短视频推荐中新型融合结构的实践
摘要
近年来,流行的短视频内容理解和推荐技术已经成为研究热点。本文提出了一种新的基于内容的混合短视频推荐算法,同时使用了FM,FMM,DeepFM,DeepDCN模型)和短视频内容(视觉,文本,用户交互)等特点进行训练到时候,采用两种混合策略的组合策略进行学习,为用户返回短片推荐高质量的效果。为了评估所提出的算法,在Biendata开放竞赛平台上对短视频内容理解和推荐竞赛数据集进行了实验,该数据源于字节跳动公司拥有的TikTok(同音海外版)短视频APP,其中包括两个轨道。要求参与者通过视频和用户交互数据集对用户的兴趣进行建模,然后预测用户对另一个视频数据集的点击行为。在分析根竞赛结果的基础上,本文提出的算法有效提高了短视频推荐算法的性能。
关键词
- FM
- FFM
- DeepFM
- DCN
- Model fusion
简介
近年来,随着深度学习算法的发展,推荐算法领域取得了长足的进步。但是,由于缺乏以下内容:
- 在现实世界中具有足够准确度的大规模注释数据可用于训练和评估;
- 公正有效地评估公共平台,使识别结果可以复制和访问。为了激发和挑战学术界和工业界对短视频产品的内容理解和推荐算法的研究,TikTok的外部版本发布了数据赛道1和赛道2的数据集。在这段简短的视频内容理解和推荐竞赛中,我们分析了系统实现与比较模型之间的关系,并试图比较模型之间的演化效果以及系统引入模型的演化,最后将融合所有最终模型都在比赛中取得成绩,取得优异成绩。
数据集
这是基于TikTok真实场景的数据集。 track1数据集包含275,855,531个训练集,并且39,969,749个测试集可用于CTR算法。 此外,bienddata竞赛还开发了一个开放平台,以帮助将研究算法转化为评估或测试结果的可访问性,可重复性和可比性.ICME 2019挑战赛更加关注了最受推荐的内容领域,参赛者必须提交作品 通过视频和用户互动行为数据集对用户的兴趣进行建模,然后在另一个视频数据集上预测用户的点击行为。 也就是说,进入者需要针对测试集中的每条数据预测用户交互(完成+点赞)的概率。 比赛使用AUC作为评估指标。 在总分中,完成度等的比率为0.7 *完成度+ 0.3 *点赞。
该功能是从数据中提取关键信息以预测结果,文本或数据。 特征工程是使用专业背景知识和技术来处理数据的过程,以使特征在机器学习算法上的性能更好。 特征工程的目的是筛选出更好的特征并获得更好的训练数据。 