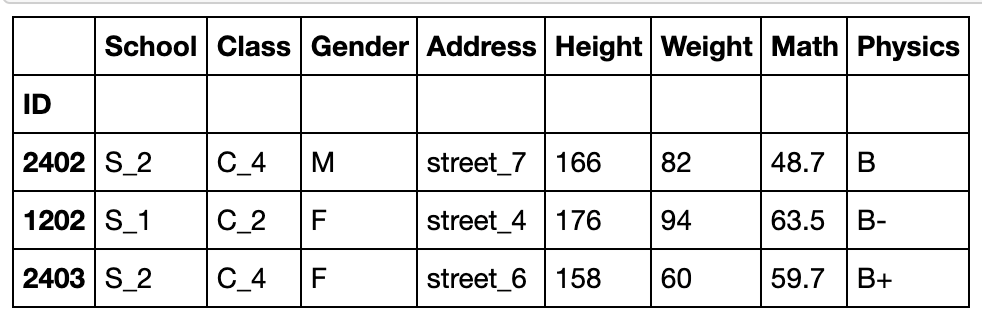
练习
练习一
现有一份关于UFO的数据集,请解决下列问题:
pd.read_csv('data/UFO.csv').head()
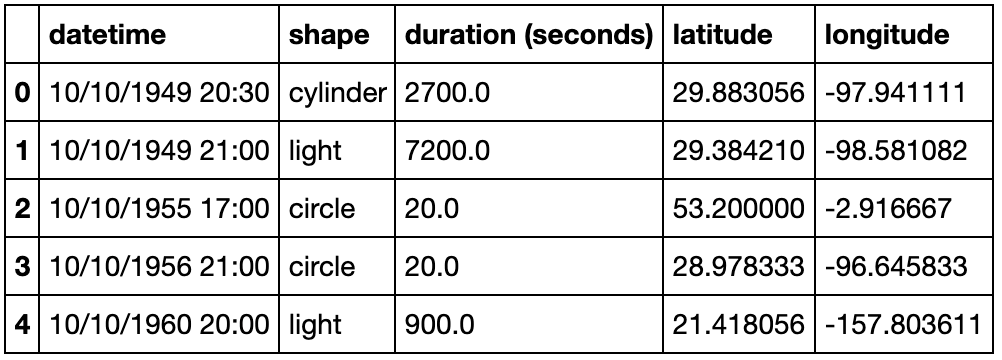
- 在所有被观测时间超过60s的时间中,哪个形状最多?
df = pd.read_csv('data/UFO.csv')
df.rename(columns={'duration (seconds)':'duration'},inplace=True)
df['duration'].astype('float')
df.head()
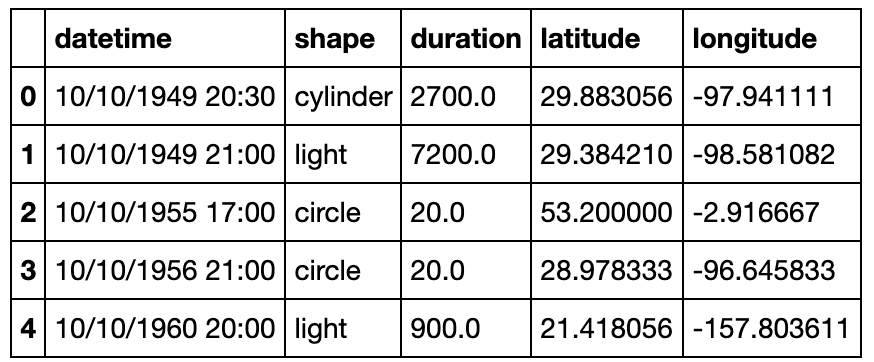
df.query('duration > 60')['shape'].value_counts().index[0]
'light'
- 对经纬度进行划分:-180°至180°以30°为一个划分,-90°至90°以18°为一个划分,请问哪个区域中报告的UFO事件数量最多?
bins_long = np.linspace(-180,180,13).tolist()
bins_la = np.linspace(-90,90,11).tolist()
cuts_long = pd.cut(df['longitude'],bins=bins_long)
df['cuts_long'] = cuts_long
cuts_la = pd.cut(df['latitude'],bins=bins_la)
df['cuts_la'] = cuts_la
df.head()
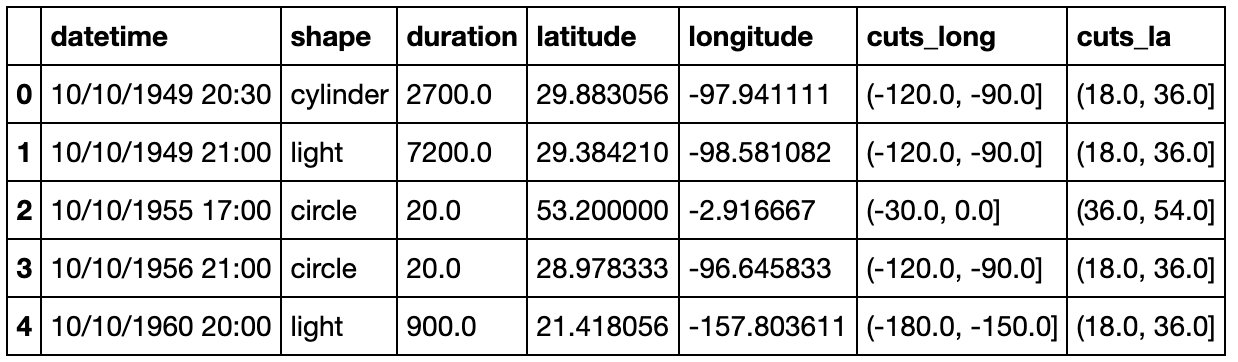
df.set_index(['cuts_long','cuts_la']).index.value_counts().head()
((-90.0, -60.0], (36.0, 54.0]) 27891
((-120.0, -90.0], (18.0, 36.0]) 14280
((-120.0, -90.0], (36.0, 54.0]) 11960
((-90.0, -60.0], (18.0, 36.0]) 9923
((-150.0, -120.0], (36.0, 54.0]) 9658
dtype: int64
练习二
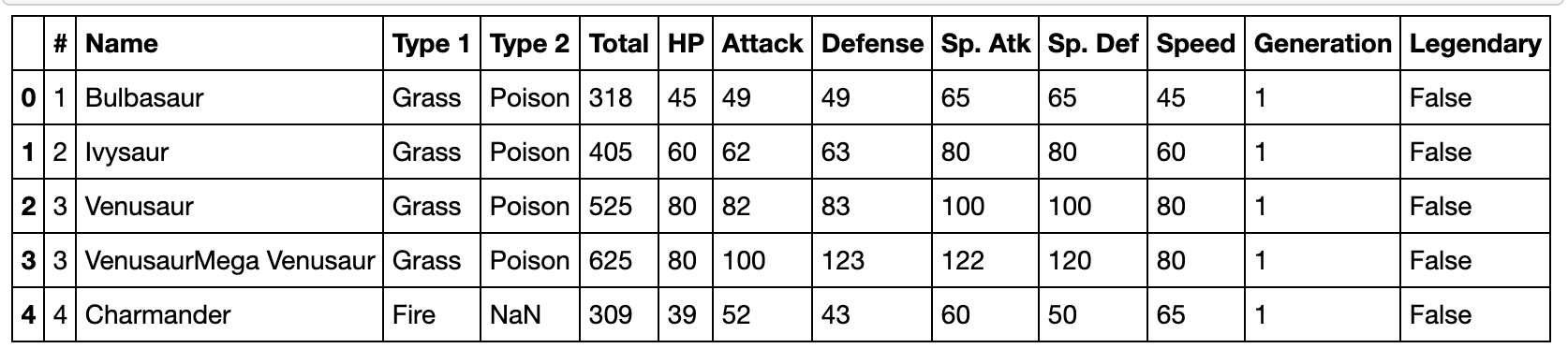
现有一份关于口袋妖怪的数据集,请解决下列问题:
pd.read_csv('data/Pokemon.csv').head()
- 双属性的Pokemon占总体比例的多少?
df = pd.read_csv('data/Pokemon.csv')
df.head()
df['Type 2'].count()/df.shape[0]
0.5175
- 在所有种族值(Total)不小于580的Pokemon中,非神兽(
Legendary=False)的比例为多少?
df.query('Total >= 580')['Legendary'].value_counts(normalize=True)
True 0.575221
False 0.424779
Name: Legendary, dtype: float64
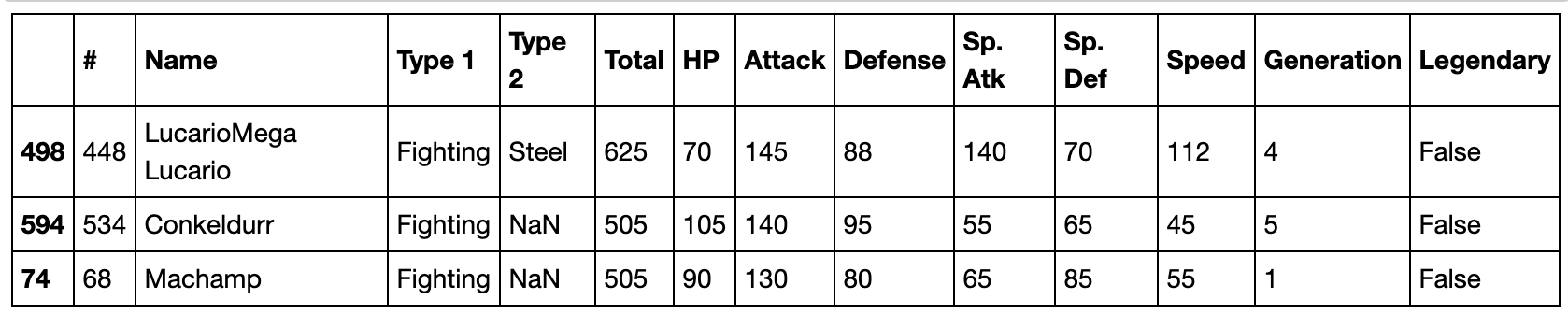
- 在第一属性为格斗系(Fighting)的Pokemon中,物攻排名前三高的是哪些?
df[df['Type 1']=='Fighting'].sort_values(by='Attack',ascending=False).iloc[:3]
- 请问六项种族指标(HP、物攻、特攻、物防、特防、速度)极差的均值最大的是哪个属性(只考虑第一属性,且均值是对属性而言)?
df['range'] = df.iloc[:,5:11].max(axis=1)-df.iloc[:,5:11].min(axis=1)
attribute = df[['Type 1','range']].set_index('Type 1')
max_range = 0
result = ''
for i in attribute.index.unique():
temp = attribute.loc[i,:].mean()
if temp.values[0] > max_range:
max_range = temp.values[0]
result = i
result
'Steel'
- 哪个属性(只考虑第一属性)的神兽比例最高?该属性神兽的种族值也是最高的吗?
df.query('Legendary == True')['Type 1'].value_counts(normalize=True).index[0]
'Psychic'
attribute = df.query('Legendary == True')[['Type 1','Total']].set_index('Type 1')
max_value = 0
result = ''
for i in attribute.index.unique()[:-1]:
temp = attribute.loc[i,:].mean()
if temp[0] > max_value:
max_value = temp[0]
result = i
result
'Normal'
分组
import numpy as np
import pandas as pd
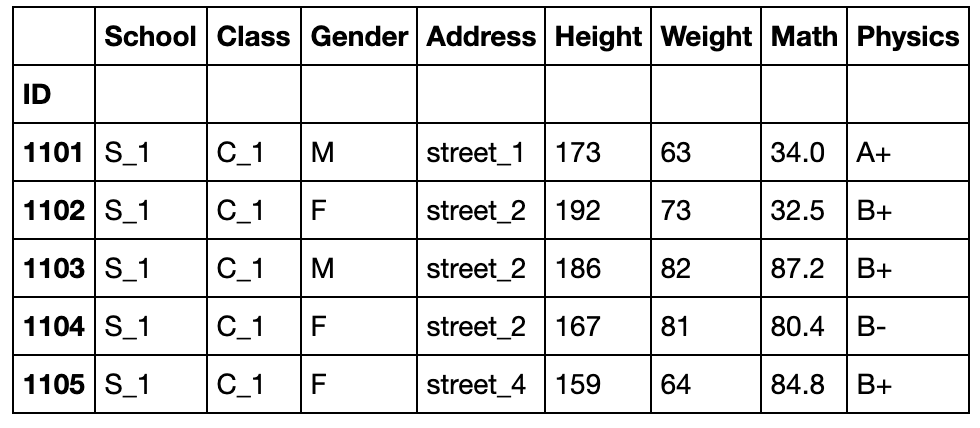
df = pd.read_csv('data/table.csv',index_col='ID')
df.head()
SAC过程
内涵
SAC指的是分组操作中的split-apply-combine过程,其中split指基于某一些规则,将数据拆成若干组,apply是指对每一组独立地使用函数,combine指将每一组的结果组合成某一类数据结构
apply过程
在该过程中,我们实际往往会遇到三类问题:
- 整合(
Aggregation)——即分组计算统计量(如求均值、求每组元素个数) - 变换(
Transformation)——即分组对每个单元的数据进行操作(如元素标准化) - 过滤(
Filtration)——即按照某些规则筛选出一些组(如选出组内某一指标小于50的组)
groupby函数
分组函数的基本内容
根据某一列分组
grouped_single = df.groupby('School')
经过groupby后会生成一个groupby对象,该对象本身不会返回任何东西,只有当相应的方法被调用才会起作用
例如取出某一个组:
grouped_single.get_group('S_1').head()
根据某几列分组
grouped_mul = df.groupby(['School','Class'])
grouped_mul.get_group(('S_2','C_4'))
组容量与组数
grouped_single.size()
School
S_1 15
S_2 20
dtype: int64
grouped_mul.size()
School Class
S_1 C_1 5
C_2 5
C_3 5
S_2 C_1 5
C_2 5
C_3 5
C_4 5
dtype: int64
grouped_single.ngroups
2
grouped_mul.ngroups
7
组的遍历
for name,group in grouped_single:
print(name)
display(group.head())
level参数(用于多级索引)和axis参数
df.set_index(['Gender','School']).groupby(level=1,axis=0).get_group('S_1').head()
groupby对象的特点
查看所有可调用的方法
由此可见,groupby对象可以使用相当多的函数,灵活程度很高
print([attr for attr in dir(grouped_single) if not attr.startswith('_')])
['Address', 'Class', 'Gender', 'Height', 'Math', 'Physics', 'School', 'Weight', 'agg', 'aggregate', 'all', 'any', 'apply', 'backfill', 'bfill', 'boxplot', 'corr', 'corrwith', 'count', 'cov', 'cumcount', 'cummax', 'cummin', 'cumprod', 'cumsum', 'describe', 'diff', 'dtypes', 'expanding', 'ffill', 'fillna', 'filter', 'first', 'get_group', 'groups', 'head', 'hist', 'idxmax', 'idxmin', 'indices', 'last', 'mad', 'max', 'mean', 'median', 'min', 'ndim', 'ngroup', 'ngroups', 'nth', 'nunique', 'ohlc', 'pad', 'pct_change', 'pipe', 'plot', 'prod', 'quantile', 'rank', 'resample', 'rolling', 'sem', 'shift', 'size', 'skew', 'std', 'sum', 'tail', 'take', 'transform', 'tshift', 'var']
分组对象的head和first
对分组对象使用head函数,返回的是每个组的前几行,而不是数据集前几行
grouped_single.head(2)
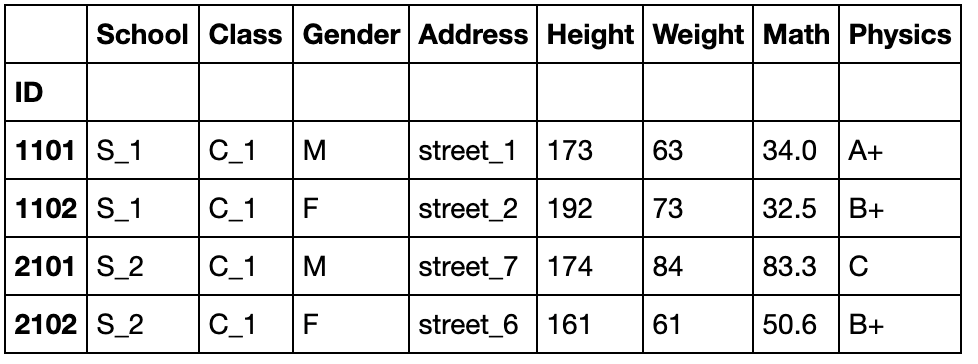
first显示的是以分组为索引的每组的第一个分组信息
grouped_single.first()
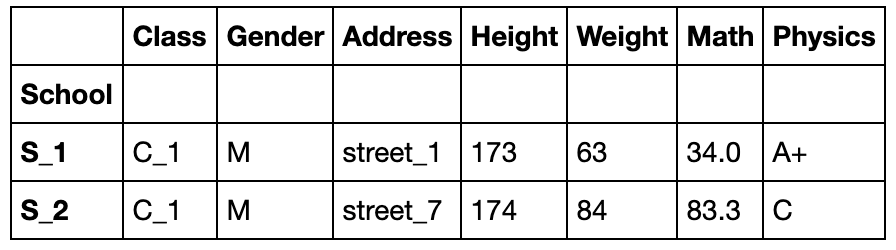
分组依据
对于groupby函数而言,分组的依据是非常自由的,只要是与数据框长度相同的列表即可,同时支持函数型分组
df.groupby(np.random.choice(['a','b','c'],df.shape[0])).get_group('a').head()
#相当于将np.random.choice(['a','b','c'],df.shape[0])当做新的一列进行分组
根据奇偶行分组
df.groupby(lambda x:'奇数行' if not df.index.get_loc(x)%2==1 else '偶数行').groups
{'偶数行': Int64Index([1102, 1104, 1201, 1203, 1205, 1302, 1304, 2101, 2103, 2105, 2202,
2204, 2301, 2303, 2305, 2402, 2404],
dtype='int64', name='ID'),
'奇数行': Int64Index([1101, 1103, 1105, 1202, 1204, 1301, 1303, 1305, 2102, 2104, 2201,
2203, 2205, 2302, 2304, 2401, 2403, 2405],
dtype='int64', name='ID')}
如果是多层索引,那么lambda表达式中的输入就是元组,下面实现的功能为查看两所学校中男女生分别均分是否及格
注意:此处只是演示groupby的用法,实际操作不会这样写
math_score = df.set_index(['Gender','School'])['Math'].sort_index()
grouped_score = df.set_index(['Gender','School']).sort_index().\
groupby(lambda x:(x,'均分及格' if math_score[x].mean()>=60 else '均分不及格'))
for name,_ in grouped_score:print(name)
(('F', 'S_1'), '均分及格')
(('F', 'S_2'), '均分及格')
(('M', 'S_1'), '均分及格')
(('M', 'S_2'), '均分不及格')
groupby的[]操作
可以用[]选出groupby对象的某个或者某几个列,上面的均分比较可以如下简洁地写出:
df.groupby(['Gender','School'])['Math'].mean()>=60
Gender School
F S_1 True
S_2 True
M S_1 True
S_2 False
Name: Math, dtype: bool
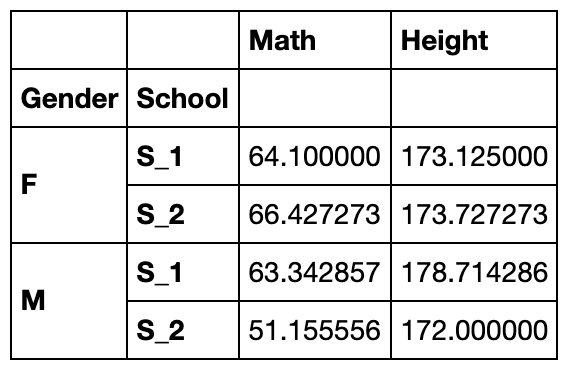
用列表可选出多个属性列:
df.groupby(['Gender','School'])[['Math','Height']].mean()
连续型变量分组
例如利用cut函数对数学成绩分组:
bins = [0,40,60,80,90,100]
cuts = pd.cut(df['Math'],bins=bins) #可选label添加自定义标签
df.groupby(cuts)['Math'].count()
Math
(0, 40] 7
(40, 60] 10
(60, 80] 9
(80, 90] 7
(90, 100] 2
Name: Math, dtype: int64
聚合、过滤和变换
聚合(Aggregation)
常用聚合函数
所谓聚合就是把一堆数,变成一个标量,因此mean/sum/size/count/std/var/sem/describe/first/last/nth/min/max都是聚合函数
同时使用多个聚合函数
group_m = grouped_single['Math']
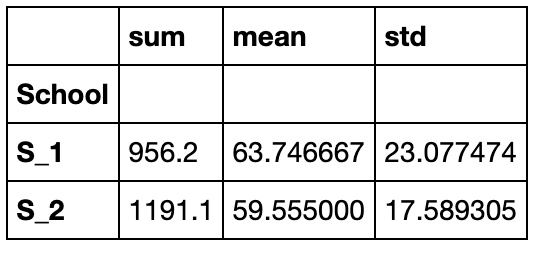
利用元组进行重命名
group_m.agg([('rename_sum','sum'),('rename_mean','mean')])

指定哪些函数作用哪些列
grouped_mul.agg({'Math':['mean','max'],'Height':'var'})
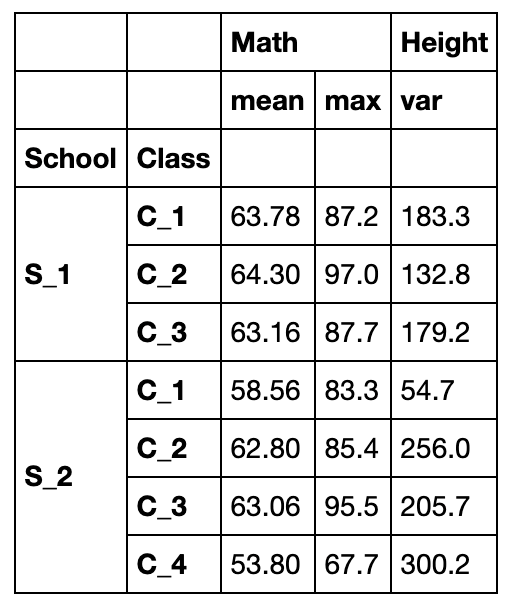
使用自定义函数
grouped_single['Math'].agg(lambda x:print(x.head(),'间隔'))
#可以发现,agg函数的传入是分组逐列进行的,有了这个特性就可以做许多事情
Series([], Name: Math, dtype: float64) 间隔
1101 34.0
1102 32.5
1103 87.2
1104 80.4
1105 84.8
Name: Math, dtype: float64 间隔
2101 83.3
2102 50.6
2103 52.5
2104 72.2
2105 34.2
Name: Math, dtype: float64 间隔
官方没有提供极差计算的函数,但通过agg可以容易地实现组内极差计算
grouped_single['Math'].agg(lambda x:x.max()-x.min())
School
S_1 65.5
S_2 62.8
Name: Math, dtype: float64
利用NamedAgg函数进行多个聚合
不支持lambda函数,但是可以使用外置的def函数
def R1(x):
return x.max()-x.min()
def R2(x):
return x.max()-x.median()
grouped_single['Math'].agg(min_score1=pd.NamedAgg(column='col1', aggfunc=R1),
max_score1=pd.NamedAgg(column='col2', aggfunc='max'),
range_score2=pd.NamedAgg(column='col3', aggfunc=R2)).head()
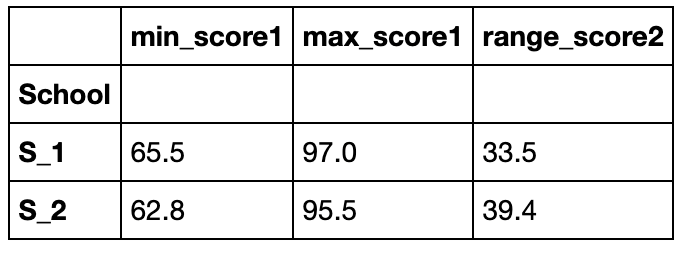
带参数的聚合函数
判断是否组内数学分数至少有一个值在50-52之间:
def f(s,low,high):
return s.between(low,high).max()
grouped_single['Math'].agg(f,50,52)
School
S_1 False
S_2 True
Name: Math, dtype: bool
如果需要使用多个函数,并且其中至少有一个带参数,则使用wrap技巧:
def f_test(s,low,high):
return s.between(low,high).max()
def agg_f(f_mul,name,*args,**kwargs):
def wrapper(x):
return f_mul(x,*args,**kwargs)
wrapper.__name__ = name
return wrapper
new_f = agg_f(f_test,'at_least_one_in_50_52',50,52)
grouped_single['Math'].agg([new_f,'mean']).head()

