建立有效的短视频建议
摘要
在社交媒体服务中,如何建立有效的个性化推荐系统是一个具有挑战性但极有价值的问题。本文着重于通过预测完成观看整个视频并按“赞”按钮的可能性,为短视频推荐构建通用框架。提出了四种新颖的技术来提高预测精度。首先,我们提出一种增量式多窗口扫描方法,以提取与用户行为有关的特征。此外,用户交互行为层次结构旨在捕获大量信息并减少计算时间。此外,模型转移能够将模型在其他数据集上学习到的知识转移到最终模型。最后,提出了一种基于AUC评价指标的基于等级的集成方法。在修订比赛规则之前,我们的方法长期以来在ICME短视频理解挑战赛(Track1)的最后阶段排名第一。
关键词
- 短视频推荐
- 模型迁移
- 融合方式
简介
随着基于短视频的社交媒体平台的日益普及,针对视频的个性化推荐已成为迫切而又具有挑战性的需求。 它允许用户接收与他们的喜好有关的视频的直接推送,而不是手动搜索内容。 这有助于提高用户忠诚度,并有助于在平台上分发新上传的内容。 但是,如[1]所述,开发推荐算法的两个主要障碍是可伸缩性和质量。 首先,许多传统的推荐算法(例如k近邻算法)无法处理大规模的数据集,而这种数据集在当今的应用场景中很普遍。 其次,推荐精度低的推荐系统会降低用户对应用程序的满意度。
TikTok也被称为Douyin,是基于短视频的社交媒体市场上的领先平台之一,每小时创建,上传和共享数百万内容。 为了使用户在启动TikTok时可以随时获得视频的娱乐和吸引,推荐策略必须基于用户的利益,这涉及用户的行为和对视频内容的理解,包括主题,编辑质量, 背景音乐和作者。
在过去的三十年中,针对个性化推荐的两种代表性策略是协作过滤(CF)和基于内容的过滤(CBF)。 根据用户对商品的偏好,CF将其与具有相似偏好的用户喜欢的商品进行匹配[1]。 奇异向量分解(SVD)之所以流行,是因为它能够减小维度,同时发现项目之间的相似性。 在著名的Netflix奖挑战赛中,[2]通过合并基于SVD的潜在因子模型和邻域模型赢得了比赛。 在[3]中构造了一个用户视频图,从中可以推导出共视信息。 通过吸收算法,可以基于相邻偏好信息的传播来做出推荐。 但是,视频内容的属性在基于CF的推荐框架中经常被忽略。
