短视频理解和推荐的多模态表示学习
摘要
我们研究了简短的视频理解和推荐任务,该任务根据多模式内容(包括视觉功能,文本功能,音频功能和用户互动历史记录)预测用户的偏好。 在本文中,我们提出了一种多模式表示学习方法,以提高推荐系统的性能。 该方法首先将多模式内容转换为嵌入空间中的向量,然后将这些向量连接起来作为多层感知器的输入以进行预测。 我们还提出了一种新颖的键-值存储器,用于将密集的实值映射到向量中,从而可以通过非线性方式获得更多的语义。 实验结果表明,在ICME 2019短视频理解和推荐挑战赛的数据集上,我们的表示法显着改善了几个基准并实现了卓越的性能。
关键词
- 多模态表示
- 因子分解机
- 键值记忆
- Word2Vec
- 随机游走
简介
简短的视频理解和推荐旨在通过视频和用户互动历史记录来模拟用户的兴趣,从而预测用户的点击行为,即预测点击率(CTR)。最近,基于神经网络的方法[1,2,3,4,5]在CTR预测中取得了令人鼓舞的性能。 这些方法主要提取分类特征交互或利用图嵌入进行CTR预测。 同时,其他现有作品往往主要集中于单模态特征。 在视频内容理解领域中,如果不考虑多媒体,用户点击历史记录和社交图等多模式功能,则推荐系统的性能将受到负面影响。
在这项工作中,我们研究如何利用具有不同结构的多峰特征。 具体来说,我们的方法首先将多模式内容转换为嵌入空间中的向量,然后将这些向量连接起来作为多层感知器(MLP)的输入。 同时,我们提出了一种新颖的键-值存储器[6],它将密集的实值映射到向量中,从而可以通过非线性方式获得更多的语义。 训练MLP的一个显着缺点是嵌入的分布随内容的不同而变化,这不利地减慢了训练速度。 为了解决这个问题,我们将批处理归一化到输入中。