过滤(Filteration)
filter函数是用来筛选某些组的(务必记住结果是组的全体),因此传入的值应当是布尔标量
grouped_single[['Math','Physics']].filter(lambda x:(x['Math']>32).all()).head()
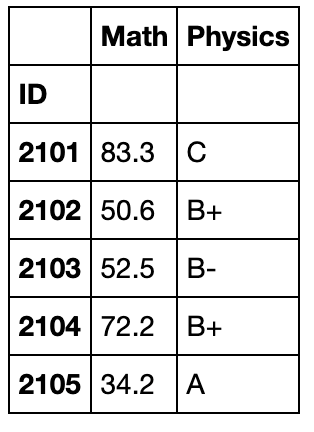
变换(Transformation)
传入对象
transform函数中传入的对象是组内的列,并且返回值需要与列长完全一致
grouped_single[['Math','Height']].transform(lambda x:x-x.min()).head()
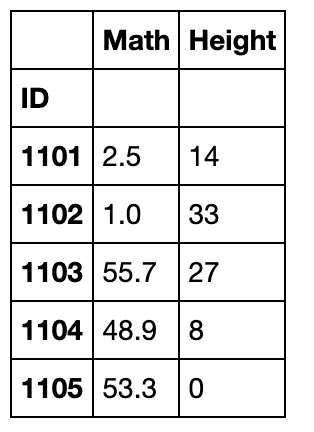
如果返回了标量值,那么组内的所有元素会被广播为这个值
grouped_single[['Math','Height']].transform(lambda x:x.mean()).head()
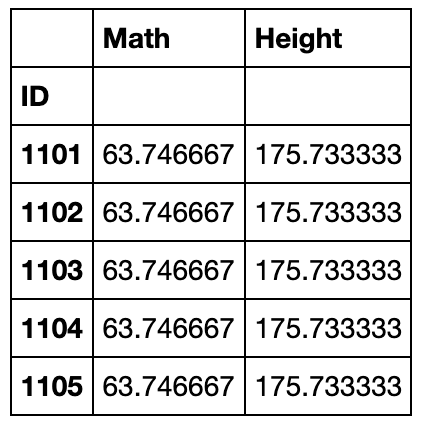
利用变换方法进行组内标准化
grouped_single[['Math','Height']].transform(lambda x:(x-x.mean())/x.std()).head()
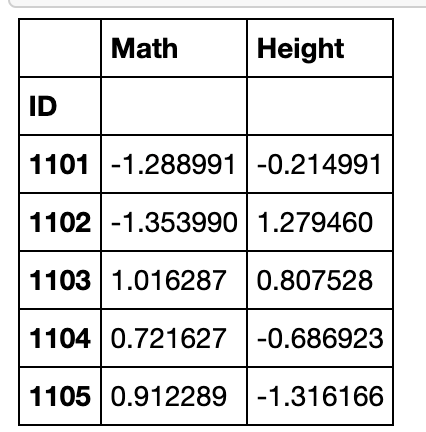
利用变换方法进行组内缺失值的均值填充
df_nan = df[['Math','School']].copy().reset_index()
df_nan.loc[np.random.randint(0,df.shape[0],25),['Math']]=np.nan
df_nan.head()
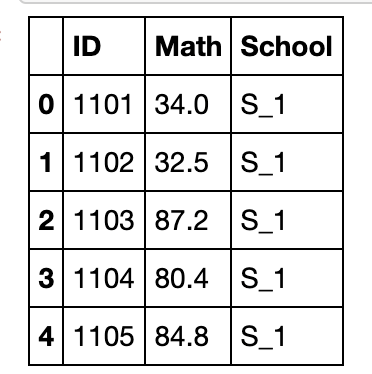
df_nan.groupby('School').transform(lambda x: x.fillna(x.mean())).join(df.reset_index()['School']).head()
apply函数
apply函数的灵活性
可能在所有的分组函数中,apply是应用最为广泛的,这得益于它的灵活性:
对于传入值而言,从下面的打印内容可以看到是以分组的表传入apply中:
df.groupby('School').apply(lambda x:print(x.head(1)))
School Class Gender Address Height Weight Math Physics
ID
1101 S_1 C_1 M street_1 173 63 34.0 A+
School Class Gender Address Height Weight Math Physics
ID
2101 S_2 C_1 M street_7 174 84 83.3 C
apply函数的灵活性很大程度来源于其返回值的多样性:
标量返回值
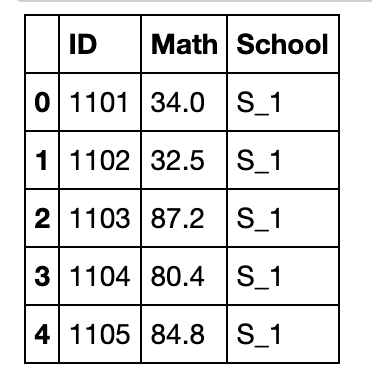
df[['School','Math','Height']].groupby('School').apply(lambda x:x.max())
列表返回值
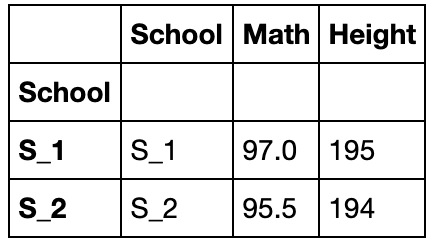
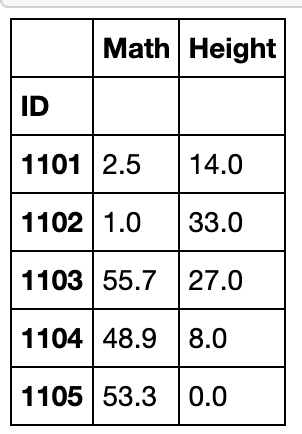
df[['School','Math','Height']].groupby('School').apply(lambda x:x-x.min()).head()
数据框返回值
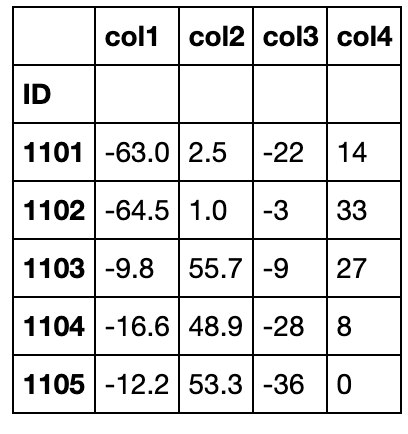
df[['School','Math','Height']].groupby('School')\
.apply(lambda x:pd.DataFrame({'col1':x['Math']-x['Math'].max(),
'col2':x['Math']-x['Math'].min(),
'col3':x['Height']-x['Height'].max(),
'col4':x['Height']-x['Height'].min()})).head()
用apply同时统计多个指标
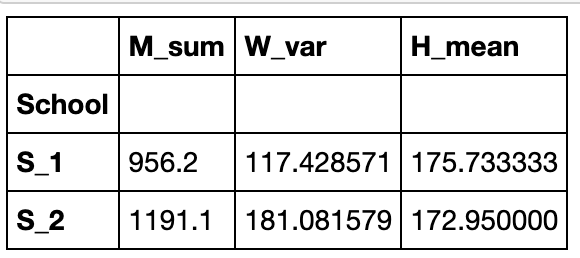
此处可以借助OrderedDict工具进行快捷的统计:
from collections import OrderedDict
def f(df):
data = OrderedDict()
data['M_sum'] = df['Math'].sum()
data['W_var'] = df['Weight'].var()
data['H_mean'] = df['Height'].mean()
return pd.Series(data)
grouped_single.apply(f)
练习
练习一
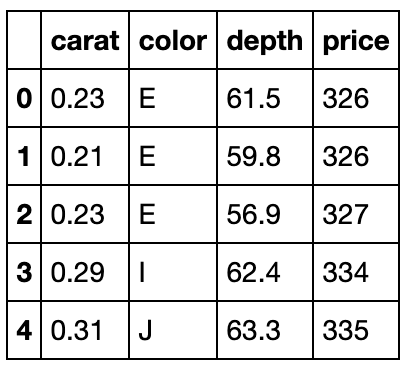
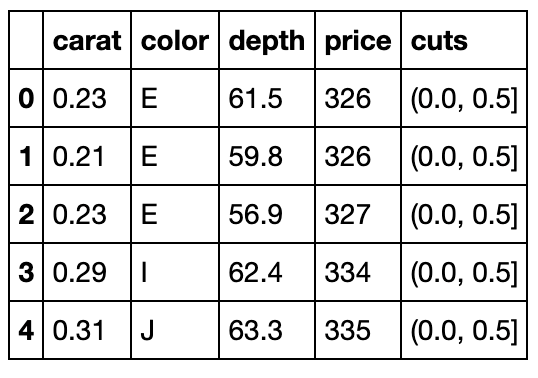
现有一份关于diamonds的数据集,列分别记录了克拉数、颜色、开采深度、价格,请解决下列问题:
pd.read_csv('data/Diamonds.csv').head()
- 在所有重量超过1克拉的钻石中,价格的极差是多少?
df_r = df.query('carat>1')['price']
df_r.max()-df_r.min()
17561
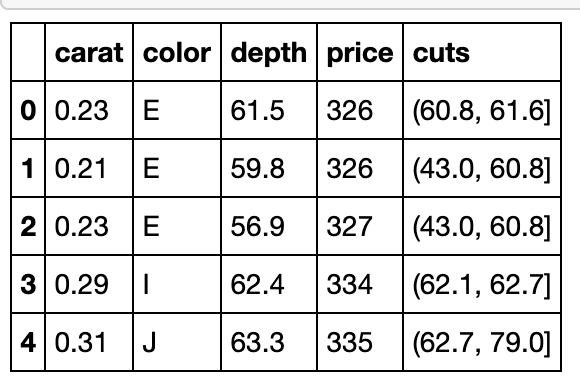
- 若以开采深度的0.2\0.4\0.6\0.8分位数为分组依据,每一组中钻石颜色最多的是哪一种?该种颜色是组内平均而言单位重量最贵的吗?
bins = df['depth'].quantile(np.linspace(0,1,6)).tolist()
cuts = pd.cut(df['depth'],bins=bins) #可选label添加自定义标签
df['cuts'] = cuts
df.head()
color_result = df.groupby('cuts')['color'].describe()
color_result
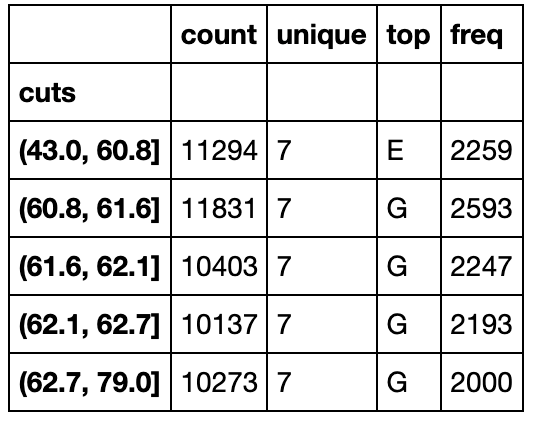
前三个分位数区间不满足条件,后两个区间中数量最多的颜色的确是均重价格中最贵的
df['均重价格']=df['price']/df['carat']
color_result['top'] == [i[1] for i in df.groupby(['cuts','color'])['均重价格'].mean().groupby(['cuts']).idxmax().values]
cuts
(43.0, 60.8] False
(60.8, 61.6] False
(61.6, 62.1] False
(62.1, 62.7] True
(62.7, 79.0] True
Name: top, dtype: bool
- 以重量分组(0-0.5,0.5-1,1-1.5,1.5-2,2+),按递增的深度为索引排序,求每组中连续的严格递增价格序列长度的最大值。
df = df.drop(columns='均重价格')
cuts = pd.cut(df['carat'],bins=[0,0.5,1,1.5,2,np.inf]) #可选label添加自定义标签
df['cuts'] = cuts
df.head()
def f(nums):
if not nums:
return 0
res = 1
cur_len = 1
for i in range(1, len(nums)):
if nums[i-1] < nums[i]:
cur_len += 1
res = max(cur_len, res)
else:
cur_len = 1
return res
for name,group in df.groupby('cuts'):
group = group.sort_values(by='depth')
s = group['price']
print(name,f(s.tolist()))
(0.0, 0.5] 8
(0.5, 1.0] 8
(1.0, 1.5] 7
(1.5, 2.0] 11
(2.0, inf] 7
- 请按颜色分组,分别计算价格关于克拉数的回归系数。(单变量的简单线性回归,并只使用
Pandas和Numpy完成)
for name,group in df[['carat','price','color']].groupby('color'):
L1 = np.array([np.ones(group.shape[0]),group['carat']]).reshape(2,group.shape[0])
L2 = group['price']
result = (np.linalg.inv(L1.dot(L1.T)).dot(L1)).dot(L2).reshape(2,1)
print('当颜色为%s时,截距项为:%f,回归系数为:%f'%(name,result[0],result[1]))
当颜色为D时,截距项为:-2361.017152,回归系数为:8408.353126
当颜色为E时,截距项为:-2381.049600,回归系数为:8296.212783
当颜色为F时,截距项为:-2665.806191,回归系数为:8676.658344
当颜色为G时,截距项为:-2575.527643,回归系数为:8525.345779
当颜色为H时,截距项为:-2460.418046,回归系数为:7619.098320
当颜色为I时,截距项为:-2878.150356,回归系数为:7761.041169
当颜色为J时,截距项为:-2920.603337,回归系数为:7094.192092
练习二
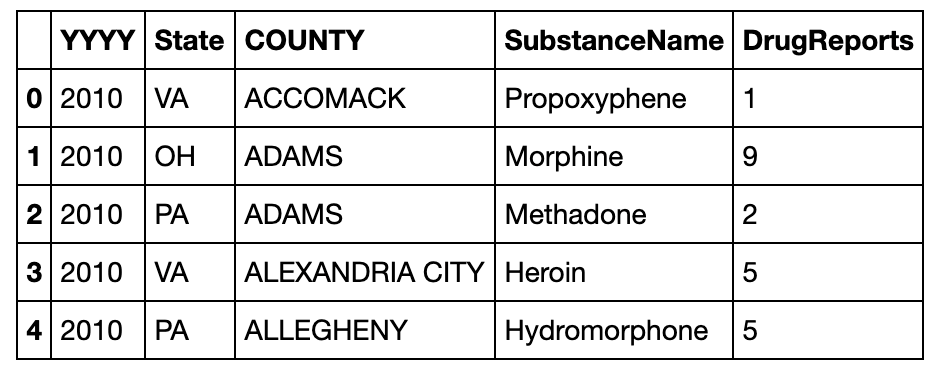
有一份关于美国10年至17年的非法药物数据集,列分别记录了年份、州(5个)、县、药物类型、报告数量,请解决下列问题:
pd.read_csv('data/Drugs.csv').head()
- 按照年份统计,哪个县的报告数量最多?这个县所属的州在当年也是报告数最多的吗?
idx=pd.IndexSlice
for i in range(2010,2018):
county = (df.groupby(['COUNTY','YYYY']).sum().loc[idx[:,i],:].idxmax()[0][0])
state = df.query('COUNTY == "%s"'%county)['State'].iloc[0]
state_true = df.groupby(['State','YYYY']).sum().loc[idx[:,i],:].idxmax()[0][0]
if state==state_true:
print('在%d年,%s县的报告数最多,它所属的州%s也是报告数最多的'%(i,county,state))
else:
print('在%d年,%s县的报告数最多,但它所属的州%s不是报告数最多的,%s州报告数最多'%(i,county,state,state_true))
在2010年,PHILADELPHIA县的报告数最多,它所属的州PA也是报告数最多的
在2011年,PHILADELPHIA县的报告数最多,但它所属的州PA不是报告数最多的,OH州报告数最多
在2012年,PHILADELPHIA县的报告数最多,但它所属的州PA不是报告数最多的,OH州报告数最多
在2013年,PHILADELPHIA县的报告数最多,但它所属的州PA不是报告数最多的,OH州报告数最多
在2014年,PHILADELPHIA县的报告数最多,但它所属的州PA不是报告数最多的,OH州报告数最多
在2015年,PHILADELPHIA县的报告数最多,但它所属的州PA不是报告数最多的,OH州报告数最多
在2016年,HAMILTON县的报告数最多,它所属的州OH也是报告数最多的
在2017年,HAMILTON县的报告数最多,它所属的州OH也是报告数最多的
- 从14年到15年,Heroin的数量增加最多的是哪一个州?它在这个州是所有药物中增幅最大的吗?若不是,请找出符合该条件的药物。
df_b = df[(df['YYYY'].isin([2014,2015]))&(df['SubstanceName']=='Heroin')]
df_add = df_b.groupby(['YYYY','State']).sum()
(df_add.loc[2015]-df_add.loc[2014]).idxmax()
DrugReports OH
dtype: object
df_b = df[(df['YYYY'].isin([2014,2015]))&(df['State']=='OH')]
df_add = df_b.groupby(['YYYY','SubstanceName']).sum()
display((df_add.loc[2015]-df_add.loc[2014]).idxmax()) #这里利用了索引对齐的特点
display((df_add.loc[2015]/df_add.loc[2014]).idxmax())
DrugReports Heroin
dtype: object
DrugReports Acetyl fentanyl
dtype: object
变形
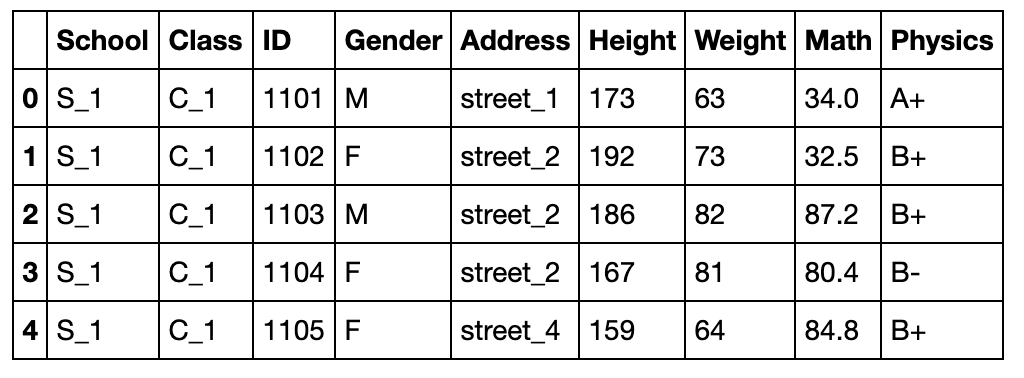
import numpy as np
import pandas as pd
df = pd.read_csv('data/table.csv')
df.head()
透视表
pivot
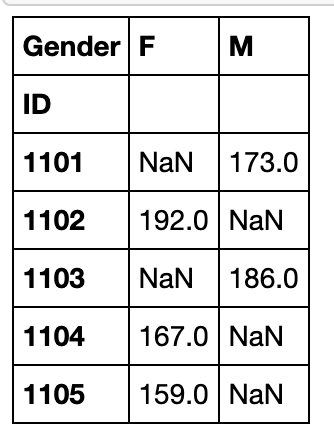
一般状态下,数据在DataFrame会以压缩(stacked)状态存放,例如上面的Gender,两个类别被叠在一列中,pivot函数可将某一列作为新的cols:
df.pivot(index='ID',columns='Gender',values='Height').head()
然而pivot函数具有很强的局限性,除了功能上较少之外,还不允许values中出现重复的行列索引对(pair),例如下面的语句就会报错:
#df.pivot(index='School',columns='Gender',values='Height').head()
因此,更多的时候会选择使用强大的pivot_table函数
pivot_table
pd.pivot_table(df,index='ID',columns='Gender',values='Height').head()
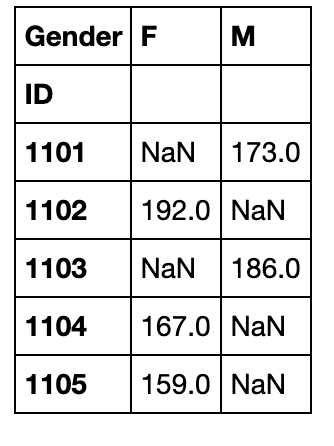
由于功能更多,速度上自然是比不上原来的pivot函数
Pandas中提供了各种选项,下面介绍常用参数:
aggfunc:对组内进行聚合统计,可传入各类函数,默认为'mean'
pd.pivot_table(df,index='School',columns='Gender',values='Height',aggfunc=['mean','sum']).head()
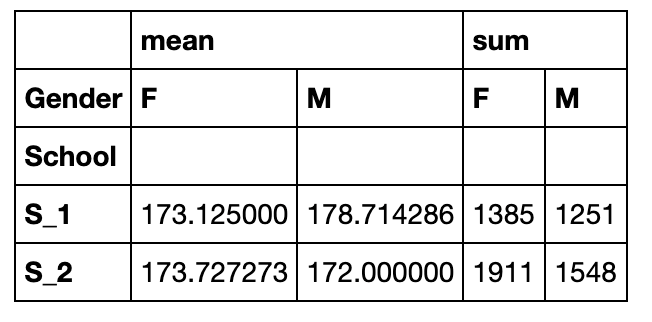
margins:汇总边际状态
pd.pivot_table(df,index='School',columns='Gender',values='Height',aggfunc=['mean','sum'],margins=True).head()
#margins_name可以设置名字,默认为'All'
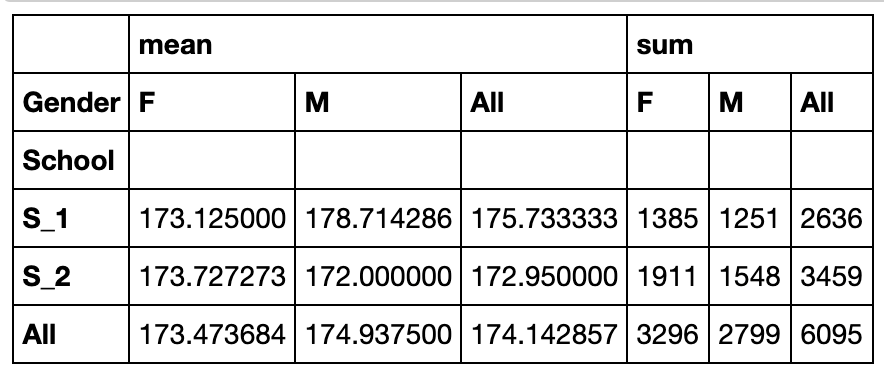
行、列、值都可以为多级
pd.pivot_table(df,index=['School','Class'],
columns=['Gender','Address'],
values=['Height','Weight'])
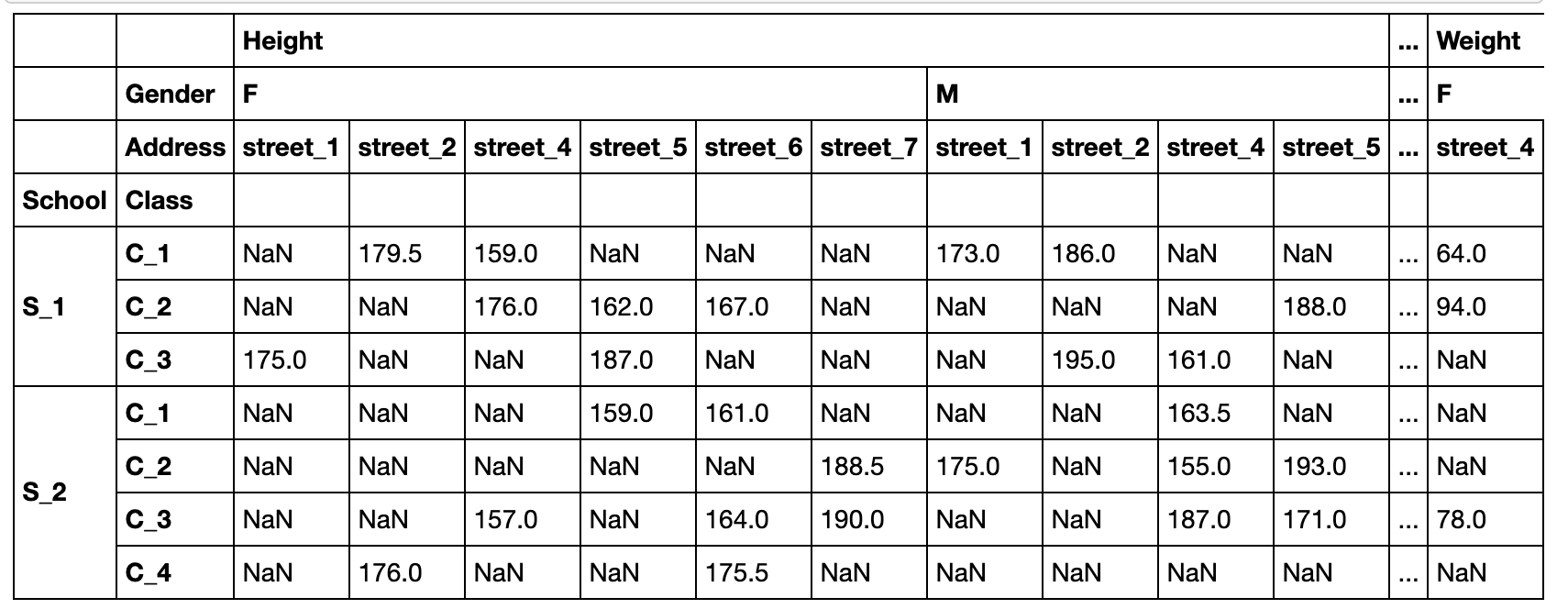
crosstab(交叉表)
交叉表是一种特殊的透视表,典型的用途如分组统计,如现在想要统计关于街道和性别分组的频数:
pd.crosstab(index=df['Address'],columns=df['Gender'])
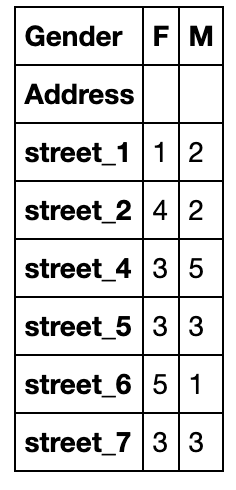
交叉表的功能也很强大(但目前还不支持多级分组),下面说明一些重要参数:
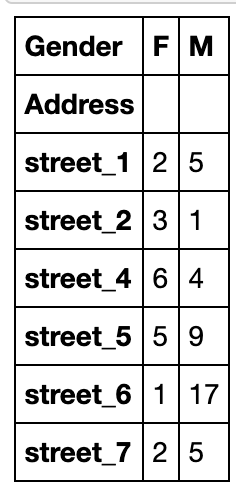
values和aggfunc:分组对某些数据进行聚合操作,这两个参数必须成对出现
pd.crosstab(index=df['Address'],columns=df['Gender'],
values=np.random.randint(1,20,df.shape[0]),aggfunc='min')
#默认参数等于如下方法:
#pd.crosstab(index=df['Address'],columns=df['Gender'],values=1,aggfunc='count')
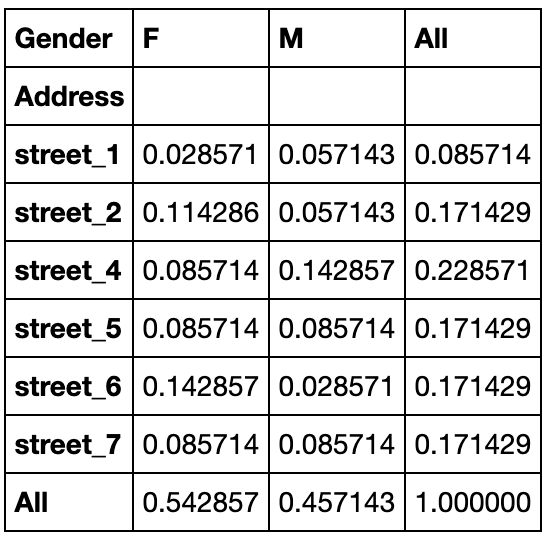
除了边际参数margins外,还引入了normalize参数,可选'all','index','columns'参数值
pd.crosstab(index=df['Address'],columns=df['Gender'],normalize='all',margins=True)
其他变形方法
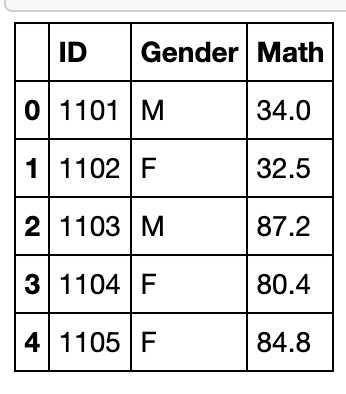
melt
melt函数可以认为是pivot函数的逆操作,将unstacked状态的数据,压缩成stacked,使“宽”的DataFrame变“窄”
df_m = df[['ID','Gender','Math']]
df_m.head()
df.pivot(index='ID',columns='Gender',values='Math').head()
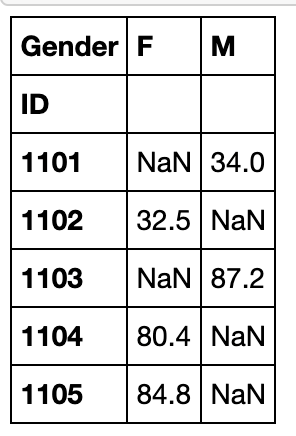
melt函数中的id_vars表示需要保留的列,value_vars表示需要stack的一组列
pivoted = df.pivot(index='ID',columns='Gender',values='Math')
result = pivoted.reset_index().melt(id_vars=['ID'],value_vars=['F','M'],value_name='Math')\
.dropna().set_index('ID').sort_index()
#检验是否与展开前的df相同,可以分别将这些链式方法的中间步骤展开,看看是什么结果
result.equals(df_m.set_index('ID'))
True
压缩与展开
stack
这是最基础的变形函数,总共只有两个参数:level和dropna
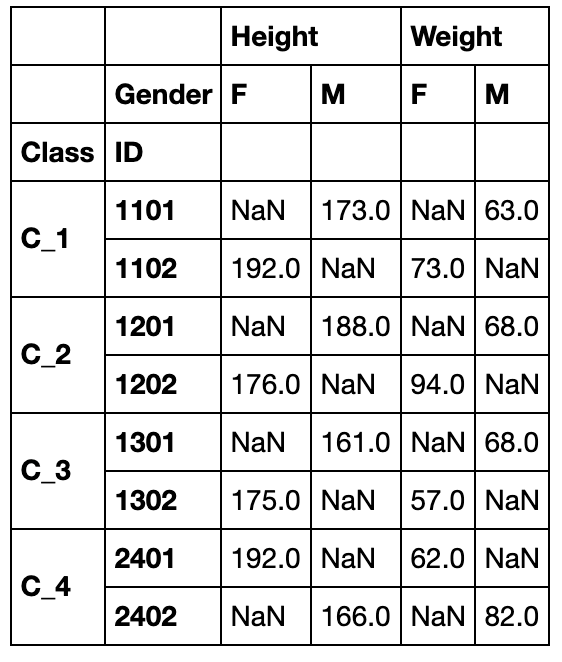
df_s = pd.pivot_table(df,index=['Class','ID'],columns='Gender',values=['Height','Weight'])
df_s.groupby('Class').head(2)
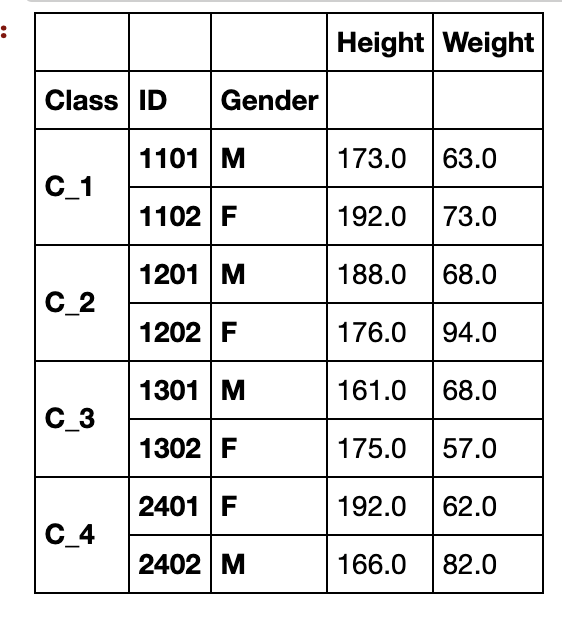
df_stacked = df_s.stack()
df_stacked.groupby('Class').head(2)
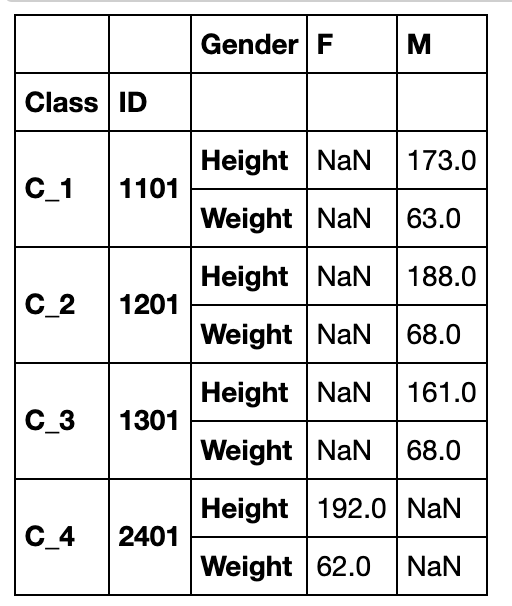
stack函数可以看做将横向的索引放到纵向,因此功能类似与melt,参数level可指定变化的列索引是哪一层(或哪几层,需要列表)
df_stacked = df_s.stack(0)
df_stacked.groupby('Class').head(2)
unstack
stack的逆函数,功能上类似于pivot_table
df_stacked.head()
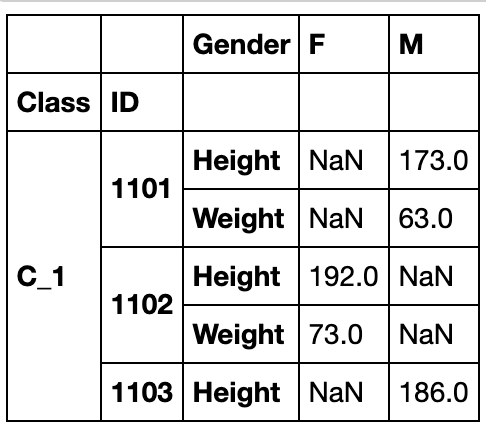
result = df_stacked.unstack().swaplevel(1,0,axis=1).sort_index(axis=1)
result.equals(df_s)
#同样在unstack中可以指定level参数
True
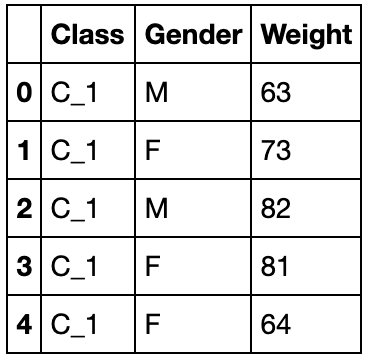
哑变量与因子化
Dummy Variable(哑变量)
这里主要介绍get_dummies函数,其功能主要是进行one-hot编码:
df_d = df[['Class','Gender','Weight']]
df_d.head()
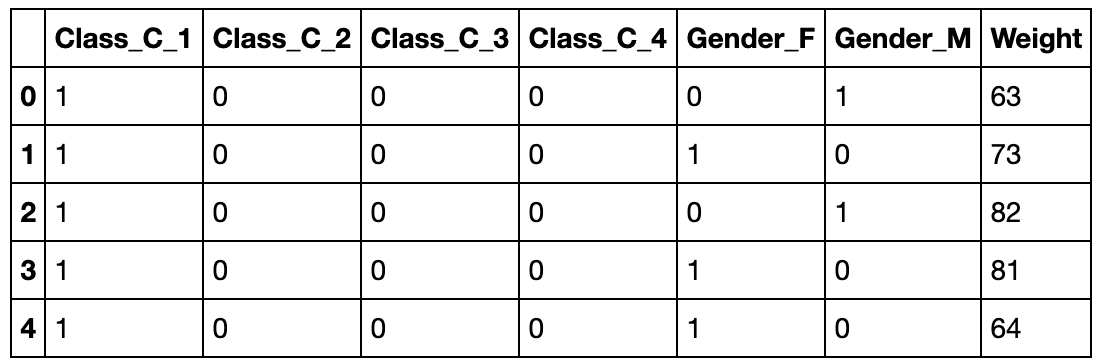
现在希望将上面的表格前两列转化为哑变量,并加入第三列Weight数值:
pd.get_dummies(df_d[['Class','Gender']]).join(df_d['Weight']).head()
#可选prefix参数添加前缀,prefix_sep添加分隔符
factorize方法
该方法主要用于自然数编码,并且缺失值会被记做-1,其中sort参数表示是否排序后赋值
codes, uniques = pd.factorize(['b', None, 'a', 'c', 'b'], sort=True)
display(codes)
display(uniques)
array([ 1, -1, 0, 2, 1])
array(['a', 'b', 'c'], dtype=object)
练习
练习一
继续使用上一章的药物数据集
pd.read_csv('data/Drugs.csv').head()
- 现在请你将数据表转化成如下形态,每行需要显示每种药物在每个地区的10年至17年的变化情况,且前三列需要排序:
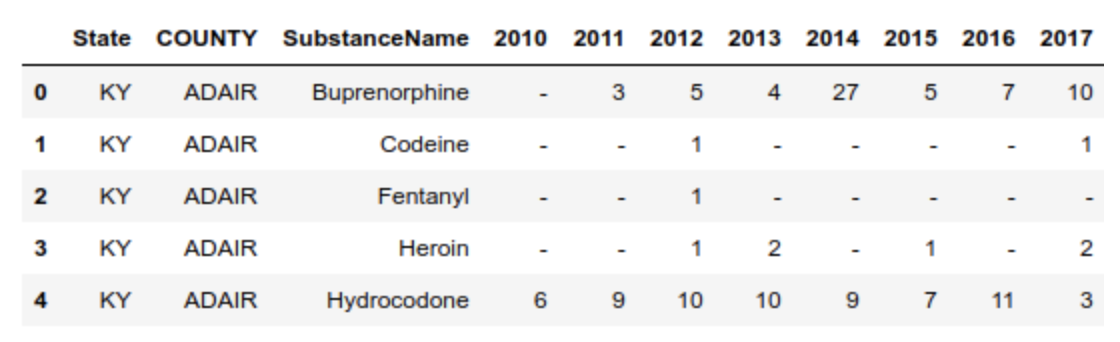
df = pd.read_csv('data/Drugs.csv',index_col=['State','COUNTY']).sort_index()
df.head()
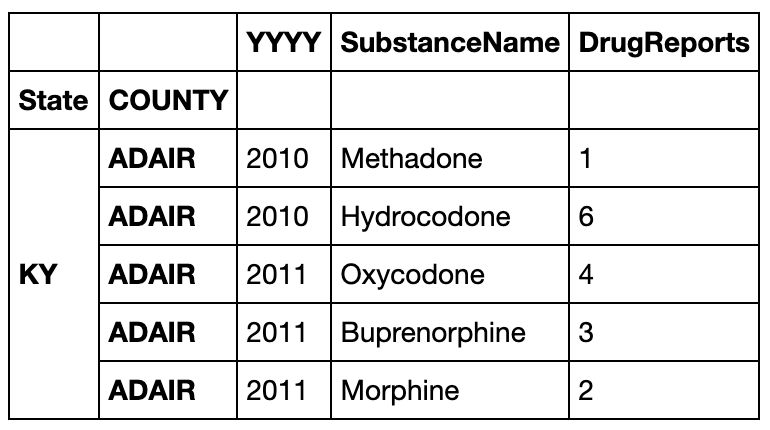
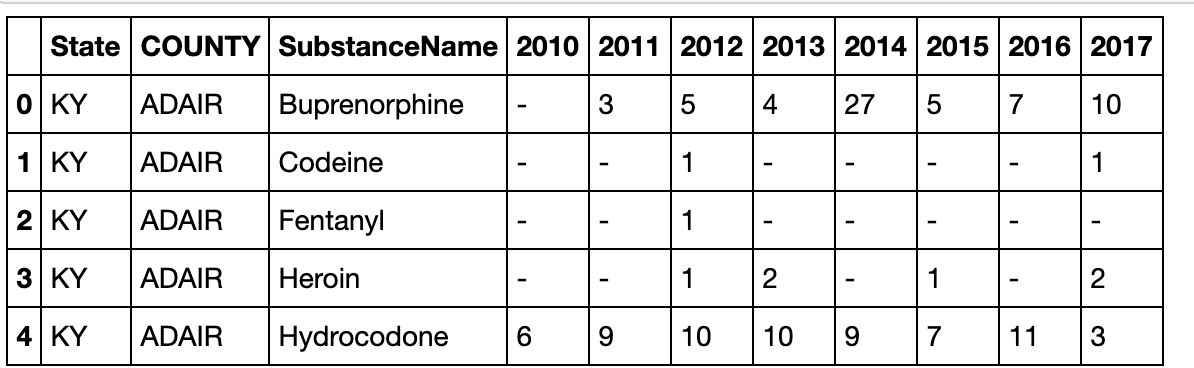
result = pd.pivot_table(df,index=['State','COUNTY','SubstanceName']
,columns='YYYY'
,values='DrugReports',fill_value='-').reset_index().rename_axis(columns={'YYYY':''})
result.head()
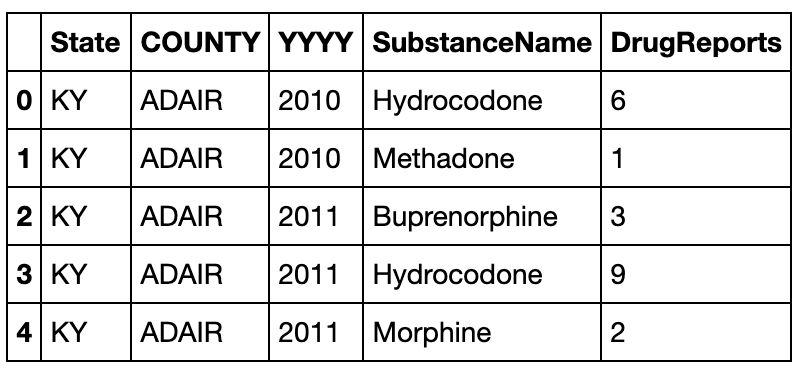
- 现在请将(a)中的结果恢复到原数据表,并通过
equal函数检验初始表与新的结果是否一致(返回True)
result_melted = result.melt(id_vars=result.columns[:3],value_vars=result.columns[-8:]
,var_name='YYYY',value_name='DrugReports').query('DrugReports != "-"')
result2 = result_melted.sort_values(by=['State','COUNTY','YYYY'
,'SubstanceName']).reset_index().drop(columns='index')
#下面其实无关紧要,只是交换两个列再改一下类型(因为‘-’所以type变成object了)
cols = list(result2.columns)
a, b = cols.index('SubstanceName'), cols.index('YYYY')
cols[b], cols[a] = cols[a], cols[b]
result2 = result2[cols].astype({'DrugReports':'int','YYYY':'int'})
result2.head()
df_tidy = df.reset_index().sort_values(by=result2.columns[:4].tolist()).reset_index().drop(columns='index')
df_tidy.head()
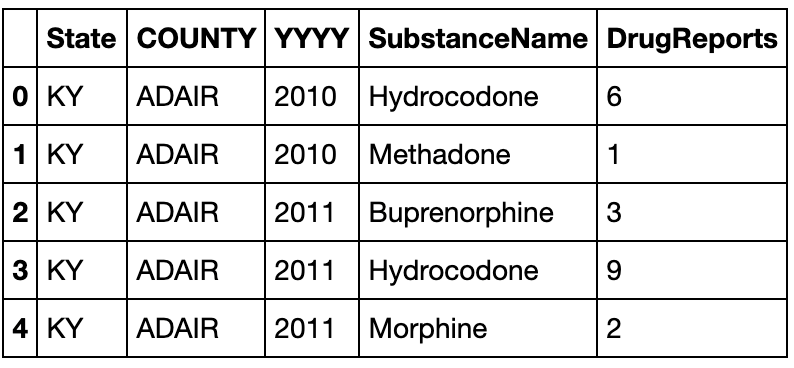
df_tidy.equals(result2)
True
练习二
现有一份关于某地区地震情况的数据集,请解决如下问题
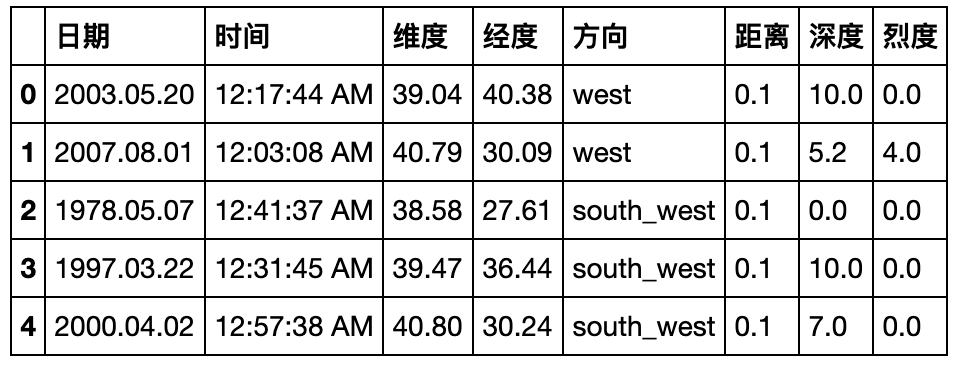
pd.read_csv('data/Earthquake.csv').head()
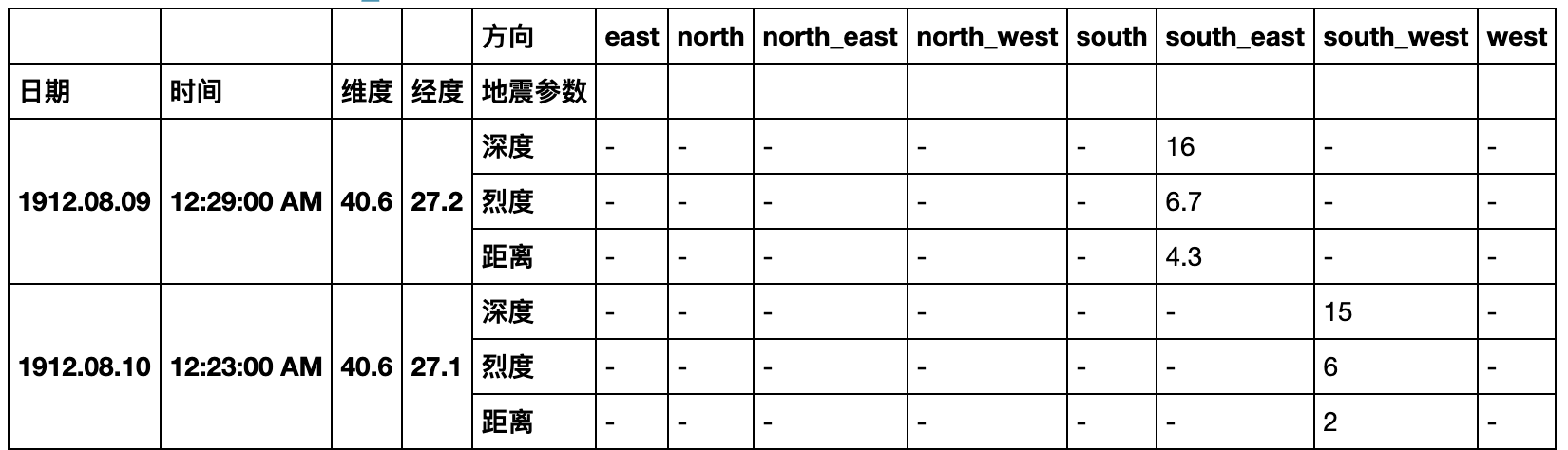
- 现在请你将数据表转化成如下形态,将方向列展开,并将距离、深度和烈度三个属性压缩:
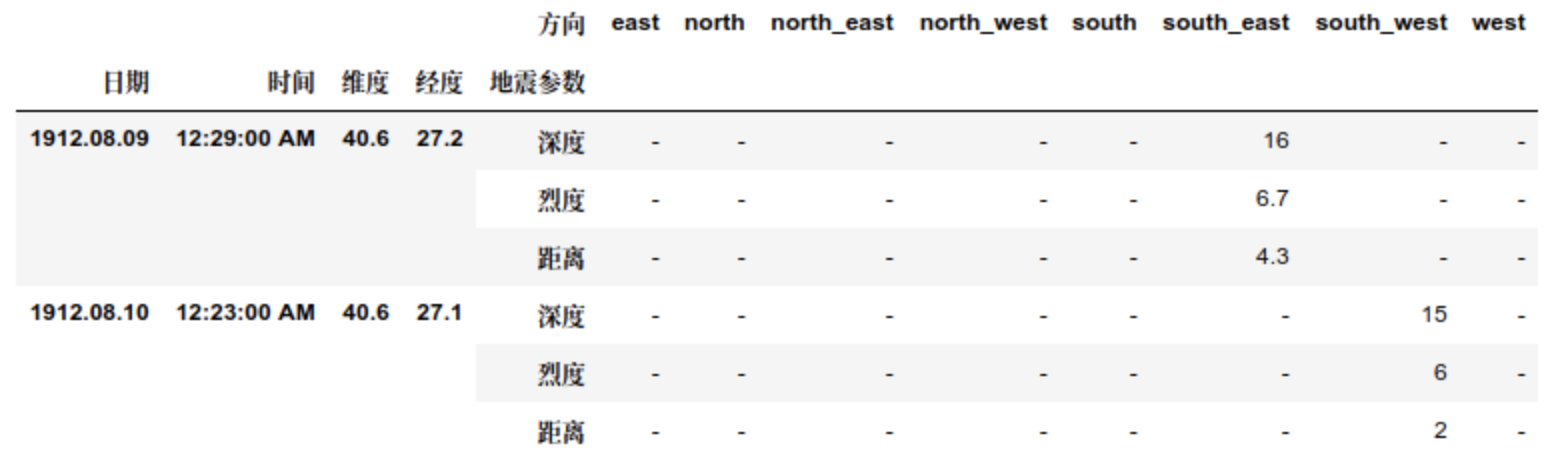
df = pd.read_csv('data/Earthquake.csv')
df = df.sort_values(by=df.columns.tolist()[:3]).sort_index(axis=1).reset_index().drop(columns='index')
df.head()
result = pd.pivot_table(df,index=['日期','时间','维度','经度']
,columns='方向'
,values=['烈度','深度','距离'],fill_value='-').stack(level=0).rename_axis(index={None:'地震参数'})
result.head(6)
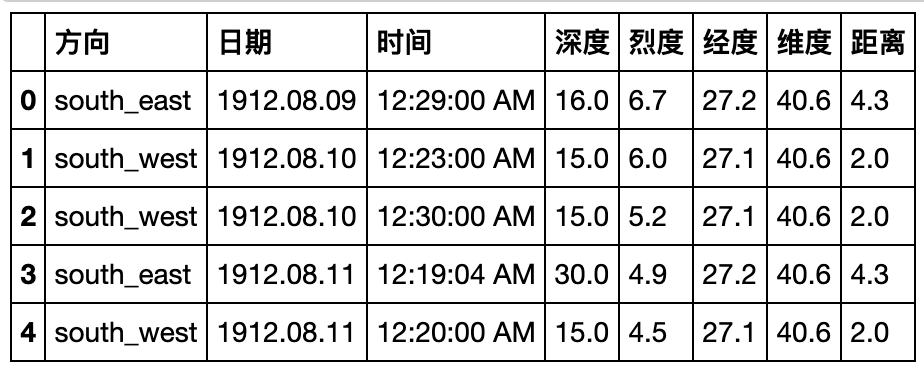
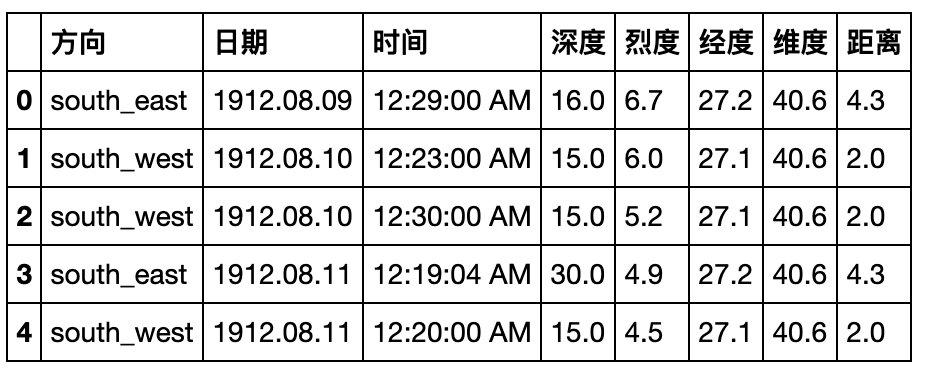
- 现在请将(a)中的结果恢复到原数据表,并通过
equal函数检验初始表与新的结果是否一致(返回True)
df_result = result.unstack().stack(0)[(~(result.unstack().stack(0)=='-')).any(1)].reset_index()
df_result.columns.name=None
df_result = df_result.sort_index(axis=1).astype({'深度':'float64','烈度':'float64','距离':'float64'})
df_result.head()
df_result.astype({'深度':'float64','烈度':'float64','距离':'float64'},copy=False).dtypes
Out[42]:
方向 object
日期 object
时间 object
深度 float64
烈度 float64
经度 float64
维度 float64
距离 float64
dtype: object
df.equals(df_result)
True
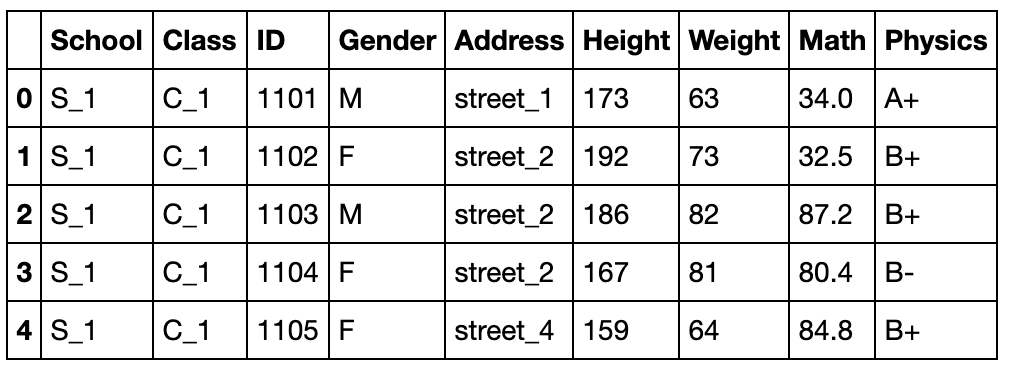
合并
import numpy as np
import pandas as pd
df = pd.read_csv('data/table.csv')
df.head()
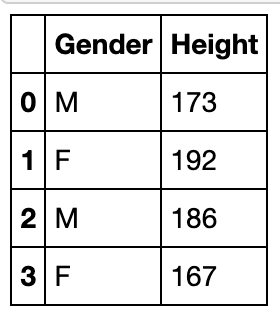
append与assign
append方法
利用序列添加行(必须指定name)
df_append = df.loc[:3,['Gender','Height']].copy()
df_append
s = pd.Series({'Gender':'F','Height':188},name='new_row')
df_append.append(s)
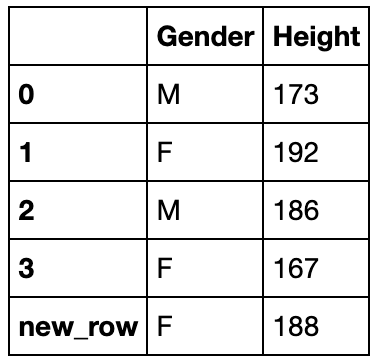
用DataFrame添加表
df_temp = pd.DataFrame({'Gender':['F','M'],'Height':[188,176]},index=['new_1','new_2'])
df_append.append(df_temp)
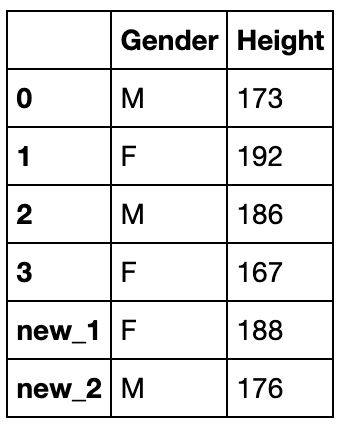
assign方法
该方法主要用于添加列,列名直接由参数指定:
s = pd.Series(list('abcd'),index=range(4))
df_append.assign(Letter=s)
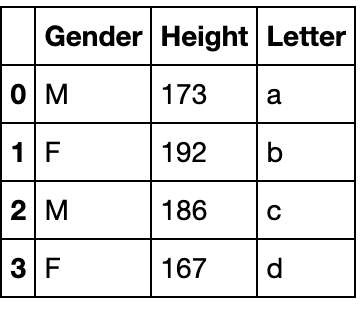
可以一次添加多个列:
df_append.assign(col1=lambda x:x['Gender']*2,
col2=s)
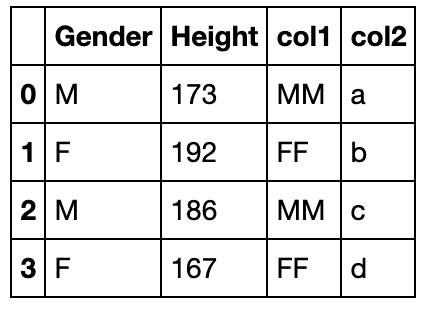
combine与update
comine方法
comine和update都是用于表的填充函数,可以根据某种规则填充
填充对象
可以看出combine方法是按照表的顺序轮流进行逐列循环的,而且自动索引对齐,缺失值为NaN,理解这一点很重要
df_combine_1 = df.loc[:1,['Gender','Height']].copy()
df_combine_2 = df.loc[10:11,['Gender','Height']].copy()
df_combine_1.combine(df_combine_2,lambda x,y:print(x,y))
0 M
1 F
10 NaN
11 NaN
Name: Gender, dtype: object
0 NaN
1 NaN
10 M
11 F
Name: Gender, dtype: object
0 173.0
1 192.0
10 NaN
11 NaN
Name: Height, dtype: float64
0 NaN
1 NaN
10 161.0
11 175.0
Name: Height, dtype: float64
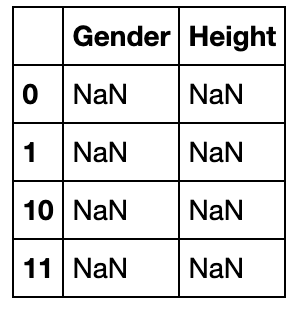
一些例子
根据列均值的大小填充
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [8, 7], 'B': [6, 5]})
df1.combine(df2,lambda x,y:x if x.mean()>y.mean() else y)
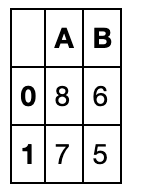
索引对齐特性
默认状态下,后面的表没有的行列都会设置为NaN
df2 = pd.DataFrame({'B': [8, 7], 'C': [6, 5]},index=[1,2])
df1.combine(df2,lambda x,y:x if x.mean()>y.mean() else y)
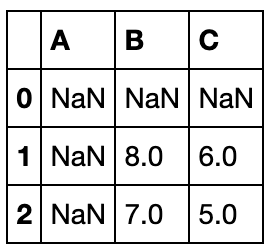
使得df1原来符合条件的值不会被覆盖
df1.combine(df2,lambda x,y:x if x.mean()>y.mean() else y,overwrite=False)
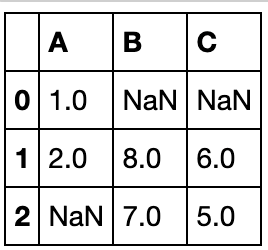
在新增匹配df2的元素位置填充-1
df1.combine(df2,lambda x,y:x if x.mean()>y.mean() else y,fill_value=-1)
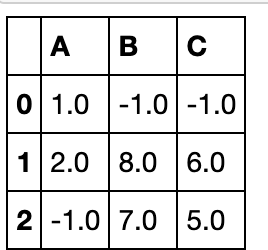
combine_first方法
这个方法作用是用df2填补df1的缺失值,功能比较简单,但很多时候会比combine更常用,下面举两个例子:
df1 = pd.DataFrame({'A': [None, 0], 'B': [None, 4]})
df2 = pd.DataFrame({'A': [1, 1], 'B': [3, 3]})
df1.combine_first(df2)
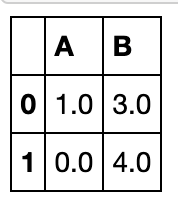
df1 = pd.DataFrame({'A': [None, 0], 'B': [4, None]})
df2 = pd.DataFrame({'B': [3, 3], 'C': [1, 1]}, index=[1, 2])
df1.combine_first(df2)
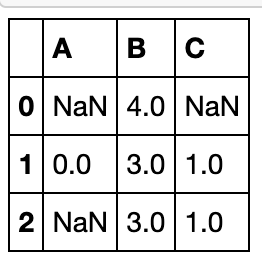
update方法
三个特点
- 返回的框索引只会与被调用框的一致(默认使用左连接)
- 第二个框中的
nan元素不会起作用 - 没有返回值,直接在
df上操作
例子
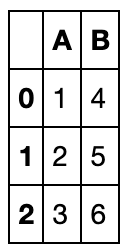
索引完全对齐情况下的操作
df1 = pd.DataFrame({'A': [1, 2, 3],
'B': [400, 500, 600]})
df2 = pd.DataFrame({'B': [4, 5, 6],
'C': [7, 8, 9]})
df1.update(df2)
df1
部分填充
df1 = pd.DataFrame({'A': ['a', 'b', 'c'],
'B': ['x', 'y', 'z']})
df2 = pd.DataFrame({'B': ['d', 'e']}, index=[1,2])
df1.update(df2)
df1
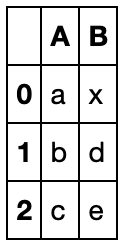
缺失值不会填充
df1 = pd.DataFrame({'A': [1, 2, 3],
'B': [400, 500, 600]})
df2 = pd.DataFrame({'B': [4, np.nan, 6]})
df1.update(df2)
df1
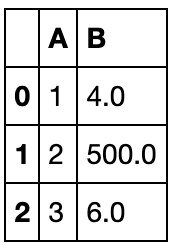
concat方法
concat方法可以在两个维度上拼接,默认纵向凭借(axis=0),拼接方式默认外连接
所谓外连接,就是取拼接方向的并集,而'inner'时取拼接方向(若使用默认的纵向拼接,则为列的交集)的交集
下面举一些例子说明其参数:
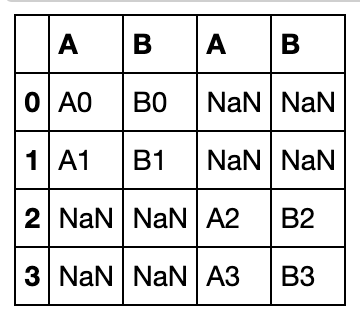
df1 = pd.DataFrame({'A': ['A0', 'A1'],
'B': ['B0', 'B1']},
index = [0,1])
df2 = pd.DataFrame({'A': ['A2', 'A3'],
'B': ['B2', 'B3']},
index = [2,3])
df3 = pd.DataFrame({'A': ['A1', 'A3'],
'D': ['D1', 'D3'],
'E': ['E1', 'E3']},
index = [1,3])
默认状态拼接:
pd.concat([df1,df2])
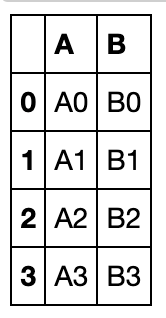
axis=1时沿列方向拼接:
pd.concat([df1,df2],axis=1)
join设置为内连接(由于axis=0,因此列取交集):
pd.concat([df3,df1],join='inner')
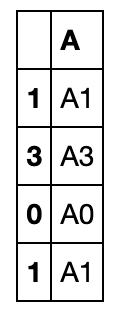
join设置为外链接:
pd.concat([df3,df1],join='outer',sort=True) #sort设置列排序,默认为False
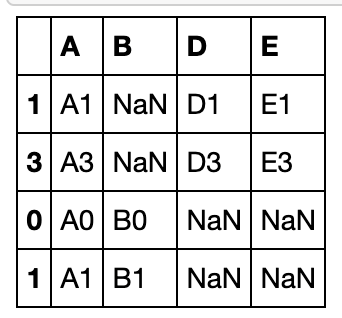
verify_integrity检查列是否唯一:
#pd.concat([df3,df1],verify_integrity=True,sort=True) 报错
同样,可以添加Series:
s = pd.Series(['X0', 'X1'], name='X')
pd.concat([df1,s],axis=1)
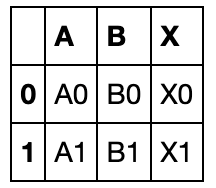
key参数用于对不同的数据框增加一个标号,便于索引:
pd.concat([df1,df2], keys=['x', 'y'])
pd.concat([df1,df2], keys=['x', 'y']).index
MultiIndex([('x', 0),
('x', 1),
('y', 2),
('y', 3)],
)
merge与join
merge函数
merge函数的作用是将两个pandas对象横向合并,遇到重复的索引项时会使用笛卡尔积,默认inner连接,可选left、outer、right连接
所谓左连接,就是指以第一个表索引为基准,右边的表中如果不再左边的则不加入,如果在左边的就以笛卡尔积的方式加入
merge/join与concat的不同之处在于on参数,可以指定某一个对象为key来进行连接
同样的,下面举一些例子:
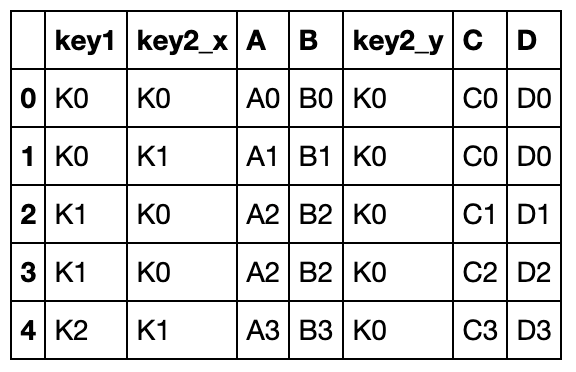
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
right2 = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3']})
以key1为准则连接,如果具有相同的列,则默认suffixes=('_x','_y'):
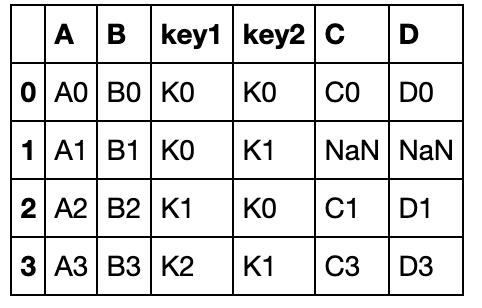
pd.merge(left, right, on='key1')
以多组键连接:
pd.merge(left, right, on=['key1','key2'])
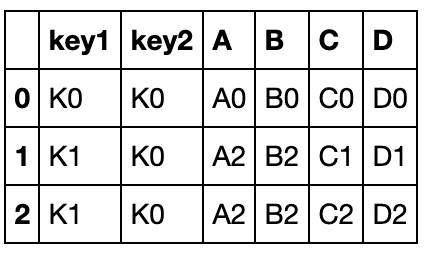
默认使用inner连接,因为merge只能横向拼接,所以取行向上keys的交集,下面看如果使用how=outer参数
注意:这里的how就是concat的join
pd.merge(left, right, how='outer', on=['key1','key2'])
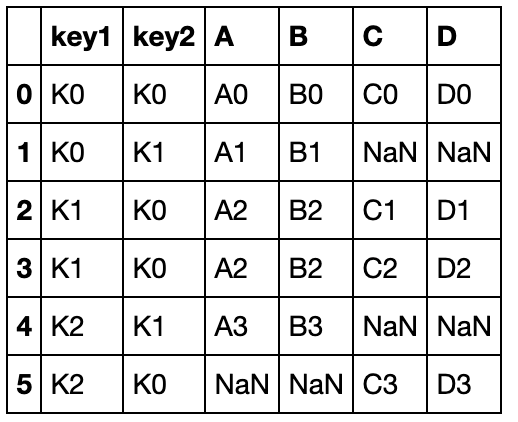
左连接:
pd.merge(left, right, how='left', on=['key1', 'key2'])
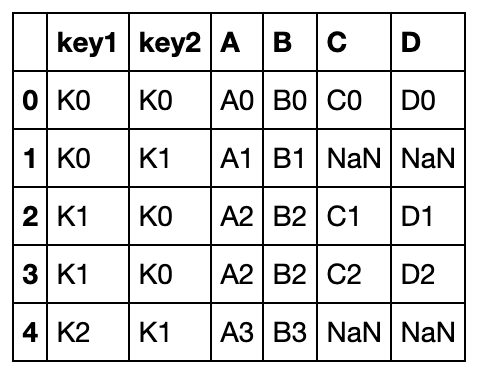
右连接:
pd.merge(left, right, how='right', on=['key1', 'key2'])
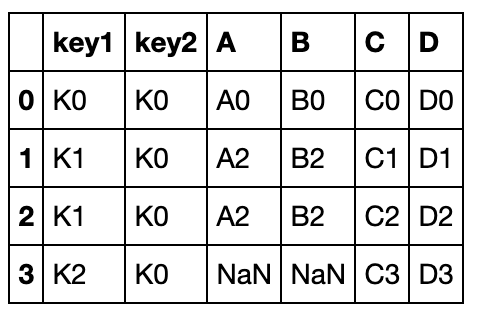
如果还是对笛卡尔积不太了解,请务必理解下面这个例子,由于B的所有元素为2,因此需要6行:
left = pd.DataFrame({'A': [1, 2], 'B': [2, 2]})
right = pd.DataFrame({'A': [4, 5, 6], 'B': [2, 2, 2]})
pd.merge(left, right, on='B', how='outer')
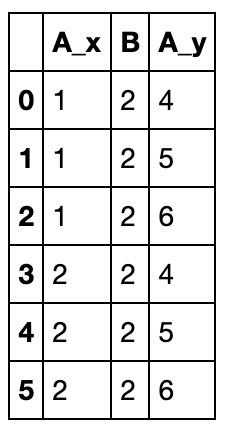
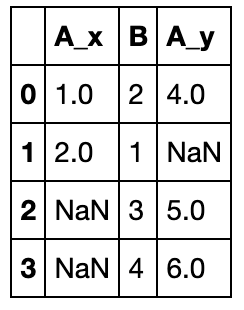
validate检验的是到底哪一边出现了重复索引,如果是“one_to_one”则两侧索引都是唯一,如果"one_to_many"则左侧唯一
left = pd.DataFrame({'A': [1, 2], 'B': [2, 2]})
right = pd.DataFrame({'A': [4, 5, 6], 'B': [2, 3, 4]})
#pd.merge(left, right, on='B', how='outer',validate='one_to_one') #报错
left = pd.DataFrame({'A': [1, 2], 'B': [2, 1]})
pd.merge(left, right, on='B', how='outer',validate='one_to_one')
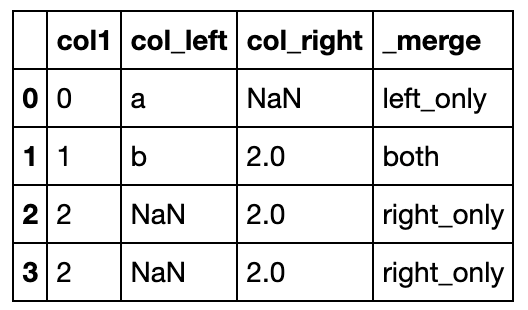
indicator参数指示了,合并后该行索引的来源
df1 = pd.DataFrame({'col1': [0, 1], 'col_left': ['a', 'b']})
df2 = pd.DataFrame({'col1': [1, 2, 2], 'col_right': [2, 2, 2]})
pd.merge(df1, df2, on='col1', how='outer', indicator=True) #indicator='indicator_column'也是可以的
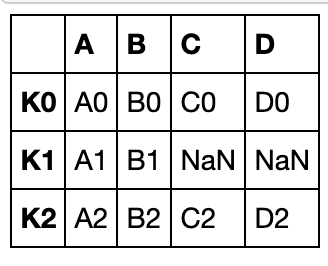
join函数
join函数作用是将多个pandas对象横向拼接,遇到重复的索引项时会使用笛卡尔积,默认左连接,可选inner、outer、right连接
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=['K0', 'K2', 'K3'])
left.join(right)
对于many_to_one模式下的合并,往往join更为方便
同样可以指定key:
left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'key': ['K0', 'K1', 'K0', 'K1']})
right = pd.DataFrame({'C': ['C0', 'C1'],
'D': ['D0', 'D1']},
index=['K0', 'K1'])
left.join(right, on='key')
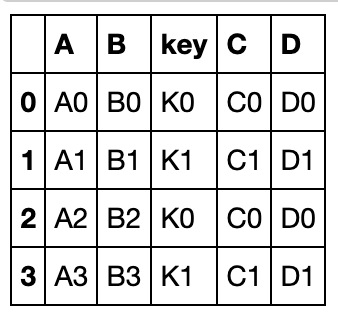
多层key:
left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1']})
index = pd.MultiIndex.from_tuples([('K0', 'K0'), ('K1', 'K0'),
('K2', 'K0'), ('K2', 'K1')],names=['key1','key2'])
right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=index)
left.join(right, on=['key1','key2'])
练习
练习一
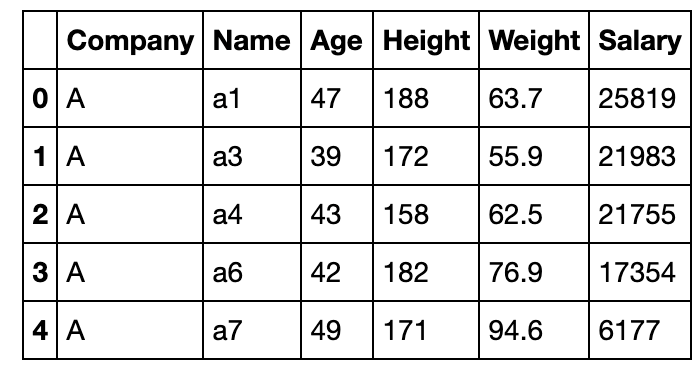
有2张公司的员工信息表,每个公司共有16名员工,共有五个公司,请解决如下问题
pd.read_csv('data/Employee1.csv').head()
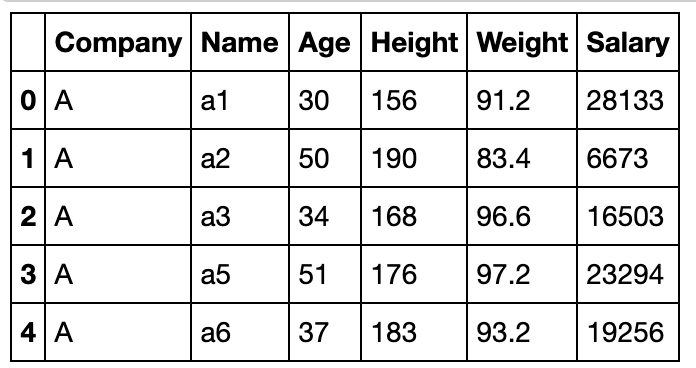
pd.read_csv('data/Employee2.csv').head()
- 每个公司有多少员工满足如下条件:既出现第一张表,又出现在第二张表。
L = list(set(df1['Name']).intersection(set(df2['Name'])))
L
['b1',
'b3',
'c13',
'a6',
'd10',
'b15',
'c10',
'c12',
'b7',
'e10',
'e11',
'd5',
'a1',
'a3',
'c3',
'e8']
- 将所有不符合1中条件的行筛选出来,合并为一张新表,列名与原表一致。
df_b1 = df1[~df1['Name'].isin(L)]
df_b2 = df2[~df2['Name'].isin(L)]
df_b = pd.concat([df_b1,df_b2]).set_index('Name')
df_b.head()
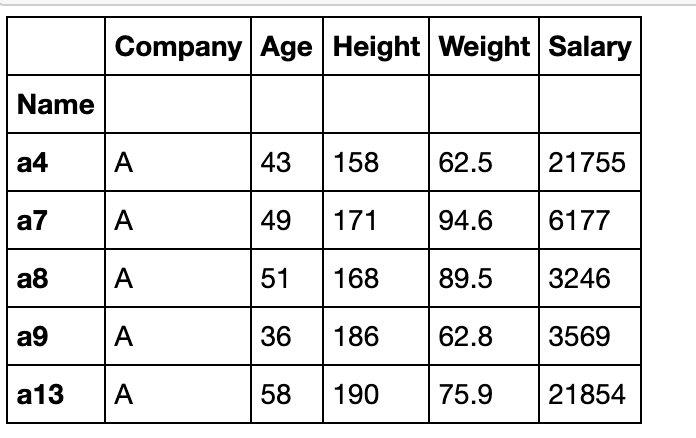
- 现在需要编制所有80位员工的信息表,对于2中的员工要求不变,对于满足1条件员工,它们在某个指标的数值,取偏离它所属公司中满足b员工的均值数较小的哪一个,例如:P公司在两张表的交集为{p1},并集扣除交集为{p2,p3,p4},那么如果后者集合的工资均值为1万元,且p1在表1的工资为13000元,在表2的工资为9000元,那么应该最后取9000元作为p1的工资,最后对于没有信息的员工,利用缺失值填充。
df2 = pd.read_csv('data/Employee2.csv')
df1['重复'] = ['Y_1' if df1.loc[i,'Name'] in L else 'N' for i in range(df1.shape[0])]
df2['重复'] = ['Y_2' if df2.loc[i,'Name'] in L else 'N' for i in range(df2.shape[0])]
df1 = df1.set_index(['Name','重复'])
df2 = df2.set_index(['Name','重复'])
df_c = pd.concat([df1,df2])
result = pd.DataFrame({'Company':[],'Name':[],'Age':[],'Height':[],'Weight':[],'Salary':[]})
group = df_c.groupby(['Company','重复'])
for i in L:
first = group.get_group((i[0].upper(),'Y_1')).reset_index(level=1).loc[i,:][-4:]
second = group.get_group((i[0].upper(),'Y_2')).reset_index(level=1).loc[i,:][-4:]
mean = group.get_group((i[0].upper(),'N')).reset_index(level=1).mean()
final = [i[0].upper(),i]
for j in range(4):
final.append(first[j] if abs(first[j]-mean[j])<abs(second[j]-mean[j]) else second[j])
result = pd.concat([result,pd.DataFrame({result.columns.tolist()[k]:[final[k]] for k in range(6)})])
result = pd.concat([result.set_index('Name'),df_b])
for i in list('abcde'):
for j in range(1,17):
item = i+str(j)
if item not in result.index:
result = pd.concat([result,pd.DataFrame({'Company':[i.upper()],'Name':[item]
,'Age':[np.nan],'Height':[np.nan],'Weight':[np.nan],'Salary':[np.nan]}).set_index('Name')])
result['Number'] = [int(i[1:]) for i in result.index]
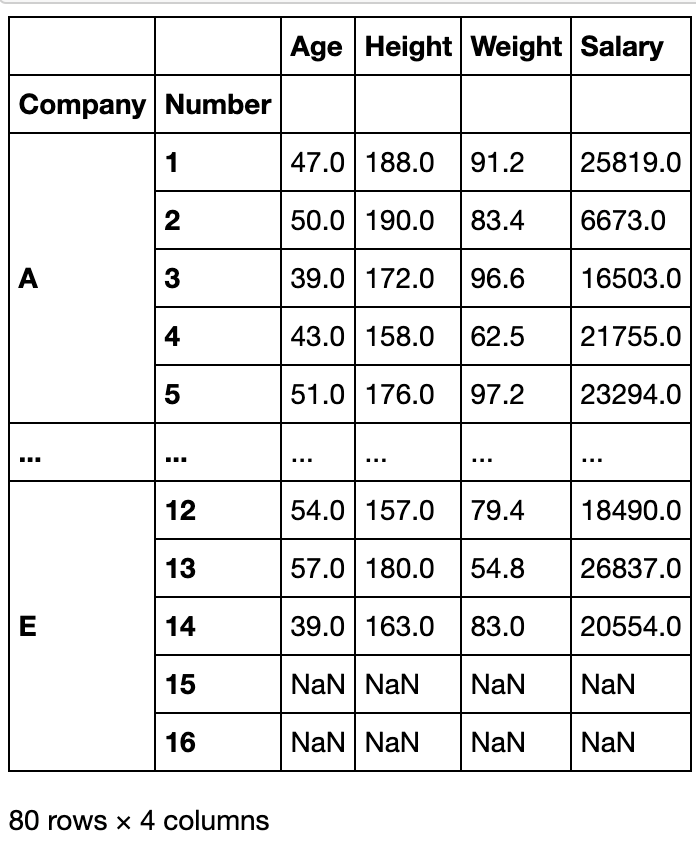
result.reset_index().drop(columns='Name').set_index(['Company','Number']).sort_index()
练习二
有2张课程的分数表(分数随机生成),但专业课(学科基础课、专业必修课、专业选修课)与其他课程混在一起,请解决如下问题:
pd.read_csv('data/Course1.csv').head()
pd.read_csv('data/Course2.csv').head()
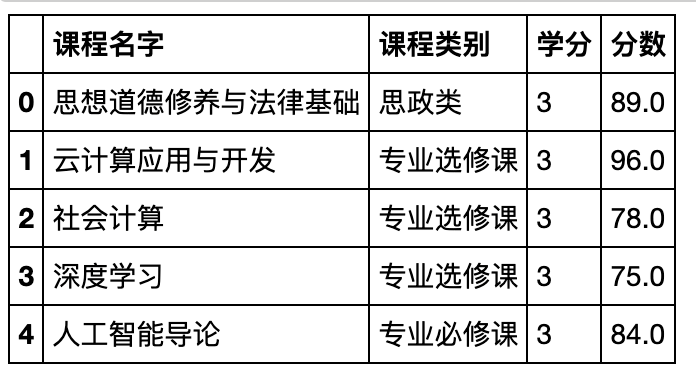
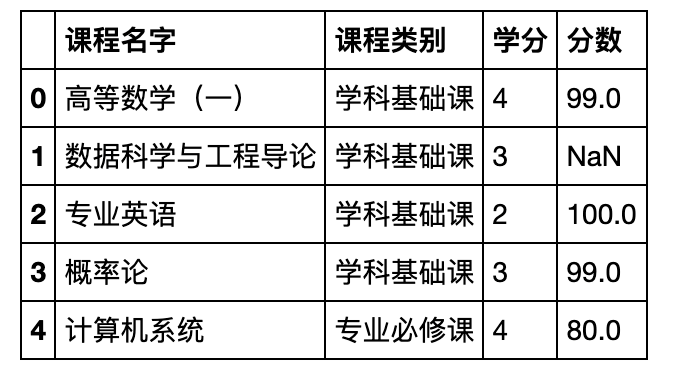
- 将两张表分别拆分为专业课与非专业课(结果为四张表)。
df1 = pd.read_csv('data/Course1.csv')
df2 = pd.read_csv('data/Course2.csv')
df_a11,df_a12,df_a21,df_a22 =0,0,0,0
df_a11= df1.query('课程类别 in ["学科基础课","专业必修课","专业选修课"]')
df_a12= df1.query('课程类别 not in ["学科基础课","专业必修课","专业选修课"]')
df_a21= df2.query('课程类别 in ["学科基础课","专业必修课","专业选修课"]')
df_a22= df2.query('课程类别 not in ["学科基础课","专业必修课","专业选修课"]')
df_a11.head()
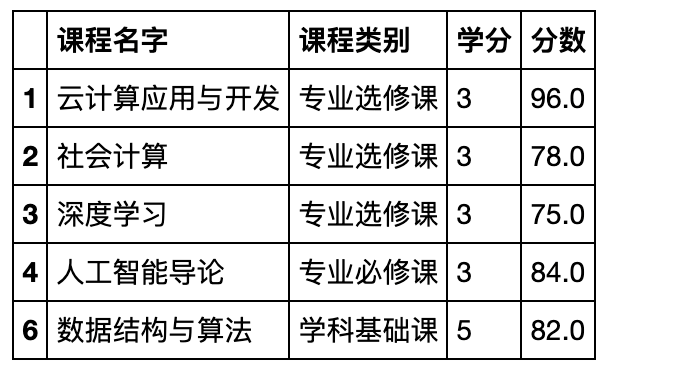
- 将两张专业课的分数表和两张非专业课的分数表分别合并。
special = pd.concat([df_a11,df_a21])
common = pd.concat([df_a12,df_a22])
special.query('课程类别 not in ["学科基础课","专业必修课","专业选修课"]')