由于良好的功能更加灵活,因此在本次比赛中,功能分类包括用户特征,项目特征,场景功能,后方功能,交叉特征,匹配功能,例如:用户的基本特征包括用户的号码,移动设备, 城市,以及用户点击的反馈信息。
反馈包括:收藏的视频,视频创作者,视频分类标题以及视频中人物的美。
视频特征:视频的标识号,创建者,城市,音乐ID,持续时间,视频中角色的性别,优美程度,字符数以及功能统计 ,作为项目的功能。
场景特征:用户在什么时间段观看视频,仔细分割时间,并将视频来源的统计信息作为模型的特征类别。
交叉特征:跨用户和视频功能,跨用户和场景功能,跨视频和场景功能以及其他功能。
特征选择是选择一些对预测多个特征的结果最有用的特征。 特征选择是对预测多个特征的结果最有用的特征的选择。 因为原始功能可能具有冗余和噪音。 因此,我们通过以下方法进行特征选择:皮尔逊相关系数,互信息,距离相关。
模型
在比赛开始时,我们尝试了传统的机器学习模型。 后来,随着竞争的深入,我们尝试了其他复杂的模型。
排名模型
在本次比赛中,我们对FM模型及其扩展模型进行了多次尝试。 在一开始,我们尝试了一个简单的模型,后来又尝试了一个更复杂的模型。 在推荐系统中,良好的特征工程是最重要的,但是良好的模型将对比赛的最终结果产生重大影响。 我们使用了FM,FFM,DeepFM,DCN,XDeepFM等模型,模型的演化路径如图1所示。