我们对ICME 2019短视频理解与推荐挑战赛的数据集进行实验。 这项挑战提供了多模式视频功能,包括视觉功能,文本功能,音频功能和用户交互历史。 根据用户交互的历史记录,我们现在能够在用户之间构建社交图。 该任务旨在预测每个用户完成观看并喜欢给定视频的可能性。 结果表明,通过将我们的多模式表示应用于推荐系统,可以进一步改进,提高了1.5%,明显证明了所提出的多模式表示学习的有效性
相关研究
个性化推荐是机器学习中的一项基本任务,旨在学习预测用户认为哪些项目(即我们作品中的视频)有趣的能力。 近来,这些特征的尺寸和形式已经变得更大并且更加多样化。 同时,现有模型的结构已从浅到深演变。
线性模型,例如使用FTRL的逻辑回归[7],由于易于管理,维护和部署而被广泛采用。 但是,线性模型缺乏学习隐藏特征的能力,这需要大量的工程交叉特征才能获得更好的性能。 因此,一些研究人员利用增强决策树[8]来帮助构建特征转换[9]。 为了克服高维和稀疏特征的问题,分解机器[10,11]将每个特征嵌入到低维潜矢量中。 与非因式分解模型相比,由于能够通过两个潜在向量的乘积进行推荐,因此它们能够学习特征交互。
最近,神经模型在推荐系统中被证明是有效的[1,2,3,4,5]。 这些方法试图从分类特征交互中自动学习模式。 与这些作品不同,我们考虑具有更复杂结构的多模式特征,例如多媒体,用户历史记录序列和社交图。 我们的方法将多模式内容转换为相同的方式(即嵌入),以增强推荐系统。
方法
我们将首先概述我们的方法,然后描述一种多模式表示学习方法,该方法将各种类型的内容转换为嵌入空间中的潜在向量。
概述
图1概述了我们的模型。 首先,给定多模式内容,我们利用各种方法将这些内容转换为嵌入。 由于嵌入的分布随内容的不同而变化,这不利地减慢了训练速度,因此使用批范数层对这些向量进行归一化。 最后,将这些向量的级联视为输入,以预测每个用户是否会按照Sigmoid函数完成观看并喜欢MLP的给定视频。