common.query('课程类别 in ["学科基础课","专业必修课","专业选修课"]')
- 不使用1中的步骤,请直接读取两张表合并后拆分。
df = pd.concat([df1,df2])
special2 = df.query('课程类别 in ["学科基础课","专业必修课","专业选修课"]')
common2 = df.query('课程类别 not in ["学科基础课","专业必修课","专业选修课"]')
(special.equals(special2),common.equals(common2))
(True, True)
- 专业课程中有缺失值吗,如果有的话请在完成3的同时,用组内(3种类型的专业课)均值填充缺失值后拆分。
df['分数'] = df.groupby('课程类别').transform(lambda x: x.fillna(x.mean()))['分数']
df.isnull().all()
课程名字 False
课程类别 False
学分 False
分数 False
dtype: bool
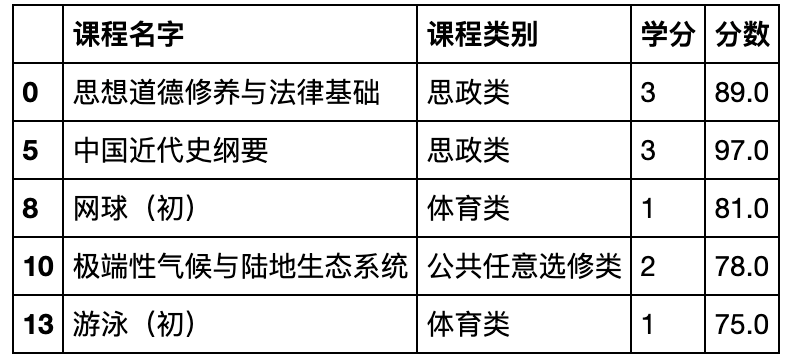
special3 = df.query('课程类别 in ["学科基础课","专业必修课","专业选修课"]')
common3 = df.query('课程类别 not in ["学科基础课","专业必修课","专业选修课"]')
common3.head()
缺失数据
import pandas as pd
import numpy as np
df = pd.read_csv('data/table_missing.csv')
df.head()
缺失观测及其类型
了解缺失信息
isna和notna方法
对Series使用会返回布尔列表
df['Physics'].isna().head()
0 False
1 False
2 False
3 True
4 False
Name: Physics, dtype: bool
df['Physics'].notna().head()
0 True
1 True
2 True
3 False
4 True
Name: Physics, dtype: bool
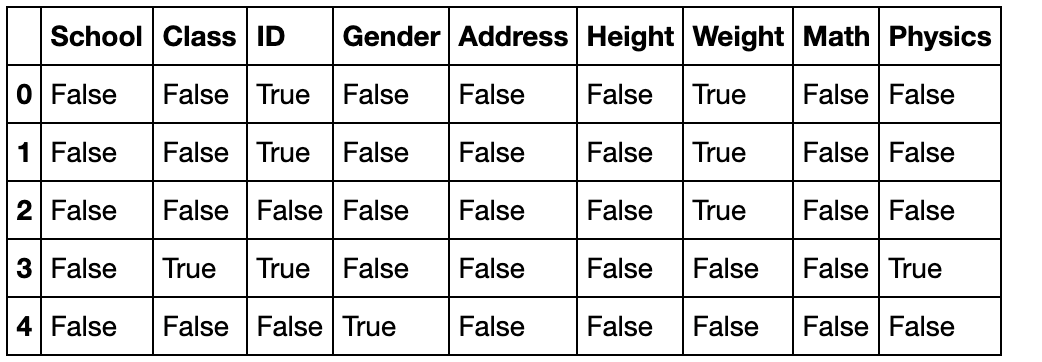
对DataFrame使用会返回布尔表
df.isna().head()
但对于DataFrame我们更关心到底每列有多少缺失值
df.isna().sum()
Out[5]:
School 0
Class 4
ID 6
Gender 7
Address 0
Height 0
Weight 13
Math 5
Physics 4
dtype: int64
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 35 entries, 0 to 34
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 School 35 non-null object
1 Class 31 non-null object
2 ID 29 non-null float64
3 Gender 28 non-null object
4 Address 35 non-null object
5 Height 35 non-null int64
6 Weight 22 non-null float64
7 Math 30 non-null float64
8 Physics 31 non-null object
dtypes: float64(3), int64(1), object(5)
memory usage: 2.6+ KB
查看缺失值的所以在行
以最后一列为例,挑出该列缺失值的行
df[df['Physics'].isna()]
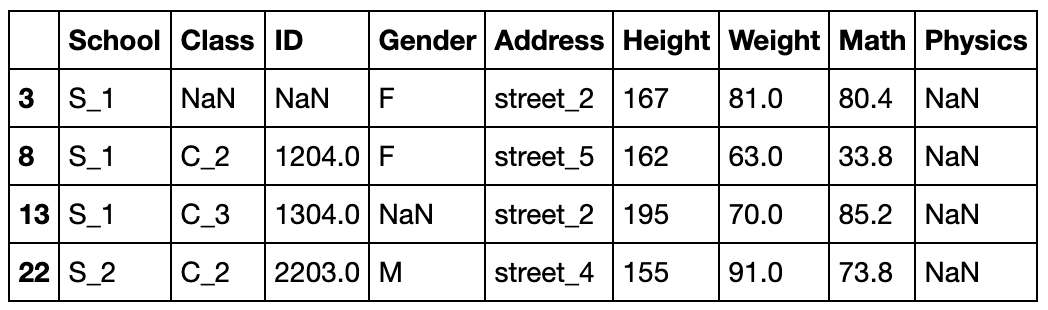
挑选出所有非缺失值列
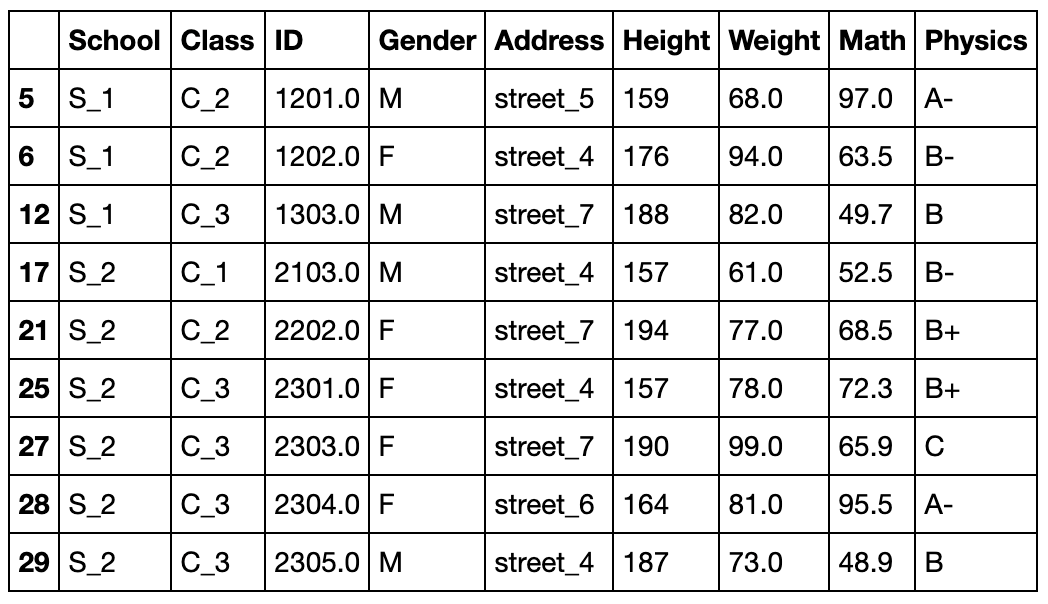
使用all就是全部非缺失值,如果是any就是至少有一个不是缺失值
df[df.notna().all(1)]
三种缺失符号
np.nan
np.nan是一个麻烦的东西,首先它不等与任何东西,甚至不等于自己
np.nan == np.nan
False
np.nan == 0
False
np.nan == None
False
在用equals函数比较时,自动略过两侧全是np.nan的单元格,因此结果不会影响
df.equals(df)
True
其次,它在numpy中的类型为浮点,由此导致数据集读入时,即使原来是整数的列,只要有缺失值就会变为浮点型
type(np.nan)
float
pd.Series([1,2,3]).dtype
dtype('int64')
pd.Series([1,np.nan,3]).dtype
dtype('float64')
此外,对于布尔类型的列表,如果是np.nan填充,那么它的值会自动变为True而不是False
pd.Series([1,np.nan,3],dtype='bool')
0 True
1 True
2 True
dtype: bool
但当修改一个布尔列表时,会改变列表类型,而不是赋值为True
s = pd.Series([True,False],dtype='bool')
s
0 1.0
1 NaN
dtype: float64
在所有的表格读取后,无论列是存放什么类型的数据,默认的缺失值全为np.nan类型
因此整型列转为浮点;而字符由于无法转化为浮点,因此只能归并为object类型('O'),原来是浮点型的则类型不变
df['ID'].dtype
dtype('float64')
df['Math'].dtype
dtype('float64')
df['Class'].dtype
dtype('O')
None
None比前者稍微好些,至少它会等于自身
None == None
True
它的布尔值为False
pd.Series([None],dtype='bool')
0 False
dtype: bool
修改布尔列表不会改变数据类型
s = pd.Series([True,False],dtype='bool')
s[0]=None
s
0 False
1 False
dtype: bool
s = pd.Series([1,0],dtype='bool')
s
0 False
1 False
dtype: bool
在传入数值类型后,会自动变为np.nan
type(pd.Series([1,None])[1])
numpy.float64
只有当传入object类型是保持不动,几乎可以认为,除非人工命名None,它基本不会自动出现在Pandas中
type(pd.Series([1,None],dtype='O')[1])
NoneType
在使用equals函数时不会被略过,因此下面的情况下返回False
pd.Series([None]).equals(pd.Series([np.nan]))
False
NaT
NaT是针对时间序列的缺失值,是Pandas的内置类型,可以完全看做时序版本的np.nan,与自己不等,且使用equals时也会被跳过
s_time = pd.Series([pd.Timestamp('20120101')]*5)
s_time
0 2012-01-01
1 2012-01-01
2 2012-01-01
3 2012-01-01
4 2012-01-01
dtype: datetime64[ns]
s_time[2] = None
s_time
0 2012-01-01
1 2012-01-01
2 NaT
3 2012-01-01
4 2012-01-01
dtype: datetime64[ns]
s_time[2] = np.nan
s_time
0 2012-01-01
1 2012-01-01
2 NaT
3 2012-01-01
4 2012-01-01
dtype: datetime64[ns]
s_time[2] = pd.NaT
s_time
0 2012-01-01
1 2012-01-01
2 NaT
3 2012-01-01
4 2012-01-01
dtype: datetime64[ns]
type(s_time[2])
pandas._libs.tslibs.nattype.NaTType
s_time[2] == s_time[2]
False
s_time.equals(s_time)
True
s = pd.Series([True,False],dtype='bool')
s[1]=pd.NaT
s
0 True
1 True
dtype: bool
Nullable类型与NA符号
官方鼓励用户使用新的数据类型和缺失类型pd.NA
Nullable整形
对于该种类型而言,它与原来标记int上的符号区别在于首字母大写:'Int'
s_original = pd.Series([1, 2], dtype="int64")
s_original
0 1
1 2
dtype: int64
s_new = pd.Series([1, 2], dtype="Int64")
s_new
0 1
1 2
dtype: Int64
它的好处就在于,其中前面提到的三种缺失值都会被替换为统一的NA符号,且不改变数据类型
s_original[1] = np.nan
s_original
0 1.0
1 NaN
dtype: float64
s_new[1] = np.nan
s_new
0 1
1 <NA>
dtype: Int64
s_new[1] = None
Out[40]:
0 1
1 <NA>
dtype: Int64
s_new[1] = pd.NaT
s_new
0 1
1 <NA>
dtype: Int64
Nullable布尔
对于该种类型而言,作用与上面的类似,记号为boolean
s_original = pd.Series([1, 0], dtype="bool")
s_original
0 True
1 False
dtype: bool
s_new = pd.Series([0, 1], dtype="boolean")
s_new
0 False
1 True
dtype: boolean
s_original[0] = np.nan
s_original
0 NaN
1 0.0
dtype: float64
s_original = pd.Series([1, 0], dtype="bool") #此处重新加一句是因为前面赋值改变了bool类型
s_original[0] = None
s_original
0 False
1 False
dtype: bool
s_new[0] = np.nan
s_new
0 <NA>
1 True
dtype: boolean
s_new[0] = None
s_new
0 <NA>
1 True
dtype: boolean
s_new[0] = pd.NaT
s_new
0 <NA>
1 True
dtype: boolean
s = pd.Series(['dog','cat'])
s[s_new]
1 cat
dtype: object
string类型
它本质上也属于Nullable类型,因为并不会因为含有缺失而改变类型
s = pd.Series(['dog','cat'],dtype='string')
s
0 dog
1 cat
dtype: string
s[0] = np.nan
s
0 <NA>
1 cat
dtype: string
s[0] = None
s
0 <NA>
1 cat
dtype: string
s[0] = pd.NaT
s
0 <NA>
1 cat
dtype: string
此外,和object类型的一点重要区别就在于,在调用字符方法后,string类型返回的是Nullable类型,object则会根据缺失类型和数据类型而改变
s = pd.Series(["a", None, "b"], dtype="string")
s.str.count('a')
0 1
1 <NA>
2 0
dtype: Int64
s2 = pd.Series(["a", None, "b"], dtype="object")
s2.str.count("a")
0 1.0
1 NaN
2 0.0
dtype: float64
s.str.isdigit()
0 False
1 <NA>
2 False
dtype: boolean
s2.str.isdigit()
0 False
1 None
2 False
dtype: object
NA的特性
逻辑运算
只需看该逻辑运算的结果是否依赖pd.NA的取值,如果依赖,则结果还是NA,如果不依赖,则直接计算结果
True | pd.NA
True
pd.NA | True
True
False | pd.NA
<NA>
False & pd.NA
False
True & pd.NA
<NA>
取值不明直接报错
#bool(pd.NA)
算术运算和比较运算
这里只需记住除了下面两类情况,其他结果都是NA即可
pd.NA ** 0
1
1 ** pd.NA
1
pd.NA + 1
<NA>
"a" * pd.NA
<NA>
pd.NA == pd.NA
<NA>
pd.NA < 2.5
<NA>
np.log(pd.NA)
<NA>
np.add(pd.NA, 1)
<NA>
convert_dtypes方法
这个函数的功能往往就是在读取数据时,就把数据列转为Nullable类型
pd.read_csv('data/table_missing.csv').dtypes
School object
Class object
ID float64
Gender object
Address object
Height int64
Weight float64
Math float64
Physics object
dtype: object
pd.read_csv('data/table_missing.csv').convert_dtypes().dtypes
School string
Class string
ID Int64
Gender string
Address string
Height Int64
Weight Int64
Math float64
Physics string
dtype: object
缺失数据的运算与分组
加号与乘号规则
使用加法时,缺失值为0
s = pd.Series([2,3,np.nan,4])
s.sum()
9.0
使用乘法时,缺失值为1
s.prod()
24.0
使用累计函数时,缺失值自动略过
s.cumsum()
0 2.0
1 5.0
2 NaN
3 9.0
dtype: float64
s.cumprod()
0 2.0
1 6.0
2 NaN
3 24.0
dtype: float64
s.pct_change()
0 NaN
1 0.500000
2 0.000000
3 0.333333
dtype: float64
groupby方法中的缺失值
自动忽略为缺失值的组
df_g = pd.DataFrame({'one':['A','B','C','D',np.nan],'two':np.random.randn(5)})
df_g
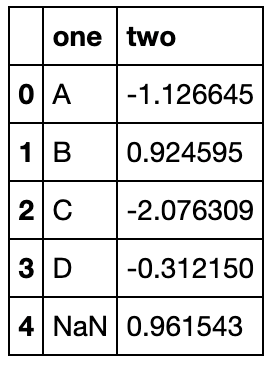
df_g.groupby('one').groups
{'A': Int64Index([0], dtype='int64'),
'B': Int64Index([1], dtype='int64'),
'C': Int64Index([2], dtype='int64'),
'D': Int64Index([3], dtype='int64')}
填充与剔除
fillna方法
值填充与前后向填充(分别与ffill方法和bfill方法等价)
df['Physics'].fillna('missing').head()
0 A+
1 B+
2 B+
3 missing
4 A-
Name: Physics, dtype: object
df['Physics'].fillna(method='ffill').head()
0 A+
1 B+
2 B+
3 B+
4 A-
Name: Physics, dtype: object
df['Physics'].fillna(method='backfill').head()
0 A+
1 B+
2 B+
3 A-
4 A-
Name: Physics, dtype: object
填充中的对齐特性
df_f = pd.DataFrame({'A':[1,3,np.nan],'B':[2,4,np.nan],'C':[3,5,np.nan]})
df_f.fillna(df_f.mean())
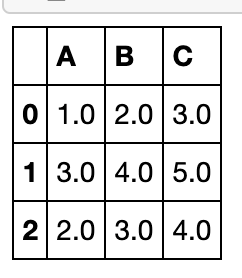
返回的结果中没有C,根据对齐特点不会被填充
df_f.fillna(df_f.mean()[['A','B']])
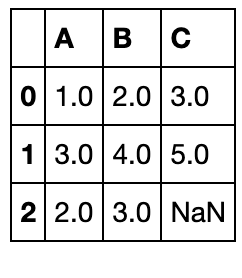
dropna方法
axis参数
df_d = pd.DataFrame({'A':[np.nan,np.nan,np.nan],'B':[np.nan,3,2],'C':[3,2,1]})
df_d
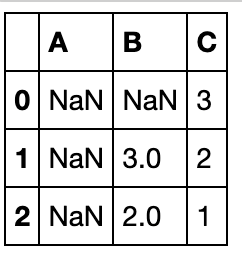
df_d.dropna(axis=0)
df_d.dropna(axis=1)
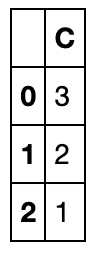
how参数(可以选all或者any,表示全为缺失去除和存在缺失去除)
df_d.dropna(axis=1,how='all')
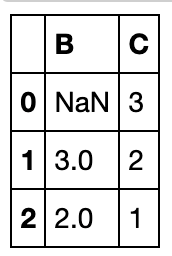
subset参数(即在某一组列范围中搜索缺失值)
df_d.dropna(axis=0,subset=['B','C'])
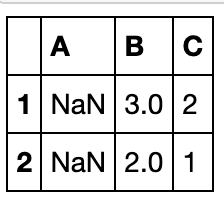
插值(interpolation)
线性插值
索引无关的线性插值
默认状态下,interpolate会对缺失的值进行线性插值
s = pd.Series([1,10,15,-5,-2,np.nan,np.nan,28])
s
0 1.0
1 10.0
2 15.0
3 -5.0
4 -2.0
5 NaN
6 NaN
7 28.0
dtype: float64
s.interpolate()
0 1.0
1 10.0
2 15.0
3 -5.0
4 -2.0
5 8.0
6 18.0
7 28.0
dtype: float64
s.interpolate().plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7fe7df20af50>
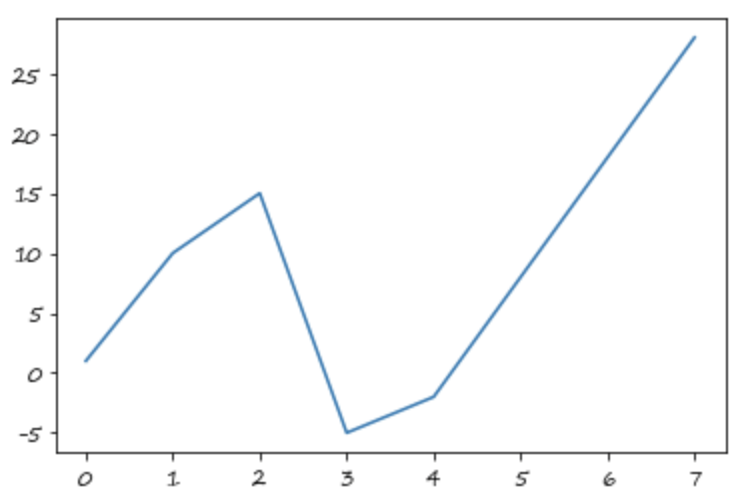
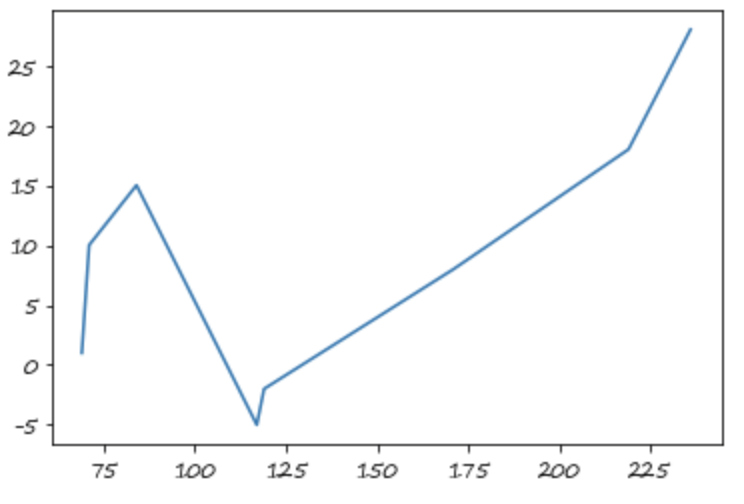
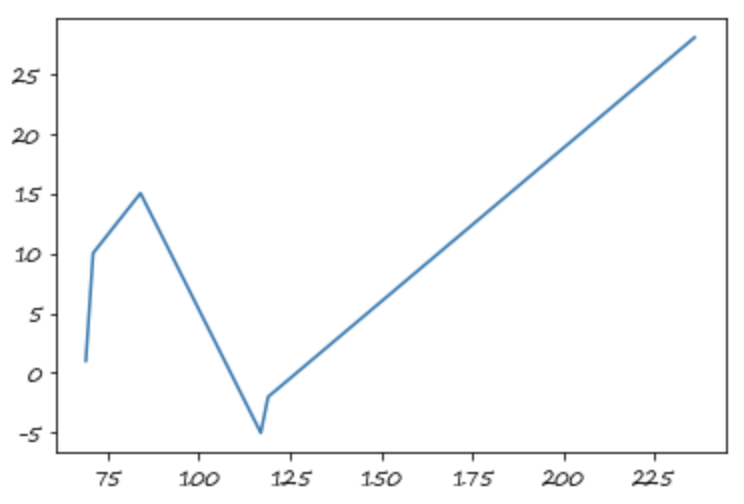
此时的插值与索引无关
s.index = np.sort(np.random.randint(50,300,8))
s.interpolate()
#值不变
69 1.0
71 10.0
84 15.0
117 -5.0
119 -2.0
171 8.0
219 18.0
236 28.0
dtype: float64
s.interpolate().plot()
#后面三个点不是线性的(如果几乎为线性函数,请重新运行上面的一个代码块,这是随机性导致的)
<matplotlib.axes._subplots.AxesSubplot at 0x7fe7dfc69890>
与索引有关的插值
method中的index和time选项可以使插值线性地依赖索引,即插值为索引的线性函数
s.interpolate(method='index').plot()
#可以看到与上面的区别
<matplotlib.axes._subplots.AxesSubplot at 0x7fe7dca0c4d0>
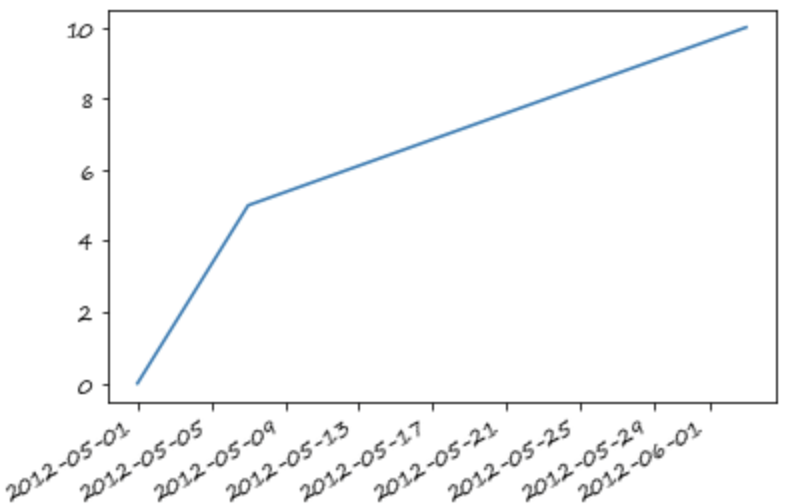
如果索引是时间,那么可以按照时间长短插值
s_t = pd.Series([0,np.nan,10]
,index=[pd.Timestamp('2012-05-01'),pd.Timestamp('2012-05-07'),pd.Timestamp('2012-06-03')])
s_t
2012-05-01 0.0
2012-05-07 NaN
2012-06-03 10.0
dtype: float64
s_t.interpolate().plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7fe7dc964850>
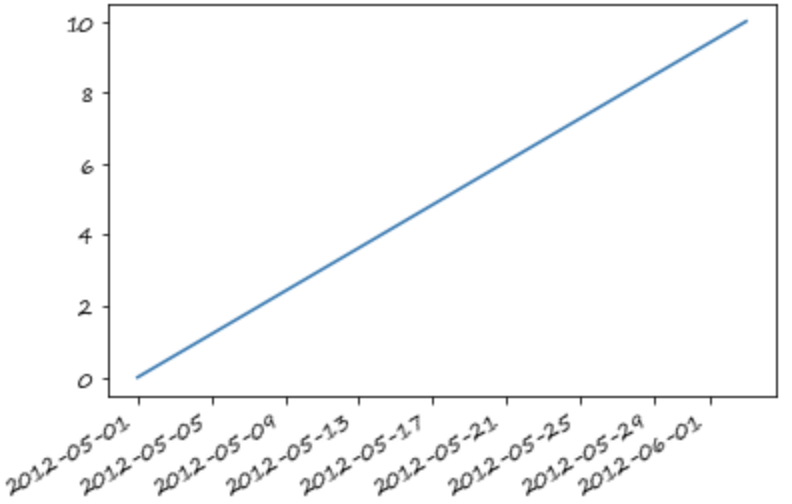
s_t.interpolate(method='time').plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7fe7dc8eda10>
interpolate中的限制参数
limit表示最多插入多少个
s = pd.Series([1,np.nan,np.nan,np.nan,5])
s.interpolate(limit=2)
0 1.0
1 2.0
2 3.0
3 NaN
4 5.0
dtype: float64
limit_direction表示插值方向,可选forward,backward,both,默认前向
s = pd.Series([np.nan,np.nan,1,np.nan,np.nan,np.nan,5,np.nan,np.nan,])
s.interpolate(limit_direction='backward')
0 1.0
1 1.0
2 1.0
3 2.0
4 3.0
5 4.0
6 5.0
7 NaN
8 NaN
dtype: float64
limit_area表示插值区域,可选inside,outside,默认None
s = pd.Series([np.nan,np.nan,1,np.nan,np.nan,np.nan,5,np.nan,np.nan,])
s.interpolate(limit_area='inside')
0 NaN
1 NaN
2 1.0
3 2.0
4 3.0
5 4.0
6 5.0
7 NaN
8 NaN
dtype: float64
s = pd.Series([np.nan,np.nan,1,np.nan,np.nan,np.nan,5,np.nan,np.nan,])
s.interpolate(limit_area='outside')
0 NaN
1 NaN
2 1.0
3 NaN
4 NaN
5 NaN
6 5.0
7 5.0
8 5.0
dtype: float64
练习
练习一
现有一份虚拟数据集,列类型分别为string/浮点/整型,请解决如下问题
pd.read_csv('data/Missing_data_one.csv').head()
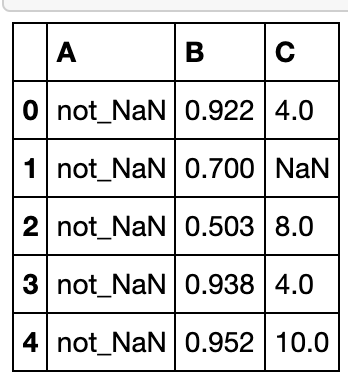
- 请以列类型读入数据,并选出C为缺失值的行。
df[df['C'].isna()]
- 现需要将A中的部分单元转为缺失值,单元格中的最小转换概率为25%,且概率大小与所在行B列单元的值成正比。
df = pd.read_csv('data/Missing_data_one.csv').convert_dtypes()
total_b = df['B'].sum()
min_b = df['B'].min()
df['A'] = pd.Series(list(zip(df['A'].values
,df['B'].values))).apply(lambda x:x[0] if np.random.rand()>0.25*x[1]/min_b else np.nan)
df.head()
练习二
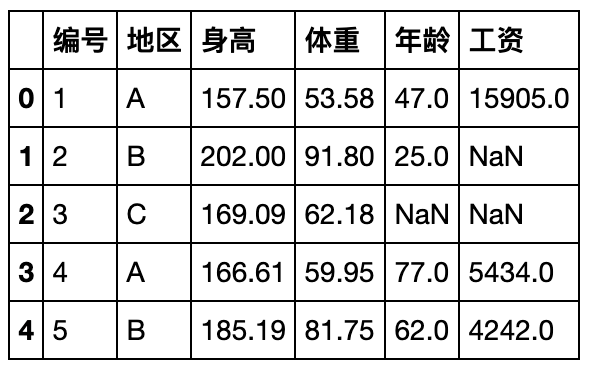
现有一份缺失的数据集,记录了36个人来自的地区、身高、体重、年龄和工资,请解决如下问题:
pd.read_csv('data/Missing_data_two.csv').head()
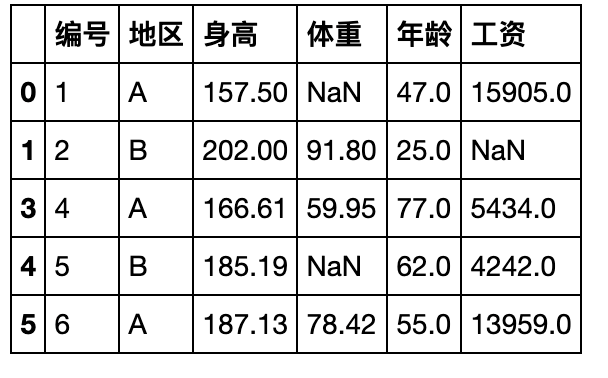
- 统计各列缺失的比例并选出在后三列中至少有两个非缺失值的行。
df.isna().sum()/df.shape[0]
Out[60]:
编号 0.000000
地区 0.000000
身高 0.000000
体重 0.222222
年龄 0.250000
工资 0.222222
dtype: float64
df_not2na = df[df.iloc[:,-3:].isna().sum(1)<=1]
df_not2na.head()
- 请结合身高列和地区列中的数据,对体重进行合理插值。
分地区,用排序后的身高信息进行线性插值
df_method_1 = df.copy()
for name,group in df_method_1.groupby('地区'):
df_method_1.loc[group.index,'体重'] = group[['身高','体重']].sort_values(by='身高').interpolate()['体重']
df_method_1['体重'] = df_method_1['体重'].round(decimals=2)
df_method_1.head()
文本数据
import pandas as pd
import numpy as np
string类型的性质
string与object的区别
string类型和object不同之处有三:
- 字符存取方法(string accessor methods,如str.count)会返回相应数据的
Nullable类型,而object会随缺失值的存在而改变返回类型 - 某些
Series方法不能在string上使用,例如:Series.str.decode(),因为存储的是字符串而不是字节 string类型在缺失值存储或运算时,类型会广播为pd.NA,而不是浮点型np.nan
其余全部内容在当前版本下完全一致,但迎合Pandas的发展模式,我们仍然全部用string来操作字符串
string类型的转换
如果将一个其他类型的容器直接转换string类型可能会出错:
#pd.Series([1,'1.']).astype('string') #报错
#pd.Series([1,2]).astype('string') #报错
#pd.Series([True,False]).astype('string') #报错
当下正确的方法是分两部转换,先转为str型object,在转为string类型:
pd.Series([1,'1.']).astype('str').astype('string')
0 1
1 1.
dtype: string
pd.Series([1,2]).astype('str').astype('string')
0 1
1 2
dtype: string
pd.Series([True,False]).astype('str').astype('string')
0 True
1 False
dtype: string
拆分与拼接
str.split方法
分割符与str的位置元素选取
s = pd.Series(['a_b_c', 'c_d_e', np.nan, 'f_g_h'], dtype="string")
s
0 a_b_c
1 c_d_e
2 <NA>
3 f_g_h
dtype: string
根据某一个元素分割,默认为空格
s.str.split('_')
0 [a, b, c]
1 [c, d, e]
2 <NA>
3 [f, g, h]
dtype: object
这里需要注意split后的类型是object,因为现在Series中的元素已经不是string,而包含了list,且string类型只能含有字符串
对于str方法可以进行元素的选择,如果该单元格元素是列表,那么str[i]表示取出第i个元素,如果是单个元素,则先把元素转为列表在取出
s.str.split('_').str[1]
0 b
1 d
2 <NA>
3 g
dtype: object
pd.Series(['a_b_c', ['a','b','c']], dtype="object").str[1]
#第一个元素先转为['a','_','b','_','c']
0 _
1 b
dtype: object
其他参数
expand参数控制了是否将列拆开,n参数代表最多分割多少次
s.str.split('_',expand=True)
s.str.split('_',n=1)
0 [a, b_c]
1 [c, d_e]
2 <NA>
3 [f, g_h]
dtype: object
s.str.split('_',expand=True,n=1)
str.cat方法
不同对象的拼接模式
cat方法对于不同对象的作用结果并不相同,其中的对象包括:单列、双列、多列
对于单个Series而言,就是指所有的元素进行字符合并为一个字符串
s = pd.Series(['ab',None,'d'],dtype='string')
s
0 ab
1 <NA>
2 d
dtype: string
s.str.cat()
'abd'
其中可选sep分隔符参数,和缺失值替代字符na_rep参数
s.str.cat(sep=',')
'ab,d'
s.str.cat(sep=',',na_rep='*')
'ab,*,d'
对于两个Series合并而言,是对应索引的元素进行合并
s2 = pd.Series(['24',None,None],dtype='string')
s2
0 24
1 <NA>
2 <NA>
dtype: string
s.str.cat(s2)
0 ab24
1 <NA>
2 <NA>
dtype: string
同样也有相应参数,需要注意的是两个缺失值会被同时替换
s.str.cat(s2,sep=',',na_rep='*')
0 ab,24
1 *,*
2 d,*
dtype: string
多列拼接可以分为表的拼接和多Series拼接
表的拼接
s.str.cat(pd.DataFrame({0:['1','3','5'],1:['5','b',None]},dtype='string'),na_rep='*')
0 ab15
1 *3b
2 d5*
dtype: string
多个Series拼接
s.str.cat([s+'0',s*2])
0 abab0abab
1 <NA>
2 dd0dd
dtype: string
cat中的索引对齐
当前版本中,如果两边合并的索引不相同且未指定join参数,默认为左连接,设置join='left'
s2 = pd.Series(list('abc'),index=[1,2,3],dtype='string')
s2
1 a
2 b
3 c
dtype: string
s.str.cat(s2,na_rep='*')
0 ab*
1 *a
2 db
dtype: string
替换
广义上的替换,就是指str.replace函数的应用,fillna是针对缺失值的替换
提到替换,就不可避免地接触到正则表达式,这里默认读者已掌握常见正则表达式知识点,若对其还不了解的,可以通过这份资料来熟悉
str.replace的常见用法
s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca','', np.nan, 'CABA', 'dog', 'cat'],dtype="string")
s
0 A
1 B
2 C
3 Aaba
4 Baca
5
6 <NA>
7 CABA
8 dog
9 cat
dtype: string
第一个值写r开头的正则表达式,后一个写替换的字符串
s.str.replace(r'^[AB]','***')
0 ***
1 ***
2 C
3 ***aba
4 ***aca
5
6 <NA>
7 CABA
8 dog
9 cat
dtype: string
子组与函数替换
通过正整数调用子组(0返回字符本身,从1开始才是子组)
s.str.replace(r'([ABC])(\w+)',lambda x:x.group(2)[1:]+'*')
0 A
1 B
2 C
3 ba*
4 ca*
5
6 <NA>
7 BA*
8 dog
9 cat
dtype: string
利用?P<....>表达式可以对子组命名调用
s.str.replace(r'(?P<one>[ABC])(?P<two>\w+)',lambda x:x.group('two')[1:]+'*')
0 A
1 B
2 C
3 ba*
4 ca*
5
6 <NA>
7 BA*
8 dog
9 cat
dtype: string
关于str.replace的注意事项
首先,要明确str.replace和replace并不是一个东西:
str.replace针对的是object类型或string类型,默认是以正则表达式为操作,目前暂时不支持DataFrame上使用
replace针对的是任意类型的序列或数据框,如果要以正则表达式替换,需要设置regex=True,该方法通过字典可支持多列替换
但现在由于string类型的初步引入,用法上出现了一些问题,这些issue有望在以后的版本中修复
str.replace赋值参数不得为pd.NA
这听上去非常不合理,例如对满足某些正则条件的字符串替换为缺失值,直接更改为缺失值在当下版本就会报错
#pd.Series(['A','B'],dtype='string').str.replace(r'[A]',pd.NA) #报错
#pd.Series(['A','B'],dtype='O').str.replace(r'[A]',pd.NA) #报错
此时,可以先转为object类型再转换回来,曲线救国:
pd.Series(['A','B'],dtype='string').astype('O').replace(r'[A]',pd.NA,regex=True).astype('string')
0 <NA>
1 B
dtype: string
至于为什么不用replace函数的regex替换(但string类型replace的非正则替换是可以的),原因在下面一条
对于string类型Series,在使用replace函数时不能使用正则表达式替换
该bug现在还未修复
pd.Series(['A','B'],dtype='string').replace(r'[A]','C',regex=True)
0 A
1 B
dtype: string
pd.Series(['A','B'],dtype='O').replace(r'[A]','C',regex=True)
0 C
1 B
dtype: object
string类型序列如果存在缺失值,不能使用replace替换
#pd.Series(['A',np.nan],dtype='string').replace('A','B') #报错
pd.Series(['A',np.nan],dtype='string').str.replace('A','B')
0 B
1 <NA>
dtype: string
综上,概况的说,除非需要赋值元素为缺失值(转为object再转回来),否则请使用str.replace方法
子串匹配与提取
str.extract方法
常见用法
pd.Series(['10-87', '10-88', '10-89'],dtype="string").str.extract(r'([\d]{2})-([\d]{2})')
使用子组名作为列名
pd.Series(['10-87', '10-88', '-89'],dtype="string").str.extract(r'(?P<name_1>[\d]{2})-(?P<name_2>[\d]{2})')
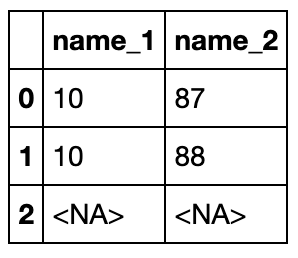
利用?正则标记选择部分提取
pd.Series(['10-87', '10-88', '-89'],dtype="string").str.extract(r'(?P<name_1>[\d]{2})?-(?P<name_2>[\d]{2})')
pd.Series(['10-87', '10-88', '10-'],dtype="string").str.extract(r'(?P<name_1>[\d]{2})-(?P<name_2>[\d]{2})?')
expand参数(默认为True)
对于一个子组的Series,如果expand设置为False,则返回Series,若大于一个子组,则expand参数无效,全部返回DataFrame
对于一个子组的Index,如果expand设置为False,则返回提取后的Index,若大于一个子组且expand为False,报错
s.index
Index(['A11', 'B22', 'C33'], dtype='object')
s.str.extract(r'([\w])')
0
A11 a
B22 b
C33 c
s.str.extract(r'([\w])',expand=False)
A11 a
B22 b
C33 c
dtype: string
s.index.str.extract(r'([\w])')
0
0 A
1 B
2 C
s.index.str.extract(r'([\w])',expand=False)
Index(['A', 'B', 'C'], dtype='object')
s.index.str.extract(r'([\w])([\d])')
0 1
0 A 1
1 B 2
2 C 3
#s.index.str.extract(r'([\w])([\d])',expand=False) #报错
str.extractall方法
与extract只匹配第一个符合条件的表达式不同,extractall会找出所有符合条件的字符串,并建立多级索引(即使只找到一个)
s = pd.Series(["a1a2", "b1", "c1"], index=["A", "B", "C"],dtype="string")
two_groups = '(?P<letter>[a-z])(?P<digit>[0-9])'
s.str.extract(two_groups, expand=True)
s.str.extractall(two_groups)
s['A']='a1'
s.str.extractall(two_groups)
如果想查看第i层匹配,可使用xs方法
s = pd.Series(["a1a2", "b1b2", "c1c2"], index=["A", "B", "C"],dtype="string")
s.str.extractall(two_groups).xs(1,level='match')
str.contains和str.match
前者的作用为检测是否包含某种正则模式
pd.Series(['1', None, '3a', '3b', '03c'], dtype="string").str.contains(r'[0-9][a-z]')
Out[49]:
0 False
1 <NA>
2 True
3 True
4 True
dtype: boolean
可选参数为na
pd.Series(['1', None, '3a', '3b', '03c'], dtype="string").str.contains('a', na=False)
0 False
1 False
2 True
3 False
4 False
dtype: boolean
str.match与其区别在于,match依赖于python的re.match,检测内容为是否从头开始包含该正则模式
pd.Series(['1', None, '3a_', '3b', '03c'], dtype="string").str.match(r'[0-9][a-z]',na=False)
0 False
1 False
2 True
3 True
4 False
dtype: boolean
pd.Series(['1', None, '_3a', '3b', '03c'], dtype="string").str.match(r'[0-9][a-z]',na=False)
0 False
1 False
2 False
3 True
4 False
dtype: boolean
常用字符串方法
过滤型方法
str.strip
常用于过滤空格
pd.Series(list('abc'),index=[' space1 ','space2 ',' space3'],dtype="string").index.str.strip()
Index(['space1', 'space2', 'space3'], dtype='object')
str.lower和str.upper
pd.Series('A',dtype="string").str.lower()
0 a
dtype: string
pd.Series('a',dtype="string").str.upper()
0 A
dtype: string
str.swapcase和str.capitalize
分别表示交换字母大小写和大写首字母
pd.Series('abCD',dtype="string").str.swapcase()
0 ABcd
dtype: string
pd.Series('abCD',dtype="string").str.capitalize()
0 Abcd
dtype: string
isnumeric方法
检查每一位是否都是数字,请问如何判断是否是数值?(问题二)
pd.Series(['1.2','1','-0.3','a',np.nan],dtype="string").str.isnumeric()
0 False
1 True
2 False
3 False
4 <NA>
dtype: boolean
练习
练习一
现有一份关于字符串的数据集,请解决以下问题:
pd.read_csv('data/String_data_one.csv',index_col='人员编号').head()
- 现对字符串编码存储人员信息(在编号后添加ID列),使用如下格式:“×××(名字):×国人,性别×,生于×年×月×日”
(df['姓名']+':'+df['国籍']+'国人,性别'
+df['性别']+',生于'
+df['出生年']+'年'
+df['出生月']+'月'+df['出生日']+'日').to_frame().rename(columns={0:'ID'}).head()
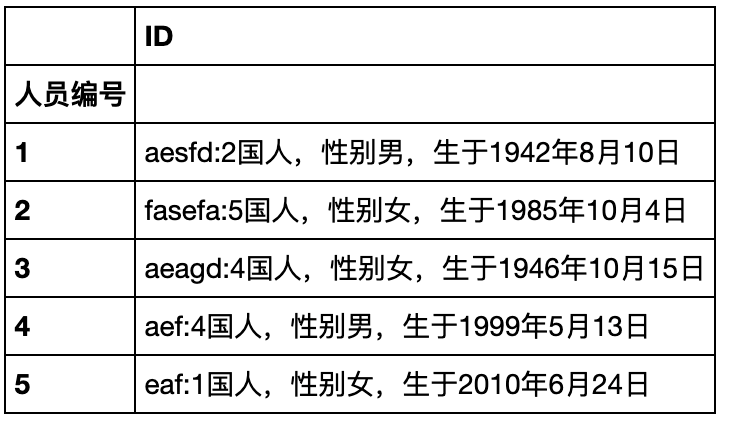
- 将1中的人员生日信息部分修改为用中文表示(如一九七四年十月二十三日),其余返回格式不变。
L_year = list('零一二三四五六七八九')
L_one = [s.strip() for s in list(' 二三四五六七八九')]
L_two = [s.strip() for s in list(' 一二三四五六七八九')]
df_new = (df['姓名']+':'+df['国籍']+'国人,性别'+df['性别']+',生于'
+df['出生年'].str.replace(r'\d',lambda x:L_year[int(x.group(0))])+'年'
+df['出生月'].apply(lambda x:x if len(x)==2 else '0'+x)\
.str.replace(r'(?P<one>[\d])(?P<two>\d?)',lambda x:L_one[int(x.group('one'))]
+bool(int(x.group('one')))*'十'+L_two[int(x.group('two'))])+'月'
+df['出生日'].apply(lambda x:x if len(x)==2 else '0'+x)\
.str.replace(r'(?P<one>[\d])(?P<two>\d?)',lambda x:L_one[int(x.group('one'))]
+bool(int(x.group('one')))*'十'+L_two[int(x.group('two'))])+'日')\
.to_frame().rename(columns={0:'ID'})
df_new.head()