CBF不再关注用户,而是将重点放在项目本身的特征上。 在[4,5]中提出了一个在线视频推荐框架,该框架中获得了视频文档的多种模式的相关性,包括文本,视觉和听觉信息。 使用基于注意力的功能,融合了不同模式的相关性。 在[6]中,从视频中直接提取的低级视觉特征被包括在它们的模型中,以更好地理解内容。
为了更好地捕捉用户和视频之间的复杂关系,像Google这样的公司正在尝试将深度学习引入其推荐系统。 例如,[7]提出了一个两阶段的推荐框架,该框架由候选人生成模块和深度排名模块组成,其中考虑了视频功能和历史点击率。
在本文中,我们解决了短视频推荐问题,并提出了一个有效的通用框架。 为了提高预测精度,提出了四种新技术,即增量多窗口扫描,用户交互行为层次结构,模型传递和基于秩的集成方法。 其余论文的结构如下。 在以下部分中,首先给出问题定义。 然后,我们通过详细阐述四种提议的技术来介绍框架的概述。 在第4节中,介绍了实验设置和评估结果。
问题定义
这项研究的总体目标是预测用户是否会完成观看特定视频以及是否会单击“喜欢”按钮。
符号和问题定义如下:
-
符号:用户交互行为数据.用户交互行为记录可以分为与用户相关的功能,与视频相关的功能和与行为相关的数据。 与用户相关的功能包括用户的ID,城市和设备。 与视频相关的功能包括ID,作者,城市,频道,背景音乐和视频时长。 对于与行为有关的数据,包括用户是否完成观看和喜欢视频以及他们开始观看的时间。
-
符号:文字特征。首先从视频标题中删除了数字和符号。 然后,标题被分割成单独的单词。 最后,计算每个单词的出现频率。
-
符号:视觉特征。 这种类型的特征是由神经网络提取的,该神经网络将每个视频转换为128维向量。
-
符号:音频特征。此特征集也由神经网络提取,并转换为128维向量。
问题:
给定用户id和视频id,基于用户交互行为数据,文本特征,视觉特征和音频特征构建机器学习模型,以预测用户是否会完成观看并喜欢特定的短视频。
其中表示用于预测的第个用户视频对,是该用户完成观看短视频的概率,是单击“like”按钮的概率。
室验和结果
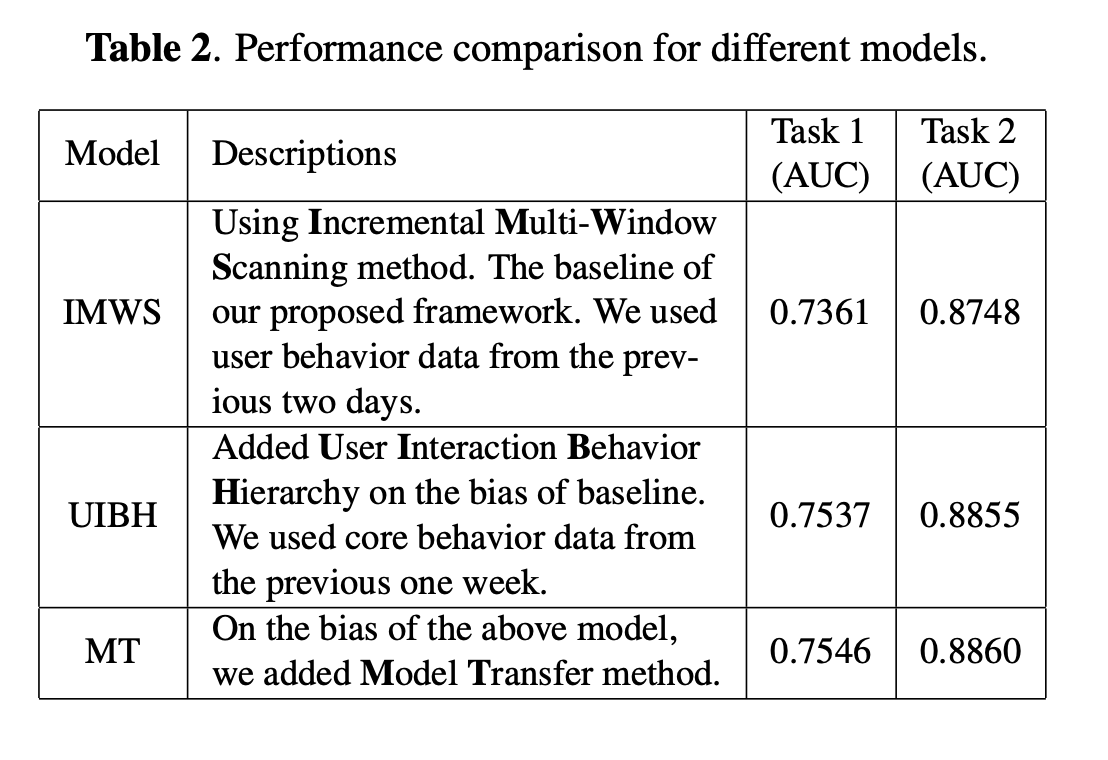
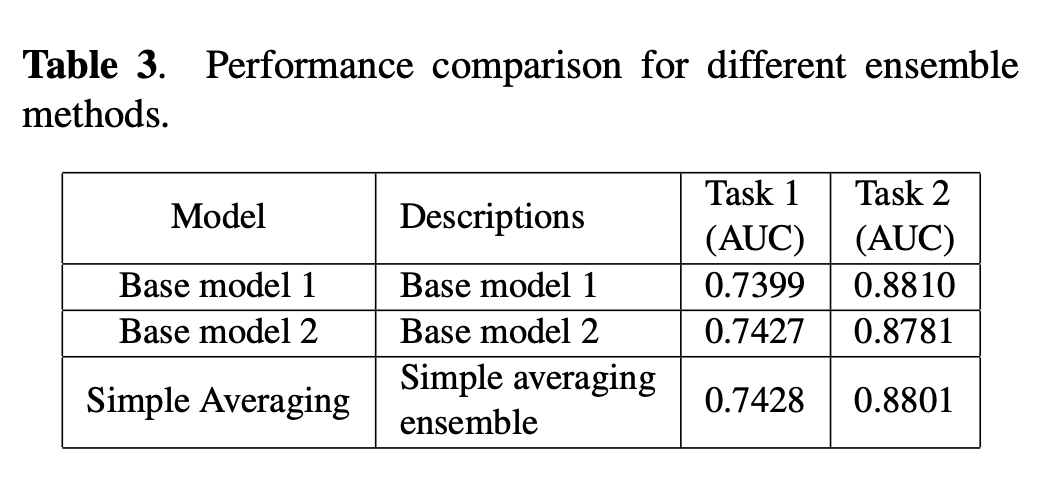