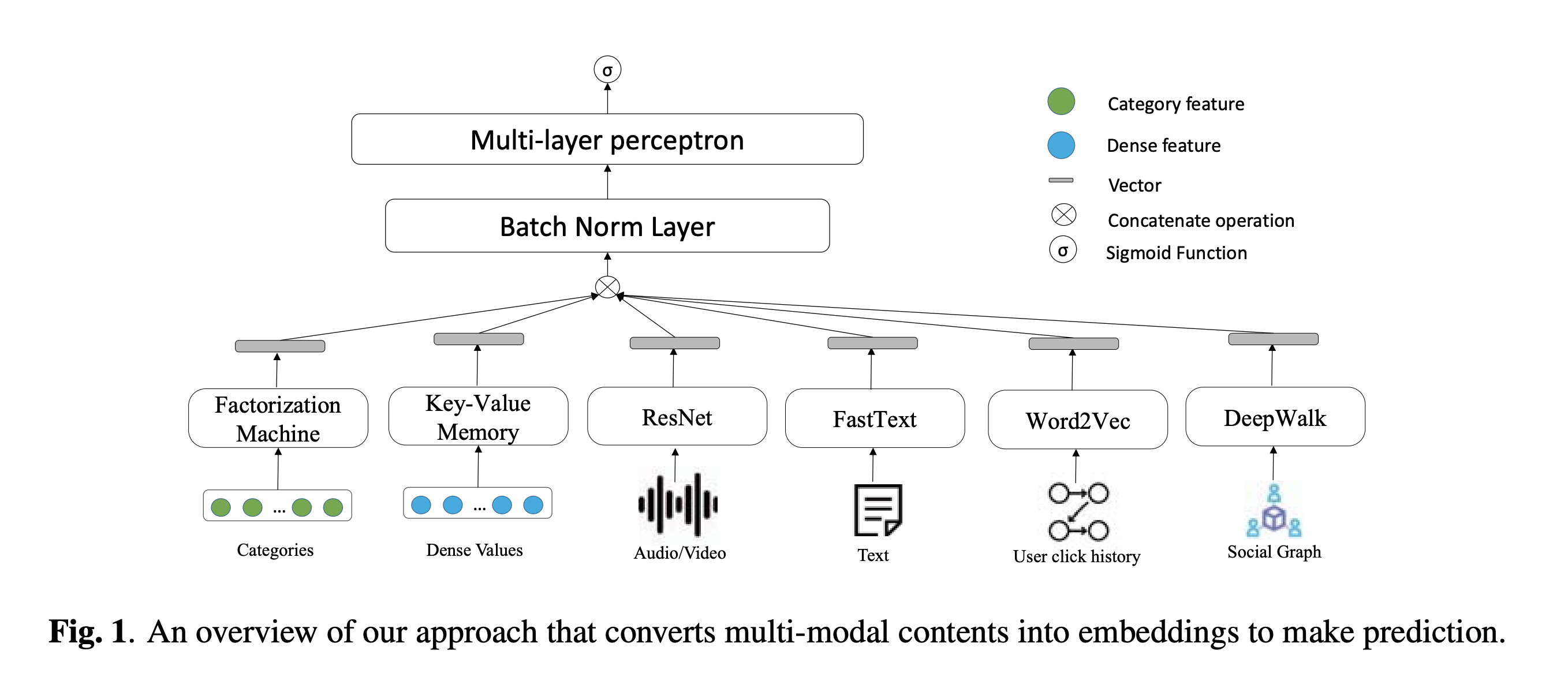
多模态表示
类别特征
类别功能非常稀疏,但有助于简短的视频理解和推荐[10]。 例如,用户通常会观看某些创作者的视频,这可以帮助我们预测用户是否会喜欢这些视频。 为了提取稀疏类别之间的交互特征,我们利用深度分解机来获取特征交互。 具体来说,首先将类别特征馈入嵌入层以获得相应的嵌入,然后使用压缩交互网络(CIN)[3]以显式方式在矢量方式上生成特征交互。
密集实数值
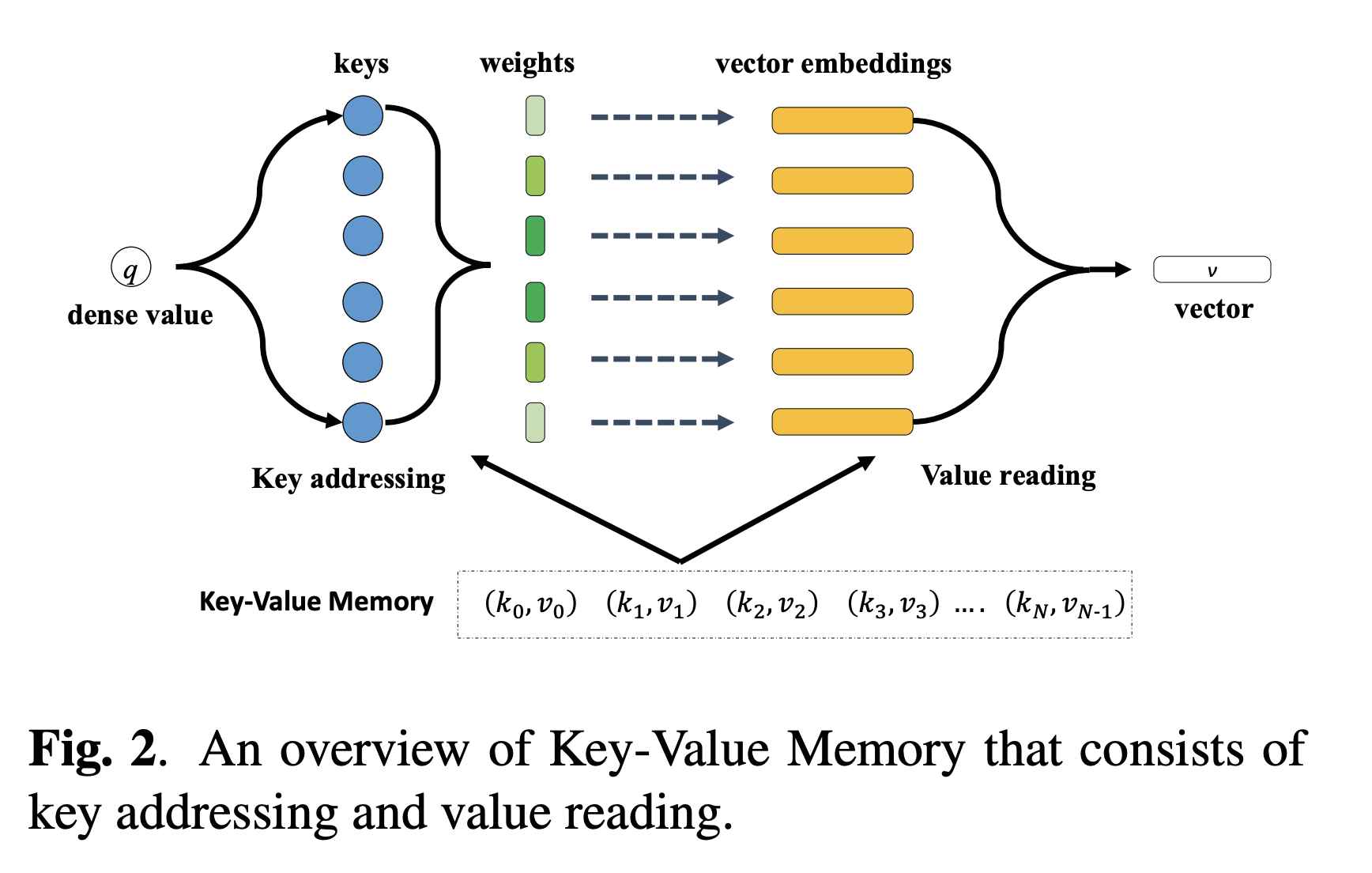
使用密集实值的传统方法直接输入到神经网络中,或分为多个存储桶作为类别特征。 取而代之的是,我们提出了一种利用键值存储器[6]将密集的实值映射到向量中的新颖方法。 基本思想是对平均可训练向量嵌入进行加权。如图2所示,键值存储网络由两个阶段组成。 在第一阶段(即键寻址),我们根据给定的密集值计算可训练向量嵌入的权重,如公式1所示。在第二阶段(即值读取),我们根据到目前为止的权重获得密集实值的最终表示形式。
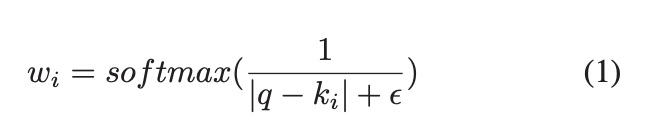
其中是可训练向量嵌入的数量,是第个向量的键,并且hyper参数在dev集上进行了调整。 我们将稠密值标准化为0到1,设置为。
多媒体
短视频推荐中的多媒体内容通常包括视频,音频和文本(例如图块),可提供有关推荐的短视频的高级信息。 我们采用Resnet [12]将视频和音频编码为嵌入。 另外,我们使用FastText [13]通过平均词嵌入来编码文本。
用户点击历史