- 将2中的ID列结果拆分为原列表相应的5列,并使用equals检验是否一致。
dic_year = {i[0]:i[1] for i in zip(list('零一二三四五六七八九'),list('0123456789'))}
dic_two = {i[0]:i[1] for i in zip(list('十一二三四五六七八九'),list('0123456789'))}
dic_one = {'十':'1','二十':'2','三十':'3',None:''}
df_res = df_new['ID'].str.extract(r'(?P<姓名>[a-zA-Z]+):(?P<国籍>[\d])国人,性别(?P<性别>[\w]),生于(?P<出生年>[\w]{4})年(?P<出生月>[\w]+)月(?P<出生日>[\w]+)日')
df_res['出生年'] = df_res['出生年'].str.replace(r'(\w)+',lambda x:''.join([dic_year[x.group(0)[i]] for i in range(4)]))
df_res['出生月'] = df_res['出生月'].str.replace(r'(?P<one>\w?十)?(?P<two>[\w])',lambda x:dic_one[x.group('one')]+dic_two[x.group('two')]).str.replace(r'0','10')
df_res['出生日'] = df_res['出生日'].str.replace(r'(?P<one>\w?十)?(?P<two>[\w])',lambda x:dic_one[x.group('one')]+dic_two[x.group('two')]).str.replace(r'^0','10')
df_res.head()
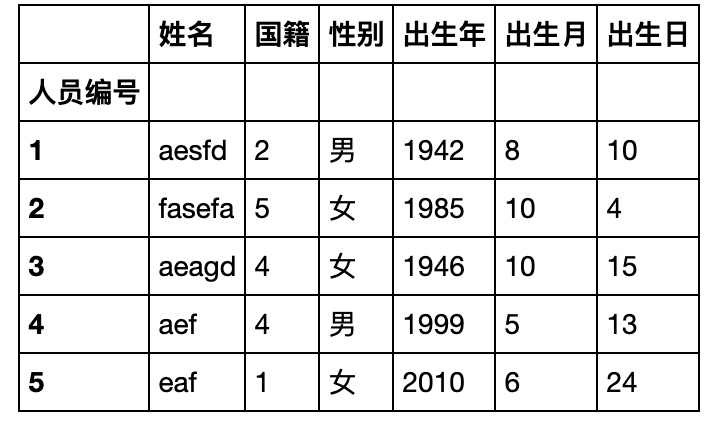
df_res.equals(df)
练习二
现有一份半虚拟的数据集,第一列包含了新型冠状病毒的一些新闻标题,请解决以下问题:
pd.read_csv('data/String_data_two.csv').head()
- 选出所有关于北京市和上海市新闻标题的所在行。
df[df['col1'].str.contains(r'[北京]{2}|[上海]{2}')].head()
- 求col2的均值。
#df['col2'].mean() #报错
df['col2'][~(df['col2'].str.replace(r'-?\d+','True')=='True')] #这三行有问题
309 0-
396 9`
485 /7
Name: col2, dtype: object
df.loc[[309,396,485],'col2'] = [0,9,7]
df['col2'].astype('int').mean()
-0.984
- 求col3的均值。
#df['col3'].mean() #报错
#df['col3'] #报错
df.columns
Index(['col1', 'col2', 'col3 '], dtype='object')
df.columns = df.columns.str.strip()
df.columns
Index(['col1', 'col2', 'col3'], dtype='object')
df['col3'].head()
0 363.6923
1 -152.281
2 325.6221
3 -204.9313
4 4.05
Name: col3, dtype: object
#df['col3'].mean() #报错
df['col3'][~(df['col3'].str.replace(r'-?\d+\.?\d+','True')=='True')]
28 355`.3567
37 -5
73 1
122 9056.\2253
332 3534.6554{
370 7
Name: col3, dtype: object
df.loc[[28,122,332],'col3'] = [355.3567,9056.2253, 3534.6554]
df['col3'].astype('float').mean()
24.707485
分类数据
import pandas as pd
import numpy as np
df = pd.read_csv('data/table.csv')
df.head()
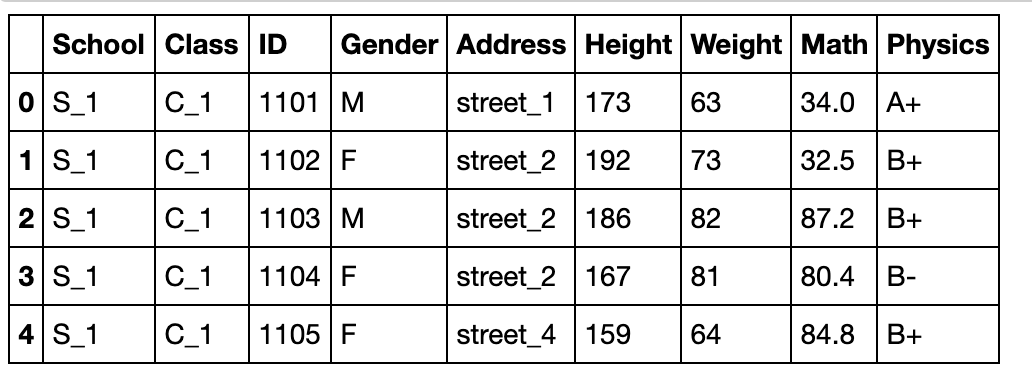
`category的创建及其性质
分类变量的创建
用Series创建
pd.Series(["a", "b", "c", "a"], dtype="category")
0 a
1 b
2 c
3 a
dtype: category
Categories (3, object): [a, b, c]
对DataFrame指定类型创建
temp_df = pd.DataFrame({'A':pd.Series(["a", "b", "c", "a"], dtype="category"),'B':list('abcd')})
temp_df.dtypes
A category
B object
dtype: object
利用内置Categorical类型创建
cat = pd.Categorical(["a", "b", "c", "a"], categories=['a','b','c'])
pd.Series(cat)
0 a
1 b
2 c
3 a
dtype: category
Categories (3, object): [a, b, c]
利用cut函数创建
默认使用区间类型为标签
pd.cut(np.random.randint(0,60,5), [0,10,30,60])
[(10, 30], (0, 10], (10, 30], (30, 60], (30, 60]]
Categories (3, interval[int64]): [(0, 10] < (10, 30] < (30, 60]]
可指定字符为标签
pd.cut(np.random.randint(0,60,5), [0,10,30,60], right=False, labels=['0-10','10-30','30-60'])
[10-30, 30-60, 30-60, 10-30, 30-60]
Categories (3, object): [0-10 < 10-30 < 30-60]
分类变量的结构
一个分类变量包括三个部分,元素值(values)、分类类别(categories)、是否有序(order)
从上面可以看出,使用cut函数创建的分类变量默认为有序分类变量
下面介绍如何获取或修改这些属性
describe方法
该方法描述了一个分类序列的情况,包括非缺失值个数、元素值类别数(不是分类类别数)、最多次出现的元素及其频数
s = pd.Series(pd.Categorical(["a", "b", "c", "a",np.nan], categories=['a','b','c','d']))
s.describe()
count 4
unique 3
top a
freq 2
dtype: object
categories和ordered属性
查看分类类别和是否排序
s.cat.categories
Index(['a', 'b', 'c', 'd'], dtype='object')
s.cat.ordered
False
类别的修改
利用set_categories修改
修改分类,但本身值不会变化
s = pd.Series(pd.Categorical(["a", "b", "c", "a",np.nan], categories=['a','b','c','d']))
s.cat.set_categories(['new_a','c'])
0 NaN
1 NaN
2 c
3 NaN
4 NaN
dtype: category
Categories (2, object): [new_a, c]
利用rename_categories修改
需要注意的是该方法会把值和分类同时修改
s = pd.Series(pd.Categorical(["a", "b", "c", "a",np.nan], categories=['a','b','c','d']))
s.cat.rename_categories(['new_%s'%i for i in s.cat.categories])
0 new_a
1 new_b
2 new_c
3 new_a
4 NaN
dtype: category
Categories (4, object): [new_a, new_b, new_c, new_d]
利用字典修改值
s.cat.rename_categories({'a':'new_a','b':'new_b'})
0 new_a
1 new_b
2 c
3 new_a
4 NaN
dtype: category
Categories (4, object): [new_a, new_b, c, d]
利用add_categories添加
s = pd.Series(pd.Categorical(["a", "b", "c", "a",np.nan], categories=['a','b','c','d']))
s.cat.add_categories(['e'])
0 a
1 b
2 c
3 a
4 NaN
dtype: category
Categories (5, object): [a, b, c, d, e]
利用remove_categories移除
s = pd.Series(pd.Categorical(["a", "b", "c", "a",np.nan], categories=['a','b','c','d']))
s.cat.remove_categories(['d'])
0 a
1 b
2 c
3 a
4 NaN
dtype: category
Categories (3, object): [a, b, c]
删除元素值未出现的分类类型
s = pd.Series(pd.Categorical(["a", "b", "c", "a",np.nan], categories=['a','b','c','d']))
s.cat.remove_unused_categories()
0 a
1 b
2 c
3 a
4 NaN
dtype: category
Categories (3, object): [a, b, c]
分类变量的排序
前面提到,分类数据类型被分为有序和无序,这非常好理解,例如分数区间的高低是有序变量,考试科目的类别一般看做无序变量
序的建立
一般来说会将一个序列转为有序变量,可以利用as_ordered方法
s = pd.Series(["a", "d", "c", "a"]).astype('category').cat.as_ordered()
s
0 a
1 d
2 c
3 a
dtype: category
Categories (3, object): [a < c < d]
退化为无序变量,只需要使用as_unordered
s.cat.as_unordered()
0 a
1 d
2 c
3 a
dtype: category
Categories (3, object): [a, c, d]
利用set_categories方法中的order参数
pd.Series(["a", "d", "c", "a"]).astype('category').cat.set_categories(['a','c','d'],ordered=True)
0 a
1 d
2 c
3 a
dtype: category
Categories (3, object): [a < c < d]
利用reorder_categories方法
这个方法的特点在于,新设置的分类必须与原分类为同一集合
s = pd.Series(["a", "d", "c", "a"]).astype('category')
s.cat.reorder_categories(['a','c','d'],ordered=True)
0 a
1 d
2 c
3 a
dtype: category
Categories (3, object): [a < c < d]
#s.cat.reorder_categories(['a','c'],ordered=True) #报错
#s.cat.reorder_categories(['a','c','d','e'],ordered=True) #报错
排序
先前在第1章介绍的值排序和索引排序都是适用的
s = pd.Series(np.random.choice(['perfect','good','fair','bad','awful'],50)).astype('category')
s.cat.set_categories(['perfect','good','fair','bad','awful'][::-1],ordered=True).head()
0 good
1 fair
2 bad
3 perfect
4 perfect
dtype: category
Categories (5, object): [awful < bad < fair < good < perfect]
s.sort_values(ascending=False).head()
29 perfect
17 perfect
31 perfect
3 perfect
4 perfect
dtype: category
Categories (5, object): [awful, bad, fair, good, perfect]
df_sort = pd.DataFrame({'cat':s.values,'value':np.random.randn(50)}).set_index('cat')
df_sort.head()
value
cat
good -1.746975
fair 0.836732
bad 0.094912
perfect -0.724338
perfect -1.456362
df_sort.sort_index().head()
value
cat
awful 0.245782
awful 0.063991
awful 1.541862
awful -0.062976
awful 0.472542
分类变量的比较操作
与标量或等长序列的比较
标量比较
s = pd.Series(["a", "d", "c", "a"]).astype('category')
s == 'a'
0 True
1 False
2 False
3 True
dtype: bool
等长序列比较
s == list('abcd')
0 True
1 False
2 True
3 False
dtype: bool
与另一分类变量的比较
等式判别(包含等号和不等号)
两个分类变量的等式判别需要满足分类完全相同
s = pd.Series(["a", "d", "c", "a"]).astype('category')
s == s
0 True
1 True
2 True
3 True
dtype: bool
s != s
0 False
1 False
2 False
3 False
dtype: bool
s_new = s.cat.set_categories(['a','d','e'])
#s == s_new #报错
不等式判别(包含>=,<=,<,>)
两个分类变量的不等式判别需要满足两个条件:
- 分类完全相同
- 排序完全相同
s = pd.Series(["a", "d", "c", "a"]).astype('category')
#s >= s #报错
s = pd.Series(["a", "d", "c", "a"]).astype('category').cat.reorder_categories(['a','c','d'],ordered=True)
s >= s
0 True
1 True
2 True
3 True
dtype: bool
练习
练习一
现继续使用第四章中的地震数据集,请解决以下问题:
pd.read_csv('data/Earthquake.csv').head()
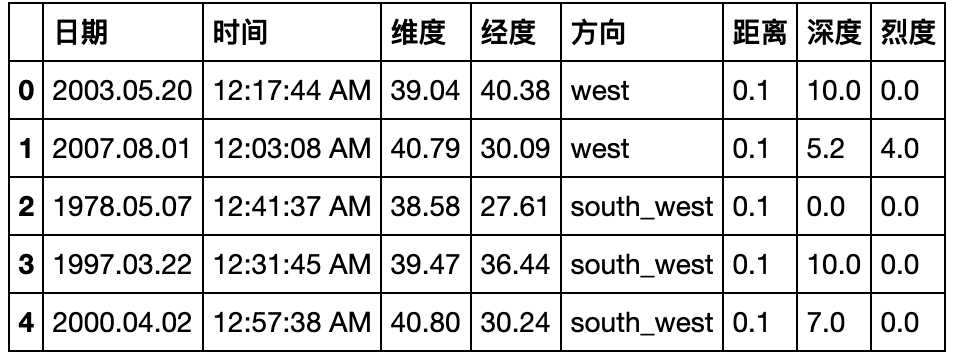
- 现在将深度分为七个等级:[0,5,10,15,20,30,50,np.inf],请以深度等级Ⅰ,Ⅱ,Ⅲ,Ⅳ,Ⅴ,Ⅵ,Ⅶ为索引并按照由浅到深的顺序进行排序。
df_a = df.copy()
df_a['深度'] = pd.cut(df_a['深度'], [-1e-10,5,10,15,20,30,50,np.inf],labels=['Ⅰ','Ⅱ','Ⅲ','Ⅳ','Ⅴ','Ⅵ','Ⅶ'])
df_a.set_index('深度').sort_index().head()
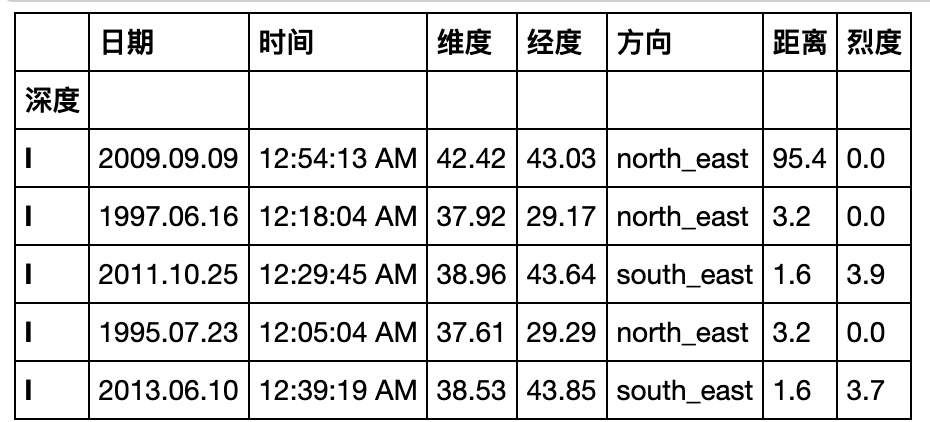
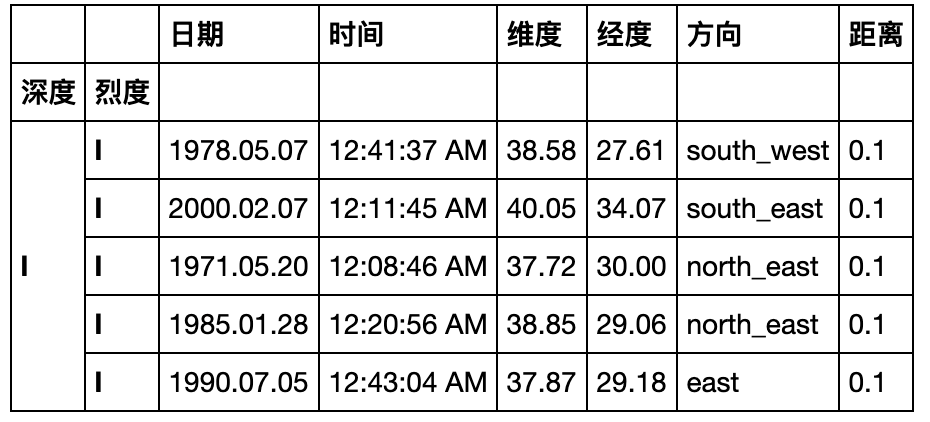
- 在1的基础上,将烈度分为4个等级:[0,3,4,5,np.inf],依次对南部地区的深度和烈度等级建立多级索引排序。
df_a['烈度'] = pd.cut(df_a['烈度'], [-1e-10,3,4,5,np.inf],labels=['Ⅰ','Ⅱ','Ⅲ','Ⅳ'])
df_a.set_index(['深度','烈度']).sort_index().head()
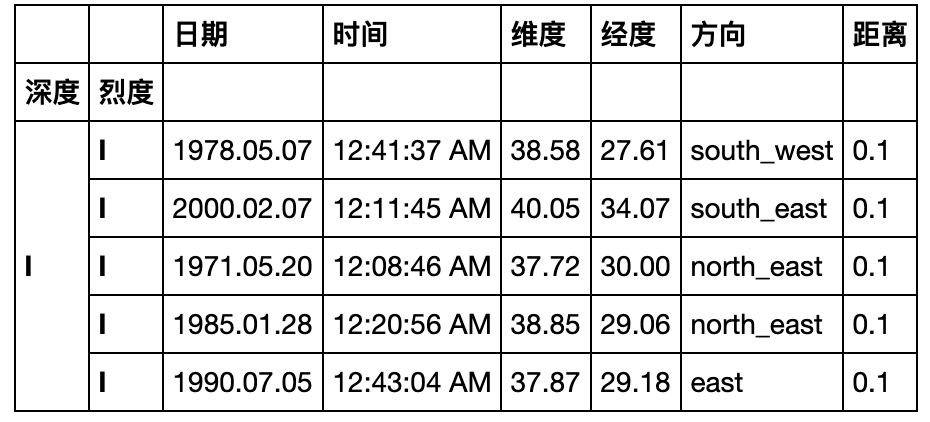
时序数据
时序的创建
四类时间变量