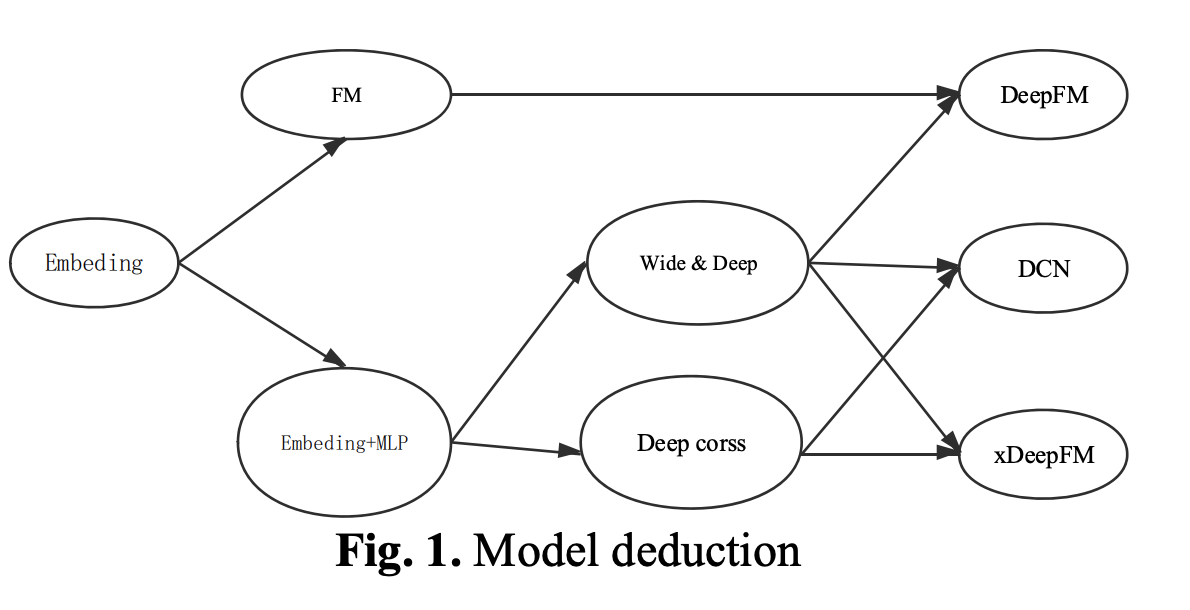
FM
以普通线性模型为例,无论特征与特征之间的关系如何,我们都独立考虑每个特征。 但实际上,许多功能是相关的。 在此竞赛数据上,用户信息(例如帐号,城市,设备),工作信息(已出版作品的作者,标题,持续时间,性别和其他作品)和场景信息(观看时间,工作来源)是关键 是在用户,作品和场景之间找到功能的组合。 例如,男性用户喜欢观看女性作品中更多的作品,以及具有较高美感的作品,因此用户ID和美学的结合是关键特征。
线性模型表示为:
传统的线性模型不考虑特征之间的关联,而是使用多项式表示特征之间的关联。 和的组合由表示。因此,二阶模型表示为:
FM模型便于组合离散值特征,对于常见的离散值特征,最常见的方法是单热编码,但是鉴于这种竞争的规模,我们使用分布式聚类进行特征编码。 计算使用的功能,并建立词汇表。 每个功能都有对应的代码。 重复数据删除后,将为每个功能生成相应的代码,与单次热编码相比,可节省大量空间。 节省大量资源,训练速度得到了极大的提高,以加快功能的优化和模型的迭代。 FM模型的初始性能仅使用离散值特征的组合,而不使用其高阶特征。