我们根据ICME短视频理解挑战赛(Track1)的数据评估了我们提出的方法。该数据集包含大约2.7天的2.7亿个用户交互行为记录,其中1.6%与“喜欢”行为相对应,其中28%完成了观看视频。在测试集中,大约需要预测3900万对用户视频。对于用户交互数据,我们从多个角度设计了许多统计功能,包括用户,视频和作者。例如,用户历史记录中“喜欢”行为的总数。关于视觉和音频特征,利用PCA,截断SVD [12]和随机投影[13]来减少128维原始特征向量的维数。对于文本特征,使用TFIDF和Word2vec将词频信息转换为特征向量。最终,保留了具有384维特征的3000万个样本,并将其用于模型训练,其中最后20%用于脱机验证。由于Track 1的数据量很大,并且我们的计算资源有限(没有GPU,小内存和2.4Ghz时钟速率),我们只能训练一个LightGBM模型[14],这对内存的需求较少。只要有更好的计算设备可用,DeepFM [15]之类的深度学习模型也值得利用和改进。表2和表3列出了不同模型的性能,其中AUC是比赛排行榜上的真实分数。
应当指出,比赛组织者仅剩四天的时间,对比赛规则进行了重大修改,即从每个团队每天提交一份,到每个团队成员每天提交10份。 此外,比赛和团队合并的截止日期都被推迟了。 换句话说,一个由五个成员组成的团队一天最多可以提交50个提交内容。 在修改规则之前,我们以比其他团队更大的优势排名第一,我们提交的总数在一个月内为19,远远少于其他团队。
结论
本文研究了社交媒体服务中的短视频推荐问题。这项研究的主要贡献是第3节中介绍的四种技术。增量多窗口扫描方法使我们能够从不同的粒度中提取用户行为特征,并使我们的基准方法达到排行榜的前三名。但是,特征提取过程中的较大时间窗口可能会导致计算资源的大量消耗。参照计算机体系结构中的内存层次结构,建议的用户交互行为层次结构使基于核心用户交互行为可以提取具有较大时间窗口的用户行为特征。根据实验结果,该方法不仅速度提高了50倍以上,而且显着提高了预测准确性。通过模型转移,可以将多个基本模型组合在一起以产生更好的结果。在基于AUC评估指标的任务中,基于等级的集成方法明显优于传统的简单平均合奏方法。所提出的推荐框架不仅适用于本文中讨论的短视频推荐问题,而且适用于许多其他问题,例如地理位置推荐[16]。
参考文献