时间点的创建
to_datetime方法
Pandas在时间点建立的输入格式规定上给了很大的自由度,下面的语句都能正确建立同一时间点
pd.to_datetime('2020.1.1')
pd.to_datetime('2020 1.1')
pd.to_datetime('2020 1 1')
pd.to_datetime('2020 1-1')
pd.to_datetime('2020-1 1')
pd.to_datetime('2020-1-1')
pd.to_datetime('2020/1/1')
pd.to_datetime('1.1.2020')
pd.to_datetime('1.1 2020')
pd.to_datetime('1 1 2020')
pd.to_datetime('1 1-2020')
pd.to_datetime('1-1 2020')
pd.to_datetime('1-1-2020')
pd.to_datetime('1/1/2020')
pd.to_datetime('20200101')
pd.to_datetime('2020.0101')
Timestamp('2020-01-01 00:00:00')
下面的语句都会报错
#pd.to_datetime('2020\\1\\1')
#pd.to_datetime('2020`1`1')
#pd.to_datetime('2020.1 1')
#pd.to_datetime('1 1.2020')
此时可利用format参数强制匹配
pd.to_datetime('2020\\1\\1',format='%Y\\%m\\%d')
pd.to_datetime('2020`1`1',format='%Y`%m`%d')
pd.to_datetime('2020.1 1',format='%Y.%m %d')
pd.to_datetime('1 1.2020',format='%d %m.%Y')
Timestamp('2020-01-01 00:00:00')
同时,使用列表可以将其转为时间点索引
pd.Series(range(2),index=pd.to_datetime(['2020/1/1','2020/1/2']))
2020-01-01 0
2020-01-02 1
dtype: int64
type(pd.to_datetime(['2020/1/1','2020/1/2']))
pandas.core.indexes.datetimes.DatetimeIndex
对于DataFrame而言,如果列已经按照时间顺序排好,则利用to_datetime可自动转换
df = pd.DataFrame({'year': [2020, 2020],'month': [1, 1], 'day': [1, 2]})
pd.to_datetime(df)
0 2020-01-01
1 2020-01-02
dtype: datetime64[ns]
时间精度与范围限制
事实上,Timestamp的精度远远不止day,可以最小到纳秒ns
pd.to_datetime('2020/1/1 00:00:00.123456789')
Timestamp('2020-01-01 00:00:00.123456789')
同时,它带来范围的代价就是只有大约584年的时间点是可用的
pd.Timestamp.min
Timestamp('1677-09-21 00:12:43.145225')
pd.Timestamp.max
Timestamp('2262-04-11 23:47:16.854775807')
date_range方法
一般来说,start/end/periods(时间点个数)/freq(间隔方法)是该方法最重要的参数,给定了其中的3个,剩下的一个就会被确定
pd.date_range(start='2020/1/1',end='2020/1/10',periods=3)
DatetimeIndex(['2020-01-01 00:00:00', '2020-01-05 12:00:00',
'2020-01-10 00:00:00'],
dtype='datetime64[ns]', freq=None)
pd.date_range(start='2020/1/1',end='2020/1/10',freq='D')
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04',
'2020-01-05', '2020-01-06', '2020-01-07', '2020-01-08',
'2020-01-09', '2020-01-10'],
dtype='datetime64[ns]', freq='D')
pd.date_range(start='2020/1/1',periods=3,freq='D')
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03'], dtype='datetime64[ns]', freq='D')
pd.date_range(end='2020/1/3',periods=3,freq='D')
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03'], dtype='datetime64[ns]', freq='D')
其中freq参数有许多选项:

pd.date_range(start='2020/1/1',periods=3,freq='T')
DatetimeIndex(['2020-01-01 00:00:00', '2020-01-01 00:01:00',
'2020-01-01 00:02:00'],
dtype='datetime64[ns]', freq='T')
pd.date_range(start='2020/1/1',periods=3,freq='M')
DatetimeIndex(['2020-01-31', '2020-02-29', '2020-03-31'], dtype='datetime64[ns]', freq='M')
pd.date_range(start='2020/1/1',periods=3,freq='BYS')
DatetimeIndex(['2020-01-01', '2021-01-01', '2022-01-03'], dtype='datetime64[ns]', freq='BAS-JAN')
bdate_range是一个类似与date_range的方法,特点在于可以在自带的工作日间隔设置上,再选择weekmask参数和holidays参数
它的freq中有一个特殊的'C'/'CBM'/'CBMS'选项,表示定制,需要联合weekmask参数和holidays参数使用
例如现在需要将工作日中的周一、周二、周五3天保留,并将部分holidays剔除
weekmask = 'Mon Tue Fri'
holidays = [pd.Timestamp('2020/1/%s'%i) for i in range(7,13)]
#注意holidays
pd.bdate_range(start='2020-1-1',end='2020-1-15',freq='C',weekmask=weekmask,holidays=holidays)
DatetimeIndex(['2020-01-03', '2020-01-06', '2020-01-13', '2020-01-14'], dtype='datetime64[ns]', freq='C')
DateOffset对象
DataOffset与Timedelta的区别
Timedelta绝对时间差的特点指无论是冬令时还是夏令时,增减1day都只计算24小时
DataOffset相对时间差指,无论一天是23\24\25小时,增减1day都与当天相同的时间保持一致
例如,英国当地时间 2020年03月29日,01:00:00 时钟向前调整 1 小时 变为 2020年03月29日,02:00:00,开始夏令时
ts = pd.Timestamp('2020-3-29 01:00:00', tz='Europe/Helsinki')
ts + pd.Timedelta(days=1)
Timestamp('2020-03-30 02:00:00+0300', tz='Europe/Helsinki')
ts + pd.DateOffset(days=1)
Timestamp('2020-03-30 01:00:00+0300', tz='Europe/Helsinki')
这似乎有些令人头大,但只要把tz(time zone)去除就可以不用管它了,两者保持一致,除非要使用到时区变换
ts = pd.Timestamp('2020-3-29 01:00:00')
ts + pd.Timedelta(days=1)
Timestamp('2020-03-30 01:00:00')
ts + pd.DateOffset(days=1)
Timestamp('2020-03-30 01:00:00')
增减一段时间
DateOffset的可选参数包括years/months/weeks/days/hours/minutes/seconds
pd.Timestamp('2020-01-01') + pd.DateOffset(minutes=20) - pd.DateOffset(weeks=2)
Timestamp('2019-12-18 00:20:00')
各类常用offset对象