FFM
FFM将具有相同性质的特征归于同一场。对于每个维特征,FFM模型为其他特征的每个场学习一个隐藏的向量。 因此,隐藏矢量不仅与特征有关,而且与领域有关。 这也是FFM模型的现场感知的起源。 假设样本总共具有个特征(个场),则FFM的二次项具有n*f个隐藏向量。 在FM模型中,每个尺寸特征只有一个隐藏向量。 FM可以看作是FFM的特例,它是将所有要素分配到一个字段的FFM模型。 根据FFM的场敏特性,可以推导模型方程。
DeepFM
分解机(FM)是每个尺寸特征的隐藏变量的特征组合。 尽管理论上结合了高阶特征,但在计算中仅使用了二阶特征的组合。 顺序特征的组合使用多层神经网络进行组合。 在对离散特征进行编码之后,尽管减少了存储空间并减少了资源消耗,但它本质上是一种独热形式。 在DNN中输入这种一键式特征会导致太多网络参数。 参照FFM的思想对特征进行分类,将最原始的独热形式转换为稠密向量形式,稠密向量层实现FM与DNN的共享,从而将二阶特征与高阶特征进行组合。
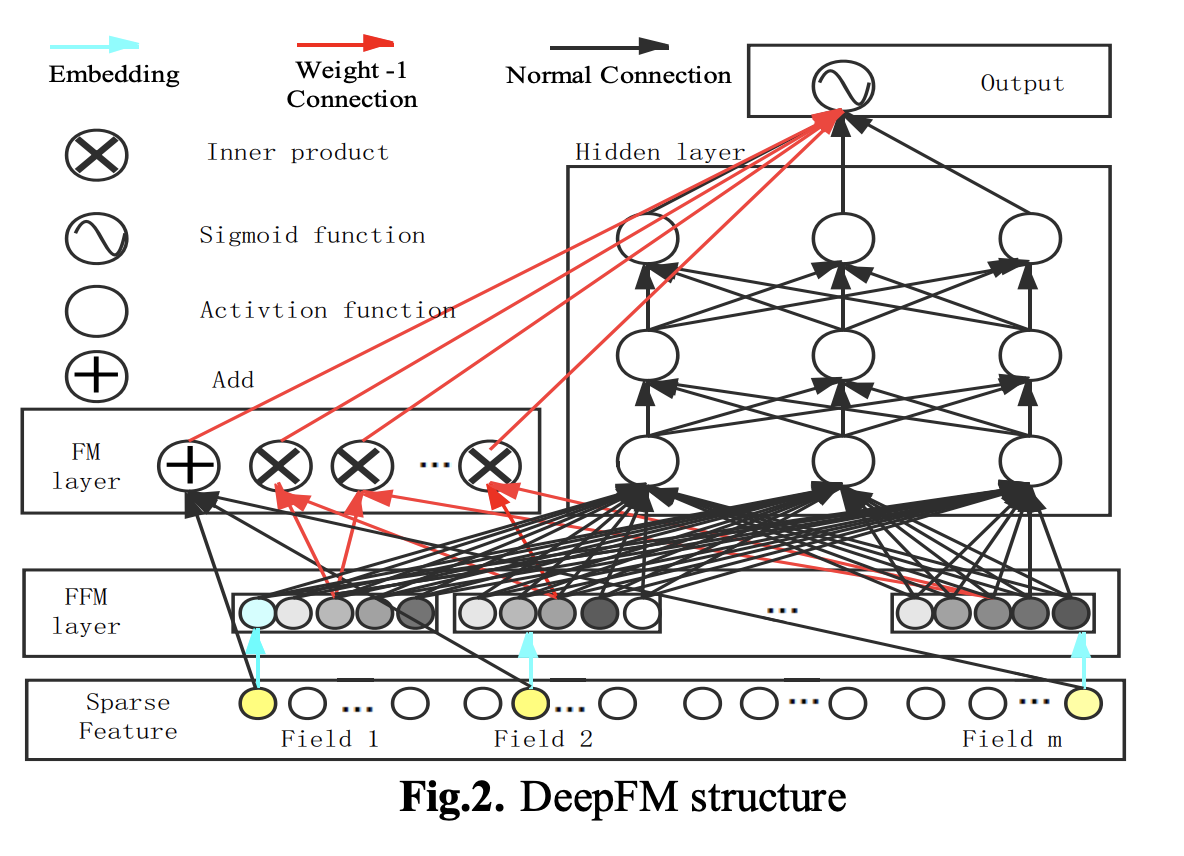