由于用户通常倾向于关注类似的作者或简短的视频,因此我们可以随后将其聚类。 我们描述了如何对短视频进行聚类并获得它们的嵌入。 作者嵌入的计算类似于短视频嵌入。用户的点击历史是视频的序列,其中用户单击后点击第个视频。我们可以将序列视为句子,将视频视为单词。 然后,我们利用Word2Vec [14]来表示视频,它可以将类似的短视频聚集在嵌入空间中。 最后,我们提取用户点击的当前视频的嵌入作为历史特征,以进行最终预测。
社会图
社交图可以反映用户之间的社交关系,这有助于通过统计模型预测用户的偏好。 我们定义了一个用户视频社交图,其中包括两种顶点(分别是用户和视频)。 从用户顶点到视频顶点的边缘意味着用户单击视频一次。 然后,我们在该社交图上采用DeepWalk [15](一种用于学习顶点的潜在表示)的方法来获得顶点的潜在向量。 这些潜在向量在嵌入空间中编码社交关系,可以将其馈入神经网络。 此外,我们还定义了一些社交图来改进我们的模型,例如用户-作者社交图。
学习
在本节中,我们描述如何学习我们的多模式表示。 对于Word2Vec和DeepWalk,这些方法可以在无人监督的情况下学习用户点击历史和社交图的表示(有关学习的更多详细信息,请参见[14,15])。 音频和视频的表示形式是从ResNet预训练中提取的。 其他嵌入将通过最大化地面真理的对数概率之和来进行有监督的训练。
在这里,我们列出了培训的详细信息。 我们将分解因子机器和FastText的维度设置为16,将Word2Vec和Deepwalk的维度设置为64。这一挑战提供了预训练的ResNet嵌入。 在键值存储器中,每个字段的可训练嵌入数为100,维度为16,超参数。
使用均匀分布初始化模型参数,并使用Adam优化器对其进行更新。 我们将学习率设置为0.0002,批量大小设置为4096。仅对模型训练了一个时期。
实验