pd.Timestamp('2020-01-01') + pd.offsets.Week(2)
Timestamp('2020-01-15 00:00:00')
pd.Timestamp('2020-01-01') + pd.offsets.BQuarterBegin(1)
Timestamp('2020-03-02 00:00:00')
序列的offset操作
利用apply函数
pd.Series(pd.offsets.BYearBegin(3).apply(i) for i in pd.date_range('20200101',periods=3,freq='Y'))
0 2023-01-02
1 2024-01-01
2 2025-01-01
dtype: datetime64[ns]
直接使用对象加减
pd.date_range('20200101',periods=3,freq='Y') + pd.offsets.BYearBegin(3)
DatetimeIndex(['2023-01-02', '2024-01-01', '2025-01-01'], dtype='datetime64[ns]', freq='A-DEC')
定制offset,可以指定weekmask和holidays参数(思考为什么三个都是一个值)
pd.Series(pd.offsets.CDay(3,weekmask='Wed Fri',holidays='2020010').apply(i)
for i in pd.date_range('20200105',periods=3,freq='D'))
0 2020-01-15
1 2020-01-15
2 2020-01-15
dtype: datetime64[ns]
时序的索引及属性
索引切片
rng = pd.date_range('2020','2021', freq='W')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts.head()
2020-01-05 1.513910
2020-01-12 0.921820
2020-01-19 -0.216364
2020-01-26 0.256636
2020-02-02 -1.318088
Freq: W-SUN, dtype: float64
ts['2020-01-26']
0.2566361282801419
合法字符自动转换为时间点
ts['2020-01-26':'20200726'].head()
2020-01-26 0.256636
2020-02-02 -1.318088
2020-02-09 -0.668092
2020-02-16 0.152675
2020-02-23 -1.163632
Freq: W-SUN, dtype: float64
子集索引
ts['2020-7'].head()
2020-07-05 0.756521
2020-07-12 0.170898
2020-07-19 -0.406184
2020-07-26 0.980721
Freq: W-SUN, dtype: float64
支持混合形态索引
ts['2011-1':'20200726'].head()
2020-01-05 1.513910
2020-01-12 0.921820
2020-01-19 -0.216364
2020-01-26 0.256636
2020-02-02 -1.318088
Freq: W-SUN, dtype: float64
时间点的属性
采用dt对象可以轻松获得关于时间的信息
pd.Series(ts.index).dt.week.head()
0 1
1 2
2 3
3 4
4 5
dtype: int64
pd.Series(ts.index).dt.day.head()
0 5
1 12
2 19
3 26
4 2
dtype: int64
利用strftime可重新修改时间格式
pd.Series(ts.index).dt.strftime('%Y-间隔1-%m-间隔2-%d').head()
0 2020-间隔1-01-间隔2-05
1 2020-间隔1-01-间隔2-12
2 2020-间隔1-01-间隔2-19
3 2020-间隔1-01-间隔2-26
4 2020-间隔1-02-间隔2-02
dtype: object
对于datetime对象可以直接通过属性获取信息
pd.date_range('2020','2021', freq='W').month
Int64Index([ 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4, 4,
5, 5, 5, 5, 5, 6, 6, 6, 6, 7, 7, 7, 7, 8, 8, 8, 8,
8, 9, 9, 9, 9, 10, 10, 10, 10, 11, 11, 11, 11, 11, 12, 12, 12,
12],
dtype='int64')
pd.date_range('2020','2021', freq='W').weekday
Int64Index([6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6,
6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6,
6, 6, 6, 6, 6, 6, 6, 6],
dtype='int64')
重采样
所谓重采样,就是指resample函数,它可以看做时序版本的groupby函数
resample对象的基本操作
采样频率一般设置为上面提到的offset字符
df_r = pd.DataFrame(np.random.randn(1000, 3),index=pd.date_range('1/1/2020', freq='S', periods=1000),
columns=['A', 'B', 'C'])
r = df_r.resample('3min')
r
<pandas.core.resample.DatetimeIndexResampler object at 0x7f0c0f89a7d0>
r.sum()
df_r2 = pd.DataFrame(np.random.randn(200, 3),index=pd.date_range('1/1/2020', freq='D', periods=200),
columns=['A', 'B', 'C'])
r = df_r2.resample('CBMS')
r.sum()
采样聚合
r = df_r.resample('3T')
r['A'].mean()
2020-01-01 00:00:00 0.050495
2020-01-01 00:03:00 0.021719
2020-01-01 00:06:00 -0.044430
2020-01-01 00:09:00 -0.015729
2020-01-01 00:12:00 -0.117970
2020-01-01 00:15:00 0.004193
Freq: 3T, Name: A, dtype: float64
r['A'].agg([np.sum, np.mean, np.std])
类似地,可以使用函数/lambda表达式
r.agg({'A': np.sum,'B': lambda x: max(x)-min(x)})
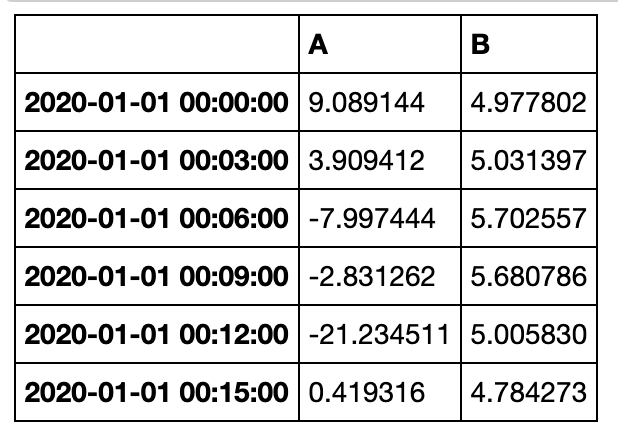
采样组的迭代
采样组的迭代和groupby迭代完全类似,对于每一个组都可以分别做相应操作
small = pd.Series(range(6),index=pd.to_datetime(['2020-01-01 00:00:00', '2020-01-01 00:30:00'
, '2020-01-01 00:31:00','2020-01-01 01:00:00'
,'2020-01-01 03:00:00','2020-01-01 03:05:00']))
resampled = small.resample('H')
for name, group in resampled:
print("Group: ", name)
print("-" * 27)
print(group, end="\n\n")
Group: 2020-01-01 00:00:00
---------------------------
2020-01-01 00:00:00 0
2020-01-01 00:30:00 1
2020-01-01 00:31:00 2
dtype: int64
Group: 2020-01-01 01:00:00
---------------------------
2020-01-01 01:00:00 3
dtype: int64
Group: 2020-01-01 02:00:00
---------------------------
Series([], dtype: int64)
Group: 2020-01-01 03:00:00
---------------------------
2020-01-01 03:00:00 4
2020-01-01 03:05:00 5
dtype: int64
窗口函数
下面主要介绍pandas中两类主要的窗口(window)函数:rolling/expanding
s = pd.Series(np.random.randn(1000),index=pd.date_range('1/1/2020', periods=1000))
s.head()
2020-01-01 0.659255
2020-01-02 -2.074411
2020-01-03 -1.354148
2020-01-04 -0.774753
2020-01-05 0.360106
Freq: D, dtype: float64
Rolling
常用聚合
所谓rolling方法,就是规定一个窗口,它和groupby对象一样,本身不会进行操作,需要配合聚合函数才能计算结果
s.rolling(window=50)
Rolling [window=50,center=False,axis=0]
s.rolling(window=50).mean()
2020-01-01 NaN
2020-01-02 NaN
2020-01-03 NaN
2020-01-04 NaN
2020-01-05 NaN
...
2022-09-22 0.044807
2022-09-23 0.071231
2022-09-24 0.098303
2022-09-25 0.110776
2022-09-26 0.085055
Freq: D, Length: 1000, dtype: float64
min_periods参数是指需要的非缺失数据点数量阀值
s.rolling(window=50,min_periods=3).mean().head()
2020-01-01 NaN
2020-01-02 NaN
2020-01-03 -0.923101
2020-01-04 -0.886014
2020-01-05 -0.636790
Freq: D, dtype: float64
count/sum/mean/median/min/max/std/var/skew/kurt/quantile/cov/corr都是常用的聚合函数
rolling的apply聚合
使用apply聚合时,只需记住传入的是window大小的Series,输出的必须是标量即可,比如如下计算变异系数
s.rolling(window=50,min_periods=3).apply(lambda x:x.std()/x.mean()).head()
2020-01-01 NaN
2020-01-02 NaN
2020-01-03 -1.534925
2020-01-04 -1.308402
2020-01-05 -1.803185
Freq: D, dtype: float64
基于时间的rolling
s.rolling('15D').mean().head()
2020-01-01 0.659255
2020-01-02 -0.707578
2020-01-03 -0.923101
2020-01-04 -0.886014
2020-01-05 -0.636790
Freq: D, dtype: float64
可选closed='right'(默认)`'left'\'both'\'neither'`参数,决定端点的包含情况
s.rolling('15D', closed='right').sum().head()
2020-01-01 0.659255
2020-01-02 -1.415156
2020-01-03 -2.769304
2020-01-04 -3.544057
2020-01-05 -3.183952
Freq: D, dtype: float64
Expanding
expanding函数
普通的expanding函数等价与rolling(window=len(s),min_periods=1),是对序列的累计计算
s.rolling(window=len(s),min_periods=1).sum().head()
2020-01-01 0.659255
2020-01-02 -1.415156
2020-01-03 -2.769304
2020-01-04 -3.544057
2020-01-05 -3.183952
Freq: D, dtype: float64
s.expanding().sum().head()
2020-01-01 0.659255
2020-01-02 -1.415156
2020-01-03 -2.769304
2020-01-04 -3.544057
2020-01-05 -3.183952
Freq: D, dtype: float64
apply方法也是同样可用的
s.expanding().apply(lambda x:sum(x)).head()
2020-01-01 0.659255
2020-01-02 -1.415156
2020-01-03 -2.769304
2020-01-04 -3.544057
2020-01-05 -3.183952
Freq: D, dtype: float64
几个特别的Expanding类型函数
cumsum/cumprod/cummax/cummin都是特殊expanding累计计算方法
s.cumsum().head()
2020-01-01 0.659255
2020-01-02 -1.415156
2020-01-03 -2.769304
2020-01-04 -3.544057
2020-01-05 -3.183952
Freq: D, dtype: float64
s.cumsum().head()
Out[59]:
2020-01-01 0.659255
2020-01-02 -1.415156
2020-01-03 -2.769304
2020-01-04 -3.544057
2020-01-05 -3.183952
Freq: D, dtype: float64
shift/diff/pct_change都是涉及到了元素关系
shift是指序列索引不变,但值向后移动diff是指前后元素的差,period参数表示间隔,默认为1,并且可以为负pct_change是值前后元素的变化百分比,period参数与diff类似
s.shift(2).head()
2020-01-01 NaN
2020-01-02 NaN
2020-01-03 0.659255
2020-01-04 -2.074411
2020-01-05 -1.354148
Freq: D, dtype: float64
s.diff(3).head()
Out[61]:
2020-01-01 NaN
2020-01-02 NaN
2020-01-03 NaN
2020-01-04 -1.434008
2020-01-05 2.434516
Freq: D, dtype: float64
s.pct_change(3).head()
2020-01-01 NaN
2020-01-02 NaN
2020-01-03 NaN
2020-01-04 -2.175196
2020-01-05 -1.173594
Freq: D, dtype: float64
速查
Series和DataFrame对象的创建
Series
Series是pandas中暴露给我们使用的基本对象,它是由相同元素类型构成的一维数据结构,同时具有列表和字典的属性,字典的属性由索引赋予。
Series:有序,有索引list: 有序,无索引dict: 无序,有索引
预览
data = [1,2,3]
index = ['a','b','c']
s = pd.Series(data=data, index=index, name = 'sss')
s
a 1
b 2
c 3
Name: sss, dtype: int64
s.index # 四个属性之一:索引
Index(['a', 'b', 'c'], dtype='object')
s.name # 四个属性之二:名字,
'sss'
s.values # 四个属性之三:值
array([1, 2, 3], dtype=int64)
s.dtype # 四个属性之四:元素类型
dtype('int64')
创建
pd.Series(data=None, index=None, name = None)
data:多种类型,见下面具体介绍;index:索引信息;name:对data的说明,用的不多,一般在和DataFrame、Index互相转换时才需要。
data无索引
如果 data 为 ndarray(1D) 或 list(1D),那么其缺少 Series 需要的索引信息;
如果提供 index,则必须和data长度相同;
如果不提供 index,那么其将生成默认数值索引 range(0, data.shape[0])。
# data = [1,2,3]
data1 = np.array([1,2,3])
index1 = ['a','b','c']
s = pd.Series(data = data1, index = index1)
s
a 1
b 2
c 3
dtype: int32
data有索引
如果 data 为 Series 或 dict ,那么其已经提供了 Series 需要的索引信息,所以 index 项是不需要提供的;
如果额外提供了 index 项,那么其将对当前构建的Series进行 重索引(增删)(等同于reindex操作)。
# data = pd.Series([a,b,c], index = ['a','b','c'] )
data2 = { 'a':1, 'b':2,'c':3 }
index2 = ['a','b','d']
s = pd.Series(data = data2, index = index2)
s
a 1.0
b 2.0
d NaN
dtype: float64
如上,index项用于从当前已有索引中匹配出相同的行,如果当前索引缺失给定的索引,则填充NaN(NaN:not a number为pandas缺失值标记)。
DataFrame
DataFrame由具有共同索引的Series按列排列构成(2D),是使用最多的对象。
预览
data = [[1,2,3],
[4,5,6]]
index = ['a','b']
columns = ['A','B','C']
df = pd.DataFrame(data=data, index = index, columns = columns)
df
A B C
a 1 2 3
b 4 5 6
df.index # 行索引
Index(['a', 'b'], dtype='object')
df.columns # 列索引,由Series的name构成
Index(['A', 'B', 'C'], dtype='object')
df.values
array([[1, 2, 3],
[4, 5, 6]], dtype=int64)
df.dtypes # 这里的dtype带s,查看每列元素类型
A int64
B int64
C int64
dtype: object
创建
pd.DataFrame(data=None, index=None, columns=None)
函数有多个参数,对我们有用的主要是:data,index和columns三项
data无 行索引,无 列索引
如果 data 为 ndarray(2D) or list(2D),那么其缺少 DataFrame 需要的行、列索引信息;
如果提供 index 或 columns 项,其必须和data的行 或 列长度相同;
如果不提供 index 或 columns 项,那么其将默认生成数值索引range(0, data.shape[0])) 或 range(0, data.shape[1])。
# data = [[1,2,3],
# [4,5,6]]
data1 = np.array([[1,2,3],
[4,5,6]] )
index1 = ['a','b']
columns1 = ['A','B','C']
df = pd.DataFrame(data=data1, index = index1, columns = columns1)
df
A B C
a 1 2 3
b 4 5 6
data无 行索引,有 列索引
如果data为 dict of (ndarray(1D) or list(1D)),所有ndarray或list的长度必须相同。dict的key为DataFrame提供了需要的columns信息,缺失index;
如果提供 index 项,必须和list的长度相同;
如果不提供 index,那么其将默认生成数值索引range(0, data.shape[0]));
如果还额外提供了columns项,那么其将对当前构建的DataFrame进行 列重索引。
data2 = { 'A' : [1,4], 'B': [2,5], 'C':[3,6] }
index2 = ['a','b']
columns2 = ['A','B','D']
df = pd.DataFrame(data=data2, index = index2, columns = columns2)
df
A B D
a 1 2 NaN
b 4 5 NaN
data有 行索引,有 列索引
如果data为 dict of (Series or dict),那么其已经提供了DataFrame需要的所有信息;
如果多个Series或dict间的索引不一致,那么取并操作(pandas不会试图丢掉信息),缺失的数据填充NaN;
如果提供了index项或columns项,那么其将对当前构建的DataFrame进行 重索引(reindex,pandas内部调用接口)。
# data3 = { 'A' : pd.Series([1,4] ,index = ['a','b']), 'B' : pd.Series([2,5] ,index = ['a','b']), 'C' : pd.Series([3,6] ,index = ['a','c']) }
data3 = { 'A' : { 'a':1, 'b':4}, 'B': {'a':2,'b':5}, 'C':{'a':3, 'c':6} }
df = pd.DataFrame(data=data3)
df
A B C
a 1.0 2.0 3.0
b 4.0 5.0 NaN
c NaN NaN 6.0
由文件创建
由.csv文件创建
pd.read_csv(filepath_or_buffer, sep=',', header='infer', names=None,index_col=None, encoding=None )
read_csv的参数很多,但这几个参数就够我们使用了:
filepath_or_buffer:路径和文件名不要带中文,带中文容易报错。sep:csv文件数据的分隔符,默认是',',根据实际情况修改;header:如果有列名,那么这一项不用改;names:如果没有列名,那么必须设置header = None,names为需要传入的列名列表,不设置默认生成数值索引;index_col:list of (int or name),传入列名的列表或者列名的位置,选取这几列作为索引;encoding:根据你的文档编码来确定,如果有中文读取报错,试试encoding = 'gbk'。
tips = pd.read_csv( 'tips.csv')
tips.head()
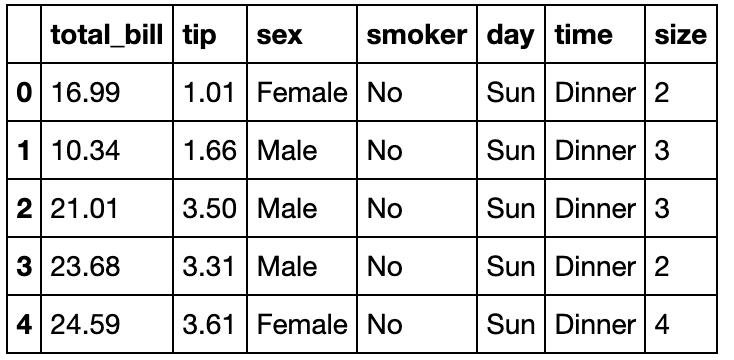
tips.index
RangeIndex(start=0, stop=244, step=1)
tips.columns
Index(['total_bill', 'tip', 'sex', 'smoker', 'day', 'time', 'size'], dtype='object')
tips.values
array([[16.99, 1.01, 'Female', ..., 'Sun', 'Dinner', 2],
[10.34, 1.66, 'Male', ..., 'Sun', 'Dinner', 3],
[21.01, 3.5, 'Male', ..., 'Sun', 'Dinner', 3],
...,
[22.67, 2.0, 'Male', ..., 'Sat', 'Dinner', 2],
[17.82, 1.75, 'Male', ..., 'Sat', 'Dinner', 2],
[18.78, 3.0, 'Female', ..., 'Thur', 'Dinner', 2]], dtype=object)
Series和DataFrame对象的查、改、增、 删
Series
查
data = [1,2,3]
index = ['a','b','c']
s = pd.Series(data=data, index=index)
s
a 1
b 2
c 3
dtype: int64
[],快捷查看
s[1] # scalar, 返回一个值
2
s[0:2] # 范围,左闭右开,返回Series切片
a 1
b 2
dtype: int64
s[[0,2]] #列表,返回Series切片
a 1
c 3
dtype: int64
mask = [False,True,False] #mask,类似于列表,只是长度必须和Series相同,返回Series切片
s[mask]
b 2
dtype: int64
.loc[],基于索引
.loc[]查询方式和[]完全一致。
s.loc['b'] # 单索引,返回一个值
2
s.loc['a':'c'] # 范围,注意:左闭右闭,返回Series切片
a 1
b 2
c 3
dtype: int64
s.loc[['a','c']] # 列表,返回Series切片
a 1
c 3
dtype: int64
mask = [False, True, False] # mask,和iloc[]效果等同,返回Series切片
s.loc[mask]
b 2
dtype: int64
.iloc[],基于位置
无视索引,只按照位置定位。
s.iloc[1] # scalar, 返回一个值
2
s.iloc[0:2] # 范围,左闭右开,返回Series切片
a 1
b 2
dtype: int64
s.iloc[[0,2]] #列表,返回Series切片
a 1
c 3
dtype: int64
mask = [False,True,False] #mask,类似于列表,只是长度必须和Series相同,返回Series切片
s.iloc[mask]
b 2
dtype: int64
改
改值
直接在查的基础上赋值,就可以修改
注意:如果要修改,使用.loc可以确保修改成功,其他方式可能会在临时创建的view上修改。
s1 = s.copy()
s1.loc['a'] = 10 #
s1
a 10
b 2
c 3
dtype: int64
s1.loc['a':'c'] = [10,4,5]
s1
a 10
b 4
c 5
dtype: int32
函数修改:Series.replace(to_replace=None, value=None, inplace=False)
to_replace:要修改的值,可以为列表;value:改为的值,可以为列表,与to_repalce要匹配;inplace:是否在原地修改;
s1.replace(to_replace = 10, value = 100, inplace=False)
a 100
b 4
c 5
dtype: int32
改索引
直接在index上改,index类似于tuple,只能引用到别处,不能切片修改
s1 = s.copy()
s1.index = ['a','e','f']
s1
a 1
e 2
f 3
dtype: int64
函数修改:Series.rename(index=None, level = None, inplace = False)
index:list or dict,list类型时必须和已有索引长度相同,dict类型可以部分修改;level:多重索引时,可以指定修改哪一重,从0开始递增;inplace:是否原地修改。
s1.rename(index = {'e':'b'}, inplace = False)
a 1
b 2
f 3
dtype: int64
增
直接增一行
s1 = s.copy()
s1.loc['d'] = 4
s1
a 1
b 2
c 3
d 4
dtype: int64
函数增多行
Series.append(to_append, ignore_index=False, verify_integrity=False)
to_append: 另一个series或多个Series构成的列表;ignore_index:False-保留原有索引,True-清除所有索引,生成默认数值索引;verify_integrity:True的情况下,如果to_append索引与当前索引有重复,则报错。
s1 = pd.Series([22,33], index = ['a', 'g'])
s.append(s1, ignore_index=False)
a 1
b 2
c 3
a 22
g 33
dtype: int64
删
直接删一行
#不建议使用
s1 = s.copy()
del s1['c']
s1
a 1
b 2
dtype: int64
函数删多行
Series.drop(labels, level=None, inplace=False)
labels:索引,单索引或索引的列表;level:多重索引需要设置;inplace:是否本地修改。
s1 = s.copy()
s1.drop(['a','c'])
b 2
dtype: int64
DataFrame
data = [[1,2,3],
[4,5,6]]
index = ['a','b']
columns = ['A','B','C']
df = pd.DataFrame(data=data, index=index, columns = columns)
df
A B C
a 1 2 3
b 4 5 6
查
[],快捷查看
[] 属于快捷查看方式,只包含下面四种,两种列操作、两种行操作。
df['A'] # 列操作,单列索引,返回Series
a 1
b 4
Name: A, dtype: int64
df[['A','C']] # 列操作,列索引列表,返回DataFrame
A C
a 1 3
b 4 6
# df[0] # 报错,0不是列名
df[0:1] # 行操作,位置范围,返回DataFrame
A B C
a 1 2 3
# df[[0,1]] #报错,不能这样使用
mask = [False,True]
df[mask] # 行操作,mask,必须和行长度一致,返回DataFrame
A B C
b 4 5 6
.loc[],基于索引
.loc[]在DataFrame中与[]不一致。
DataFrame 有两维,每一维都和 Series 的 .loc[] 用法相同;
Series有四种方式,所以DataFrame有16种方式;
可以缺省后面维度,默认补全为 ':' 。
下面都以第一维度为例,第二维可以类比。
df.loc['b','B'] # 返回单一值,因为两维都是单索引
5
df.loc['a':'b', 'B'] #返回Series,如果只有一维是单索引
a 2
b 5
Name: B, dtype: int64
df.loc[['a','b'],'B'] #返回Series,如果只有一维是单索引
a 2
b 5
Name: B, dtype: int64
mask1 = [False, True, False]
df.loc[mask1,'B']
b 5
Name: B, dtype: int64
.iloc[],基于位置
无视索引,只按照位置定位。
DataFrame 有两维,每一维都和 Series 的 .iloc[] 用法相同;
Series有四种方式,所以DataFrame有16种方式;
可以缺省后面维度,默认补全为 ':' 。
下面都以第一维度为例,第二维可以类比。
df.iloc[1,1] # 返回单一值,因为两维都是scalar
5
df.iloc[0:2,0] # 返回Series,如果只有一维是scalar
a 1
b 4
Name: A, dtype: int64
df.iloc[[0,1],[0,2]] # 返回DataFrame
A C
a 1 3
b 4 6
mask1 = [False, True, False] # 返回DataFrame
mask2 =[True,False]
df.iloc[mask1,mask2]
A
b 4
改
改值
在查的基础上赋值进行修改,.loc[]方法确保在原地修改。
#修改单值
df1 = df.copy()
df1.loc['a','A'] = 10
df1
A B C
a 10 2 3
b 4 5 6
#修改单列
df1.loc[:, 'A'] = [100,200]
df1
A B C
a 100 2 3
b 200 5 6
#修改多列
df1.loc[:, ['A','B']] = [[1,2],[3,4]]
df1
A B C
a 1 2 3
b 3 4 6
#修改行,见下面的增减操作
函数批量任意修改:
DataFrame.replace(to_replace=None, value=None, inplace=False)
to_replace:要修改的值,可以为列表;value:改为的值,可以为列表,与to_repalce要匹配;inplace:是否在原地修改;
df1.replace(to_replace = 10, value = 100, inplace=False)
A B C
a 1 2 3
b 3 4 6
改索引
直接在索引上改,索引类似于tuple,必须全改,不能切片修改
df1 = df.copy()
df1.index = ['e','f']
df1.columns = ['E','F','G']
df1
E F G
e 1 2 3
f 4 5 6
函数修改:
DataFrame.rename(index=None, columns = None, level = None, inplace = False)
index:list or dict,list类型时必须长度相同,dict类型时可以部分修改;columns:list or dict,list时必须长度相同,dict时可以部分修改;level:多重索引时,可以指定修改哪一重,目前还用不着;inplace:是否原地修改。
df1.rename( index = {'e':'b'},columns = {'E':'A'}, inplace = False)
A F G
b 1 2 3
f 4 5 6
增
直接增一行
df1 = df.copy()
df1.loc['c'] = [7,8,9]
df1
A B C
a 1 2 3
b 4 5 6
c 7 8 9
函数增多行
pd.concat(objs, axis=0)
确保 列索引 相同,行增加。 (其实这个函数并不要求列索引相同,它可以选择出相同的列。而我写这个教程遵循了python的宣言—明确:做好一件事有一种最好的方法,精确控制每一步,可以少犯错。)
objs:list of DataFrame;axis: 取0,行增加操作。
df1 = pd.DataFrame([[22,33,44],[55,66,77]], index = ['c','d'],columns = ['A','B','C'])
pd.concat([df,df1], axis = 0 )
A B C
a 1 2 3
b 4 5 6
c 22 33 44
d 55 66 77
直接增一列
df1 = df.copy()
df1['H'] = [7,8]
df1
A B C H
a 1 2 3 7
b 4 5 6 8
函数增多列
pd.concat(objs, axis=1)
确保行索引相同,列增加
objs:list of DataFrame;axis: 取1,列增加操作。
df1 = pd.DataFrame([[22,33],[44,55]], index = ['a','b'],columns = ['D','E'])
pd.concat([df,df1], axis =1)
A B C D E
a 1 2 3 22 33
b 4 5 6 44 55
删
函数删多行
DataFrame.drop(labels, axis = 0, level=None, inplace=False)
labels:索引,单索引或索引的列表;axis:0,删行;level:多重索引需要指定;inplace:是否本地修改。
df1 = df.copy()
df1.drop(['a'],axis =0 )
A B C
b 4 5 6
直接删一列
#不建议使用
df1 = df.copy()
del df1['A']
df1
B C
a 2 3
b 5 6
函数删多列
DataFrame.drop(labels, axis = 1, level=None, inplace=False)
labels:索引,单索引或索引的列表;axis:1,删列;level:多重索引需要指定;inplace:是否本地修改。
df1 = df.copy()
df1.drop(['A','C'],axis =1 )
B
a 2
b 5
merge详解
函数说明
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort = False)
concat函数本质上是在所有索引上同时进行对齐合并,而如果想在任意列上对齐合并,则需要merge函数,其在sql应用很多。
left,right: 两个要对齐合并的DataFrame;how: 先做笛卡尔积操作,然后按照要求,保留需要的,缺失的数据填充NaN;left: 以左DataFrame为基准,即左侧DataFrame的数据全部保留(不代表完全一致、可能会存在复制),保持原序;right: 以右DataFrame为基准,保持原序;inner: 交,保留左右DataFrame在on上完全一致的行,保持左DataFrame顺序;outer: 并,按照字典顺序重新排序;
on:对应列名或者行索引的名字,如果要在DataFrame相同的列索引做对齐,用这个参数;left_on,right_on,left_index,right_index:on对应列名或者行索引的名字(所以行索引一般要跟列一样看待,有自己的名字),用这俩参数;DataFrame中用作连接键的列名;这个参数中左右列名不相同,但代表的含义相同时非常有用。index对应要使用的index,不建议使用,会搞晕。使用DataFrame中的行索引做为连接键,用到这个参数时,就有点类似于JOIN函数了
sort:TrueorFalse,是否按字典序重新排序。
df1 = pd.DataFrame([[1,2],[3,4]], index = ['a','b'],columns = ['A','B'])
df2 = pd.DataFrame([[1,3],[4,8]], index = ['b','d'],columns = ['B','C'])
df1
A B
a 1 2
b 3 4
df2
B C
b 1 3
d 4 8
如果单纯的按照index对齐,不如用concat方法。
pd.merge(left = df1, right = df2, how = 'inner' ,left_index = True, right_index = True)
A B_x B_y C
b 3 4 1 3
#小区别是concat对重复列没有重命名,但是重名的情况不多,而且重名了说明之前设计就不大合理。
pd.concat([df1,df2], join = 'inner',axis =1)
A B B C
b 3 4 1 3
on 用法
设置 how = 'inner'
#对于'B'列:df1的'b'行、df2的'd'行,是相同的,其他都不同。
pd.merge(left = df1, right = df2, how = 'inner' , on =['B'])
A B C
0 3 4 8
# df1的'A'列'b'行,df2的'C'列'd'行是相同的,其他都不同。
# 其他列如果同名会进行重命名。
pd.merge(left = df1, right = df2, how = 'inner',left_on = ['A'] ,right_on = ['C'])
A B_x B_y C
0 3 4 1 3
how 用法
#保持左侧DataFrame不变,用右侧来跟它对齐,对不上的填NaN。
pd.merge(left = df1, right = df2, how = 'left', on = ['B'] )
A B C
0 1 2 NaN
1 3 4 8.0
# 保持右侧DataFrame不变,用右侧来跟它对齐,对不上的填NaN。
pd.merge(left = df1, right = df2, how = 'right', on = ['B'] )
A B C
0 3.0 4 8
1 NaN 1 3
对齐的列存在重复值
重复的也没关系,操作逻辑是一致的,完全可以假想不存在重复。
df1.loc['a','B'] =4 #改成重复
df1
A B
a 1 4
b 3 4
### 保持右侧的列都在,如果左侧对齐的列存在重复值,那么对齐上后也存在重复。
pd.merge(left = df1, right = df2, how = 'right', on = ['B'] )
A B C
0 1.0 4 8
1 3.0 4 8
2 NaN 1 3
Index对象的创建,查、改、增、删和使用
- 索引类似于元组,其本身是不能赋值修改的;
- 其在数据进行整体运算时,辅助自动对齐,这是pandas不同于其他数据处理库的一大特征;
- 多层索引可以帮助改变表的形态,如透视表等。
单层索引
创建
pd.Index(data, dtype = Object, name = None)
name:一维列表dtype:索引元素的类型,默认为object型name:索引的名字,类似于列的名字
data = ['a','b','c']
index = pd.Index(data, name = 'name1')
index
Index(['a', 'b', 'c'], dtype='object', name='name1')
从返回值可以看到,index由三部分组成,可以分别查看。
index.name
'name1'
index.values
array(['a', 'b', 'c'], dtype=object)
index.dtype
dtype('O')
查
查询方式和一维ndarray或Series的.iloc[]完全一样。
index[0] # scalar,返回值
'a'
index[0:2] # 范围,返回index
Index(['a', 'b'], dtype='object', name='name1')
index[[0,2]] # 列表,返回index
Index(['a', 'c'], dtype='object', name='name1')
mask = [True,False,True] # mask,返回index
index[mask]
Index(['a', 'c'], dtype='object', name='name1')
改索引名
虽然索引的值是不能修改的,但是名字确是可以修改的。
直接改
index.name = 'new_name'
index
Index(['a', 'b', 'c'], dtype='object', name='new_name')
函数改
Index.set_names(names, inplace=False)
names:要设置的名字,可以为名字的列表;inplace:是否原地修改。
index.set_names('new_name')
Index(['a', 'b', 'c'], dtype='object', name='new_name')
增
按位置添加一行
Index.insert(loc, value)
loc:位置编号value:值
index
Index(['a', 'b', 'c'], dtype='object', name='new_name')
index.insert(1,'d')
Index(['a', 'd', 'b', 'c'], dtype='object', name='new_name')
尾部添加多行
Index.append(other)
other:其他索引对象
index1 = index.copy()
index1
Index(['a', 'b', 'c'], dtype='object', name='new_name')
index1.append( index)
Index(['a', 'b', 'c', 'a', 'b', 'c'], dtype='object', name='new_name')
并
Index.union(other)
index2 = pd.Index(['b','c','d'])
index2
Index(['b', 'c', 'd'], dtype='object')
index1.union(index2)
Index(['a', 'b', 'c', 'd'], dtype='object')
删
按位置删除一行
Index.delete(loc)
loc:位置编号
index1.delete(1)
Index(['a', 'c'], dtype='object', name='new_name')
交
Index.intersection(other)
index1.intersection(index2)
Index(['b', 'c'], dtype='object')
多层索引
创建
pd.MultiIndex.from_tuples(labels, names = None)
labels:元组或列表的列表;names:名字的列表。
# data = [['a','one'],['a','two'],['b','one']]
data = [('a','one'),('a','two'),('b','one')]
index = pd.MultiIndex.from_tuples( data, names = ['name1','name2'])
index
MultiIndex(levels=[['a', 'b'], ['one', 'two']],
labels=[[0, 0, 1], [0, 1, 0]],
names=['name1', 'name2'])
s = pd.Series([1,2,3], index = index)
s
name1 name2
a one 1
two 2
b one 3
dtype: int64
查
查询方法和单层索引完全一致。
index[0] # scalar,返回值
('a', 'one')
index[0:2] # 范围,返回MultiIndex
MultiIndex(levels=[['a', 'b'], ['one', 'two']],
labels=[[0, 0], [0, 1]],
names=['name1', 'name2'])
index[[0,2]] # 列表,返回MultiIndex
MultiIndex(levels=[['a', 'b'], ['one', 'two']],
labels=[[0, 1], [0, 0]],
names=['name1', 'name2'])
mask = [True,False, True] # mask,返回MultiIndex
index[mask]
MultiIndex(levels=[['a', 'b'], ['one', 'two']],
labels=[[0, 1], [0, 0]],
names=['name1', 'name2'])
获取某一层索引:
MultiIndex.get_level_values(level)
level:int,选中的那一层
index.get_level_values(0)
Index(['a', 'a', 'b'], dtype='object', name='name1')
index.get_level_values(1)
Index(['one', 'two', 'one'], dtype='object', name='name2')
改
改索引名(函数改)
MultiIndex.set_names(names, level=None, inplace=False)
names:要设置的名字,可以为名字的列表;level:多层索引需要设置修改的索引层次,可以为列表,要与names匹配;inplace:是否原地修改。
index.set_names('new_name_1',level=0)
MultiIndex(levels=[['a', 'b'], ['one', 'two']],
labels=[[0, 0, 1], [0, 1, 0]],
names=['new_name_1', 'name2'])
改索引层次顺序
MultiIndex.swaplevel(i=-2, j=-1)
改变`level i 和level j的次序
index.swaplevel()
MultiIndex(levels=[['one', 'two'], ['a', 'b']],
labels=[[0, 1, 0], [0, 0, 1]],
names=['name2', 'name1'])
Series.swaplevel(i=-2, j=-1)
DataFrame.swaplevel(i=-2, j=-1, axis = 1)
axis:0-行索引,1-列索引。 这两个函数更实用一些。
s.swaplevel()
name2 name1
one a 1
two a 2
one b 3
dtype: int64
columns = index.copy()
columns.set_names( names = ['name3','name4'], level = [0,1], inplace = True) #列索引取和行索引相同,只是改了名字
df = pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]], index= index, columns = columns)
df