DeepFM由两部分组成:神经网络部分和分解机器部分,分别负责低阶特征的提取和高阶特征的提取。 这两个部分共享相同的输入。 DeepFM的预测结果可以写成:
FM的二阶特征被转换为密集向量。 作为DNN的输入功能,两个模型被共同训练。 我们在DeepFM模型竞赛中使用的深度神经网络隐藏层的层数为[256,128,64]。 该特征的单词嵌入大小为32维,学习速率为0.02,激活功能为RELU。 梯度下降优化器是Adagrad。
DCN
我们已经在竞争数据上尝试了新模型的性能。 DCN模型比较了以前的DeepFM模型,其中DNN网络层次结构和DeepFM模型具有相同的网络层次结构。 主要区别在于DeepFM模型中FM模型的一部分,已由功能的跨网络替代。
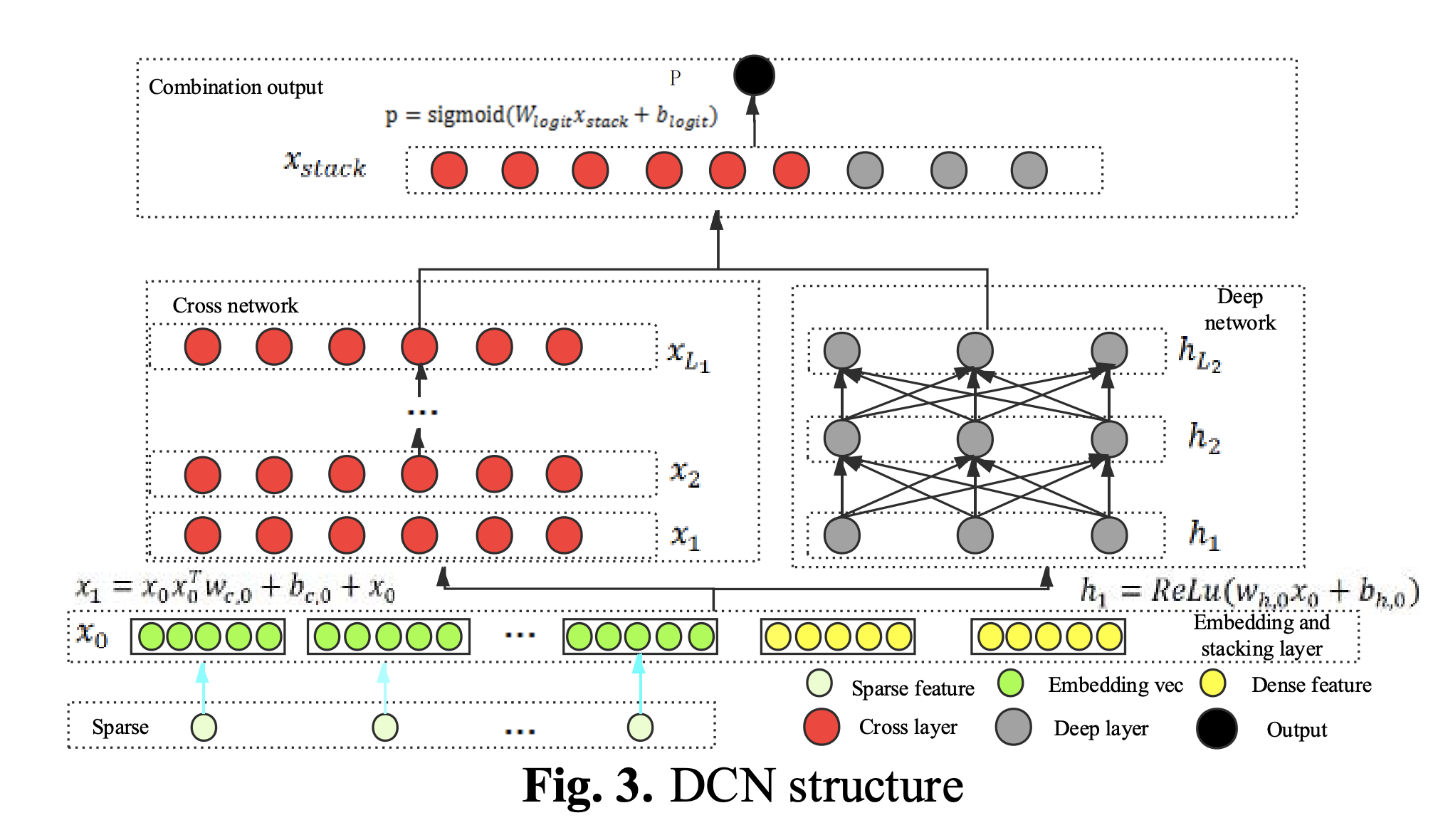
许多输入数据是离散特征。 一键编码后,这些特征会导致过多的高维特征空间。 为了减小尺寸,通常的做法是将这些离散特征转换为实值密集向量。
然后将其叠加在连续特征向量上以形成向量。