我们在ICME 2019短片视频理解与推荐挑战赛中进行了实验。 数据集由ByteDance提供,包括3百万个示例。每个示例均包含分类特征(例如作者和用户信息)和短视频的多媒体内容。 在本竞赛中,该任务旨在预测用户浏览视频时完成观看和喜欢短视频的可能性。 AUC(ROC曲线下的面积)用作评估指标。 最终得分通过加权平均完成度以及0.7和0.3之类的得分获得。
模型对比

我们在数据集上报告了现有方法的结果,并证明了我们的多模式表示学习是提高当前推荐系统性能的有效方法。 我们实现了几种方法,包括FM [10],这是一个分解因子的机器。 XdeepFM,先进的广泛深度神经网络,可用于CTR预测; Xgboost是可扩展的树增强系统。 基本的基本特征允许模型仅使用分类特征进行预测,而多峰特征是本文提出的多峰表示。 根据表1,我们可以看到,将多模式表示应用于Xgboost模型会产生进一步的改进,绝对增益为1%。 此外,我们通过提供多模式表示将MLP与批处理规范层结合使用,以80.00%的得分获得优异的性能,这表明我们的多模式表示可用于不同的模型。
不同表征的影响
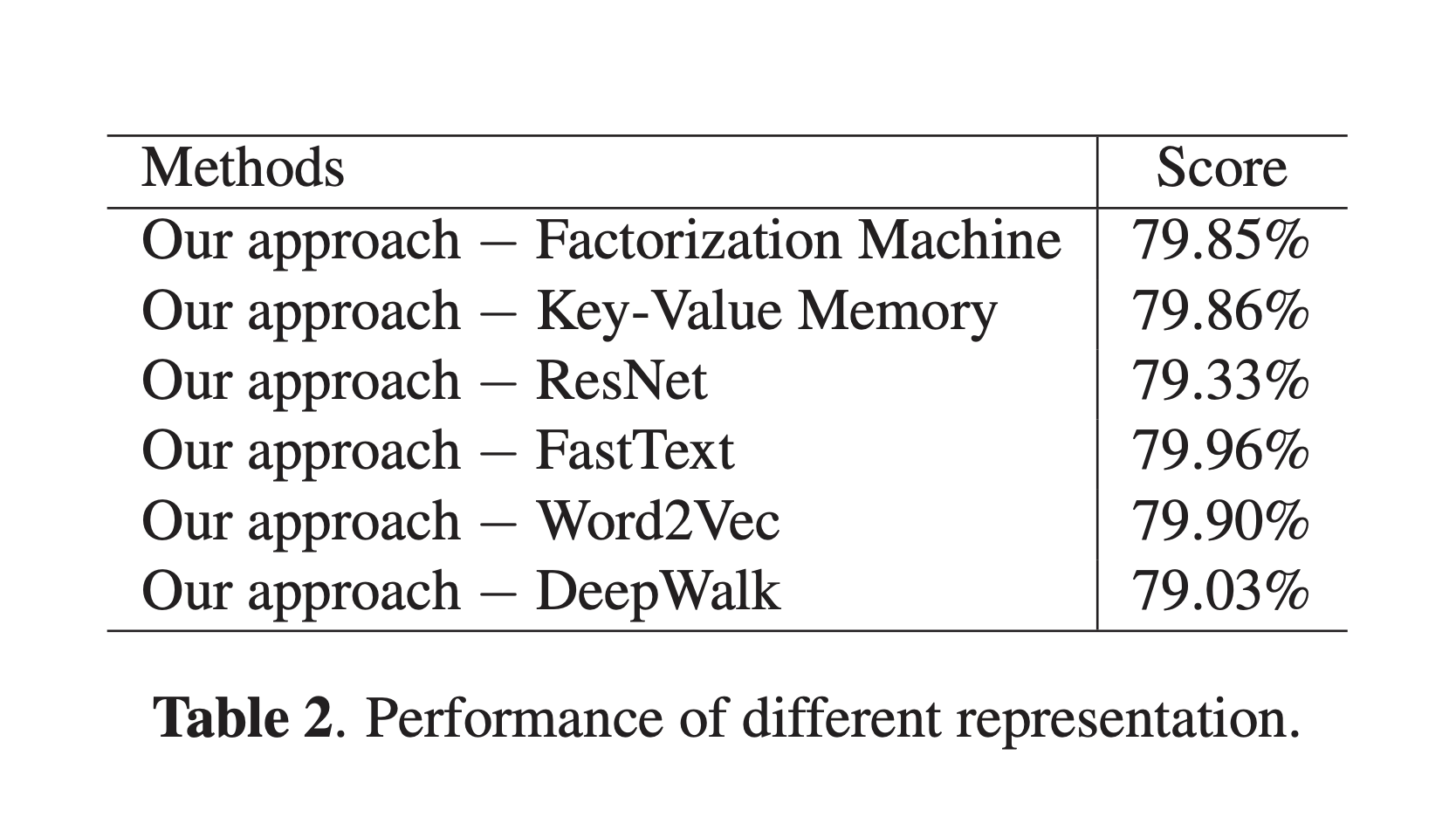
我们进行消融分析,以更好地了解各种组件如何影响我们的表现的整体表现。 我们删除每个组件以分别分析它们的贡献。 表2显示,消融DeepWalk时,得分从80.00%下降至79.03%,这表明社交图在短视频推荐场景中的重要性。 删除ResNet后,得分下降至79.33%。 这与我们的直觉一致,即视频/音频的内容是为用户推荐更多简短视频的关键因素。 我们可以看到其他表示形式也带来了0.1%〜0.2%的改善。
结论
在本文中,我们提出了一种将多模式内容转换为嵌入内容的多模式表示学习方法,以及一种通过键值存储器将密集的实值映射到向量的新方法。 我们表明,我们的多模式表示学习方法可以进一步改善推荐系统,并且我们提出的键值存储可以更好地利用密集的实值。
参考文献