df.swaplevel( axis =1) # 交换列索引顺序
多层索引使用方法
对values进行查看时,多层索引可以分开使用。
df1 = df.copy()
df1
索引为空不代表缺失,缺省写法,意思是之前的索引一致。
对于外层索引
记住:无论是Series还是DataFrame,外层索引都是可以直接使用,也就是说可以认为只有这一层索引
[]
df1['b'] # 列外层

df1[['a','b']] # 列外层
df1[0:2] # 行外层
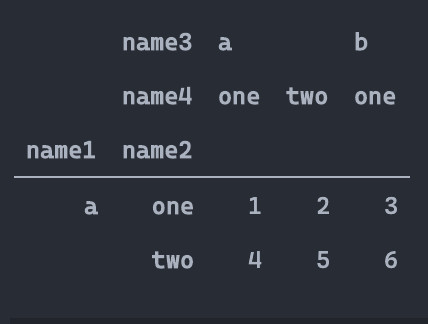
mask =[True,False,True] # 行外层
df1[mask]

.loc[]
df1.loc['a','b'] # 单行索引'a'
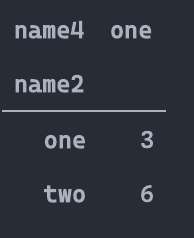
df1.loc['a':'b','b'] #范围
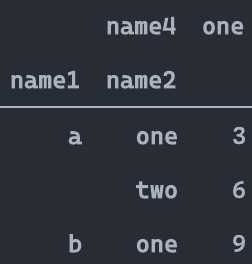
df1.loc[['a','b'],'b'] #列表
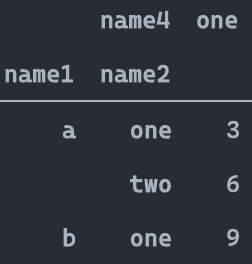
mask = [True, False, True] # mask
df1.loc[mask,'b']

.iloc[]
df1.iloc[0,0:2]
name3 name4
a one 1
two 2
Name: (a, one), dtype: int64
df1.iloc[0:2,0:2]

df1.iloc[[0,1],0:2]
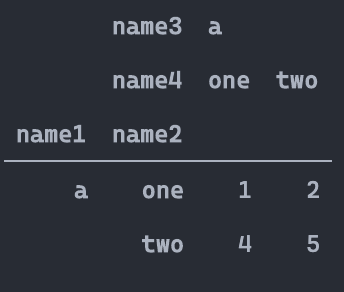
mask = [True, False, True]
df1.iloc[mask,0:2]

对于内层索引
内层索引不可直接使用,必须先外层、再内层,直接使用会报错;
内层只能使用单索引形式,其他形式报错。
[ , ]
df1
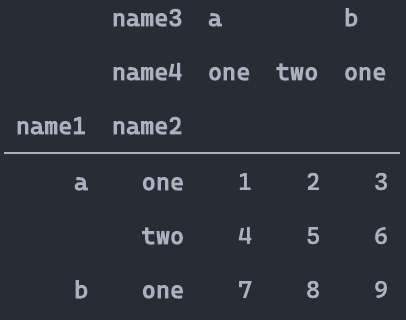
df1['a','one'] #取一列,先外层单列索引,再内层单列索引,其他形式都报错
name1 name2
a one 1
two 4
b one 7
Name: (a, one), dtype: int64
.loc[ , ]
df1.loc['a','one'] # 取一行,先外层单行索引,再内层单列索引,其他形式都报错
name3 name4
a one 1
two 2
b one 3
Name: (a, one), dtype: int64
xs直接选取法
适合在单层level选取,不能行列同时操作。
Series.xs(key, level=None, drop_level=True)
DataFrame.xs(key, axis=0, level=None, drop_level=True)
key: 要选取的索引值或其列表;axis:0-行索引,1-列索引;level:索引层次;drop_level:TrueorFalse,是否显示用于选取的level索引,默认不显示。
df1 = df.copy()
df1
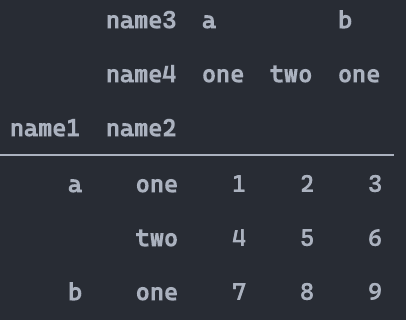
df1.xs( 'one', axis = 0, level = 1 ) # 行索引的level 1, 有两行

df1.xs( 'two', axis = 1, level = 1 ) # 列索引的level 1,有一列

普通列和行index的相互转化
data = [[1,2,3],[4,5,6]]
index = ['a','b']
columns = ['A','B','C']
df = pd.DataFrame( data = data, index = index, columns = columns)
df
A B C
a 1 2 3
b 4 5 6
普通列 转化为 行索引
DataFrame.set_index(keys, drop=True, append=False, inplace=False)
-keys:用于转化的列名称,列名或列名的列表,如果是列表则转化为多重索引;
drop:TrueorFalse,是否保留原列;append:TrueorFalse,是否保留当前索引;inplace:TrueorFalse,是否原地修改。
DataFrame中的列
注意:下面的这种用法只能处理单层列索引情况。
df.set_index('A', drop = True, append = False) #单列转化为行索引,列名作为索引的名字
B C
A
1 2 3
4 5 6
df.set_index(['A','B'], drop = True, append = False) # 列名的列表
C
A B
1 2 3
4 5 6
df.set_index(['A','C'], drop = False, append = False) # drop = False, 保留原列
A B C
A C
1 3 1 2 3
4 6 4 5 6
df.set_index(['A','C'], drop = False, append = True) # append = True, 保留原索引
A B C
A C
a 1 3 1 2 3
b 4 6 4 5 6
任意列
普通列不是必须为DataFrame中的列,任何行数匹配的列表或列表的元组都可以;
此方法可以处理多层列索引情况,方法是先提取需要的列,构建成元组,再来替换索引。
li = ['c','d']
df.set_index(keys = [li], append = False)# 注意是[li]不是li,如果是单层,会当做列名处理
## append为False,实现了改索引功能
A B C
c 1 2 3
d 4 5 6
#如果是多层索引情况,append为False,所有索性会被替换
df1 = df.set_index(keys = [li], append = True)
df1
A B C
a c 1 2 3
b d 4 5 6
df1.set_index(keys = [['e','f']],append = False)
A B C
e 1 2 3
f 4 5 6
# 元祖的列表建立多层索引
list_tuple = [('e','f'),('g','h')]
df1.set_index(keys = [list_tuple],append = False)
A B C
e f 1 2 3
g h 4 5 6
行索引 转化为 普通列
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')
level:int或者行索引的名字,可以为列表,默认包含所有行索引。drop:TrueorFalse,是否将行索引插入到列中,默认是插入;inplace:是否本地修改col_level:如果列索引也是多重的,那么新插入的列设置哪一重索引;col_fill:如果有多重索引,除了col_level已经设置的
单层 列索引 情况
df1 = df.set_index(['A','C'], drop = True, append = True)
df1
B
A C
a 1 3 2
b 4 6 5
# df1.reset_index(level = 'A', drop = False)
df1.reset_index(level = 1, drop = False) #单 行索引
A B
C
a 3 1 2
b 6 4 5
df1.reset_index(level = [1,2], drop = False) # 行索引的列表
A C B
a 1 3 2
b 4 6 5
In [13]:
#如果所有行索引都恢复为列,那么将生成默认数值索引,如果行索引没有名字,那么生成默认的名字
df1.reset_index(level = [0,1,2], drop = False)
level_0 A C B
0 a 1 3 2
1 b 4 6 5
df1.index.set_names(names = 'ab', level = 0, inplace = True)
df1
B
ab A C
a 1 3 2
b 4 6 5
#行索引如果有名字,那么将其设置为列名
df1.reset_index(level = [0,1,2], drop = False)
ab A C B
0 a 1 3 2
1 b 4 6 5
df1.reset_index(level = [1,2], drop = True) # drop = True, 直接丢掉选中的行索引,不插入
B
ab
a 2
b 5
多层 列索引 情况
df1 = df.copy()
df1.columns = pd.MultiIndex.from_tuples( [('one','A'),('one','B'),('two','C')])
df1
one two
A B C
a 1 2 3
b 4 5 6
#多重索引下,如果行索引没有名字,那么变为列之后在列索引的外层生成了默认索引:index。
df1.reset_index(level = 0)
index one two
A B C
0 a 1 2 3
1 b 4 5 6
#多重索引下,如果行索引有名字,那么变为列之后在列索引的外层索引名作为列名。
df1.index.set_names(['ab'], inplace = True)
df1
one two
A B C
ab
a 1 2 3
b 4 5 6
df1.reset_index(level = 0)
ab one two
A B C
0 a 1 2 3
1 b 4 5 6