拼接后的向量将用作我们的跨网络和深层网络的输入。 DCN可以有效地捕获有限的有效特征的相互作用,学习高度非线性的相互作用,无需人工特征工程或遍历搜索,并且具有较低的计算成本。 dcn的隐藏层数为[1000,1000,1000],在交叉网络中使用三层交叉结构,学习率为0.02,激活函数为RELU。 梯度下降优化器是Adagrad。
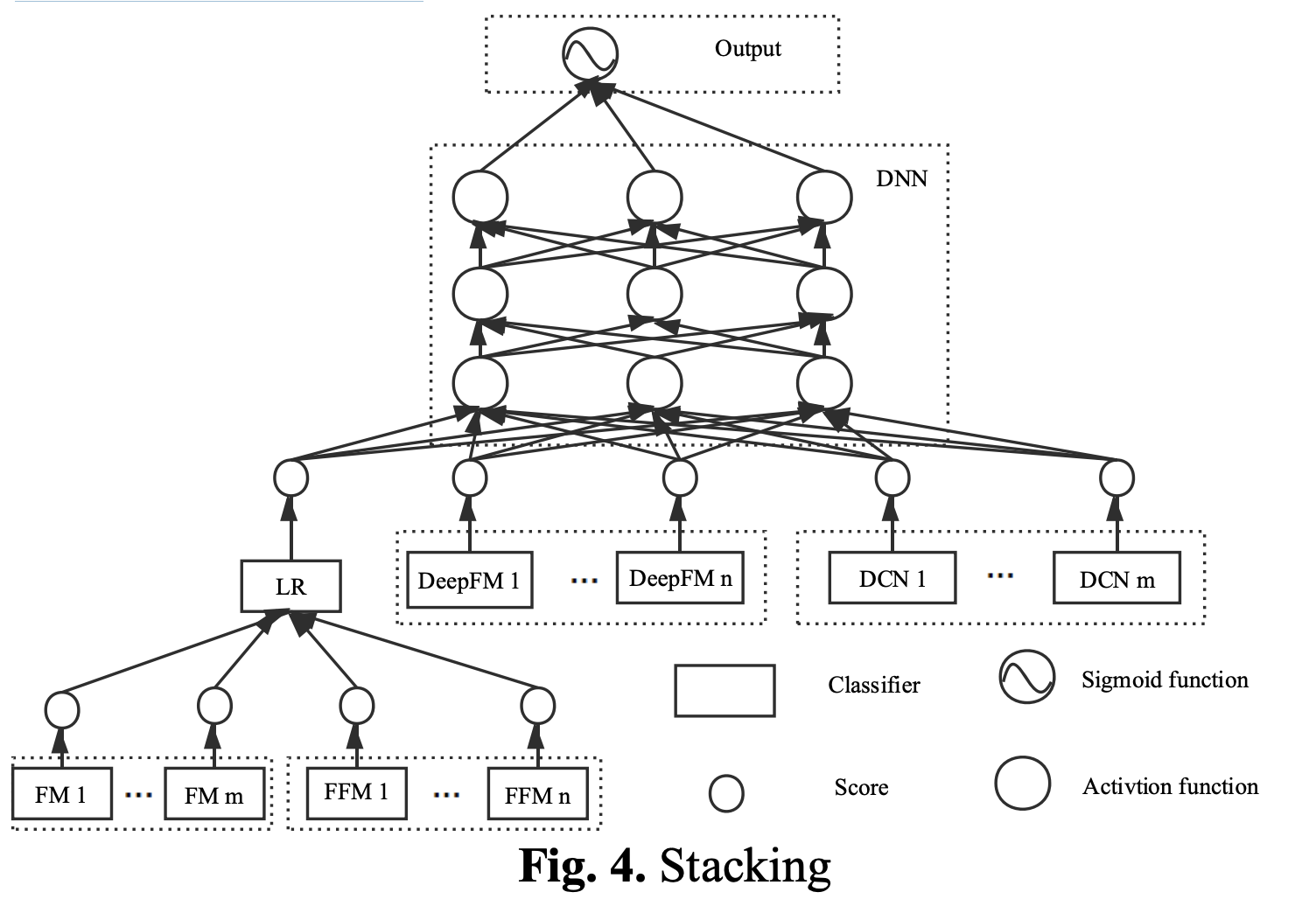
模型融合
尽管各个模型在数据上的得分非常好,但是模型的最终融合在改善比赛成绩方面有更好的表现。 模型的融合通常分为两种,一种是装袋,另一种是堆叠。
我们的模型融合装袋方案是对每个模型的分数求和后取平均值。 看起来很简单,没有脑子,但是非常有效。 但是权重没有很好地确定,我们使用离线交叉验证来确定权重,但是效果未能达到预期。
第二种模型融合方案是堆叠。 每个模型的分数都作为特征,并输入到新的分类器中以训练结果。 我们的方法是比较多个分数较低的模型,先装袋效果更好。 结果,在堆叠了复杂模型之后得分更高的模型,最终得分被视为比赛的最终结果。
实验结果
实验结果分为两部分,一是传统模型与模型融合的实验结果,二是融合模型的总分。
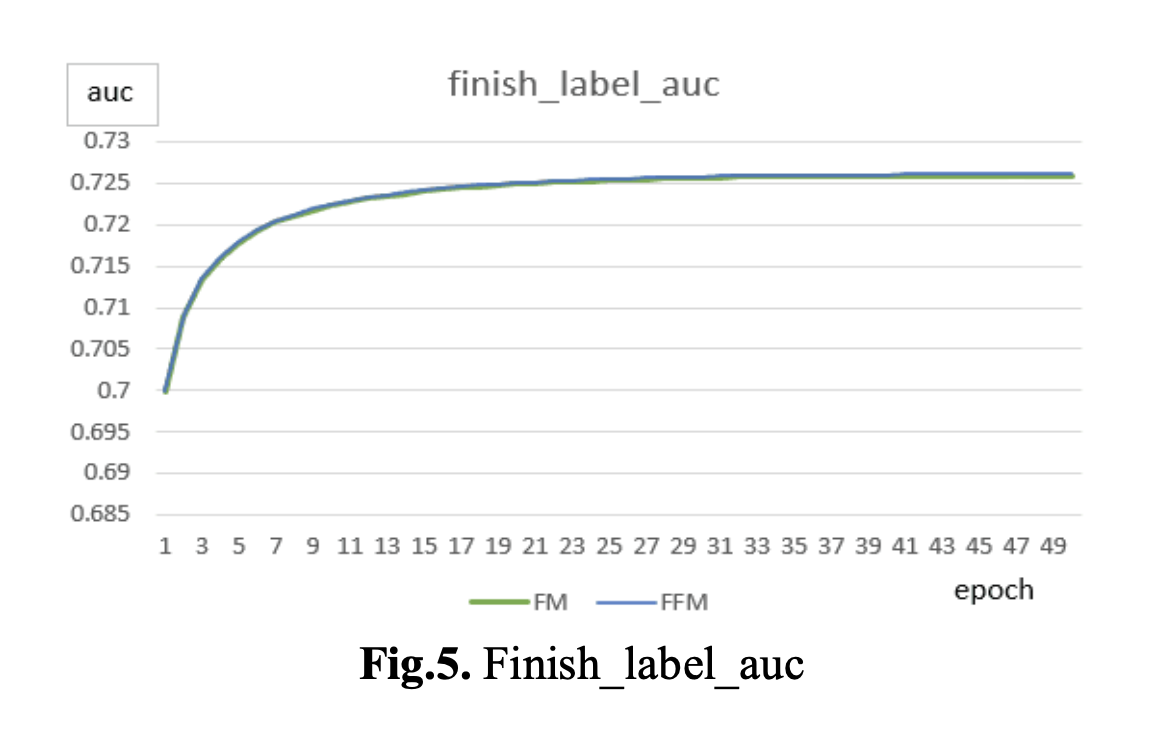
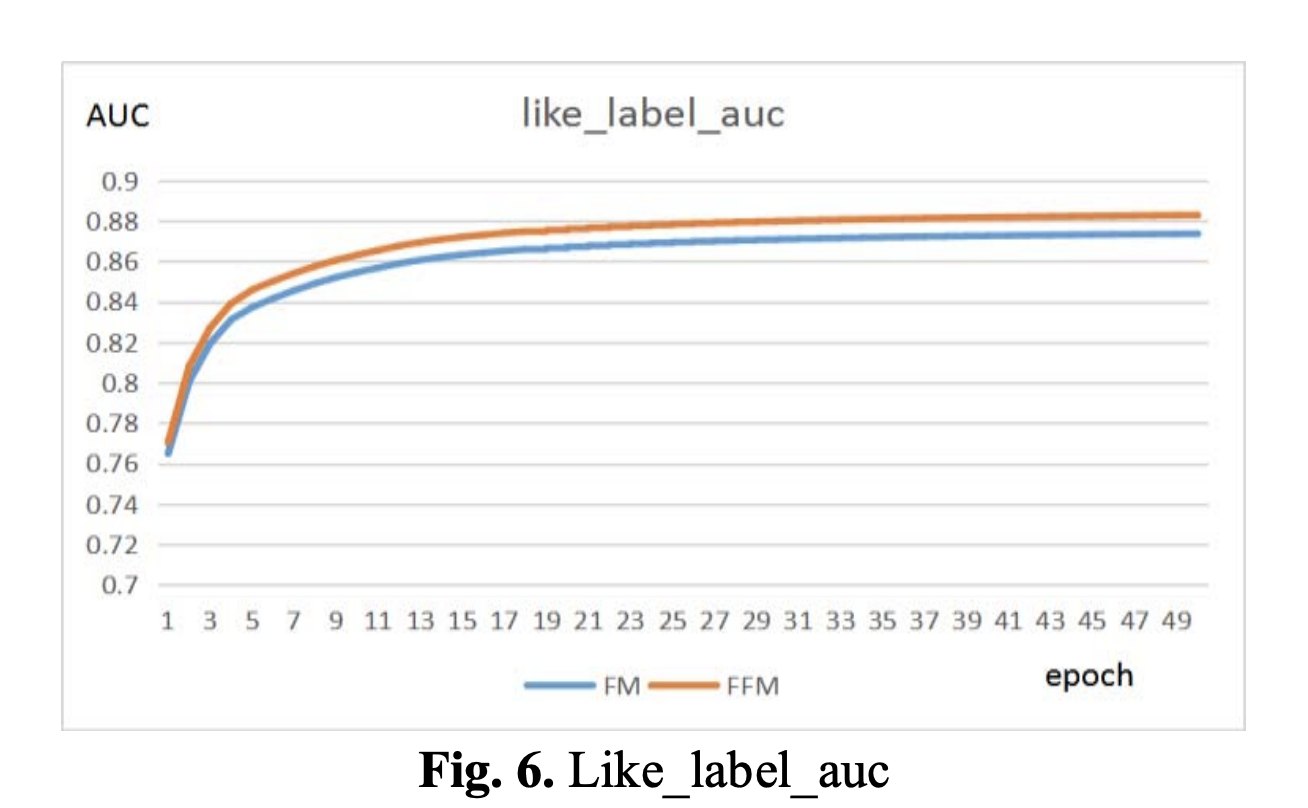
尽管FM模型在验证集上表现更好,但在实际测试集上却表现不佳。 可能的原因是训练集和测试集的数据分布不同,结果如图5和图6所示。
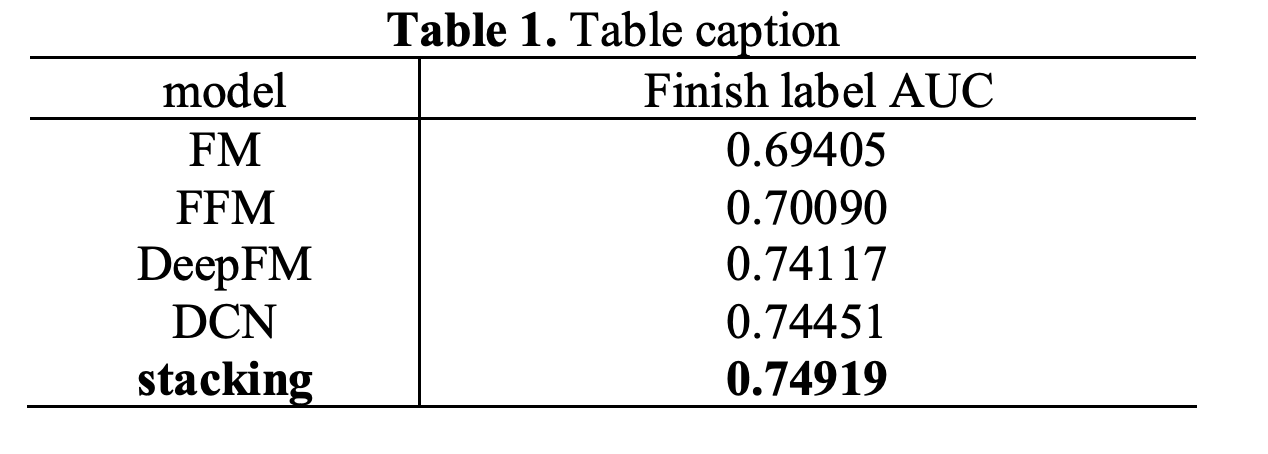
实验表明,堆叠后的模型具有比表1中的传统模型更好的性能。
为了证明模型各部分的有效性,我们对模型的四个主要部分进行了消融实验。 表2显示了融合模型的多次实验后的总分。 总得分结果的权重为0.7 * 完成度 + 0.3 * 喜欢。

结论
特征工程是最重要的部分。 我主要研究模型的数据和要素工程的各个部分。 其余的功能工程由团队中的其他成员提供。 在比赛开始时,我们尝试了传统的机器学习。 该模型在稍后阶段尝试了更复杂的深度神经网络模型,并且该模型显示出了极大的数据改进,因此我们坚持使用它。 最有影响力的功能是时间。 匿名化时间数据需要对数据有充分的了解和分析,甚至需要尝试基于业务理解执行反编码,这可以指示特征工程的方向。 模型的融合是我们成功的关键。 套袋和堆叠是模型融合的常用方法。 最初,我们尝试添加功能并获得一些不错的单一模型。 将这些单个模型的分数合并后,分数将大大提高。
引用
